Alluxio论文
原文:
《Tachyon: Reliable, Memory Speed Storage for Cluster Computing Frameworks》
设计目标
Alluxio的前身叫Tachyon,后来改名的。
Tachyon是一个分布式文件系统,对于跨集群的计算框架,可以提供可靠的内存级别的数据共享。
缓存可以提高读取效率,但写需要依赖网络复制、或者写磁盘来达到容错。
Tachyon使用了血缘关系这种技术,将其写入到存储层,来消除这些问题;基于血缘关系存储时,如果长时间运行那么一旦出错,想要快速恢复是个挑战。
Tachyon使用了checkpoint来解决这些问题,可以控制恢复的时间,在资源调度时,提供了重计算时的资源分配策略。
在评估中显示出,Tachyon比使用内存的HDFS写数据时候快了110倍,对于端到端的工作流延迟也提高了4倍,Tachyon目前已开源并部署到多家公司。
介绍
在过去几年,业界在大规模数据并行处理方面做了很多工作,让性能、复杂度都有了很大提升,也推出了各种编程框架、适用于各种工作服在的存储系统。
由于许多系统的瓶颈是I/O,那么自然的想法是将数据加载到内存中,来提升它的性能。 cache确实可以提高读性能,但对于写性能帮助不大,因为并行的系统需要提供容错能力,为了实现容错数据就需要跨节点的复制。
对于写请求,即使是基于内存的复制也会带来很大的性能下降,因为跨节点复制会有延迟、也有吞吐量限制,比本地内存要差太多。
对于job管道任务,缓慢的写请求会导致巨大的性能下降,一个job需要消费另一个job的输出,管道是由Oozie、Luigi等产生的。
比如执行MapReduce的提取任务、再执行SQL查询、然后在查询结果上运行一个机器学习算法,之后像Pig、FlumeJava、等编程语言接口会继续运行在多个MapReduce左右中,而上面的所有case,都会触发跨网络的数据复制。
为了提供写请求,我们推出了Tachyon,一个基于内存的存储框架,可以实现高吞吐量的读/写,而不影响容错,Tachyon通过血缘来避免跨节点复制,通过血缘关系重建执行操作来达到容错。
血缘这一概念在Spark、Nectar 、BADFS这样的框架中出现过,Tachyon是一个存储系统所以需要持续运行,那么相比之前的几个框架,会出现几个新问题:
- Spark、MapRecue的任务重新计算时间为单个任务的时间,而
Tachyon是需要持续运行的,那重计算的时间可能会无限长;前面几个框架通过checkpoint来避免复制问题,但存储层并不知道job的数据语义(比如 输出被重用时),job的特征可能也各式各样;如果数据写入速度 比磁盘带宽快,那么固定间隔的checkpoint可能导致恢复时间无限长,而根据血缘图的数据结构来选择checkpoint可以控制恢复时间。 - 如何分配资源,如果某个job优先级很高,那么重新计算的时候就必须确保获得足够的资源(当集群资源满了);另外重计算时,也不能对现有的高优先级任务有影响。
Tachyon通过在后台持续的运行checkpoint,控制了重新计算的成本,解决了第一个问题。
对于哪个文件做checkpoint,以及什么时候做,我们提出了一个边缘算法,不管计算负载是什么样的,这种算法的花费的时间上限都可以确定。
为解决第二个问题,Tachyon基于job优先级提出了资源分配模型,有两种分配模型:
- 严格的优先级
- 加权公平共享
比如,在严格优先级调度的集群中,如果一个低优先级job缺少必要输入,那么会最小化重这个job的重算资源,以便对高优先级的影响降到最低。
如果之后又有一个高优先级job有没有必要输入,那么Tachyon会自动增加其重新计算时的资源分配,这样避免了高优先级job被资源倒挂。
我们用一个通用的血缘规范API实现了Tachyon,它可以用于目前大部分流行的并行计算框架中,如MapReduce和SQL,我们还将Hadoop和Saprk移植到Tachyon上面。
该项目已开源,有来自15家机构的40多位开发者贡献了代码,Tachyon超过内存级Hadoop 110倍的写吞吐量,在真实的端到端环境中,延迟是内存级别Hadoop的 1/4。
由于计算集群中很多文件都是临时的,在checkpoint之前就被删除了,Tachyon可以减少 50%的网络复制开销,根据 facebook 和bing的研究,Tachyon重新计算的的开销大约占总资源的 1.6%。
更重要的是,由于带宽的限制,想让集群存储系统的性能达到内存计算的速度,基于血缘恢复的方式可能是唯一一种选择了。
这样工作的主要挑战是解决上面那些问题,使得这样的系统是可行的。
背景
本节将介绍我们的工作目标,以及现有方案的背景。
目标工作点
我们根据当前的大数据环境,设计了Tachyon,他有下列特点:
- 数据不可变:一旦写入就不可变了,如占据主导的HDFS只支持追加写
- 确定的job:像MapReduce、Spark都是用重计算方式来解决容错问题,同时也要求用户代码是确定的,我们使用的血缘恢复方式也基于同样的假设,对于不确定的框架,仍然可以复制的方式将数据存储在
Tachyon中 - 本地化调度:很多计算框架的作业调度都是使用本地化,这样可以最大限度减少网络开销
- 所有数据vs工作集:整体数据量很大,只能存在磁盘上,但工作集数据量并不大可以放到内存中
- 程序size vs 数据size:相同的操作反复的应用到了海量数据上,因此程序复制的开销 必定小于 各种情况下的数据复制开销
反对复制的理由
对于内存计算框架-如Spark、Piccolo,以及存储系统,都大幅度提高了job的执行速度;但对于频繁在job之间共享(写入)数据,则会成为瓶颈。
在现有的大数据解决方案中,写入吞吐量受限于磁盘,以及网络带宽,比如HDFS、FDS、Cassandra、HBase、RAMCloud。这些系统都使用了远低于内存的介质(table 1),这样做的目的是保证从容。
这些系统需要需要跨网络复制,至少写一份拷贝到持久存储设备中,用来避免数据中心级别的估值,如停电。
由于这些限制,以及内存计算框架的发展,job之间的数据共享导致端到端的延迟,job的输出明显小于他们的输入。
根据Cloudera的报告,跨5个客户端的job只有34%的情况下,输入和输出是差不多的,在内存计算框架中,job受限于写瓶颈。
| Media | Capacity | Bandwith |
|---|---|---|
| HDD (x12) | 12-36 TB | 0.2-2 GB/sec |
| SDD (x4) | 1-4 TB | 1-4 GB/sec |
| Network | N/A | 1.25 GB/sec |
| Memory | 128-512 GB | 10-100 GB/sec |
Table 1: Typical datacenter node setting
硬件的发展也解决不了这个问题,内存的带宽是磁盘的三个数量及之多,而且这之间的差距还在增大。
SSD的出现也解决不了此问题,因为主要的影响是磁盘的随机访问,而不是顺序访问,随机访问是大多数数据密集型应用所需要的。
网络吞吐量的增长说明了基于内存的复制时可行的,然而要保证数据中心的高可用,需要至少一份的磁盘拷贝,为了实现高吞吐量又要实现容错,那就必须放弃复制这个选项。
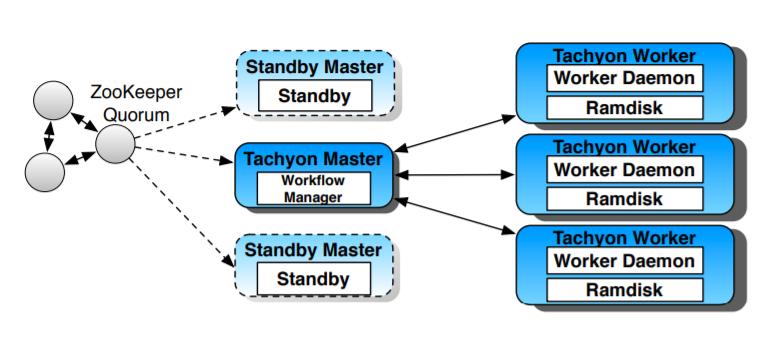 Figure 1: Tachyon Architecture.
Figure 1: Tachyon Architecture.
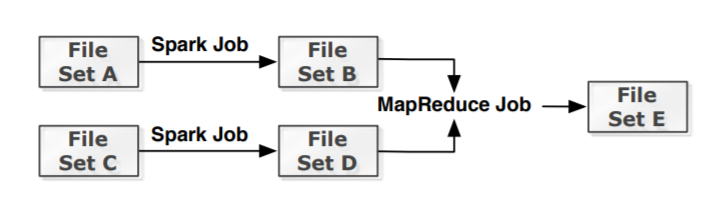 Figure 2: A lineage graph example of multiple frameworks
Figure 2: A lineage graph example of multiple frameworks
设计概览
Checkpointing
资源分配
实现
评估
相关工作
局限性和未来计划
结论
随着越来越多的数据中心工作负载出现在内存,对应的写吞吐量成为主要瓶颈。
因此,我们相信,想让集群存储系统达到内存级别的吞吐量,基于血缘的恢复方式是唯一的选择。
我们提出了Tachyon,一种基于内存的存储系统,包括一系列的血缘关系加速部分重要的任务(如批处理任务)恢复
基于基于血缘可能是唯一一种,能让集群存储系统达到内存级别吞吐的方式。
通过找到Tachyon的关键问题,我们的评估显示了Tachyon可以提供一种解决方案,帮助现有存储系统加速。HDFS社区也采用了我们类似的方案,在集群上高效的使用内存。
我们将Tachyon开源了,可以将其使用在真实的环境、或研究平台上。有超过15家公司、40多个人为我们的项目捐款。