Kudu论文翻译
背景
Kudu支持结构化数据、低延迟随机访问,可以跟查询分分析模式整合;支持水平分区,分区选主支持raft。
Kudu支持Hadoop生态,包括Spark、Impala、MapReduce
Hadoop 生态的结构化目前有两种方式:
- 静态数据:基于Avro、Parquet,但它们都不提供更新记录、也不支持随机访问
- 不可变数据:基于HBase、cassandra,提供低延迟的随机读写,但对于批量读比前者差了很多
对于某些应用,可能同时包括了上述两种需求:随机读/写,大批量的文件扫描,这样需要将上述两种系统整合才可以,这就带来了一系列问题:
- 首先是架构变复杂了,要维护、监控两套系统
- 对于应用层来说,要主动区分流数据、非流数据,代码也复杂了
- 数据是先进HBase、再落到HDFS上,对于实时分析来说,是有延迟的
- 真实系统,可能要经常修复过去的错误数据、删除隐私敏感数据、还要适应延迟数据,上述架构要实现这些代价也不小
Kudu是新设计的一套存储系统,为的就是填补上述的 “空隙”,对于现有系统,他们在适合的场景下仍然有优势,但Kudu的优势提供了一个简化的架构,可以同时满足 低延迟随机读写+批量scan。
Kudu也提供了高层的API,包括对行级别的CURD操作。
高层API
Kudu集群包含了多个 table,每个table都包含了多个列,每个列都是有具体类型的,这一点跟关系型数据库比较类似
Kudu的表包含一个主键,通过主键做更新/删除
用户也可以修改表、删除表,但是不能删除主键
显示的列类型有两个优势:
- 可以对某一列更好的压缩、编码
- 可以将元数据导出到其他系统如BI、数据探索工具等
Kudu目前不支持唯一约束、不支持二级索引、没有自增主键
对于 insert、update、delete 需要手动指定主键
目前不提供多行更新的事务API,对于单行操作相当于 跨多列的原子操作
对于读,Kudu只提供了 scan 操作,并提供了两种类型的谓词:
- 基于列和常数值的比较
- 复合主键range
除了谓词,还可以指定列,因为Kudu是列存储的,这样也可以提高性能
Hadoop生态系统中通过调度数据位置来提升性能,Kudu也提供了对应的API,让调用者可以决定数据映射到指定的服务器
这可以帮助上层的计算框架如Spark、Impala、MapReduce来更好的调度
一致性
Kudu提供了两个一致性模式,默认的是 “快照一致性” ,对单个客户端来说相当于 read-your-writes 一致性
Kudu不提供外部一致性保证,比如一个客户端执行写,另一个客户端通过外部机制执行一个写,这两个写之间的依赖就没法保证了。
Kudu提供了一个选项,通过时间戳token来保证多个客户端之间的因果依赖
如果token太复杂,可以类似 Spanner那样,增加一个 commit-wait,通过等待一个周期就可以保证因果依赖了
这种方式需要依赖硬件时钟,只有少部分企业可以实现,而现在云厂商提供了全球时间同步机制
时间戳分配算法是: HybridTime
Kudu内部通过 时间戳 来实现一致性,但不允许用户手动设置时间戳 执行写操作,这点跟Hbase、Cassandra不同
Kudu的设计者认为 写带时间戳对大部分用户来说,会带来混乱,特别是插入、删除的语义方面
但Kudu允许 读 带时间戳,这样就可以查询过去的某个时间戳的数据,相当于是 读 一致性快照
架构
跟Hbase、HDFS类似,有一个master,通过复制实现快速故障恢复
Kudu也支持分区,多个行会对应到一个固定的tablet上,随机访问可以根据主键映射到一个确定的分区
Kudu可以根据提供的函数将 主键 映射到一个分区,客户端可以根据key来路由到确定的分区
- hash分区:由方言
DISTRIBUTE BY HASH(hostname, ts) INTO 16 BUCKETS指定- 这是将 hostname,ts编码为二进制键,然后连起来再编码,对 16 取模,最后落到一个具体的分区上
- range分区:由一系列主键列子集组成;根据指定列使用的编码,将tuples转为二进制string
为了写负载,可以将 timestamp设置为hash分区,不过读效率就会很差
也可以将 timestamp 设置为 range分区,并将 metric 和 hostname 设置为 hash分区,这样就兼顾了读和写
复制
Kudu将Table的数据复制到所有机器上,当创建表时候可以指定复制因子,如3、5
Kudu使用Raft来复制更新操作,也就是客户端的一个写操作会发送到leader:
- 如果当前的不是leader,则连接拒绝,并使客户端的元数据失效,然后重新找leader
- leader之后会锁住这个操作,避免并发问题
- 然后通过Raft将操作发给所有的follower,如果大多数同意,则提交这个请求
- 之后将log发给所有副本,如果大多数节点完成了 write-ahead log操作,则认为这个操作已经持久化
- 这里并没有规定再发送 log 到所有follower时,leader必须先提交
- 这样的好处是,如果leader本地磁盘有问题,则会首先收到网络返回的数据包
Kudu对Raft的一些小改动
- 当leader选举失败时后采用指数退避算法,将Raft元数据持久化到被征用的磁盘时,会加剧这个过程,因此这个算法会确保在繁忙的集群上尽快收敛
- 如果leader发现follower跟自己的日志有分歧,Raft建议是每次回退一个点,直到找到分歧的位置
- Kudu则增加了一个
committedIndex,当发生分歧的时候会立刻跳到这个位置 - 这样就减少了很多不必要的网络操作
- Kudu则增加了一个
Kudu不复制存储在磁盘上的数据,只复制log,每个table的副本的物理存储完全解耦,有如下优势:
-
一个复制在后台操作时(flush、压缩),其他节点不太可能再同一时间、同一节点上运行,因为Raft要等到大多数确认之后才提交,这减少了物理层操作对客户端写操作的尾部延迟;未来会继续实现一些技术,进一步减少并发读/写中的读取尾部延迟
-
我们还发现了一些罕见的条件竞争,因为存储层是跨节点解耦的,因此不会导致数据丢失无法恢复,在所有情况下,可以检查副本已经损坏并复制它
Raft协议中,建议配置变更采用:一个接一个方式,也就是从3副本变成5副本需要经过两步:
- 从 3 -> 4,提交
- 从 4 -> 5,提交
Kudu的变更流程:
- 在Kudu中通过
remote bootstrap来实现的,首先增加一个 成员到 Raft中,再提交变更 - master触发
StartRemoteBootstrap RPC,目标服务器会从 leader上拉取数据和log的快照 - 当传输完成,新的服务器就会打开表的数据,并重放必要的 write-ahead log
- 此时新机器就完成了leader在开始传输时的状态,并可以作为正常的副本响应请求了
- 最初实现时,是将这个服务器立刻变成一个 VOTER副本,但这会有问题
- 从 3副本变为4副时,4个中的3个都必须确认彼此的操作
- 但新机器还在拷贝中,它无法确认操作,一旦有机器此时宕机了,table的写操作就会不可用
- 直到 remote bootstrap 完成前都不可用
- 为了解决这个问题:
- 新增一个状态 PRE_VOTER
- leader会发送Raft变更,触发数据拷贝,但不会将其算作投票者
- 当检查到PRE_VOTER完成赶上了当前log,leader会触发一个提议和提交,将其变为VOTER
- 对于删除副本也是类似的,leader触发一个配置变更,但不包含被移除的节点
- 当这个提议被commit后,其他节点就不再跟 删除节点通信了,尽管删除节点自己并不知道
- 其他节点向master报告配置的变更,而master负责删除掉这个节点
master
master作为中控主要负责,非多主方式,可以简化设计,也方便调试
- 作为catalog管理者,维护table和tablet,相当于他们的schema
- 当 创建、修改、删除表时 master负责协调这些操作,确保最终完成
- 集群的协调者,用于跟踪机器的状态,等服务宕机后负责协调
- 跟踪每个tablet的副本都在哪些机器上
master自身维护了一个 单tablet的表,这个表不能直接访问,master内部将这个表的数据全部放在缓存中
因为现代商业机器的内存都比较大,而且每个tablet的元数据也不大,足够放入内存了,如果实在放不下,可以考虑linux的page cache
master还维护了每个表的状态(比如创建中,运行中,删除中),以及当前表的schema版本
master将CREATING状态写入catalog中,用来表示创建表,并异步副本信息发给其他tablet
这里是用Raft来维护复制的,所以收到大多数响应后master就可以提交了,否则就是失败,失败的话表可以被安全的删除
如果master在中间状态失败,需要往前回滚
master -> follower是冥等的,如果主master挂了,备份的master会被选举为主,然后scan 元数据表,加载到内存,并服务请求
集群协调
- master中包含了所有机器名的列表
- 服务启动后就会向master报告,第一次报告是全量的
- 之后每次都是增量信息(增、删、改)
- 状态变更是通过Raft完成的,所以master会保持最新状态
- 一旦某个主机的index跟master不对,可以简单丢弃
- master并不负责对机器的检查,而是由Raft来实现的,当有机器宕机后,就会检查到并触发Raft变更,将此机器移除
- master是根据负载情况,选择副本的,当master选择了要复制的 副本后,就会触发一次变更
- master自身并不改变配置,它必须等待其他副本提议并提交后,才会操作
- 如果中途失败,只要不断重试就可以了,这些操作都是冥等且不冲突
- 如果master收到了一个移除消息(一个table的副本从配置中移除了)就会触发一个
DeleteTable的RPC请求 - 为了确保master宕机这个操作也会成功,master也会触发一个RPC请求,指明这个表正在被删除
客户端访问目录:
- 客户端会只要访问过就会缓存元信息,包含表的分区key范围,raft配置等
- 某时,客户端的cache可能过时了,当它发送信息给旧的leader时(此时已变成follower),服务端会拒绝请求,客户端会联系新的master
- 上面的方式会多一次往返开销,其实follower所持有的信息都是最新的,可以让follower响应这个客户端,返回最新数据即可
- master将所有分区信息全部cache了,论文中270个节点、几千个tablet集群,99.99%的请求tablet位置信息,都是在3毫秒返回
tablet存储
Kudu的每个tablet都是完全独立的,也就是相互解耦的,这样的设计对于开发底层的存储系统很方便
理论上对于每个table、tablet、每个复制事件都可以有独立的存储布局,不过kudu目前只提供了一种存储布局
tablet存储实现要解决这些问题
- 快速的列扫描:跟Parquet、ORCFile这些不可变数据的差不多的分析性能,有效的列数据编码就很重要
- 低延迟的随机更新:对任意行进行快速读/更新,需要 $O(logN)$ 查找时间
- 性能一致性:有些用户宁可牺牲最快的性能,也要使时间在预期内完成
为了实现这些特性,Kudu重新开发了一套存储引擎,实现了新的混合式的列存储架构 RowSets,Tablets的更小单位,一行就代表RowSets中的RowSet
- 有两种实现MemRowSets、DiskRowSets
- 前者是将数据放在内存中,比如最近插入的数据
- 后台线程会周期的将内存数据flush到磁盘,刷新过程对 读/写都不影响,是并发的
- flush过程中的更新操作会跟记录,然后前滚到磁盘数据中
MemRowSet实现:
- 基于MessTree实现,是一个并发的B树,并做了锁优化
- 不支持删除,用MVCC记录表示一个删除的墓碑,真正删除是等待disk再做的
- 不支持原地更新,只允许不修改值大小,这样可以通过 CAS把变更操作 加到每个记录的链表中
- 对叶子节点增加了 next 指针,这样做 scan 的时候就会非常有效
- 没有实现完整的 前缀树,只实现了一棵树,设计者不太关注极高的随机访问吞吐量
- MemRowSets是行存储布局的,设计者使用 SSE2 指令在 scan 之前预取了一个叶节点
- 使用LLVM 进行 JIT 编译了投影操作,这些操作都显著的提升了性能
- 使用顺序编码主键,使插入到B树更高效,运行 memcmp,由于MemRowSet是排序的,所以scan,或者查找单个key都很高效
DiskRowSet实现:
- MemRowSets刷到磁盘后,就变成了 DiskRowSets,默认每 32M 为一个段
- DiskRowSets自身也是有序的,每个段的主键都是不想交的
- 包含两个组件:base data、delta data
- base data是列存储格式,每个列都会写到独立的磁盘上,并被单独写入到一个连续的数据块中
- 列自身被分为更小的page,可以更细粒度的随机读,同时内嵌了 B树索引
- 列的page可以使用各种编码,如bitshuffle、字典等,也包括各种压缩算法:如LZ4、gzip、bzip2
- 每个列都可以使用不同的压缩算法,如不经常访问的文本列使用 gzip,小整数列使用 bit-packed
- Kudu的页格式使用了Impala代码,所以很多页格式都是相同的
- Kudu还对主键做了编码,另外flush的时候可以加入Bloom过滤器
- Kudu不支持原地更新,因为编码后再更新效率很低,而将更新的数据写入到 delta store中
- delta store要不在内存中(DeltaMemStore),或者在磁盘(DeltaFiles)
- DeltaMemStore是并发的B树结构 ,DeltaFiles是二进制类型的块,
- 增量存储维护了 (row_offset,timestamp)到 RowChange-List记录的映射
- row_offset是RowSet中的有序索引,比如主键的最低offse是 0 ,timestamp是写操作时分配的MVCC时间戳
- RowChangeList是行的变更记录(二进制编码),指明 column是: id 3 = ‘foo’ 或 DELETE
Delta flush:
- 当 DeltaMemStore 满了,后台进程就会将其刷新到磁盘上,变成 DeltaFiles
- DeltaFiles 是二进制列,相当于 DeltaMemStore 的不可变副本
写路径:
- Kudu因为有主键约束,所有插入的数据必须要先检查唯一约束
- 每个表可能包含了几百上千个DiskRowSets,必须保证其高效性
- 可以使用Bloom过滤器,将其划分为4K页面,每个页对应以一个小范围的key
- Bloom过滤器索引使用B树结构,在服务端用LRU缓存,这样就避免磁盘操作
- 对于每个DiskRowSet还存储了max、min key,这样可以进一步做剪枝
- 后台压缩进程可以重新组织DiskRowSet结构
- 对于无法做减枝的DiskRowSet,就只能通过B树查找,其page会被放入OS的page cache中
读路径:
- Kudu的采用批量行读取方式,这样可以平摊函数调用开销
- 同时有机会对循环做展开,和SIMD指令优化
- Kudu内存中的批处理格式由一个顶层的结构组成,这个结构包含一些指针,指向每个正在读取的列的小块
- 每个批处理本身是列式的,当从磁盘列拷贝到批处理时,避免了偏移量计算
- scan时Kudu确定是否可以用range谓词来过滤DiskRowSet中的行
- scan的时候可以设置主键的上下界,这样就可以确定其偏移量
- 相当于把key的range谓词转成了offset range谓词,这样就避免了字符串比较操作
- kudu一次扫描一列,首先定位到正确的offset,将列中的数据解压拷贝到内存的batch中
- 之后会检查是否有 delta数据,应用到当前的MVCC快照中
- delta记录了offset,所以不用任何比较可以直接定位
- 服务端会维持scan的迭代器,下次查询就不用重新定位,直接从上次的位置直接查找即可
延迟物化
- 如果 scan 中指定了谓词,kudu会对列数据对延迟物化
- 在对任何其他列之前,会优先读取带有 range谓词的列,之后读取每个列时,都会评估关联的谓词,这样谓词就会过滤掉 - 批处理查询中的所有行,相当于对其他列做了短路查询,提升了巨大的性能
- 因为其他列中的大部分数据都不会真正触发磁盘读
delta压缩
- delta数据不是列式存储的,当delta文件数量增大后,读取就会变慢
- Kudu后台进程会定期扫描DiskRowSets,当发现 base data 和 delta data的比列过高,会将delta数据合并到base data
- 如果delta中的数据只包含都某一列的更新,那么合并就只针对具体列,避免对其他列的操作
RowSet压缩
- 跟delta压缩类似,Kudu也有一个后台进程会定期压缩不同的 DiskRowSets
- 压缩后重写到新的 DiskRowSets,让人是32M一个段
- 压缩时,可以将删除标记的数据 真正删掉
- 不同的DiskRowSets 的key范围可能会重叠,压缩后就减少了重叠,也为Boolm过滤器做了加速
调度管理
- tablet server内部维护了一个线程池,之前说的那些后台调度任务,都是在这些线程池中执行的
- 线程都是常驻的,不是由事件触发的
- 完成一个操作后,调度器会评估磁盘存储状态,执行启发式算法,平衡内存使用,WAL保留,和进一步的读写操作性能
- 优化过程是:给定一个I/O预算(如128M),然后选择一组DiskRowSet,进行压缩以减少他们的seek次数
- 这个优化过程实际上是等价于 动态规划中的-背包问题
- 当插入负载变高时,后台线程会将内存中的数据flush到磁盘;当插入负载降低,后台线程会做压缩以减未来的写负载
- 这提供了平滑的性能过渡,使开发和运维人员可以方便的对 容量做规划,对负载延迟做评估
Hadoop整合
MapReduce和Spark
- Kudu提供了对Hadoop生态系统组件的整合,可以将Kudu跟M-R的input、output job整合
- 可以跟Spark高层API绑定,就可以用Spark-SQL、DataFrame操作Kudu表
- 提供了数据本地化处理能力
- 提供了API让用户选择需要使用的列投影,这样就减少I/O
- 谓词下推,通过Spark-SQL就可以执行
Impala整合
- Kudu自身不提供SQL、shell,这些是通过整合Impala提供的
- Impala查询计划通过Kudu的java API检索表位置信息,将后台查询处理任务分配到相同的节点上
- 未来考虑通过共享内存来传输数据,以进一步做优化
- 谓词下推,修改了Impala的查询计划,可以识别出谓词并下推给Kudu,只有在传递谓词后Kudu才物化列
- DDL扩展,Impala的 DDL(create table)支持Kudu分区schema、复制因子、主键定义
- Kudu是Hadoop生态中第一个支持快速分析的引擎,并且支持更新,Impala之前不支持的更新操作,现在都可以支持了
- Impala的模块化设计,可以支持联邦查询
性能评估
和parquet比较
使用了TPC-H数据集,数据量 100G, 75个节点,每个节点配置:
- 2G cpu、6核
- 64G内存
- 12块磁盘
集群总内存是远大于数据集量的,所有的查询都会落到内存中
但所有的数据都会持久化到 DiskRowSet,而不是内存中
使用 Impala 2.2 + parquet 去运行全部的 22个查询;再用 Impala + Kudu 运行一次 做对比
每个表按主键分为 256个bucket,除非特别小的表如国家和地区等维度表
所有的数据都是用 CREATE TABLE AS SELECT创建的
目前还没有执行更深度的并行负载测试,只是用 TPC-H 对比了两个系统,结果如下:
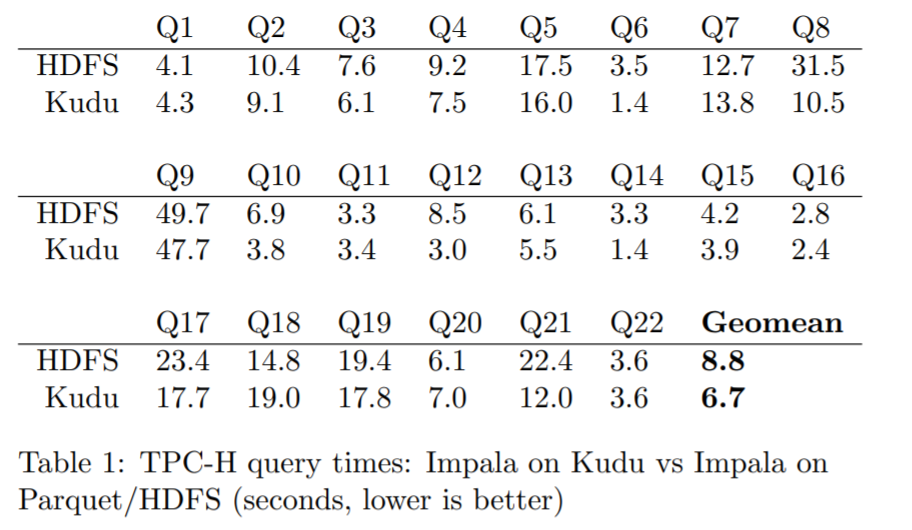
按照上述结果, Kudu平均比 parquet 快了 31%,大概是有两点导致的:
- 延迟物化,TPC-H中的查询都限定了谓词,Kudu的延迟物化避免了谓词不匹配时对其他列的操作,而这个特性parquet没有
- CPU效率,parquet对于每一行都会执行一次函数调用,导致效率不高
在未来,parquet实现了上述功优化后,Kudu的优势可能就不明显了
parquet更适合磁盘常驻的负载如 8M的I/O访问,而Kudu适合小的页面级别的访问
Kudu和parquet的比较证实了,Kudu有能力实现跟不可变存储类似的性能,同时还提供了可变的特性
和phoenix比较
虽然phoenix的主要目标不是做分析用的,我们还是做了少量的比较
展示了Hbase、Kudu在执行分析性负载下的性能差异
这次用了一个小的集群,一共 9 个节点,配置如下:
- 2.13G cpu、4核 Xeon L5630
- 48G内存
- 3块数据盘
- Phonenix 4.3 + HBase 1.0
- HBase的 block cache为默认值, 9.6G
- Kudu配置了 1G 的进程block cache,更多是依靠OS的 buffer cache避免物理I/O
- HBase配置了 FAST_DIFF 编码,无压缩,一个版本
- Impala端使用 逐查询选项,关闭代码生成,消除了与存储引擎无关的开销
- region-server 和 tablet-server分配了24G内存
将相同的 TCP-H lineitem表(62G csv格式)使用 CsvBulkLoadTool M-R job 加载到 phoenix中
phoenix配置了100个hash分区,Kudu也一样
通过执行压缩去报 100%的HDFS数据快被本地化,并确保region被均匀的分配到各个节点上
当62G的数据被复制到 HBase后,被膨胀为 570G, kudu是 227G
之后验证了两个系统都没有磁盘读取,这样只关注CPU效率,kudu的列布局和更好的存储效率性能更好
为了只关注scan速度而不是 join 情况,测试了 TPC-H的 query 1,同时也增加了其他几个查询,结果如下:
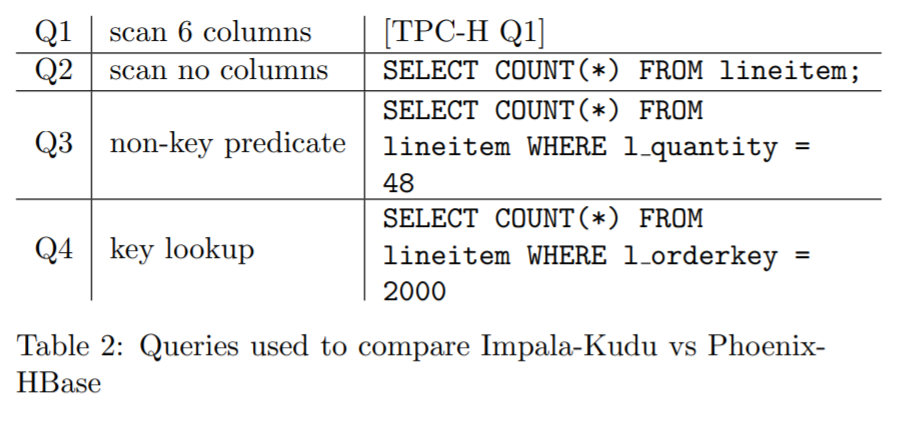
此外还对比了 Impala+Kudu、Impala+parquet、phoenix+HBase的各种查询
每个查询执行 10次,取中间结果:
 如上显示,Impala+Kudu 是 phoenix+HBase的 16 - 187倍
如上显示,Impala+Kudu 是 phoenix+HBase的 16 - 187倍
对于基于主键的小范围扫描,Impala+Kudu、Impala+parquet都是压秒结果,而Phoenix+HBase 因为查询计划中的低常数因子开销,使得性能也 比 Impala+Kudu更好
随机访问性能
尽管Kudu不是为OLTP设置的,它适合于轻度的随机访问,这里评估了Kudu的随机访问性能
使用 Yahoo Cloud Serving Benchmark YCSB 来测试
集群为 10个节点,配置跟测试 phoenix 时一样
为Kudu和HBase都配置了 24G内存,HBase使用了9.6G的block cache,Kudu使用了 1G 的block cache,更多是依靠OS的 buffer-cache,其他配置都是默认
为两个系统都分配了 100个 tablet
YCSB加载了 1亿条数据集,包括10列,每列100byte,由于Kudu没有行主键因此再增加一个主键key列
数据是完全加载到内存中的,这里没有测试 flush常驻、磁盘常驻的情况,因为大多数低延迟的应用基本都可以放到内存中
YCSB总结如下,先加载表,再执行A 到 D,中间没有暂停
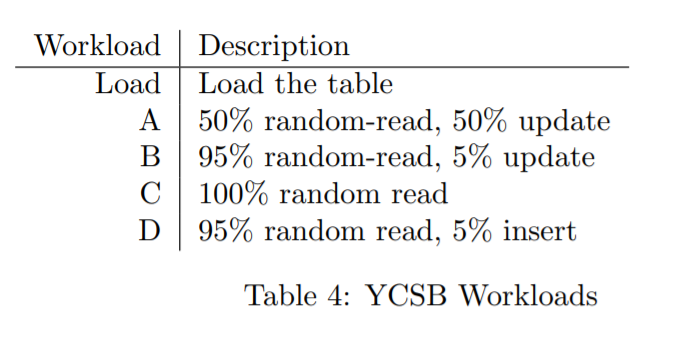
对每种情况执行 1000W次操作
对于加载数据,使用 16个客户端线程,并开启客户端缓存,可以发送大批量数据到服务端
其他操作使用 64客户端线程 并关闭客户端缓存
对两个系统都执行两次,每次都是删除并重新加载
对第二次执行,使用 统一的分布式访问来替换默认的 Zipfian 执行 A - C
对于D使用特定的访问分布,它随机插入行,并随机读取最近查询的行
不执行E,因为这个是小范围查询Kudu目标表现不好,而 F 是基于CAS操作的,kudu目前不支持
下图展示了其结果
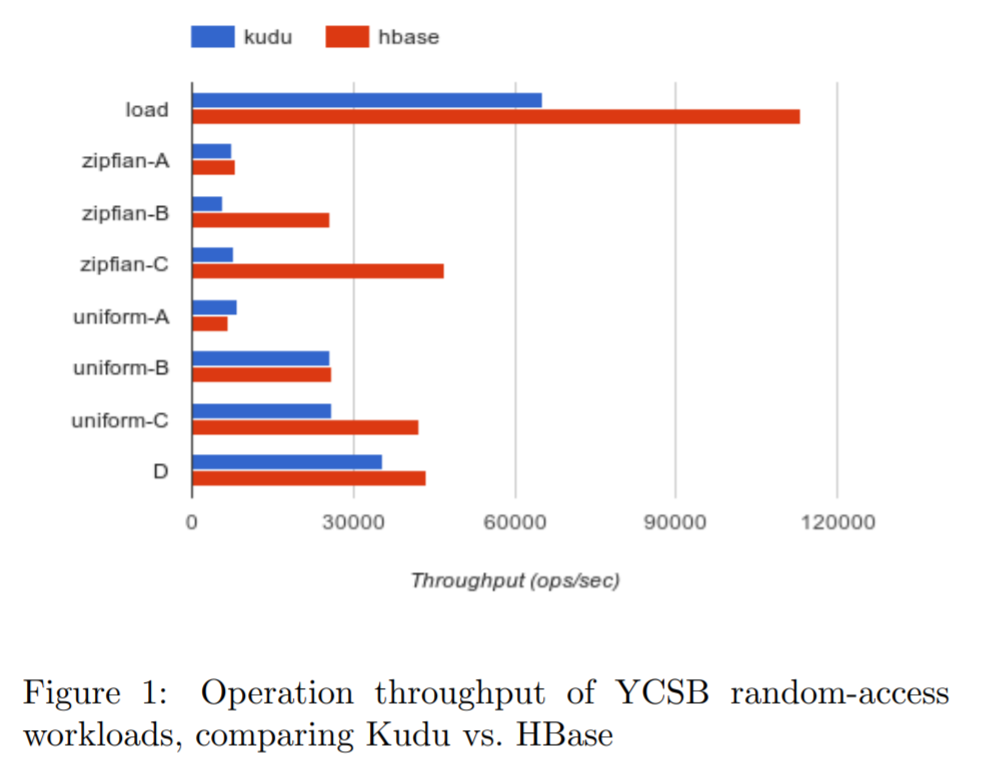
HBase执行的吞吐量明显比Kudu更好,Kudu在 zipfian 更新上效率不高,因为这行的链太长了,有很多delta合并操作
这些测试是Kudu的beta版发布时做的,因为时间有效测试场景不多