AI的简单学习
背景
原型系统
链式调用黏合剂(Langchain)
- 调度中心将帮助大语言模型(LLM)连接到我们之前学到的各种生态组件
- 如计划组件、记忆组件和工具组件等等
- 零代码快速搭建(Flowise)
- 领域知识库(Embedding & 向量检索引擎)
- 自主可控 LLM 底座(LocalAI)
- 更高、更快、更强(Llama)
工业级的大模型系统
误区
- 将 LangChain 和 AutoGPT,只是原型,跟工业级差很远
- 将 Embedding 检索奉为记忆增强的“圭臬”
- 无视开源大模型的内容生成质量问题
架构基础
推荐系统
AIGC 是从 内容推荐系统 AIRC 演化来的
AIRC 系统可以分成三大部分的工作
- 策略建模
- 数据工程
- 模型工程
策略建模,也就是指标建模
- 对商品进行排序,优先展示排序靠前的内容
- 一个是如何得到排序的概率值
- 第二是,如何对海量商品进行在线“实时”的排序
- 将用户对每个商品的期望收益进行排序,将排名靠前的商品,展示给用户
- 大规模数据排序不现实,AIRC 系统往往会拆分为召回和排序两个模块
- 召回模块的核心目的,就是用时间复杂度较低的算法排除大量的“错误答案”,减少排序算法的压力。
- 如 倒排索引中拉取内容,还需要对业务有深入了解
风控模块
- 工业级的系统最大的特点是要考虑线上风险
特征工程
特征处理的过程是对数据进行微观和宏观投影的过程
总结
- 对特征进行微观投影,得到特征的特征
- 怎样把低维特征投射到高维空间,使用独热编码
- 怎样在高维空间,刻画特征之间的语义关系
- 用对比学习的方法,刻画了高维空间中的特征距离
- 也就是单词之间的语义关系,进而让模型“抄近道”理解特征在现实世界中的关系
模型工程
监督学习(Supervised Learning)
- 根据问题和答案,拟合这个过程
- 点击率模型(CTR),不断尝试逼近结果
- 梯度下降法,它是一种投石问路、步步逼近的策略
对比学习(Contrastive Learning)
- 只需要得到样本之间的“相似度”就能完成训练
- 用户和物品是图的节点,它们之间的交互行为是图的边,边的权重则是它们交互行为的频率
强化学习(Reinforcement learning)
数据算法
根据具体的业务场景选择适合 AI 系统的数据
- 用户画像的构成,以及相似人群扩展的技术
- 数据来源:第一方数据,用户使用产品时产生的信息,如用户注册信息,人群特征数据,来自数据平台
- 第二方数据,是团队内部产品或者业务伙伴提供的数据
- 第三方数据,数据供应商提供的数据,例如从 BlueKai、秒针这类地方购买的数据
- 难点:第一种是对数据做“身份对齐”的能力,比如对同一人在多设备、多账号产生的数据做身份识别。
- 第二种则是挖掘某个人群的“潜在用户”的能力,比如识别符合某个品牌产品调性的用户
- 人群扩展算法(Look-alike)
- 1、挖掘潜在高净值用户
- 2、提高风控能力
- 3、提高冷启动推荐效果
- 物品特征的构成,知识图谱技术的关键步骤
- 由多个“实体 - 关系 - 实体”的三元组所组成
- 在 AIRC 系统中发挥了重要的作用,同样也是 AIGC 系统中,提示语工程的重要组成部分
- 首先是知识抽取、然后是知识融(包括对齐实体、对齐关系和解决冲突等)、最后是知识加工
- 如果某个用户对美白感兴趣,基于POI收集相关物料,生成更服务用户喜好的产品介绍,提高点击率
- 场景特征的定位,以及实时特征的独特价值
- 应用程序所处的界面(应用、页面、媒体位等)
- 用户的设备信息(信号强度、手机型号、电池电量等)
- 所在地点信息(城市、气温、邮编等)
- 将与用户长期习惯相关的数据放在用户画像
- 随着场景变化频率较高的数据应该放在场景特征中
- 场景特征的最大价值,在于它在时间维度上的区分性和敏感性
- 如:用户最近 30 分钟的商品点击数量”或“用户最近 1 小时浏览商品数量;会对推荐结果产生很大影响
- 用户画像和物料特征数据相对稳定,更新频率不高;场景特征的输入可以让模型变得更加敏感
离线系统
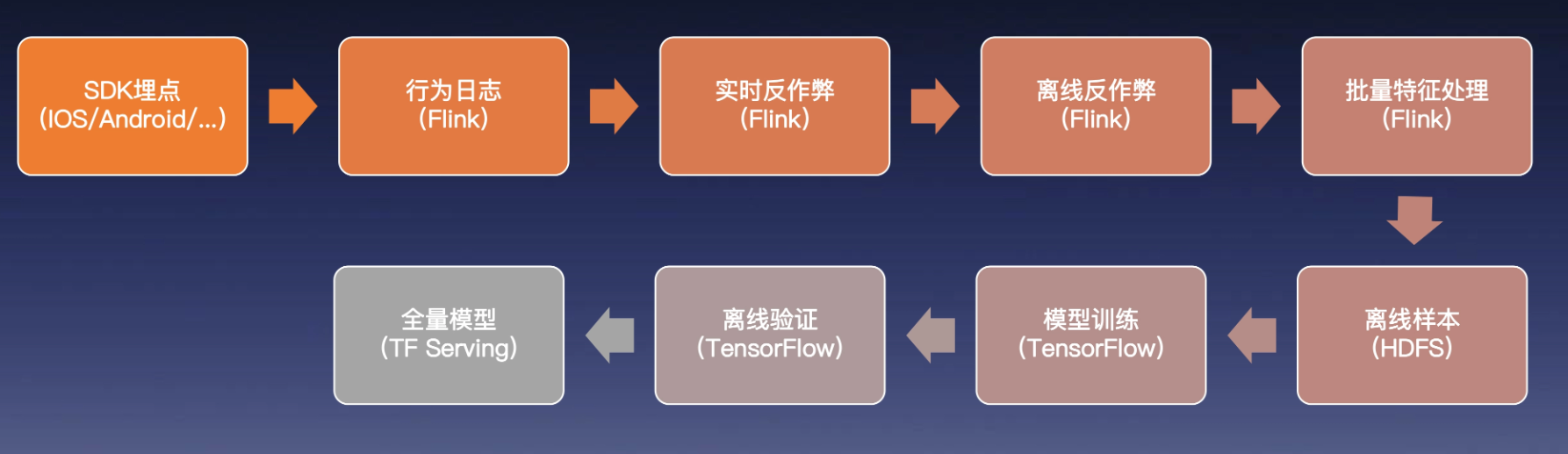
全量模型训练
- API和SDK埋点上报
- 为了防黑产,需要做实时(比如两次点击少于100ms就不是人类行为)、离线反作弊(相似特征)
- 样本制备过程一般分为两步。第一步是数据拼接,第二步是特征投影
- 发布模型,使用 PyTorch 和 TensorFlow 来训练得到模型文件
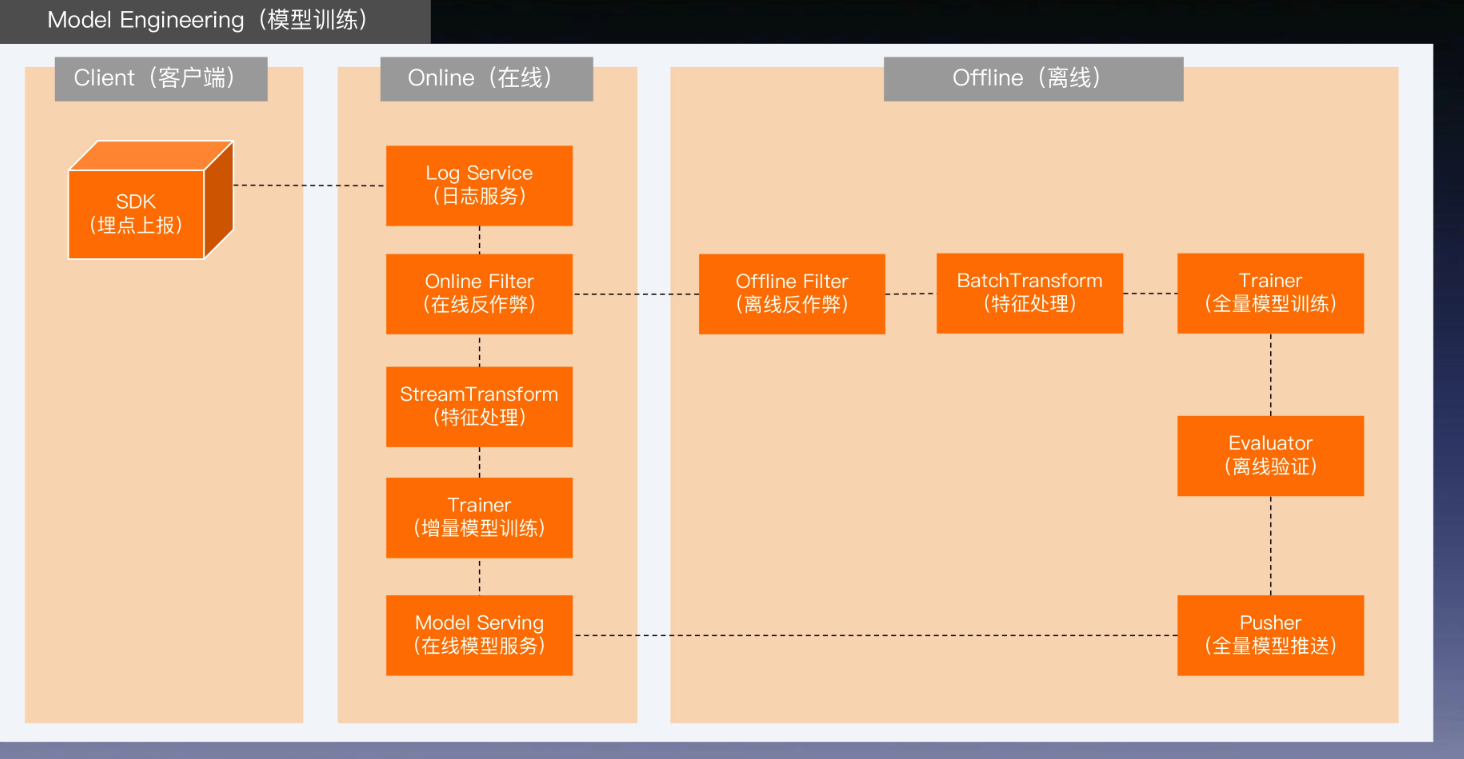
增量模型训练
- 第一级火箭使用全量(例如过去一年)的样本,一周一次
- 第二级火箭是模型的短期增量训练,一天一次
- 第三级火箭,把在二级模型部署到线上后,24小时内产生的增量数据,实时地喂给在线模型进行训练和更新
- 在线增量训练中缺少离线反作弊的参与,所以不能用增量训练替代全量训练,需要另外两级火箭做安全性和实时性的平衡
- 一旦关键指标出现大幅波动,就需要回滚模型,并降级到非增量训练模式
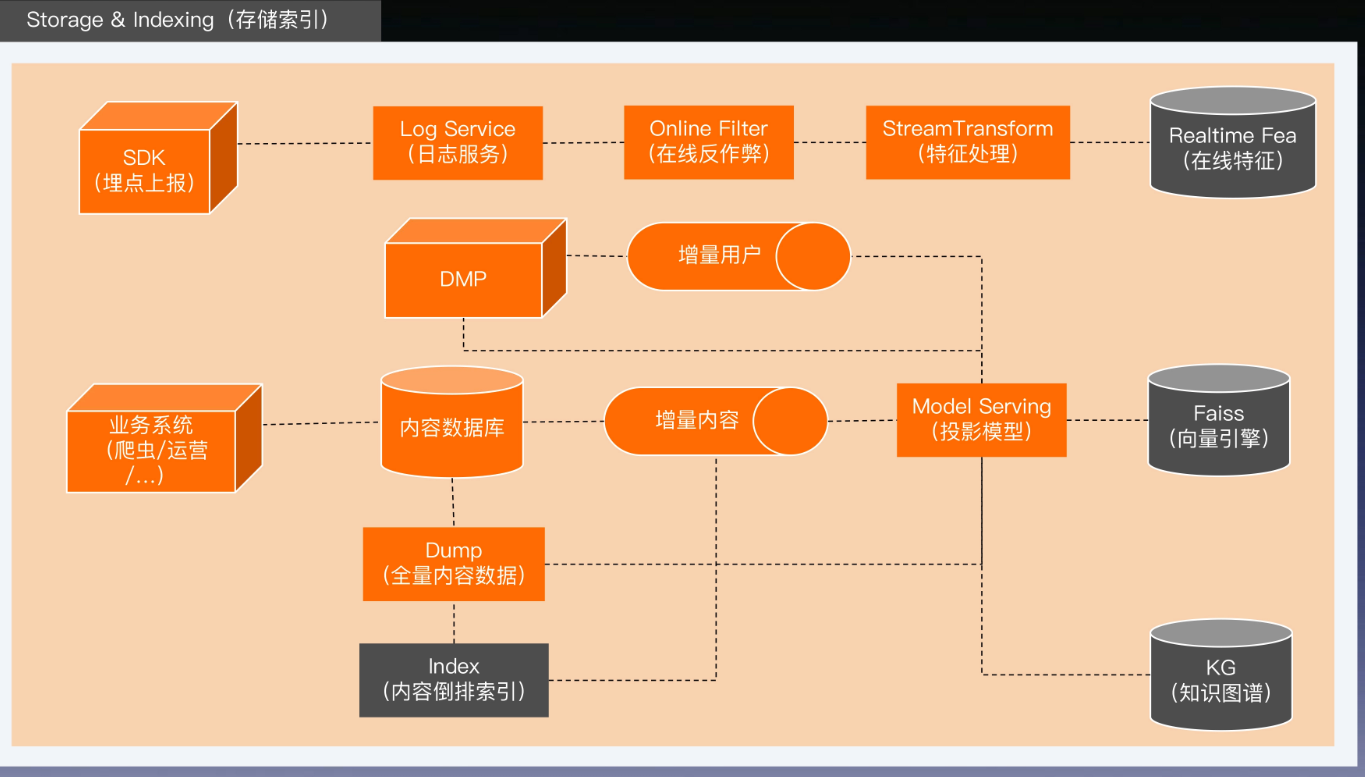
存储索引
- AI 系统通常将内容数据,存储在诸如 MySQL
- 倒排数据放到 ES 中
- 增量数据,mysql 的实时解析 binlog
向量索引服务
- 基于规则的方式很可能会误杀大量的候选内容
- 目前最先进的方法是基于语义相关性的向量召回(embedding based retrieval)
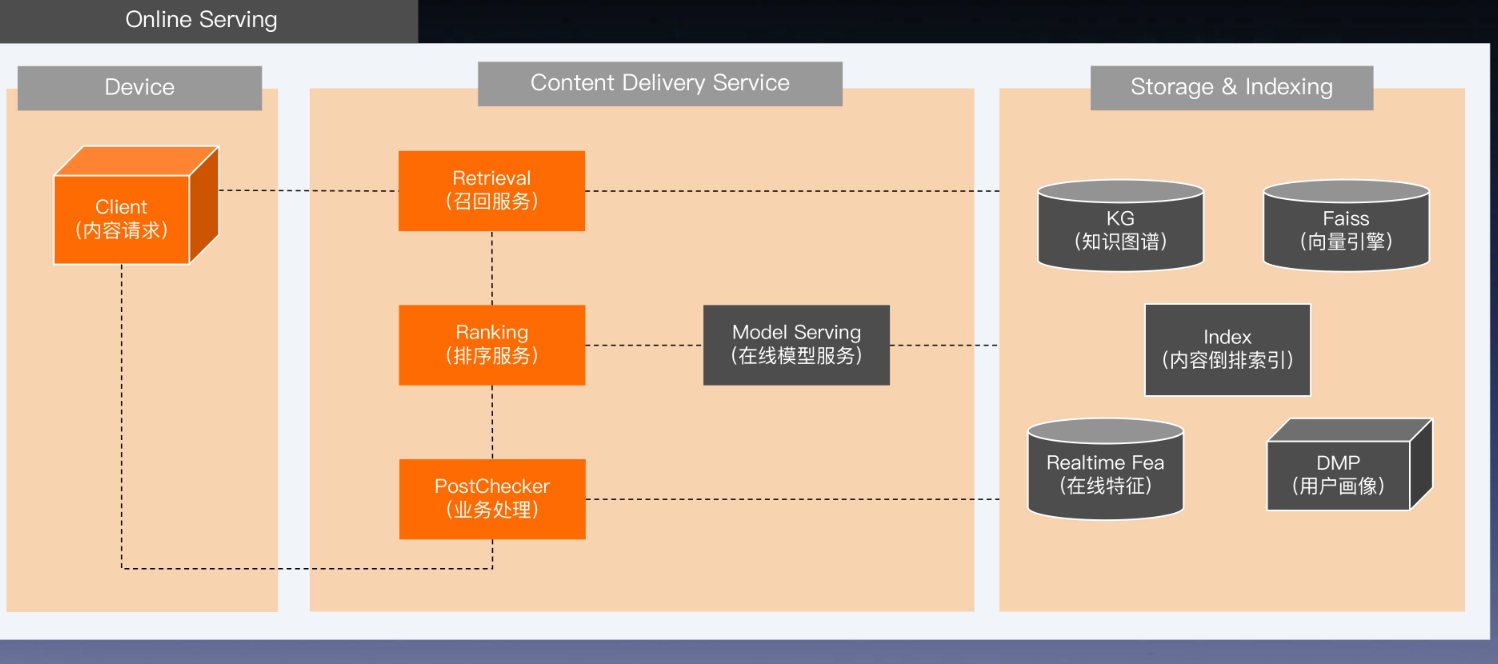
在线服务
- 实时特征存储在 redis 中
- 知识图谱会存储在类似 neo4j 中
- 还会配合 Embedding 和内存图数据库,来提高图谱的查询效率