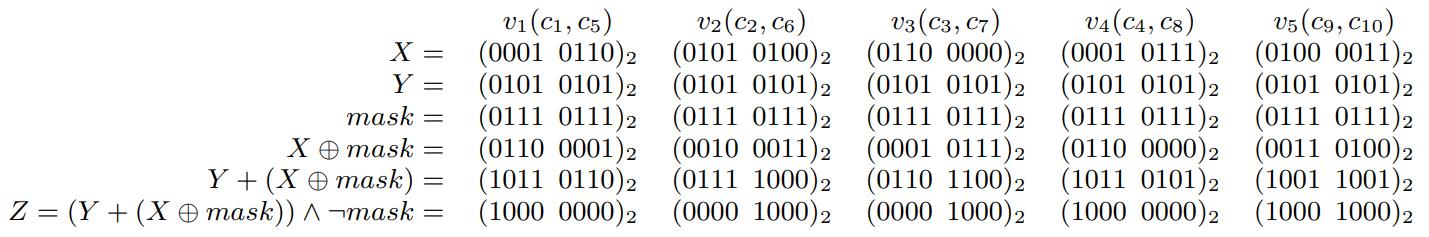2023年6月1日
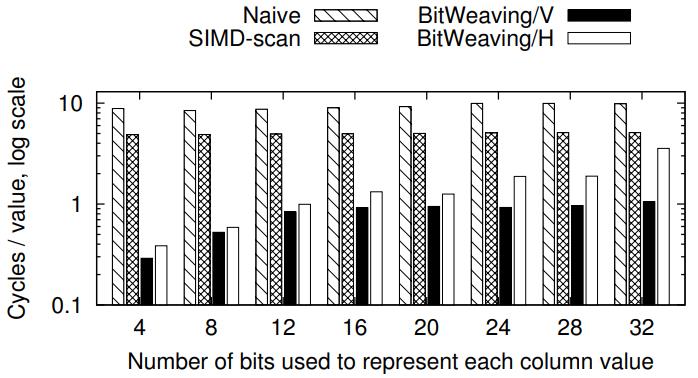
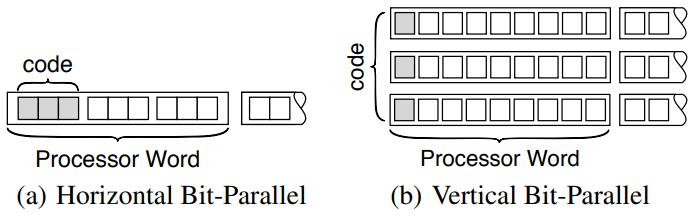
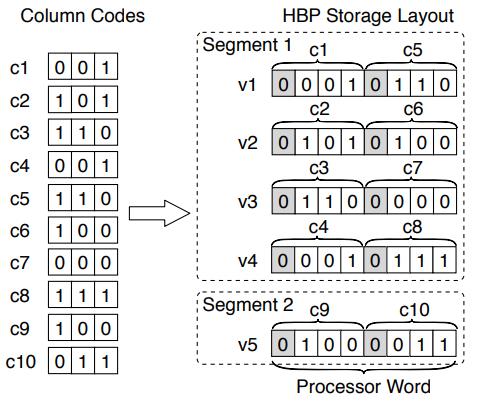
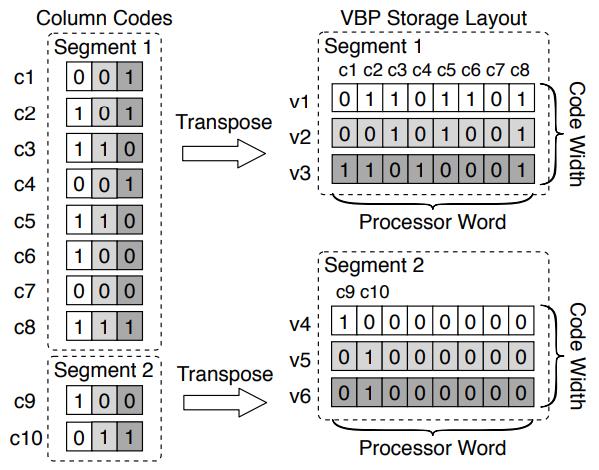
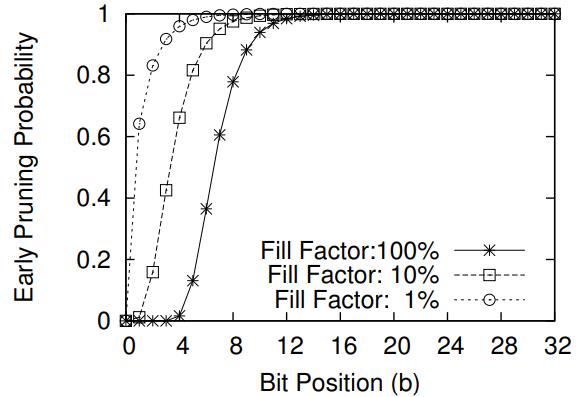
基于主内存数据库的 scan 优化,提出的技术:BitWeaving,又分为两种:BitWeaving/V 和 BitWeaving/H;BW/H 相当于是bit 级别的水平分布,将列的数据水平的分布到不同segment 中,通过亦或、以及各种位运算技术,实现了 =、!=、<、<= 的比较操作,比较完之后,每个process word 分隔符bit就会被设置为 1 或者0,然后将上下四组分别做不同的位移在 or,就能得到最终结果;BW/V 实现bit 级别的列存储,一列数据将每个数据的第一个bit存到 process word v1中,第二列存到 v2中,按照这种分布就可以实现早期裁剪,SIMD 再进一步优化,他的scan很快,但是查找需要跨多个processor word,相当于是垂直的从左往右计算,性能会 BW/H要差;而对于 VBP,其真实数据布局可以再优化,比如原先 9个processor word 一个segment,变成一个segment 3个 bit group,每个bit group 3个 processor word,这样做 cut-off的时候可以不用再加载斗鱼的processor word,节省了内存带宽,减少cache miss;从性能对比看,BW 技术在scan方面是最好的,SIMD有打包和对其开销所以效果远不如 BW,而BW 存在选择 BW/V 和 BW/H 布局的问题,也是待研究的问题
阅读全文
2023年5月28日
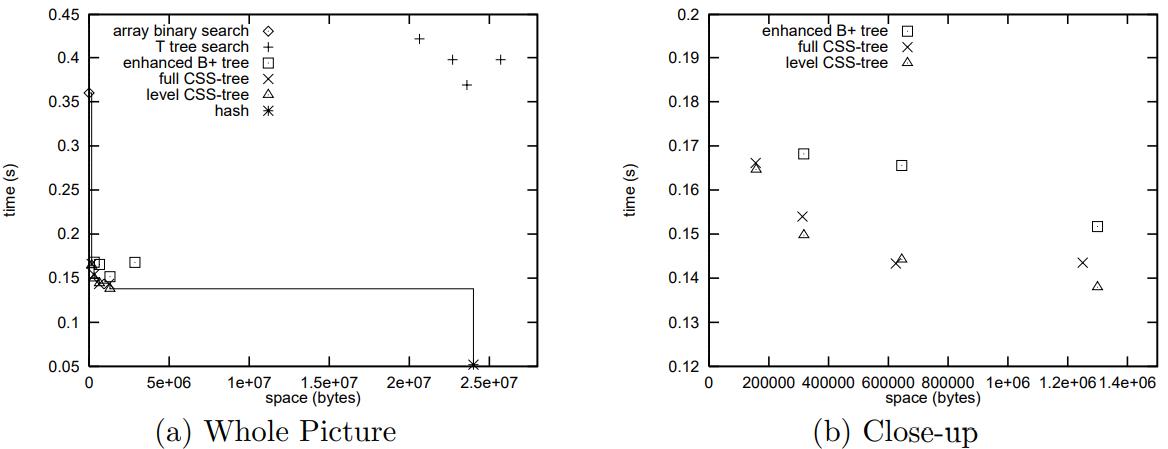
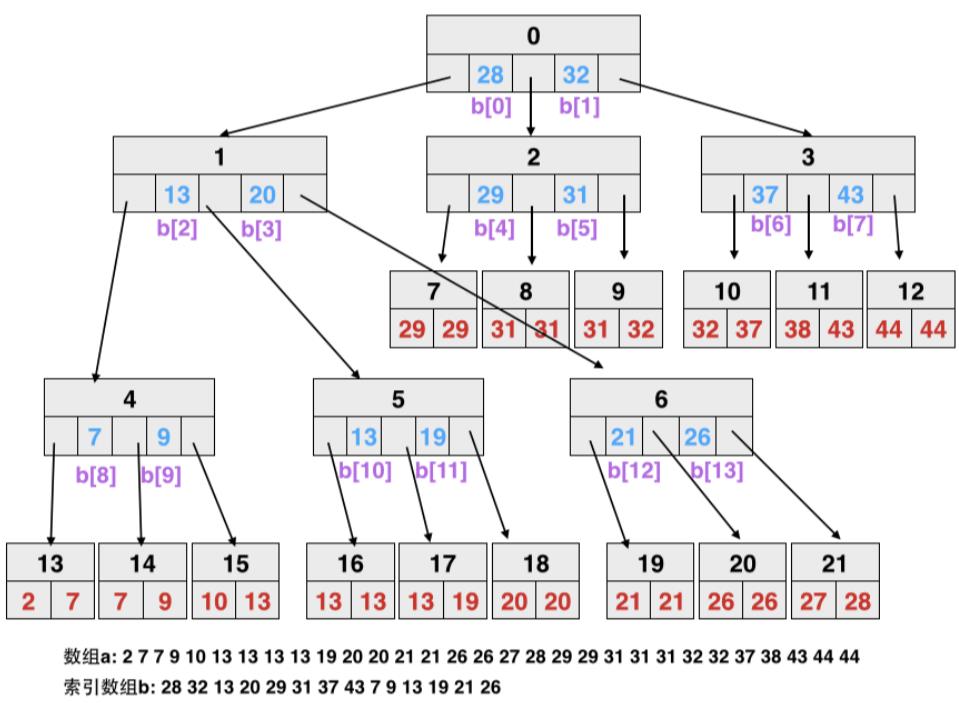
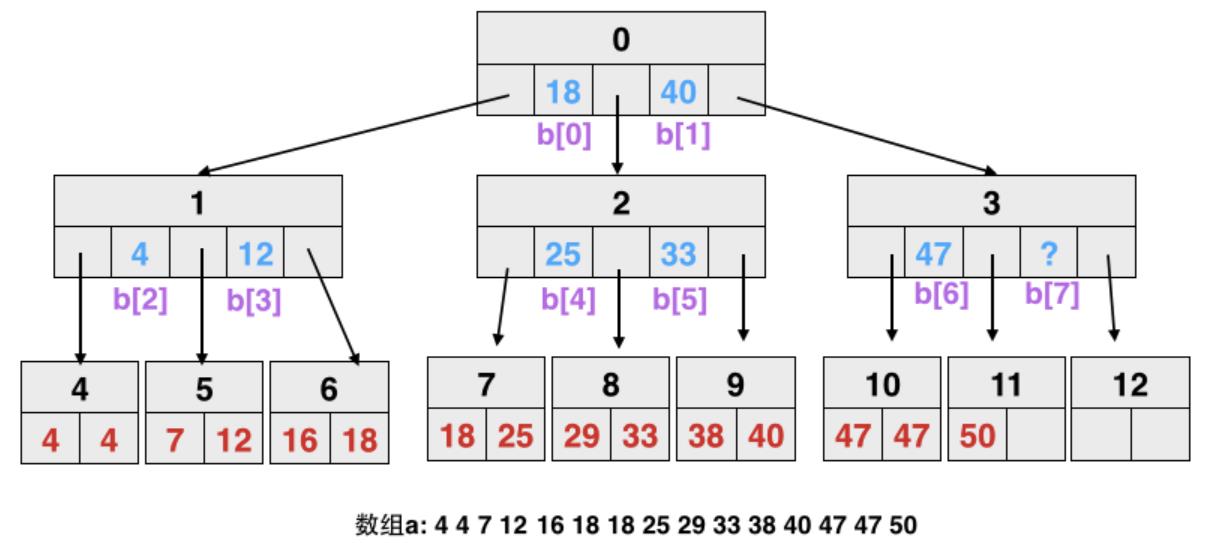
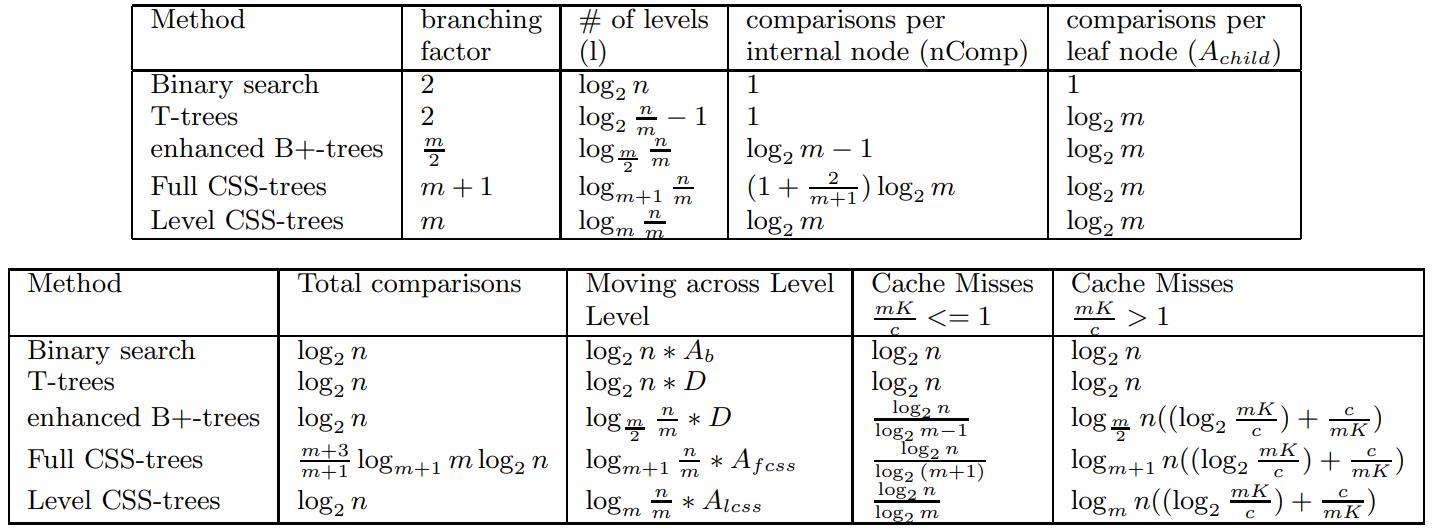
对于主内存 OLAP 场景,提出的针对 cache有效性的优化,如果排序数组远大于 cache line,则二分查找的 cache miss 是很严重的,基本每查找一次就有一次cache miss;T树 看起来是缓存友好的,但每次查找只有 min、max做了匹配,仍然会有很大的 cache miss,B 树虽然是面向磁盘的,但有多个子节点,一次可以做多个匹配,所以cache miss 比 T 树更好一些,hash index需要占用大量空间,当然二分的好处是不用空间;在这些基础上论文提出了针对cache line的 CSS树(Cache Sensitive Search Trees),他在排序数组基础上,增加了一个字典数组,使得整个树可以被平铺,有点像 树堆,不过它的节点有多个,个数一般跟 cache line有关,它没有子节点指针,而是用数组下标来代替,这样一个 node 内可以放更多的数据,查找起来的cache miss就会小很多;值得注意的是类似满二叉树,CSS树的字典指向的排序数组其 part-1、part-2整合跟正常排序数组是相反的;从测试结果看CSS 树的表现也不错,随着CPU和内存差距越来越大,CSS树可能会变现的更好
阅读全文
2023年5月26日
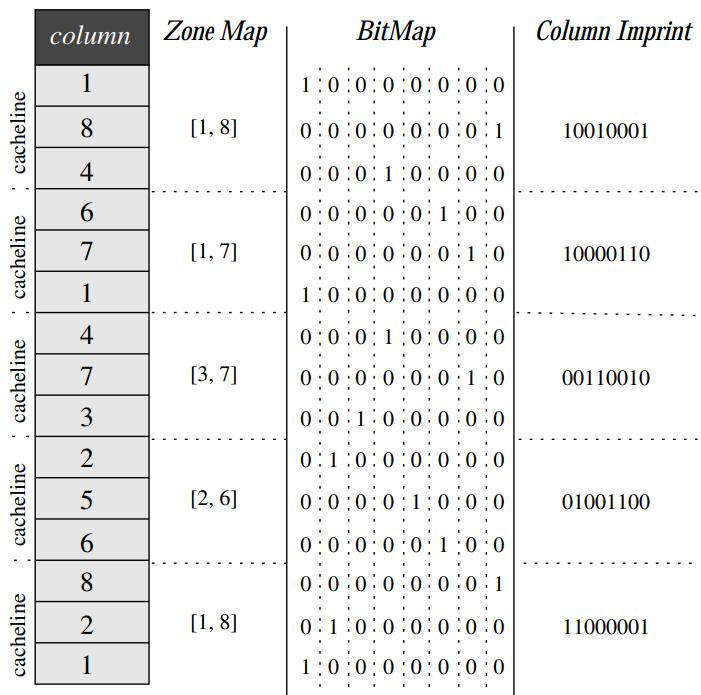
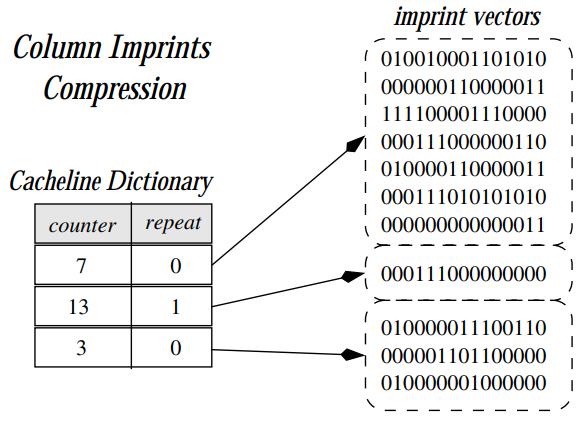
针对主内存数据库,提出了一种轻量级二级索引技术:imprints column,它是属于bit 向量索引家族的,zone map对于随机值正好落在min、max内的查询就无效了,仍然需要扫描,而 bit map占用的空间更大,imprint 则综合了这两者的优点,它是基于cache line做bit向量分组的,对CPU更友好,而且将一个cache line内的值统一合并为一个bit向量,占用空间更小;通过 counter 和 repeat标志位,可以实现imprint 的压缩,论文中给出了相关的压缩、查询算法,由于是针对读场景的设计,更新主要是append和索引重建;通过实验对比,imprint 对于数据分布随机和有规律的场景,表现的都很好,索引压缩效果不错,压缩后的索引占比看 imprint最少,zonemap也差不多,WAH最高;查询性能看,三个索引基本差不多,imprint略好一些,时间上imprint也略块一些,但随着选择率上升几个都趋同;总体看随选择率上升也跟scan 差不多,但是对于熵低/高的场景表现都比较稳定
阅读全文
2023年5月24日
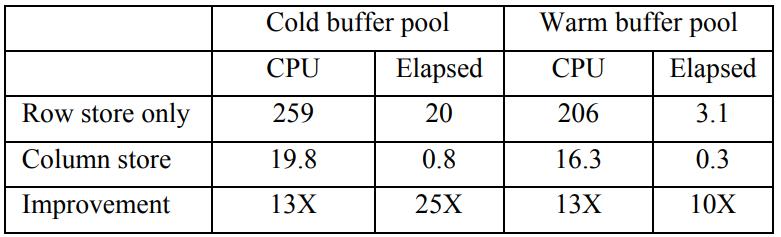
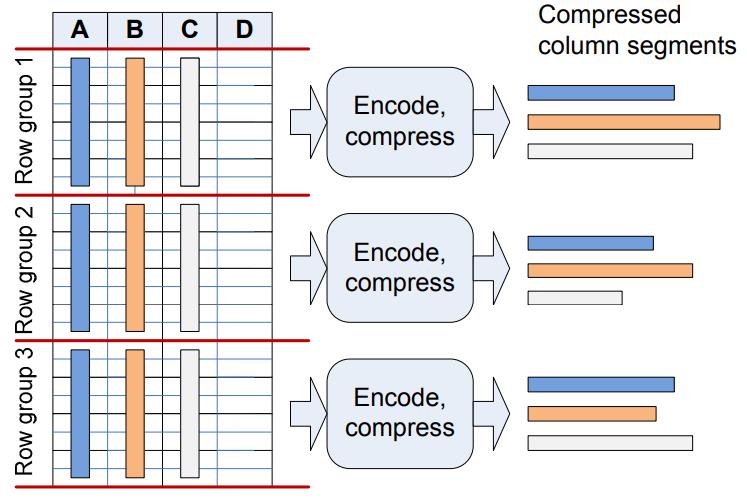
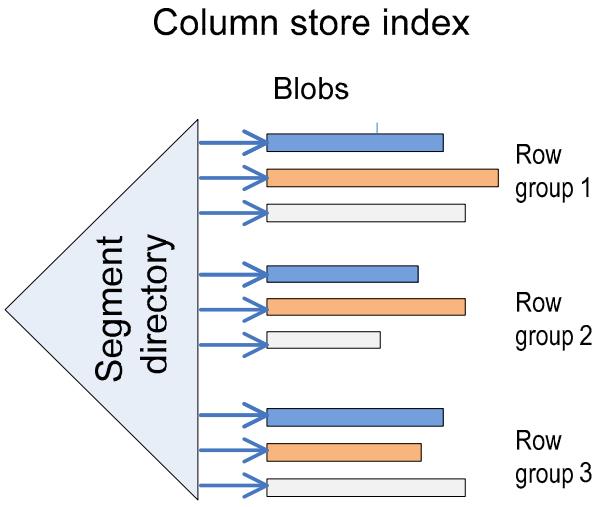
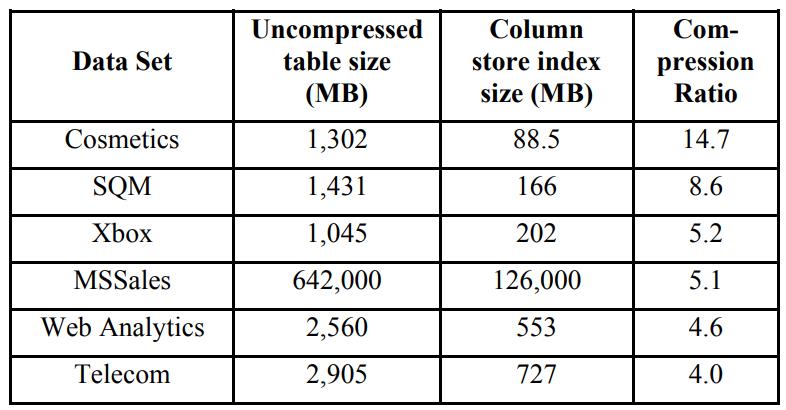
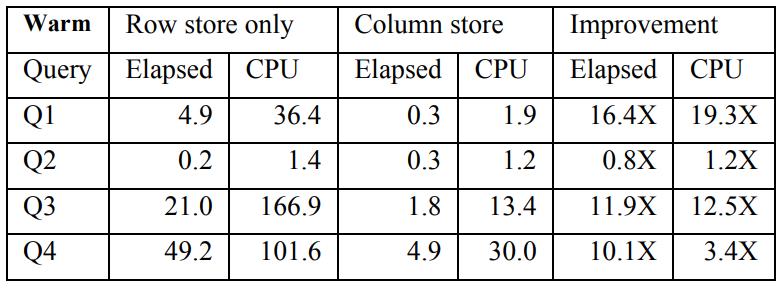
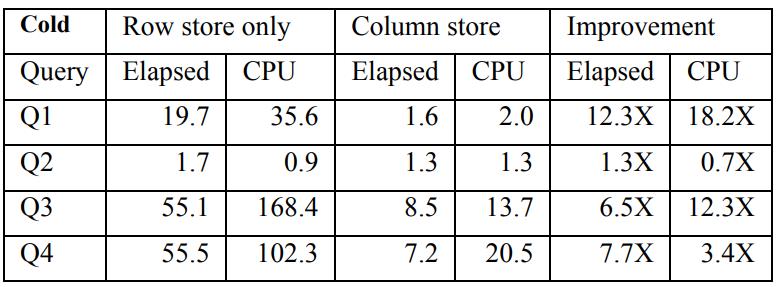
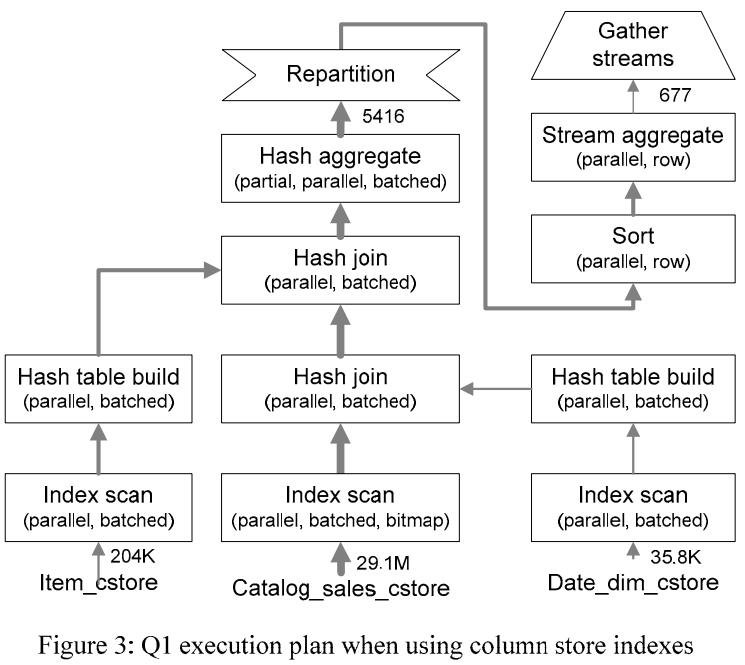
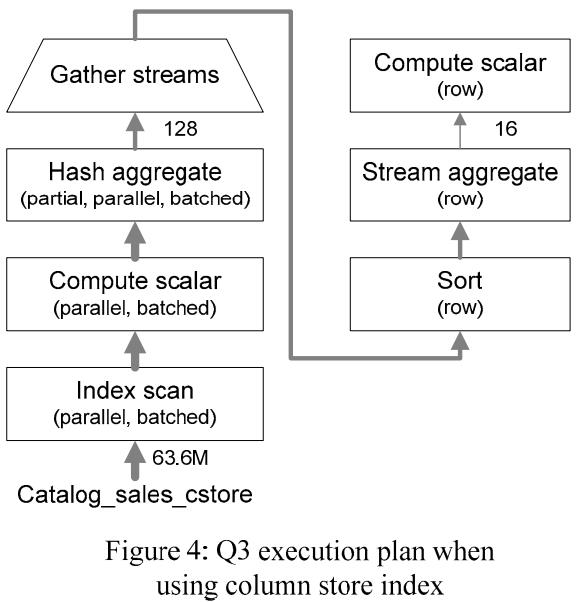
《SQL Server Column Store Indexes》:SQL Server 11代 Denali,在行存系统上增加了列存和索引结构,这些改动并不是重新来一套,而是基于现有技术的改进,如对行做了分片segment,每个 row segment 再根据 column 进一步细分为 column segment;column segment本身是现有的 blob存储,同时还利用了压缩技术,基于 column segment 又开发出了 segment directory,这个 directory包含了一些元信息如行数量、size、多少数据被编码了、min和max等,这些改动之后,还可以跟现有的lock、log、recovery、patition、mirror、replication完全兼容整合;之后查询引擎部分也会做一些改动来兼容行、列数据,这里使用了多核、bitmap filter、算子间的内存共享、SIMD等进一步优化,根据代价模型评估,选择合适的索引,测试TPC-DS时,前面大部分数据都是批的方式处理的,而且做了并行化,只有最后的聚合、重分区是用 行模式处理的,最后效率大幅度提升
阅读全文
2023年5月22日
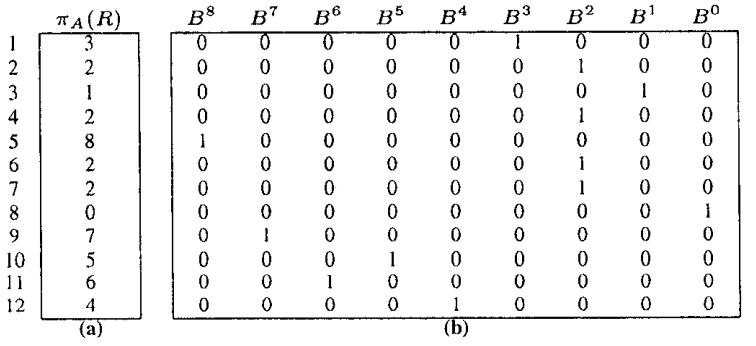
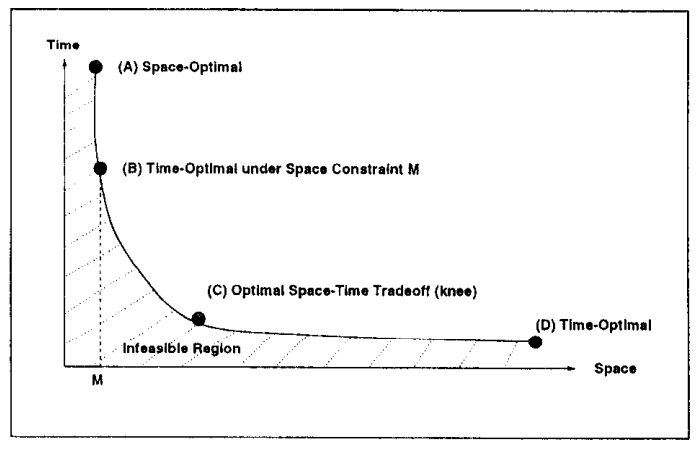
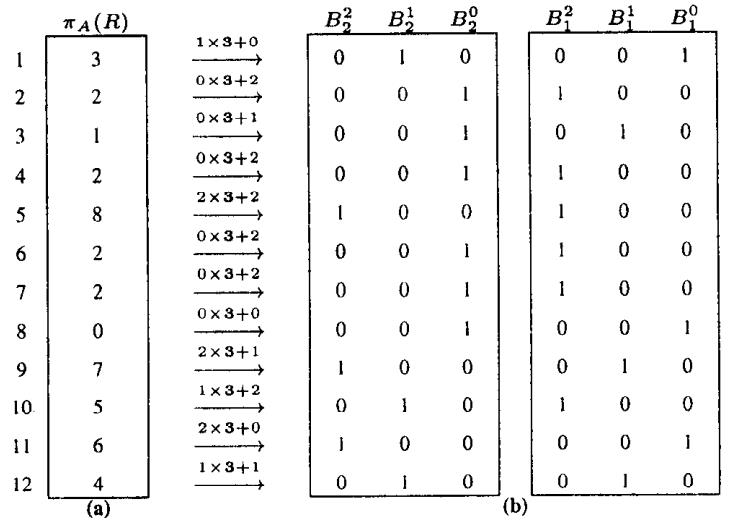
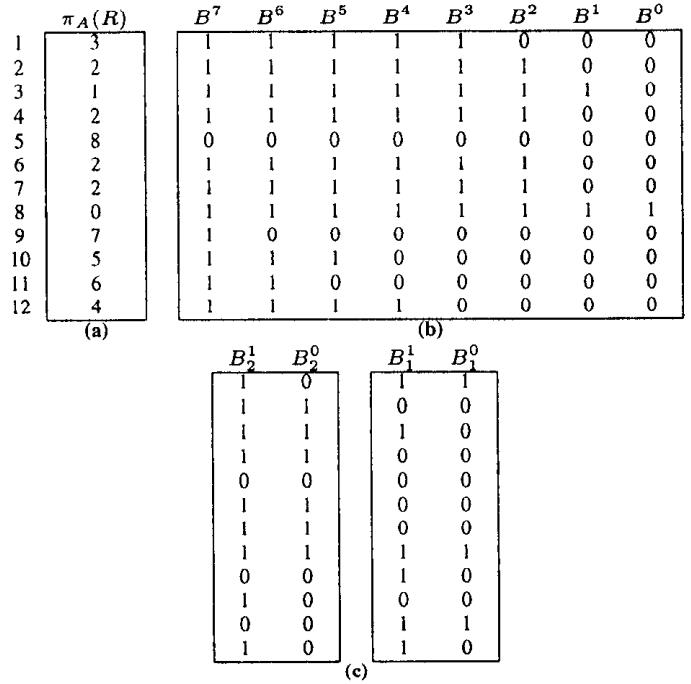
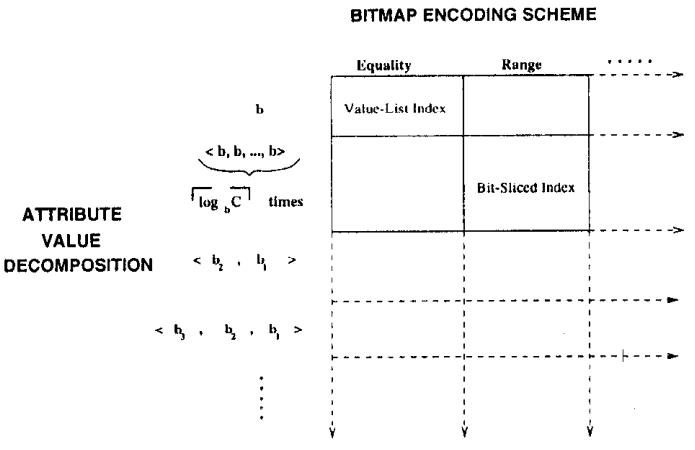
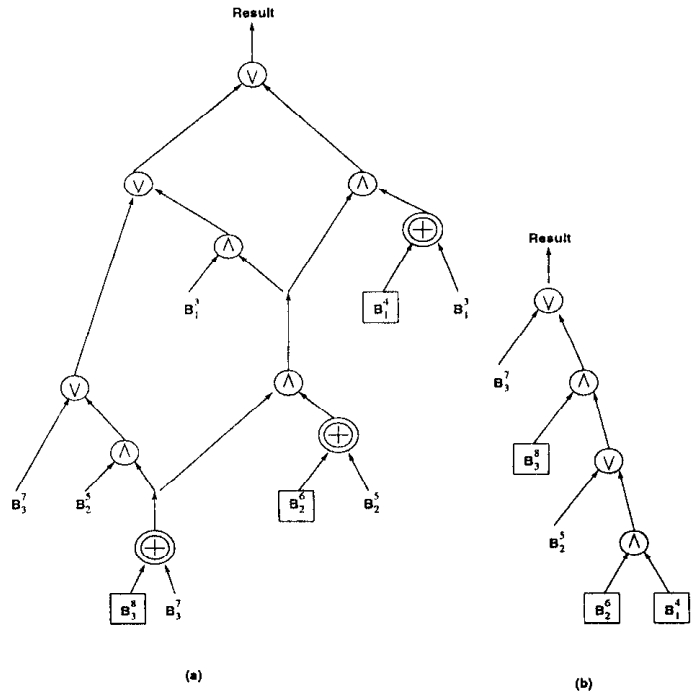
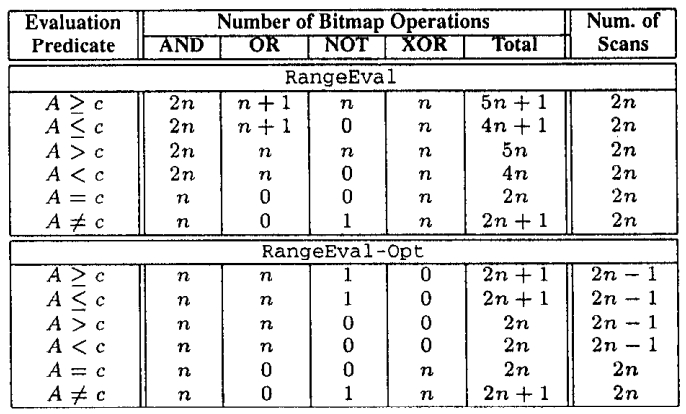
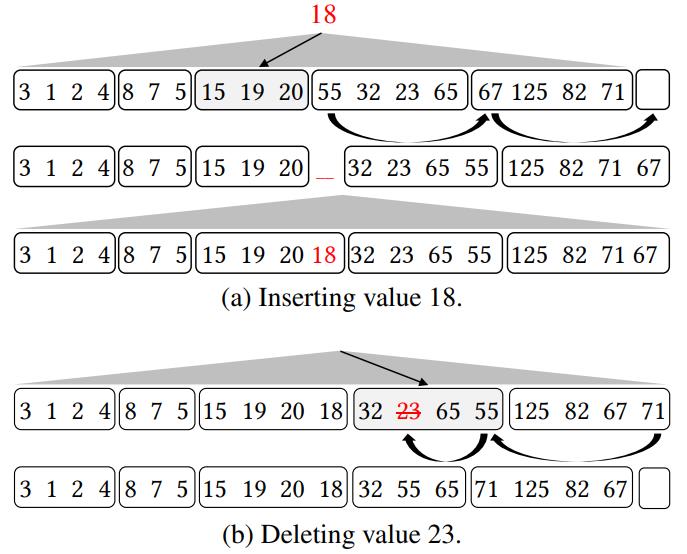
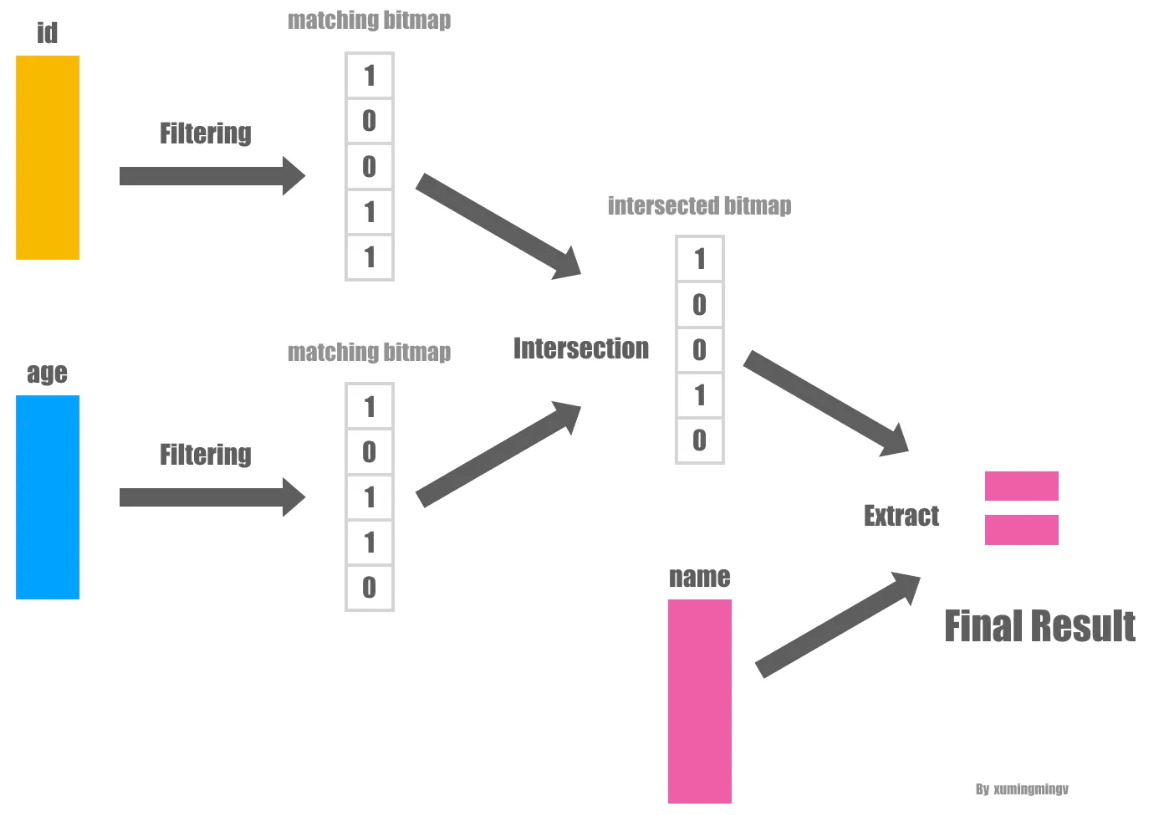
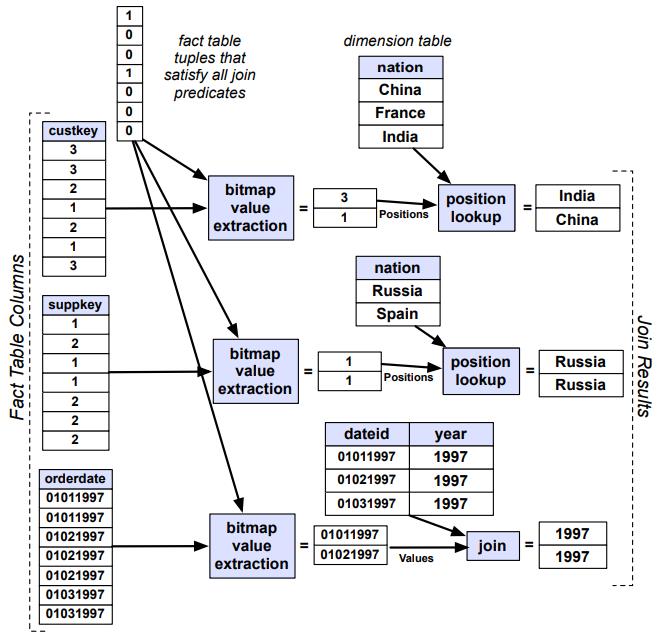
针对 bitmap 索引提出的一系列指导设计建议,传统方式对于带谓词的查询,一般是:全表scan、B树 索引、每个谓词做scan然后merge;使用 bitmap 后采用第三种方案效果最好,论文中提出了四种时空权衡:空间最优、时间最优、基于空间限制下的时间最优、时空权衡; 在大量数、数据基础范围较小的情况下使用 bitmap 索引效果很好,而 bitmap 可以采用 基于范围的、基于等值的;基于范围的相当于 Value-List set,在这种场景下继续拆分,如基于<3,3>的Value-List,其空间比原始的更小;论文中提出了对 Algorithm RangeEval 改进的 Algorithm RangeEval-Opt 算法,需要处理的谓词更少,只需一次扫描;论文指出 范围编码的时空权衡效果更好,之后又对比了压缩的情况,buffer的增大,对于时空权衡也有帮助
阅读全文
2023年5月21日
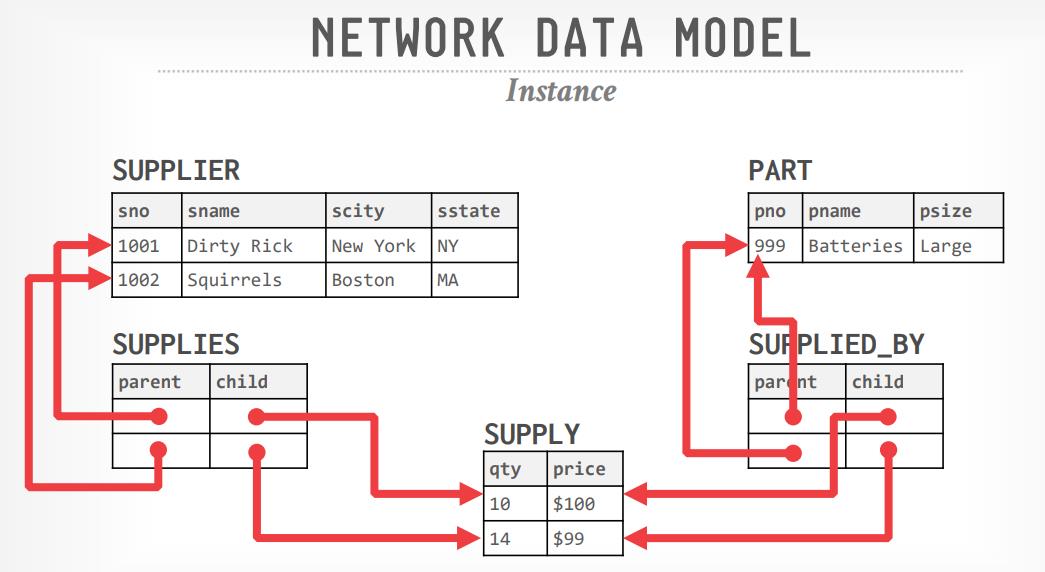
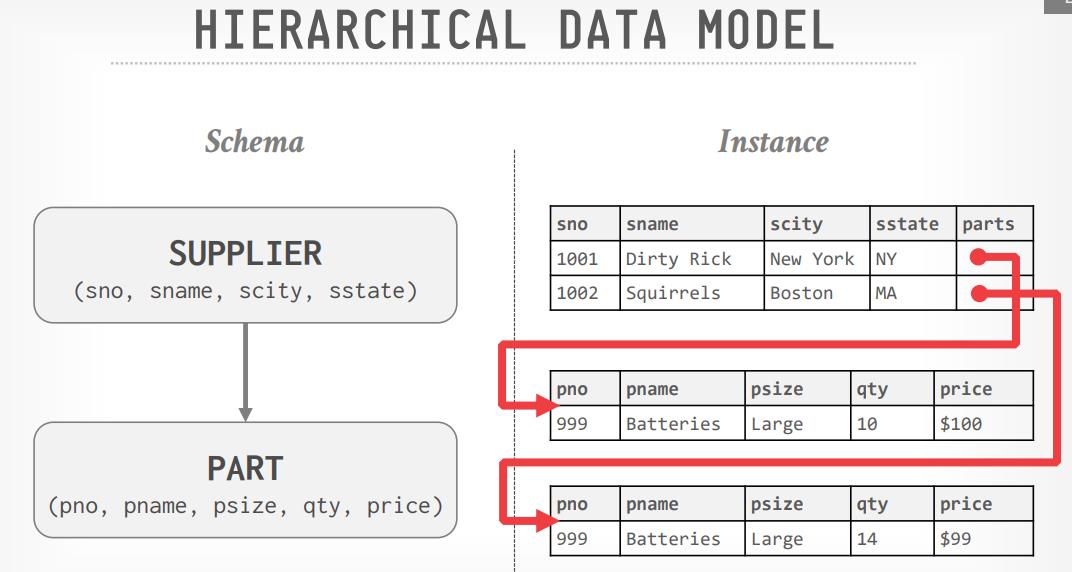
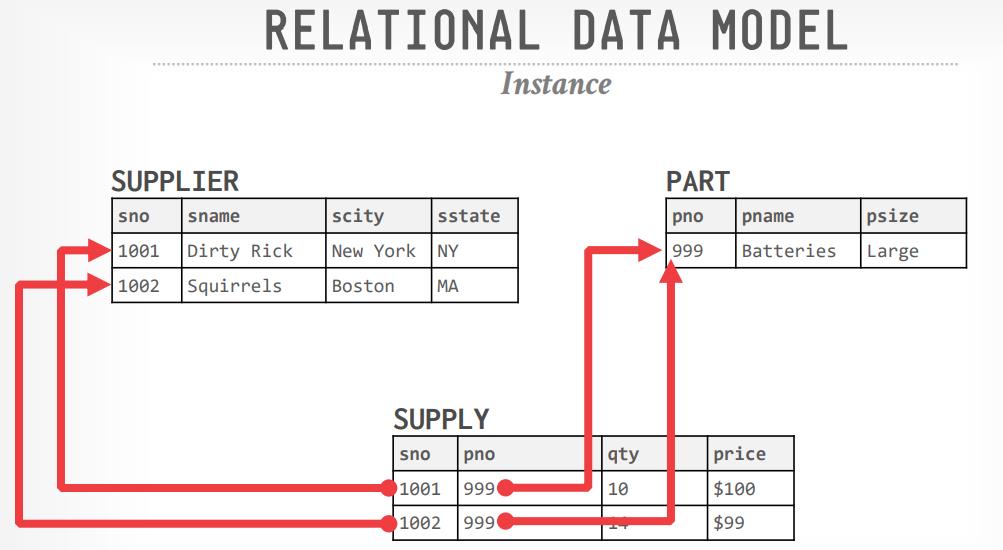
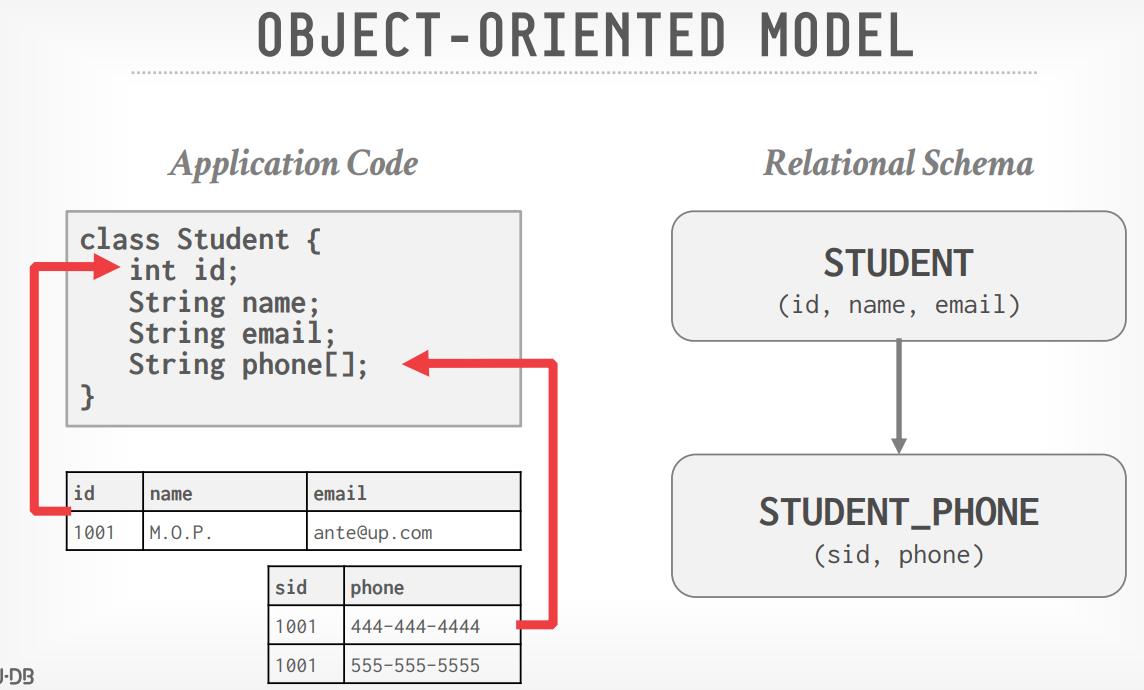
数据库的发展历史,从复杂模型:网络模型、层次模型,再到简单的关系模型最后胜出,关系模型不止是简单,而且提出了物理、逻辑解耦、高层级别API;所以从1970年代开始,数据库的基本模型,发展方向是定了;后面出现了各种对关系模型的补充,但是大多数只是重复发明,除了code in database,schema last是比较新颖的发明;在这几十年内,商业数据库一直是主导,IBM、Oracle、微软一直是领导者;直到2000年互联网的出现打破了这个局面,数据库面临大量的访问,需要购买大量商业数据库成本太贵,此时开源产品就是更好的选择;同时也出现了各种对关系模型,他们的扩展性、性能都非常好,但他们不支持SQL、不支持事务,十年之后再看这些数据库多多少少都有一些局限性,于是分布式的NewSQL出现,加上云厂商的对象存储,云上数据库也成为主流;现在数据库有很多细分市场,每个主题内都有好几个玩家,这些数据库在巩固自己领地的同时,又在不断扩展自己的能力;他们开始支持SQL,增加事务,从历史角度看,声明式语言、解耦、简单模型一直是有生命力的
阅读全文
2023年5月17日
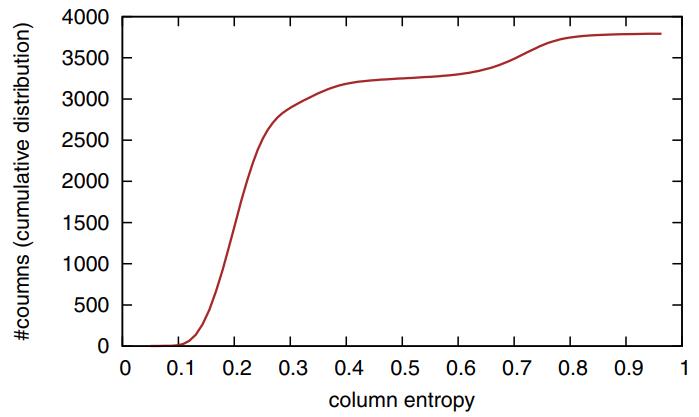
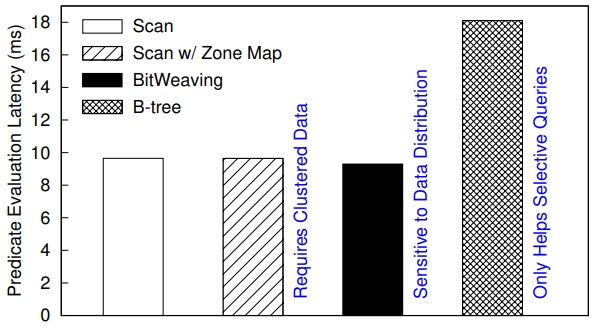
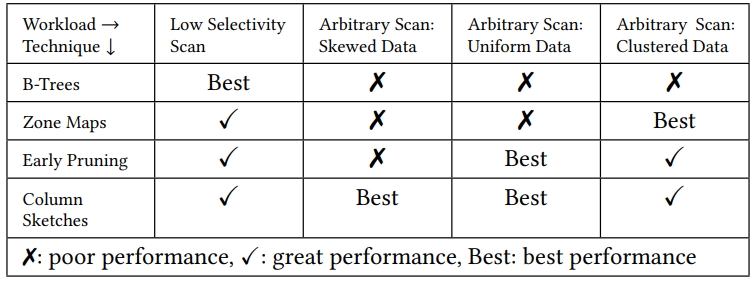
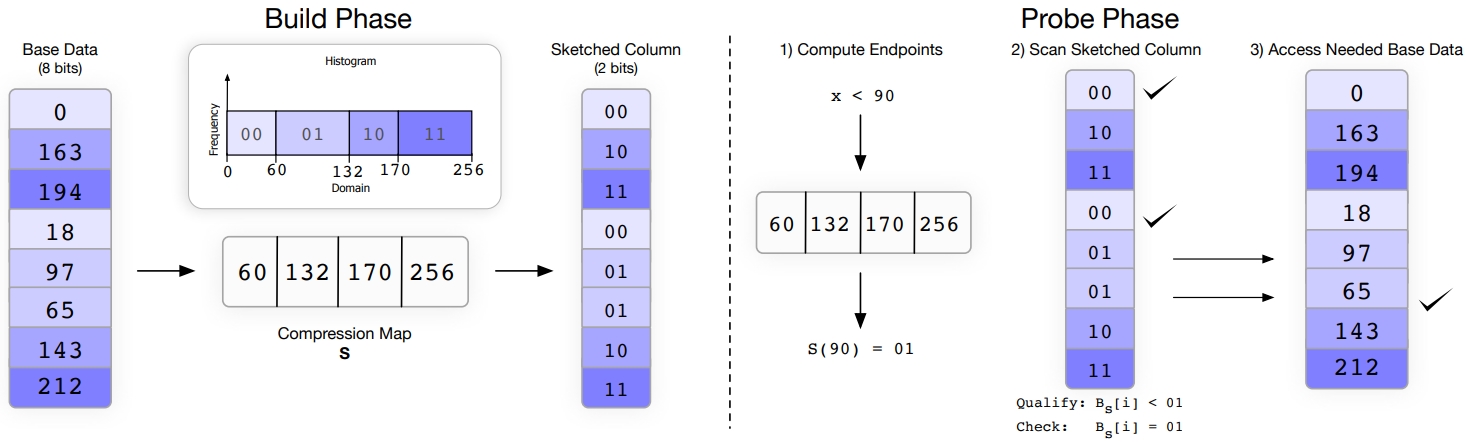
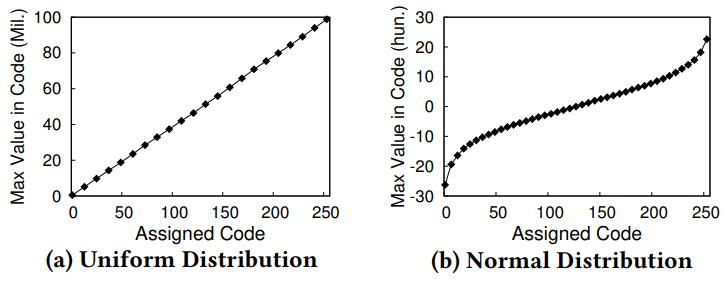
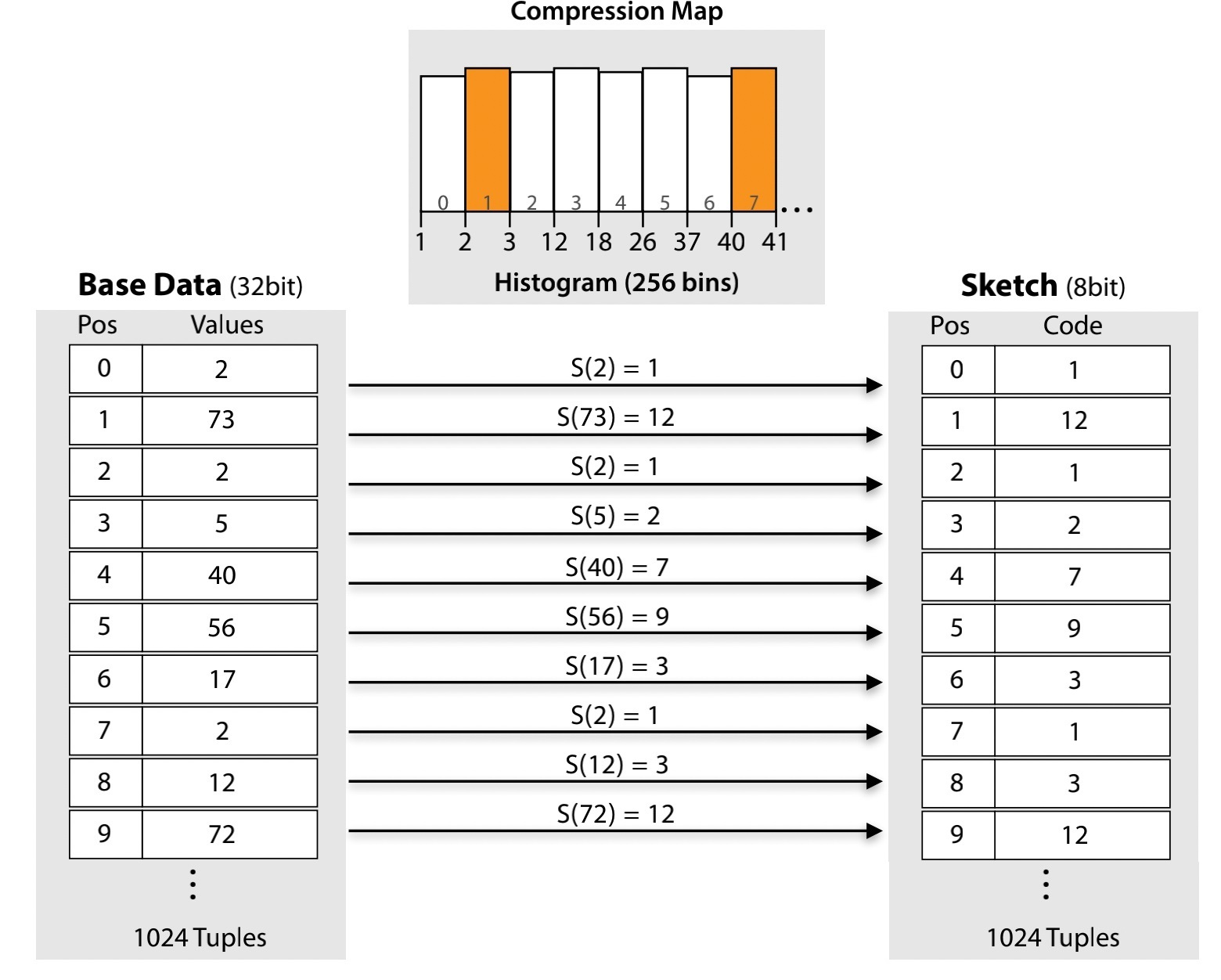
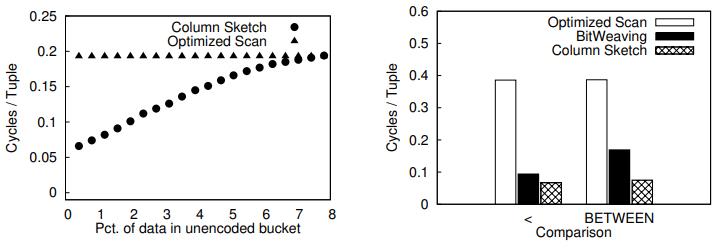
B数索引 对于选择率低时效果很好、但选择率一旦上升性能就不行了;轻量级索引 Zone Map、Column Imprints、Feature Based Data Skipping对数据聚集性有要求;早期裁剪 ByteSlicing、Bit-Slicing、Approximate and Refine 在数据倾斜情况下,高位可能都是重复的效果不好。Column Sketches使用直方图统计列数据分布,同时考虑了频繁值和普通值,之后建立映射函数,将频繁值映射成唯一code,非频繁值均匀分布,通过这种映射之后,数值类型的 原先 8bit 的值,映射完只需要 2bit 就可以表示了,对于频繁唯一值也不需要回表检查进一步加速;对于分类型也是类似方式,只是不需要排序,可以直接映射。对比其他方案,Column Sketches在选择率高/低,L1 miss,tuple处理速度,数据倾斜,鲁棒性,数据加载上都很不错;Column Sketches还可以利用 SIMD加速scan,可以跟现有技术做整合
阅读全文
2023年5月13日
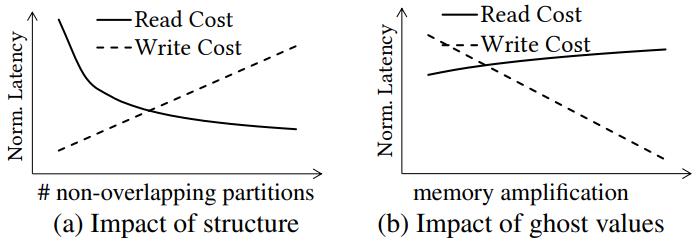
基于 HTAP 场景的列布局优化,仍然使用列布局,但是对列做水平分区,一个分区内包含多个 block,每个block 的大小是 CPU cache 的数倍,这样更好利用CPU;每个分区根据是否为边界(0 或 1 表示),输出为一堆的 bit范围,这是一个 NP hard问题,也有相关研究可以解决此问题;工作负载包括:点查询、范围查询、插入、删除、更新;每种场景对应底层 I/O 包括 随机读、随机写、顺序读、顺序写,不同场景对于 block的访问频率也是不同的,论文给出了 10 种统计的直方图;之后收集各种负载的 block 访问情况然后离线分析,再将分析后的结果优化,输出为一堆bit,这样就可以动态调整分区,达到了自适应的效果;从性能分析结果看,可以适用于各种场景,除了读基本不变,其他场景都有大幅度提升,同时吞吐量也保持不变
阅读全文
2023年5月7日
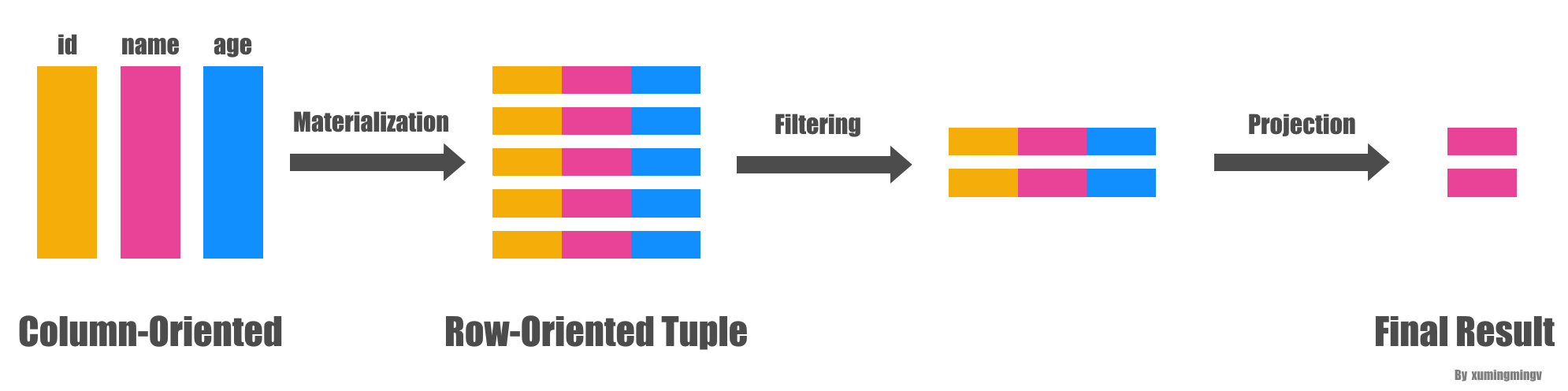
《Column-Stores vs. Row-Stores: How Different Are They Really?》论文中通过行存系统来模拟列存,并将几个可能提升的关键点:延迟物化、块迭代、压缩、invisible-join,挨个拆分,并分析每种可能提升的原因和提升比例‘在行存的系统中使用垂直分区依然达不到列存性能,因为垂直分区后需要冗余存储主键,重建这些tuple 需要hash-join,数量大内存CPU开销也大;全索引如果返回的数据多hash-join压力大可能会更慢,反之可能更快;物化视图最好只需要读取部分数据,bitmap选择率高时效率会变差。对于列存:块迭代可以提升5% - 50%性能(取决于压缩)、invisible-join可以提升50% - 70%、压缩为2倍,如果数据有序可以量级提升、延迟物化提升3倍,如果将这些全部去掉,列存跟行存就差不多了;在列存中使用反规范化大宽表效果不好,增加维度表列冗余数据变多、只有大宽表的维度属性是排序高度压缩的才有效
阅读全文
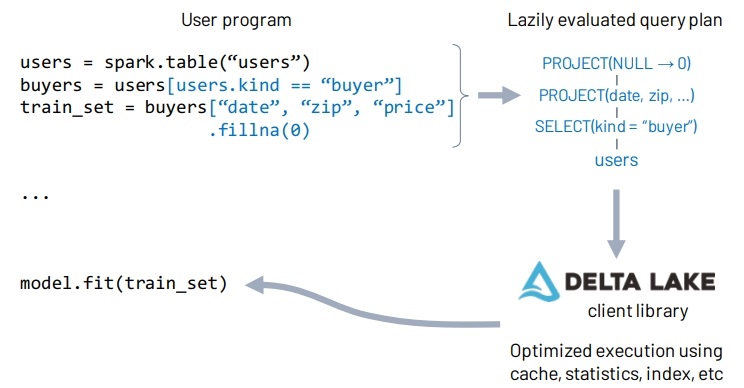
2023年5月6日
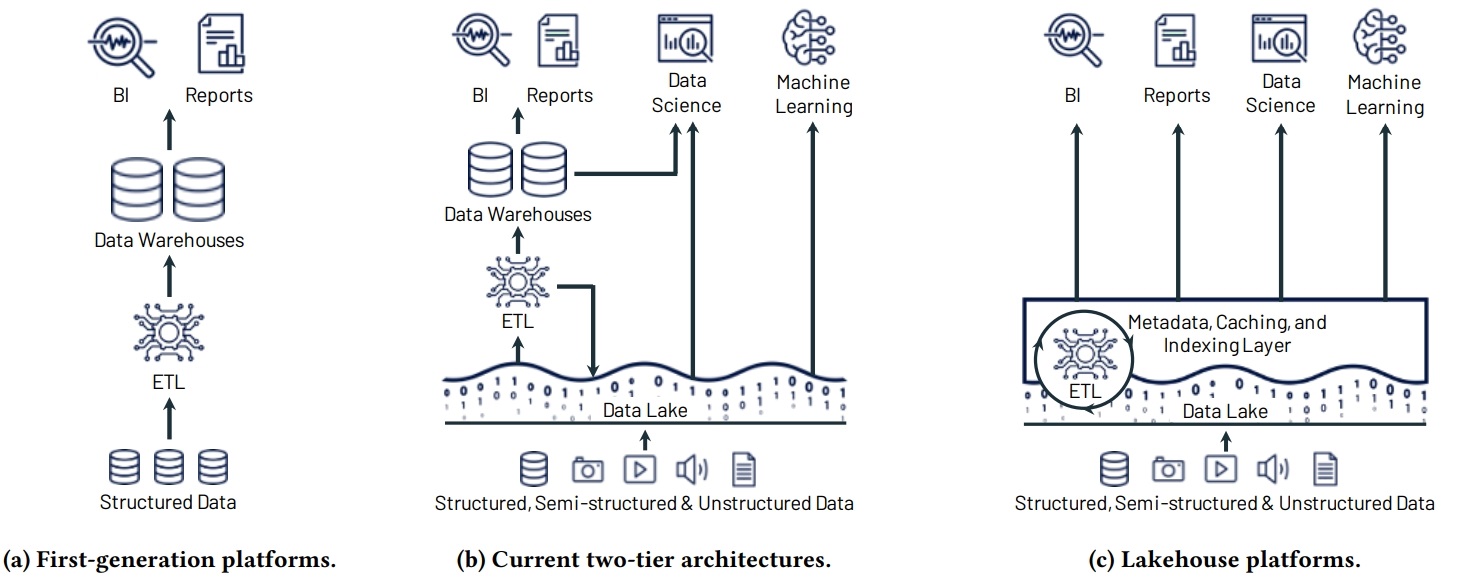
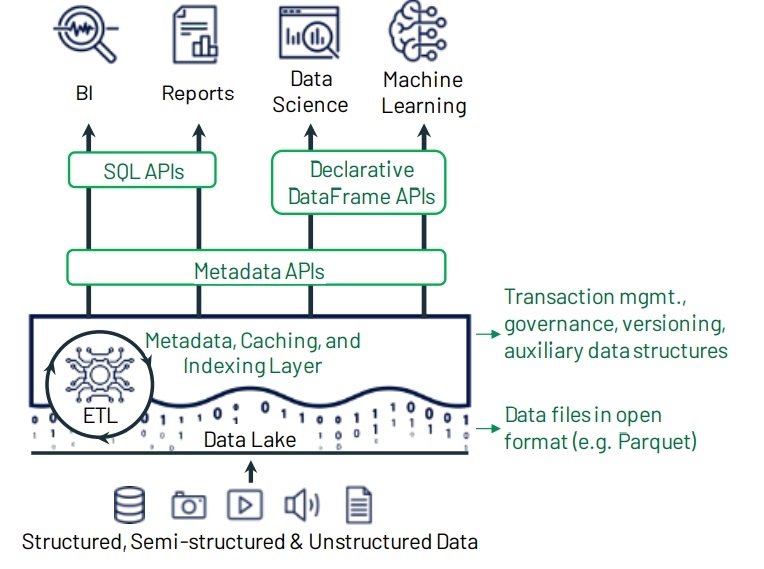
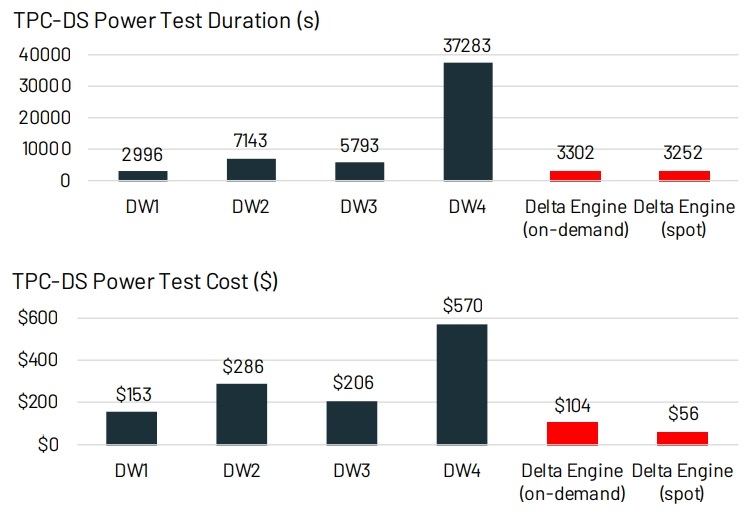
第一代的数仓有很好的数据治理,缺点是计算存储耦合,且无法存储半结构数据;第二代的数据湖将计算存储分离,且能存储各种格式,云厂商推出的对象存储本质是差不多,不过扩展和可靠性更高更便宜,但二代需要两套系统,数据要在数仓和对象存储之间做ETL,有很多问题;而LakeHouse则试图解决这些问题,通过在对象存储之上增加元数据管理,实现事务功能,数据质量、ACID都实现了,因为是基于开放的格式,不会锁定厂商,也能支持各种场景。因为开放的格式和对象存储的延迟问题,性能和每秒事务不会很好,通过缓存系统、辅助数据结构、数据布局优化来优化性能,另外DataFream 支持SQL和 API,可以延迟处理这样可以进一步优化。目前的限制:S3的延迟、单表事务、servless;通过TPC-DS对比其他云厂商的数仓,性能和价格都很不错,还能支持传统场景,机器学习、科学分析等各种复杂场景。
阅读全文