Hive论文
背景
Hive是Facebook推出的一个基于Hadoop的开源项目。
为什么Facebook会开发这么一款产品,根据论文和相关背景,大概能得到这么一些信息:
- 数据量是越来越大了,而商用的解决方案太贵了
- 因为数据量的增多,用户的增多,相应的BI、机器学习、数据分析的需求也变得更多了
- Facebook就靠广告业务来赚钱的,所以数据分析对他们来说很重要
- Facebook当时已经有
PB数据规模了,用传统的存储对他们不合适,所以也上了Hadoop - Hadoop的Map-Reduce确实不错,但是太底层了,连简单的
count、avg都没有 - Facebook内部的分析人员使用最多的可能是
SQL,这是他们最熟悉的 - 既然Map-Recue太底层,而很多分析人员对
SQL又很熟悉,所以就想做一个类SQL的系统 - 这个系统基于Hadoop,可以享受Hadoop的扩展性,同时又有SQL的一些特性
根据背景能发现,Facebook做的Hive并不是拍脑门弄出来的,而是真的有实际场景的。
Facebook的体量决定了它们必须上Hadoop,而他们的商业模式使得对数据分析非常依赖,但是Map-Recue太底层不合适分析人员。
像pig也是基于Map-Reduce,提供了更高层的接口,但是pig有自己的语法,跟SQL完全不同。
而Hive就是给公司内部分析人员使用的,所以场景其实很明确,就是谷歌的GFS一样,最初也是解决公司内部需求的。
所以Hive的出现提示了我们,好的产品应该是有明确的定位,能真正解决一些典型的问题
同时,这个产品最好能在已经成熟的基础方案之上,比如Hive很多重要的组件和思想都是基于成熟产品的:
- 元数据库的关系型数据库
- 底层的分布式文件系统、Map-Reduce
- SQL
基于现有成熟技术,找准产品定位,解决典型用户的需求,做微小创新
数据模型
Hive支持基本类型,以及复杂类型:
- Integers
- bigint(8 bytes)
- int(4 bytes)
- smallint(2 bytes),
- tinyint(1 byte)
- All integer types are signed.
- Floating point numbers
– float(single precision),
- double(double precision)
- String
- Associative arrays – map<key-type, value-type>
- Lists – list
- Structs – struct<file-name: field-type, … >
复杂类型还可以继续组合成更复杂的类型,比如:
|
|
这就是 list 里面可以嵌套 map,而map的value又是 struct类型
struct本身由两个基本类型组成,这样 Hive 就可以组合成任意复杂的数据结构了
创建复杂结构的建表语句如下:
|
|
t1.li[0] 可以引用 list里面的元素,也就是map
t1.li[0][‘key’] 可以引用 map里面嵌套的 struct
y t1.li[0][‘key’].p2 可以引用 最里面的struct
Hive 需要处理一些遗留的数据,那么就需要 序列化、反序列化 对此Hive提供了序列化接口:
- SerDe
- ObjectInspector
Hive内置的SerDe和复杂结构也是实现了上述接口,当实现了这些接口后,可以以jar包的形式导入
比如这样:
|
|
Hive的查询语言非常类似SQL,但有一些限制,此外还增加了很多针对企业内部特点的功能
像子查询、左右连接、笛卡尔积、union,group by、聚合都是支持的
所以任何对SQL熟悉的人(Facebook内部就有很多这样的分析人员),上手Hive就很快
Hive还提供了元数据展示,比如 show tables、desc、分析查询计划这样的功能
论文中给出了Hive的一些限制
比如,在join中有相等判断的谓词时需要这么写:
|
|
另一个显示就是 插入,可能是底层的HDFS本身只有append,并不支持随机的插入
所以Hive的插入实际是覆盖:
|
|
不过论文中也提到了,随着数据量的增加,这种折中的 insert,update都会有性能问题
所以未来会支持真正的 增删改
Hive还可以在SQL中嵌入map-readuce:
|
|
这里的输入是通过自定义的程序(map)转为 doctext的,然后输出也是通过自定义的reduce做处理的
SQL中可以只包含 map 部分没有reduce,反之也一样,如下就是一个例子:
|
|
Hive 对于 insert的目标端也支持多种类型
可以插入到表中,也可以写到HDFS,或者本地文件中,如下:
|
|
Hive这个产品在设计的时候,考虑到了公司的遗留数据处理问题,而把处理数据的细节(序列化、反序列化)交给用户了
并以jar包的形式导入,这么设计整个产品就更开放了
另外为了照顾到更高级的用户,在SQL中也可以嵌入map-reduce的脚本
因为Hive本身是基于Map-Reduce的,但是做了更高层的封装,但它并没有完全关上,而是提供了一个入口,让用户也可以直接执行M-R
Hive的字段类型是任意嵌套结构的,这种结构设计比较有意思,可以支持非常复杂的数据结构
从Hive的设计看
- 应该是在公司层面做了大量的调研
- 主要是面向使用SQL的分析人员(大部分用户),也照顾了小部分用户(使用MapReduce的用户)
- 还考虑了遗留数据和复杂结构的处理
- 从技术上来说很难,可能也不需要完全兼容标准SQL,所以这个SQL就不是标准SQL了
数据存储、序列化和文件格式
表在Hive中只是一个逻辑概念,Hive表的数据和HDFS上的目录管理,而管理的信息则存在元数据中
数据到HDFS的映射有这么几种:
- Table,对应到HDFS的目录
- Partitions,相当于一个表在HDFS上的子目录
- Buckets,分区或者表中的文件
table的完整路径是:
|
|
其中 <warehouse_root_directory>的默认路径为:/user/hive/warehouse
分区表的创建语法如下:
|
|
这个表的存储路径为:/user/hive/warehouse/test_part
Hive的分区列并非真实存在数据文件中,它仅仅是编码到 HDFS 的路径中了
当然 元数据中仍然会存储分区的列信息
分区可以通过下面SQL创建:
|
|
上面两个SQL会分别创建下面两个目录:
- /user/hive/warehouse/test_part/ds=2009-01-01/hr=12
- /user/hive/warehouse/test_part/ds=2009-02-02/hr=11
Hive的编译器会根据分区,也就是目录信息,做列裁剪,这样在scan的时候会忽略大量的目录,可以大幅提高性能
|
|
上面的SQL只会扫描/user/hive/warehouse/test_part/ds=2009-01-01/hr=12 这一个分区,这样效率就提高了
Hive还支持分桶,下面的SQL就是在32个分桶文件中只查询一个,这样对于分析的采样特别有效,因为底层是hash过滤的
|
|
Hive还可以支持外部表,也就是在建表的时候指定LOCATION,外部表删除时只会删除元数据信息,而不会真正删除外部数据
|
|
默认的序列化为LazySerDe,这个类实现类SerDe接口
只有在需要时才会序列化
这个序列化类假设数据存储在文件中,并使用指定的分隔符来分割数据和行
比如,可以这么指定字段、行、list中元素、map中的元素不同的分隔符
分隔符
|
|
- 字段使用ASCII字符002 ctrl+B分割
- 行使用012,ctrl+L 分割
- 使用ASCII 003 来分割list中的每个元素
- 使用004来分割map中的元素
Hive还提供了基于正则表达式的 序列化
|
|
这里使用了input.regex对输入的数据做正则拆分
然后用output.format.string将拆分后的数据写入到对应的字段中
Hadoop文件可以用各种格式来存储,如 文件、二进制、RCF等
|
|
像上面的方式,就指定了输入、输出为 二进制格式,当然也可以自定义文件格式,只需要实现:
- FileInputFormat
- FileOutputFormat
实现完后,将它们打成 jar 包,然后在建表的时候引入就行了,这种方式跟 实现自定义的 SerDe 类似
从论文的这章描述来看
- Hive确实跟传统的关系数仓不同,它的文件是存储在HDFS之上,所以其表结构只是逻辑的,最终到HDFS上都是目录格式
- Hive可以创建分区,这是逻辑列,只是在目录上出现,并非真实数据,但通过列裁剪可以大幅提供性能
- Facebook内部可能有大量的分析需求,所以分桶这个功能对于数据采用非常有用
- Hive在设计的时候就很开放,考虑到了HDFS上不同的文件格式,所以提供了不同的输入、输出格式,并可以自定义文件格式
- 同理,Hive也提供了各种序列化的方式,也支持自定义
- 可以看出Hive的SQL底层其实跟普通数据库差别非常大,但是它在设计的时候就充分考虑到了存储文件的特点
- 对于上层应用的使用尽可能接近SQL,同时又提供了很多的开放接口,方便自定义
系统架构和组件
Hive包含了下面这些组件:
- Metastore,存储了系统的catalog,表、列、分区的元数据信息
- Driver,管理hive sql的生命周期,也维持了session处理和session统计信息
- Query Compiler,将hive sql编译为无环图的 map/reduce 任务
- Execution Engine,执行由编译器生成的任务,并按照指定顺序执行,底层是跟Hadoop实例交互
- HiveServer,提供thrift接口和JDBC/ODBC server,用来整合hive和其他应用
- Clients,包括命令行,web UI,JDBC/ODBC 驱动
- 扩展的接口,包括 SerDe、ObjectInspector接口,以及UDF、UDAF接口
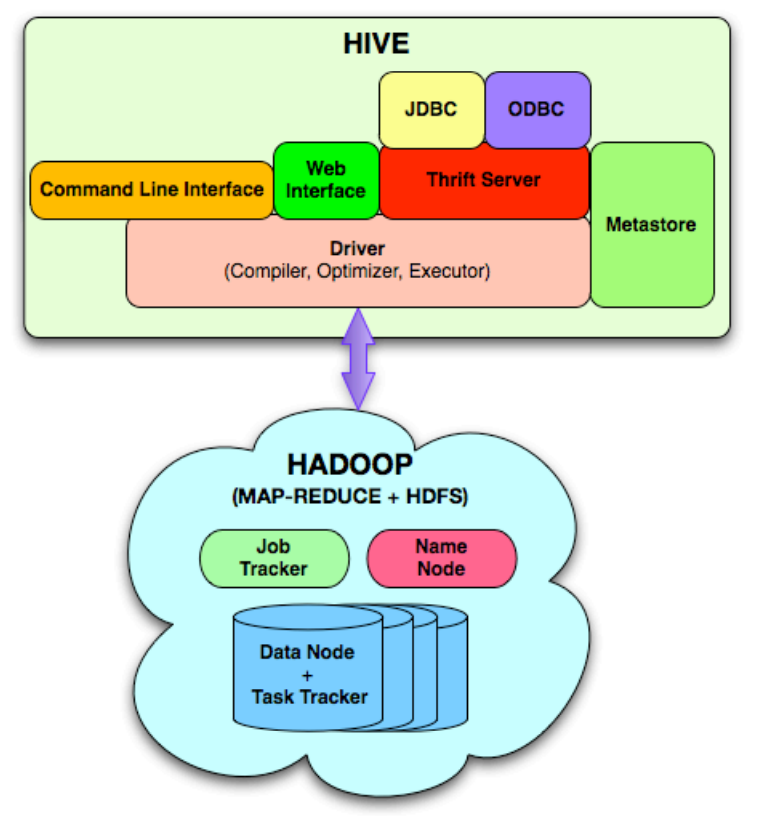 Hive 通过CLI、web UI、thrift、jdbc等 来提交hive sql
Hive 通过CLI、web UI、thrift、jdbc等 来提交hive sql
之后驱动会把查询语句交给编译器,编译器会做一些语法检查、语法校验,然后将元数据跟解析的逻辑计划绑定
之后是优化阶段,hive内置了一些简单的优化规则,最终会生成一个优化后的DAG map/reduce 和HDFS任务
执行引擎按照依赖关系的顺序来执行这些任务
Hive的元数据库管理 表结构、分区信息、类型、数据路径等等
为了保证低延迟,Facebook选用MySQL作为Hive的元数据存储库,当然也可以切换到其他关系型数据库
元数据库非常重要,就是它把Hadoop上的数据映射为逻辑的表
map、reduce任务需要的元信息由XML传递,而这些XML是由编译器生成的
Hive的编译器使用元数据来编译查询语句,生成逻辑计划,这些步骤跟传统的关系型数据很类似
整个过程如下:
- 语法解析,Hive用ANTLR做的词语、语法解析
- 类型检查和语法分析,从元数据库中读取表信息做绑定,再做类型检查,之后将AST转为 query block(QB) tree
- 将嵌套查询转为QB树的父子关系
- 优化,由一些转换规则组成,将一个转换变为另一个转换,想要添加自己的优化规则,只需要继承 Transform 接口
- DAG遍历的时候牵扯到5个接口:Node、GraphWalker、Dispatcher、Rule、Processor
- 转换过程是对DAG遍历,将满足某个条件或规则时调用对应的规则
- Dispatcher 维护了 Rules 到 Processors 的映射关系
- DAG中的操作符实现了Node接口
- GraphWalker负责遍历,当Node节点被访问时,就会调用对应的Processors
整个优化过程如下:
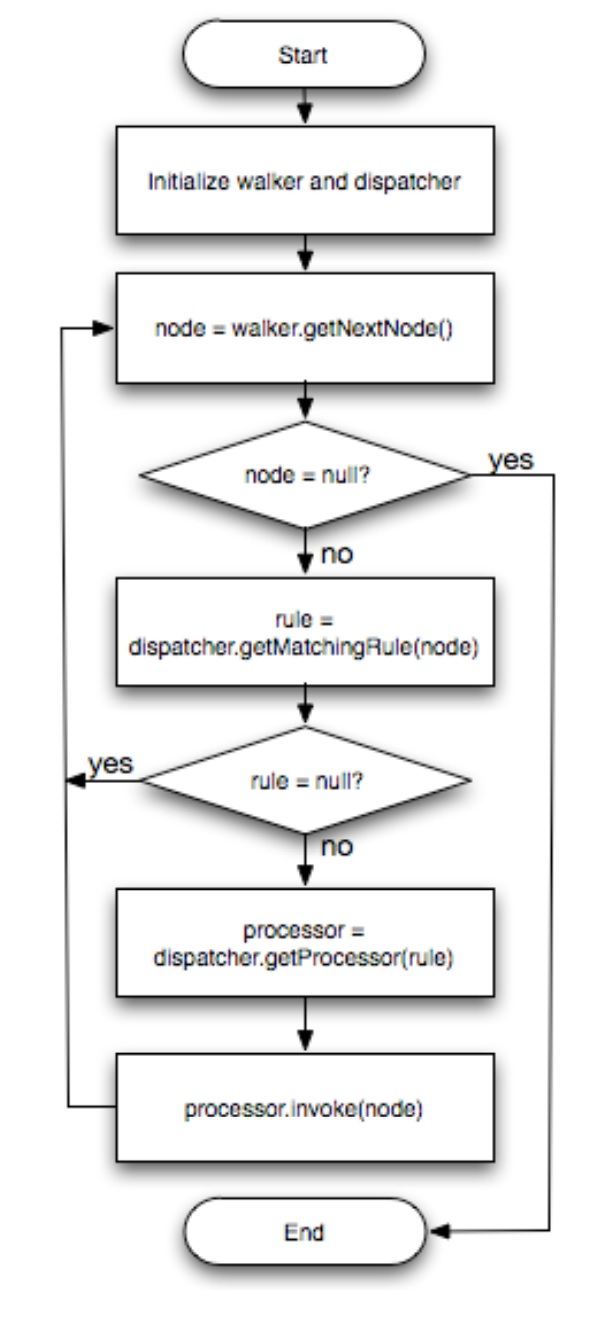
Fig. 2: Flowchart for typical transformation during optimization
优化内容包括:
- 列裁剪
- 谓词下推
- 分区裁剪
- map端join,对于小表就直接复制到所有的map端做join
- join重排序
map端join的可以通过一个提示来触发
|
|
map端join可以通过参数设置
- hive.mapjoin.size.key
- hive.mapjoin.cache.numrows
除了 map端join的提示,Hive还有下面一些提示
- 处理 group by,真实世界的数据可能分布的不均匀导致效率低,可以通过 2个阶段的map/reduce来优化
- 首先将 数据随机分布到 reduce端并计算部分聚合
- 在第二阶段,这些部分聚合数据被分布到 group by列的reduce
- 由于部分聚合的的数量比 数据集要小很多,所以性能会有大幅提升
使用下面方式来触发:
|
|
map端基于 hash的部分聚合
- 基于hash的部分聚合可以有效减少map发往reduce的数据
- 从而也减少了merge、sort的数据量
- 通过参数: hive.map.aggr.hash.percentmemory 来控制
- 另一个参数:hive.map.aggr.hash.min.reduction
优化阶段之后会生成物理执行计划
比如处理group by倾斜数据的情况,会生成 两个map/reduce,后会有一个HDFS任务,将数据移动到正确的路径
整个物理计划就是一个DAG,每个任务封装了部分计划
下面是一个多表插入查询,以及对应的物理计划
|
|
一个join后面跟了两个聚合函数,然后是一个多表的插入操作,join只会执行一次
对应的物理计划如下:
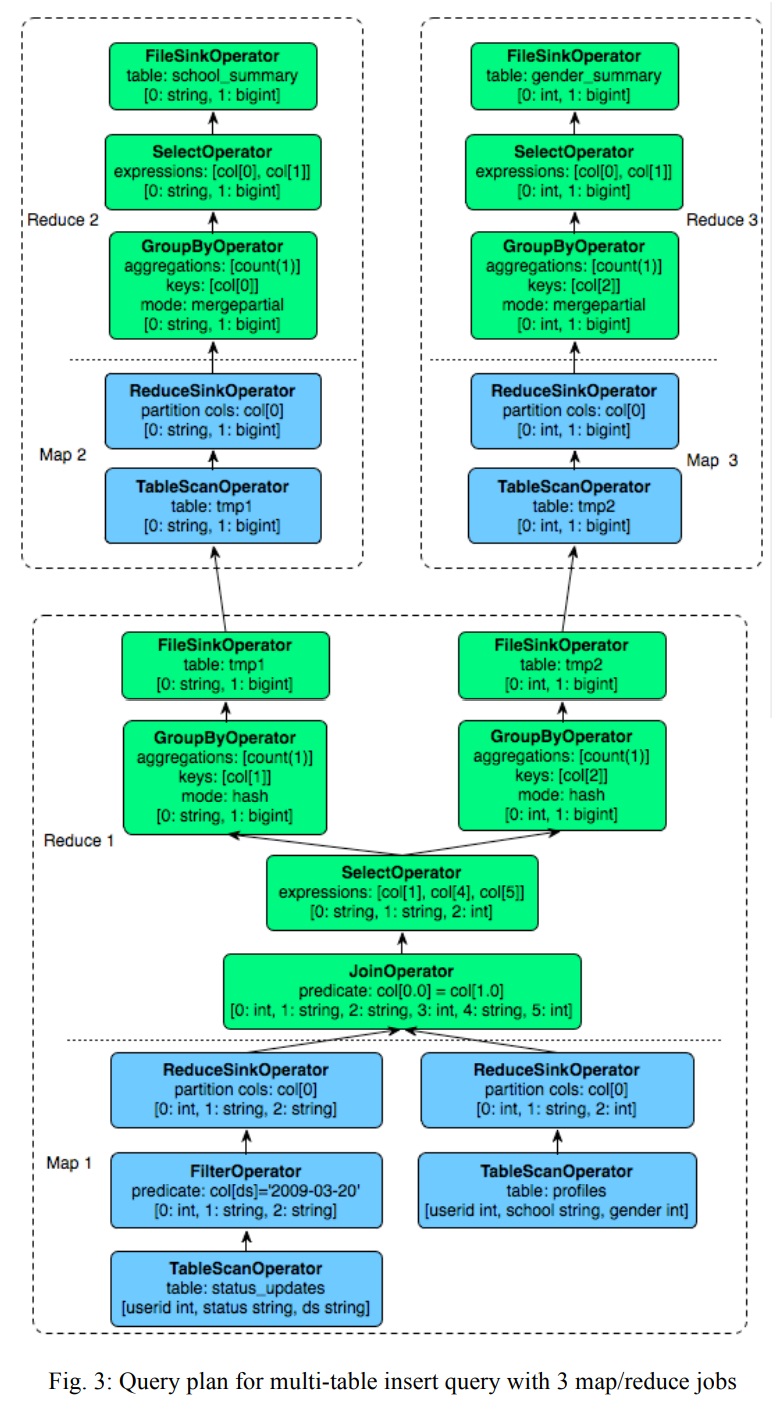 上图有 三个map/reduce,边缘表示 两个操作之间的数据流转
上图有 三个map/reduce,边缘表示 两个操作之间的数据流转
在同一个map/reduce任务内,mapper操作执行 在重分区ReduceSinkOperator 下面的部分,上面的是reducer部分
重分区是由执行引擎执行的
第一个map/reduce将两个临时文件写入到HDFS,tmp1和tmp2,他们被第二、第三个map/reduce继续使用,而后面的任务需要等待第一个map/reduce执行完
所有的任务是按依赖顺序执行的,只有当父依赖全部执行完后才会执行当前任务
map/reduce任务首先会将查询计划的一部分 序列化到 plan.xml 中
文件随后被添加到 任务的 job cache中
而 ExecMapper、ExecReduers 是由Hadoop创建的
每个class都会反序列化plan.xml,并执行DAG的一部分,并将结果写入到临时文件中
整个查询完成,会将临时路径的数据move到执行的位置
根据这章的论文:
- Hive的那些组件基本都不是原创的,很多都是基于现有组件
- MySQL、Hadoop、map/reduce、thrift、ANTLR的语法解析、数据库的优化技术、分布式技术
- 但是Hive创造性的在开源的Hadoop、map/reduce之上,增加了SQL这个高层的API
- 同时借助编译技术、数据库技术,把上层的SQL,跟底层的Hadoop很好的整合了
- Hive就是把现有技术组合在一起,搞了一个发明创新,解决了本公司内部的很多真实需求
内部使用情况和总结
那个时候,Facebook的集群有 700TB的规模,每天增加5T的压缩数据(压缩比1:7)
每天都有 7500个job作业,75TB的数据处理量
集群中有一半的资源用于处理 adhoc 查询,剩下用于来处大屏报告
但是共享集群有一个挑战,可能会碰到各种各样的job,导致消耗了大量资源,从而使正常的查询报告也变得很慢
这主要是Hadoop的资源调度能力有点弱,目前唯一的解决办法是将 adhoc和查询报告所属的集群分开部署
集群上跑了各种job,从简单的总结job,到rollup、cube的job,再到高级的机器学习算法
系统上有老手也有新手,新手经过简单的培训就可以使用了
由于Hadoop的伸缩能力,这套系统的成本比传统数仓要小得多
Hive相比Pig,提供了元数据功能,使得它更像一个传统的数仓
后面的工作包括增加更多的RBO、加入一些CBO、扩展更多的语法、跑TPC-H变得更工业化、支持更多的BI工具等等