GFS论文
设计目标
GFS文件系统设计时候,也是考虑了性能、扩展性、可用性、可靠性等。
跟传统文件系统不一样,GFS在设计时,是基于自身的业务需求来的,有点点像是基于自由的业务属性,针对性的开发了一套文件系统。
论文的开头就指出了GFS设计时的 四个 目标:
- 因为机器很多,而且都是
x86机器,所以失败是常态,因此在软件层面必须能自动处理失败的情况 - 当时存储的文件基本上都是
GB级别的,对于这种级别尺寸的文件,设计时就要重新考量了,比如针对I/O- 块的大小需要定制设计,小文件也有但不多,不用特别考虑
- 吞吐量优先,很少有应用对读写的响应时间有要求
- 文件基本都是追加写的,极少有覆盖或者随机写入的,这对于文件系统优化和原子性也是有优势
- 设计通用的
API,放宽了一致性的要求,多个客户端并行写可以不用加锁
设置概览
按照之前介绍的需求,再重新审视一下:
- 系统是由廉价机器组成的,失败是常态,必须包含监控,并能从故障中快速恢复
- 系统主要存储大文件,通常是100M或更多,几个G的也经常出现,小文件需要支持单无需优化
- 主要包含大量的连续读、小量的随机读,读一般是几百KB或1M,客户端可以批量读来优化
- 写主要是连续的追加,大小跟读差不多,随机写的场景很小,可以支持但无需优化
- 文件被当做生产者-消费者来读写,或者多个合并,会有多个客户端append,需要用锁来保证原子性
- 几乎都是批量读场景,需要保证高吞吐量,低延迟几乎不用
architecture
GFS集群包括一个master,和多个chunkserver,每个服务器都是普通的linux机器,进程运行在用户态,单master的设计会简化整体架构
文件被分割为固定大小的chunks,每个chunk都对应一个 64位,全局唯一的标志,这个标志由master维护
chunkserver将文件存储在本地磁盘上,所以底层用的是Linux文件系统,读写chunk通过标识符来定位,默认提供了3个副本来保证高可靠
master维护了系统的元数据,功能包括:
- namespace
- 访问控制信息
- 文件 到 chunk的映射
- 当前chunks的具体位置
- chunk的租约管理
- 回收垃圾chunk
- chunk的迁移
- 跟chunk-server的心跳
客户端通过master找到chunk,然后就直接跟chunk-server通讯了
客户端会缓存chunk-server的位置信息,但chunk-server和客户端都不会缓存数据
因为文件都比较大,而且是顺序读取的,缓存意义不大
另外底层使用的是linxu文件系统,对于频繁读取的文件,本身就会被放入到 cache 中
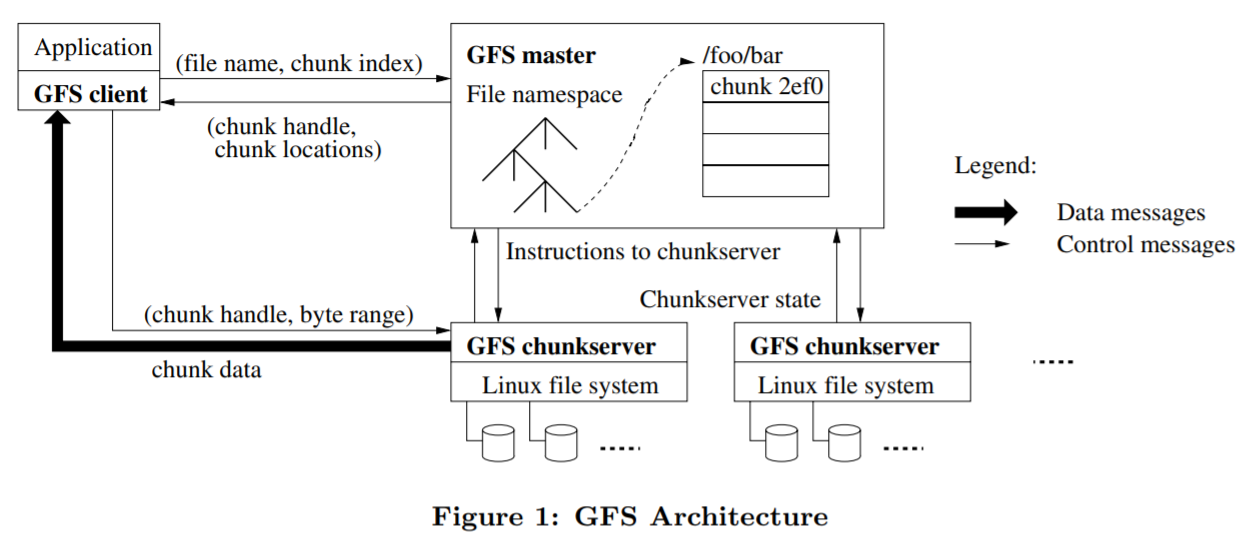
客户端首先根据文件名,offset,转换为 chunk index,然后跟master通讯(发送文件名和chunk index),获得具体的chunk-server信息
chunk size
默认为 64M,而底层使用的是linux文件系统
选择这么大的原因:
- 文件大了,集群总量不变的情况下元数据就会减少,master在内存中就可以完全放下
- 公司内部的需求看,大部分都是大文件读写
- 减少了频繁的TCP创建
- 客户端和master的交互也减少了
论文里面也说了,小文件的情况下会出现浪费
另外可能会出现热点,谷歌内部曾经碰到这么一个场景:
大量的客户端同时读取单个文件导致热点,解决办法是调大复制因子,并将客户端读取的启动时间错开
更好的方式是:允许客户端读取其他客户端的数据,有点像树状结构了,这样可以彻底解决热点问题,不过整个架构都需要调整
meta-data
master主要存储三类元数据:
- 文件和chunk的namespace
- 文件到chunks的映射
- 每个chunk副本的具体位置信息
第一、第二个需要持久化存储的,存储到master的本地磁盘上,然后复制到远程机器上
这样是防止master挂掉
第三种不用持久化,当master启动时候会主动询问每个chunk-server获取具体数据信息,或者是新的chunk-server加入集群后也会主动上报
元数据的设计要点:
- 元数据是全部放在内存中的,可以周期性的快速的扫描整个数据状态
- 发现过期数据,对于挂掉的chunk-server做元数据修复,迁移数据等等
- 元数据全部放在内存也不算太大限制,因为大多数文件都很大,一个元数据不到64字节就可以映射到一个chunk
- 文件名是前缀压缩的,也是少于64字节,所以整体占用空间都不大
- 如果想扩大内存,就直接加内存条即可
- 通过单master,元数据常驻内存,就可以获得很好的性能、高可靠、灵活性,而且设计也不会很复杂
chunk位置
- chunks的映射关键已经保存在master的内存中了,只是具体对应到哪个chunk-server没保存,而是等chunk-server主动上报
- 这么做的好处是避免了master的记录、和chunk-server存储的不一致,因为数据是存储在chunk-server端的,而chunk-server可能因为各种问题导致数据丢失
- 而master很难维护这种一致性,所以主动上报就解决了这种问题,实际是简化了一致性设计
操作日志
- 元数据的持久记录,也包含了并发操作排序的逻辑时间
- 文件和chunk,都是在他们被创建时通过逻辑时间唯一标识的
- 元数据非常重要,即使chunk-server本身存活,元数据丢了会导致整个系统的文件丢失、或者丢失最近的操作
- 需要将master的操作复制到远端 多个机器上,等本地和远端机器都flush到磁盘后才返回给客户端成功
- 为了提高吞吐,master会一次操作多个日志
- checkpoint采用了 压缩的B树结构,可以直接映射到内存,无需额外解析
- master会新开一个线程处理checkpoint,然后将新来的日志 写入到新文件中
- 等到本地和远程机器都成功flush磁盘,这个checkpint就算成功了
- 如果checkpoint失败可以安全删除,而checkpint成功后,只需最近一次的checkpoint+之后的日志文件即可
consistency-model
文件的namespace变更时原子的,由master加锁来保证原子性
根据是否变更成功、是否为并发,可以组合成不同的结果:是否为确定的,文件区域是否一致
- 变更后,所有的客户端都能看到变更后的全部写入内容,那就是确定的,否则就是不确定的
- 变更成功 且没有并发情况,那就是确定的
- 并发变更成功会导致 不确定但可以保证一致性,所有客户端都能看到一样的内容,但可能反映不了任何一个变更的写入
- 变更失败就是不一致,当然也是不确定的,所有客户端在不同时间会看到不同结果
上述情况总结的表格如下:
| Write | Record Append | |
|---|---|---|
| Serial success | defined | defined interspersed with inconsistent |
| Concurrent successes | consistent but undefined | defined interspersed with inconsistent |
| Failure | inconsistent | inconsistent |
变更包含两种:
- write:应用程序指定写入文件的offset
- append:被原子的append,即使在并发情况下也能保证至少一次的语义
客户端认为的append,其offset是文件的末尾处,返回客户端的offset是一个确定区域的开始处,GFS可以插入填充、或者记录副本,这里可能就会出现不一致
在一系列成功的变更之后,变更的文件区域就是:确定的,并包含最后一次变更的内容,GFS为了实现这个目标:
- 将这个变更按顺序应用到所有的chunk副本上
- 使用chunk 版本来检查是否变成过期
过期的副本不会牵涉到变更中,在客户端询问master具体文件位置时,也不会触发到过期副本
所有的客户端都会缓存chunk位置,在refresh之前可能会读到过期数据
大多数客户端都是append操作,所以过期副本返回的是过早的数据,而不是过期的数据
客户端可以通过重新检索位置,立即获取到最新的位置
由于组件的故障,会导致数据的损坏,GFS master会定期联系chunk-server,并检查数据,一旦发现问题,就会从其他副本中恢复数据
如果所有的副本都损坏了,那这个chunk就真的不可用了
GFS应用程序可以通过一简单的技术来实现宽松的一致性
- 依靠append,而不是覆盖写
- checkpoint
- 自我验证
- 自我识别记录
系统交互
变更就是:
- 通过append,或者wirte 改变chunk的内容
- 或者通过append、write改变chunk的元数据
为了减轻master的负担,master会分配一个租约给一个主分片,然后主分片按顺序变更所有的其他分片
租约是通过心跳来管理的
master也可能会回收租约,比如租约超时,rename,通讯中断
租约可能会超时,也可能因为rename被master主动关闭
写入流程如下:
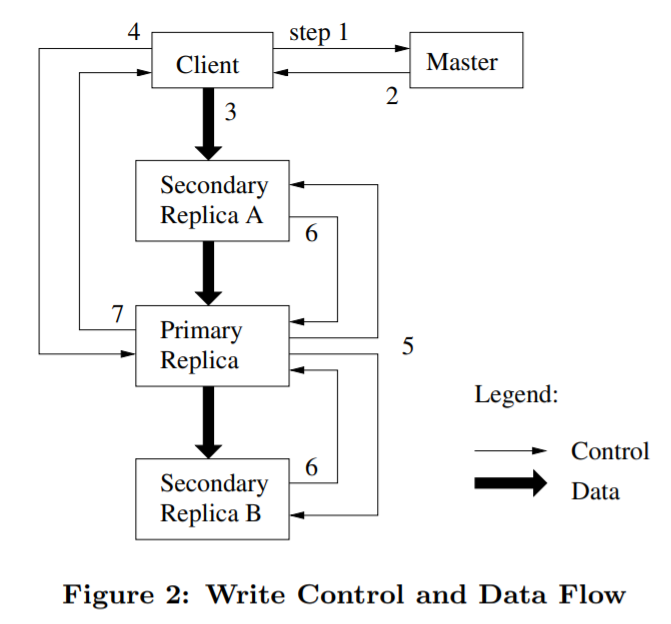
执行步骤如下:
- 客户端向master要chunk对应的chunk-server租约,并获取其他chunk的位置
- master返回主副本和其他副本的位置,客户端缓存这些信息,待租约失效或副本不可达时会再次联系master
- 客户端将数据写入所有chunk-server,每个server都有LRU缓存,为了解耦合优化,GFS还改变了一些部署拓扑
- 当所有副本都接收到数据后,客户端发写请求到主副本,主副本为所有变更分配序号,并按序号顺序变更本地状态
- 主副本发送给所有从副本,按同样顺序变更状态
- 从副本发送完成请求给主副本
- 主副本响应客户端,如果成功可能是 主和从任意副本出现失败,如果返回失败,意味着主副本根本没分配过序号,失败后客户端可以继续(3)-(7)重试
如果文件很大,会被分成多个chunk写入
共享的文件区域可能会包含来自多个不同客户端的文件片段
数据流:
- GFS对数据做了管道化处理
- 客户端写入最新的S1,然后S1 -> S2,S2到最近的S3
- 交换机是全双工,所以S1 直接写到S2,是没有TCP拥塞的
- 网络是足够简单的,所以通过IP就能找到最近的机器
- 假设要发送 B字节 到 R个副本,那么总延迟为 B/T + RL,T是带宽,L是两个机器延迟
原子append
- 普通的写入,如果是并发情况下,可能一个区域内会有多个客户端的写入片段
- GFS提供了append的原子写入到文件末尾,保证至少一次的语义
- 类似于unix 的O_APPEND 模式,但是没有条件竞争
- 这种特性在谷歌内部非常有用,这种场景包括:多个生产者/一个消费者,或者是从多个客户端做合并
- 主副本会检查append到当前chunk是否会超过默认64M,如果是则返回错误,让客户端去另一个chunk重试
- append的限制写入量为最大快(64M)的 1/4
- GFS不保证所有副本写入的内容一样,只保证append至少一次的原子语义
- append成功后某个快的所有副本的offset都是相同的
- 成功的append后这块区域就是 确定的,否则就是 不确定的
- 客户端需要处理这些不一致的区域
快照
- 创建快照很快,对正在进行的变更影响很小,用户可以使用这个功能做文件、目录的拷贝,做checkpoint
- GFS使用copy-on-write方式实现snapshot
- master收到快照请求后,将回收所有租约,这样客户端就需要再次跟master交互获取chunk的位置
- 回收租约后,master将记录flush到磁盘,然后在内存中copy一份新的元数据(源可能是文件/目录),两个元数据都指向同一个chunk
- 之后客户端会对chunk C做一个写请求,master注意到这个chunk引用数 > 1,然后就推出回复客户端
- master找到拥有 chunk C的chunk-server,要求他们在本地创建一个C‘,这样就避免了网络I/O
- 完成这些之后就响应客户端,后面的操作都是正常流程了
master操作
锁的管理:
- GFS没有inode,symbolic和hard link这些
- namespace类似一个查找表 全路径 -> metadata
- 使用了前缀压缩,这样可以节省很多空间
- namespace是一个树结构,如 /d1/d2/…/dn/leaf 这样的
假设有一个快照操作将 /home/user 复制为 /save/user,它需要组织一个创建文件的操作: /home/user/foo
- 快照首先获取 /home、/save的读锁
- 然后获取/home/user 和 /save/user的写锁
- 创建文件(写操作)需要两个操作(按顺序执行)
- 先是获取/home读锁,再获取/home/user读取,最后执行/home/user/foo写锁
- 创建文件是允许并发操作的
- 好的文件策略应该是尽量允许并发,比如目录/home/user做读锁,对创建文件/home/user/foo做写锁,这样尽可能允许并发,并限制了foo文件的快照、删除、重命名
- 锁的顺序也很重要,这样可以防止死锁,先获得高层级目录的锁,同级目录获取锁时候按字典排序
副本的位置
- 副本位置要满足两个目标:最大化数据的可靠性、可用性,以及带宽利用率
- 为了利用率需要将数据放到机架内,但为了可靠性需将数据跨机架存放
- 机架内的带宽要远大于机架顶部的交换机的in/out带宽
- 因为跨机架存储,所以写就必须跨机架做复制了,这也是一种权衡
创建、重复制、再平衡
- 创建的原因:选择低磁盘使用率的;想限制最近创建文件的数量,写文件意味着未来即将会有流量;为了高可用跨机架复制
- 如果副本数低于用户指定的,或者提高了副本数量
- 丢失2个副本(如果一共有3个副本)的chunk,优先级比丢失1个的高
- 优先重复制最近活跃的,而不是最近删除的chunk
- master选择优先级最高的,然后指定某个chunk-server来clone这个chunk
- 为了不影响用户,master限制了集群,以及chunk-server的活跃clone数量
- chunk-server本身也限制了读chunk的带宽
- 周期性的检查当前集群的副本分布,然后选择更好的分布
- 对于新上线的机器,master会周期性的往新机器上添加数据,而不是瞬间填满
- master也会删除一些副本,通常是使用率比较高的,以达到平衡使用率
垃圾收集
- 文件被删除后并不是立即被删除,而是等待一段时间,等执行垃圾收集时再删除,这可以使设计简单,并使系统更可靠
- 当删除文件后,master立刻记录删除log,并将文件rename放到隐藏文件区域
- 当超过三天后文件就会删除(并删除所有chunk-server上的chunk),三天内还可以继续读取并恢复
- master和chunk-server会定期发心跳,当master发现某个chunk不在meta-data列表中就可以删除了,之后chunk-server也可以删除这个chunk
- 分布式垃圾收集是很困难的实现,但GFS的实现很简单,任何master不知道的chunk都是垃圾
- 提供垃圾收集的好处是:分布式环境下master立即删除的指定可能会丢失,chunk-server也一样,而统一的垃圾收集可以提供更可靠的保证
- 垃圾收集属于master的后台任务,可以批量执行,这样就平摊了每次的开销,master可以在低峰期运行,这样可以即时响应客户端
- 延迟回收提供了一种保护机制,防止误删除
- 延迟回收的问题是,如果有大量临时创建并删除的文件,并不会真的删除,导致磁盘资源使用紧张
- 解决办法是,如果被删除的文件被再次调用删除命令,后台会加速删除进度
- 另外用户可以指定某些文件的复制和回收策略,可以指定某目录下的文件不复制,删除后就真的立刻删除
过期副本的检查
- 当chunk-server宕机后,就不会接收变更,导致某个chunk变成过期的
- 当master分配租约时,就会增加chunk的版本号
- master和副本都会记录这个版本号到持久存储中
- 当chunk-server重启后会向master汇报状态,此时master就可以检测出过期副本
- master会删除过期副本,如果发现chunk-server的版本号>自己的,就更新这个版本号(可能是分配租约失败导致的)
- 客户端或者chunk-server在读数据,或者clone时,都会验证版本号,保证读的是最新数据
容错和诊断
高可用
对于大规模集群来说,要认为失败是常态,而要保持整个集群的高可用也是一个挑战,对此常用的方式为:
- 快速恢复,不区分是怎么失败的,只要失败了就kill进程然后重启服务
- chunk-复制,未来可能会增加奇偶校验和纠删码,由于整个系统主要是读和append所以整个复杂度是可控的
- master复制,需要将操作log复制到多个机器,并且远端都回复了本地也写盘成功了才算提交成功
- master宕机后只需要简单重启就可以了,新的master就会继续拿到log继续操作
- 客户端可以通过DNS名字来访问master
- GFS还提供了 影子master功能,跟master会有一些延迟
- 影子master提供了更好的可用性,但不能处理写,另外会读到一些过期数据
数据完整性
- 对于损坏的数据可以从其他副本读取,为了检查当前副本是否损坏,不能从其他机器读数据,而要增加校验功能
- 原子的append,在不同副本中可能就是不一致的,因此每个chunk-server都需要保证自己的数据是一致的
- 每个chunk按64K划分,每64K都有一个32位的chunsum,可以被持久化
- 当其他chunk-server或client读取本chunk-server的一段数据时,会先做chunksum,如果有误则返回错误,这样就不会把损坏的数据传播出去
- 此chunk-server会把这个信息上报master,master会指示它去其他chunk-server再获取正确的数据,并把错误的副本删除
- checksum对于读的影响很小,因为并没有I/O操作
- 对于写也做了优化,因为大多数场景都是append,这时候只要更新最后一个checksum即可
- 即使最后的的这个check-sum有问题,在下一次读取的时候也会被发现
- 如果是覆盖写,就得将覆盖的这段范围做一次读取,然后计算校验和,再写入,最后计算校验和并写入,如果读取时少读了一段,那么校验就不对了
- 对于那些很少被读到,但损坏的副本,chunk-server在后台会定期扫描,当发现有不正确的,就重新生成正确的副本,并删除损坏的
诊断工具
- GFS提供了一套完整的日志记录,用于发现问题,负载测试、性能测试观察
- 日志中包含chunk-server启动、停止等事件,所有的RPC请求和响应
- 日志可以随意删除,不影响线上服务
- 通过对比RPC请求的读和写,可以重构整个交互历史,并发现问题
- 日志是顺序写,并支持异步,所以对性能影响非常小
测试
基准测试
测试环境使用了 1个master,2个备master,16个chunk-server,以及16个客户端
1.4G的CPU、2G内存、80G 5400转磁盘、100M全双工交换机
19个机器都在一个交换机下,16个客户端在另一个交换机下,他们两者通过一个顶层交换机连接1G带宽
读
- 每个客户端端随机读 320G数据集的4M内容,重复256次
- chunk-server一共有32G内存,linux的 buffer cache差不多是 10%的使用量
- 对于读来说,最大带宽就是125M/秒,或者是12.5M/每个机器
- 一个客户端读的时候,差不多是 10M/秒,相当于是峰值的80%
- 16个客户端同时读,速度是6M/s,差不多是峰值的75%,因为多个客户端可能在同时读一个chunk-server
写
- N个客户端并行写入N个文件,每批次1M一共写1G
- 理论上限是 67/秒,因为有副本复制的情况
- 单个客户端写时6.3M/秒,主要是push数据到chunk部分的管道交互这块使用的不好
- 导致延迟从一个副本传到另一个副本
- 16个客户端聚合写的速率是35M/秒,随着客户端数量增加冲突也在增加(同时写一个server)
- 写需要操作副本,所以比读的影响更大
- 不过总体看对于聚合写影响没有那么大
append
- N个客户端并发append到一个文件
- 性能受chunk-server的带宽影响,而跟客户端数量无关
- 单个客户端时 6M/秒,16个是4.8M/秒
- 实际情况是 N个客户端写M个文件,N和M都是几十到几百不等
- 因此chunk-server的带宽和冲突不是大问题
- 不同客户端可能写一个chunk-server的不同文件
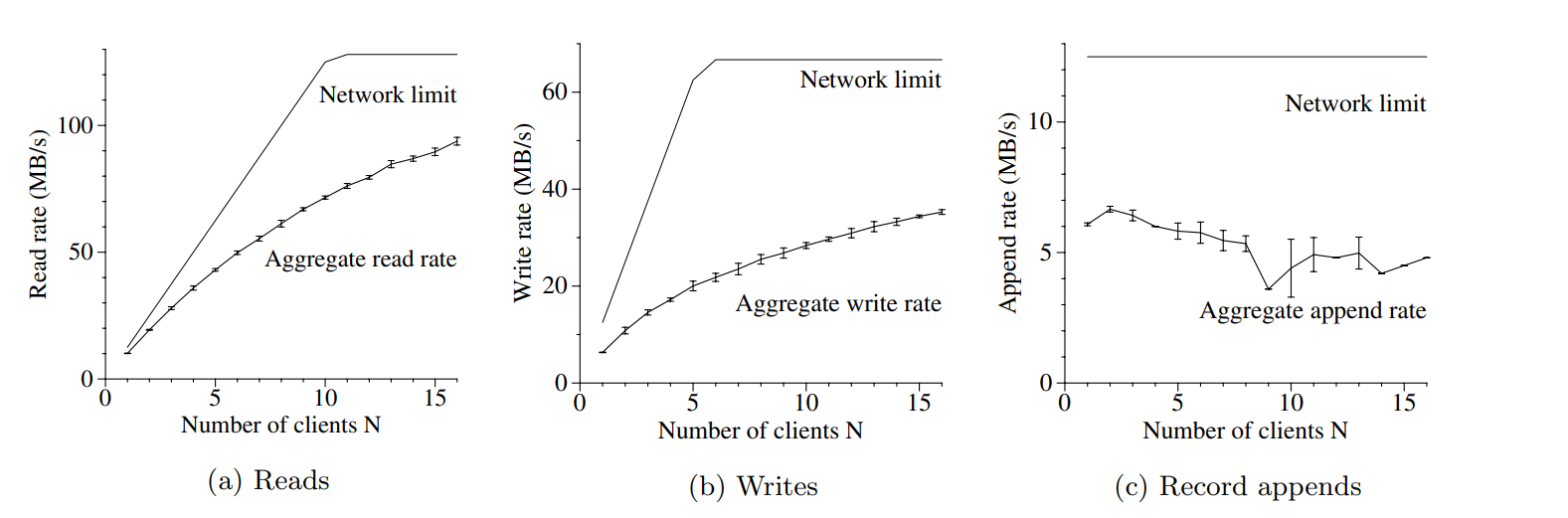
Figure 3: Aggregate Throughputs. Top curves show theoretical limits imposed by our networktopology. Bottom curves
show measured throughputs. They have error bars that show 95% confidence intervals, which are illegible in some cases
because of low variance in measurements.
真实世界的数据
目前有A、B两个集群
- A集群给研究人员和开发使用,用于数据分析,并将结果写回chunk-server
- B集群用于产生数据,期间很少人工干预
- 集群的总元数据大概 几十G,大多数是chunk-server的64K的checksum
- master的元数据总量很小,只有几十M,所以内存不是问题
- 每个元数据包括:拥有者、权限、文件->chunk映射、chunk版本
- chunk-server恢复很快,大概几秒,master会慢些大概30-60秒
- 写入大概是30M/s,读的速度要比写的快
- master的QPS 大概是 200-500
- 早期版本master也有瓶颈,后来加入了 二分查找就好了,如果想进一步提速,还可以增加一个hash表
- 对于1.5W个chunk,600G数据,为了不影响集群正常业务做了限速恢复,大概23.2分钟可以恢复完,速度大概440M/s
- 对于丢失两个副本的,会有更高优先级,266个chunk只有一个副本,可以在 2分钟内复制完
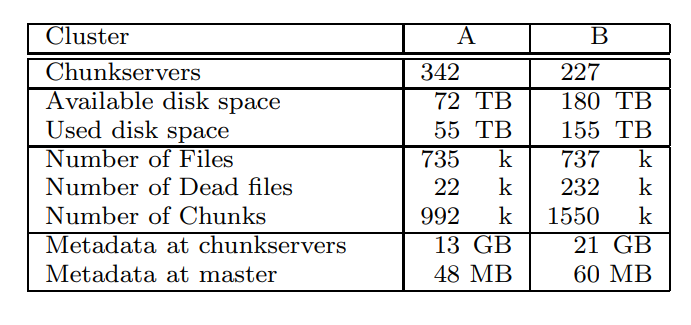
Table 2: Characteristics of two GFS clusters
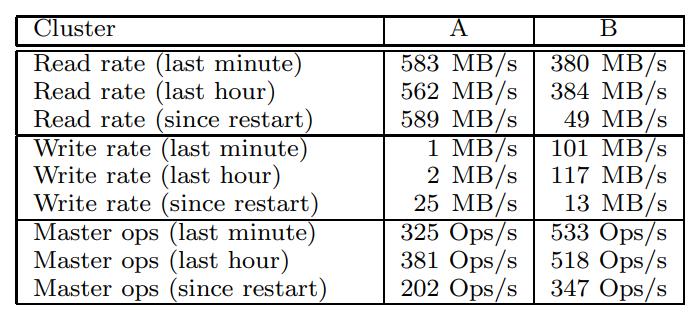
Table 3: Performance Metrics for Two GFS Clusters
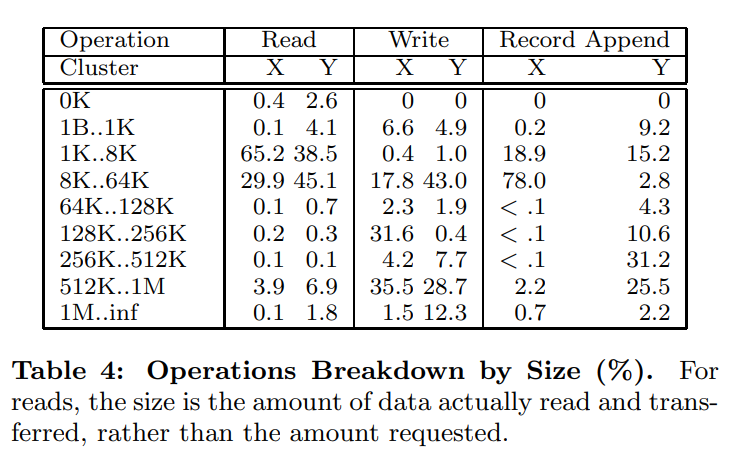
实际的读取情况,如下图
- 读分为两种,小数量(小于64K)读,一般是大文件的随机读取,或者是大量读(大于512K),也就是顺序读
- 写也有两种,小量的写(小于64K),或者大量写(大于256K),一般是buffer满了在flush
- Table5展示了各种读写情况
- append和write比例大概是108:1,另一个集群大概是8:1
- 覆盖占变更数量的0.0001%以下
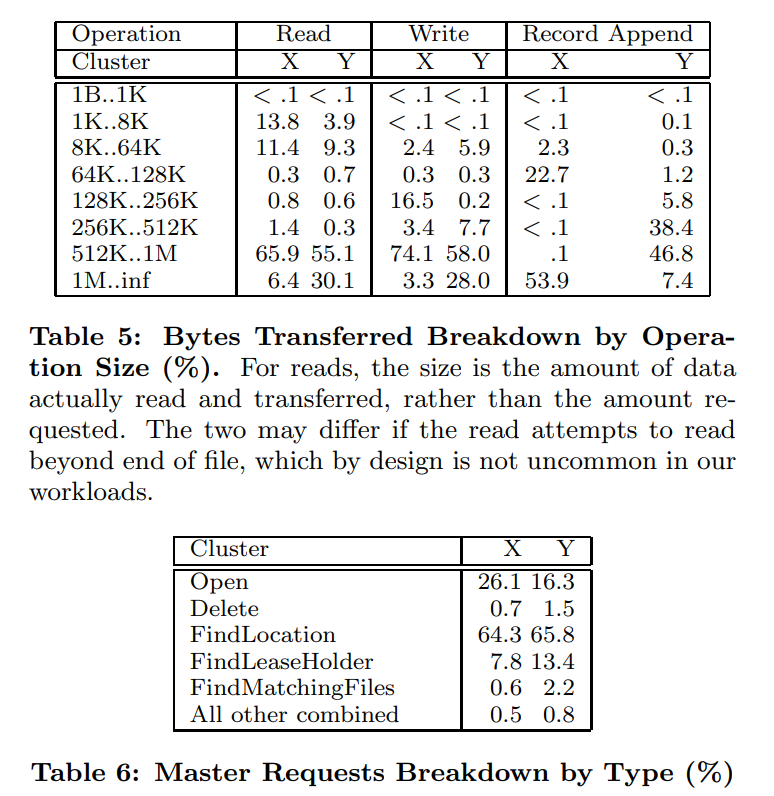
master
- 大多是查找chunk位置的
- FindMatchingFiles 是一个模式匹配操作,比较耗费资源
总结
经验
- 最初的GFS只是作为后台文件系统使用的
- 之后不断增加了需求,现在可以应对各种场景
- 原先权限、配额几乎都没有,现在都完善了
- 比较大的问题跟linux内核和磁盘有关,有的磁盘号称支撑各种IDE协议,但只支持最新的
- 这些问题很难发现,会导致偶尔不兼容出现数据损坏
- 之后增加了checksum,又修改了内核
- linux内核早期的问题,fsync()的时间跟文件大小成比例,而不是修改的大小,之后升级了版本
- linux的读写锁问题,从磁盘读数据页,或者修改mmap中对应的磁盘数据时会持有锁
- 当磁盘线程对之前映射的数据进行分页时,会阻塞网络线程将新数据映射到内存中
- 主要限制是网络接口而不是内存拷贝,所以用pread来代替mmap,但会有一些内存拷贝开销
相关工作
- GFS有点类似AFS,但提供了透明的文件移动来实现容错,这点类似xFS
- 考虑到存储越来越便宜,GFS不用RAID这种复杂方式,而是多副本复制,消耗的空间比xFS和Swift大
- GFS不使用任何缓存,因为实际的场景用不到
- 不适用共识算法,而用一个master,这样可以大幅度简化设计
- GFS的架构跟NASD最为相似
- GFS的生产者消费者模型有点类似 River
- River是内存级别的,容错不行,支持N * M,而GFS是一个生产多个消费
- GFS只考虑普通硬件
总结
- GFS在设计的时候就考虑到了规模和成本问题,有一些场景是针对谷歌特有的
- 在设计之前也参考过传统的分布式文件系统,但跟我们预想的有很大偏差
- 将失败作为常态,优化那些大部分被追加(并发的),之后在顺序读取的场景
- 设计了失败容错机制,并可以实时检测修复损坏数据、复制丢失的副本
- 增加了checksum,以应对磁盘驱动问题
- 单个master的设计也不是瓶颈
- 目前在谷歌运行良好