系统设计
限流
限流的例子
- Prevent resource starvation caused by Denial of Service (DoS) attack
- Almost all APIs published by large tech companies enforce some form of rate limiting
- For example, Twitter limits the number of tweets to 300 per 3 hours
- Google docs APIs have the following default limit: 300 per user per 60 seconds for read requests
- 固定时间的发帖,一段时间注册,点赞,各种情况都有限制,都可以做限流
- 可以在 7层做,或者 4层,或者 3层做限流
限流算法 Token bucket algorithm
- 设置两个参数,bucket 允许的最大令牌数量
- 每秒中,往 bucket 中填充的 令牌数量
Leaking bucket algorithm
- 定义队列的长度,也就是相当于:漏洞的大小
- 处理速度,也就是每秒中 从队列中 处理/获取 多少请求来处理
Fixed window counter algorithm
- 如果突然流量正好落在两个窗口之间,会导致流量激增
Sliding window log algorithm
- 解决了固定窗口的问题,需要消耗更多的内存
Sliding window counter algorithm
- 混合了固定窗口,滑动窗口,但是实现更复杂
Rate limiter in a distributed environment
- Race condition
- Read the counter value from Redis.
- Check if ( counter + 1 ) exceeds the threshold.
- If not, increment the counter value by 1 in Redis.
- 因为有分布式条件竞争问题,可能需要 lua 脚本做原子操作
- Synchronization issue
Hard vs soft rate limiting
- Hard: The number of requests cannot exceed the threshold.
- Soft: Requests can exceed the threshold for a short period.
Avoid being rate limited. Design your client with best practices:
- Use client cache to avoid making frequent API calls.
- Understand the limit and do not send too many requests in a short time frame.
- Include code to catch exceptions or errors so your client can gracefully recover from exceptions.
- Add sufficient back off time to retry logic.
Reference materials
- [1] Rate-limiting strategies and techniques: https://cloud.google.com/solutions/rate-limitingstrategies-techniques
- [2] Twitter rate limits: https://developer.twitter.com/en/docs/basics/rate-limits
- [3] Google docs usage limits: https://developers.google.com/docs/api/limits
- [4] IBM microservices: https://www.ibm.com/cloud/learn/microservices
- [5] Throttle API requests for better throughput: https://docs.aws.amazon.com/apigateway/latest/developerguide/api-gateway-requestthrottling.html
- [6] Stripe rate limiters: https://stripe.com/blog/rate-limiters
- [7] Shopify REST Admin API rate limits: https://help.shopify.com/en/api/reference/restadmin-api-rate-limits
- [8] Better Rate Limiting With Redis Sorted Sets: https://engineering.classdojo.com/blog/2015/02/06/rolling-rate-limiter/
- [9] System Design — Rate limiter and Data modelling: https://medium.com/@saisandeepmopuri/system-design-rate-limiter-and-data-modelling9304b0d18250
- [10] How we built rate limiting capable of scaling to millions of domains: https://blog.cloudflare.com/counting-things-a-lot-of-different-things/
- [11] Redis website: https://redis.io/
- [12] Lyft rate limiting: https://github.com/lyft/ratelimit
- [13] Scaling your API with rate limiters: https://gist.github.com/ptarjan/e38f45f2dfe601419ca3af937fff574d#request-rate-limiter
- [14] What is edge computing: https://www.cloudflare.com/learning/serverless/glossary/whatis-edge-computing/
- [15] Rate Limit Requests with Iptables: https://blog.programster.org/rate-limit-requests-withiptables
- [16] OSI model: https://en.wikipedia.org/wiki/OSI_model#Layer_architecture
一致性hash
总结
- 普通 hash 的问题
- 一致性 hash 的优化
- 虚拟节点优化
Reference materials
- [1] Consistent hashing: https://en.wikipedia.org/wiki/Consistent_hashing
- [2] Consistent Hashing: https://tom-e-white.com/2007/11/consistent-hashing.html
- [3] Dynamo: Amazon’s Highly Available Key-value Store: https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
- [4] Cassandra - A Decentralized Structured Storage System: http://www.cs.cornell.edu/Projects/ladis2009/papers/Lakshman-ladis2009.PDF
- [5] How Discord Scaled Elixir to 5,000,000 Concurrent Users: https://blog.discord.com/scaling-elixir-f9b8e1e7c29b
- [6] CS168: The Modern Algorithmic Toolbox Lecture #1: Introduction and Consistent Hashing: http://theory.stanford.edu/~tim/s16/l/l1.pdf
- [7] Maglev: A Fast and Reliable Software Network Load Balancer: https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/44824.pdf
KV 存储
产品
- Amazon dynamo、cassandra
- Memcached、Redis
- BitTable、HBase
CAP 需要做权衡
RWN 协议
- 三副本的情况下,R = 1,W = 1,可用性很好,读写很快
- R or W > 1,提供更好的一致性
- W + R > N,强一致性
- R = 1 and W = N, the system is optimized for a fast read.
- W = 1 and R = N, the system is optimized for fast write.
- W + R > N, strong consistency is guaranteed (Usually N = 3, W = R = 2).
- W + R <= N, strong consistency is not guaranteed.
使用 向量时钟 来解决冲突
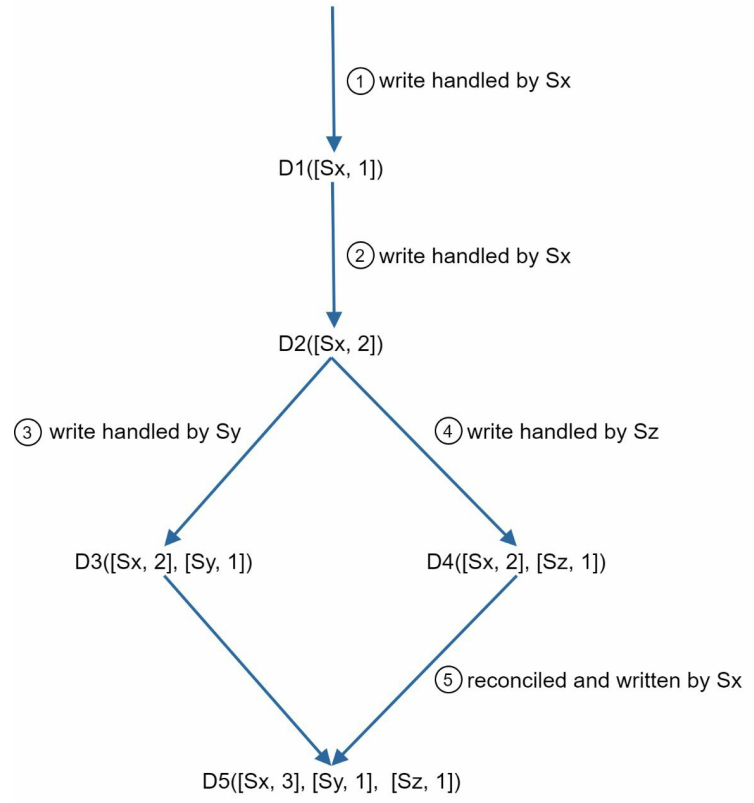
表示
- 用 a [server, version] 来表示
- 如果存在,则更新,不存在则设置 [si,1]
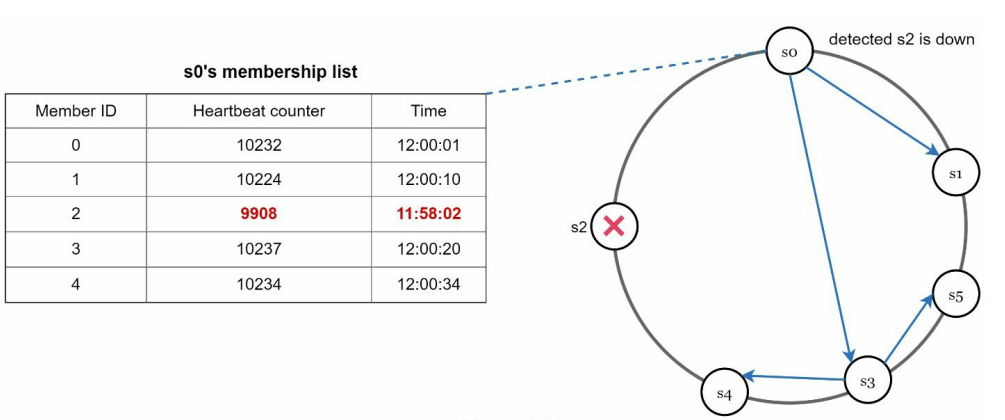
gossip 协议
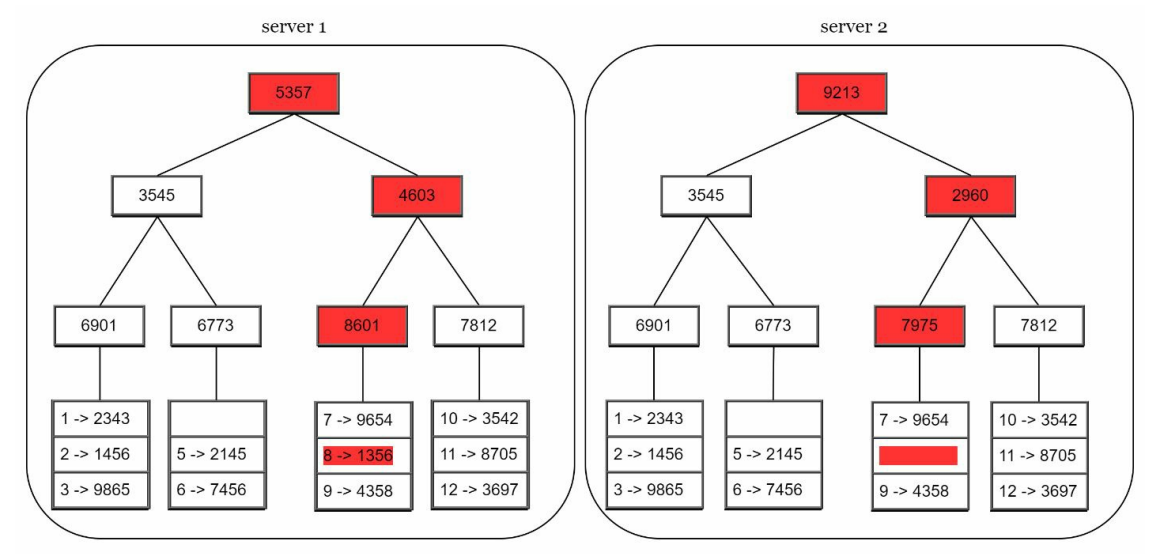
Merkle trees,用来快速查找哪些 key 不匹配
字底向上的方式创建
Main features of the architecture are listed as follows:
- Clients communicate with the key-value store through simple APIs: get(key) and put(key, value).
- A coordinator is a node that acts as a proxy between the client and the key-value store.
- Nodes are distributed on a ring using consistent hashing.
- The system is completely decentralized so adding and moving nodes can be automatic.
- Data is replicated at multiple nodes.
- There is no single point of failure as every node has the same set of responsibilities.
读写方式
- 可以参考 Cassandra
- 先写 WAL,再写内存,满了就刷到磁盘,生成 sstable
- 读先读内存,有就直接返回,没有就查 sstable,可以用 bloom filter
总结
| Goal/Problems | Technique |
|---|---|
| Ability to store big data | Use consistent hashing to spread the load across servers |
| High availability reads | Data replication, Multi-data center setup |
| Highly available writes | Versioning and conflict resolution with vector clocks |
| Dataset partition | Consistent Hashing |
| Incremental scalability | Consistent Hashing |
| Heterogeneity | Consistent Hashing |
| Tunable consistency | Quorum consensus |
| Handling temporary failures | Sloppy quorum and hinted handoff |
| Handling permanent failures | Merkle tree |
| Handling data center outage | Cross-data center replication |
Reference materials
- [1] Amazon DynamoDB: https://aws.amazon.com/dynamodb/
- [2] memcached: https://memcached.org/
- [3] Redis: https://redis.io/
- [4] Dynamo: Amazon’s Highly Available Key-value Store: https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
- [5] Cassandra: https://cassandra.apache.org/
- [6] Bigtable: A Distributed Storage System for Structured Data: https://static.googleusercontent.com/media/research.google.com/en//archive/bigtableosdi06.pdf
- [7] Merkle tree: https://en.wikipedia.org/wiki/Merkle_tree
- [8] Cassandra architecture: https://cassandra.apache.org/doc/latest/architecture/
- [9] SStable: https://www.igvita.com/2012/02/06/sstable-and-log-structured-storage-leveldb/
- [10] Bloom filter https://en.wikipedia.org/wiki/Bloom_filter
分布式ID生成器
要求
- IDs must be unique.
- IDs are numerical values only.
- IDs fit into 64-bit.
- IDs are ordered by date.
- Ability to generate over 10,000 unique IDs per second
解决办法
- 多主之间用 increment + k 的方式,但是扩展性不好
- UUID,128位太长了,而且时间无法排序
- Ticket Server,用一个中心节点生成 ID,但会有单点问题
- Twitter snowflake
| 1 bit | 41 bits | 5 bits | 5 bits | 12 bits |
|---|---|---|---|---|
| 0 | timestamp | data center ID | machine ID | sequence number |
时间戳是 41 bit,最多可以使用 69 年
时间戳是 12 bit,也就是 1 ms 可以生成 4096个 ID
Reference materials
- [1] Universally unique identifier: https://en.wikipedia.org/wiki/Universally_unique_identifier
- [2] Ticket Servers: Distributed Unique Primary Keys on the Cheap: https://code.flickr.net/2010/02/08/ticket-servers-distributed-unique-primary-keys-on-thecheap/
- [3] Announcing Snowflake: https://blog.twitter.com/engineering/en_us/a/2010/announcingsnowflake.html
- [4] Network time protocol: https://en.wikipedia.org/wiki/Network_Time_Protocol
设计URL短链
Back of the envelope estimation
- Write operation: 100 million URLs are generated per day.
- Write operation per second: 100 million / 24 /3600 = 1160
- Read operation: Assuming ratio of read operation to write operation is 10:1, read operation per second: 1160 * 10 = 11,600
- Assuming the URL shortener service will run for 10 years, this means we must support 100 million * 365 * 10 = 365 billion records.
- Assume average URL length is 100.
- Storage requirement over 10 years: 365 billion * 100 bytes * 10 years = 365 TB
跳转
- 301,永久重定向
- 302,临时重定向
实现
- 使用 bitmap 可以做查询检查
- 生成一个 id,然后将 id:2009215674938,映射成 zn9edcu
- 映射规则是对这个数做 base 62,也就是 62进制,这样就能得到一个 7 位长的短链接了
- 62^7 可以支持 3.65万亿 记录
- post 请求用来创建一个 长URL -> 短URL
- 使用 短ULR 访问 web服务,然后 重定向到真实的 长 URL
扩展
- 需要考虑限流问题,IP 地址限流
- web 服务是无状态的很容易扩展,数据库层面做主从复制
Reference materials
- [1] A RESTful Tutorial: https://www.restapitutorial.com/index.html
- [2] Bloom filter: https://en.wikipedia.org/wiki/Bloom_filter