Raft论文
Introduction
Raft算法等价于 Multi-Paxos,但是结构上有所不同;另外比Paxos更容易懂一些
Raft算法也提供了很好的工程实践,其目标就是增强 易懂性
Raft算法将一致性算法的几个关键点隔离了:
- leader选举
- log复制
- 安全性
- 增强了一致性以减少需要考虑的状态数量
另外Raft算法包含了一个新的机制,也就是集群的成员变更;通过覆盖多数派来保证 安全性
共识算法允许一组机器来实现一致性的工作,能实现容错,这个特性让其能构建大规模分布式系统;并主导了最近10年的一致性算法
大多数共识算法的实现都考虑了Paxos或者受其影响,也是教学的主要工具,但这个东西太难懂了
Paxos的架构需要复杂的变更来支持实际的系统
在跟Paxos算法做斗争很久后,我们发现了一个更容易的共识算法:Raft
它的设计目标是 容易理解,我们构建这个算法可以用于实际系统,并比Paxos算法更容易理解
我们希望算法能帮助开发者构建直觉,重要不是算法是否能工作,而是为什么它能工作
在实现Raft时,我们应用了特定的技术来提高理解性,包括组件的分离:
- 领导者选举
- log复制
- 安全等
相比Paxos,Raft减少了不确定性的程度、以及服务器之间不一致的方式
两所大学43个学生都认为Raft比Paxos更简单,33个学生能回答关于Raft胜过Paxos的问题
Raft跟现有的共识算法有很多相似性,但有几个新特性:
- strong leader,比其他共识算法的leader更强;比如日志实体 只能通过leader流向其他服务器,这简化了日志复制管理,也更易懂
- leader election,增加了一个随机时间,只是在共识算法的心跳机制上增加了一些小改动
- membership changes,使用了一种新的联合共识机制,让两个不同的配置在多数派节点上有重合,这允许在配置变更期间集群可以继续运行
Raft的安全和已经被证明,并且性能跟其他共识算法也差不多,但是更易懂
Replicated state machines
共识算法通常出现在 复制状态机 中,状态机就是一组服务,并计算出相同的状态相同副本,这样就可以实现高可靠,可以解决分布式系统中的容错问题
比如大规模的分布式系统一般会有单个leader,如GFS、HDFS、RAMCloud等
他们用一个独立的复制状态机来管理 leader选举,并存储配置信息,用来防止leader宕机
复制状态机包括:
- Chubby
- Zookeeper
复制状态机 的实现是 复制日志
每个服务存储了包含一系列命令的日志,然后按顺序执行这些命令
每个日志都包含了相同顺序的命令,所以每个状态机都会处理相同序列的命令;由于每个状态机都是确定性的,所以会产生同样的状态,以及相同的输出序列
保持 复制日志的一致性,就是共识算法的工作
一个服务器上的共识算法模块,会收到客户端的命令,然后将其保存到 log中,并跟其他其他机器通讯,以确保每个日志最终以 相同顺序包含相同请求
这样即使有机器宕机也不怕
一旦命令被正确的复制,每个机器的状态机都会按顺序处理他们的日志,然后产生输出到客户端
这样一组机器看起来就像是一台机器,实现了状态机的可靠性
用于实际系统的共识算法一般有下面一些属性:
- 确保安全性,在非拜占庭模型下,绝不会返回不正确的结果,包含网络延迟、分区、丢包、重复、乱序
- 功能齐全(可用性),只要大多数机器彼此能相同通讯,并和客户端通讯;比如5台机器可以容忍任何2台机器宕机;机器停机重启,并通过持久化的状态恢复并重新加入集群
- 不依赖时钟来确保日志的一致性,时钟故障,极端的延迟;在最坏情况下会导致可用性问题
- 通常情况下,只要大多数响应了一轮RPC,命令就算完成了,即使少量的服务运行过慢,也不影响整个系统性能
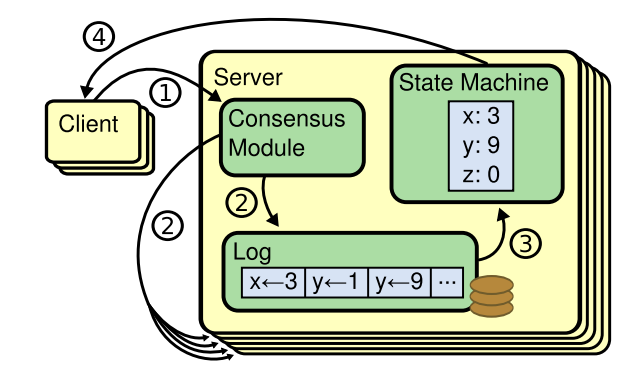
Figure 1: Replicated state machine architecture. The consensus algorithm manages a replicated log containing state
machine commands from clients. The state machines process
identical sequences of commands from the logs, so they produce the same outputs.
What’s wrong with Paxos?
在过去的10年里,Paxos算法几乎就等同于 共识,在各种教学课程中也是用Paxos来教的
Paxos首先定义了就单个值达成一致的协议,也就是复制单个日志实体,也叫作 Basic Paxos
之后结合此协议的多个实例,以一系列促进一系列决策,如日志,这样的协议称为:Multi-Paxos
Paxos同时确保了 安全性、活性,并支持成员变更
它的正确性是被证明过的,同时大多数场景下性能也不错
Paxos有两个问题
- 极其难以理解
- 没有为构建真实的实现提供基础
完全解释Paxos非常困难,只有少数人能理解
Raft的作者也是花了一年的时间,看了很多简单的说明,加上自己的简化设计,才理解了Paxos
很多人尝试简化Paxos的描述,首先是对Basic Paxos做描述,但这也很困难
Paxos的不透明源自于它的单一指令共识作为基础,它被分为两个阶段,也没有直观的解释,不能独立理解
而Multi-Paxos则更复杂了和更微妙了
我们认为,就多个决定达成共识的整体问题(一个日志而不是一个条目),可以分解为更直接、更明显的方式
Lamport主要是介绍了Basic Paxos,而对Multi-Paxos的描述不多,现在也没有对Multi-Paxos算法达成一致的实现
Lamport描述了很多Paxos的可能方面,但是缺少细节实现,Lamport也对其有过优化
但优化的实现跟原始的算法有些不同
Multi-Paxos的最初实现是谷歌的 Chubby,但这是不开源的
更进一步来讲,Paxos算法对于构建真实系统来说很不好,这是因为单指令分解的结果导致的
比如,独立的选择一个日志条目集合,然后将他们融入到一个连续的日志中,这样做没有什么好处,只是增加了复杂度而已
而围绕着日志设计系统会简单且有效,新的条目是按照约束追加的
另一个问题是,Paxos的核心是类似对称的点对点,之后又增加了一个弱的leader来优化
在一个简化的世界中,只有一个决策,这样做是有意义的,但对于真实系统来说没什么用
对于真实系统来说,如果要对一系列的值做出决策,那么选择一个leader是最快而有效的方式
结果就是,Paxos对于构建真实系统没什么帮助,所有的实现都是从Paxos开始的,然后他们就会发现其架构有很大的不同,并开发了一个不同的架构,既费时有容易出错,而理解Paxos又加剧了这个问题
Paxos有很好的定理证明,但是真实的系统跟Paxos有很大不同,下面来自是Chubby的论文中的一段话:
Paxos算法的描述 和 真实系统的需求有巨大的差距,而最终的系统是未经证明的
于是我们得出结果,Paxos对于教学、或者构建真实系统都不好
考虑到共识算法在构建大规范分布式系统的重要性,我们决定是否能设计一个比Paxos更合适的共识算法
而Raft 就是实验的结果
Designing for understandability
我们设计Raft的目标
- 对于系统构建,提供一个完全并有效的基础
- 可以大量减少开发者设计的工作
- 在所有条件下都必须安全
- 在典型的情况下必须可用
- 最重要一点,必须是:容易理解的
- 必须让大多数人能理解,也能让开发者理解并实现这个算法
在设计Raft算法时,我们有很多地方需要在不同的方式中选择
在多种备选方案中,我们主要考量是否容易理解,解释这个实现困不困难
比如状态空间的复杂程度、是否有不易察觉的隐含条件
我们需要让读者能完全理解这些方式
我们使用了两种技巧
第一个是问题分解,我们将问题划分为相对独立的方式,这样就可以解决、解释、理解这些方式
比如,Raft中,leader选举、log复制、安全性、成员变更都是独立的
第二点是,通过减少需要考虑的状态数量,来简化状态空间;
这样系统更一致,并消除了不确定性;Raft禁止日志有空洞,因为这种方式会让彼此变得不一致
大多数情况下我们都试图消除不确定性,不过某些情况下的不确定性反而提高了易懂性
比如,引入随机化就带来了 不确定性,但是通过处理类似的方式,来减少状态空间数量,我们就是使用了随机化来简化了leader选举的
Raft consensus algorithm
Raft算法管理复制log,figure2对其做了总结;figure3是算法的关键属性
Raft首先要选举出一个leader,这个leader负责管理日志复制;接受客户端的日志条目,并复制到其他服务器
当leader将log条目应用到自身的状态机后,就通知其他服务器
leader可以简化日志管理的工作,比如leader可以决定在日志中的哪个位置防止条目,而不用跟其他机器协商,这种就属于强leader的模式了
并且数据的流转,只能是 leader -> other
如果leader宕机了,就需要重新选举
而通过强leader的方式,Raft可以将一致性问题分解为三个独立的子问题:
- leader election,当现有的leader宕机了,就需要重新选举
- log replication,leader从客户端接受日志条目并复制到所有机器,并强制他们的日志跟自己的一致
- safety,figure3总结了Raft状态机的安全属性,只要有服务器对其状态机应用了某个特定的日志条目,那么其他机器也要保持一致,后面会讨论如何确保这个属性,其解决方案涉及到选举机制的额外限制
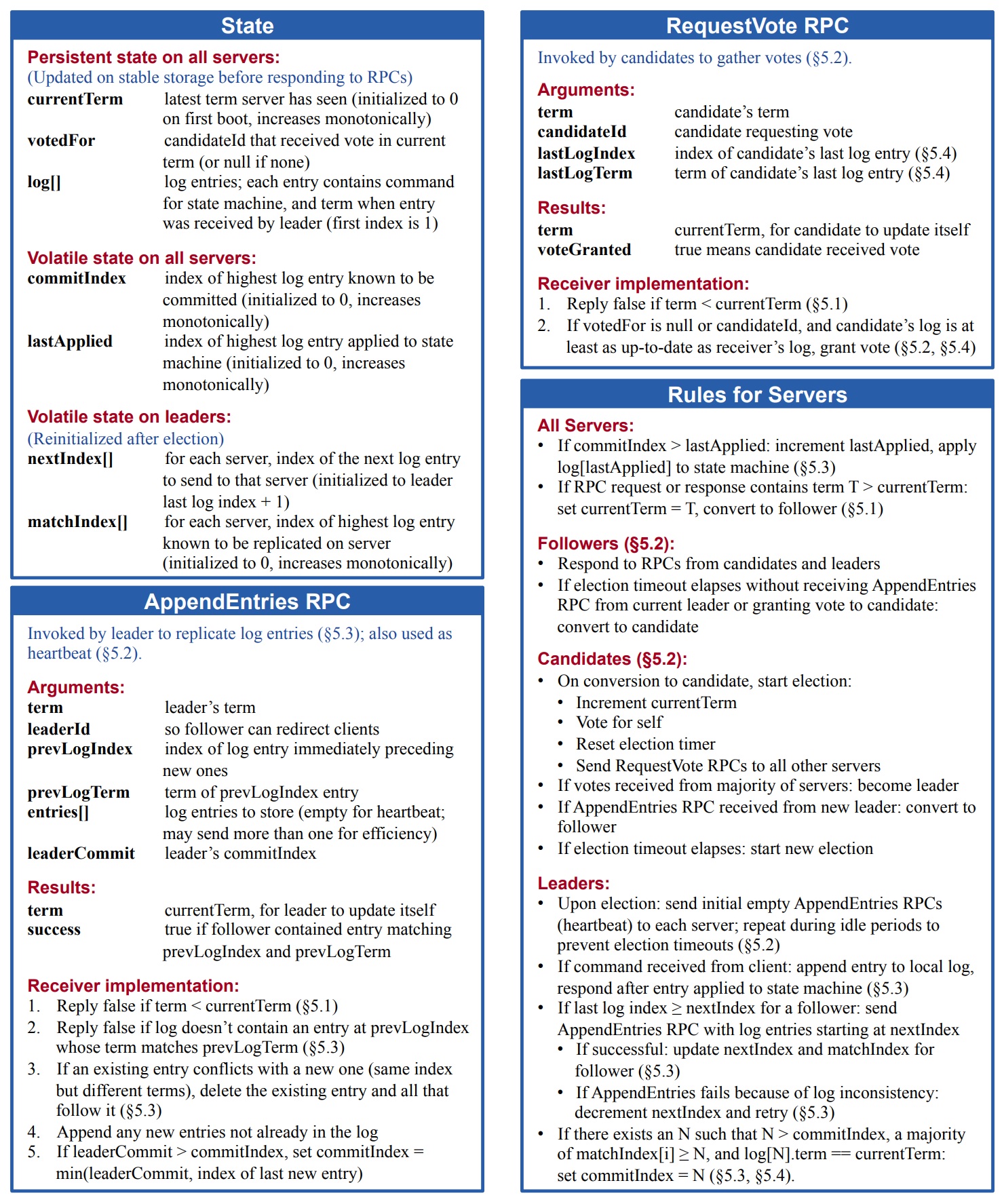
Figure 2: A condensed summary of the Raft consensus algorithm (excluding membership changes and log compaction). The server
behavior in the upper-left box is described as a set of rules that trigger independently and repeatedly. Section numbers such as §5.2
indicate where particular features are discussed. A formal specification [31] describes the algorithm more precisely.

Figure 3: Raft guarantees that each of these properties is true
at all times. The section numbers indicate where each property is discussed.
Raft basic
Raft集群中包含了多个服务,一般是5个服务器,也就是说最多能容忍2台宕机
任何时刻服务器都处于三种状态之一:
leader、follower、candidate
集群中只有一个leader、所有的follower不会发送消息,只是被动的接受leader信息
leader处理所有的客户端请求,如果请求发给了follower,它会转给leader
第三种角色是 candidate,这是用于选举leader时的临时角色
figure 4 描述了 三种角色的转换关系
Raft将时间划分为 任意长度的条目 terms,figure 5展示了这一点
terms的编号是连续的整数,每个term由一个选举开始,此时一个或者多个candidate会创始将自己变成leader
如果一个candidate赢得了选举,那么后面的时间它都是leader
有时候因为split vote导致没有leader产生,那么就再开始新一轮的选举
Raft会确保一个集群最多只有一个leader
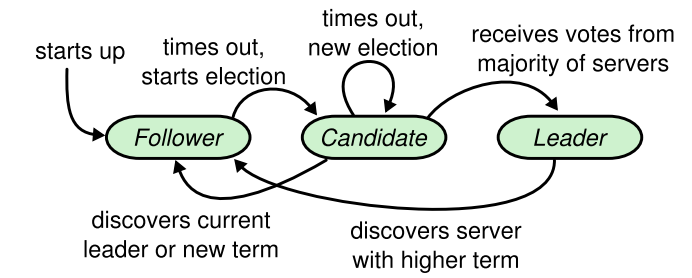
Figure 4: Server states. Followers only respond to requests
from other servers. If a follower receives no communication,
it becomes a candidate and initiates an election. A candidate
that receives votes from a majority of the full cluster becomes
the new leader. Leaders typically operate until they fail.
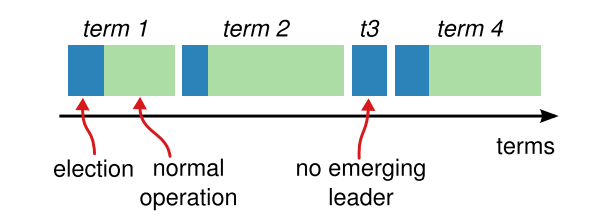
Figure 5: Time is divided into terms, and each term begins
with an election. After a successful election, a single leader
manages the cluster until the end of the term. Some elections
fail, in which case the term ends without choosing a leader.
The transitions between terms may be observed at different
times on different servers.
不同服务器上的不同时间,能观察到 任期的转换
在某些情况下,服务器可能不会察觉到选举,甚至整个任期
Raft使用的是逻辑时钟,这使得它能发现过期的leader
每个服务存储一个 当前的term编号,并随着时间推移单调递增,而服务通讯时就会交换彼此的term
如果一个服务的term比其他服务要小,就将当前term更新为更大的值;如果leader或者candidate发现自己的term过期了,就立刻转换为follower状态
如果服务收到了过期的term编号,就拒绝这个请求
Raft的服务使用RPC进行通讯,基本的共识算法请求包含两种类型的RPC
- request vote RPC,在选举期间,由candidate触发
- append entries RPC,leader复制日志时使用,这个RPC还附带了心跳功能
后面还增加了 第三种RPC,用于在不同服务之间 传递快照
服务器收不到RPC后,会重试,另外PRC也可以并行发送提高性能
leader election
Raft使用心跳机制来触发leader选举;当一个服务启动时候,它首先是follower状态
如果它收到了leader或者candidate的有效RPC,那么它还是follower
leader会周期性的发送心跳包(append entries RPC,不携带日志数据)给所有的follower,告诉他们自己仍然是leader
如果一个follower一个周期内没有收到通讯,那么就会触发 election timeout
此时它会假设当前没有leader,并开始选举新leader
这个follower首先递增他的term,并转换为 candidate状态,它会将vote投给自己和集群中其他服务器
此时会持续这个状态,直到下面三种情况之一发生:
- 它赢得了选举
- 另一个服务器当选为了leader
- 选举周期过了,没有赢家
如果一个candidate在同一任期(same term)内赢得了集群内大多数服务器的投票,那么久就赢得选举
每个服务器在一个任期内,最多投票给一个candidate,基于先来先投票的原则(后面会接收一个附加的投票约束条件)
多数派的规则确保了在特定的任期内,只有一个candidate可以赢得选举,安全属性参见 figure 3
一旦candidate变成了leader,它就会发送心跳包给其他服务器,建立权威,以防止再次选举投票
如果在 vote过程中,candidate收到了一个 append entries的RPC请求
- 如果这个请求的term至少跟candidate的term一样大,那么对方就是leader,candidate转为follower
- 如果比candidate的term小,则candidate拒绝这个RPC,并继续维持candidate的状态
我们在前面提到过,选举会出现 第三种情况:选举周期过了,没有赢家
这是因为 split vote导致的,没有赢家,没有输家;因为每个candidate都是同时启动的;然后同时超时,这样的话,会导致split vote无限循环
解决办法是增加一个随机的超时时间,当一轮结束后,没有赢家,在等待一个随机的时间后,大概是 150ms - 300ms
candidate开启了新一轮选举
由于是随机的时间,所以第一个超时的candidate会触发新一轮投票,那么它就会当选为leader
选举这个例子说明了,可理解性如何引导我们在设计方案之间做出选择
作者们最初并不是用超时,而是采用了排名系统,每个candidate都被分配了一个唯一的排名;可以通过排名来选择candidate
如果一个candidate发现另一个更大,则它就变成follower,这样更高排名的candidate就容易变成leader
但是这种设计在可用性方面有微妙的问题
如果一个高排名的服务挂了,那么一个低排名的服务就需要超时变成candidate;但是这个过程太快,可能会导致重新选举leader发生
作者们几次修改了算法,但是每次修改后会发现,又来带了新的边界问题
最终,发现使用随机超时这种即使,更容易理解
Log replication
一旦leader被选举了,它就开始处理client的请求
每个client请求都包含了一个被 复制状态机执行的命令;leader首先将这个命令append到自己的log中
然后发布 append entries RPC到所有的机器,当这个条目被安全的复制了,leader就将条目应用到自己的状态机中,并返回客户端的请求
如果因为follower挂了、运行缓慢、丢包,那么leader会无限制重试,直到所有的follower存储了条目
日志的组织方式为 figure 6,当leader接受了条目就将其存储,其内容为一个状态机命令、以及一个term编号
term编号用于设别 log间的不一致性,并保证了 figure 3中的安全属性
每个日志条目也有一个整数的下标
leader会考虑到如何应用一个日志条目到 状态机,这样的条目称为:committed
Raft会保护条目被持久化,并最终由所有可用的状态机执行
一旦leader创建的日志条目被大多数机器复制了,那么这个日志就 committed
比如figure 6 中的 条目7,三个机器都被复制了,所以就处于committed
另一个特点是,只要当前的日志提交了,那么它前面的日志都是处于 committed,包括由任前leader创建的条目也是一样
leader变更时会由一些隐含的细节,后面会讨论;同时这样表明committed 这个定时是安全的
leader会跟踪它知道的最高的 committed 索引,也包含了将要将要 append entries RPC的索引(包含心跳),这样其他机器最终会发现它
一旦follower学习到了一个日志条目被 committed,它就将条目应用到他本地状态机(按照日志顺序)
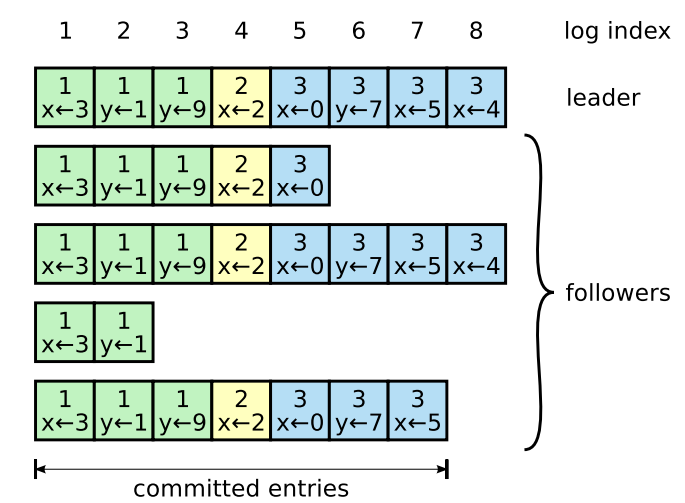 Figure 6: Logs are composed of entries, which are numbered
Figure 6: Logs are composed of entries, which are numbered
sequentially. Each entry contains the term in which it was
created (the number in each box) and a command for the state
machine. An entry is considered committed if it is safe for that
entry to be applied to state machines.
我们设计Raft日志机制来维持高度的一致性,这种一致性用于不同机器上的log
这样做不光简化了系统行为,更容易预测,同时也是安全属性中的一个重要属性
Raft维持了下面属性,这些是 figure 3中的日志匹配属性:
- 如果两个条目在不同的日志中有相同的索引和term,则他们存储了相同的command
- 如果两个条目在不同的日志中有相同的索引和term,则他们前面的日志也是一样的
第一个属性的事实是,leader在给定的term中最多只创建一个日志索引条目,并且绝不会更改他们的位置
第二个属性由append entries来执行一致性检查来保证
当发送一个 append entries RPC时,leader在日志中包含紧挨着新条目之前的条目的index和term
如果follower没有在它的日志中发现相同index和term的条目,则拒绝
一致性检查归纳为如下阶段:
- 初始化空的日志状态,满足日志匹配属性
- 一致性检查包含了日志匹配属性,当日志被扩展时
结果就是,只要 append entries返回成功;那么leader就知道follower的日志跟,通过新条目记录的自己的日志,是相同的
正常情况下,leader的日志和follower的日志都会保持一致,所以append entries的一致性检查不会失败
而当leader宕机会导致日志的不一致,旧的leader还没有完全复制它的日志
而这种不一致,在之后的leader、follower持续宕机后又会引发一系列的不一致
figure 7展示了这种场景,follower的日志可能跟新的leader不一致
- follower 可能缺少leader的日志
- follower可能存在leader中没有的日志
- 或者上述两种情况都存在
缺失的,以及多余的日志可能跨多个terms
在Raft中,处理这种不一致的方式是,强制让follower拷贝leader的日志,然后用leader的日志覆盖自己的
通过这种方式,就可以保证一致性,后面会解释再加上一个限制,就是安全的
为了让follower的日志跟leader的保持一致
leader会首先找到最近一条两边都相等的日志,然后删除follower后面的日志,并将这个点之后的所有日志都发送给follower,这样就可以实现两边一致了
所有这些操作是发生在 append entries响应之后的,leader会管理所有follower的nextIndex,它是leader将要发送给follower的下一个日志的index
当leader上任时,它会初始化所有nextIndex值,将他们调整到最后一条日志之后
如果follower的日志跟leader的不一致,在下一次append entriers检查时会发现,于是follower会拒绝
之后leader将nextIndex减1,并持续这个操作,最终就可以找到两者相匹配的那个点,此时append entries就成功了
于是删除所有不一致的数据,并用laeder的日志做覆盖,之后一致保持这个状态
这里有一个优化选项:
follower找到不一致的条目,返回给leader,这样leader就可以直接定位到一致的条目
并将所有不同的条目发送给follower,就可以减少RPC的交互
不过作者团队觉得,这样的优化不是必须的,因为发生故障的情况很少,也很少有很多不一致的条目发生
有了这种机制,当leader上任时,不需要做什么特殊操作来存储日志一致性,它被转换为正常操作了
当响应失败时,append entries一致性检查失败时,日志会被自动收敛
leader绝不会覆盖或者删除它自己的日志,它只会做append 操作
日志复制机制展现了 第二部分描述的理想的共识属性:
- Raft可以接受、复制、应用新的日志条目,只要大多数机器还存活
- 复制新的条目通常只需要一轮RPC请求,只要多数派机器有响应
- 个别慢的机器不会影响性能
Safety
前面的章节描述了Raft如何选举leader、复制日志;然而这个机制目前为止还没有完全确保,每个状态机都按照相同的顺序执行相同的命令
比如,一个follower在leader提交一批日志的时候不可用,就会触发选举当选为leader,然后它就会用新日志做覆盖,这样集群里有两个不同的状态机,执行不同的命令序列
现在要对选举leader增加一些约束,这个约束就确保了,leader的任何term都包含了在其之前提交的term
有了这些限制,就可以得到更确定的规则了,后面会展示展示leader完整性属性的证明图,并展示它如何确保复制状态机的正确行为的
选举约束
- 任何基于leader的共识算法,其leader最终都要包含所有已经提交的日志条目
- Viewstamped 算法中,即使leader没有包含所有的条目,也能被选举为leader,它是通过额外的机制在选举中/选举后将条目发送给leader,完成一致性的,但增加了很多机制和复杂性
- Raft使用了一种简单的机制,确保自选举的那一刻起,所有之前提交的term都会出现每个新的leader中
- 这就意味着不需要将条目传送到leader,所有的流转路径都是laeder->follower,并且leader绝不会覆盖已存在的日志
- Raft使用投票处理的方式避免follower赢得候选,除非它包含了所有提交的日志
- candidate必须包含多数派选票,那么每个被committed的条目在这些服务器中至少出现一次
- 如果candidate的日志跟多数派的日志,至少一样新,它才能赢得选举
- request vote RPC的月数为:RPC包含了candidate的日志信息,如果它的日志比candidate的更新,则拒绝投票
- Raft通过比较index和term来决定两个日志谁更新
- 如果两个日志的最后条目有不同的term,则最晚的那个更新;如果日志以相同的term结束,则较长的日志是最新的
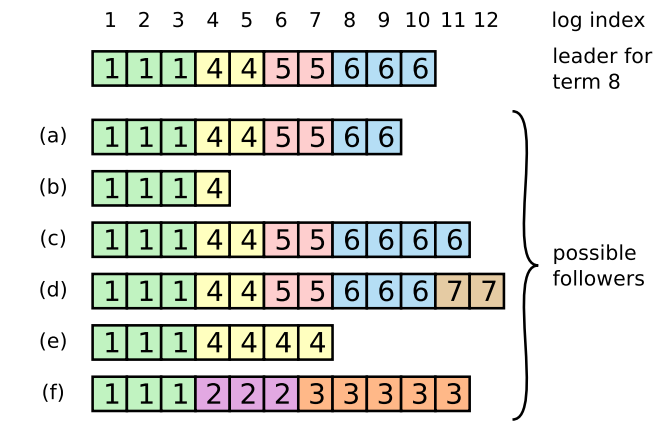 Figure 7: When the leader at the top comes to power, it is
Figure 7: When the leader at the top comes to power, it is
possible that any of scenarios (a–f) could occur in follower
logs. Each box represents one log entry; the number in the
box is its term. A follower may be missing entries (a–b), may
have extra uncommitted entries (c–d), or both (e–f). For example, scenario (f) could occur if that server was the leader
for term 2, added several entries to its log, then crashed before
committing any of them; it restarted quickly, became leader
for term 3, and added a few more entries to its log; before any
of the entries in either term 2 or term 3 were committed, the
server crashed again and remained down for several terms.
从前面的terms来提交条目
- 一旦条目被存储到多数派机器上,leader就知道当前的一个条目被提交了
- 如果leader在提交前宕机了,那么新leader会尝试完成条目的复制
- 但是leader并不能立刻得到这样的结论:前面的term一旦存储到多数派的机器上,它就被提交了
- figure 8展示了这种情况,一个旧条目被存储在多数派机器上,但仍然被新leader给覆盖了
- Raft并不是统计前面term的副本数量再提交日志条目的;只有当前term的副本数量足够了才会提交日志
- 一旦当前条目以这种方式提交了,那么它之前的条目也被提交了;这是满足了log 匹配属性
- 在某些情况下,leader可以安全的认为旧的条目被提交了(如被存到每个服务器上);但Raft使用了更保守的方式
- Raft在提交规则中增加了额外的复杂性;当leader从先前的terms中复制条目时,日志条目会保留他们的原始term编号
- 在其他共识算法中,如果新leader重新从以前terms中赋值条目,必须使用新的term编号
- Raft方式使日志条目的更容易理解,因为它随着时间流逝,在不同的日志维持了相同的term编号
- 和其他算法相比,Raft中新leader从之前terms中发送的日志条目更少
- 其他算法在提交前,必须发送冗余日志条目来重新编号
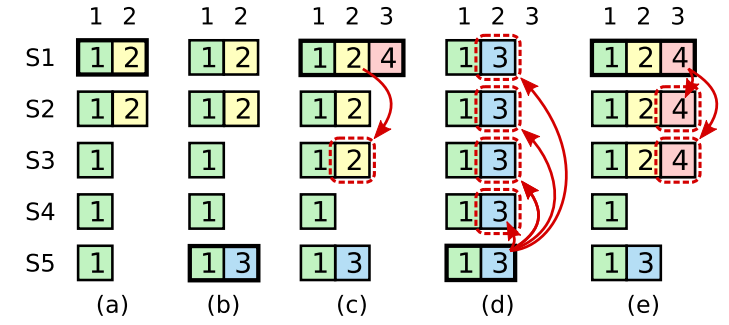 Figure 8: A time sequence showing why a leader cannot determine commitment using log entries from older terms.
Figure 8: A time sequence showing why a leader cannot determine commitment using log entries from older terms.
In (a) S1 is leader and partially replicates the log entry at index 2.
In (b) S1 crashes; S5 is elected leader for term 3 with votes from S3, S4, and itself, and accepts a different entry at log index 2.
In (c) S5 crashes; S1 restarts, is elected leader, and continues replication. At this point, the log entry from term 2 has been replicated on a majority of the servers, but it is not committed.
If S1 crashes as in (d), S5 could be elected leader (with votes from S2, S3, and S4) and overwrite the entry with its own entry from term 3. However, if S1 replicates an entry from its current term on a majority of the servers before crashing,
as in (e), then this entry is committed (S5 cannot win an election). At this point all preceding entries in the log are committed as well.
安全参数
现在来论证leader的完整熟悉,假设leader不存在完整性,那么就证明了一个矛盾
假设leader(t)从term T提交了一个日志条目
假设一个term T的leader(t)从他的term提交了一个日志条目,但是日志条目不是由未来的某个term的leader存储的
考虑到最小的term U > T 不存储该条目
- 自它的选举时刻,这个被提交的条目肯定不会出现在leader(u)的日志中(leader不会覆盖删除条目)
- leader(t)复制这个条目到集群中的多数机器,leader(u)收到多数派的投票;因此至少有一个机器同时接受了leader(t)的条目,以及leader(u)的投票
- 在投票给leader(u)之前,肯定是接受了leader(t)的条目提交;否则它会拒绝leader(t)的append entries的请求(它当前的term高于T)
- 投给leader(u)时,投票者仍然存储了条目;因为每个介入的leader都包含了条目(假设),leader不会删除条目,而follower只有跟leader冲突的时候才会删除条目
- 投票者投给了leader(u),所以leader(u)的日志必须是跟投票者是一样新的,这就导致了两个矛盾中的一种
- 如果投票者和leader(u)的上一个term一样,那么leader(u)的日志至少跟投票者一样,所以他的日志包含了每个投票者的条目;这就是矛盾的,因为投票者包含了已提交的日志,而leader(u)假设是没有的
- 否则leader(u)的日志条目就必须 大于投票者的,它也大于t,因为投票者的最后一个条目至少是T(包含来自T的提交条目);leader(u)的最后一个日志条目必须包含上一个leader提交的条目(根据假设),通过log匹配熟悉,leader(u)也包含这个被提交的条目,这就是矛盾的
- 上述过程就证明了这是矛盾的;包含所有条目的leader大于T,必须包含在term T时提交的条目
- 日志匹配属性保证了新的leader也会包含间接提交的条目
有了leader完全属性,我们可以从figure 3中证明状态机的安全属性
如果一个server将log条目应用到了一个index,那么其他服务器对于相同的index不会出现不同的条目
当一个server应用一个日志条目到它自己的状态机时,这个日志必须跟leader的相同,同时日志已提交
现在假设任意服务器上的给定日志index上的最低term,完整熟悉保证较高term的leader将存储相同日志条目,因此较晚term中的应用index服务器将使用相同的值,完全属性保持不变
Raft要求服务器按照日志index顺序应用条目,结合状态机的安全属性,这意味着:
所有服务器以相同的顺序将相同的一组条目应用到 他们的状态机上
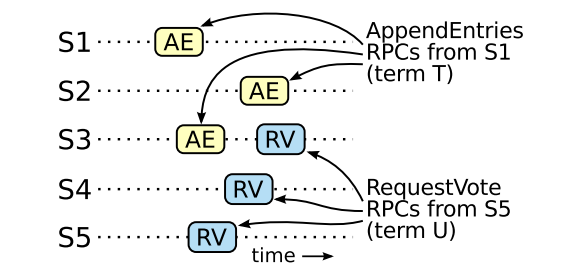 Figure 9: If S1 (leader for term T) commits a new log entry
Figure 9: If S1 (leader for term T) commits a new log entry
from its term, and S5 is elected leader for a later term U, then
there must be at least one server (S3) that accepted the log
entry and also voted for S5
Follower and candidate crashes
直到此时,我们将焦点转到 leader宕机上
而follower和candidate宕机比leader处理更容易,他们都以相同的方式处理
当后续的 request vote RPC和append entries RCP失败后,Raft需要无限的重试
如果server宕机后重启了,那么RPC会成功;如果服务在收到RCP但还没响应前宕机了,那么重启后会收到相同的RPC
Raft的RPC是冥等的,比如一个follower收到了一个append entries请求,这个请求中包含的日志条目已经存在于follower的日志中了,则follower会忽略这些条目
Timing and availability
Raft的需求之一是,安全不依赖时间
系统不会产生不一致的结果,因为某些事件比预想的更快、更慢;然后可用性(系统响应客户端的能力)必然依赖于时间
比如,在server crash时消息交换的时间会比平常更长,candidate没有足够机会赢得选举;而没有稳定的leader,则Raft没法继续处理
leader选举是Raft的一方面,时机则是最关键的,Raft有能力选举并维持一个稳定的leader,只要满足下面的时间需求:
|
|
上面的三个时间:
- broadcastTime:leader并行发送所有的RPC到集群的每个server,并等待收到的响应,再求其平均值
- electionTimeout:选举的超时时间
- MTBF:单个服务器的平均故障时间
broadcastTime应该远小于选举超时时间,这样leader就可以发送心跳包到每个server,以防止出现选举
用随机化的方式实现选举超时,也避免了split vote
选举超时应该比MTBF小几个数量级,这样系统才能保持稳定;当leader挂了系统不可用,因为选举超时,我们希望这只是总时间的一小部分
broadcastTime、MTBF是底层系统的属性,而选举超时是必选选择的
Raft的RPC要求接受者将信息持久化,所以广播时间大致是 0.5ms - 20ms,这跟具体的存储实现相关
因此选举超时时间可能再 10ms - 500ms
而MTBF通常是几个月甚至更久,所以很容易满足计时需求
Cluster membership changes
前面的所有操作,我们假设了集群配置是固定的(共识算法由一系列服务组成),而实时上,集群配置可能偶尔需要做一些变动
比如,当机器挂了需要做替换,或者修改复制的副本数
尽管可以将集群全部下线再修改配置后上线,但这会让集群在一段时间内变得不可用,另外手动操作也增加了出错的风险
为了解决这些问题,我们设计了配置变更自动化,使其成为Raft的一部分
为了保证配置变更的安全,必须确认在 转换过程的任何时间点上,不会出现两个leader有同一个term
但是,直接将 老配置切换为新配置 这种方式是不安全的
因为不可能在同一时刻将所有的机器都做切换,所以可能会出现split的风险,也就是在转换过程中,出现两个多数派(figure 10)
为了确保安全,配置变更必须使用两阶段的方式来实现,两阶段的实现有很多种
比如,有些系统,在 一阶段让老配置不可用,这样它就不能再处理客户端的请求了;第二阶段把新配置打开
在Raft中,集群首先切换到 过渡配置中,也叫作joint consensus,一旦 joint consensus完成了提交,那么系统就转换为新配置了
而joint consensus包含了新、老配置:
- 日志条目被复制到所有服务器的新、老配置中
- 新、老配置的服务器都可以作为leader
- 协议(对于选举和提交条目)要求在新、老配置中分别获得多数派
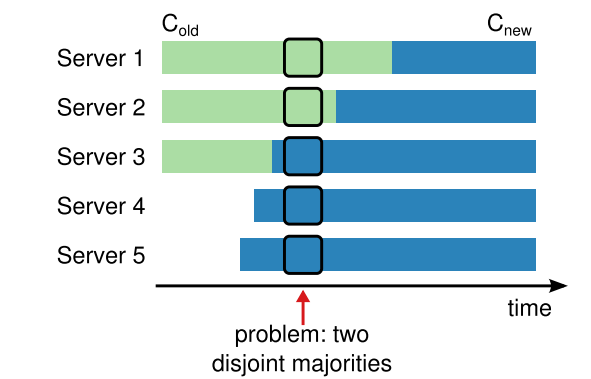 Figure 10: Switching directly from one configuration to another is unsafe because different servers will switch at different times. In this example, the cluster grows from three
Figure 10: Switching directly from one configuration to another is unsafe because different servers will switch at different times. In this example, the cluster grows from three
servers to five. Unfortunately, there is a point in time where
two different leaders can be elected for the same term, one
with a majority of the old configuration (Cold) and another
with a majority of the new configuration (Cnew).
joint consensus 允许单个服务器在不同的时间在新、老配置中转换,而不影响安全性
也就是说,joint consensus允许集群在 变更期间 继续处理客户端的请求
集群的配置使用复制日志的特殊条目,进行存储和通讯,figure 11展示配置更变处理
当leader收到 C(old) -> C(new)的变更请求,它将joint consensus信息存储起来 C(old,new),使用之前描述的状态机方式来复制该条目
一旦给定的服务器增加到新的配置条目 到log中,之后使用这个配置做进一步的决策(服务总是使用日志中最近的配置,不管条目是否提交)
这意味着,当C(old,new)被提交后, leader将会使用C(old,new)来做决定
如果leader挂了,那么新leader是基于C(old)或者C(old,new)来决定的,这依赖于它赢得了哪一方的选举,老配置candidate,还是新配置的candidate
不管是新的还是老的,此时C(new)都不能单独做出决策
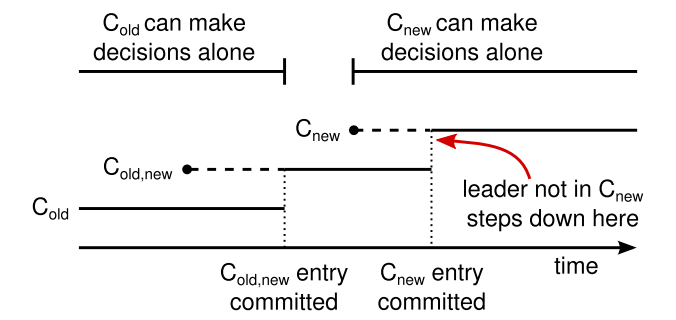 Figure 11: Timeline for a configuration change. Dashed lines
Figure 11: Timeline for a configuration change. Dashed lines
show configuration entries that have been created but not
committed, and solid lines show the latest committed configuration entry. The leader first creates the Cold,new configuration
entry in its log and commits it to Cold,new (a majority of Cold
and a majority of Cnew). Then it creates the Cnew entry and
commits it to a majority of Cnew. There is no point in time in
which Cold and Cnew can both make decisions independently.
一旦C(old,new)被提交了,那么C(old)或者C(new)都可以单独做出决定了,而根据leader完全属性,可以确保只有C(old,new)日志条目的server可以被选举为leader
现在leader可以安全的创建一个日志条目C(new)并将其复制到集群 ,自后配置被复制到所有机器上
当C(new)规则下提交了新配置,那么老配置就不重要了,它们没有新配置所以可以被关闭了,figure 11 显示了任何时刻C(old)和C(new)都不单独做出解决,这就保证了安全性
此时,我们还有三个问题没有解决
- 新sever没有存储任何log,如果将这种状态加入到集群中,他们需要很长时间才能赶得上(日志的term),此时不能提交任何新日志条目;为解决此问题,Raft增加在配置变更前增加了一个阶段,新server加入集群后作为 无投票者(leader只是将日志复制给他们,但会忽略他们),等新server追上来后,就可以按上述方式继续处理配置变更
- 新leader不是新配置的一部分,此时新leader一旦提交C(new)日志就会被下线(返回follower状态),这意味着会有一段时间(提交C(new)时),leader管理了一个不包括自己的集群;它复制日志条目,但不把自己作为多数派。leader转换发生在C(new)提交的时,因为这是新配置可以独立运行的第一个点(leader总是来自C(new)),在这之前只有C(old)的服务器才能被选为leader
- 那些要从集群中删除的server,这些server接收不到心跳,于是触发了超时并开启选举,他们发送了request vote RCP和新的term,可能会导致当前leader变成follower,新的leader最终会被选举出来,但是移除的server会再次超时,然后重复上述过程,导致可靠性问题
为了避免第三个问题,当server相信当前leader存在时,会忽略掉 request vote RPC
当一个server在当前leader最小超时的心跳包期间,收到了 request vote RPC,它不糊更新term或者做出投票
这不会影响正常的选举,每个server在开始选举之前,至少会等待一个最小的选举超时 时间
然后,这避免了移除server的破坏,如果leader能将心跳包发送到集群,那么它就不会受到更大 term的干扰
Log compaction
Raft的日志随时间推移,会不断增加;实际场景中可能会无限增大,会导致占用更多空间以及回放
如果不删除掉日志中冗余的信息,还会导致可用性问题
快照就是一种简单的压缩,真个当前系统会将状态写入一个持久存储中,然后丢弃之前的日志
快照技术在Zookeeper、Chubby中都有使用,下面来介绍Raf中的快照技术
采用增量的方式去做压缩,如日志清理、日志结构树LSM
他们只是处理数据一次,随着时间推移可以更均衡的压缩数据;首先选择一篇区域的数据,这些数据有有被删除的、覆盖的对象
然后重写那些存活的对象,以更紧凑的方式存储,并释放空间
相比于快照,这些操作需要额外的机制,复杂度更高
为了简化问题,总是对整个数据集进行操作
虽然日志清理需要修改Raft,但状态机可以使用与快照相同的接口使实现 LSM树
figure 12展示了基本的快照理念,每个服务的快照都是独立的,只是在提交的时候覆盖日志
大部分工作包括状态机写入当前状态到快照中,Raft也包含了小量的元数据:
- 最后包含的index是,被快照替换的日志中最后一个条目索引,最后被状态机应用的条目
- 最后一项包含了条目中的term,它支持 紧跟着快照后的第一条日志条目的 append entries的一致性检查,因为检查需要前一个日志的index和term
为了确保集群成员变更,快照中还包含了日志中的最近的配置信息,这点跟之前的类似
一旦server完成了写入快照,它就可以删除最后index之前的所有日志,也包含前面的快照
尽管server可以独立的操作快照,但leader也必须偶尔向掉队的follower发送快照
当leader丢弃了它需要发送给 follower的条目时,就会发生这种情况
不过这种情况不会在正常的操作中出现
一般的follower都是包含了leader中的条目的,只有缓慢掉队的,或者是刚加入的机器才没有,此时leader会通过网络发送这些快照
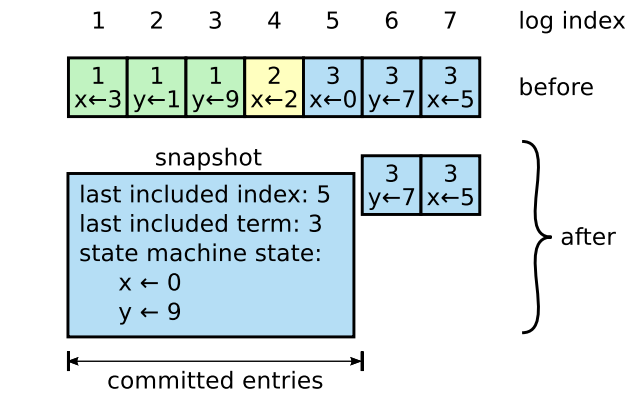 Figure 12: A server replaces the committed entries in its log
Figure 12: A server replaces the committed entries in its log
(indexes 1 through 5) with a new snapshot, which stores just
the current state (variables x and y in this example). The snapshot’s last included index and term serve to position the snapshot in the log preceding entry 6.
leader使用了一个新的RPC:install snapshot,将快照发送给那些掉队的follower,figure 13
当follower收到了RPC的快照后,它必须决定如何处理存在的日志
通常,快照中包含了接受者没有的日志信息;于是follower会丢弃这些日志,它会被快照取代,有未提交的条目可能会与快照冲突
相反,如果follower收到了描述其日志前缀的快照(由于重传或错误)
那些跟快照相同的日志会被删除由快照替代,而快照后面的日志会被继续保留
这种方式看起来是 背离了Raft的强leader策略,因为follower可以自行决定快照而无需leader知道
然而我们认为这是合理的,leader可以帮助避免冲突而达成共识;而产生快照时已经达成共识了
所以就不会有数据冲突,数据仍然是单方向的leader -> follwer ,只是follwer可以重新整理这些数据
我们也曾考虑过完全基于leader的方式,快照只能由leader创建,并发送给每个follwer,但这么做的问题:
- 发送快照到每个follwer会占用大量带宽;每个follwer自己都生成自己快照的信息,从本地状态生成快照比走网络快很多
- leader的实现机制会更复杂,需要同时向follwer发送日志复制信息,以及发送快照信息,如果不这样的话会阻塞客户端请求的
此外还有两个性能相关的问题
- 服务器需要决定何时创建快照,如果太频繁则会放到磁盘带宽,如果太低会导致磁盘耗光的风险,也会增加重启后重放日志的时间,简单的方式是当日志达到固定大小后进行快照;如果设置的大小显著大于其预期大小,则会降低磁盘I/O的消耗
- 另外一个是快照写入时会占用很多时间影响正常操作;可以使用copy-on-write方式,这在快照期间可以继续接收新的更新;比如状态机可以构建一个数据结构来支持它;也可以使用操作系统的机制fork,可以创建整个状态机的内存快照(我们使用了此方式)
 Figure 13: A summary of the InstallSnapshot RPC. Snapshots are split into chunks for transmission; this gives the follower a sign of life with each chunk, so it can reset its election
Figure 13: A summary of the InstallSnapshot RPC. Snapshots are split into chunks for transmission; this gives the follower a sign of life with each chunk, so it can reset its election
timer.
Client interaction
这部分描述客户端如何跟Raft交互,包括客户端如何找到leader,以及Raft如何支持 可线性化的语义 linearizable semantics
这些问题适用于所有基于共识的系统,Raft的解决方案和其他系统类似
Raft的客户端会会将所有请求发给leader
当客户端启动后,它会随机的选择一个服务进行连接,如果这个server不是leadr则会拒绝,并提供相关的信息,信息是通过心跳得到的最新的leader(append entries请求包含了leader的网络地址)
如果此时leader挂了,客户端请求会超时,客户端之后会继续随机选择server进行通讯
我们的目标是实现 可线性化语义,每个操作都看起来都是立刻执行的,并只执行一次,在请求和响应的某个点上
然而,根据目前的描述,Raft可以对一个命令执行多次
比如,leader在提交日志后,响应客户端之前宕机了,这样的话客户端会继续重试,导致这个命令第二次执行
解决办法是,给客户端的每个命令分为一个 唯一的序号,之后状态机会跟踪处理的每个客户端的最近的编号,以及相关的响应,如果接收到的命令编号已经被处理了,则会立刻响应且不会重复执行 ## Client interaction
这部分描述客户端如何跟Raft交互,包括客户端如何找到leader,以及Raft如何支持 可线性化的语义 linearizable semantics
这些问题适用于所有基于共识的系统,Raft的解决方案和其他系统类似
Raft的客户端会会将所有请求发给leader
当客户端启动后,它会随机的选择一个服务进行连接,如果这个server不是leadr则会拒绝,并提供相关的信息,信息是通过心跳得到的最新的leader(append entries请求包含了leader的网络地址)
如果此时leader挂了,客户端请求会超时,客户端之后会继续随机选择server进行通讯
只读操作不需要操作任何日志,如果没有额外的错误会出现读到过期数据的风险 ,因为响应的leader可能不是最新的leader
而 可线性化的语义是,不能返回过期的数据,Raft需要两个额外的错误来防止 只读情况下的问题
- leader必须知道被提交条目的最新信息,leader完全属性可以保证leader有所有已提交的条目,但在岗上任时,它可能不知道哪些是已提交的,为找到答案,它需要从自己的term中提交一个条目,在刚上任时候,让每个leader提交一个
no-op的条目 - leader在响应只读请求之前必须检查它是否已经过期了(最近有新leader上任),Raft让leader跟多数派机器交互心跳(在响应之前),leader也可以依靠心跳机制来提供一种租约形式,这种方式依赖安全的时间(假设没有时钟倾斜)
Implementation and evaluation
我们已将Raft实现为,存储配置新的状态机的一部分,帮助RAMCloud实现故障转移
Raft实现包含大约2000行的C++代码,不包含测试、注释、空行,源码可以免费获得
在基于本论文的基础上,还有25个独立的第三方实现,目前处于不同开发阶段
也有很多公司正在开发基于Raft的系统,剩余部分,注意评估Raft的三个标准:
- 容易理解
- 正确性
- 性能
Understandability
为了评估Raft相对于Paxos的易懂性,我们对高年级本科和研究生的高级操系统课程(斯坦福)、以及分布式计算课程(伯克利)做了一些评估
我们也记录了Raft的一些视频课程和Paxos课程,并创建了对应的实验
Raft的课程包含了论文中的内容,除了日志复制
Paxof的课程包含了足够多的材料,如创建等价的复制状态机、包含basic paxos、multi-paxos、重配置、实践中的一些优化如leader选举
每个学生都会观看视频,并做对应的实验,观看第二个视频、做第二个实验;为解释从研究的第一部分中获得的个人表现和经验差异,我们比较了参与者在每个测试中得分,以确定参与者是否对Raft更易懂做出解释
为了比较Paxos和Raft,我们的实验更偏向Paxos,43人的15人对Paxos有过一些了解,Paxos的视频也比Raft长14%,总结的表格如table-1
我们采取了一些措施以减少潜在的偏见,所有的材料都有记录

参与者的Raft平均得分比Paxos高 4.9分
总分为60分,Raft平均得分为25.7,而Paxos为20.8分, figure 14展示了他们的独立分数
一个配对的 t-test校验表明,在95%的可信度下,Raft的真实分布比 Paxos真实分布至少高 2.5
我们还创建了一个线性回归模型,通过三个因素来预测新生的测试成绩:
- 他们使用的工具
- 之前对paxos的了解程度
- 他们的算法掌握程度
这个模型预测了,实验中产生了12.5分的差距,都是有利于Raft,这笔之前观察到的 4.9分要高,因为很多学生之前都有Paxos的经验,这也就帮助了Paxos,但对Raft没什么帮助
奇怪的是,该预测模型还表示,已经参加过Paxos测试的人在Raft上的得分要低于6.3分,虽然不知道是为什么,但在统计上倒是很重要
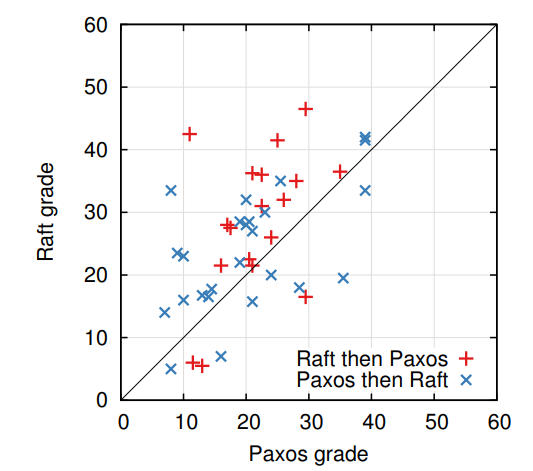 Figure 14: A scatter plot comparing 43 participants’ performance on the Raft and Paxos quizzes. Points above the diagonal (33) represent participants who scored higher for Raft.
Figure 14: A scatter plot comparing 43 participants’ performance on the Raft and Paxos quizzes. Points above the diagonal (33) represent participants who scored higher for Raft.
我们在测试之后也做了调查,看看哪种算法更容易实现,更容易解释,结果显示为 figure 15
大部分参与者表示Raft更容易实现、更容易理解
然而,这种自我解释的感觉,可能不如之前的测试分数更可靠,另外参与者已经知道了,我们已假设Raft更容易理解,从而产生偏见
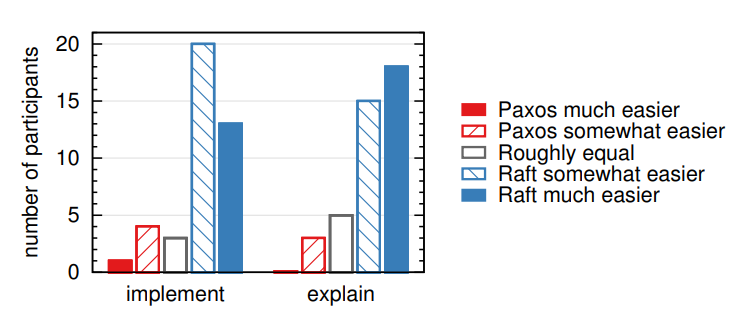
Figure 15: Using a 5-point scale, participants were asked
(left) which algorithm they felt would be easier to implement
in a functioning, correct, and efficient system, and (right)
which would be easier to explain to a CS graduate student.
Correctness
我们已经为第五章中描述的共识机制,开发了一个正式的规范 和安全证明
正式规范使用 figure 2中总结的 完整信息 使用了TLA+规范语言
大约400行,也是证明的主题,对于任何想实现Raft的人也很有帮助
我们使用了TLA证明系统,证明了日志完全属性 ;这个证明依赖于没有经过机械检查的不变量(比如,我们还没有证明规范的类型安全性)
此外,我们还写了一个非正式的证明,用于状态机安全性的完整性(依赖于规范)和相对精确性(大约3500字)
Performance
Raft的性能类似于其他共识算法,如Paxos
对性能影响最大的是,当leader建立后复制新的日志条目,Raft将消息通讯最小化,单轮RPC,leader发送给一半的服务器
它也可能会进一步的改进Raft的性能,比如可以简单的支持批处理、管道的方式,来实现高吞吐和低延迟
文献中对其他算法提出了各种优化,这些都可以被用到Raft中,不过我们将其留到以后的工作中了
我们使用Raft实现测试 leader选举算法的性能,并回答了两个问题
- 选举过程是否能快速收敛
- leader宕机后的最小化停机时间是多少?
为了测量leader选举,我们反复使集群中的5台机器宕机,并计算检查到宕机和选举一个新leader的时间,figure 16
为生成一个最坏的场景,每个服务器有不同的日志长度,所有有些candidate 没有资格称为leader
为测试split vote,我们的测试脚本在leader将自己终止之前,触发了同步的心跳广播,这个行为类似于在崩溃之前复制新日志条目的leader
leader在心跳间隔内均匀的崩溃,心跳间隔是所有测试中最小选举超时的一半,因此最小的可能停机的时间大约为最小选举超时时间的一半
figure 16的上半部分显示了选举超时中的 少量随机化时间,可以避免split vote
而在缺少随机化时间的情况下,由于split vote导致选举花费时间都超过了10秒
增加了 5ms随机化时间非常有帮助,平均的停机时间为 287ms
使用更多的随机化时间,可以改善最坏的情况,在最坏的情况下使用50ms的随机化时间,完成时间为513ms(1000轮)
figure 16的下半部分显示了减少选举超时时间,可以减少停机时间
选举超时时间为12-24ms,平均的的leader选举时间为 35ms(最长的为152ms)
但再次降低时间会导致违反Raft时间要求,leader很难在其他服务器开始新选举之前,广播自己的心跳
者导致了leader的不必要的切换,降低了系统的整体可用性
我们推荐使用一个保守的选举超时时间:150-300ms
这个时间不会导致leader不必要的变更,并且也能保证其可用性
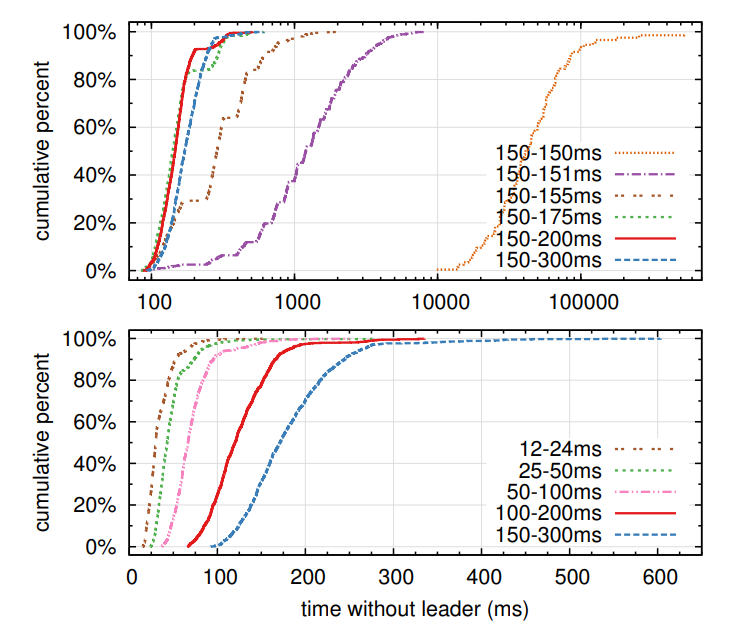 Figure 16: The time to detect and replace a crashed leader.
Figure 16: The time to detect and replace a crashed leader.
The top graph varies the amount of randomness in election
timeouts, and the bottom graph scales the minimum election
timeout. Each line represents 1000 trials (except for 100 trials for “150–150ms”) and corresponds to a particular choice
of election timeouts; for example, “150–155ms” means that
election timeouts were chosen randomly and uniformly between 150ms and 155ms. The measurements were taken on a
cluster of five servers with a broadcast time of roughly 15ms.
Results for a cluster of nine servers are similar.
Related work
已经有许多跟共识算法相关的出版物,其中多属于下面类别:
- lamport的paxos的原始描述[15],并尝试用更简洁的方式描述[16,20,21]
- paxos的细节,填补了缺失的细节,并对算法进行了修改,为实现提供了更好的基础[26,39,13]
- 共识算法的系统实现,如Chubby[2,4]、Zookeeper[11,12],Spanner[6],Chubby和Spaner没有公开实现,而Zookeeper虽然公开了细节,但跟Paxos有很大不同
- Paxos的性能优化[18,19,3,25,1,27]
- Oki和Liskov的 viewstamped复制VR,是另一种共识方式,跟Paxos差不多是同时推出的,最初的描述[29]于分布式事务纠缠在一起,不过最近的更新中将核心的共识独立出来了[22],VR使用了领导者的方式跟Raft有很多相似之处
Raft和Paxos最大的不同是:Raft是基于强leader的方式,Raft的leader选举也是共识算法的一部分
并尽可能给leader赋予更多的功能,这样做的结果了简化了算法,使得更容易理解
比如说,Paxos中leader选举和基本共识算法是结合在一起的,它只能作为优化选项,不是达成共识所必须的
然后这需要额外的机制
- Paxos需要一个两阶段协议实现基本共识,basic paxos
- 以及一个独立的机制,实现leader选举
相反,Raft将leader选举纳入进了共识算法,作为共识算法两阶段的第一个部分,这就比Paxos需要更少的机制
跟Raft类似,VR和Zookeeper也是基于leader的,这就比Paxos有更多优势
然而,Raft比VR和Zookeeper需要更少的机制,因为对follower做了很多限制,比如,日志只能从leader流向follower
leader使用append entries RPC发送日志,而在VR中,有双向的日志流转,在leader选举中,leader可以接受日志,这就需要增加额外的机制,增加了复杂性
公开的描述看,Zookeeper的日志复制也是有双向流转的,不过它的实现更像Raft
Raft比其他基于日志复制的共识算法,所需要的消息数量更少
比如,我们统计了VR和Zookeeper的消息类型,包括基本的共识和成员变更,不包括日志压缩和客户端交互,因为这些几乎是独立的部分
VR和Zookeeper大概需要10个不同的消息类型,而Raft只需要4个消息类型,2个RPC请求和2个RPC响应
Raft的消息比其他的更密集,但也只是简单整合而已
VR和Zookeeper在leader变更期间,传输整个日志,需要额外的消息类型来优化这些机制,使其具有实用性
Raft的强leader方式使的算法更简单,但却阻碍了性能优化
比如,公平Paxos可以在弱领导者条件下实现高性能,EPaxos使用状态机的命令进行通讯
任何server提交的命令都只需要一轮通讯,只要其他提议的命令与它并行交换
但是,如果并行提议的命令不能相互转换,那么就需要增加额外的一轮通讯,因为任何服务都可以提交命令
EPaxos能很好的平衡服务之间的负载,比Raft在WAN下有更低的延迟,但需要在Paxos上增加额外的复杂性
在其他工作中已经有了或者实现了,几种不同的成员更变方式,包括Lamport的原始提案,VR,SMART
我们选择了 joint consensus 实现,因为它利用了共识协议的剩余部分,对于成员变更只需要增加很少的机制
Lamport的 a-based方式不适合Raft,因为它假定没有leader也能达成共识
与VR和SMART比较,Raft的重配置算法,在成员变更期间,也可以响应正常请求
而VR在变更期间,需要停止所有正常操作
SMART对未处理的请求增加了一个a-like的限制,而Raft比VR和SMART需要更少的机制
Conclusion
算法 设计通常需要有正确性、有效性、简洁 为主要目标;但我们相信,易懂性也是一个重要的标准
在开发人员将算法转换为实际实现之前,其他目标都无法实现,而实现不可避免的偏离了其目标,并在此基础上做了扩展
除非开发人员深深理解了此算法,并对此有直观感觉,否则在实现的过程中,很难保证描述中的属性
在本论文中,我们讨论了 分布式共识问题,Paxos是被广泛接受的,但又很难实现的算法,困扰了学生和开发者多年
于是我们设计了一个新的算法:Raft,它比Paxos更容易懂,我们相信Raft对于系统构建提供了一个更好的基础
使用易懂性设计为主要目标,改变了我们设计Raft的方式
在设计过程中,我们反复重用了一些技术,如分解问题、简化状态空间
这些技术不但使的Raft更容易懂,也很容易相信其正确性
References
- [1] BOLOSKY, W. J., BRADSHAW, D., HAAGENS, R. B.,KUSTERS, N. P., AND LI, P. Paxos replicated state machines as the basis of a high-performance data store. In Proc. NSDI’11, USENIX Conference on Networked Systems Design and Implementation (2011), USENIX, pp. 141–154.
- [2] BURROWS, M. The Chubby lock service for looselycoupled distributed systems. In Proc. OSDI’06, Symposium on Operating Systems Design and Implementation (2006), USENIX, pp. 335–350.
- [3] CAMARGOS, L. J., SCHMIDT, R. M., AND PEDONE, F.Multicoordinated Paxos. In Proc. PODC’07, ACM Symposium on Principles of Distributed Computing (2007), ACM, pp. 316–317.
- [4] CHANDRA, T. D., GRIESEMER, R., AND REDSTONE, J.Paxos made live: an engineering perspective. In Proc. PODC’07, ACM Symposium on Principles of Distributed Computing (2007), ACM, pp. 398–407.
- [5] CHANG, F., DEAN, J., GHEMAWAT, S., HSIEH, W. C., WALLACH, D. A., BURROWS, M., CHANDRA, T., FIKES, A., AND GRUBER, R. E. Bigtable: a distributed storage system for structured data. In Proc. OSDI’06, USENIX Symposium on Operating Systems Design and Implementation (2006), USENIX, pp. 205–218.
- [6] CORBETT, J. C., DEAN, J., EPSTEIN, M., FIKES, A., FROST, C., FURMAN, J. J., GHEMAWAT, S., GUBAREV,A., HEISER, C., HOCHSCHILD, P., HSIEH, W., KANTHAK, S., KOGAN, E., LI, H., LLOYD, A., MELNIK, S., MWAURA, D., NAGLE, D., QUINLAN, S., RAO, R., ROLIG, L., SAITO, Y., SZYMANIAK, M., TAYLOR, C., WANG, R., AND WOODFORD, D. Spanner: Google’s globally-distributed database. In Proc. OSDI’12, USENIX Conference on Operating Systems Design and Implementation (2012), USENIX, pp. 251–264.
- [7] COUSINEAU, D., DOLIGEZ, D., LAMPORT, L., MERZ, S., RICKETTS, D., AND VANZETTO, H. TLA+ proofs. In Proc. FM’12, Symposium on Formal Methods (2012), D. Giannakopoulou and D. M´ery, Eds., vol. 7436 of Lecture Notes in Computer Science, Springer, pp. 147–154.
- [8] GHEMAWAT, S., GOBIOFF, H., AND LEUNG, S.-T. The Google file system. In Proc. SOSP’03, ACM Symposium on Operating Systems Principles (2003), ACM, pp. 29–43.
- [9] GRAY, C., AND CHERITON, D. Leases: An efficient faulttolerant mechanism for distributed file cache consistency. In Proceedings of the 12th ACM Ssymposium on Operating Systems Principles (1989), pp. 202–210.
- [10] HERLIHY, M. P., AND WING, J. M. Linearizability: a correctness condition for concurrent objects. ACM Transactions on Programming Languages and Systems 12 (July 1990), 463–492.
- [11] HUNT, P., KONAR, M., JUNQUEIRA, F. P., AND REED, B. ZooKeeper: wait-free coordination for internet-scale systems. In Proc ATC’10, USENIX Annual Technical Conference (2010), USENIX, pp. 145–158.
- [12] JUNQUEIRA, F. P., REED, B. C., AND SERAFINI, M. Zab: High-performance broadcast for primary-backup systems. In Proc. DSN’11, IEEE/IFIP Int’l Conf. on Dependable Systems & Networks (2011), IEEE Computer Society, pp. 245–256.
- [13] KIRSCH, J., AND AMIR, Y. Paxos for system builders. Tech. Rep. CNDS-2008-2, Johns Hopkins University, 2008.
- [14] LAMPORT, L. Time, clocks, and the ordering of events in a distributed system. Commununications of the ACM 21, 7(July 1978), 558–565.
- [15] LAMPORT, L. The part-time parliament. ACM Transactions on Computer Systems 16, 2 (May 1998), 133–169.
- [16] LAMPORT, L. Paxos made simple. ACM SIGACT News 32, 4 (Dec. 2001), 18–25.
- [17] LAMPORT, L. Specifying Systems, The TLA+ Language and Tools for Hardware and Software Engineers. AddisonWesley, 2002.
- [18] LAMPORT, L. Generalized consensus and Paxos. Tech. Rep. MSR-TR-2005-33, Microsoft Research, 2005.
- [19] LAMPORT, L. Fast paxos. Distributed Computing 19, 2(2006), 79–103.
- [20] LAMPSON, B. W. How to build a highly available system using consensus. In Distributed Algorithms, O. Baboaglu and K. Marzullo, Eds. Springer-Verlag, 1996, pp. 1–17.
- [21] LAMPSON, B. W. The ABCD’s of Paxos. In Proc. PODC’01, ACM Symposium on Principles of Distributed Computing (2001), ACM, pp. 13–13.
- [22] LISKOV, B., AND COWLING, J. Viewstamped replication revisited. Tech. Rep. MIT-CSAIL-TR-2012-021, MIT, July 2012.
- [23] LogCabin source code. http://github.com/logcabin/logcabin
- [24] LORCH, J. R., ADYA, A., BOLOSKY, W. J., CHAIKEN,R., DOUCEUR, J. R., AND HOWELL, J. The SMART way to migrate replicated stateful services. In Proc. EuroSys’06, ACM SIGOPS/EuroSys European Conference on Computer Systems (2006), ACM, pp. 103–115.
- [25] MAO, Y., JUNQUEIRA, F. P., AND MARZULLO, K. Mencius: building efficient replicated state machines for WANs. In Proc. OSDI’08, USENIX Conference on Operating Systems Design and Implementation (2008), USENIX, pp. 369–384.
- [26] MAZIERES ` , D. Paxos made practical. http://www.scs.stanford.edu/˜dm/home/papers/paxos.pdf, Jan. 2007.
- [27] MORARU, I., ANDERSEN, D. G., AND KAMINSKY, M. There is more consensus in egalitarian parliaments. In Proc. SOSP’13, ACM Symposium on Operating System Principles (2013), ACM.
- [28] Raft user study. http://ramcloud.stanford.edu/˜ongaro/userstudy/.
- [29] OKI, B. M., AND LISKOV, B. H. Viewstamped replication: A new primary copy method to support highly-available distributed systems. In Proc. PODC’88, ACM Symposium on Principles of Distributed Computing(1988), ACM, pp. 8–17.
- [30] O’NEIL, P., CHENG, E., GAWLICK, D., AND ONEIL, E. The log-structured merge-tree (LSM-tree). Acta Informatica 33, 4 (1996), 351–385.
- [31] ONGARO, D. Consensus: Bridging Theory and Practice.PhD thesis, Stanford University, 2014 (work in progress).http://ramcloud.stanford.edu/˜ongaro/thesis.pdf.
- [32] ONGARO, D., AND OUSTERHOUT, J. In search of an understandable consensus algorithm. In Proc ATC’14, USENIX Annual Technical Conference (2014), USENIX.
- [33] OUSTERHOUT, J., AGRAWAL, P., ERICKSON, D., KOZYRAKIS, C., LEVERICH, J., MAZIERES ` , D., MITRA, S., NARAYANAN, A., ONGARO, D., PARULKAR,G., ROSENBLUM, M., RUMBLE, S. M., STRATMANN,E., AND STUTSMAN, R. The case for RAMCloud. Communications of the ACM 54 (July 2011), 121–130.
- [34] Raft consensus algorithm website.http://raftconsensus.github.io.
- [35] REED, B. Personal communications, May 17, 2013.
- [36] ROSENBLUM, M., AND OUSTERHOUT, J. K. The design and implementation of a log-structured file system. ACM Trans. Comput. Syst. 10 (February 1992), 26–52.
- [37] SCHNEIDER, F. B. Implementing fault-tolerant services using the state machine approach: a tutorial. ACM Computing Surveys 22, 4 (Dec. 1990), 299–319.
- [38] SHVACHKO, K., KUANG, H., RADIA, S., AND CHANSLER, R. The Hadoop distributed file system. In Proc. MSST’10, Symposium on Mass Storage Systems and Technologies (2010), IEEE Computer Society, pp. 1–10.
- [39] VAN RENESSE, R. Paxos made moderately complex. Tech. rep., Cornell University, 2012.