Spark论文
原文:
《Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing》
设计目标
RDD全称为Resilient Distributed Datasets
它主要为了解决两类问题:
- 多轮的迭代计算
- 交互式数据挖掘
谷歌发表的Pregel也是用于处理交互式计算的,不过Spark的处理范围比它更广。
论文中提到了,Spark提供了受限制的共享内存,基于粗粒度的转换,而不是细粒度更新。
RDDs provide a restricted form of shared memory, based on coarse-grained transformations rather than fine-grained updates to shared state.
对于多轮迭代(PageRank, K-means聚类、逻辑回归)、交互式分析,需要重复使用计算的中间结果,两个Map-Reduce如果想重用数据,就只能将数据写入HDFS,这个效率很低。
为了解决这些问题,后续出现了Pregel,用来解决多轮迭代的图计算框架,以及HaLoop用于解决迭代的Map-Reduce接口。
但是这些框架只是用于特定目的,而Spark想解决的,是提供一个更通用的抽象框架,用于可以数据集放入内存,然后执行各种ad-hoc查询。
RDD提供了容错的、并行的数据结构,可以显示的将中间结果保存在内存中,可以控制分区来优化数据的位置,还提供了一组丰富的操作。
现有的基于集群的内存框架包括key-value存储、数据库、Piccolo,他们提供了细粒度的更新,如操作表中的记录,他们实现HA的方式是跨节点复制数据、或者是跨节点的WAL,但对于数据密集型操作来说这又太重了,会有大量的网络拷贝。
RDD提供了一组粗粒度的操作(map、filter、join)。它只对数据集转换做记录,而不是真实的操作数据。如果RDD丢失了,根据已经信息重新计算即可,恢复起来也很快。
根据论文中的介绍,得出Spark的设计原因:
- 要解决机器学习、交互式分析多轮迭代效率低下的问题,传统的
M-R需要频繁写磁盘 - 现有解决方案只是对于某些特定问题的,如
Pregel、HaLoop不够通用 - 现有基于集群范围的内存框架是细粒度更新的,因为这些系统是偏向
OLTP场景的 - 而现在的场景更偏
OLAP,目的是基于内存、复用中间结果,计算结果丢了可以重算一次
Resilient Distributed Datasets
RDD是只读的、被分区的数据集
创建RDD有两种方式:
- 从持久存储中
- 从其他
RDD转换而来
RDD也不需要物化操作,根据数据集的血缘关系,可以从持久存储中计算得出
控制RDD包括两个方面:
- persistence,一个具体的存储策略,默认放内存,也可以溢出到磁盘,反正是可配置的
- partitioning,根据每个记录的
key做分区,对JOIN操作优化很有帮助
RDD提供的程序接口是基于对象上的函数操作,类似于DryadLINQ和FlumeJava
DryadLINQ是分布式版的LINQ
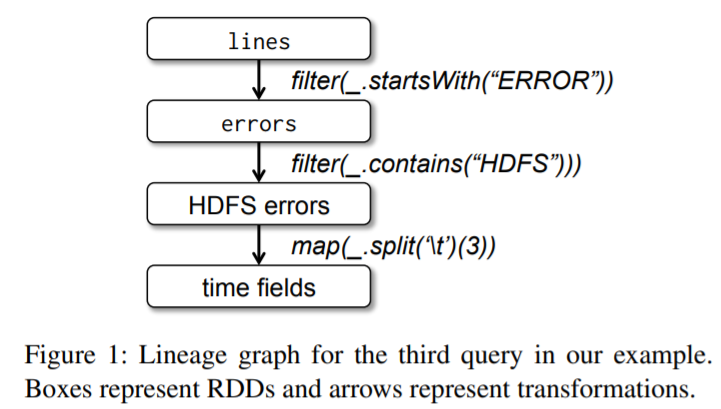
Figure 1: Lineage graph for the third query in our example.
Boxes represent RDDs and arrows represent transformations.
|
|
上面的执行过程:
- 从
HDFS文本集合中读取数据 - 通过
filter得到一个新RDD - 将其保存在内存中,这样其他查询可以共享这些信息
经过上面三步之后,其实并没有执行什么操作,而执行通过下面操作触发执行
|
|
也可以继续做一些转换操作:
|
|
当第一次调用action操作后,Spark将记录错误信息的分区存储在内存中。
而原始的RDD则不需要放到内存中。
和传统分布式共享内存(distributed shared memory DSM)对比:
| Aspect | RDDs | Distr. Shared Mem. |
|---|---|---|
| Reads | Coarse- or fine-grained | Fine-grained |
| Writes | Coarse-grained | Fine-grained |
| Consistency | Trivial (immutable) | Up to app / runtime |
| Fault recovery | Fine-grained and lowoverhead using lineage | Requires checkpoints and program rollback |
| Straggler mitigation | Possible using backup tasks | Difficult |
| Work placement | Automatic based on data locality | Up to app (runtimes aim for transparency) |
| Behavior if not enough RAM | Similar to existing data flow systems | Poor performance (swapping?) |
Table 1: Comparison of RDDs with distributed shared memory.
DSM是一种非常通用的抽象,但是对于普通集群来说,要在其之上实现有效和容错比较难。
相比DSM,RDD要实现【写】,只能通过粗粒度转换这种方式,而传统的DSM允许任意位置的读写。
RDD的转换相当于执行批量写,这种方式对容错比较有效,不需要 checkkpint。因为丢失一个分区,可以并行重计算方式来恢复,所以不用将程序再执行一遍。
由于RDD是不可变的,也可以将其的副本放到一个运行较慢的系统上。
对于批量执行时,还可以将这个计算下推到数据节点上提升性能;对于 scan 这种操作,如果内存不够了,也可以放到磁盘上。
RDD适用于 大量类似操作的批处理任务;对于异步的细粒度状态更新则不合适,比如 web应用的存储系统、增量的web爬虫。
这种操作用 更新日志、或者数据库的checkkpoint 更合适。
根据上述内容,可以得出结论:
- RDD的这些特性是用于重复的批处理操作的,在这种情况下用DSM就不划算了
- RDD的lazy、粗粒度转换,对于性能和容错都不错
- 而且可以将计算下推到数据节点,优化性能
- 两个特性:persistence,也就是怎么存(内存、还是磁盘等),以及partitioning,怎么分区
- RDD提供的这些操作接口类似
LINQ,而且是通用的基于内存的批处理模型
Spark编程接口
Spark使用scala实现的,选用这门语言的原因是:操作方便(交互特性)、效率也不错(静态类型)
开发者可以写一个driver程序,这个程序会连接到集群中的所有节点,driver中包含了一个或多个RDD,Spark还可以追踪driver的调用链。
工作节点都是常驻内存的。
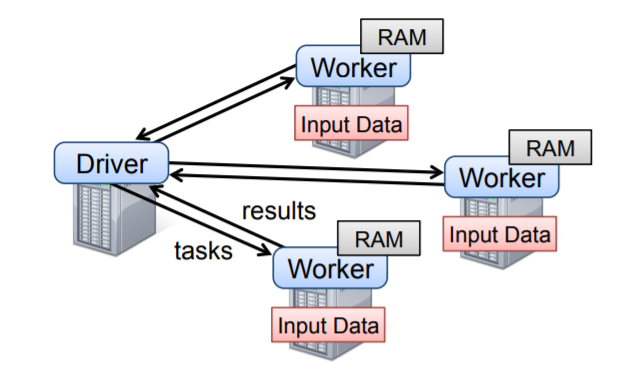
Figure 2: Spark runtime. The user’s driver program launches multiple workers, which read data blocks from a distributed file system and can persist computed RDD partitions in memory.
scala通过跨节点传递闭包(每个闭包就是一个Java对象),所以这些对象/闭包就可以序列化/反序列化 到其他节点上,还可以将任何变量绑定到这些闭包上。
RDD是可以带类型参数的,比如RDD[Int]表示一个integer类型的RDD,不过一般可以省略,因为scala支持类型推导。

Table 2: Transformations and actions available on RDDs in Spark. Seq[T] denotes a sequence of elements of type T.
大部分机器学习算法都是迭代计算,因为要迭代优化程序,比如梯度下降,以最大化函数,将数据保存在内存中,可以大幅度提高运行效率。
论文中给出了用Spark实现迭代应用的两个例子
一个逻辑回归的例子
|
|
操作过程如下:
- 定义一个
points的RDD(通过解析文本中的每一行得到的) - 再定义一个随机的
w - 然后反复运行
map和reduce,通过当前w的函数求和来计算每一步的梯度 - 对
w除以数据的函数求和,这样w就朝着改进的方向前进
一个page-rank的例子
该算通过增加链接到每个文档的贡献,迭代的更新每个文档的排名,每次迭代中,每个文档向它的邻居发送$\frac{r}{n}$的贡献。
这里的r是排名,n是邻居的数量,然后将其排名更新为:$\frac{a}{N} + (1 - a)\sum{ci}$
sum是受到的贡献总和,N是文档总数,在Spark中可以这么写:
|
|
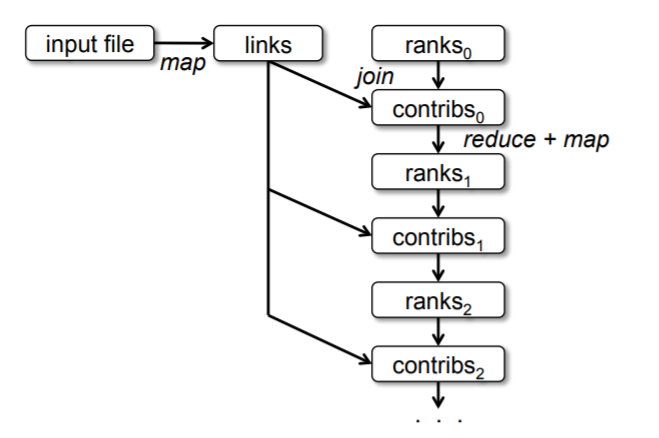
Figure 3: Lineage graph for datasets in PageRank
随着迭代次数的增加,计算时间也在增加,在有许多迭代的任务中,需要可靠的复制来减少故障恢复的时间。
可以手动的设置 persist 来执行此操作,但 links并不需要复制到其他机器,因为通过 重新执行文件块上执行map,就可以重建分区了。
数据集一般比rank要大很多,因为文档有很多链接,但是排名只是一个数字,通过血缘关系重建可以节省时间,不用把整个程序状态做checkpoint。
我们通过控制RDD的分区来优化PageRank程序
比如指定link的分区,在join时,以相同的方式对link和rank分区,那么每个URL的 rank 和它的 link就在一台机器上,这样就能节省网络 I/O
也可以自定义一个 Partitioner类来对每个相互链接的页面做分组
|
|
这种跨迭代的一致性分区类型,是专用的框架如Pregel的主要优化手段,而在 Spark中,用户可以直接使用这种方式。
RDD的表示
设计RDD的一个挑战是为他们提供一种抽象表示,可以各种transformations时追踪其血缘关系。
设计者的目标是为系统尽可能多的转换(transformations),而对于用户来说,要能任意的组合这些转换。
设计者使用了 图的方式来实现,这样不用增加什么额外信息,而且设计也简单很多。
通过接口,对每个RDD暴露这么一些信息:
- partitions集合,它是dataset的一部分
- dependencies集合,
RDD的父依赖 - 基于父dataset的计算函数
- 关于partitioning scheme的元数据
- 数据的具体位置
一个RDD(表示一个HDFS文件),对文件的每个块都有一个分区,也知道这个文件在哪个机器上。同时RDD上的映射结果也有相同的分区,计算它的元素时,将函数映射到父分区的数据上。
| Operation | Meaning |
|---|---|
| partitions() | Return a list of Partition objects |
| preferredLocations(p) | List nodes where partition p can be accessed faster due to data locality |
| dependencies() | Return a list of dependencies |
| iterator(p, parentIters) | Compute the elements of partition p given iterators for its parent partitions |
| partitioner() | Return metadata specifying whether the RDD is hash/range partitioned |
Table 3: Interface used to represent RDDs in Spark.
RDD之间的依赖关系有两种,如下面的 图4
- 窄依赖,父RDD的每个分区最多被子RDD的一个分区使用
- 宽依赖,多个子分区可能依赖一个父RDD分区
窄依赖很有用:
- 允许在一个集群节点上流水线执行,如可以执行map,再执行filter;而宽依赖要求所有父分区的数据都是可用的,然后执行一个map-reduce操作
- 节点故障恢复更有效,只需要重新就算丢失的父分区即可
这种通用的接口,在Spark上不到20行代码,就可以直线各种转换了。
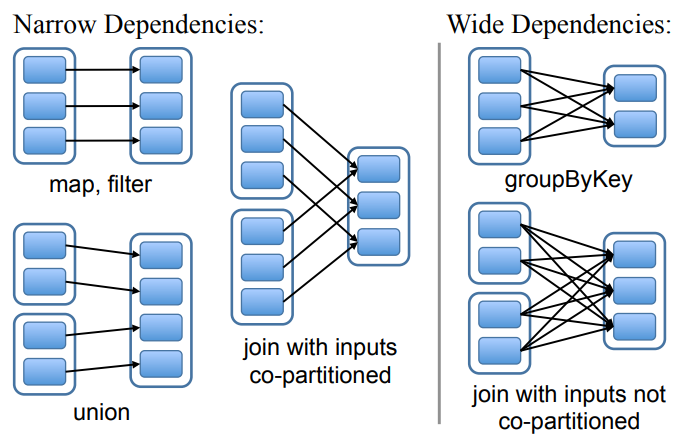
Figure 4: Examples of narrow and wide dependencies. Each
box is an RDD, with partitions shown as shaded rectangles.
几个重要的操作
- HDFS文件:输入的
RDD是HDFS上的文件,文件的每个block都对应一个partition,块的offset存在每个partition对象中 - map:在任何
RDD上调用后返回一个MappedRDD,跟父分区有相同的partition和preferred_locations,在迭代父对象时,将函数传递到map中 - union:新的分区是两个父分区的并集,每个子分区通过窄依赖到对应的父分区
- sample:类似映射,为每个分区存储一个随机数生成器seed,然后确定抽样的父记录
- join:会出现两个窄依赖(如果有相同分区)、或者两个宽依赖、也可能是一个混合依赖
实现
最初版的Spark只用了1.4W行的scala代码;出版的Spark跑在Mesos上,可以访问Hadoop、MPI等其他应用资源。
每个Spark应用都是独立的,有自己的 driver 和 worker,而应用之间的共享由Mesos负责。
下面来分析几个重要的部分:
- job scheduler:数据是怎么关联的,任务是怎么调度的
- 交互式的解释器:Spark的交互式执行方式,以及对scala解释器的改动
- 内存管理:RDD的几种存储方式
- checkpoint:通过检查点,可以加速恢复宽依赖
Job scheduler
有点类似 Dryad,但会分析内存中哪些持久RDD分区可用
当用户调用 action 操作后,scheduler 检查RDD的血缘关系,然后建立要执行的 DAG stages,类似下图
每个 stage 都包含进可能多的,有窄依赖的流水线转换;而 stage 的边界是宽依赖的 shuffle 操作,或者是一个计算好的分区,可以缩父RDD的计算量。
scheduler 启动 task,计算每个 stage所需要的分区,直到目标RDD完成。
scheduler 将计算任务下推到数据节点上,也就是尽可能满足数据本地性,如果要处理的分区正好在一个节点的内存中,那就将这个task发往那个节点,否则就找一个本地性最好的节点执行。
对于宽依赖,我们要将中间结果物化到节点上,来保存父节点的数据,这样可以简化故障恢复,而这个操作非常像Map-Reduce中的map物化输出。
如果任务失败了,但父分区仍然可用,那就再找一个节点重新计算一下;如果stage变成不可用(如shuffle丢失了map输出),我们重新提交这个任务,并行的计算丢失分区。复制RDD血缘很简单,但是scheduler不能容忍调度失败。
所有的计算都是通过 driver端调用action触发的;也可以让集群上的任务执行查找操作,该操作通过 key 随机访问RDD的hash分区元素。如果缺少所需分区,task需要告诉scheduler所需的分区。
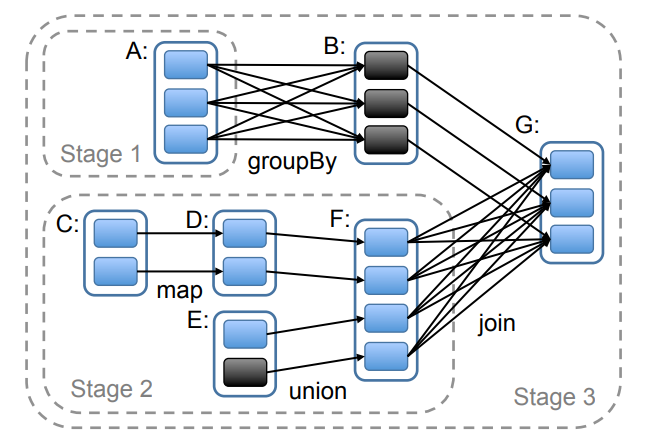
Figure 5: Example of how Spark computes job stages. Boxes
with solid outlines are RDDs. Partitions are shaded rectangles,
in black if they are already in memory. To run an action on RDD
G, we build build stages at wide dependencies and pipeline narrow transformations inside each stage. In this case, stage 1’s
output RDD is already in RAM, so we run stage 2 and then 3.
解释器整合
- 类似于 ruby 和 python 这样的交互式执行,用户可以通过解释器运行
Spark交互式查询大数据集 - 每输入一行都会被编译成一个类,然后加载到JVM中运行
- 这个类中包含一个单例对象,该对象包含各种变量和函数,并在初始化函数中运行这些代码
Spark的解释器做了一些改动:
- 让工作节点从每一行中获取字节码,通过
HTTP来传递解释器的字节码 - 修改代码生成逻辑
- 一般是通过静态函数访问每行创建的单例对象,但对于闭包引用
line.x,Java不会传输对象图 - 也就是,节点收不到line包裹的x,所以修改了代码生成逻辑,直接引用每行的对象逻辑
- 一般是通过静态函数访问每行创建的单例对象,但对于闭包引用
We modified the code generation logic to reference the instance of each line object directly.
操作过程类似下图
在初版的Spark中,设计者们还没有引入SQL这种更高级的交互式查询
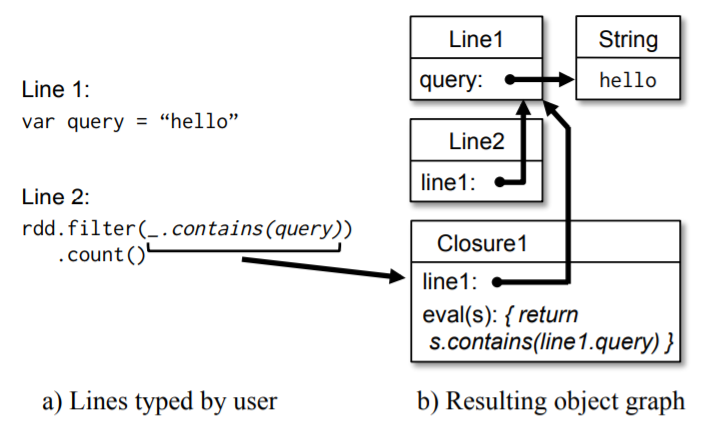 Figure 6: Example showing how the Spark interpreter translates
Figure 6: Example showing how the Spark interpreter translates
two lines entered by the user into Java objects.
内存管理
Spark提供了三种RDD持久存储:
- 类似 Java对象序列化形式,保存在内存中;性能最快
- 序列化数据保存在内存中;比原生Java对象更节省内存,但性能会有损失
- 保存在磁盘,当
RDD太大内存放不下可以保存到磁盘,这样节省了重复计算的时间
Spark使用了LRU算法来管理内存中的分区
旧的分区也会保存在内存中,以防止同样的分区频繁换入/换出
在初版,Spark的每个实例都有自己独立的内存空间,未来对于跨实例的共享RDD,用统一内存管理实现。
Checkpointing
通过血缘关系可以恢复RDD,但如果调用链太长的话,恢复时间也会增加。
checkpoint 对于宽依赖很有帮助,因为在宽依赖时,一个节点的失败会导致所有节点的父分区都丢失,通过checkpoint可以加速恢复;而对于窄依赖帮助则不大。
因为窄依赖只需要在其他节点上计算丢失的分区即可,这个动作还可以是并行的。
初版的Spark提供了checkpoint的选项,但对于哪些RDD需要做checkpoint这个动作留给用户;未来这个动作可能会变成自动化,因为 scheduler 是知道每个数据集的大小,那么就可以选择一个最优的RDD集合做checkpoint。
由于RDD是只读的,所以在做checkpoint时比普通的共享内存要容易,因为共享内存要考虑到一致性问题,可能牵扯到程序的暂停、分布式快照等问题,而RDD做checkpoint时,只要在后台写即可。
评估
基于AWS上做了一系列实验,以及一些应用级别的性能测试,得出结论如下:
- 相比Hadoop上的迭代机器学习和图应用,
Spark提升了 20倍 性能,主要是避免了大量的I/O以及从磁盘读取数据反序列化的时间 - 应用程序有很好的扩展性,使用
Spark将 Hadoop 上的分析报告提升了 40倍 - 节点宕机了,可以快速恢复
- 在 1TB数据上做交互查询,延迟为 5- 7秒
测试环境:
- AWS上的4核15G机器
- Hadoop的block为256M
- 每次测试都清空了 OS 的缓存
迭代机器学习应用
在下面几种环境中运行迭代的机器学习应用(逻辑回归、K-means)
- 普通的Hadoop
- HadoopbinMem,输入数据是二进制的,这样省去了文本解释时间,另外数据是放在Hadoop的内存实例中
- Spark
运行这两种算法 10 轮,数据量为100G,集群规模为 25 - 100台
这两个算法的区别是计算量,k-means由计算量决定,而逻辑回归计算量少些,但对I/O和反序列时间更敏感
由于要经过10次迭代,因此列出了第一轮和后续的迭代的报告
第一轮
Spark比普通的Hadoop稍微快一点,这其中的差别是Hadoop的主从心跳导致的
而HadoopBinMem明显慢得多,因为它要运行M-R任务,将数据转换为二进制,还要通过网络复制数据到其他节点上。
后续迭代
可以看到Spark有大幅度提升,相比Hadoop有20倍的提升,而HadoopBinMem也有2-3倍的提升
参考图7、图8
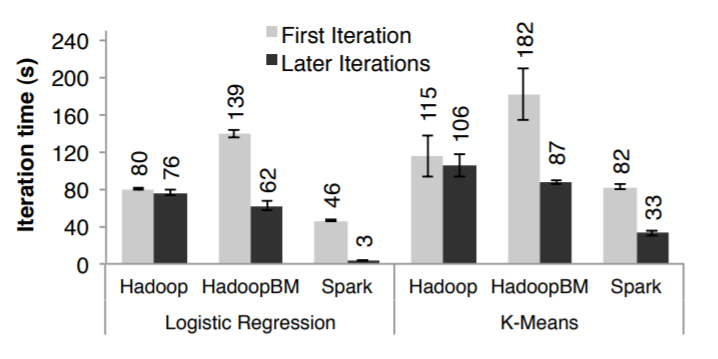 Figure 7: Duration of the first and later iterations in Hadoop,
Figure 7: Duration of the first and later iterations in Hadoop,
HadoopBinMem and Spark for logistic regression and k-means
using 100 GB of data on a 100-node cluster.
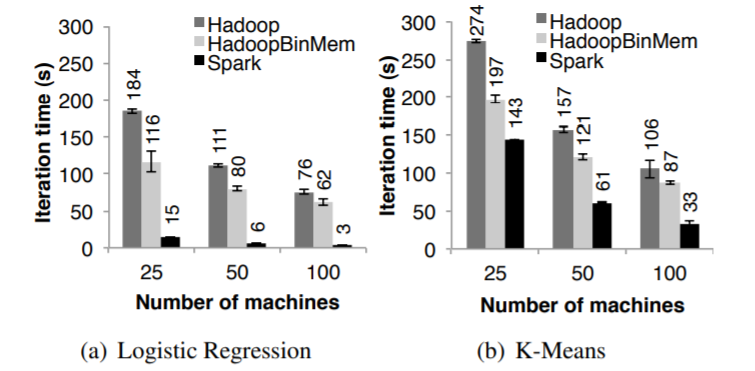 Figure 8: Running times for iterations after the first in Hadoop,
Figure 8: Running times for iterations after the first in Hadoop,
HadoopBinMem, and Spark. The jobs all processed 100 GB.
Spark比内存中的Hadoop还要好,这主要是下面这些原因:
- Hadoop软件栈本身的开销
- 处理数据的消耗
- 将二进制转为Java对象的开销
Spark没有运行任何Hadoop作业,而这些作业本身需要启动、清理、设置,这会带来25秒开销- Hadoop对每个block会执行多个内存拷贝和checksum
之后又补充了单机版的基准测试,输入为各种格式的256M数据,再运行逻辑回归算法
这里比较了从HDFS上读取二进制/文本文件(都是放在本地内存中的)
图9显示了 文本文件、二进制文件的差异
- 即使数据在本地内存,通过HDFS读取也有2秒的开销
- 文本和二进制解析开销为7秒
- 从内存中读取文件时,将二进制转为Java对象也有3秒开销(几乎跟逻辑回归本身花费一样了)
RDD将Java对象直接存储在内存中,避免了这些开销
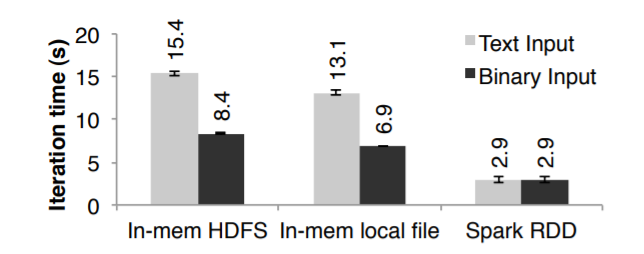 Figure 9: Iteration times for logistic regression using 256 MB
Figure 9: Iteration times for logistic regression using 256 MB
data on a single machine for different sources of input.
PageRank
使用了 54G的维基百科文档,运行10轮 PageRank 算法,文档总量约 400万
图10显示了在30个节点上,Spark运行速度是Hadoop的 2.4倍
如果显示的控制分区,那么可以提升 7.4倍,机器数量也可以线性的扩展到 60台
此外还在Spark上实现了Pregel版本,这个版本的效果跟图10差不多,但是总时间会多 4秒,这是因为Pregel在每轮迭代时有一个额外的操作,让顶点投票是否结束这个任务
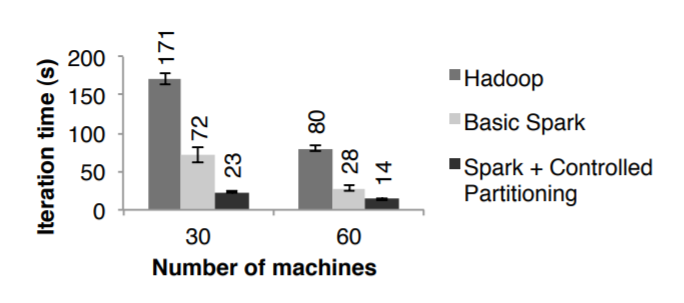 Figure 10: Performance of PageRank on Hadoop and Spark.
Figure 10: Performance of PageRank on Hadoop and Spark.
失败恢复
用 k-means 来评估节点失败的情况
如图11所示,运行10轮 k-means算法,集群规模为75个节点,每轮迭代有400个task,100G的数据
前面 5轮的 执行时间都是58秒左右,到 第6轮 时,人为的kill掉一个节点
于是这个机器上任务分区数据就丢失了,之后Spark在其他节点上并行的再次执行这些任务,根据血缘关系从输入中读取数据重建RDD
这轮的时间为80秒,等恢复完成后面的运行时间又降回到58秒
如果使用了checkpoint恢复机制,则需要好几轮迭代,还需要把100G的数据集跨节点复制,这至少需要两倍的内存、或者等待100G数据写磁盘
而基于RDD的血缘图,则不到10K
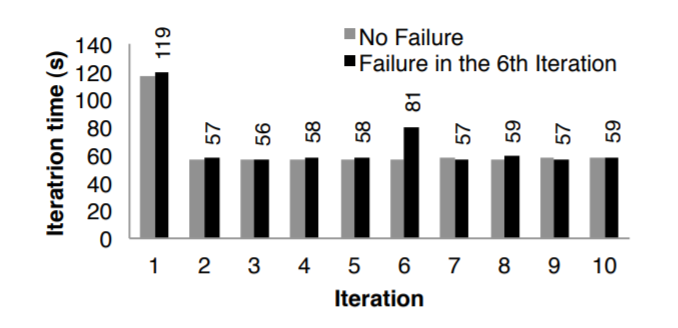 Figure 11: Iteration times for k-means in presence of a failure.
Figure 11: Iteration times for k-means in presence of a failure.
One machine was killed at the start of the 6th iteration, resulting
in partial reconstruction of an RDD using lineage.
内存不够的情况
前面的例子都是内存充足情况下的测试,现在展示内存不足情况下Spark的运行情况。
配置每个机器的内存不超过固定的百分比,图12显示各种存储空间情况下的运行结果,可以看到,在空间不足的情况下,执行效果是优雅的退化。
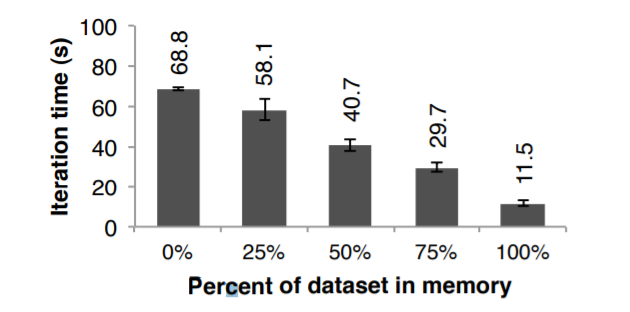 Figure 12: Performance of logistic regression using 100 GB
Figure 12: Performance of logistic regression using 100 GB
data on 25 machines with varying amounts of data in memory.
使用Spark构建应用
内存分析
有一个视频分发公司之前使用了Hadoop,而后改为用Spark。
之前是用 Hive 计算客户的各种统计信息,这些查询使用了相同的数据集(对客户数据的过滤),但是执行各种分组聚合时(avg、百分比、count、distinct)却跑了不同的M-R任务上。
而Spark上的RDD是可以跨节点共享的,这家公司将查询时间提升了40倍。
之前在Hadoop上的200G压缩数据需要 20个小时才能跑完,而Spark只用两台机器 30分钟就搞定了。
Spark需要96G内存,用来存放 filter之后的用户数据,而不是整个解压缩文件。
流量模型
伯克利的研究团队使用了一种并行学习算法,根据少量的GPS数据,来推断道路拥塞情况。
数据来自大城市的 1W交通路线,以及60W个点对点GPS行程(每个行程可能包含多个路线)
系统可以评估每条路线的花费时间,研究人员训练的模型使用了最大期望(expectation maximization)算法。
这个算法需要两轮 map和reduceByKey 迭代,应用基本是线性的从20个节点扩展到了80个节点(每个节点4核)
图13(a)展示了运行效果
推特垃圾邮件
伯克利使用Spark识别推特上的垃圾信息,在Spark上实现了逻辑回归分类器,使用了分布式的 reduceByKey 并行计算梯度向量之和。
数据子集为50G,包括25W个URL,每个URL的网络和内容数量有107个(特征/尺寸)。
由于每次迭代都有比较大的固定通讯开销,导致扩容后的效率不是线性增长,如图13(b)
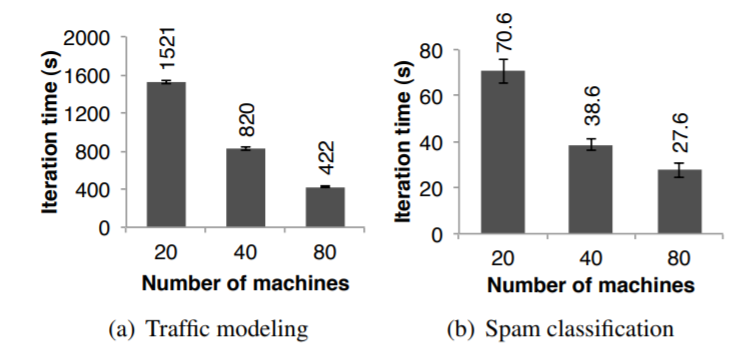 Figure 13: Per-iteration running time of two user applications
Figure 13: Per-iteration running time of two user applications
implemented with Spark. Error bars show standard deviations.
交互式的数据检索
为了证明Spark可以用于交互式的查询,使用了 1TB的维基百科页面访问日志(2年的数据)
使用了100个AWS机器,每个机器为 8核68G内存
包括三种查询,每种查询都是扫描全部数据
- 查询所有页面总数
- 通过给定关键字,精确匹配网页标题
- 通过给定关键字,部分匹配网页标题
图14显示了查询 100G、500G、1T的响应时间,即使 1T数据量,也只需要5-7秒时间
这比磁盘处理快了一个数量级,从磁盘读1T数据需要170s,这证明Spark在交互式的数据检索上效果非常好。
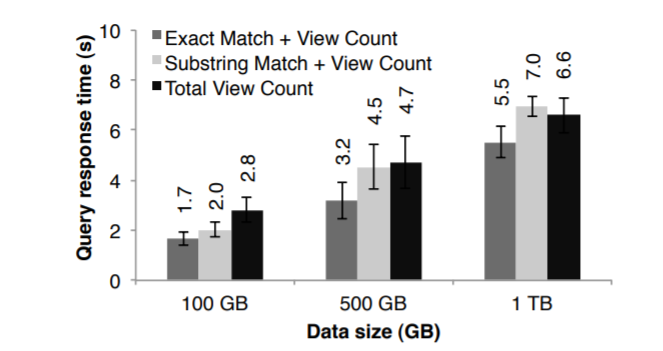 Figure 14: Response times for interactive queries on Spark,
Figure 14: Response times for interactive queries on Spark,
scanning increasingly larger input datasets on 100 machines.
讨论
尽管RDD只提供了有限的接口,如不可变性、粗粒度转换等,但他们实际的应用范围却很广,可以用RDD来实现现有的各种分布式编程模型, 另外RDD的血缘关系,对于 debug 也有帮助。
RDD可以产生和程序一样的输出,也可以处理框架执行时的优化,如: - 在内存中保持特定的数据
- 分区最小化通讯
- 有效的失败恢复
表示现有的编程模型:
- Map-Reduce:通过
flatMap和groupByKey来表示,如果要组合则用reduceByKey - DryadLINQ:提供比
MapReduce更宽泛的操作,但都是批量的,对应Spark的map、groupByKey、join等 - SQL:类似于DryadLINQ,SQL查询是对数据集的并行操作
- Pregel:谷歌的迭代图模型
- 程序运行一系列协调的"supersteps"
- 每个"supersteps"上的每个图顶点运行一个用户函数,该函数可以更新关联的顶点、状态拓扑、发送消息到其他顶点,以便在下个"supersteps"中使用
- 这个模型可以表示很多图算法如:最短路径、二部匹配、PageRank
- 用
RDD实现的关键点是,Pergel在每次迭代时,对所有顶点使用相同的用户函数 - 在每次迭代时存储顶点状态,然后使用这些函数执行批量转换(flatMap),生成消息的
RDD - 然后将这个
RDD和顶点状态做join,来执行消息交换 RDD也可以在内存中保存顶点状态,控制分区减少通讯,支持部分错误恢复
- Iterative MapReduce:HaLoop、Twister提供了迭代的MapReduce模型
- 用户可以提交一系列的MapReduce作业
- 这些系统可在执行迭代时保持分区的一致性
- Twister还可以将其保存在内存中
- 这两种优化用
RDD实现起来都比较容易
- Batched Stream Processing
- 每15分钟更新一次广告点击统计信息
- 将前面15分钟的中间数据 跟当前数据合并
- 将中间结果放入
RDD中可以加速处理
为什么RDD可以实现这么多程序模型:
- 在并行应用中
RDD的那些限制其实微不足道 - 并行操作时可以将同一个操作应用到多个数据上
- 同样也可以创建多个
RDD表示同一个数据集的不同版本 - 大多数
M-R应用是不允许更新文件系统的 - 先前的那些框架可能是专注于
Map-Reduce和Dryad的不足,导致他们缺乏通用的抽象模型
利用RDD做调试:
- 最初只是用来做容错的,但是发现对于debug也有帮助
- 通过重新计算依赖的
RDD分区,可以在单个流调试器中运行各种作业 - 传统的分布式系统上,需要捕获、推断跨节点的时间顺序
RDD只有记录血缘关系即可,团队打算基于这种方式增加Spark的调试功能
相关工作
Cluster Programming Models:
- 像
M-R、Dryad、Ciel这样的模型可以支持很多操作,但他们都是通过持久存储共享数据的,而RDD提供了更有效的方式,避免了数据复制、磁盘I/O、序列化 - DryadLINQ和FlumeJava这种高级编程接口,通过map、join实现实现并行集合,虽然也能用流水线的方式操作多个map,但是没能在多个查询中有效共享数据
- Pregel、Twister、HaLoop 这些框架将数据共享的方式隐藏了,用户无法指定可以将哪些数据集加载到内存,更没法在上面做什么操作
- Piccolo 这样的分布式内存系统,提供的是细粒度的状态更新,允许用户的函数读/写分布式hash表中的每个元素,而他们提供的checkpoint做容错代价很高
Caching Systems:
- 通过识别带有分析程序的子表达式,Nectar可以重新DryadLINQ的job的中间结果
- 不过Nectar没有提供内存级的缓存,也没有控制数据集的接口
- Ciel和FlumeJava 也可以缓存任务结果,但没有提供操作接口
- 现有的缓存方案是将数据写入到分布式文件系统,但对于中间结果这块没有很好处理,所以效率不如
RDD
Lineage:
- 捕获血缘或者源头信息,一直都是计算机和数据库方面的研究主题,可以用来解释结果
- 允许在其他地方重新构建数据,或者因为BUG、数据集丢失,可以重新计算
RDD提供了细粒度的血缘关系,用于容错- MapReduce、Dryad也有恢复机制,通过跟踪任务的DAG来实现
- 但这些系统一旦任务结束,血缘就丢了,需要持久存储来保存其结果
RDD是将血缘放在内存中的,避免了复制和I/O开销
Relational Databases:
RDD在概念上跟关系型数据的view类似,持久化的RDD类似物化视图- 关系型数据库允许细粒度的读/写所有数据
- 需要WAL和容错来实现一致性,这也带来了不小的开销
RDD是用粗粒度方式实现的,所以不需要这些额外的开销
结论
resilient distributed datasets (RDDs)是有通用性的、容错的框架,可以在集群应用中共享数据。
RDD可以用于很多并行应用,包括很多特定的变成模型,和现有的框架不同,RDD不需要数据复制来实现容错,它的 API是基于粗粒度转换,通过血缘关系实现容错。
我们用一个叫Spark的系统实现了RDD,它有超过Hadoop20倍的速度做迭代查询,也可以在几百G的数据上做交互式查询。