Delta Lake论文
Delta Lake论文
Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores
背景
S3作为对象存储,性价比流行度都没得说,不过它只提供了 key-value特性,没有ACID、性能也不行
想实现list 对象这种元数据操作都比较困难
delta-lake是基于对象存储之上的 ACID表存储层,提供事务日志实现ACID,还有时间旅行、快速的元数据操作
能对 10亿数据做快速查询,也提供了一些高级特性:
- 自动的数据布局优化
- upsert
- 缓存
- 审计日志
可以被spark、hive、presto、redshift、以及其他系统访问
亚马逊的S3、微软的 azure blob存储都是非常流行,存储了几EB的数据
从管理、经济的扩容、便捷性来说都是非常不错的,而且他们也实现了存储和计算分离
各种开源的大数据系统,都支持读写对象存储上的 Parquet、ORC等格式
类似的商业服务包括
- AWS Athena
- 谷歌 big query
- redshift
但是,在这些系统之上,实现 性能和可变的表格就变得很有挑战了,使在其之上实现数据仓库也变得很难
他们的实现跟分布式文件系统HDFS有很大不同,仅仅只有key-value特性,缺乏关键的一致性保证
这些特性使的他们跟分布式文件系统有很大不同
想在对象存储之上实现数据仓库,一般的想法是利用列存储的特性,比如由一些字段聚集成一个分区
这种设计想实现性能和正确性会有两个问题
- 因为多个对象更新不是原子的,如果要删除一个表中某个用户的所有parquet文件,就不满足隔离性,回滚也变得困难
- parquet本身的foot是带有min/max的,可以跳过一些数据,在hdfs上读取很快几毫秒,但是对象存储的延迟就很高了
这些问题对于企业用户影响更大,在 databricks云服务的这些年,有一半的需求是
- 数据损坏,如消除更新任务挂掉后的影响
- 一致性
- 性能,查询一万个对象等
Delta-Lake是在2017年提供给客户的,并在 2019年开源,2020年发表了这篇论文
核心思想是:
- 以 ACID的方式维护一些信息,这些信息是:哪些对象是 delta表的一部分
- 使用WAL的方式将自身写入到 对象存储中
- 对象本身是用 parquet编码的
使用这种方式,客户端就可以更新多个文件,达到原子性,而读/写是通过parquet文件的,所以性能也有保证
WAL日志中中也包含了min/max这样的统计信息
元数据、数据文件都是存到 对象存储中的,所以不需要额外的服务来维护 delta表信息了
只要在运行查询的时候启动服务就可以,可以实现存储计算分离的好处
针对这种事务设计,还增加了一些传统对象存储无法提供的功能,以解决用户常见的问题
- 时间旅行,可以查看历史数据的快照,以及回滚到某个时间点
- upsert、delete、merge操作
- 流式I/O,将流消息以小文件的方式低延迟写入,再以事务的方式合并为大文件,对新增的数据可以用tail的方式读取
- 缓存,因为 delta表上的对象和log都是不可变的,所以可以轻松的将其缓存
- 数据布局优化,这个是云服务上的功能,可以自动优化数据大小和数据聚集不影响查询(Z-order实现多维分析的局部性)
- schema 演化,如果表结构变了,允许继续读 旧的parquet文件,而不用重写他们
- 审计日志
通过这些特性,就整合 数据仓库的特性、数据湖的特性,也就是 lakehouse 湖仓
用户直接使用 湖仓可以解决独立的数据湖、数据仓库、流存储的问题,可以大幅度简化设计
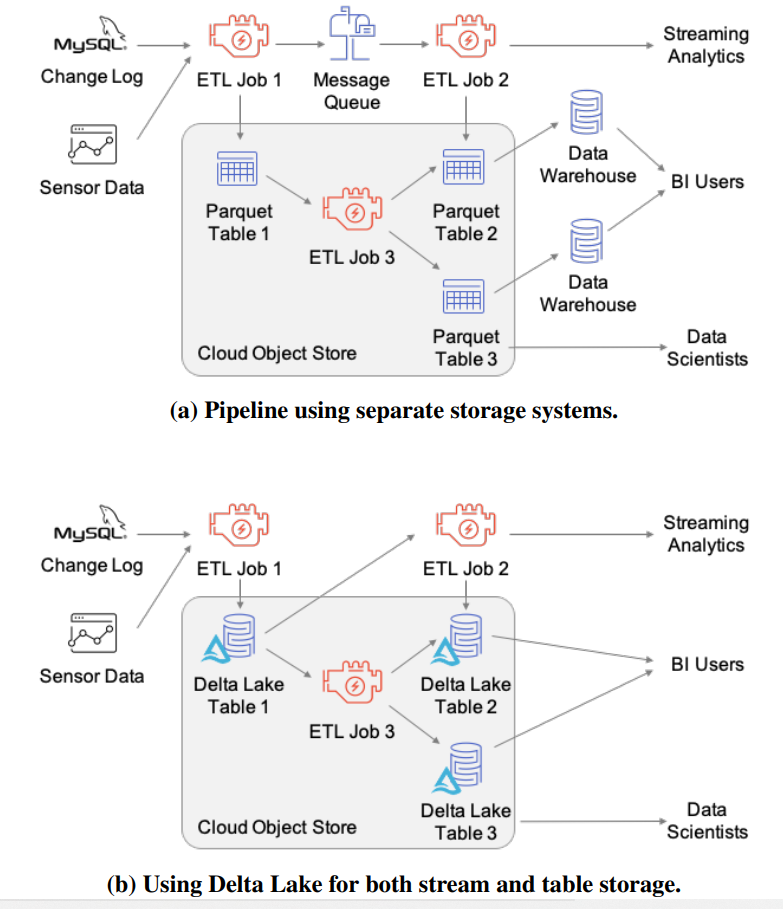
Figure 1: A data pipeline implemented using three storage systems (a message queue, object store and data warehouse), orusing Delta Lake for both stream and table storage. The Delta Lake version removes the need to manage multiple copies of the data and uses only low-cost object storage.
在之前的设计中,需要三个存储系统,消息队列、对象存储、数据仓库,而现在只需要一个存储系统
支持谷歌云、阿里、腾讯等各种云厂商,而用户包含
- 传统的 ETL和数据仓库
- 生物学
- 实时网络安全分析(每天几百G流数据)
- GDPR合规
- 机器学习的数据管理,几百万图片存储在 delta表上,提供了事务功能
后面我们将介绍设计 delta lake的动机
以及通过用户案例、性能体验来 驱动 我们的设计
动机:对象存储的特征和挑战
这里描述了对象存储的API和性能特点,并解释为什么在对象存储之上,实现高效的表存储是有挑战的,并描述现有的方式来管理表存储
对象存储API
- 包括亚马逊S3,微软的Azure Blob存储、谷歌云存储、openstack的swift 提供了一个可扩展的key-value接口
- 运行创建一个 bucket,然后里面包含了多个对象,每个对象都是二进制的,可以扩展到很多,如5T
- 每个对象用一个 stirng 的key来标识,如 warehouse/table1/part1.parquet
- 对象存储一般不提供 rename功能
- 提供列出一个 bucket下的文件列表这样的元数据操作,但返回1000个列表大概要10-100毫秒,百万个文件大概要几分钟
- 对象存储支持范围读取,如读取大文件的 1000-2000字节很高效,也支持update(重写整个文件,是原子性的)
一致性问题
- 大部分留下的对象存储都提供了最终一致性,并对跨多个key不保证一致性
- 一个客户端上传了一个文件,那么LIST操作可能不会马上看到,另一个客户度可能也不会立刻看到
- 更新文件,其他用户也不会马上看到,甚至 看不到自己刚刚写的对象
- 不同的厂商提供的细节不同,S3 提供了 read-after-write 一致性,也就是PUT之后GET肯定能看到
- 有一个例外,如果在写入前有一个GET(查询一个不存在的key)
- 则PUT之后的GET可能在一段周期内看不到,者可能是S3提供了负缓存
性能特点
- 想要在对象存储之上实现高吞吐,需要在 大量的顺序I/O,以及并行性上做平衡
- 对于字节范围的读,基本延迟是 5-10毫秒,成本为 50-100M/s
- 至少要读取几百K,才能达到峰值的一半,而读几M就能接近吞吐
- AWS上分析场景的虚拟机,一般有10G带宽,所以要并行的执行 8-10个read 才能最大化利用带宽
- list操作需要并行化才能提高性能,每个list返回1000个对象,延迟为10-100毫秒,所以客户端可以触发几百个LIST
- 在云环境中,driver就通过并行的LIST发送到worker节点,加速这个查询
- delta-lake中,元数据是存储到delta-log中的,不过也使用了并行化读取来加速
- 写是覆盖更新的,所以要金可能性小,这跟支持大量的读取是不一样的
- 实现表存储,对象存储的性能特点 导致了分析场景的三个考虑因素
- 频繁的访问数据要接近顺序读,也就是选择 列存储
- 选择大对象,但不能太大,太大的对象会导致更新成本很高,因为要完全覆盖
- 必须LIST操作,让这些操作按 字典顺序范围排列
表存储的现有方式
包括了下面几种
- 目录中的文件
- 通用的方式,支持各种开源大数据以及云服务,将表存储为对象集合,用列存实现
- 通过指定的字段作为分区,如 mytable/date=2020-01-01/obj1
- 分区减少了读成本,也减少了LIST操作的成本
- 此方案优点,表相当于一些对象,类似于Hive的meta-store、parquet,将元数据和HDFS数据分离,相当于读时定义
- 没有原子性操作,事务会导致其他用户看到了部分更新、最终一致性
- 即使分区了,LIST也操作也很重,因为还是需要高延迟的读取Parquet的数据
- 缺少一些管理工具,如数据仓库的那些工具
- 自定义的存储引擎
- 比如 snowflake的方式,对象存储在它看来就是一个基本的块文件
- 因此可以用标准的技术实现高效的读、写、查询
- 不过它需要额外的方式来存储元数据并保证可靠性,使用扩展的计算引擎查询时会带来额外开销
- 也可能会让用户锁定某个厂商
- 所有的I/O操作都需要联系元数据服务,比如从snowflake的spark连接器读取的数据要经过 snowflake的服务
- 不能重用现有存储格式如parquet,需要重新实现底层的存储格式
- 数据团队希望使用各种计算引擎,如Spark、TensorFlow、PyTorch连接他们的数据,让连接器易于实现很重要
- 专有的元数据服务,会让用户可能会绑定某个厂商
- Hive的ACID使用HDFS/对象存储+传统数据库的方式实现,通过hold住表中每个文件的变更
- 这种方式受到meta-store的限制,当有几百万个文件,可能会称为瓶颈
- 对象存储中的元数据
- delta lake使用事务日志和元数据目录的方式,并在对象存储之上使用一系列协议实现可线性化
- 数据使用parquet存储的,这样可以跟现有支持parquet格式的系统兼容
- delta-lake是第一个使用这种设计的系统,2016年就开始了,后面又出现了 hudi和ice-berg
- delta-lake有其他两个系统没有的特点,Z-order聚类、缓存、后台优化
delta-lake的存储格式和访问协议
delta-lake是对象存储之上的一个目录,或者是 包含表内容和事务操作日志的数据对象 文件系统
客户端使用对象存储之上的 定制化的优化的并发控制协议

Figure 2: Objects stored in a sample Delta table.
数据和日志的格式
存储格式-数据对象
- 表按照指定字段做分区,数据对象存到不同的分区中
- 底层是parquet格式,因为是列文件,支持字描述数据,性能也很好
- 每个文件有一个唯一的名字,由GUID生成
- 哪个对象属于表的哪个版本,由事务日志决定
日志
- 存放在 _delta_log 子目录下的,包含了一系列JSON文件,不够长的会补0
- 会由定期的checkpoint日志,这些对象以parquet格式汇总到该点的日志上
- 每个日志对象包含一组操作,应用于表的上一个版本,这样就可以生成下一个版本
- change metadata,更改表的当前元数据,第一个操作应该是change meta-data
- add、remove,修改表数据,通过增加、删除一个独立的数据对象来表示的
- 客户端通过查找所有未删除的对象,来决定是否存在这个表中
- 数据对象add记录,包含数据统计,如每列min/max和总条数
- 当增加一个path,这个path已经存在了,就使用当前版本替换之前的任何版本的统计信息
- 删除操作只是一个墓碑操作,物理删除会延迟进行,允许用户可以读过期的快照
- chang data
- protocol evolution,用来支持老版本的格式
- 增加来源信息,比如是哪个用户操作的
- update 应用事务ID,对于流系统想要实现 精确一次需要将流消息的ID存到delta-lake的日志中,包含偏移量等
- 当流job挂掉之后,通过这个应用事务ID,可以实现精确一次的重放,应用需要提供AppID、version即可
checkpoint
- 将前面的日志中允许的操作去掉,写入parquet文件中
- removef后面的add如果操作相同对象则可以去掉,因为这个对象已经不存在了,remove的文件可以作为墓碑继续保留
- 多个add操作一个对象,只保留最后一次的
- 多个事务操作相同appID,可以只保留最后一次的
- change-metadata也可以合并,保留最近的,00003.parquet则包含了00003.json,默认10个事务一次checkpoint
- 由于需要高效的找到最近一次的checkpoint,而不用LIST整个_delta_log目录
- 会将最新的checkpoint写入到 _delta_log/_last_checkpoint 文件中
访问协议
可以让客户端在对象存储之上,实现可线性化的事务,而对象存储只是最终一致性的
核心是日志记录对象,比如 0003.json表示 根数据结构,这个结构让用户看到了表的某个特定版本
通过这个对象存储的内容,用户就可以查询到其他对象存储,如果因为最终一致性不可见,则会等待
写的时候需要确保只能有一个用户写成功,这就是 优化的并发控制
对于 delta-lake表的只读事务
- 读 _last_checkpoint(如果存在),获取最近的事务ID
- 使用start key列出最近的checkpoint ID,找到表目录中最新的 json和parquet文件
- list操作列出的元数据和数据,可以重建表的状态
- 如果因为最终一致性只返回了 004.json、006.json但没有005,值使用最大版本的去查找并等待不可见对象变为课件
- 使用checkpoint和后续的日志记录 重建表的状态
- 这些对象已经增加了,并且没有对象删除记录,就可以关联到数据统计信息
- 我们的设计可以让其并行化,可以使用spark job来读checkpoint文件和parquet文件和日志对象
- 使用统计信息识别出读请求 关联的数据对象文件
- 查询对象存储读取关联的数据对象,可能是跨集群并行读取
- 因为最终一致性,worker节点的可能无法查询这些对象,这些对象是在日志中的
- 可以通过一段时间的简单重试来完成
这种设计是可以容忍最终一致性的
比如,客户端读了一个过期的 _last_checkpoint文件,但他仍然可以在随后的LIST 操作中发现 最近的日志文件
并重建表的快照,_last_checkpoint 只是用来降低查找成本的,也就是提供了最近的checkpoint ID
客户端也LIST最近记录时,也能容忍一致性的,如log记录中出现空隙
或者日志管理的对象暂时不可见
写事务
- 使用 读协议的1-2步,识别出最近的checkpoint的ID,事务读版本 r,然后写日志记录 r+1
- 读版本 r的数据(使用读协议),将之前的checkpoint和后续的日志结合起来,再对这些数据中引用的数据对象
- 将新对象写入到当前目录中,对象名为GUID,这一步可以并发执行
- 尝试写事务日志到 版本 r+1.json 中,这步需要原子性;如果失败可以继续重试,客户端继续(3)写入新文件
- 可选的,写一个新的 .parquet checkpoint 记录 r+1版本日志(10个事务一个checkpoint),再更新_last_checkpoint
注意,第5步的只影响性能,即使失败也不会破坏数据
第五步的checkpoint失败了,或者_last_checkpoint失败了,客户端会使用更早的事务(只要步骤4成功了)
原子性的增加 r+1.json日志,这一步需要原子性,也就是 put-if-absent,但不是所有存储系统都支持的
- 谷歌云存储,微软Azure Blob支持 原子性的 put-if-absent,直接使用即可
- 对于HDFS,使用原子性的rename,将临时文件改为目标文件名,如果存在则失败
- 亚马逊S3不支持put-if-absent和原子rename,所以提供了一个轻量级的协调器,确保只有一个用户可以记录日志ID,只用于处理写日志的情况
- 开源的Delta-Lake,确保写操作经过相同的driver,使用内存状态获取不同的日志记录ID,这意味着一个集群内用户可以并发写delta表
- 如果用户想运行一个隔离的、强一致的存储,我们提供了一个API来插入自定的LogStore类
可用的隔离级别
- delta-lake的并发控制协议,所有的事务执行是串行化的,事务日志ID的连续递增的
- 这是因为写事务提交协议,只有一个事务可以写入日志记录
- 读事务可以实现 可线性化、快照隔离
- 读事务只能实现快照隔离,如果想实现串行化,可以执行一个读-写事务,执行一个dummy写入来实现串行化
- delta-lake连接器会缓存最近的事务ID,所以即使是快照隔离度,也能看到其他人的写入
- delta-lake当前只支持单表的事务,不过这种设计可以扩展,用相同的日志记录多表数据,就可以实现多表事务了
事务率
- 事务率是受put-if-absent延迟影响的,如果事务率太高了,则容易失败
- 写对象存储的延迟大概是 10-100毫秒,所以每秒大概 几个事务
- 几个事务/秒 实际是足够了,即使流写入一般是并行的作业,可以在一个事务内批处理多个新数据对象
- 如果需要更高并发事务,需要一个自定义的LogStore来协调存储,如用DBMS记录事务日志,数据异步写入到对象存储中
- 不过对于读事务是快照隔离,只读取对象存储中的对象,所以任意数量的读事务都可以并发执行
delta的高级特性
时间旅行和回滚
- 对于从外部数据源社区的数据,如果出现脏数据则很麻烦,传统的数据湖想实现uodo很麻烦
- 对于机器学习训练场景,需要严格的报告出新旧算法针对相同数据的训练效果
- delta-lake支持时间旅行,因为所有的数据和事务日志都是不可变的,用户可以简单的回溯到之前的版本
- 这类似快照读过期数据,MVCC实现,提供旧的事务ID即可
- 用户可以设置数据的保留时间,通过SQL或者API的方式来读取
可以通过下面方式,实现一个uodo的更新
|
|
高效的upsert、delete、merge
- 很多企业分析数据库随时间推移,需要修改能力,这是因为数据隐私协议要求的
- 企业需要删除指定用户的数据
- 即使是个人无关的数据,可能因为上游的收集的错误,或者延迟到达需要能更新
- 在传统的数据湖场景中,在不停止当前读情况下很难实现更新,而且更新需要非常小心,不能因失败出现部分更新
流摄取和消费
很多场景下需要部署流管理 到ETL、或者实时的聚合数据,但传统的数据湖则很难
需要部署额外的消息队列如kafka、kinesis等,delta-lake的设计可以不用这些组件
支持三种主要特性
- 写压缩
- 数据湖场景下将一批数据insert,但需要在读性能/写延迟之间做平衡
- 写入小对象则会很快,但是读时会需要读很多小文件以及元数据
- delta-lake允许在后台压缩这些小文件,流快速写入小文件,读旧数据保持高效
- 精确一次的流式写入
- 在应用层每次写入一个事务时,增加一个日志记录(appID,version)实现精确一次写入
- 支持各种流计算,如append,aggregation,upsert
- tail操作
- 因为事务日志是按字典排序的,通过LIST操作就可以发现最近的事务ID
- 通过事务ID就可以获取到最新的数据了
通过上述三个特点,就可以免去消息队列,通过delta-lake实现秒级别的流管道
数据布局优化
delta-lake 可以在后台处理数据,做数据压缩,合并、甚至更新辅助数据结构,如索引、统计信息等
来实现更高效的查询
- 优化命令
OPTIMIZE命令,可以在后台压缩小文件,将其合并为 1G大小- 用户也可以自定义大小
- 自动优化命令,
AUTO OPTIMIZE,允许后台自动运行 - Z-Ordering
- 在多维分析场景下回碰到,比如网络安全会记录 (sourceIp,destIp,time)
- Hive可以将其分区,但是太多的分区则影响性能
- delta-lake支持重新布局使的可以实现z-order,多个维度的高度局部性
缓存
- 因为delta-lake表的checkpoint、日志、数据都是不可变的
- 使用缓存就可以简单的加速查询,并且缓存对于用户是透明的
审计日志
- 开源版本的也有这个功能,运行
DESCRIBE HISTROY命令即可 - 审计日志也是不可变的
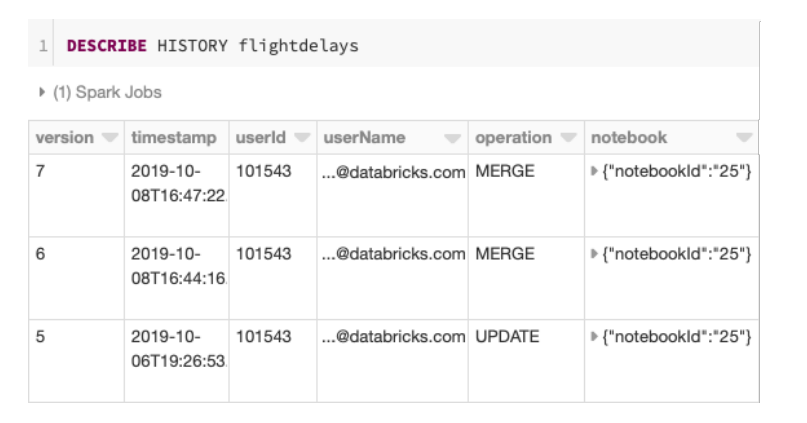
Figure 3: DESCRIBE HISTORY output for a Delta Lake table on Databricks, showing where each update came from.
schema演化
- 每个事务日志中都带有schema,当schema变更后,不会影响到旧的事务日志
- 于是旧的事务日志依然保留了旧表的结构,以及对应的parquet文件
- 如果新写入的数据格式不对,则最新的事务日志中就能检查出这个错误
连接到查询引擎和ETL
- 目前支持的查询因:Hive、Presto、AWS Athena、AWS Redshift、Snowflake
- ETL和CDC工具:Fivetran、Informatica、Qlik、Talend
- 使用符号连接清单文件的方式整合hive,对象存储中包含了一个文本文件,或者HDFS中文件包含一堆path
- 对待符号文件中的path,视为目录的内容,符号连接:_symlink_format_manifest
使用案例
每天处理EB级的数据,数据类型包括OLTP的CDC数据、应用log、时序数据、图
表聚合报告、图像、机器学习的特征数据
应用运行包括:SQL、BI、流、数据科学、机器学习、图分析
如同 figure 1中的那种架构,使用delta-lake之后可以简化不少
数据引擎和BI
- 传统企业因为成本压力,会考虑上云
- 数据的源头可能是可视化的目录追踪系统、OLTP中的销售点,用于下游数据和机器学习英语
- 他们会选择将数据存到数据湖中,因为存储成本更低
- 然后会导出数据放到数据仓库中,因为它的计算性能更好
- 使用delta-lake可以简化设计,重用之前的工具,支持SQL和API
数据仓库和BI
- 传统的数据仓库系统联合了ETL/ELT功能和有效的工具,可以实现交互式的查询
- 支持这些特性的技术是:合适的存储格式(列存)、数据访问优化如聚类和索引、硬件、查询优化引擎
- delta-lake支持事务,所以上面的都可以支持,用户可以在delta-lake上实现上述功能
规章制度
- 隐私的规则要求企业删除、或者损毁用户的个人数据,所以需要支持 delete、upsert
- 安全审计 帮助企业完成审计
- 时间旅行也可以用作机器学习修补数据
一些用户case
- 一个大企业,做网络安全审计的,有几P数据,每天会生成几百T数据
- 包括各种TCP、UDP、认证请求、SSH日志等
- 可能会有100个分析查询这个源头并导出数据,用于侦察某些可疑用户
- 因为是多维分析,所以后面采用了 z-order布局优化来提速了
- 一个搞生物研究的企业,分析DNA、RNA和各种基因序列
- 电子商务、旅游公司对各种资源文件做机器学习分析
性能实验
主要是两个实验
1、小文件合并后的性能
2、z-order
大量对象和分区的影响
- 大量小文件和hive风格的分区 -几千个都会影响性能
- 使用16个节点的集群,8核61G 19.T的SSD
- hive、presto都运行在云存储之上做查询,list大量小文件找过了一个小时
- 优化后的spark可以用450秒list出10W个分区
- 并行后的优化可以用108秒list 1百万个文件,用SSD可以17秒完成
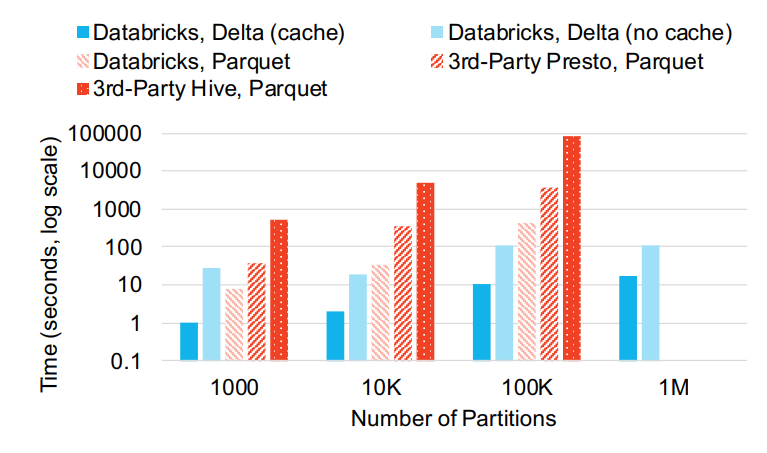
Figure 4: Performance querying a small table with a large number of partitions in various systems. The non-Delta systems took over an hour for 1 million partitions so we do not include their results there.
Z-order的影响
- 记录ip的信息:sourceIP, sourcePort, destIP,destPort
- 查询:SELECT SUM(col) WHERE sourceIP = “127.0.0.1”
- 使用这个查询在100个parquet中过滤效果很好,但是对于其他字段则没有效果
- z-order后的效果则好很多,500TB的数据,使用z-order可以跳过93%的数据

Figure 5: Percent of Parquet objects in a 100-object table that could be skipped using min/max statistics for either a global sort order on the four fields, or Z-order.
TPC-DS测试
- 8个节点 8核, 1T的TPC-DS数据
- 测试包括 delta-lake,spark,presto
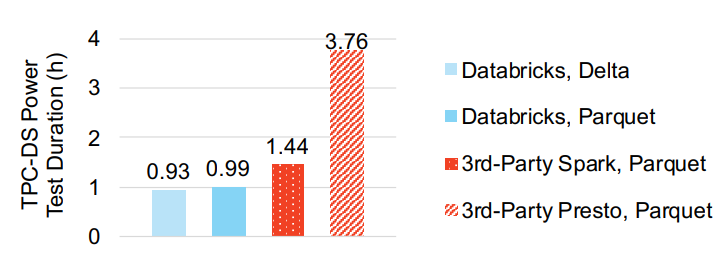
Figure 6: TPC-DS power test duration for Spark on Databricks and Spark and Presto on a third-party cloud service.
写性能
- 写入一个400G的TPC-DS表 store-sales数据
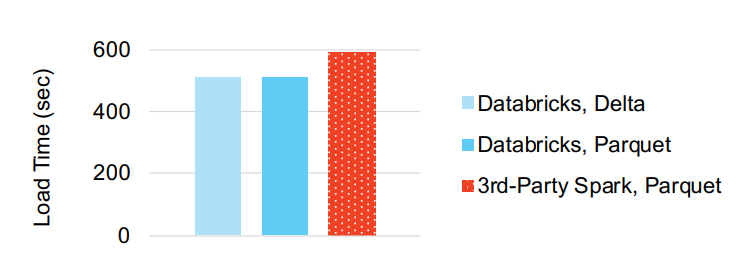
Figure 7: Time to load 400 GB of TPC-DS store_sales data into Delta or Parquet format
总结
限制
- 不能用多表事务,因为一个事务是记录在单表内log中的
- 对于很大的事务,协调器还可以调解对日志的写访问,而不需要成为数据对象读写路径的一部分
- 对于流场景,受到底层的云存储对象延迟的限制,很难实现毫秒级别的延迟,一般是几秒,但大部分企业可以接受
- 不支持二级索引,不过已经开始基于布隆过滤器的索引
越来越多的系统开始适配云环境
AWS Aurora OLTP系统
Google BigQuery , AWS Redshift Spectrum ,Snowflake 这是OLAP系统
这些系统需要额外的前端服务
如何自动的适配云存储,实现弹性、多租户的场景