What's Really New with NewSQL论文
What’s Really New with NewSQL? 论文
What’s Really New with NewSQL?
A BRIEF HISTORY OF DBMSS
一种新类型的数据库管理系统 NewSQL,可以可以之前系统无法处理的事情
最早是在2011年的一篇文章中出现的,讨论了商业数据库在增长的同时面临的挑战
当时正好有一批作者在开发他们的新系统,于是就使用了这个名字
关系型数据库的历史-1
- 最早出现在1960年,IBM IMS系统,用于记录土星V和阿波罗探索项目的 供应商和部分库存信息
- 它引入了一个新的理念,应用的代码和操作他们的数据 隔离开来
- 开发者只需要关注访问和管理数据,不需要关系真实的数据如何操作
- IMS的后继者是 1970年早期的 IBM System R 关系型数据库,以及加利福尼亚大学的 INGRES
- INGRES之后被很多大学采购用于他们的信息系统,并与1970年后期商业化
- 1970年后期Oracle也发布了他们的第一个版本,类似 System R的设计
- 1980年其他公司也发现了这些商机,开发了他们自己的数据库,如Sybase、Informix
- System R并没有被公开,但1983年新的数据库 DB2则使用了部分 System R的代码
- 1980年晚期和1990年早起,出现了新类型的数据库设计,消除了面向对象和关系型的阻抗匹配,叫面向对象数据库
- 由于他们没有采用SQL接口所以没有被广泛使用,但一些想法出现在10年后的数据库中(支持XML),以及20年后的NoSQL追踪
- 1990年还有两个重要的开源数据库,MySQL开始于1995年的瑞士,基于早期的ISAM mSQL系统
- 另一个开源的是1994年两个伯克利研究生,使用基于1980年代QUEL的Postgre代码分支,增加了SQL支持
关系数据库历史-2
- 到2000年代,由于互联网的到来,出现了更大的挑战,需要的资源远超之前
- 需要支持大量的并发用户并且时刻都要在线,但对于当时的数据库来说,硬件资源和处理能力都是瓶颈
- 很多人尝试垂直升级,但升级到最后效率就不明显了,而且将数据库从A机器移到B机器会导致停机
- 之后就出现了中间件的解决方案,对应用来说好像就只有一个数据库
- 而中间件将SQL做了改写,分发到多台机器,等这些机器执行完后,再汇总结果并返回给用户
- 其中典型的代表是e-bay基于Oracle的集群,以及谷歌基于MySQL的集群,facebook也采用了此方案,一直沿用至今
关系数据库历史-3
- 传统数据库的焦点是在一致性和正确性,从而影响了性能和可用性,而互联网应用更关注后者
- 对于只是简单的查询来说,使用传统数据库MySQL的,其很多功能都是多余的
- 在2000年中期出现了第一批NoSQL,他们放弃了事务保证、关系模型
- 他们选择了最终一致性,可以的数据模型 key-value,图,文档,因为这些更适合互联网
- 两个最著名的系统是谷歌的BigTable和亚马逊的Dynamo
- 后续的仿造者facebook的Cassandra和HBase,后面的系统都参考了NoSQL的哲学,最著名的是MongoDB
关系数据库历史-4
- 到了2000年代后期,出现了一批可扩展的的分布式DBMS,他们可以使用
- NoSQL的优势是开发人员只需要专注于他们的商业和组织,而不用关系伸缩问题
- 有一些组织和部分是需要支持事务的,比如对于订单,金融这些业务
- 有一些组织也发现了,他们的开发人员需要经常处理不一致的数据,如果有事务保证则会高效很多
- 早期的解决方案是垂直升级机器硬件,或者定制化中间件支持事务
- 由于这两点都不是很好的解决方案,因此出现了NewSQL系统
NewSQL的崛起
- 具备了NoSQL的伸缩能力和性能,也有传统数据库的事务保证
- 这些系统实现了2000年NoSQL的伸缩能力和1970-1980年代传统数据库的事务能力
- 开发者就不用担心最终一致性问题了,同时也解决了高并发问题,不需要使用NoSQL的那套API,只需要SQL即可
- 数据仓库出现在2000年代中期,典型的如:Vertica, Greenplum, Aster Data,这种类型的DB不应该放入NewSQL范畴
- NewSQL的目标是执行读写事务,并且生命周期应该是很短的
- 查询的数量较小,没有全表扫描或者大的分布式join,也是重复的,相同的查询with不同的输入
- 另一种争论是定义了一个更窄的限定,NewSQL系统必须实现无锁并发控制的schema
- 必须是一个 shared-nothing分布式架构,我们研究发现确实满足了上述风格
CATEGORIZATION
我们将NewSQL分为三类
- 使用了新架构设计出的新颖系统
- 跟2000年代谷歌设计的中间件类似,一种重新实现的中间件
- database-as-a-service,基于云计算实现的服务,也是一种新的架构
也包含了单节点DBMS的存储引擎,如MySQL的
- InnoDB
- TokuDB
- ScaleDB
- Akiban
- deepSQL
使用新存储引擎的好处是,兼容了以前所有的特点,工具、API都可以兼容
并且获得了比之前更好的性能
ScaleDB就是一个典型的例子,提供了透明的底层共享,而没有用中间件重新分布式 存储引擎之间的执行
微软的内存OLTP数据库 Hekaton,无缝衔接了传统的、驻留磁盘的表
其他的使用postgres的 foreign data wrapper和API实现整合,他们的目标是OLAP,如 Vitesse,CitusDB
对于这种只是 单机存储引擎的替换,或者是扩展的方式,不属于NewSQL
就像MySQL的innodb,它的可靠性和性能都很不错,所以替换它能得到的收益没那么大
当然如果是OLAP风格的,替换引擎确实能有很大提升,典型的如 Infobright, InfiniDB
但只是将MySQL的存储引擎替换为商业的,一般都是失败的案例
New Architectures
这里的都是新的架构,而不是基于现有系统,或者扩展实现的,像微软的Hekaton就是扩展
所有的newsql都是分布式架构,shared-nothing 架构,包含的组件支持多个节点的并发控制,容错通过复制、流控制、分布式查询处理等
他的优势是,所有的组件都是可以分发到多个节点上的。包括查询优化,通讯协议等
可以发送并发查询直接到数据节点上,而不是像中间件那样,经过一个中间层
他们管理自己的存储系统,在内存或者磁盘上;他们用自己的引擎来跨资源分布数据库,而不是基于现有的分布式文件系统(HDFS)或者存储结构(apache ignite)
这里有一个重要的特点
- send query to data
- rather than: bring the data to the query
这会极大的减少网络通讯
自己管理存储还有一个好处,就是复制的时候可以有各种多更的选择策略,而不是像HDFS那样,只能复制块
像Trafodion、Splice Machine 就是基于HBase之上的,他们的事务和传输就依赖HBase,因此这样的系统不算是NewSQL
不过太新的架构也有问题,很多技术可能都不成熟,未经过太多考验,能比较的范围也比较少
这也意味着新的组织可能会失去对现有管理和报告的访问能力
相关系统
- Clustrix
- CockroachDB
- Google Spanner
- H-Store
- HyPer
- MemSQL
- NuoDB
- sap hana
- VoltDB
Transparent Sharding Middleware
这些产品本质上来说,就是ebay、谷歌、facebook在2000年代搞出的中间件
就是将数据库分成多个分片,然后存储到多个节点上,这跟数据库联邦技术有很大不同
- 运行的是相同的DBMS
- 每个节点只有整体数据的一部分
- 访问、访问并不是完全独立的
中心化的中间件负责 路由请求、协调事务,管理数据位置、复制、跨节点的分区
在每个数据库节点上有一个简单的程序,这个程序跟 中间件通讯,这个组件负责执行代表中间件做查询,查询本地磁盘并返回结果
最后由中间件负责输出结果
中间件的方式好处是兼容性很好,开发者基本上不用重写他们的应用,而最通用的中间件系统就是MySQL
也就是为了兼容mysql,中间件的协议也是mysql的
中间件管理的节点都是传统的关系型数据库节点,他们是针对面向磁盘设计的,没有用到新的面向内存的架构设计
没有很好的存储管理、并发控制schema,这也限制了这些传统DB使用更多核的CPU、更大的内存
中间件也带了冗余的查询计划,比如中间件做了一次查询计划,每个节点也做了一次
相关系统
- AgilData Scalable Cluster
- MariaDB MaxScale
- ScaleArc
- ScaleBase
Database-as-a-Service
云计算提供了newsql database as a service 产品
使用者不用关心他们的硬件,或者云环境的虚拟机,相反DBaaS有责任来管理数据库的物理配置
包括系统调优,如buffer pool大小,复制、备份等
客户端用URL连接到这个DB,或者面板,或者API
DBaaS是基于块存储的,也就是公有云上的各种对象存储服务
客户定于他们指定的最大资源利用率阈值,比如存大小,计算能力,内存分配,剩下的由提供商来实施
一般来说,大的云厂商也是同样的参与者,不过他们的提供的服务底层都是基于传统数据库的
包括: Google Cloud SQL,Microsoft Azure SQL, Rackspace Cloud Database, and Salesforce Heroku
这些都是面向磁盘的设计,跟1970年代的数据库本质差不多,所以不算是newsql
另一些云厂商真的使用了新的脚骨,比如 Amazon的 Aurora,他们在 InnoDB之上增加了分布式特性
这是使用日志结构化存储来提供I/O的并行性
ClearDB 也是一个很有意思的列子,他们自己没有数据中心,完全是基于各个云厂商的
而他们的服务是可以跨不同的供应商的,在一个物理区域内跨不同的供应商,实现更好的容错
也有一些云厂商失败了,他们的失败原因
- 想法领先于市场需求
- 主要供应商定价过高
这里仅有的两个玩家是
- Amazon Aurora
- ClearDB
当然这篇论文是发表在2016年的,而现在 snowflake 肯定也算是一个玩家
THE STATE OF THE ART
main memory storage
所有的主要的数据库都是使用面向磁盘的架构,这种架构是基于1970年代的原始DMBS设计
这些数据库的主要存储位置是基于持久化的块地址设备,SSD、HDD等,因为他们读写太慢了
DBMS使用缓存保存block,从事务中更新buffer
这种设计的原因是内存太贵了,而且容量太小
但是如今,存储容量和价格都是负担得起了,可以将大型的OLTP的整个数据集全部放入内存中
这就可以实现很多优化,因为DBMS不再假设任何时候执行的事务,可能不在内存中
因此这些系统就可以获得更好的性能,很多这样的组件如buffer pool、繁重的并发控制schema都不是必须的了
这里有几个基于主内存的架构,包括
- 学术界的 H-Store、HyPer
- 商业街的 MemSQL、SAP HANA、VoltDB
这些系统在OLTP场景比传统的面向磁盘的架构,性能要好很多
基于主内存的架构并不是新玩意,1980年代威斯康星大学就建立了很多理论基础,包括
- 查询处理
- 索引
- 恢复算法
1990年代,第一批商业的分布式内存数据库出现了
- Altibase
- Oracle’s TimesTen
- AT&T’s DataBlitz
面向内存的架构还有一个重要功能,有能力驱逐数据库的一个子集到持久化设备
比如可以支持数据量远大于 内存容量,只需要跟踪那些不再访问的数据,将他们驱逐到磁盘即可
H-Store使用了anti-caching 组件来完成这个工作,它将冷tuple移动到磁盘端
并在原始数据位置上记录一个墓碑,当一个事务通过墓碑访问到tuple时
则访问会中断,并触发一个独立的线程去检索这些数据,将其重新加载到内存中
其他一些学术项目的DB,如VoltDB,使用虚拟内存,来支持超过物理内存大小的数据集
为了避免错误,所有这些DBMS在索引中保留了被驱逐元组的key,这限制了很多使用二级索引的应用的潜在内存开销
微软的 Hekaton维护了 每个索引的bloom filter,减少track驱逐tuple的内存存储开销
还有一个不同的设计是 MemSQL,采用了列存,也是允许数据集 > 物理内存
他不跟踪那些switch到磁盘的tuple,而是采用了日志结构存储,来减少更新的开销
这种开销在传统的OLAP数据库中消耗比较高
Partitioning / Sharding
几乎所有的newsql DBMS的扩展方式,都是将数据集split到一个不想交的子集中,这叫:分区、或者shared
基于分区的分布式事务处理不是什么新概念,在1970年代末就有研究了,到了1980年代,两个数据库的先驱,分别搞了他们对应的分布式版本:
- IBM’R* 分布式数据库,是一个shared-nothing、面向磁盘的DBMS
- INGRES的分布式版本,实现了动态的查询优化,将一个分布式查询递归的简化为小的查询
在当时,这两个分布式版的数据库几乎没什么使用场景,因为当时的硬件很昂贵,没有多少人能负担的起一个集群的开销
另外当时的业务量也不高,每秒的事务峰值是 10-1000,也不用到这种分布式数据库
但是现在不同了,想创建一个可扩展的、数据密集型的应用比以前要容易很多,这要归功于开源软件的功劳
另外硬件的价格也负担的起了
数据库的表被水平分割为多个片段,这个边界是由表列的一个或多个值决定的,也就是分区属性
属性的值使用 hash分区、或者range分区
多个表的相关片段组合在一起,形成一个单节点管理的分区;这个节点负责在分区上执行任何想要的查询
只有DBaaS的系统不支持这种分区,如Amazon Aurora、ClearDB
DBMS将查询执行分发到多个分区上,然后合并他们的结果为单个,几乎所有的newsql都提供了这种功能
OLTP的这些数据库还有一个关键属性,数据库模型可以被转换为 树结构,他们的后代可以通过关系找到root
根据关系中的属性对被做分区,单个实体的所有数据都被位于同一个分区中
比如,树的根节点是客户端表,数据库按照用户来分区,这样订单信息和账户信息就放在一个分区中
这样的好处是,在一个事务中只需要访问单个分区的事务,不需要有跨分区的事务,不需要原子的两阶段提交协议
NuoDB、MemSQL使用了非对等的架构,它包含若干存储数据的 storage manager SM,以及transaction engine TE
SM将数据库切分为block,也叫作原子
TE节点减少所有的原子,从对应的SM或者其他SM获取,TE需要一个写锁,然后广播修改到其他的TE或者SM
为避免原子在节点间移动,NuoDB 有负载均衡机制,确保经常使用的数据在相同的TE内
这意味着NuoDB跟其他分布式数据库有类似的分区方案,但不需要预分区,或者识别表之间的关系
MemSQL也是一个非对等的架构,包括只做执行的聚合节点,以及真正存储数据的页节点
NuoDB中,TE会缓存数据来减少存储节点的返回数据开销
MemSQL不缓存数据,不过页节点只执行部分查询,以此来减少返回的数据量开销
这两个两个系统是 异构系统,而同构系统:每个节点都存储数据并执行查询
在性能和操作复杂性方面,异构系统是否有优势,还有待研究
newsql的分区还有一个特点,是支持在线迁移,可以让数据在物理资源之间重新平衡,缓解热点
也可以增加/减少DBMS的容量而不用中断服务
这种方式在nosql中很常见,不过NewSQL执行这些平衡时,仍然支持ACID,和事务
它是通过两方面实现的
- 组织数据库为多个虚拟的粗粒度的逻辑分区,让他们分布到多个物理节点,当需要重平衡时,就移动这些逻辑分区
- 使用这种技术的是:Clustrix and AgilData,类似的NoSQL是:Cassandra and DynamoDB
- 另一种方式通过范围分区,重新分布式独立的tuple、以及tuple组,实现更细粒度的平衡
- 使用这种自动sharding的NoSQL是 mongoDB,NewSQL是:ScaleBase、H-Store
Concurrency Control
这是DBMS事务处理中最突出,最重要的实现了,它也影响了系统的所有特性
并发控制允许终端用户以多种程序风格访问数据库,同时也保证了一种错觉,它让用户以为执行的事务是在独立的系统上运行的
本质上它提供了原子的、隔离的保证,它也影响了整个系统的行为
分布式DBMS另一个重要的特性是,中心化的、还是去中心化的:
- 中心化的事务协调机制,所有的事务都通过一个中心协调器,由它来决定执行或不执行
- 1970-1980年代,IBM CICS,Oracle Tuxedo
- 去中心化的,每个节点管理访问数据的事务状态,然后节点之间相互协调,以确定是否并发冲突
- 去中心化的协调机制有更好的扩展性,但需要DBMS节点之间的时钟高度同步,这样生成全局有序的事务
第一个分布式数据库出现在 1970-1980年代,使用了 two-phase locking 2PL,SDD-1,有一个中心化的协调机制
IBM的R* 是去中心化的,使用了分布式的2PL协议,事务直接锁定在节点上的数据项
INGRES的分布式版本也是去中心化的2PL,使用了一个中控的死锁检查机制
现在的分布式数据库的新架构几乎都避开了 2PL,因为处理死锁方式很复杂
现在的趋势是使用: 时间戳排序(TO)的并发控制变种,数据库假设事务不会执行 违反序列化顺序的交错执行
NewSQL中使用最多的协议是 去中心化的 multi-version concurrency control MVCC
MVCC允许事务直到完成,即使另一个事务在更新相同的tuple,也允许长时间允许的只读事务,不会阻塞写
使用这个协议的包括:
- MemSQL
- HyPer
- HANA
- CockroachDB
这些都不是新玩意,第一个相关的MVCC描述是MIT 1979年的博士论文
第一个商业数据库使用MVCC的是 Digital’s VAX Rdb 和 InterBase,在1980年代
值得注意的是,InterBase的设计者也是NuoDB的设计者,也是MySQL存储引擎Falcon的设计者
其他一些系统混合了 2PL和MVCC,事务底层仍然使用2PL获取锁,修改数据库
当事务修改一条记录,DBMS会创建一个记录的新版本使用MVCC,允许只读事务,这样不阻塞写事务
最著名的例子是MySQL的InnoDB、谷歌Spanner、NuoDB、Clustrix
其中NuoDB改进了MVCC,使用gossip 协议在节点之间广播版本信息
所有的中间件以及DBaaS都继承了并发控制模式,因为其底层的是MySQL,所以有MVCC的2PL
Spaner
- 包括它的后代F1和Spanner SQL,他们都是混合了几十年前的MVCC和2PL协议
- 它的不同之处在于硬件设备,GPS,原子时钟,来实现高精度的时钟同步
- 使用这些时钟来规范事务分配时间戳,实现广域网上多版本数据库的一致性视图
CockroachDB跟Spanner类似的一致性,跨多个数据中心的事务,但没有使用原子时钟
它使用了一种混合时钟协议,这种协议包含了 同步的硬件时钟,以及逻辑计数器
Spanner这种设计也表明他们继续使用了事务,而作者甚至说,让程序员处理过度使用事务而导致的性能问题
而不是像NoSQL那样,通过代码处理缺乏事务导致的问题
唯一没有使用MVCC的是VoltDB,他使用了TO并发控制,它调度事务在每个分区上挨个执行
它使用了混合的架构,单个分区事务可以分散化的方式调度;多个分区事务以集中化的协调者调度
VoltDB以逻辑时间戳排序事务,并将他们调度到一个分区上执行
当分区的事务执行时,会阻止分区上所有的访问,所以这里没有设置lock或者latch
这样事务之间就没有冲突了,执行效率非常高,但缺点是多个分区之间的事务则会降低效率
基于分区的事务不是新玩意,最早的变种在1992年,其实现是1990年代后期,H-Store,而VoltDB是其商业版
总的来看,NewSQL的并发控制都没有什么重要的新东西,不过这些系统在工程方面做的都不错,利用了现代的硬件以及分布式的环境
Secondary Indexes
二级索引包含了表的一些属性,它跟主键索引不同;允许除主键索引、分区索引之外的另一种快速查询方式
在单机版的DB中能很好允许,但是在分布式数据库中就有很大挑战
因为不能跟数据库其他部分以相同的方式分区
假设,以客户表的主键作为分区,但是有些查询是根据客户的e-mail去反查账户信息的
由于是主键分区的,那么DBMS就只能把查询广播到所有节点,效率很低
在分布式数据库中,支持二级索引需要考虑两个设计决策
- 系统在哪里存储它们
- 如何在事务的上下文中维护它们
如果是基于共享中间件的方式,二级索引可以驻留在协调节点,或者共享节点上
这种方式的优势是,整个系统只有一个版本,很容易管理
所有的分布式数据库都是去中心化的,使用分区的二级索引,这意味着每个分区存储索引的一部分
而不是每个节点拥有全部的索引,需要在分区索引,和复制索引之间做权衡:
- 分区索引,一个查询可能会跨多个节点才能找到想要的数据,但更新索引则只需要修改某个节点
- 复制索引,查询只需要一个节点就可以完成,但是更新二级索引的属性,则需要分布式事务,更新所有节点
Clustrix的去中心化二级索引混合了者两种模式
它在每个节点上维护了一个复制的、粗粒度的索引(range的),索引将值映射到分区上
这个映射可以让DBMS根据查询属性,路由到对应的节点上,请求会访问节点上的二级分区索引,索引将值映射为tuple
这种两层的方式减少了维护的协调的数量,这个协调者是需要跨集群同步复制的索引
它只需要映射到rangef而不是单个值
所以这种方式相当于是 复制索引、分区索引的一个折中
对于那些不支持二级索引的数据库,一般的解决方案是将索引放到一个分布式缓存如Memcached中
但需要开发者额外的维护缓存,因为DBMS不会自动的让外部缓存失效
Replication
对于OLTP系统来说,要保证其高可用、持久性就需要复制机制,所有的NewSQL都支持各种类型的复制机制
DBaaS有点特殊,因为他们对客户端隐藏了所有复制细节,管理员可以很轻松的部署一个复制的DB,而不用担心日志复制以及节点同步这些问题
这里有些设计决策需要考虑
- 如何在跨节点时保证数据一致性,对于强一致性的事务来说,必须在提交前确保所有的数据都被复制了
- 这种方式的优势是副本可以处理读,仍然能保证一致性
- 如果应用收到了事务被commit的确认,那么后续的修改不管访问哪个节点,都能保证可见性
- 这意味着即使某个副本挂了也没关系,因为其他副本是同步的
- 维持这种同步需要一种原子协议,如两阶段提交,也就是所有的副本都同意这个结果
- 这增加了额外的开销,如果有节点挂了,或者出现分区,那么就会卡主
- 这就是为什么NoSQL支持弱的(最终一致性),当DBMS通知应用写成功了,但不是所有副本都知道这次修改
NewSQL都支持强一致性,但这不是什么新玩意,基本的状态机复制研究在1970年代就有了
NoStop SQL是第一个分布式数据库,在1980年就出现了,提供强一致性来实现容错
DBMS传播一个更新到副本,有两种不同的执行模式
- active-active复制,所有的副本节点都同时处理相同的请求,DBMS在所有副本上并行执行这个查询
- active-passvie复制,在一个节点上执行完后,然后将结果传输到其他节点
NewSQL都是采用第二种,因为他们使用了一个不确定的并发控制模式
这意味着当请求到达主副本时不能做查询,因为可能会以不同的顺序在副本上执行,每个副本上的数据库状态也是不同的
执行的顺序依赖好几种情况
- 网络延迟
- 缓存
- 时钟倾斜
一些确定性的DBMS,如:H-Store、VoltDB、ClearDB,它们不会执行额外的协调阶段
因为DBMS保证了事务在 每个副本上以相同的顺序执行,因此数据库的状态是相同的
VoltDB、ClearDB确保应用不会执行DBMS外部源的查询,这些信息在每个副本上是不同的(如给本地系统时钟设置时间戳)
现代NewSQL跟之前不同的是,考虑到了WAN广域网复制问题,因为现代环境需要跨低于很远的数据中心部署
但这会带来很大的网络延迟,于是这些系统提供了异步复制
这里最著名的是Spanner,CockroachDB,他们提供了一个优化的,基于WAN的强一致性复制
使用了硬件时钟,以及混合逻辑时钟
失败恢复
NewSQL提供了另一个重要特新是容错,也就是在宕机中恢复的机制
传统的DB需要确保更新不会丢失,而现代的NewSQL还要考虑到最小化宕机时间,因为web应用是实时在线的
传统的恢复方式对于单机(没有复制的情况下),当DB挂了,它会从磁盘上load最近的checkpoint,并重放WAL,恢复到crash哪个时刻的状态
规范化的方式是ARIES,这是IBM在1990年代的研究产物,所有主要的DBMS都是ARIES的变种
但是这种方式不能直接用于分布式数据库,当master宕机后,其他的某个slave会变成新的master
而当旧的master重新恢复后,它不能只load最近的checkpoint并运行WAL,因为DBMS还在继续运行,数据库状态一直在变
恢复的节点需要从新master那里得到宕机的这段时间的更新状态,那么恢复节点需要:
- 加载最新的checkpoint和WAL,并从其他节点pull丢失的日志
- 只要这个节点处理日志的速度 > 新的更新速度,那么这个节点最终会更其他节点状态一样
- 因为DBMS使用物理日志,将其直接应用到tuple上,其速度 远小于 执行原始的SQL,所以这种方式是可行的
- 另一种恢复方式是,恢复节点放弃现有的checkpoint,选择一个新的
- 这种方式的好处是,对于新加入的副本,也可以采用相同的复制方式
- 对于中间件、DBaaS需要依赖底层的单节点DBMS,但需要额外的选举和其他管理能力
NewSQL系统依赖的新架构联合了现有的机制如 Zookeeper、Raft,以及自定义的Paxos
所有与的这些标准程序、技术,自1990年代在商业的分布式系统中就已经有了
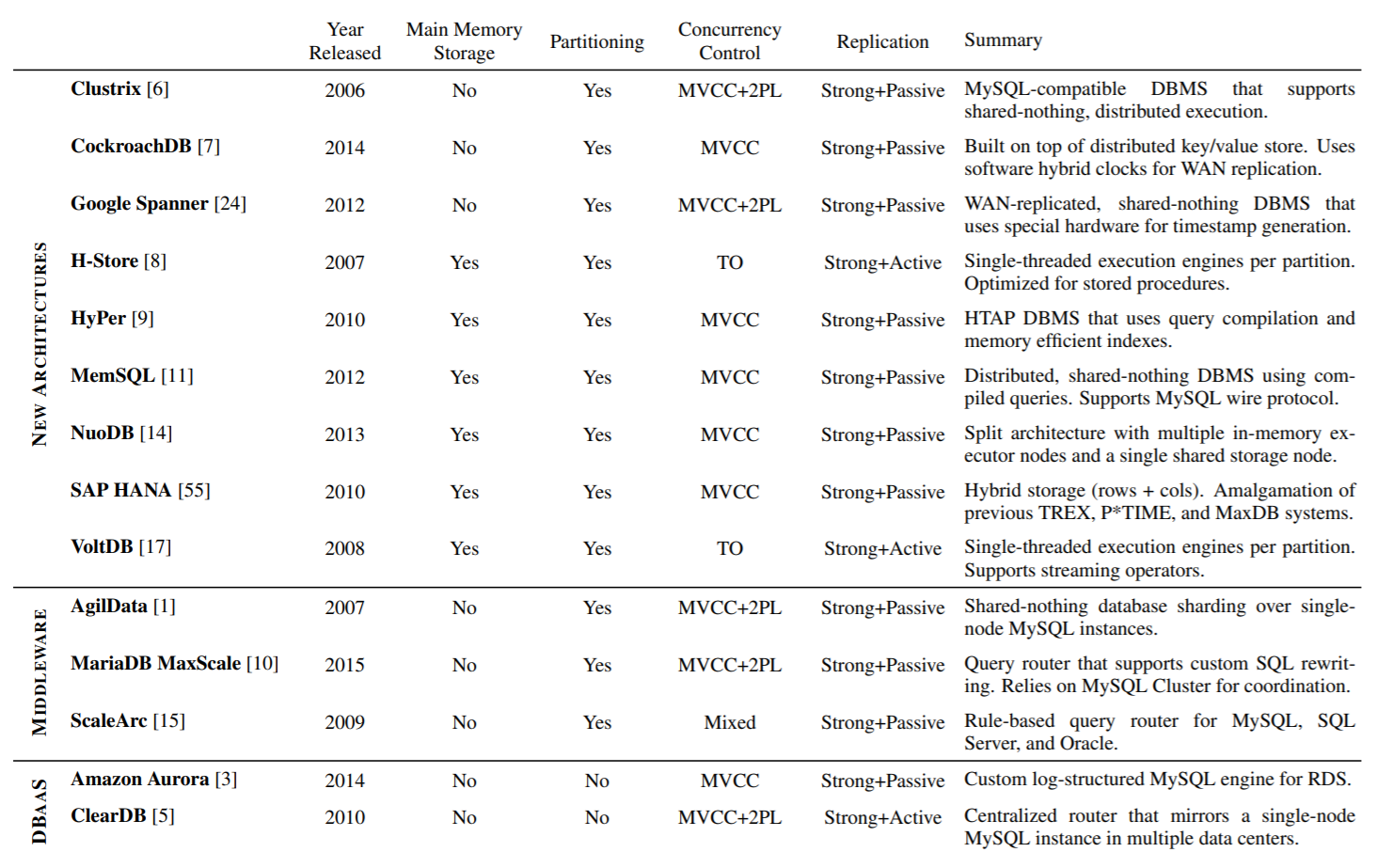
Table 1: NewSQL Systems – Summary of the system features described in Section 4 for the different DBMSs. Note that the year released is either when the project was announced publicly or when the company was first formed.
FUTURE TRENDS
下一个趋势是,数据库应用能够对 新获得的数据,执行分析查询和机器学习算法
也就是实时分析,或者是混合事务分析处理HTAP,通过分析新数据和历史数据,获取能力和知识
以前的商业BI只能针对历史数据做分析,而现在的应用需要对实时数据做分析,因为数据刚创建的时候价值最大,随时间推移价值会降低
为实现HTAP一般有这么几种方式:
- OLTP来处理最新的事务,通过ETL将数据放到数据仓库中,复杂的OLAP查询去数仓避免拖累OLTP,而OLAP新生成的数据则写回到OLTP中
- lambda架构,批处理层使用Hadoop和Spark在历史数据上计算综合视图,同时流处理(spark-straem和storm)提供增量视图
- 批处理层周期的重新扫描数据集,将结果写到流系统,然后基于新的数据做修改
- lambda的问题是两个隔离的系统传播变更需要分钟甚至小时级别,使的应用不能立刻处理刚到的数据
- 维护两套系统开销也不小,需要联合两套系统,就需要写两套系统的查询
- 有些系统隐藏了底层的实现,对外看起来只有一个系统,但这种系统也有问题,需要将OLTP(HBase)拷贝到OLAP(Spark)才能使用
- 第三种方式,是HTAP同时支持OLTP和OLAP,OLAP可以同时查冷(历史)数据,热(事务)数据
- 这种系统是整合最近10年的技术,OLTP的内存存储、无锁执行,OLAP的列存、向量化执行,将其融入单个DB中
SAP HANA和MemSQL是第一批NewSQL系统
HANA包含了两个引擎,包含一个面向行的引起处理事务,一个面向列的引起处理分析查询
MemSQL也包含了这两种存储管理,但是将他们混合到了一个引擎中
HyPer可以做引擎切换,它有一个面向行的系统H-Store-style用于处理OLTP的并发,以及一个OLAP的列存用MVCC实现,支持复杂查询
即使是VoltDB也改变了他们的市场营销策略,从原始的OLTP提供流式语义
S-Store支持流语义,是在H-Store架构之上做的,它有点像2000年代的特殊OLAP系统Greenplum,能更好的支持OLTP
HTAP的崛起意味着OLAP数据仓库的没落,它们将成为组织所有前端OLTP筒仓的通用后端数据库
但最终数据库联合的兴起,允许执行多个跨OLTP数据库的查询(甚至包括多个供应商),而不需要移动数据
CONCLUSION
NewSQL系统并不是背离了现有系统的架构,他是对现有技术的延伸
现有系统的技术都是之前出现在学术、工业界的,但这些系统只针对单个问题做了实现
NewSQL的创新是将这些技术整合为一个平台,但是技术难度并不小
当前的计算资源很丰富价格也不贵,但同时应用的需求也比之前大的多,分布式数据库就是这个时代的产物
NewSQL的商业市场也是一个有趣的话题,传统的DBMS市场依然不可动摇,最近几年一些NewSQL的公司已经死了,或者转型去专注其他问题了
根据我们的调查,目前NewSQL的采购比列并不高,特别是跟NoSQL相比
NewSQL是设计用来支持事务场景的,在企业应用中更常见,但企业相比web应用一般更加保守
NewSQL一般是作为传统DB的补充,而NoSQL是部署在新应用的工作场景中的
2000年代开始的OLAP数据库,大部分供应商都被巨头收购了,而NewSQL被收购的很少
2016年Tableau收购了HyPer
2015年,评估收购了FoundationDB,不过这个其实是NoSQL,在上面增加一个低效的SQL封装
ScaleArc acquiring ScaleBase,这是一个竞争对手收购另一家
以及2011年,传统供应商收购新兴企业 Teradata收购Aster Data
一些大厂则没有选择收购,而是创新、改进了他们的系统,如微软的内存数据库Hekaton,改进了OLTP场景
Oracle和IBM对其产品做了创新,增加了列存,可以让其产品跟OLAP系统(HP Vertica,Amazon Redshift)做竞争
更长远看,这四类系统未来可能都会趋于一致
- 老的DBMS如1980-1990年代的
- 2000年代出现的OLAP系统
- 2000年代出现的NoSQL系统
- 2010年代出现的NewSQL系统
所有这些系统都支持某种形式的关系模型和SQL
以及OLTP和OLAP场景混合在一起 HTAP