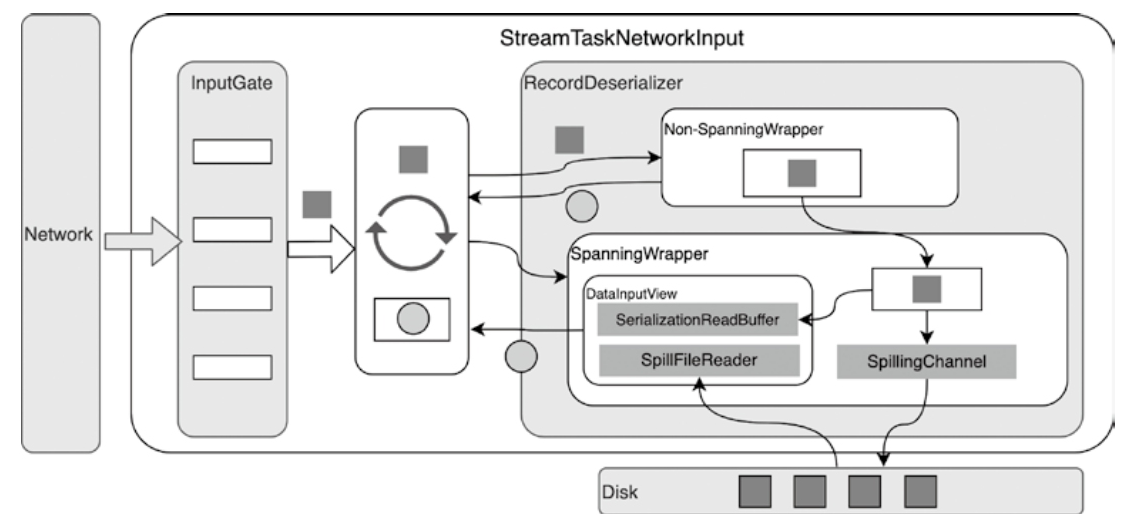
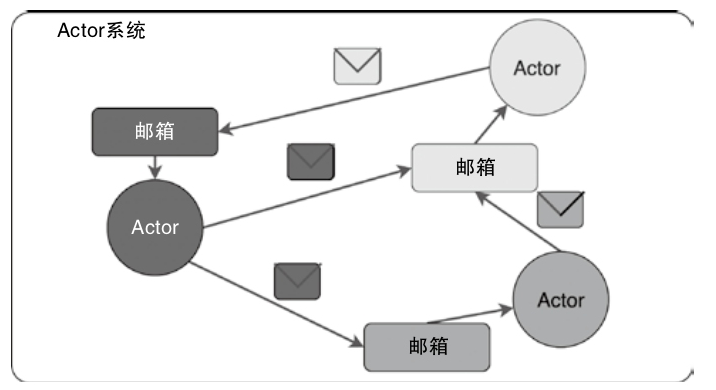
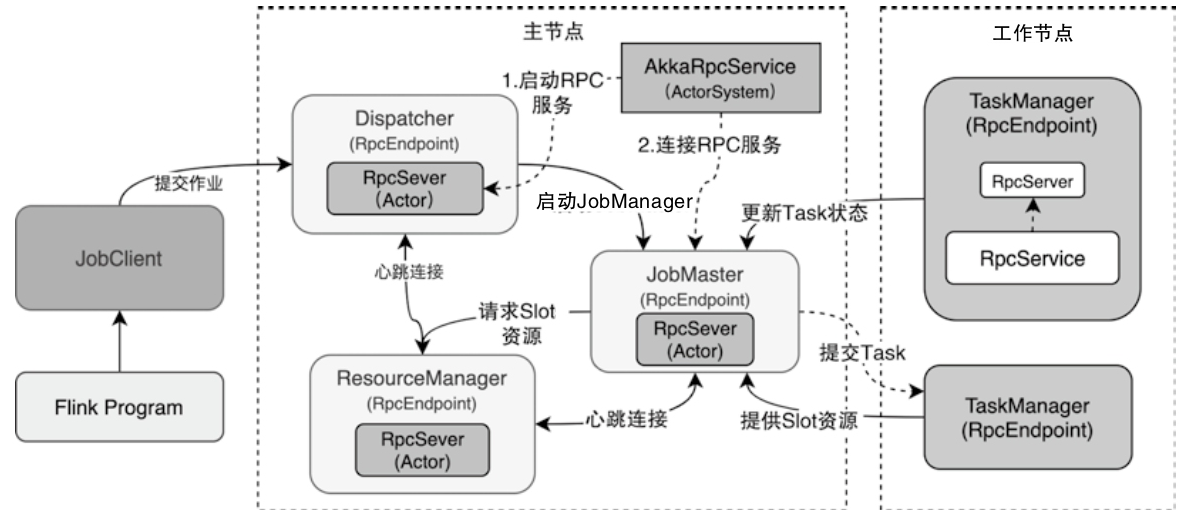
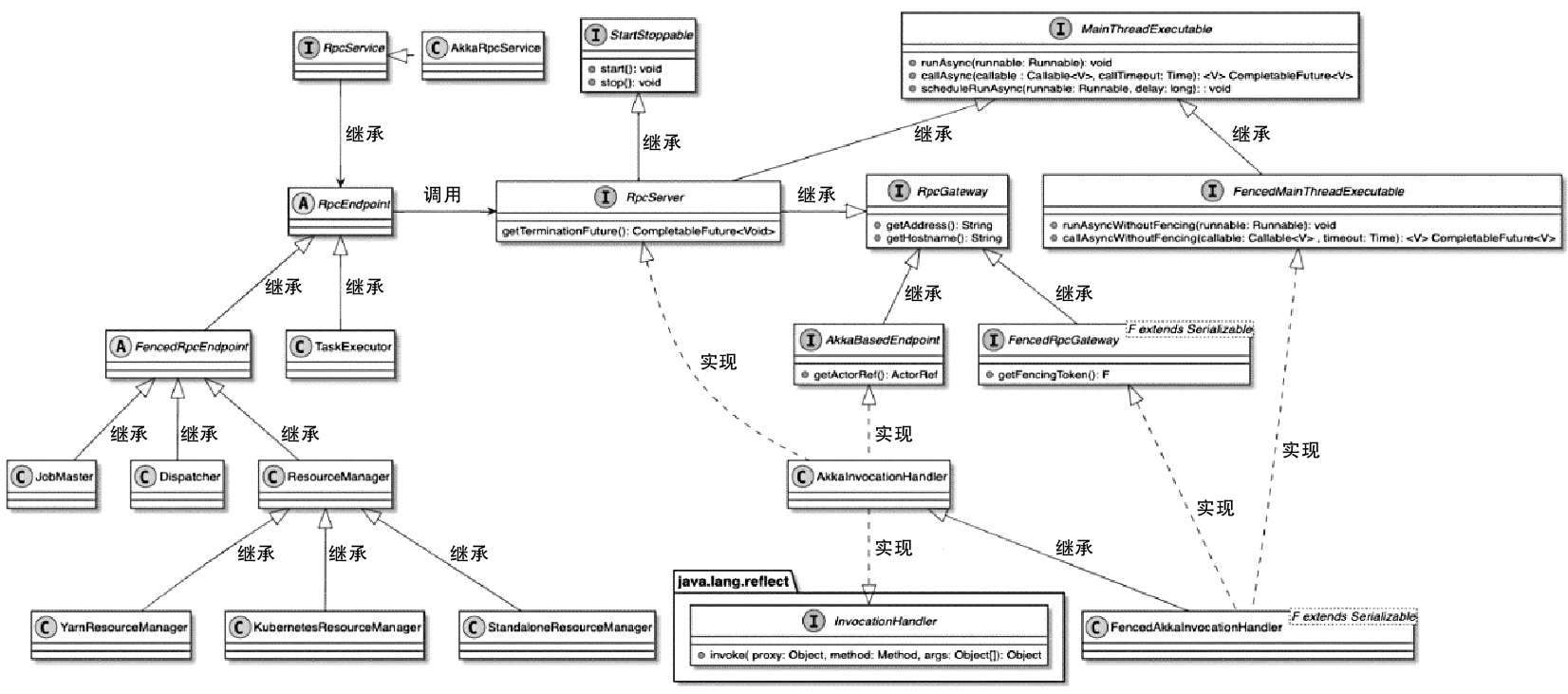
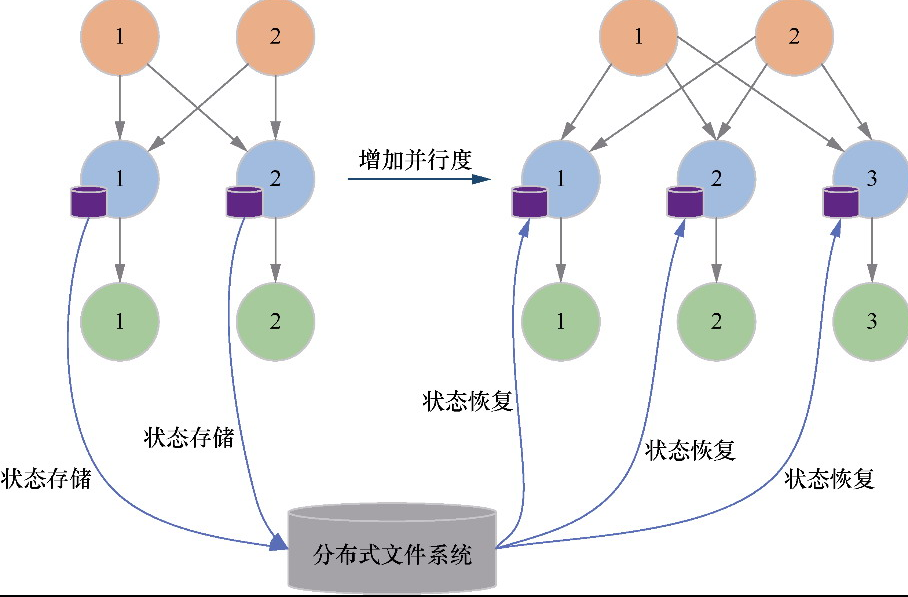
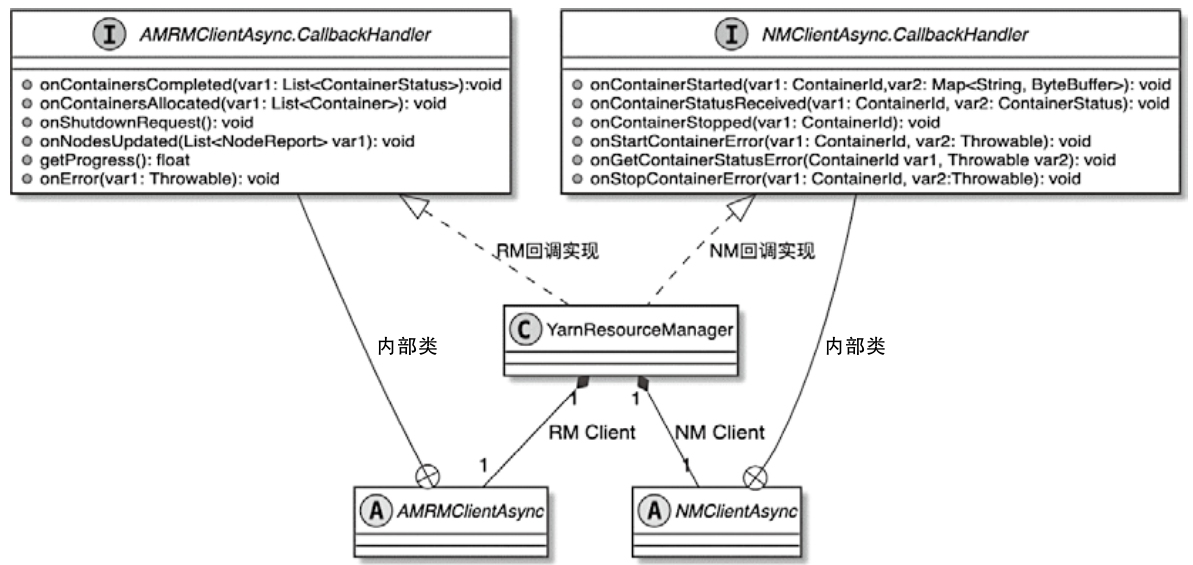
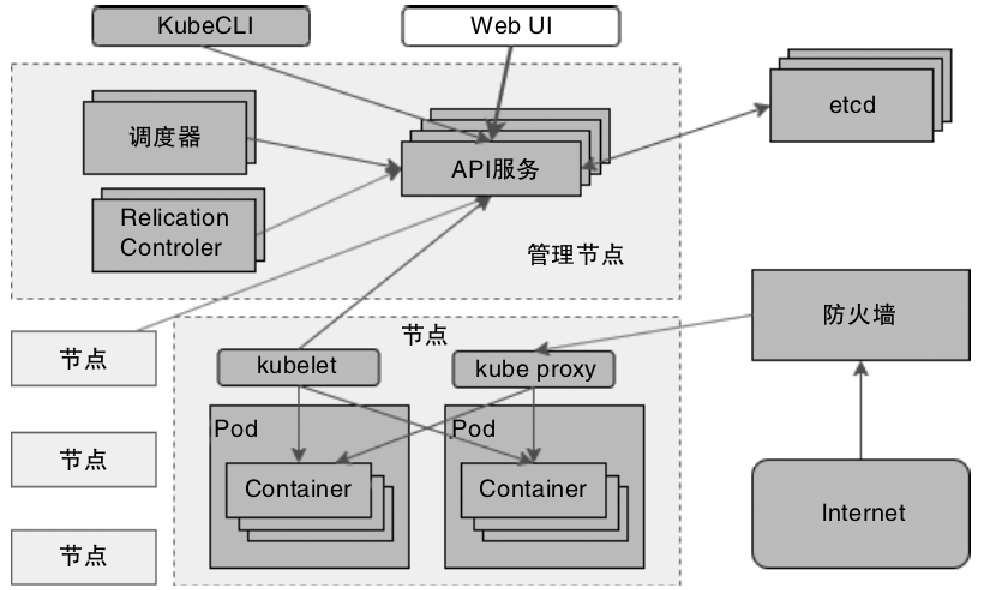
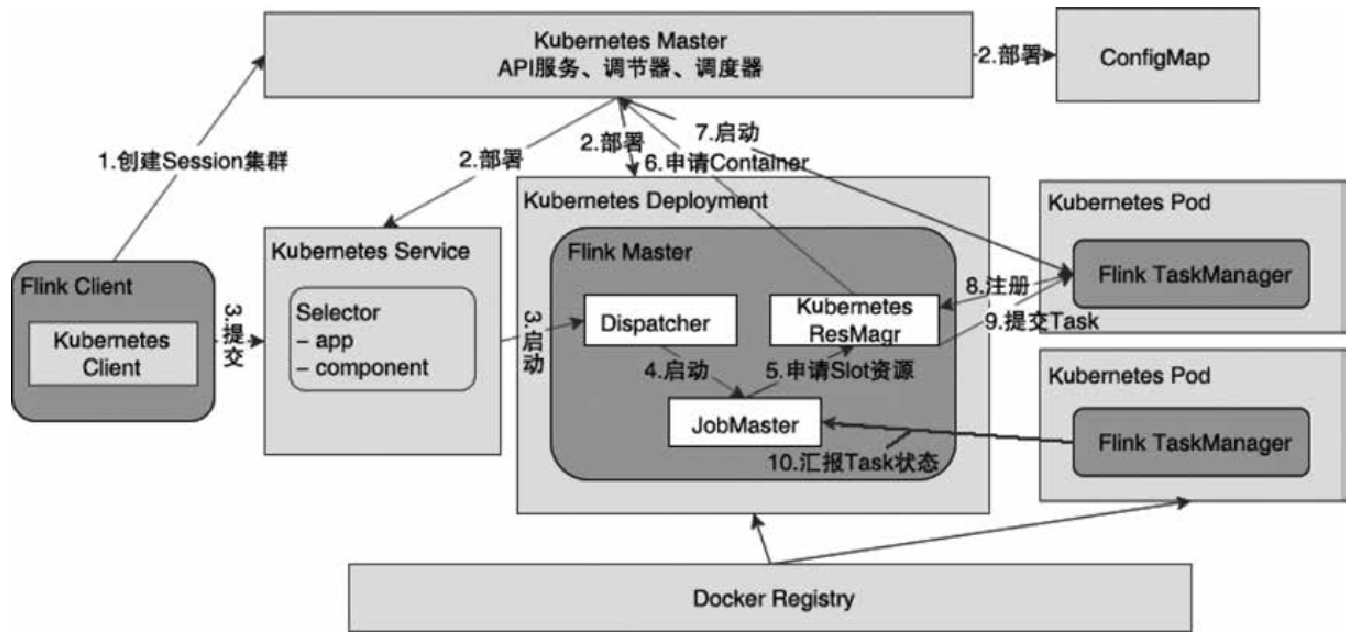
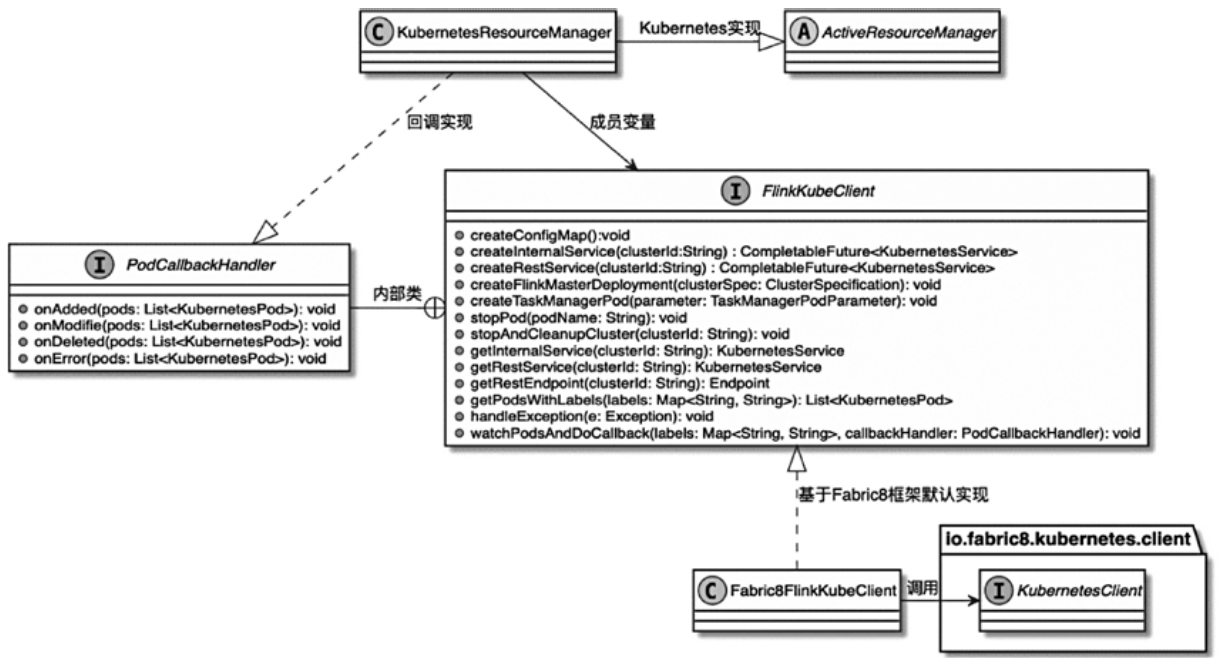
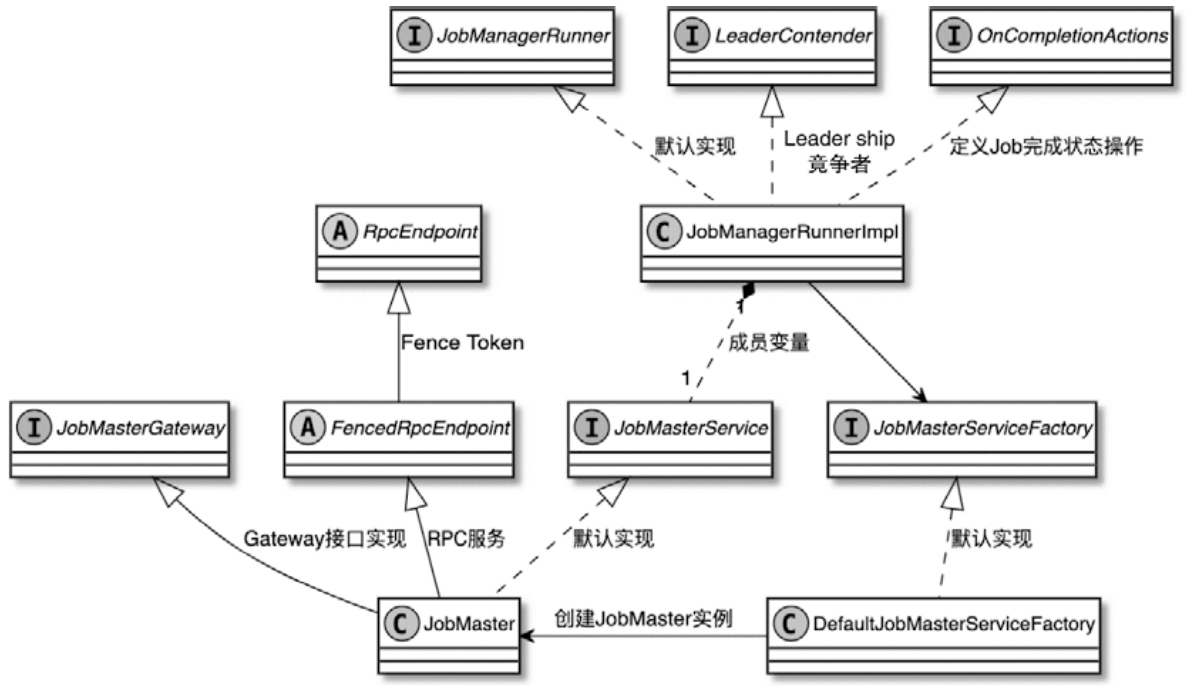
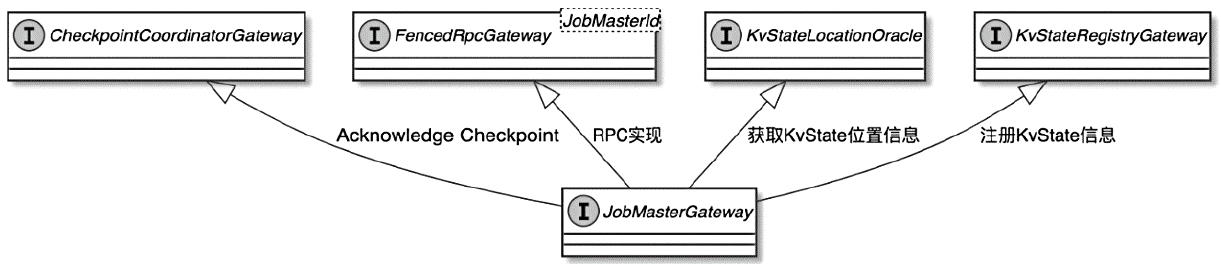
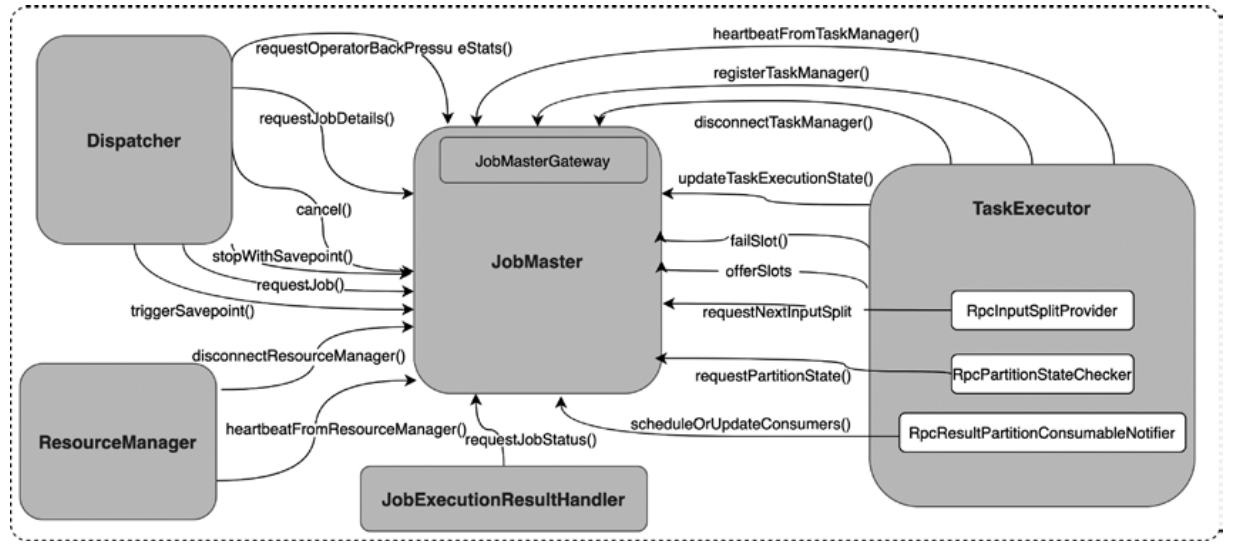
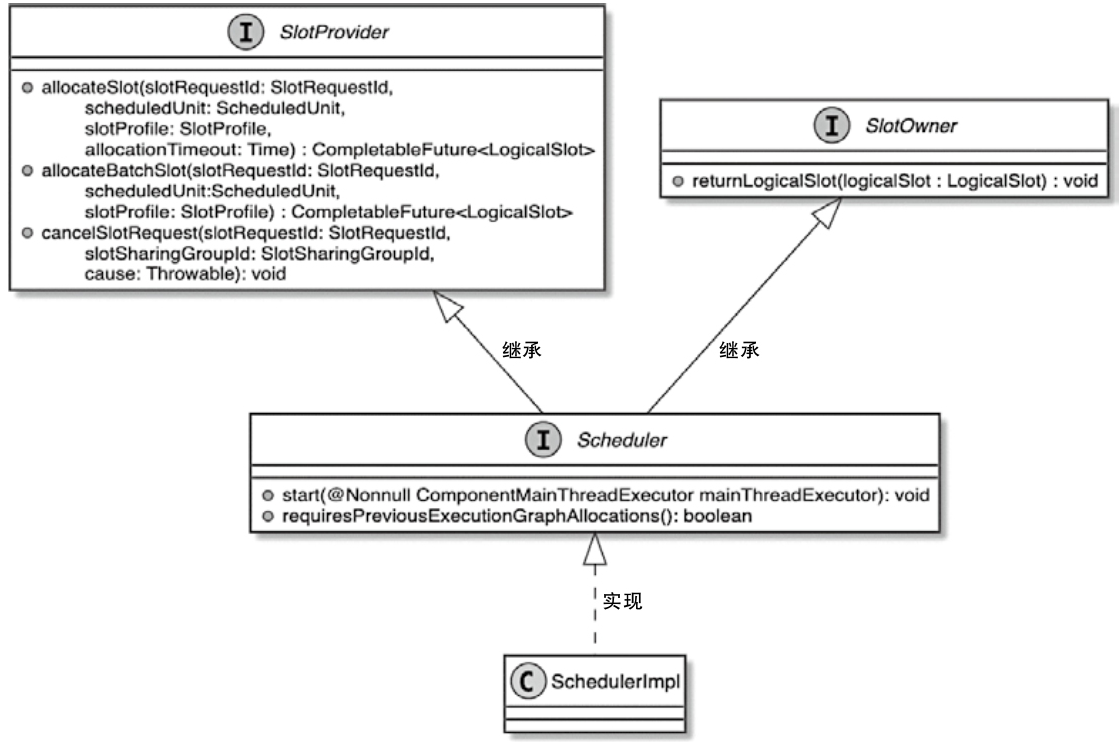
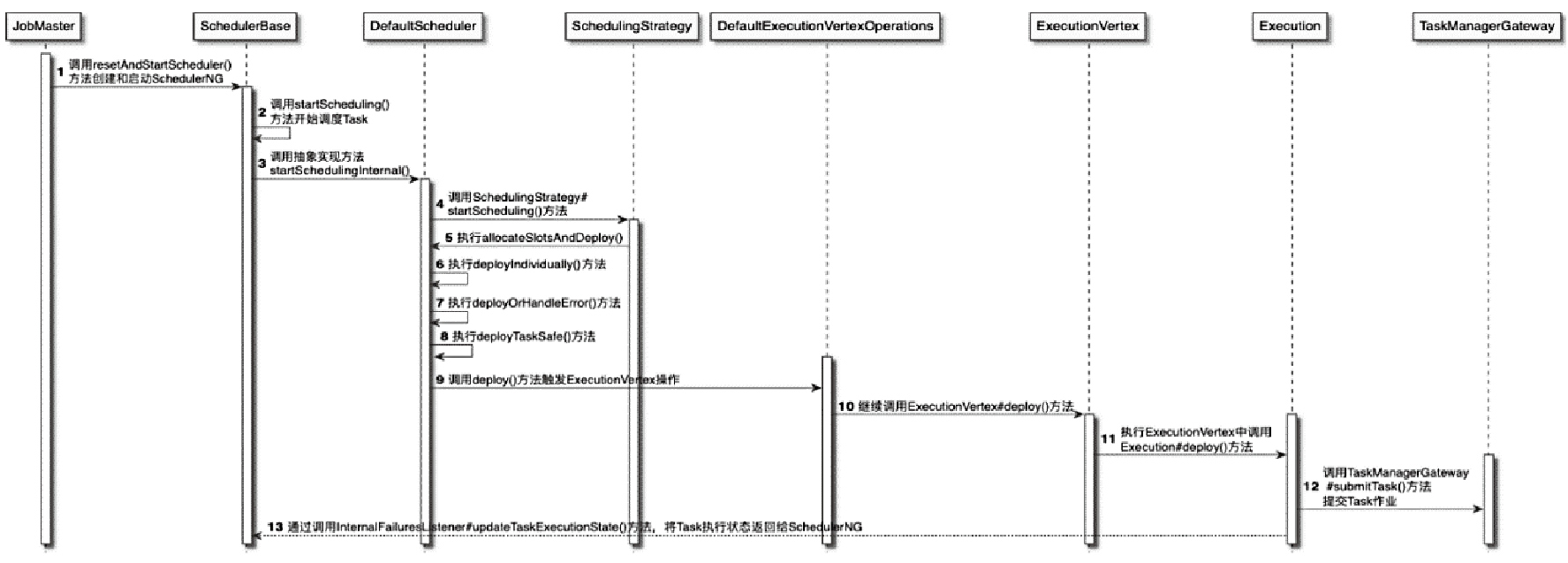
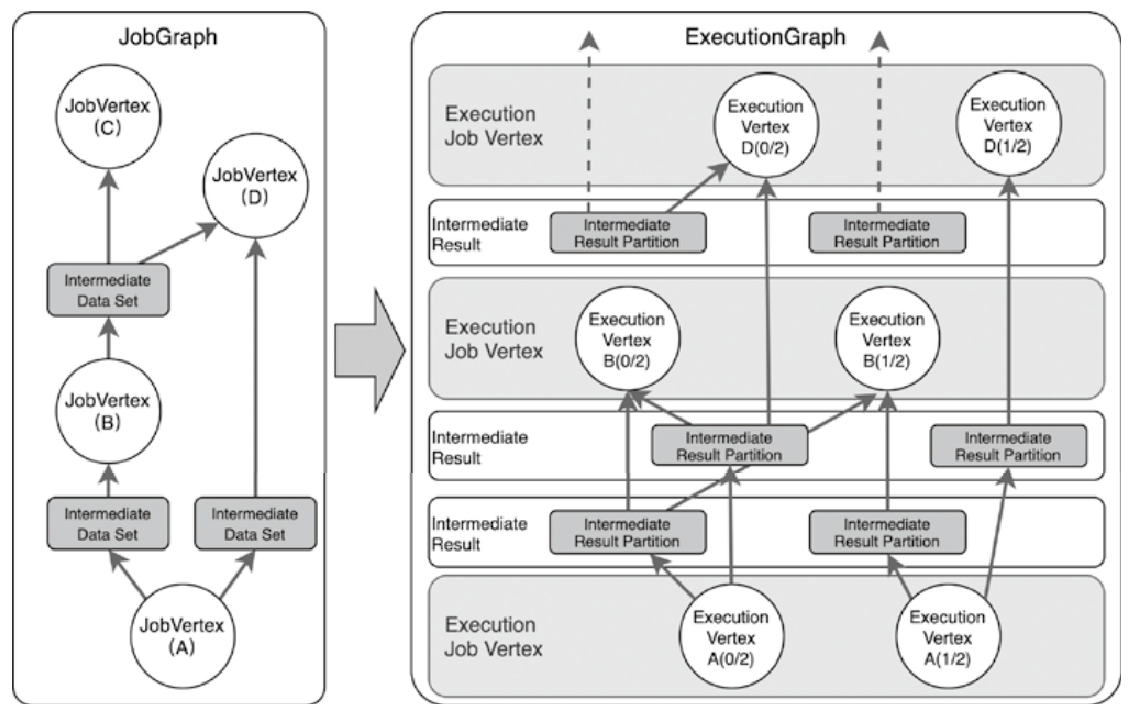
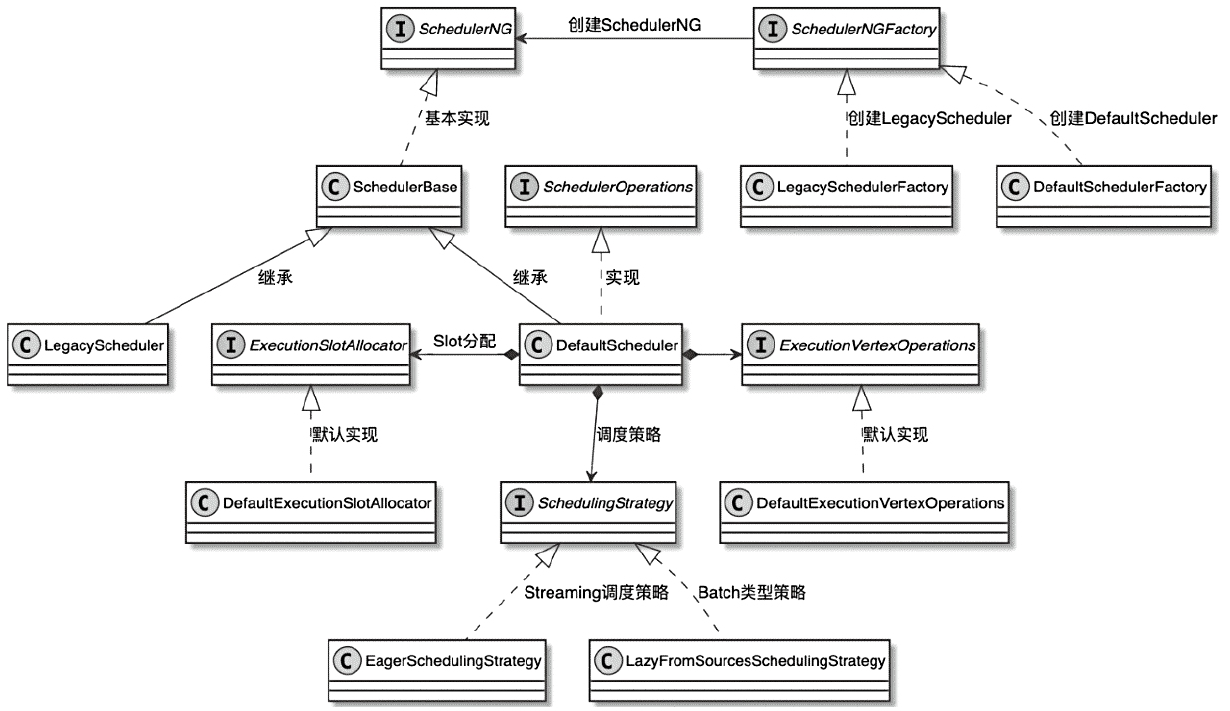
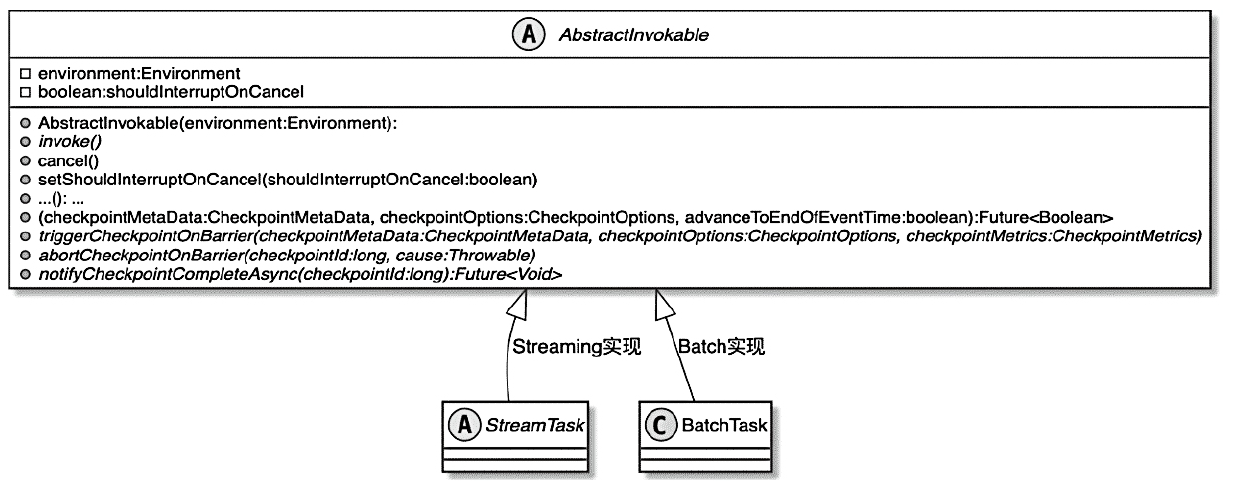
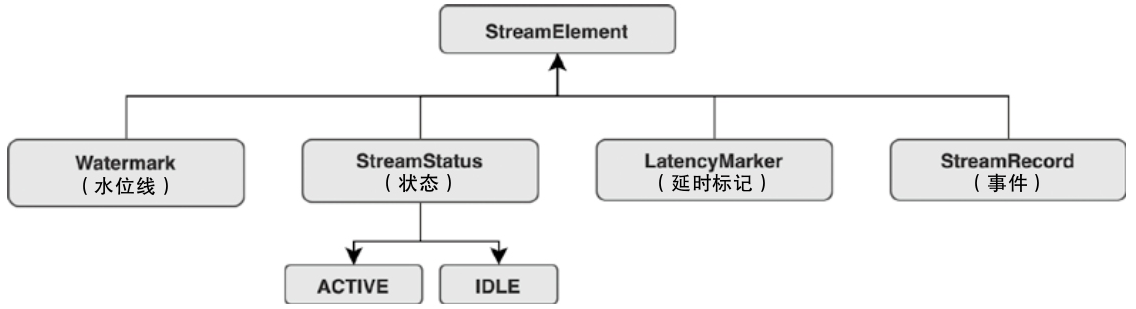
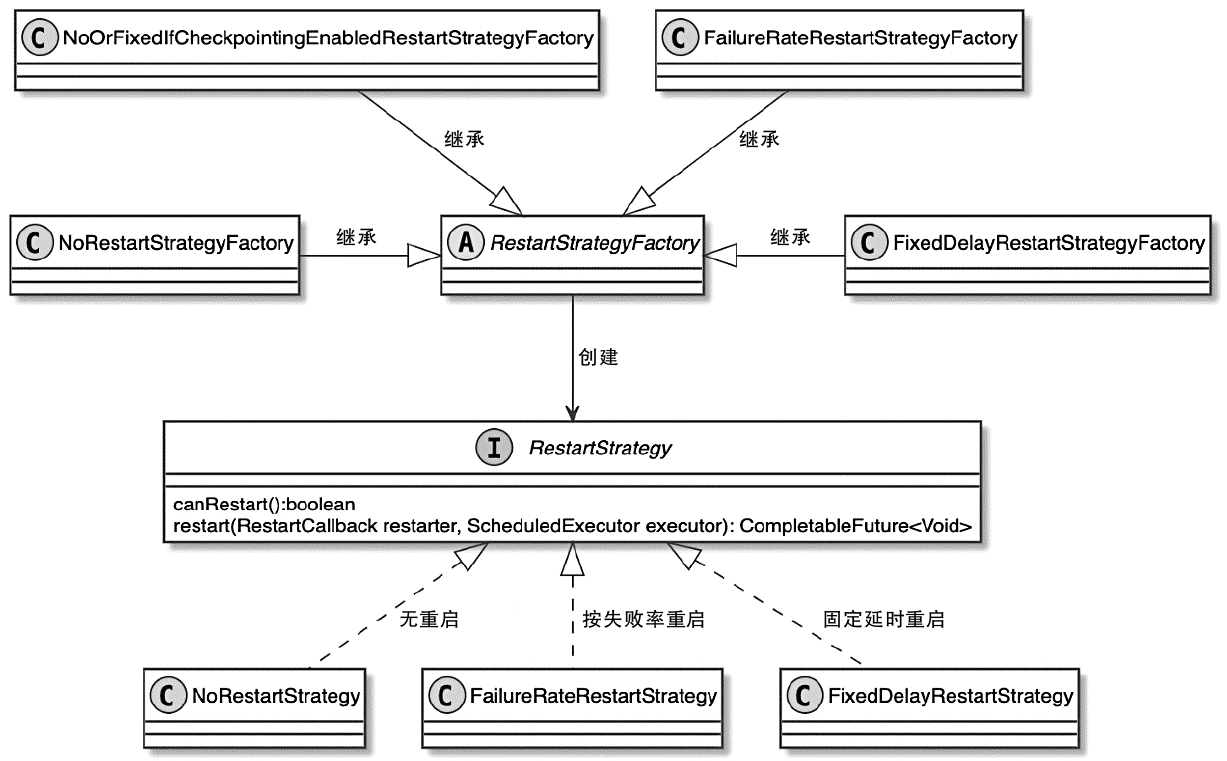
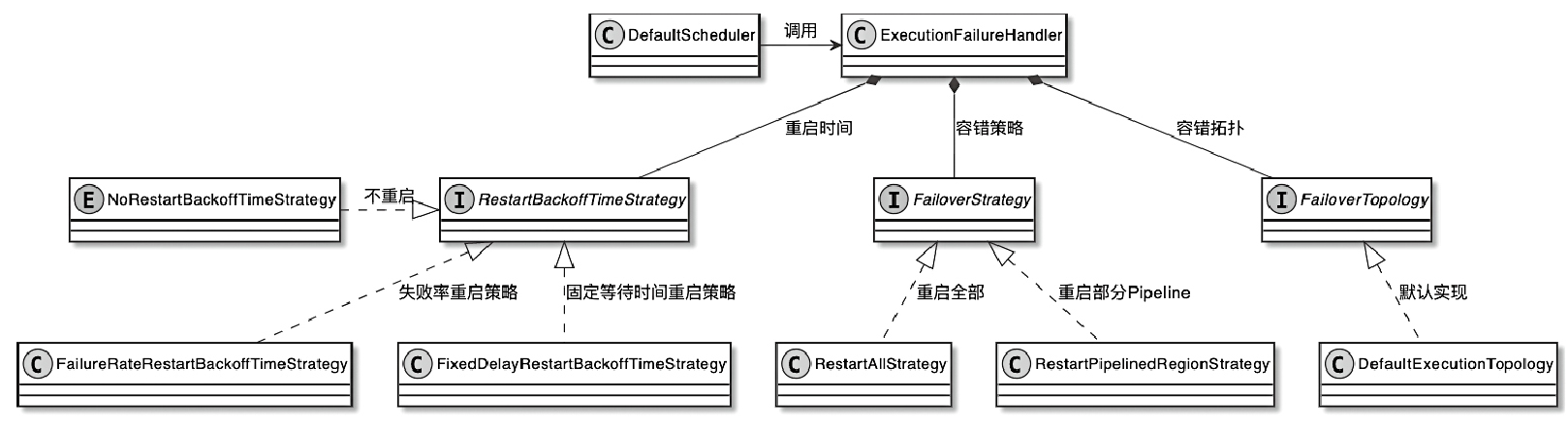
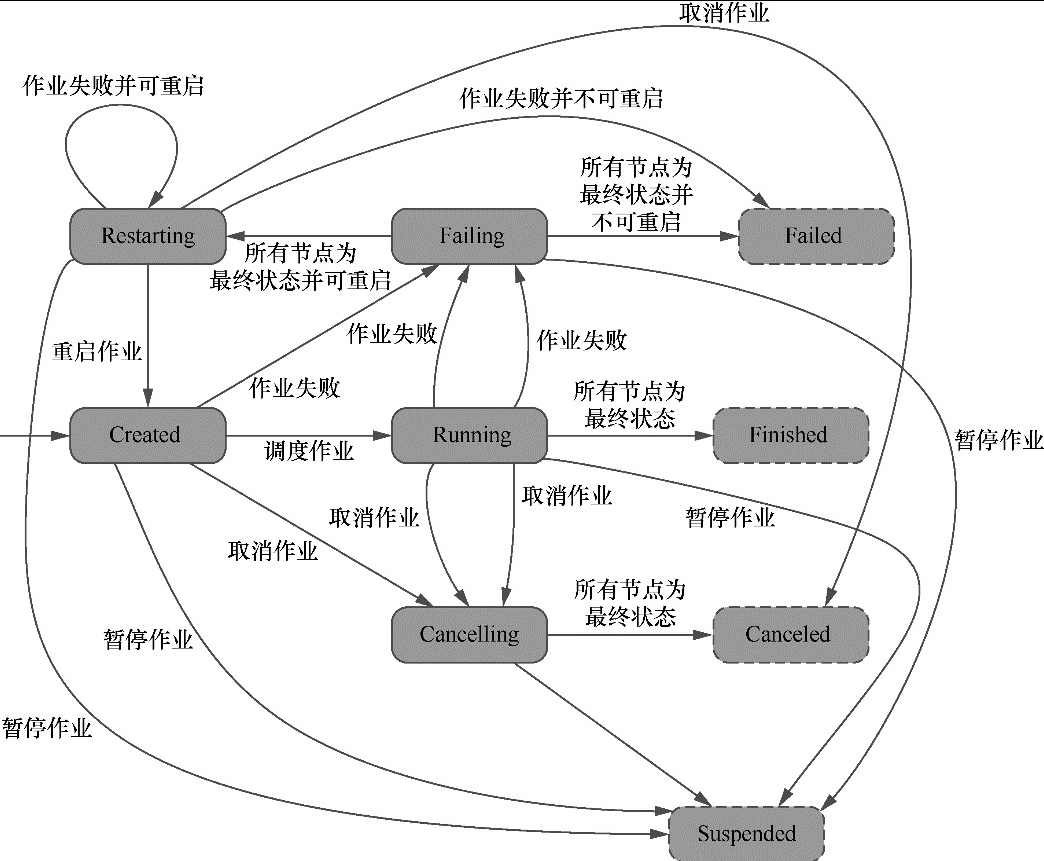
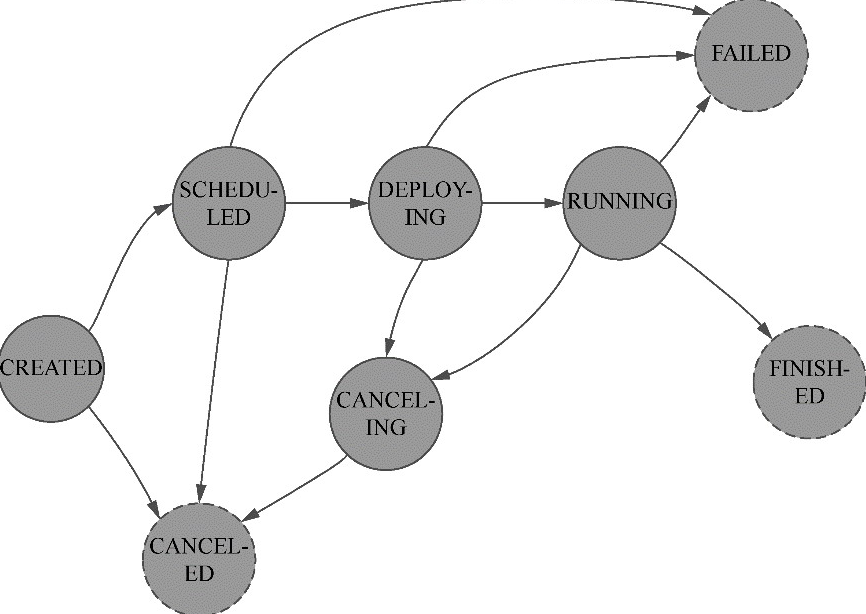
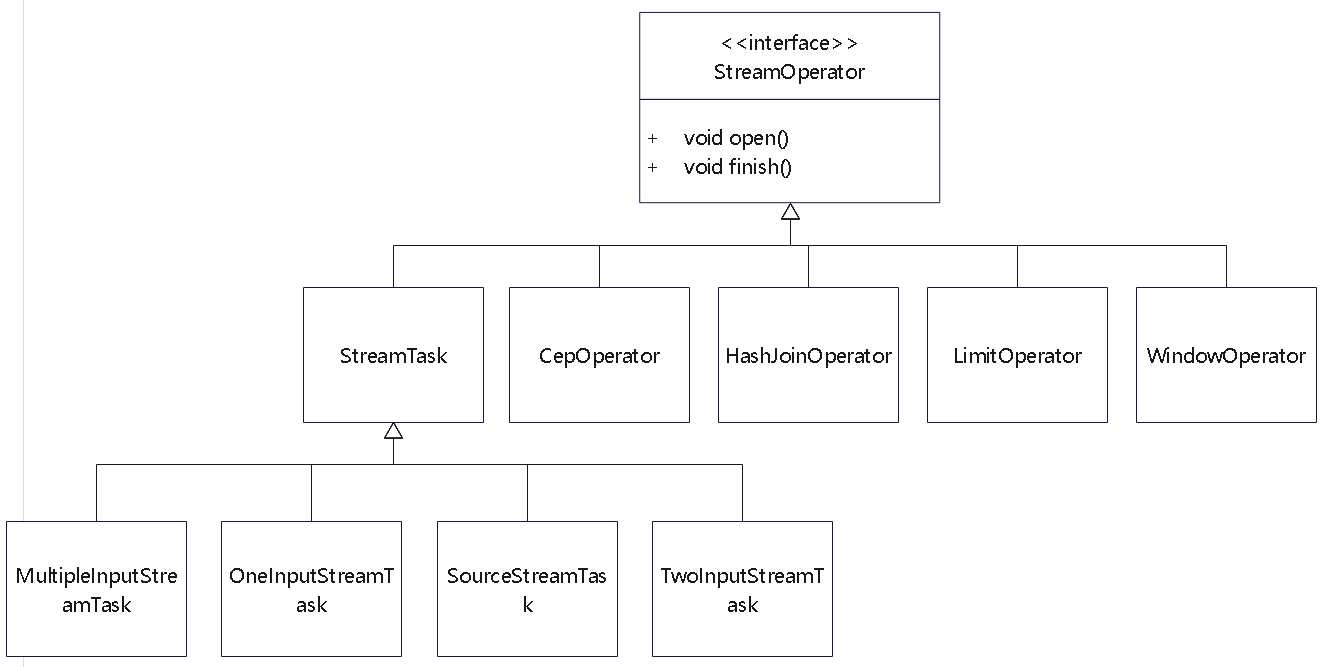
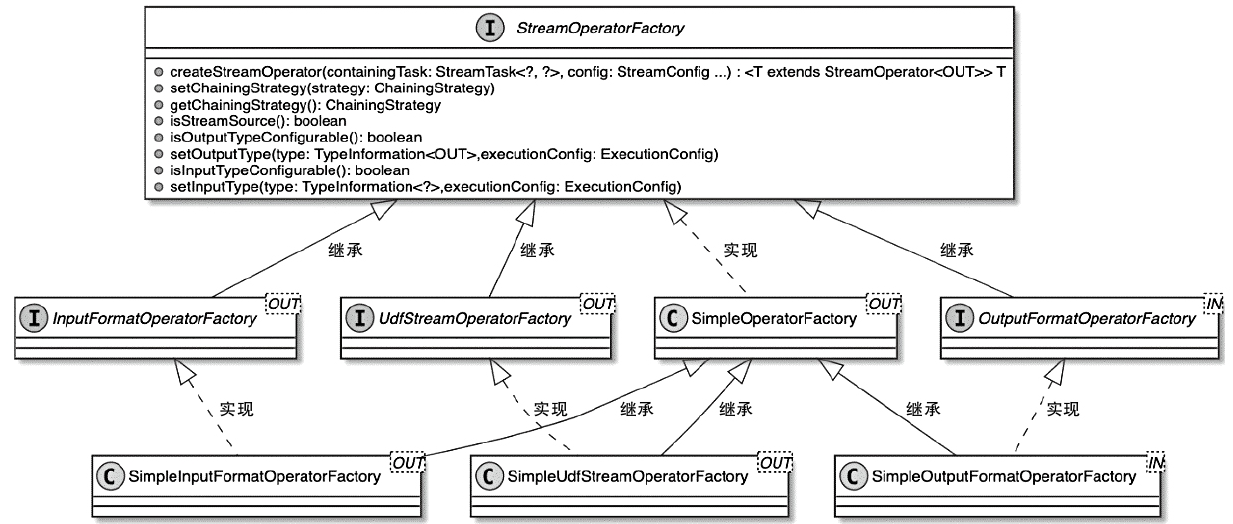
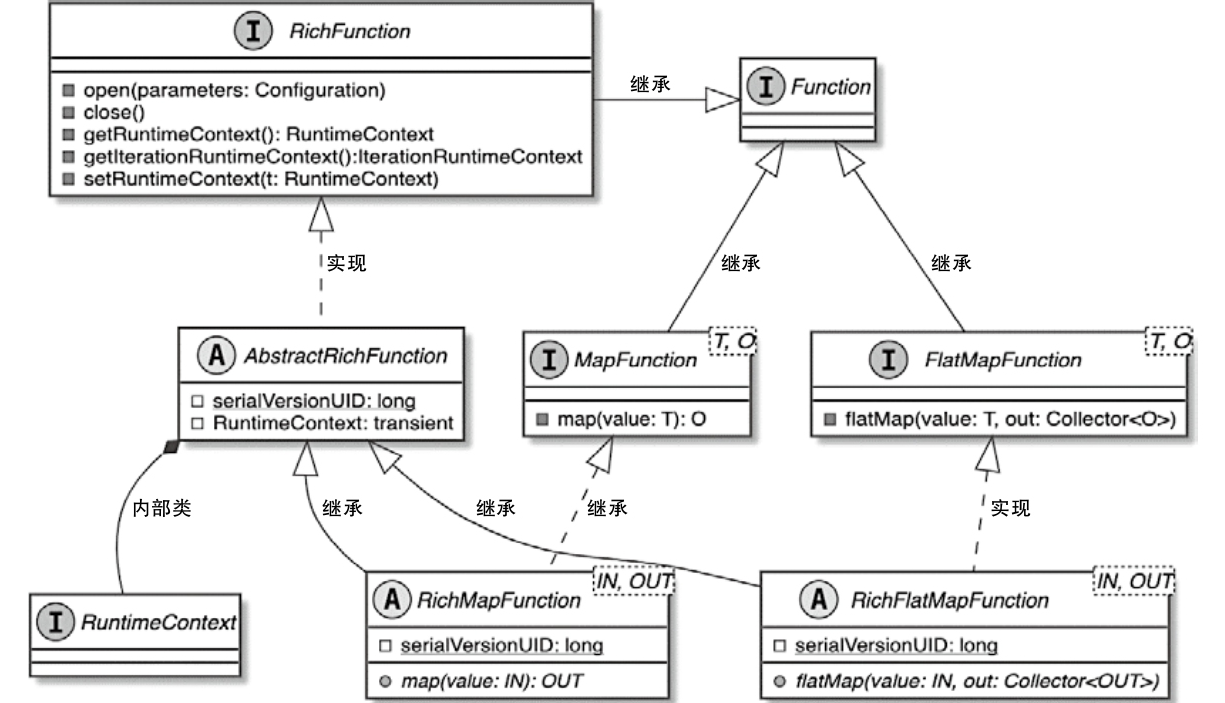
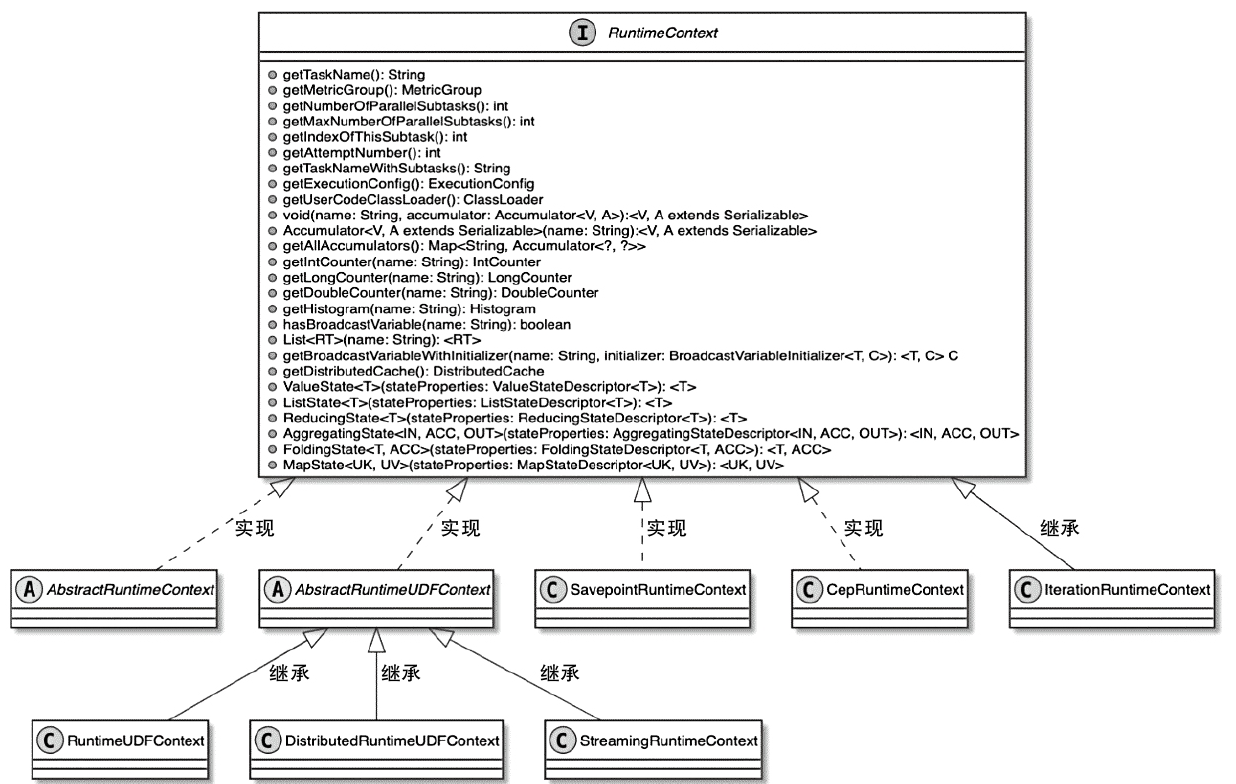
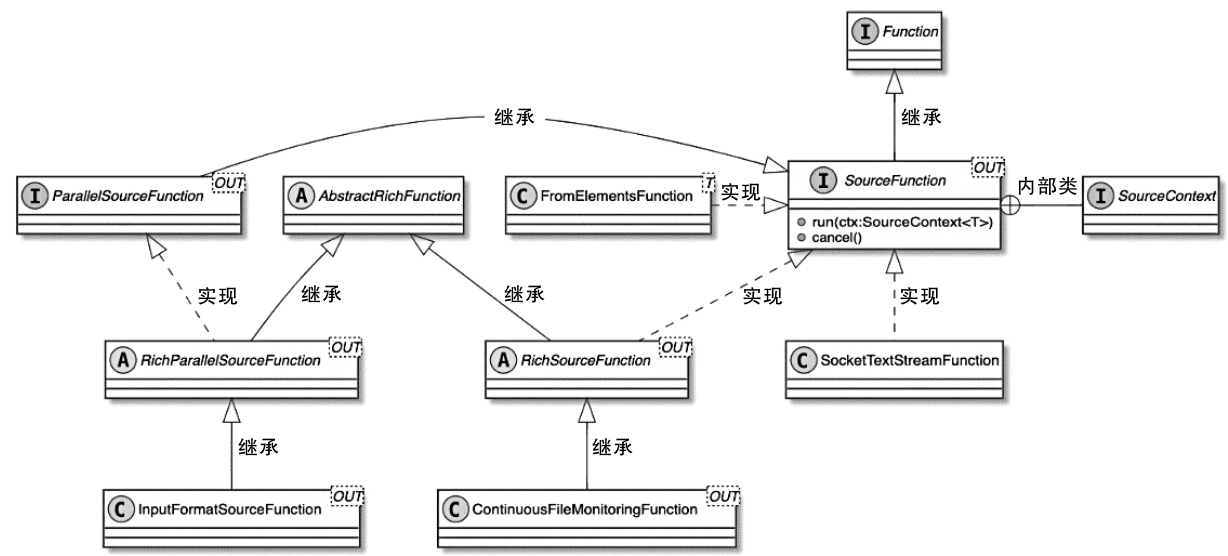
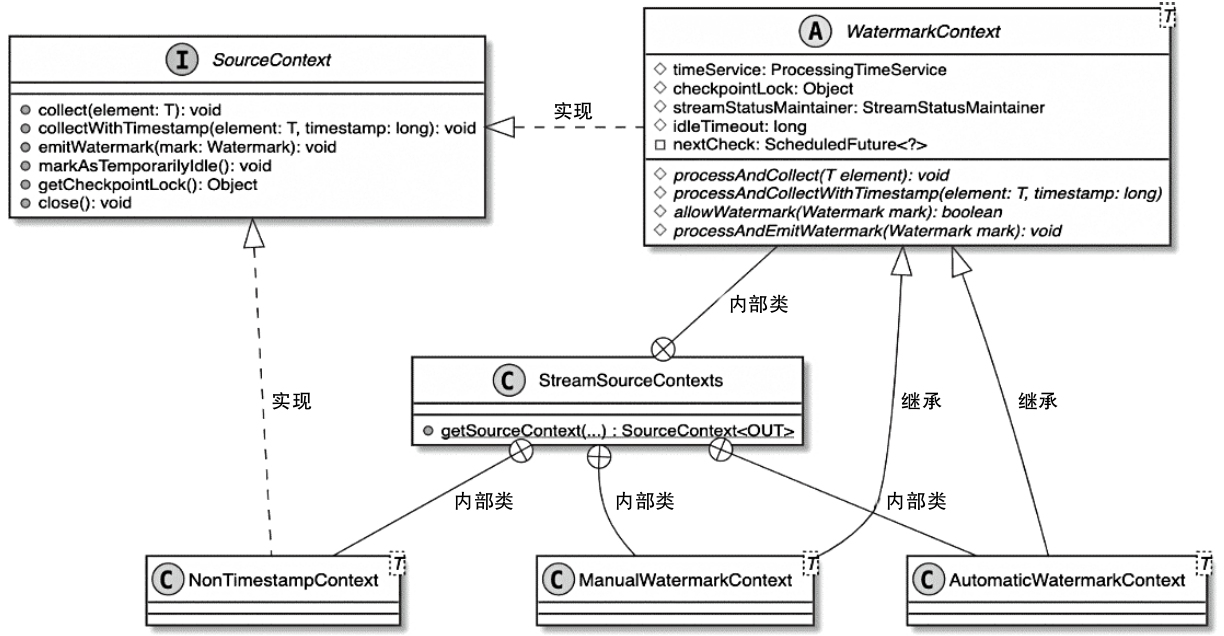
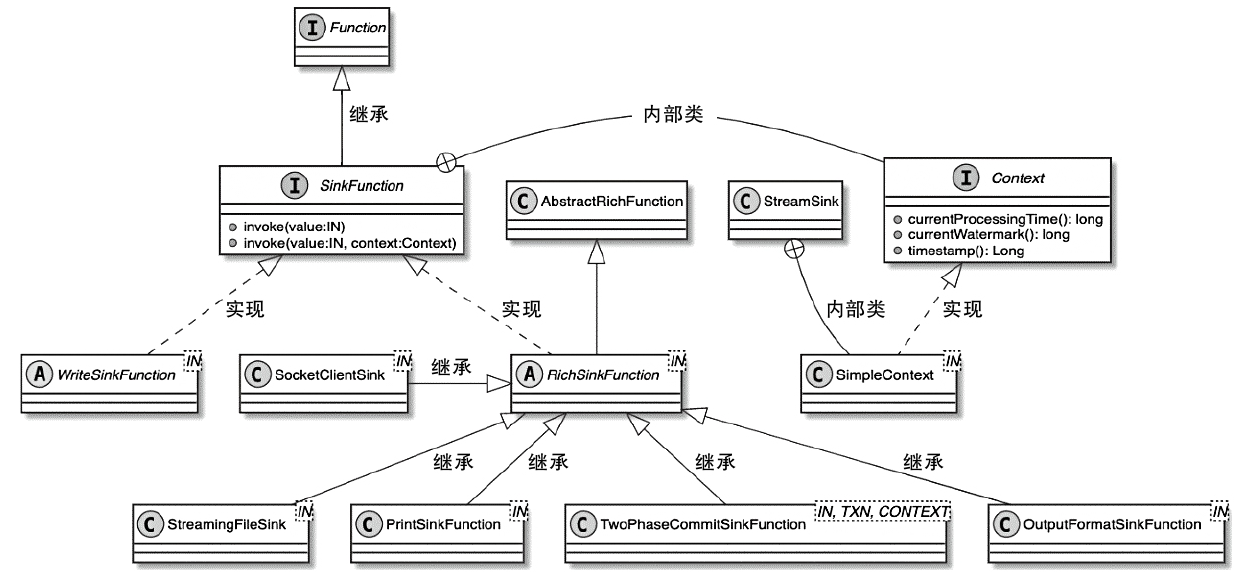
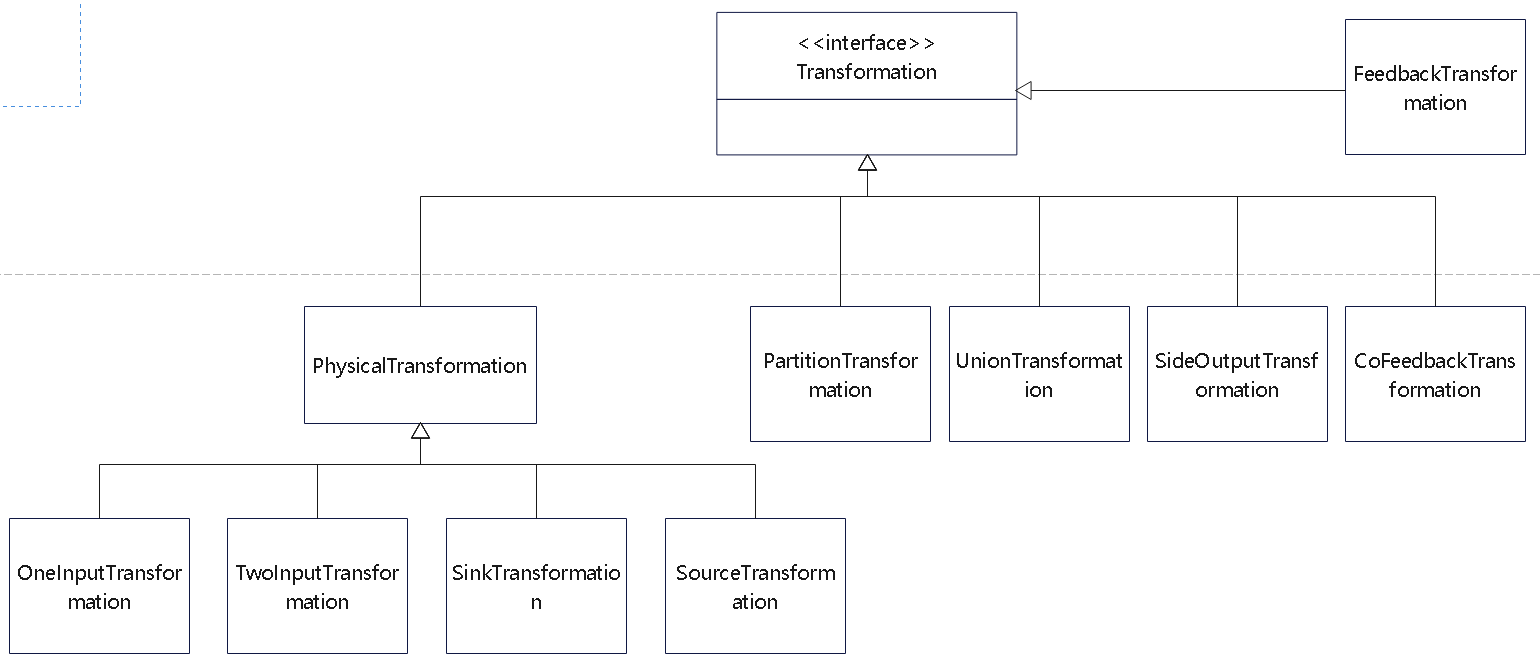
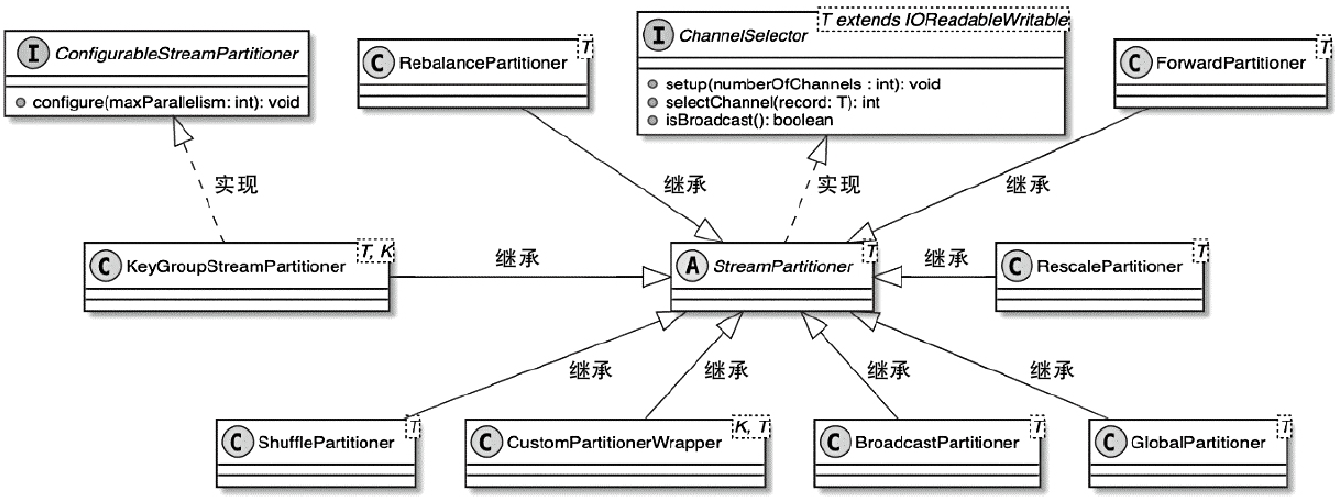
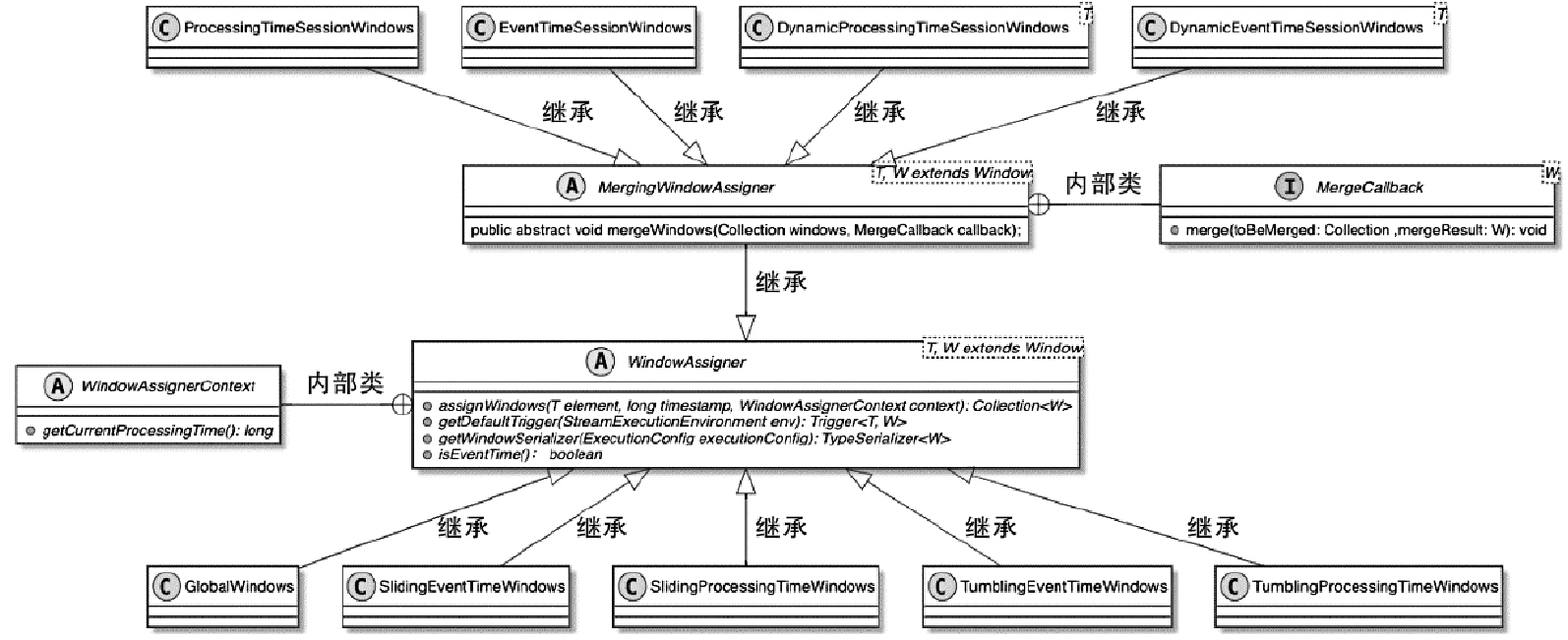
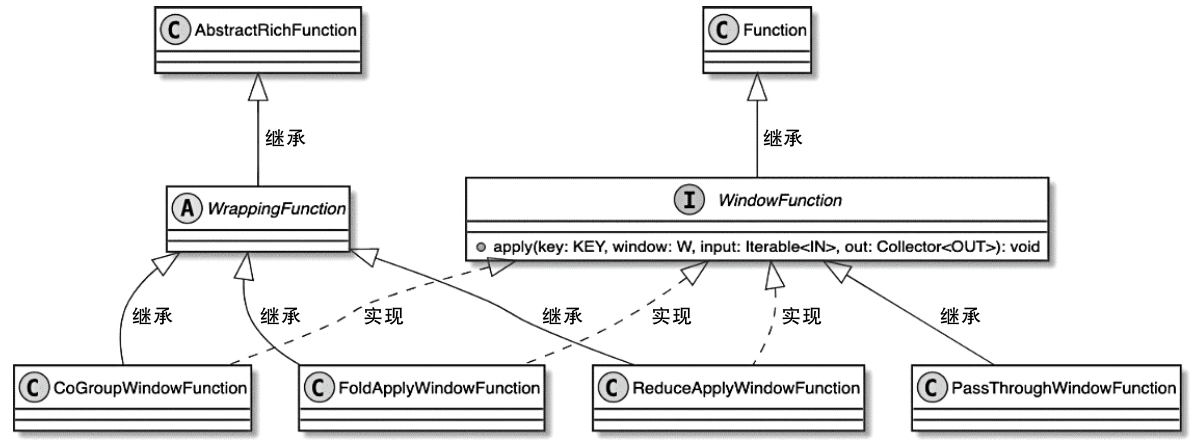
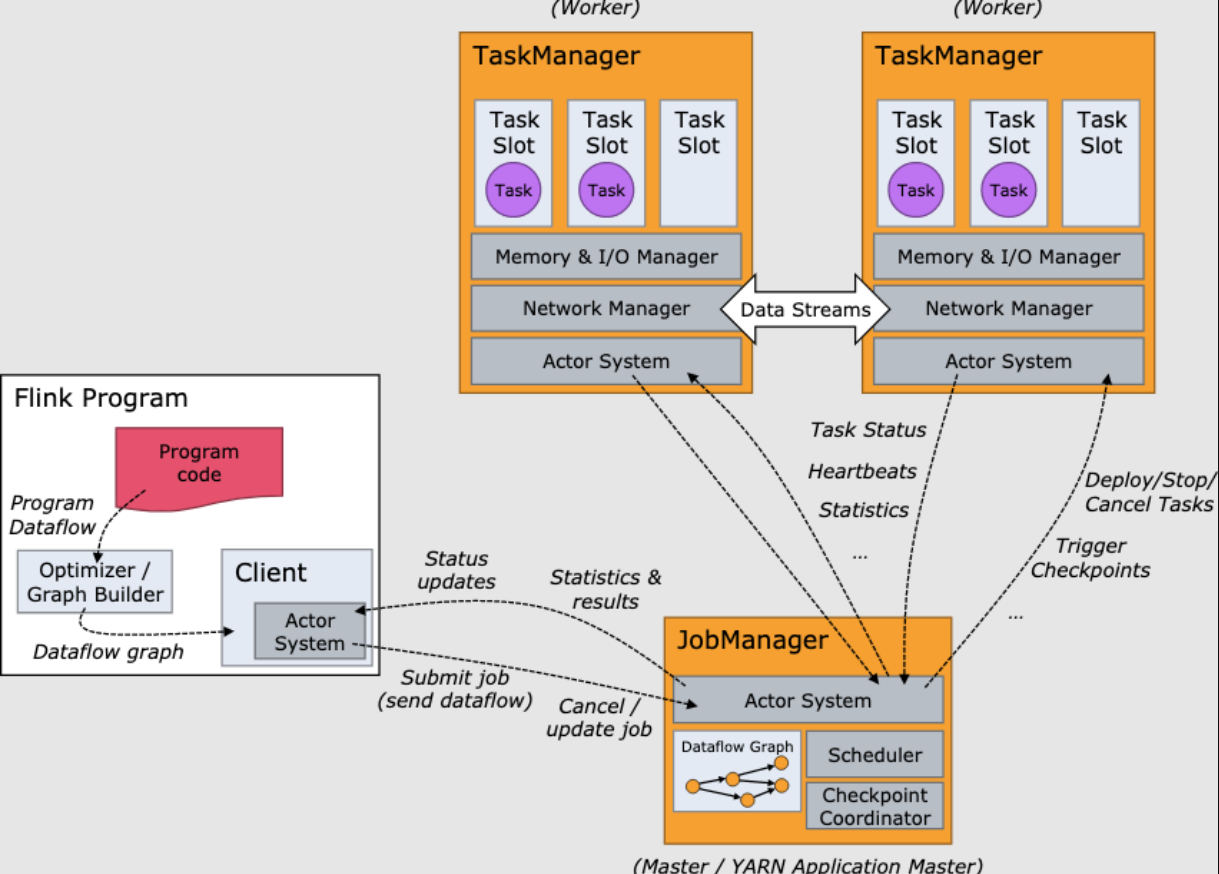
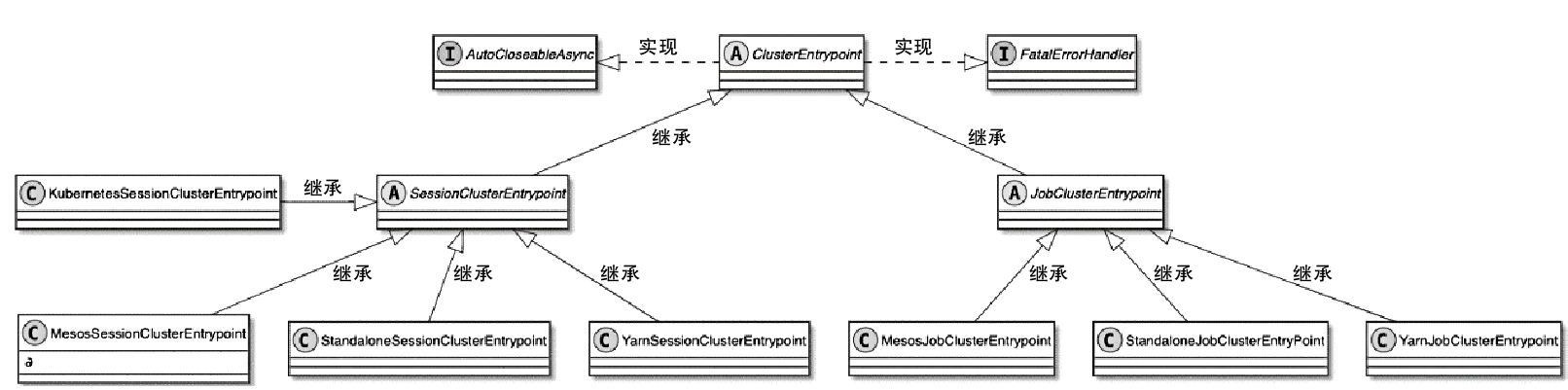
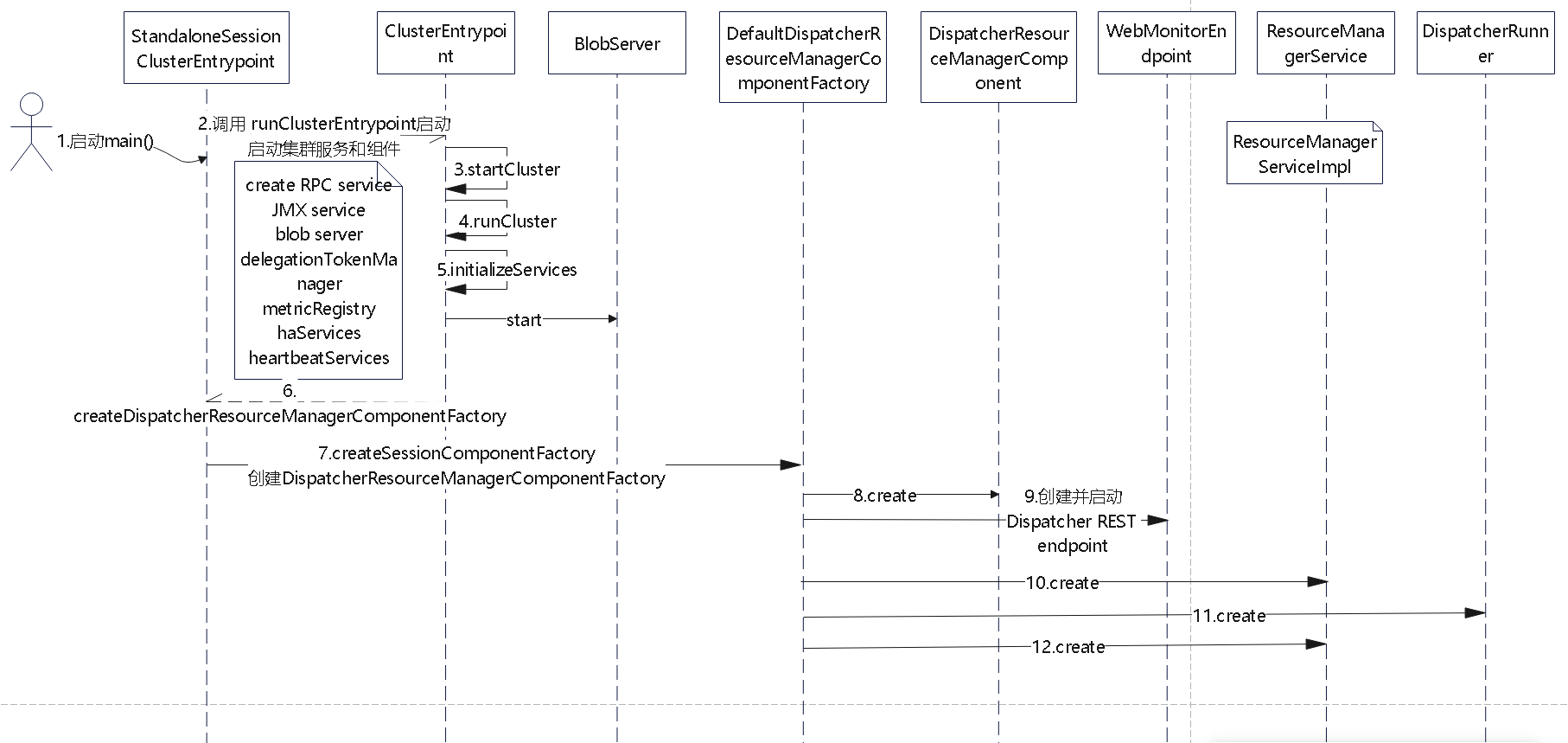
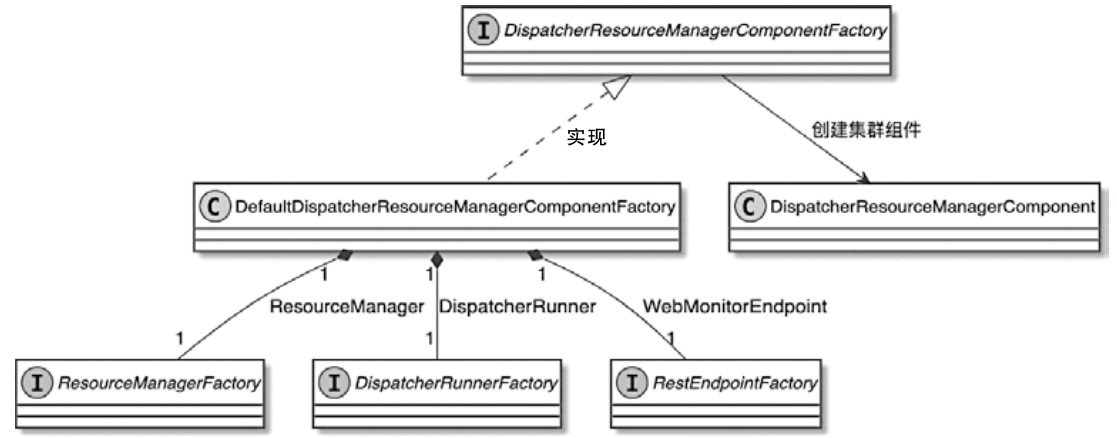
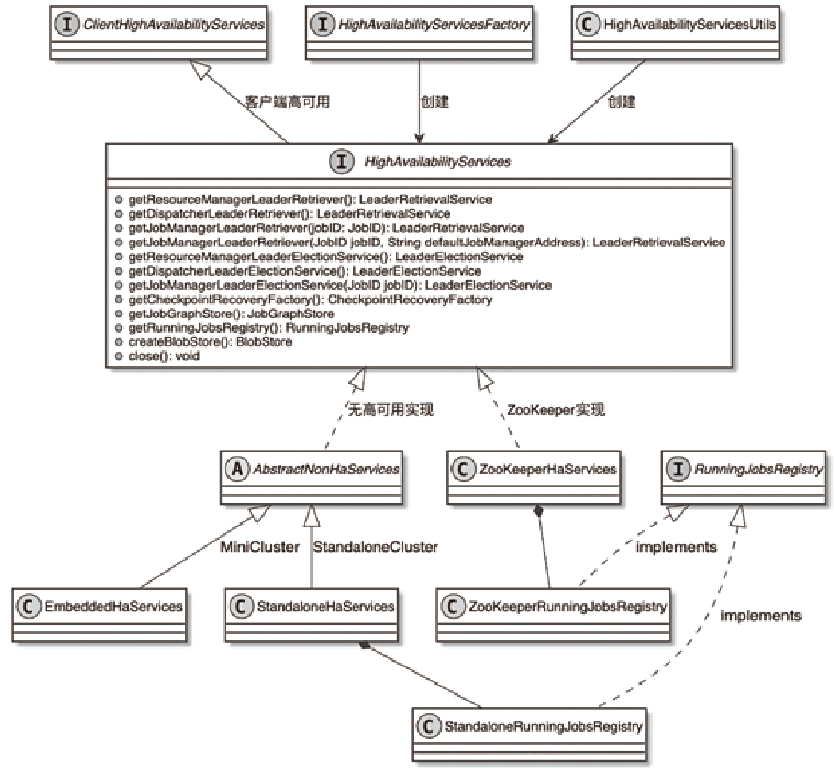
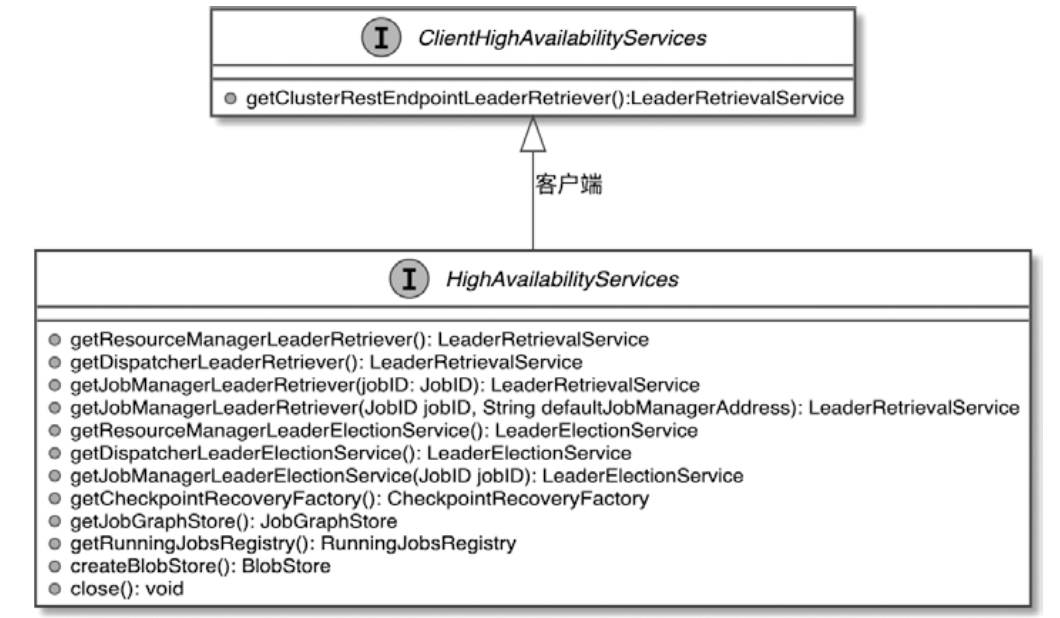
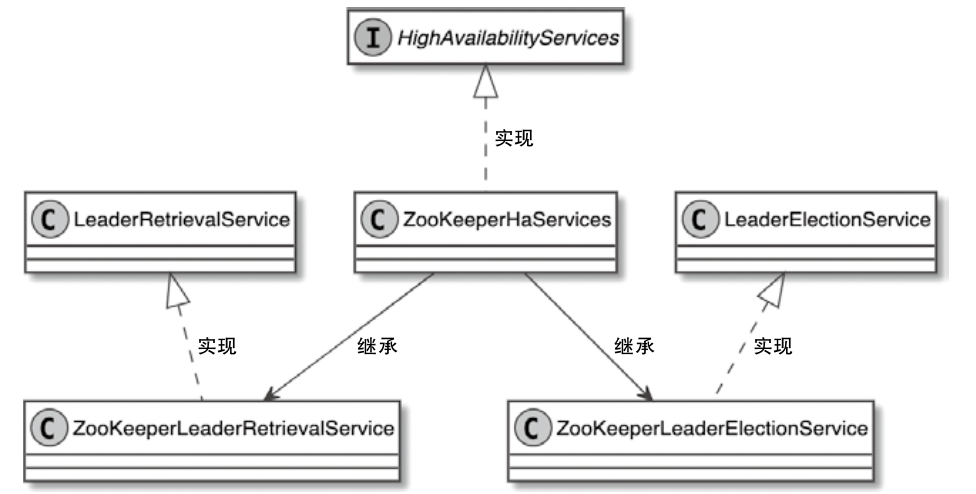
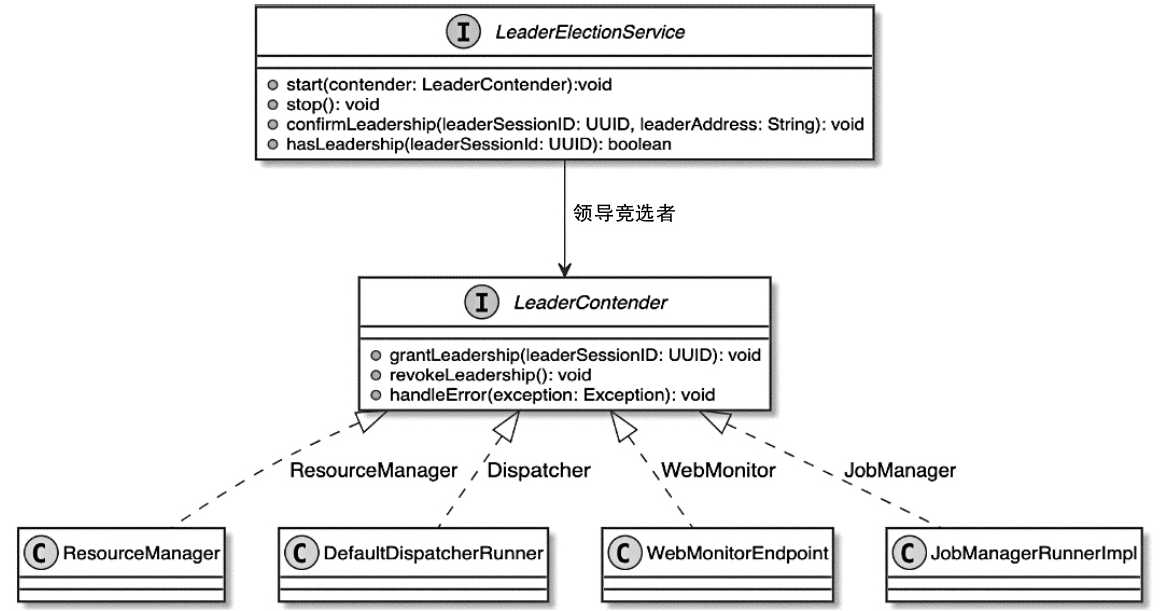
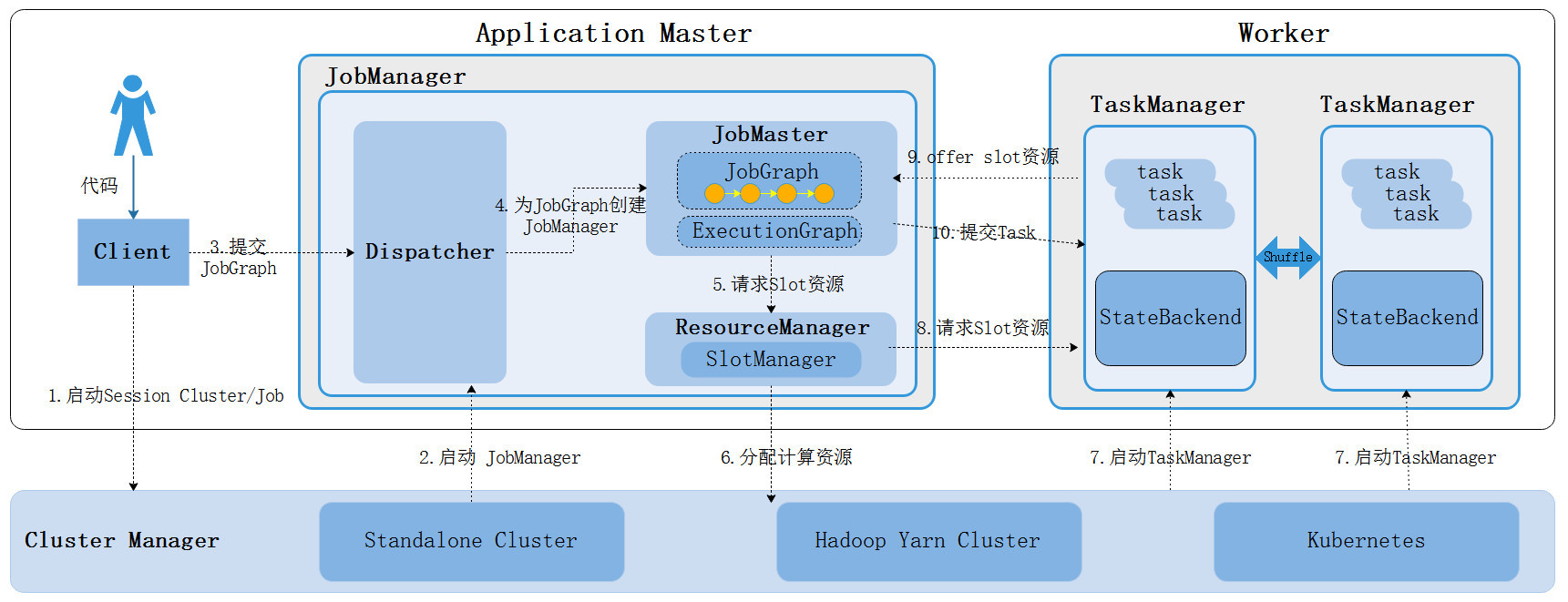
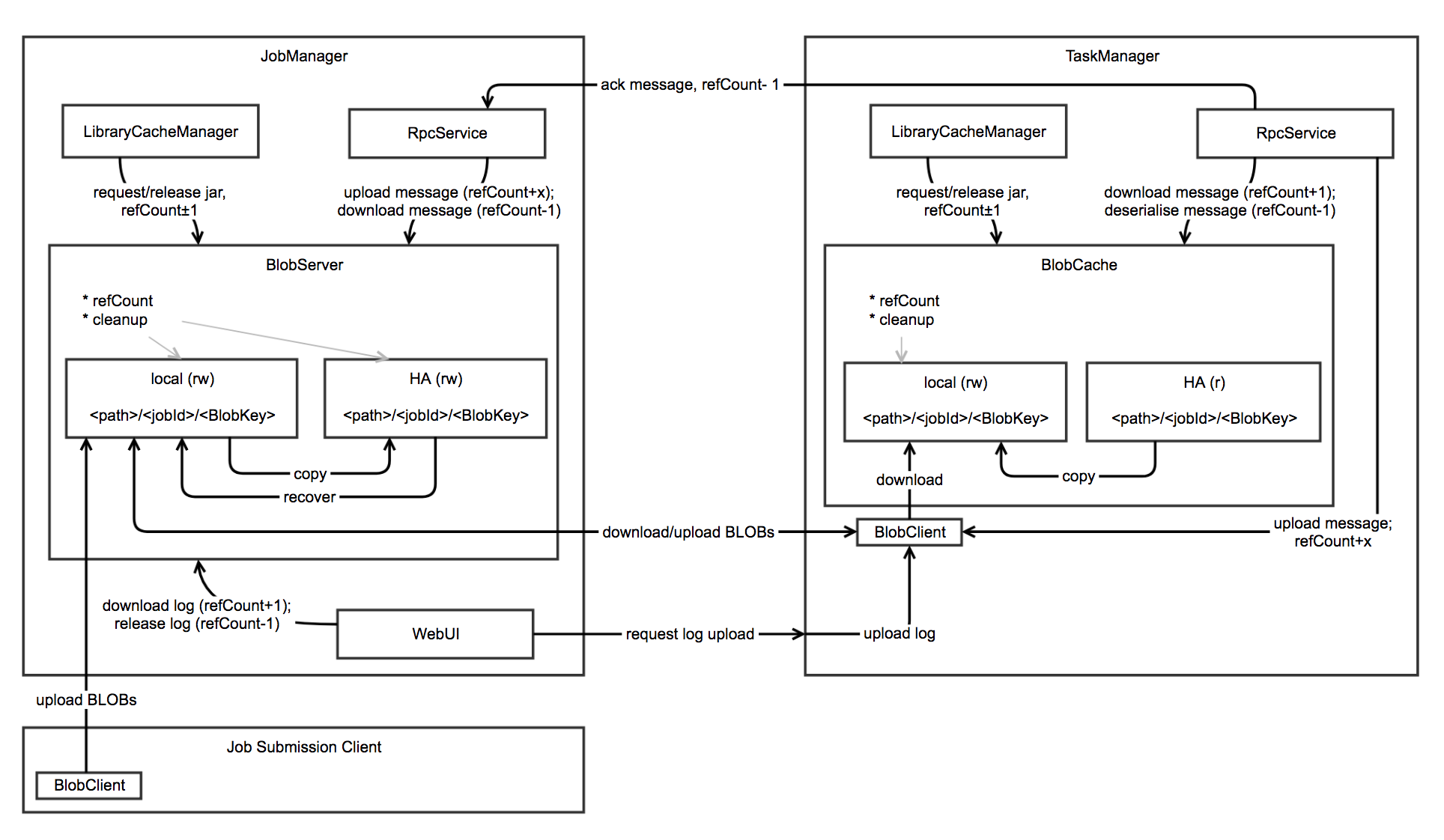
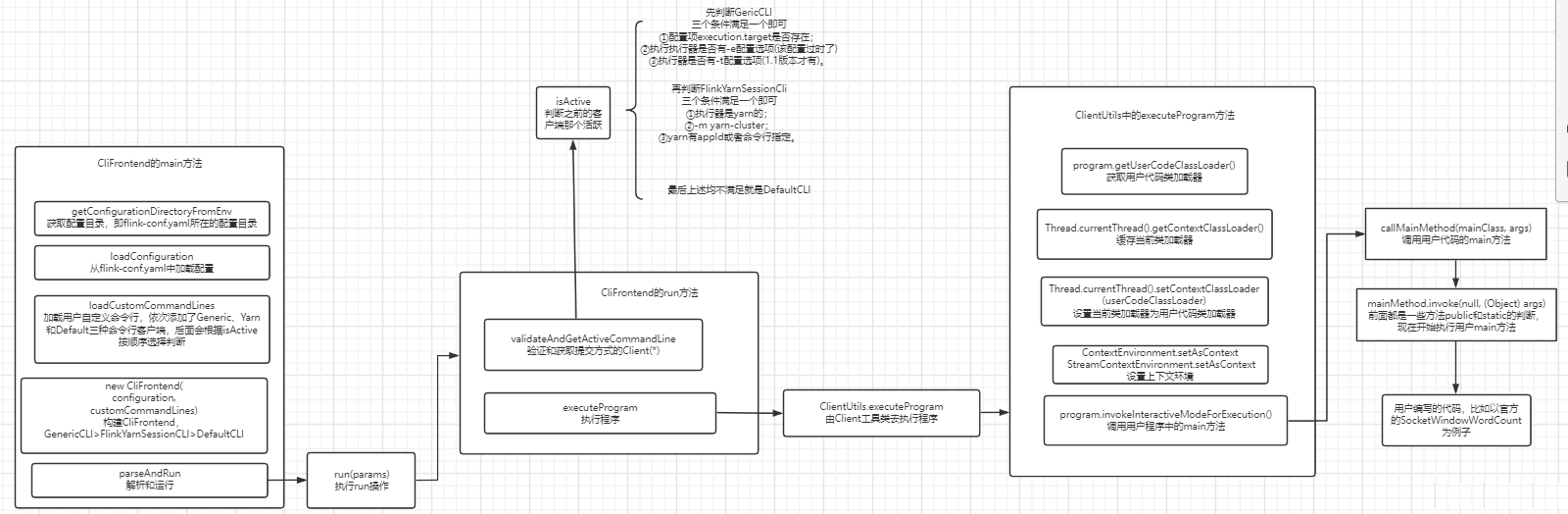
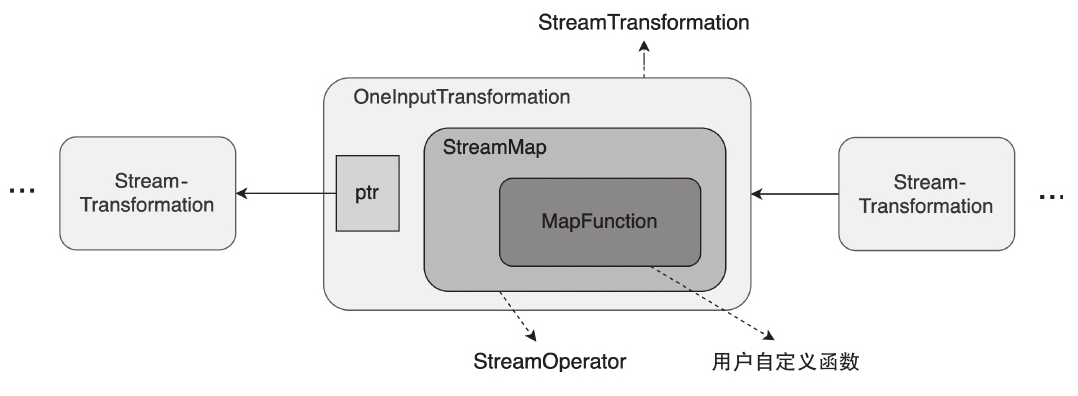
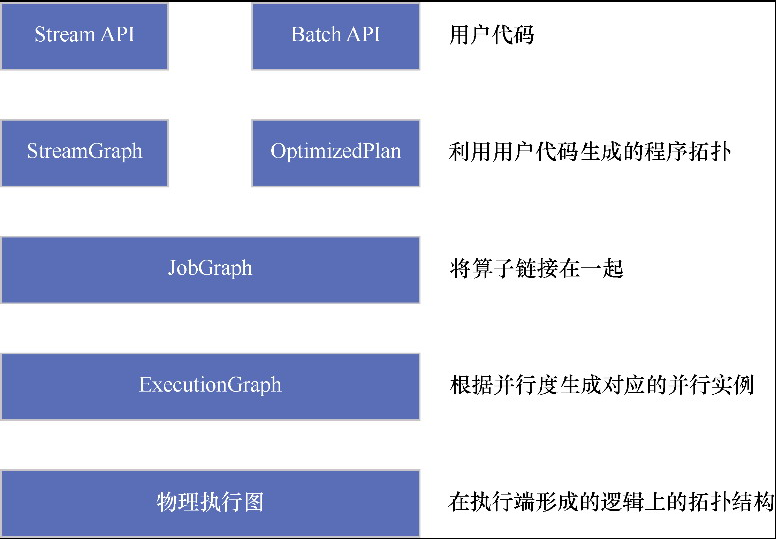
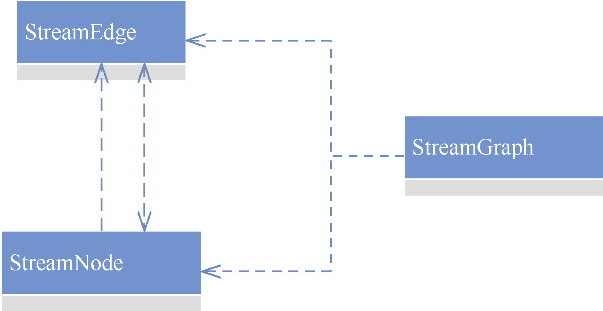
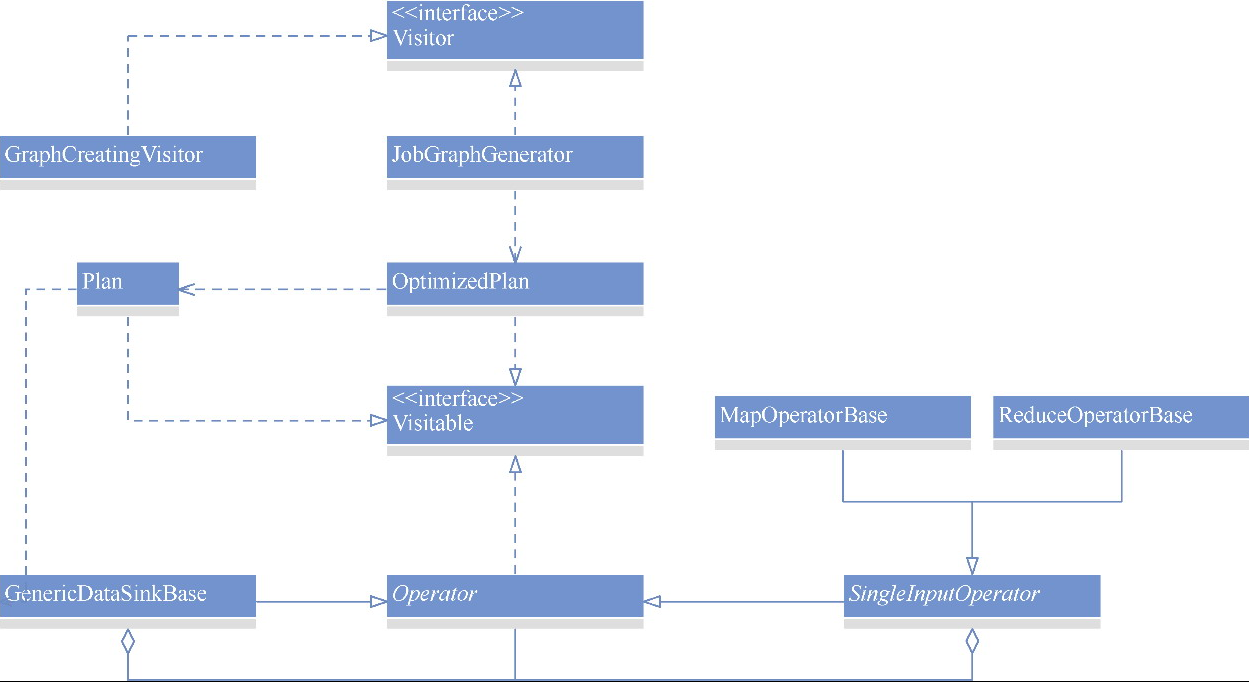
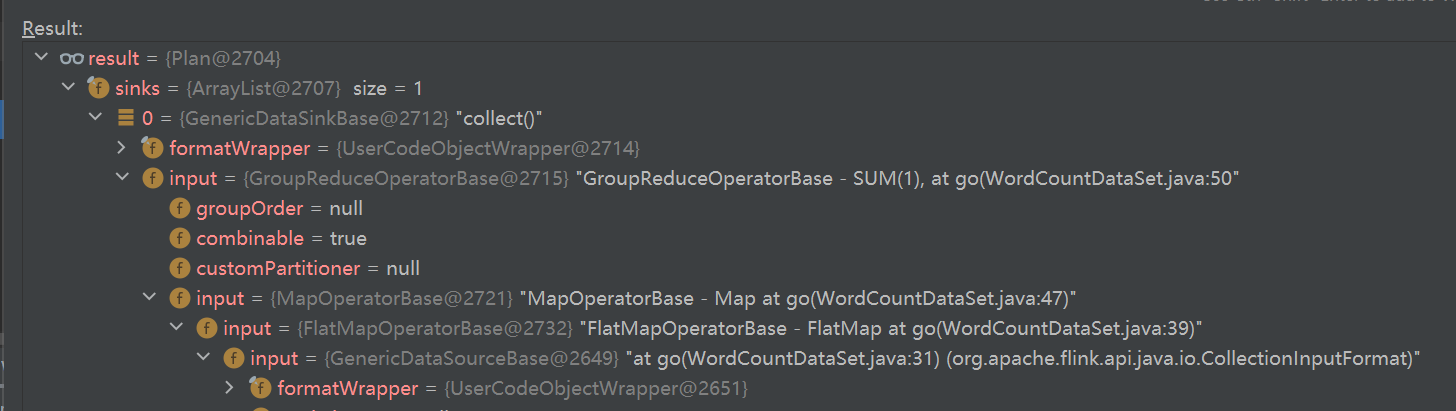
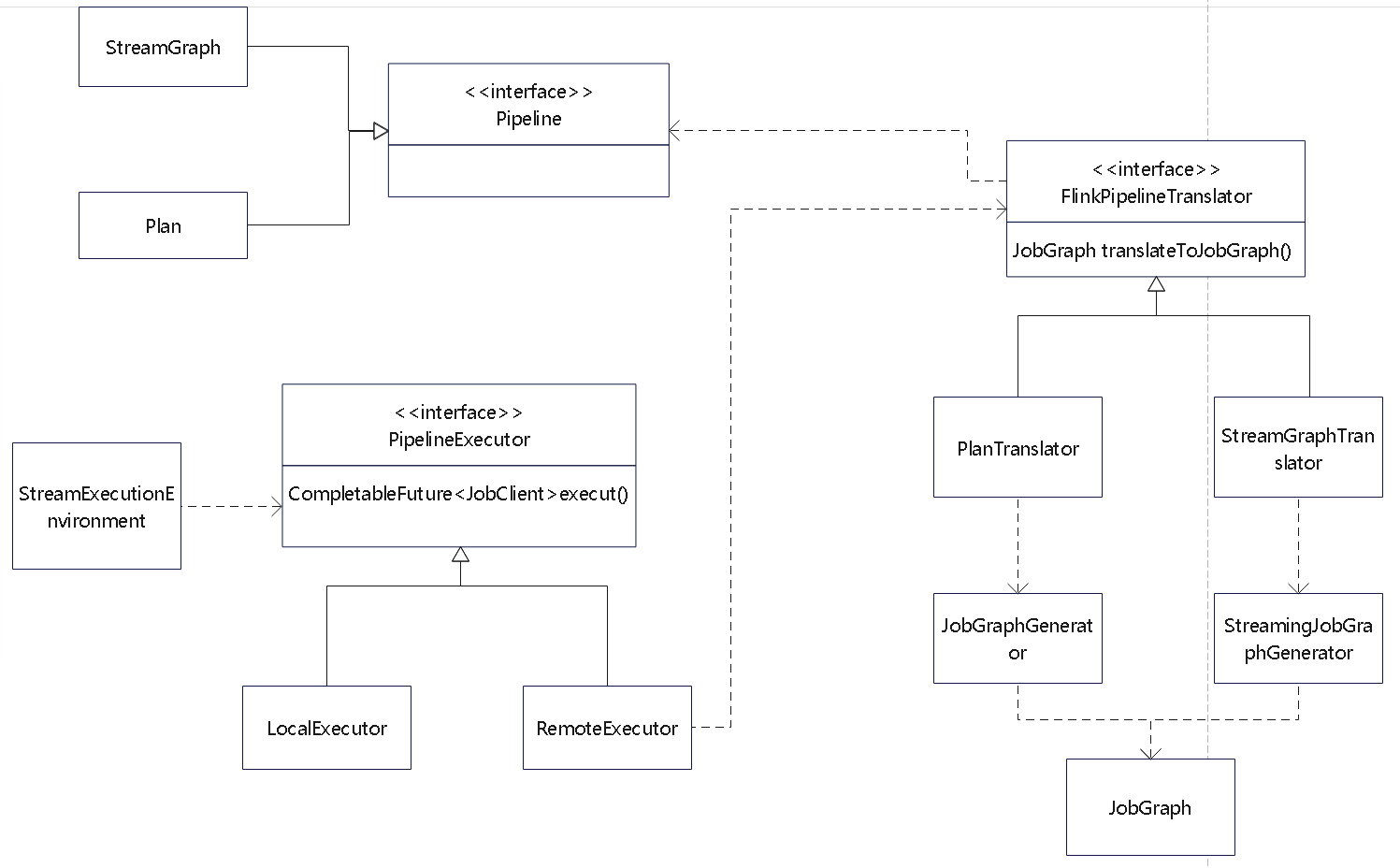
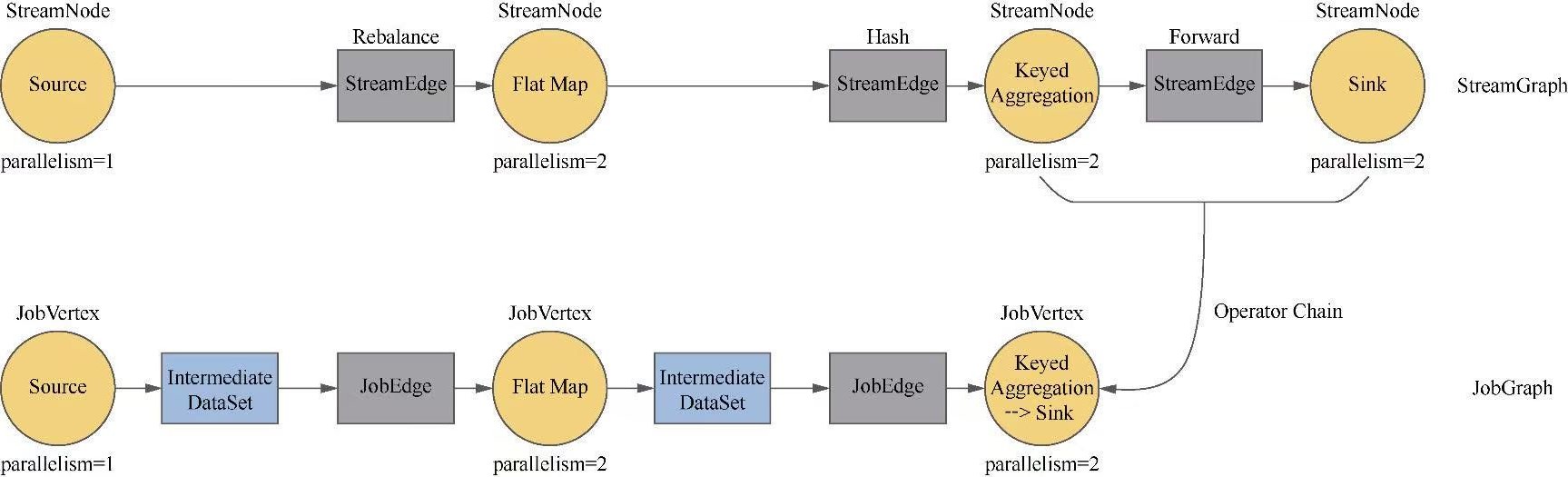
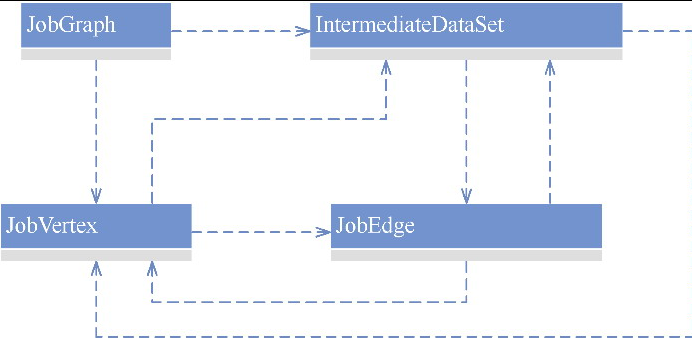
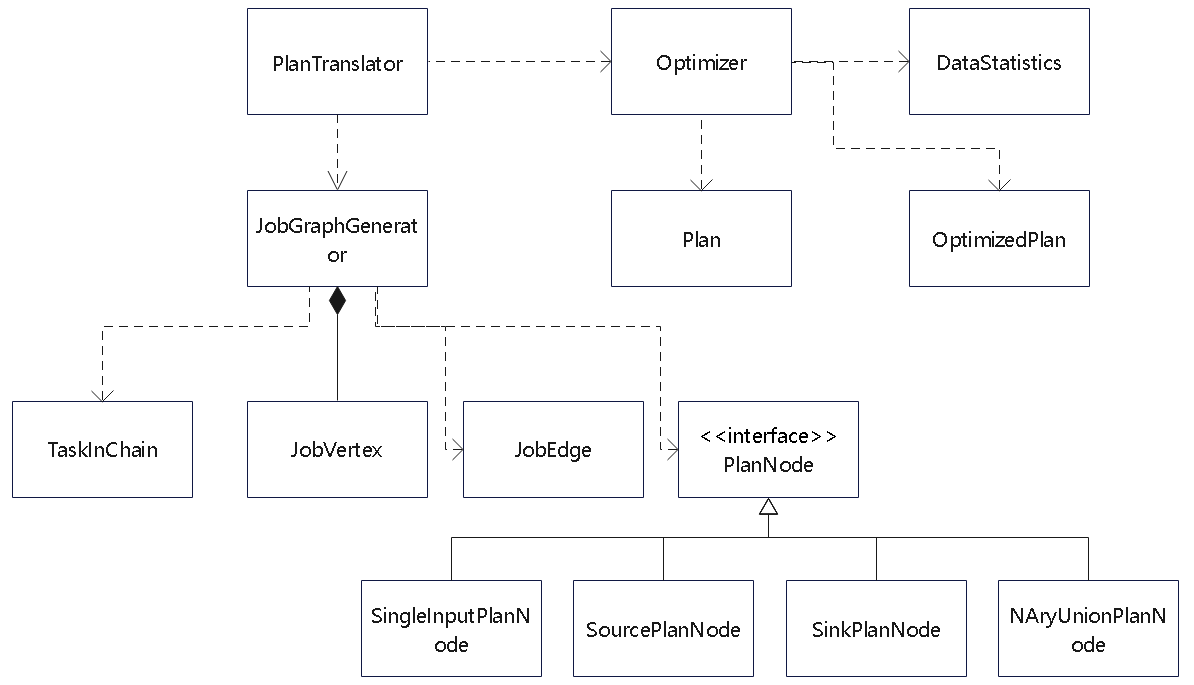
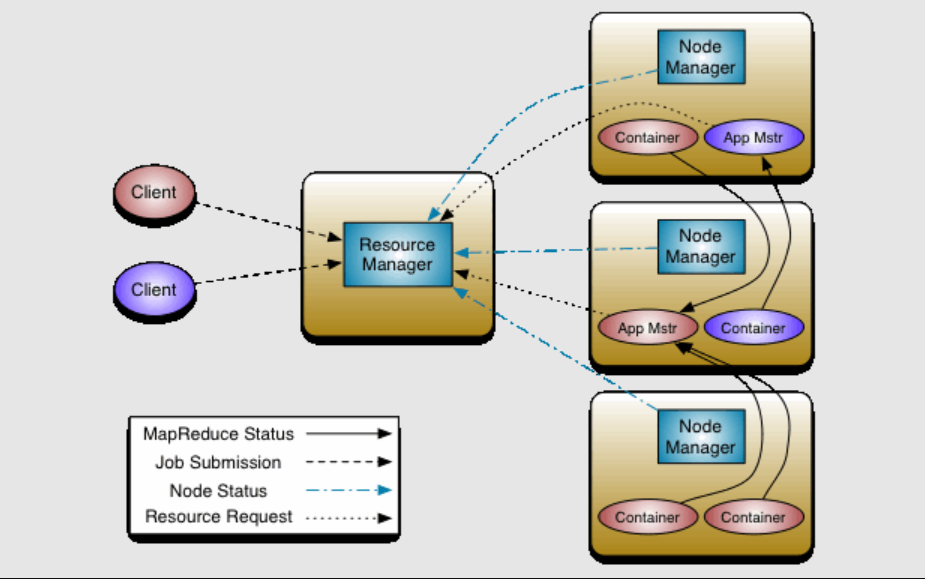
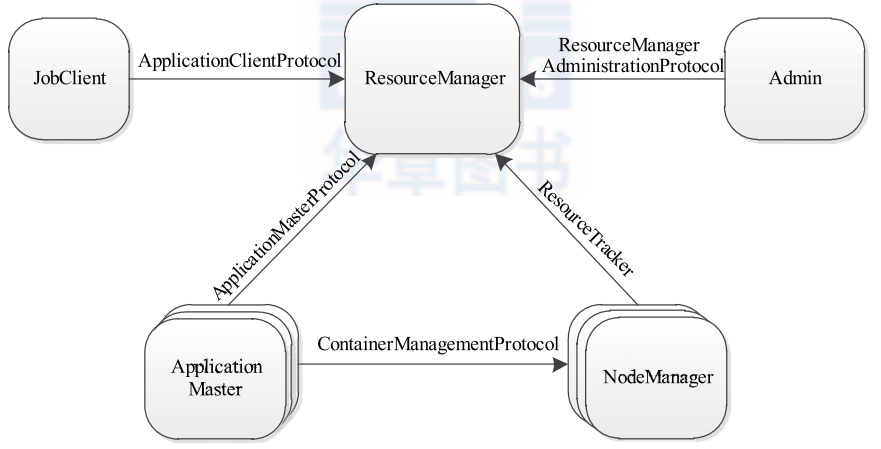
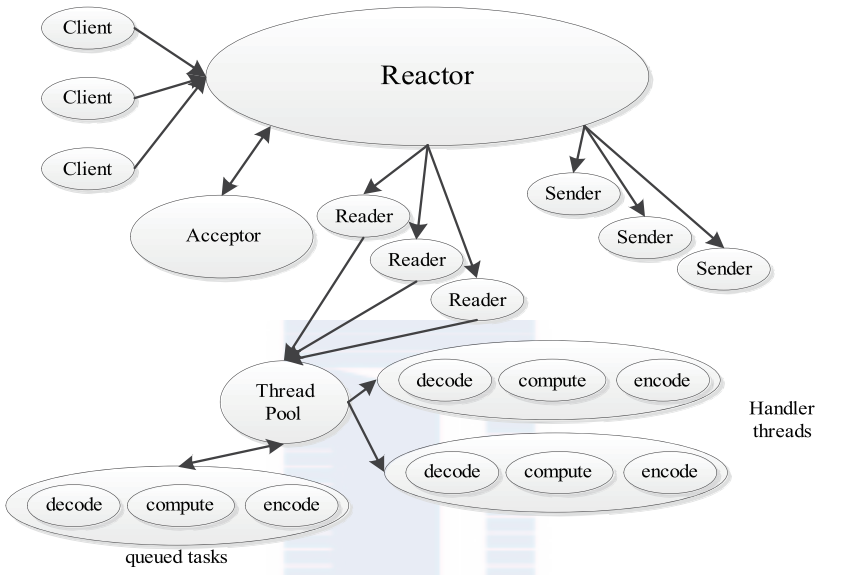
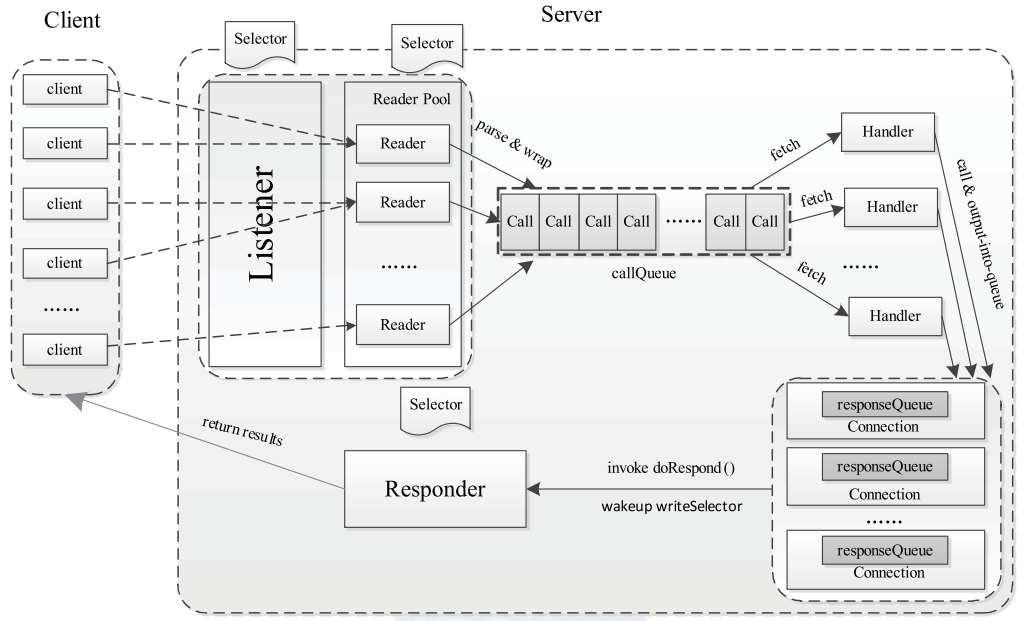
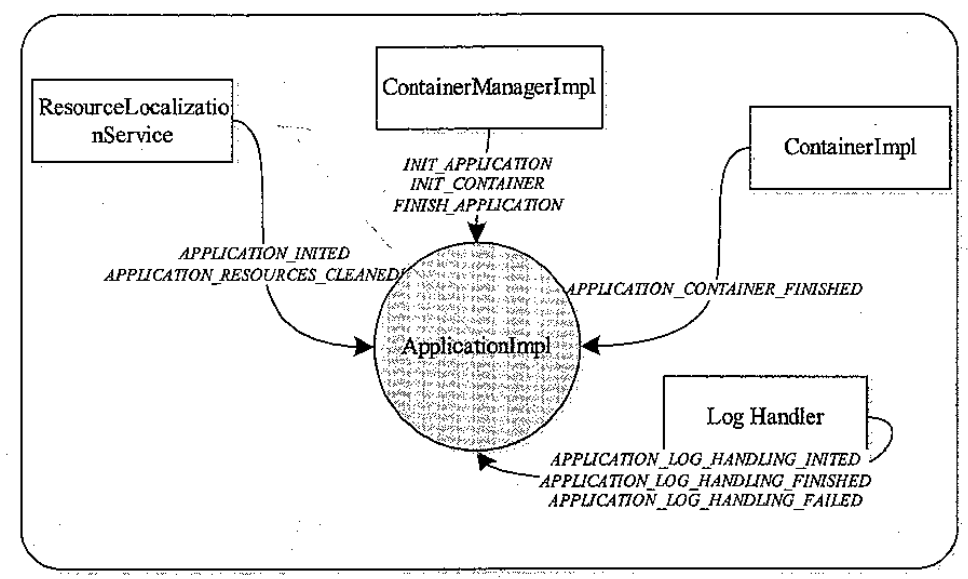
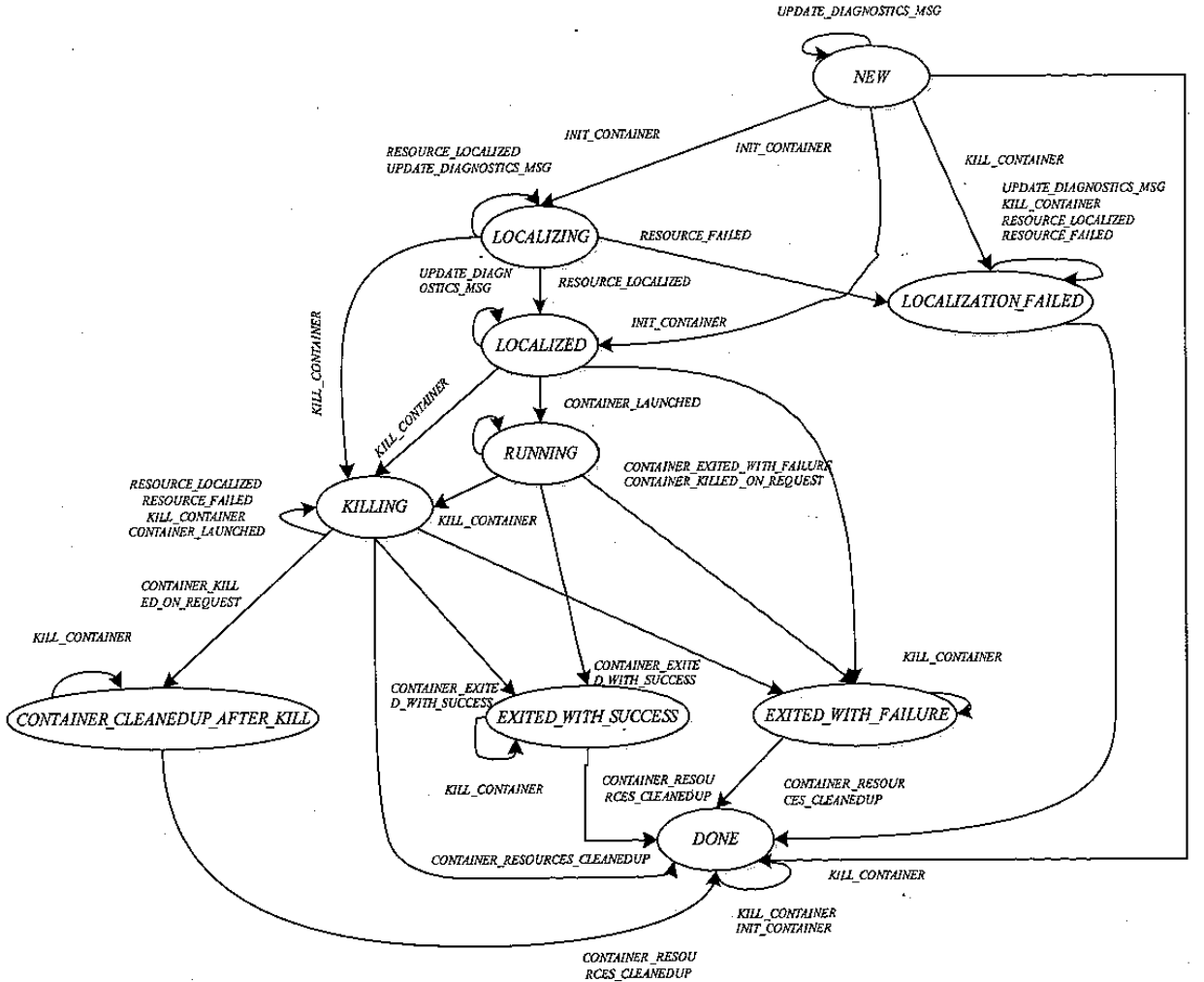
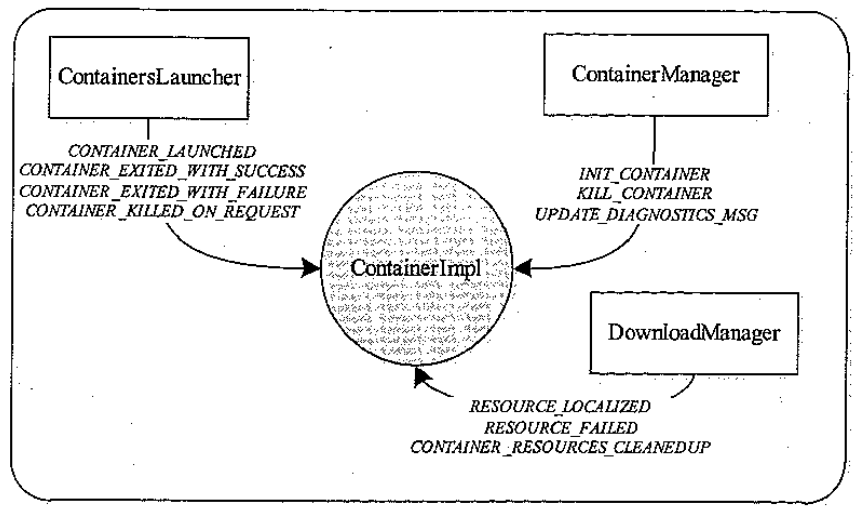
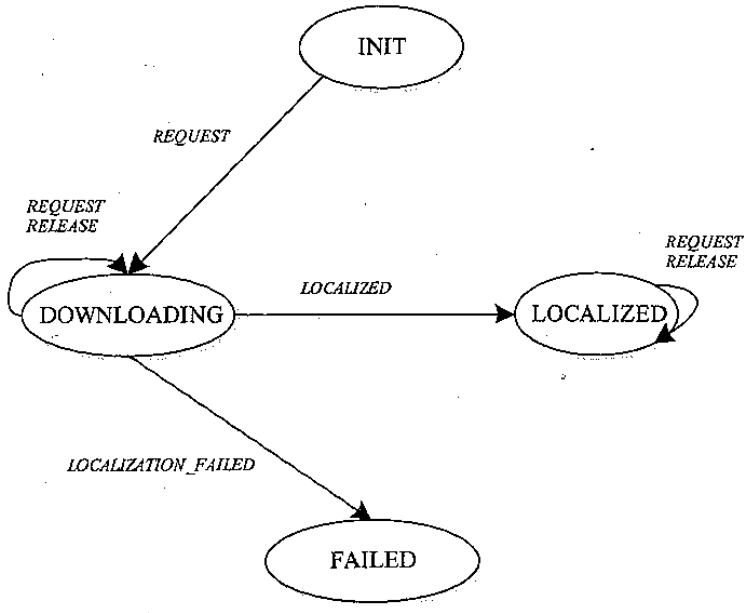
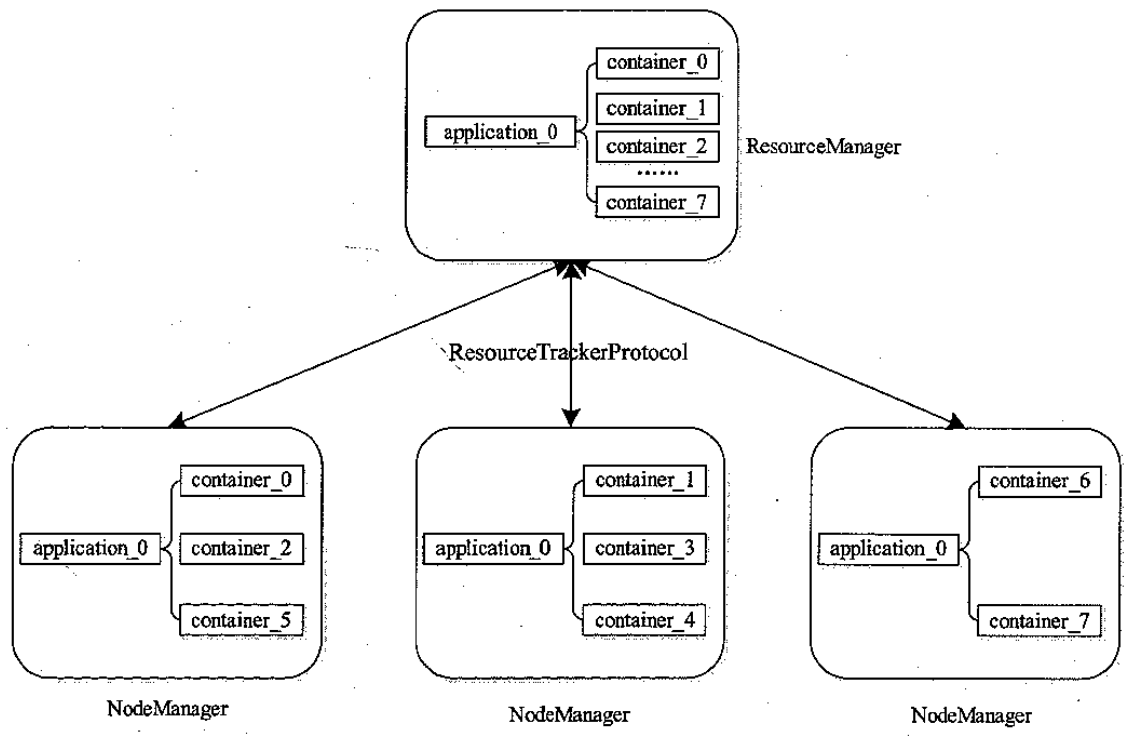
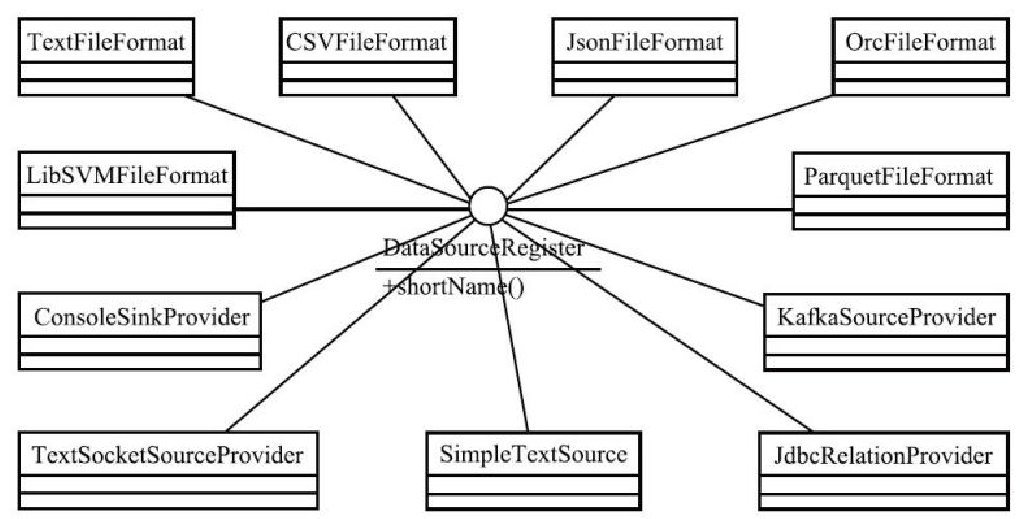
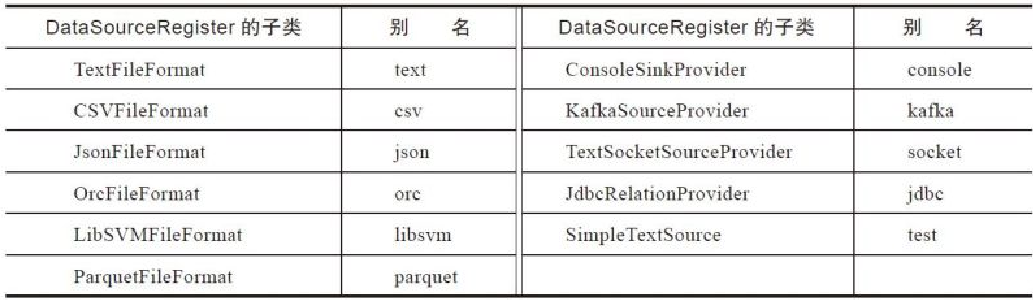
Flink 内存管理
重点包括:
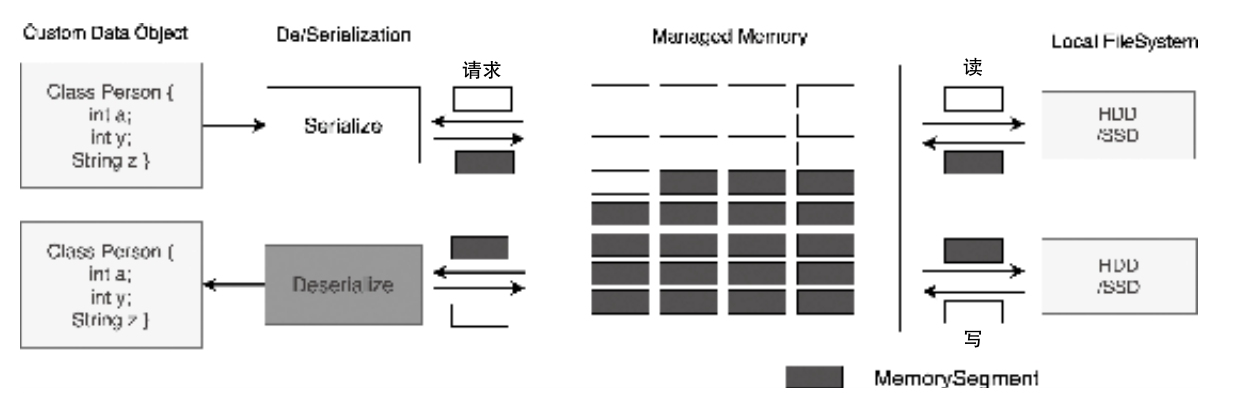
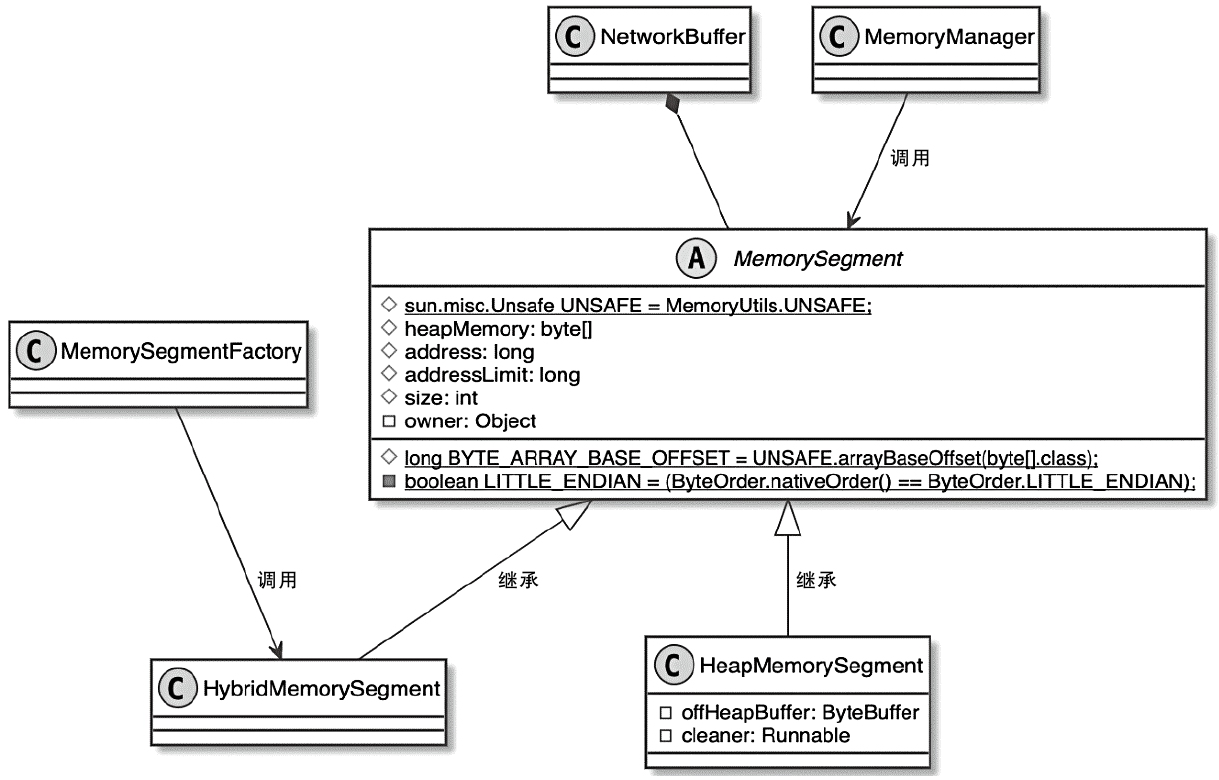
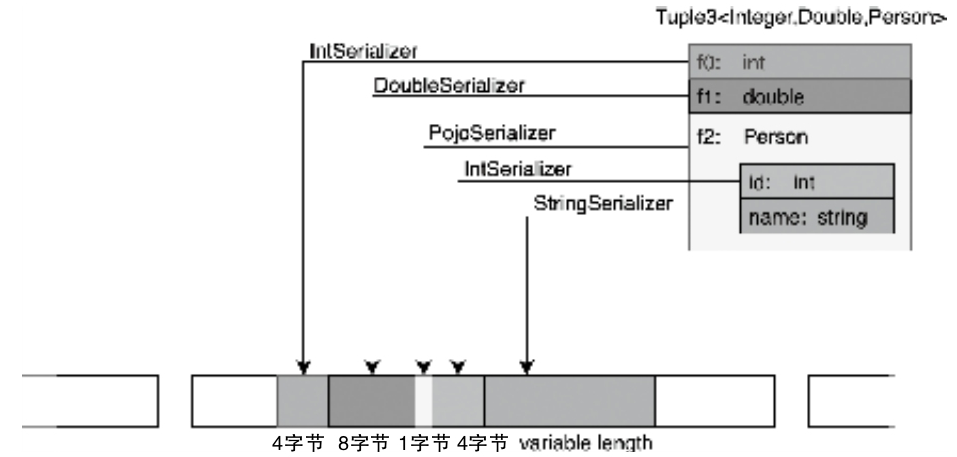
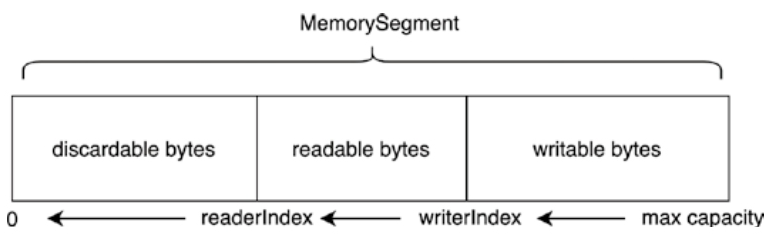
- MemorySegment 是 Flink 最小的内存分配单元,默认 32KB,既可以直接驻留内存,也可以在必要时借助序列化写到磁盘
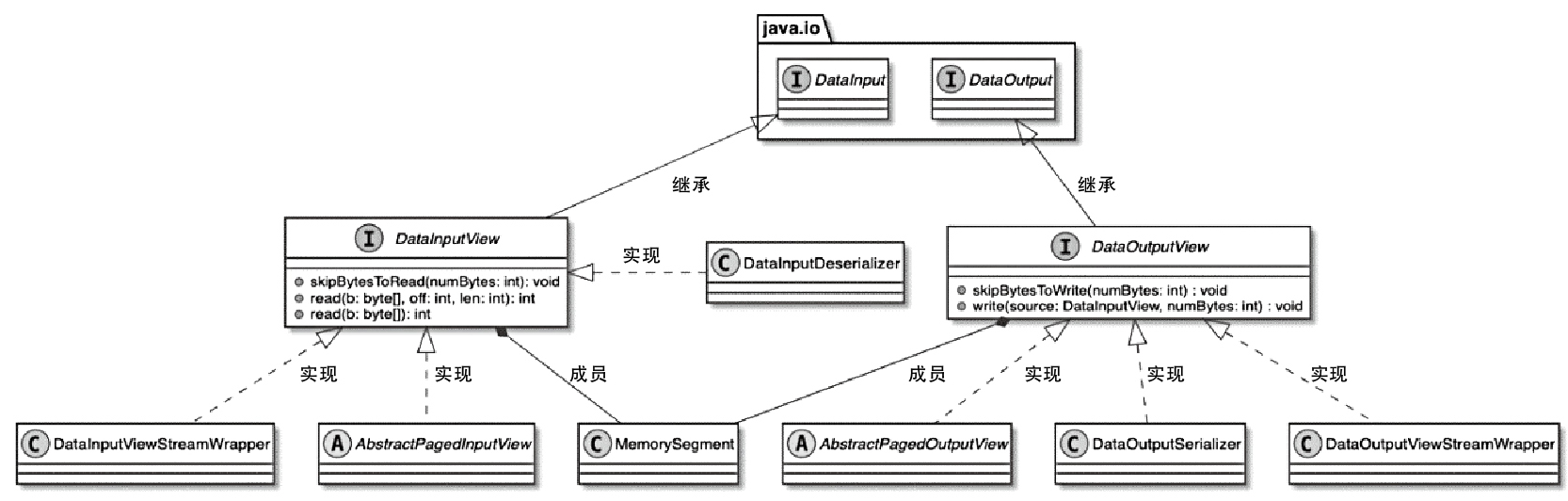
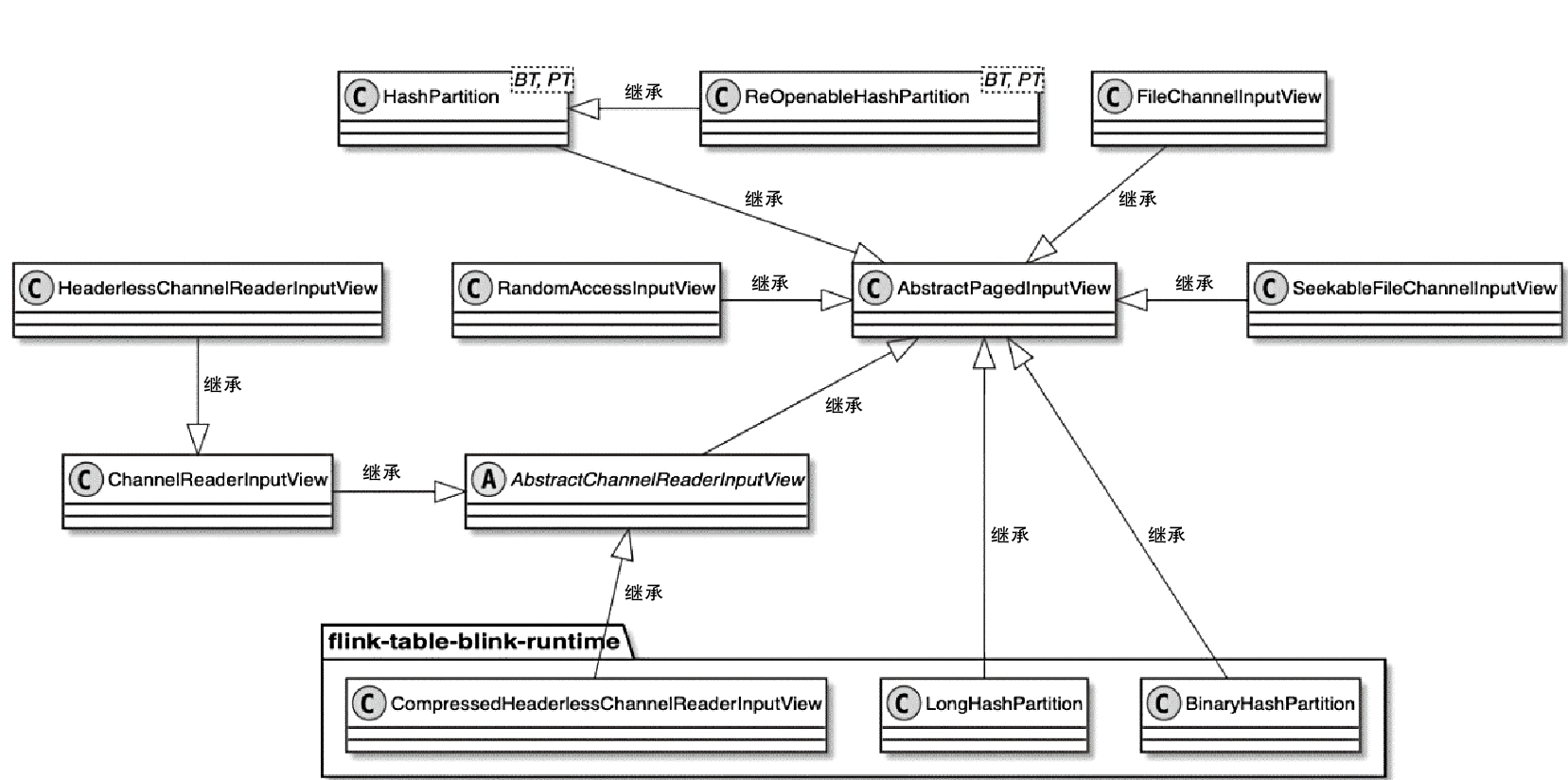
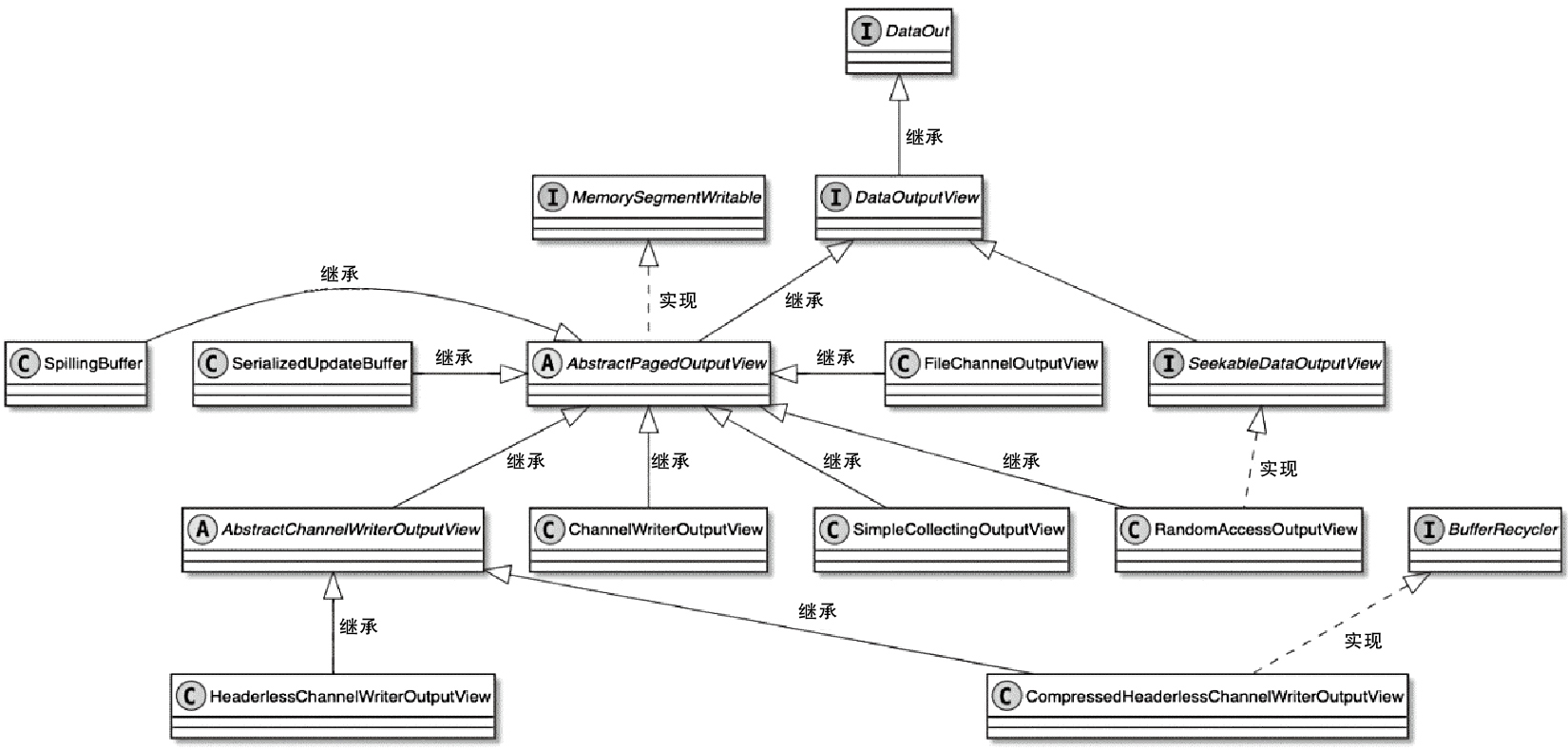
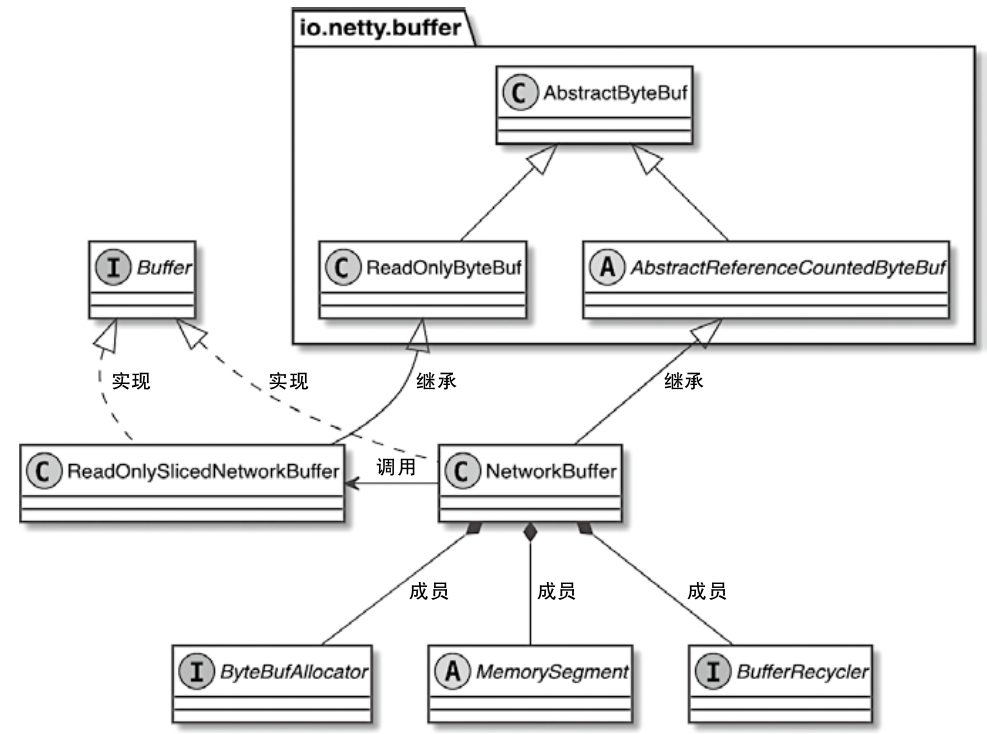
- HeapMemorySegment、DataInputView、DataOutputView 这些基础抽象分别负责堆内内存访问、读取视图和写入视图,是上层算子和序列化框架的基础
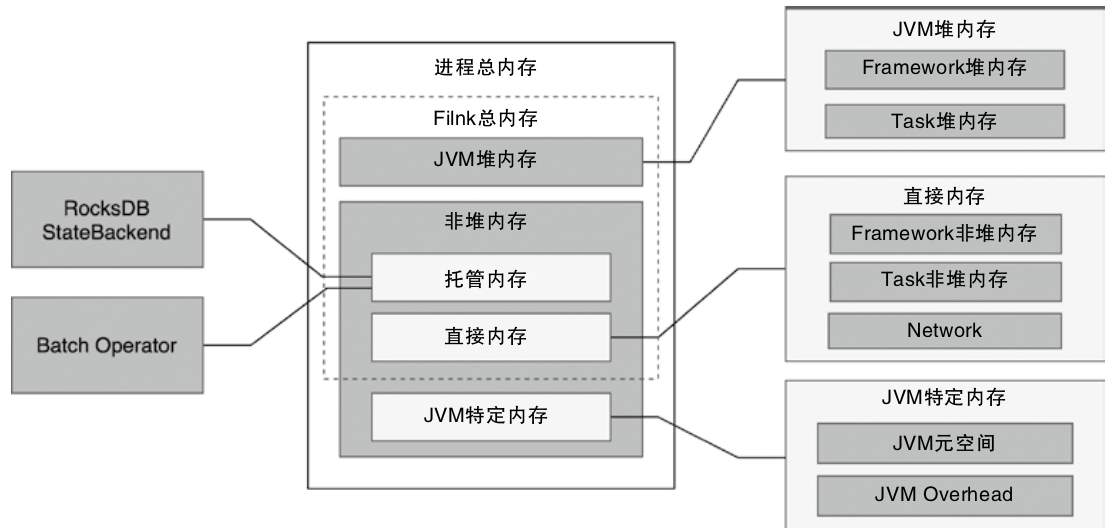
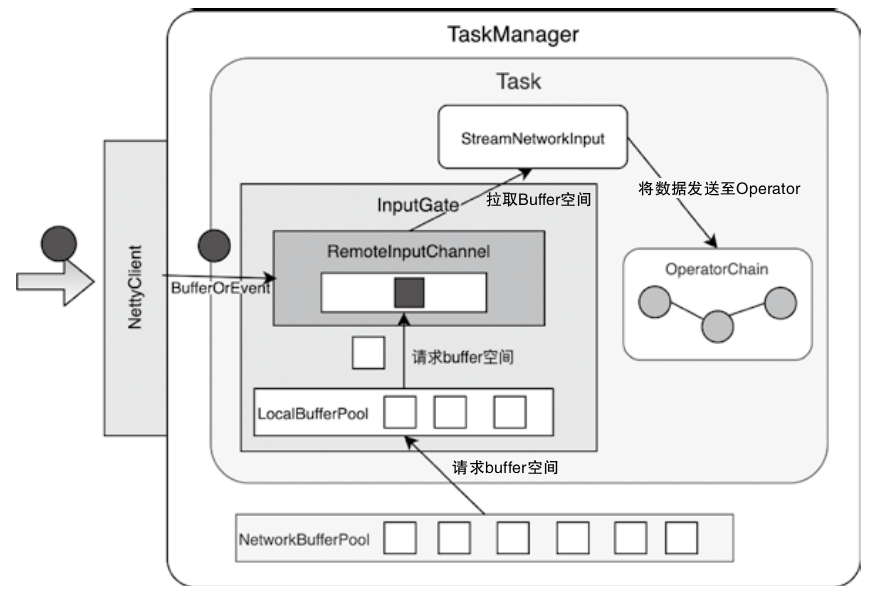
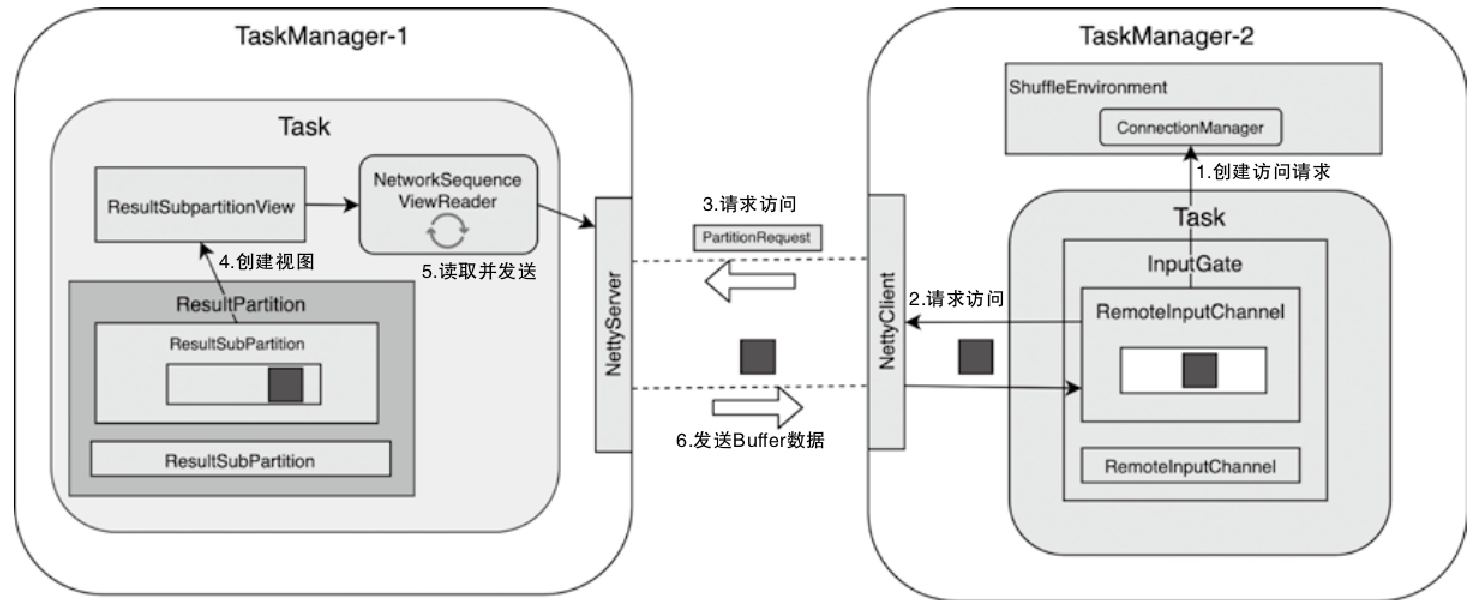
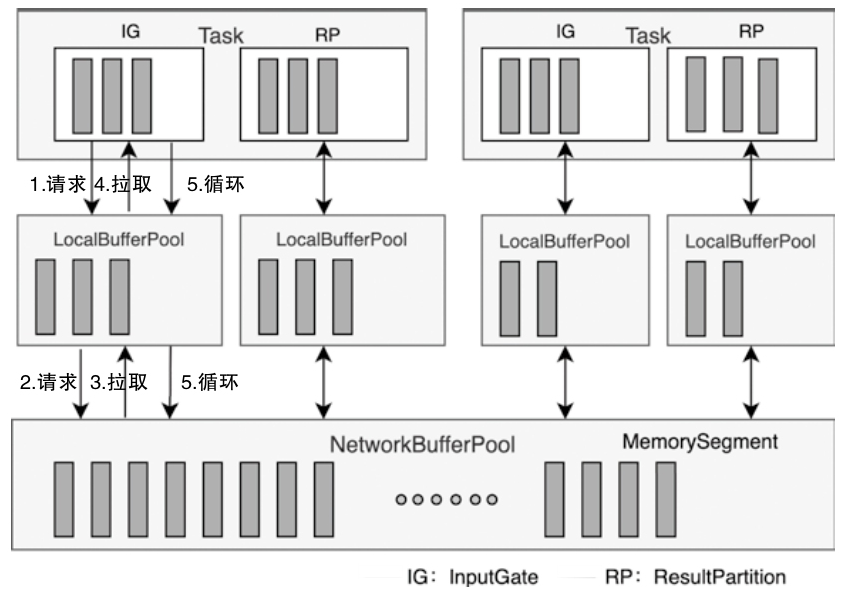
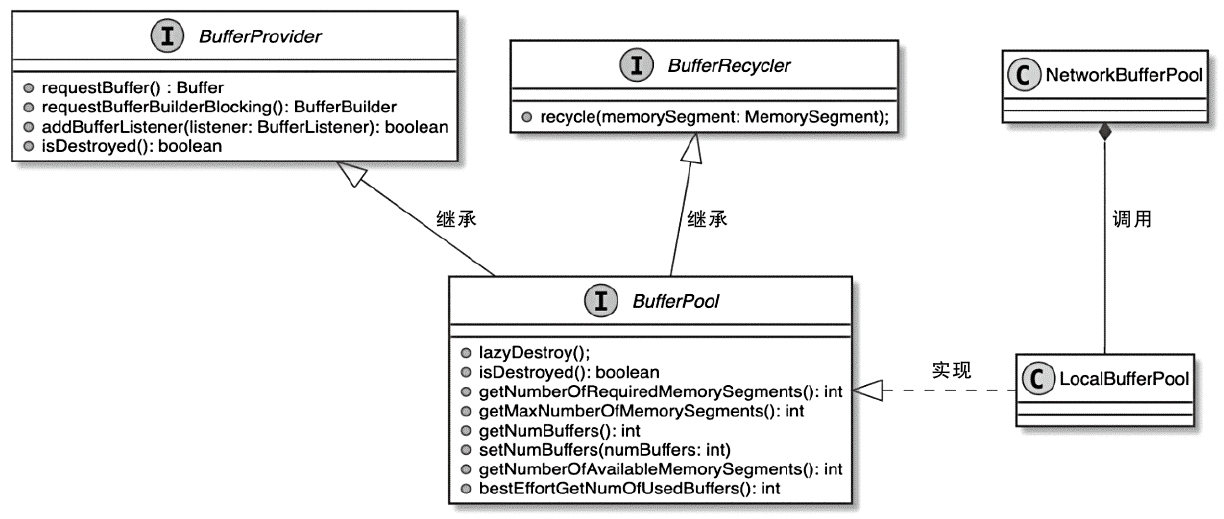
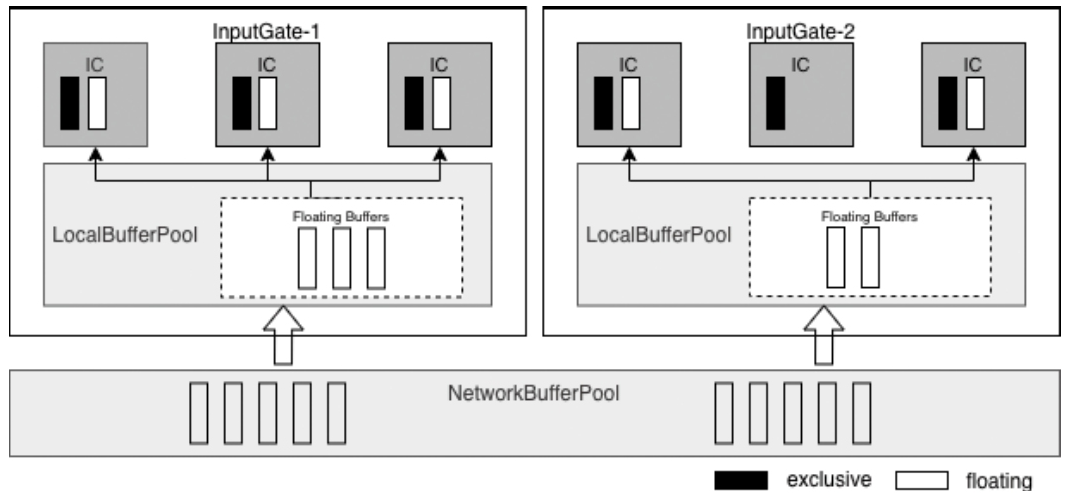
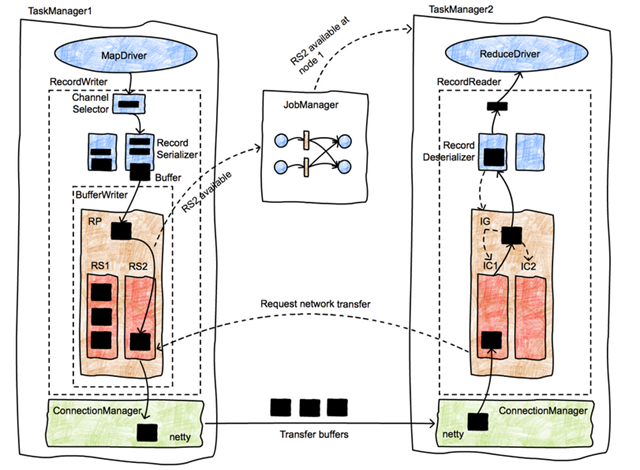
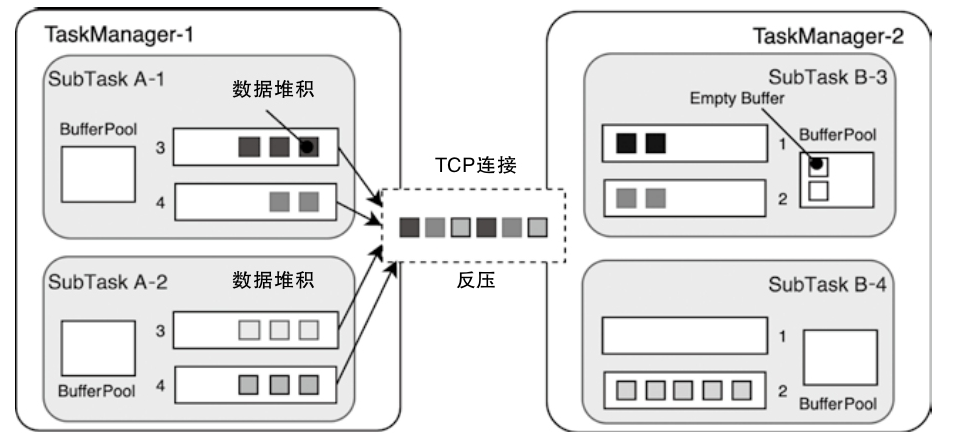
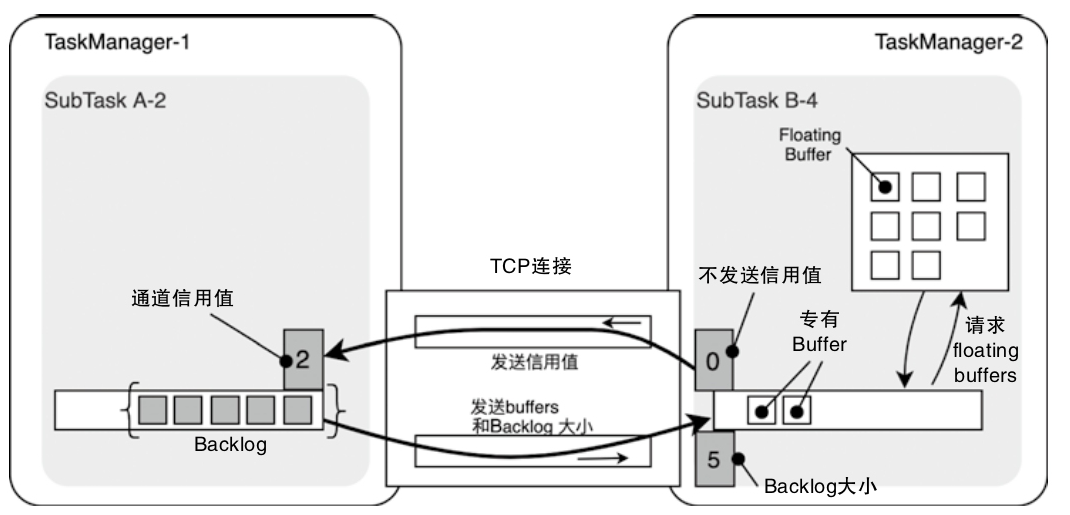
- MemoryManager 主要管理排序、哈希、缓存等更偏离线计算的内存,而 NetworkBufferPool 则通过
MemorySegmentFactory申请网络缓冲区使用的内存 - 调用链可以从 TaskManager -> TaskSlot -> MemorySegment 这条路径去理解,后面再结合 KryoSerializer 和
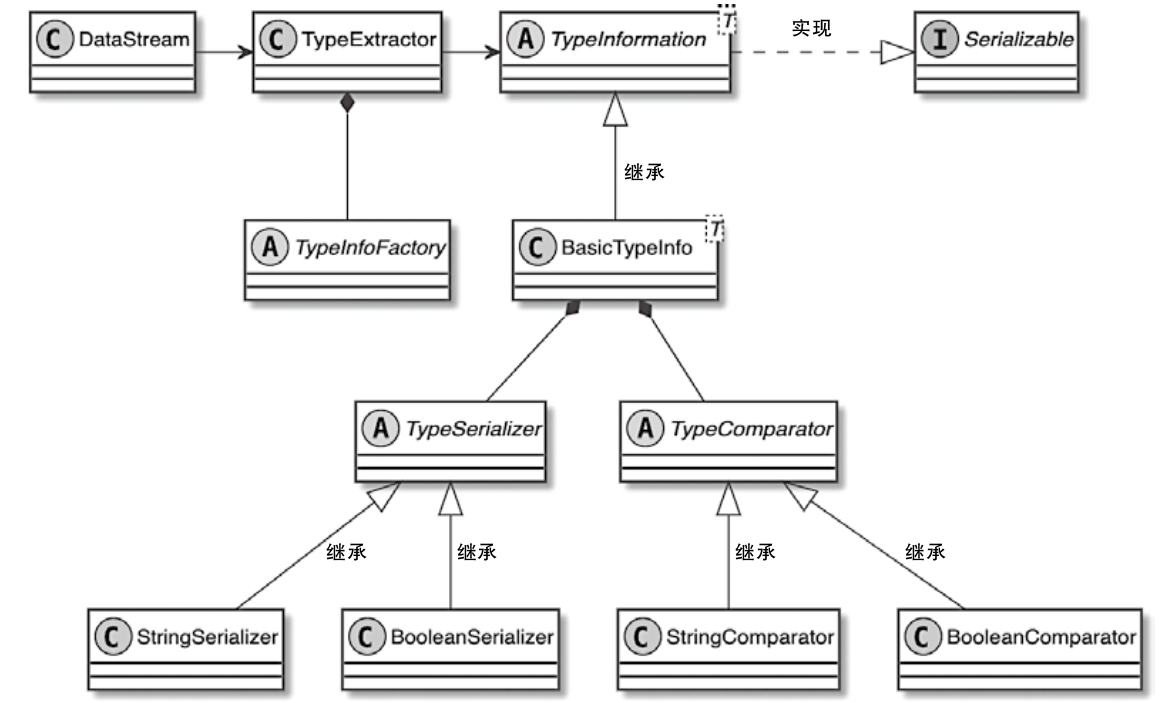
TypeInformation看 Flink 的序列化体系怎么工作