Architecture of a Database System论文翻译
原文地址
https://dsf.berkeley.edu/papers/fntdb07-architecture.pdf
Introduction
数据库管理系统是一个非常重要的组件,包含了学术界、工业界十多年的研究成果
早期的DBMS是设计用来服务多个用户的,很多先进的理念如扩展、可靠性也被用作其他场景
虽然DBMS教科书中介绍了很多算法和抽象,但关于系统设计方面的材料却很少,这篇论文就是讨论DBMS的设计理论,包括
- 处理模型
- 并发架构
- 存储系统设计
- 事务系统实现
- 查询处理和优化架构
- 以及一些共享组件和工具
数据库市场的玩家就那么几个,被高端产品占据了
从事数据库的人一般都时高校、知名社区或者知名公司,范围比较小,所以影响力没那么大
另外传统教科书中偏算法和抽象概念,真正到架构设计层面的很少
所以这篇论文相当于是对传统教科书的补充,但不会牵涉到代码细节,毕竟太多了
主要是描述DBMS系统的架构设计,再对比开源和商业数据库的设计
Relational Systems: The Life of a Query
如今的成熟的、被广泛使用的数据库系统是:关系型数据库管理系统 DBMS
这些系统被用作很多应用的基础设施核心,包括:
电子商务、医疗记录、账单、人力资源、工资单、客户关系管理、供应链管理
DBMS作为几乎所有的在线事务、在线内容管理系统:blogs、wikis、社交网络等
下面以一个典型的查询作为入口,来看看关系型数据库的整体结构
一个登机口代理点击一个表格,请求航班的乘客列表,这个点击会触发一个单个查询事务,整个工作流程如下:
- 客户端通讯管理
- 代理机构作为入口点,相当于客户端,会调用API,由DBMS的客户端通讯管理来负责
- 建立客户端<->DBMS服务端的连接,比如ODBC、JDBC等,这种是两层结构
- 此外客户端可以通过一个中间件,如web服务,事务处理监听,它使用一个协议代理,作为客户端和服务端的中间层
- 上面的是三层结构,如果还有一个应用服务器,那么相当于是四层结构
- DBMS需要兼容上面所有的场景,不过大体来说上面的连接处理都是类似的
- 建立连接,并记录连接的状态(客户端、中间件),返回数据和控制信息(错误编码等)
- 将客户端的请求更深入的转发到DBMS中进行处理
- 处理管理
- DBMS需要分配一个计算线程,来处理上面接收到的命令
- 同时也会将计算结果通过连接返回给客户端
- DBMS需要决定此时的查询是否要开始处理,或者延迟一段时间等待资源充足再处理
- 查询处理
- 一旦开始执行,就调用查询处理模块,对用户做认证,并编译SQL查询文本,将其转换为内部的查询计划
- 计划执行器就可以执行这些计划了,计划执行程序包括一系列的算子
- 如:join,selection、projection、aggregatin、sorting等等
- 这里还包含了一个查询优化过程
- 事务存储管理
- 有一个或者多个算子从数据库上请求数据,他们调用了事务存储管理模块
- 这个模块管理了所有数据的访问(读)和维护(创建、更新、删除)
- 存储系统包括用于组织和访问磁盘上数据的算法和数据结构,如表、索引
- 也包括了buffer管理,决定了数据在磁盘和内存中的移动
- 为了确保事务的ACID,需要在访问前加上lock,必须跟其他事务冲突
- 如果是更新操作,在commit时候需要持久化,如果未完成需要中止
- 返回结果
- 从数据库中获取到tuple后,放到客户端的连接缓存中,返回给客户端
- 如果结果集很大,需要分批次返回,客户端下次调用还会触发到通讯管理、查询处理、存储管理模块
- 对于简单的结果就直接返回了,之后连接会关闭,事务管理会做清除状态,处理管理也会释放所有控制结构
除此之外,还有内存管理、catalog等共享组件
当一个请求来了,会有认证、解析、查询优化这些阶段,都会使用到catalog
DBMS也会决定内存的释放和分配
Process Models
设计多用户服务时,早期的决策需要考虑到执行多用户并发请求,以及如何将其映射到OS的进程、线程中
这些设计决策深度的影响了后面的系统设计,以及性能、扩展性、移植性等
我们从一个方简化的模型开始讨论
讨论依赖下面的定义
- 操作系统进程联合了操作系统程序执行单元,利用私有地址空间去执行,包括对处理器资源的管理,安全上下文,由OS内核调度单个程序执行单元,每个程序有自己唯一的地址空间
- 系统线程是一个OS程序执行单元,无需额外的私有OS上下文,无需私有地址空间,进程内的线程资源共享;线程由内核调度,系统线程称为内核线程,k-threads
- 轻量级线程,用户态线程,由用户态调度者负责调度,避免了上下文切换,比基于OS调度的更快;缺点是任何阻塞的线程都会 阻塞所有线程;可以:(1)采用异步I/O,(2)避免任何阻塞操作,轻量级线程提供了不同的模型,基于OS进程、OS线程
- 一些DBMS有自己的轻量级线程 LWT实现
- DBMS客户端需要实现一个通讯协议跟服务端交互,如JDBC、ODBC、OLE/DB,有些是采用了嵌入式SQL编写,这种是混合了程序语言和数据库访问的技术,最初是IBM COBOL、PL/I,以及之后的SQL/J(java实现),这个实现最终是调用API完成的,这种混合方式都是私有且无文档的
- 过去有几次尝试标准化 client-database的通讯协议,但都失败了,最著名的是 Open Group DRDA
- 工作线程用来执行客户端的请求任务,并响应,跟客户端是 1:1对应的
Uniprocessors and Lightweight Threads
这里我们简化了处理器模型分类,这些架构对现代的DBMS影响很大
首先我们有如下假设:
- OS线程支持,假设OS是支持线程的,有内核线程,可以支持非常多的线程,切换开销小,内存开销也不大;这些假设在如今都是成立的,但很多DBMS最初设计时并不是这样,有些OS不支持,或者调度很差,DBMS需要自己实现
- 但处理器硬件,假设所有的设计都是在单机单CPU上,CPU包含多个核心,现代系统不会使用这种架构,但会简化讨论
通过简化模型,得到了三种处理模型,如今所有的商业DBMS都使用这三种模型
- 每个工作者一个进程
- 每个工作者一个线程
- 处理器池
Process per DBMS Worker
- 这是最简单的模型,也是最早的实现,现在仍然有商业数据库使用这种模型
- 这种模型直接将DBMS 的worker映射到OS的进程中,OS的调度器负责分配worker和DBMS的时间片
- 这种模式对于一些常见的debug工具,内存检查工具也能良好适配
- 这种模式下,DBMS的连接器,lock table、buffer pool都需要共享内存,需要OS显示的支持
- 这种模式需要大量的进程间共享内存,降低了内存地址隔离
- 这种模式需要进程间切换,包括:安全上下文、内存管理状态、文件和网络处理表、其他的进程上下文
- 这些在线程中都不需要,所以其并发效率不如线程
- 不过仍然有一些商业的数据库采用这种模型:IBM DB2、PostgreSQL、Oracle
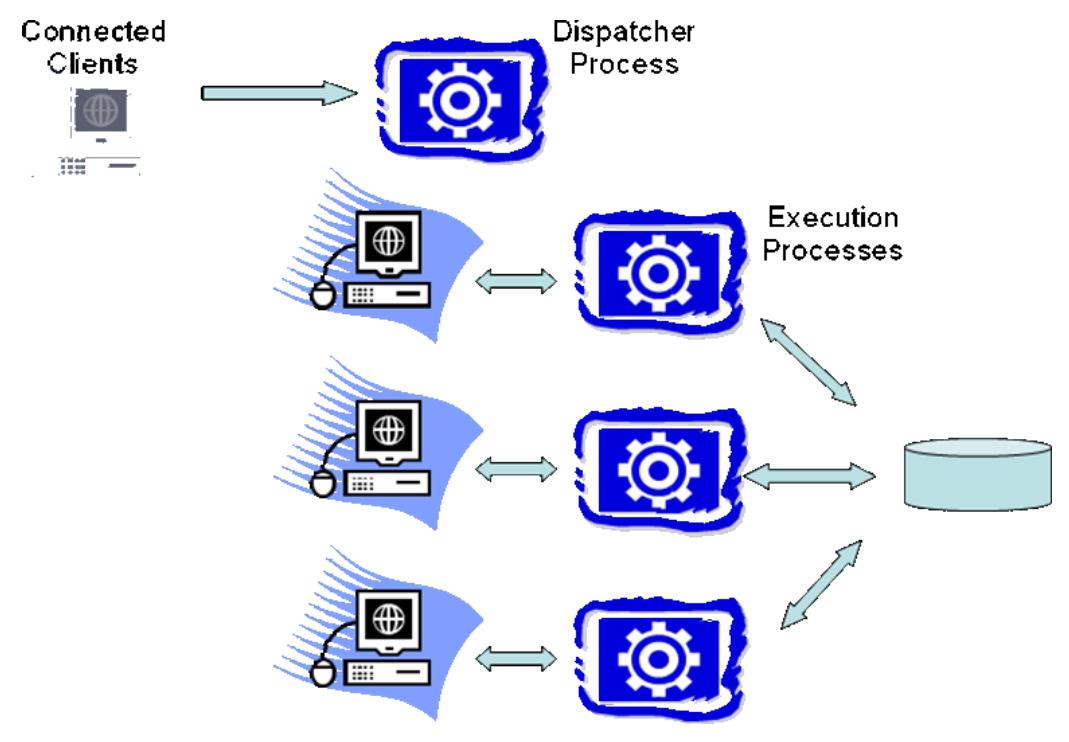
Thread per DBMS Worker
- 单个dispatcher线程负责分配SQL任务,然后启动对应的线程执行,执行完后线程返回,等待下一次执行
- 多线程也带来了新的挑战,其他线程导致的内存溢出会影响到当前线程,以及指针问题,调试困难,别特是条件竞争问题
- 线程接口和多线程扩展性的不同,导致软件在不同OS之间迁移很困难
- 多线程模型中的问题,在进程模型中也会存在,都是大量的使用了共享内存
- 虽然跨OS的多线程问题已经被最小化了,但仍然存在,也不好调试
- 目前使用多线程模型的包括:IBM DB2、SQLServer、MySQL、Infomix、Sybase
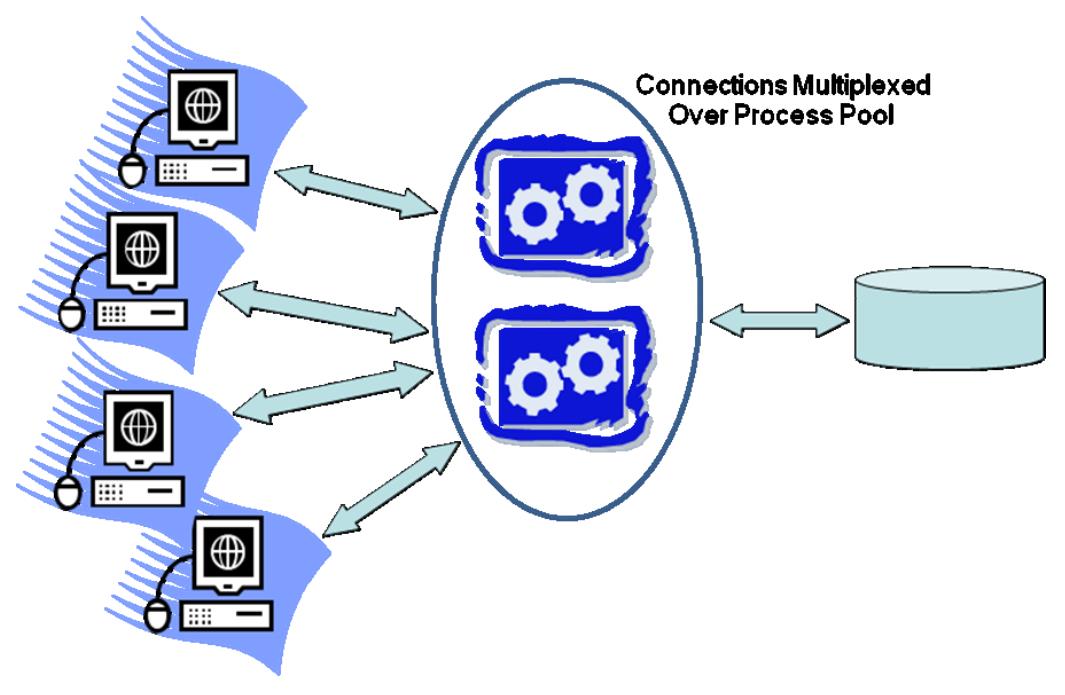
进程池
- 这是进程模型的变种,有个固定大小的进程池,避免了重分配的开销
- 可以设置最大、最小进程数量,做到动态调整
- 这种模型在今天也很流行
共享数据和处理器边界
- 所有的模型目标都是处理并发请求并尽可能独立,但实际不可能
- 他们都需要操作共享的相同的数据库,这些三种模型都需要将数据库中的数据移动到客户端
- 也就是移动到服务端进程,再将所有结果返回给客户端
- 这里主要是依靠各种buffer,主要是两种 磁盘I/O buffer,客户端通讯buffer
磁盘I/O buffer
- 最常见的跨worker的数据关系依赖,对数据库的读写操作,包括数据库请求、日志请求
- 对于线程模型,buffer pool是简单的驻留堆内存的数据结构,让所有线程共享DBMS地址空间
- 其他两种模型也是类似的,buffer pool对于进程/线程来说,都是大的共享数据结构
- 当线程需要从数据库中读一个page时,会生成一个I/O指定磁盘地址,并在buffer pool中放置一个空闲的帧
- 当需要flush buffer pool到磁盘,I/O请求包含buffer pool当前page的帧地址,并指明磁盘的目标地址
日志I/O请求
- 是一个或多个磁盘中的存储的 数组条目
- 日志在事务执行中生成,他们首先放在内存队列,然后以FIFO形式周期的flush到磁盘
- 这个队列一般叫做 log tail,一个独立的进程、线程负责周期性的将日志刷新到磁盘
- 在线程模型中,log tail是堆内存的数据结构
- 对于进程模式,有单独的进程负责管理日志,日志条目跟日志管理器通讯,是通过共享内存、或者进程间通讯交互的
- 总体来说log tail跟buffer pool的管理方式类似
- 事务必须等到日志flush到磁盘才算成功,这意味着客户端必须等到日志flush,DBMS也必须保持住所有资源
- 为了提高效率,可以批量flush一批日志
以上两种都是磁盘I/O buffer,客户端通讯buffer:
- 这是一种pull模式,客户端通过游标的方式,周期性的消费tuple
- DBMS会在FETCH流之前工作,以便在客户端请求之间将结果排队
- 为了支持预抓取行为,DBMS用客户度通讯socket当做队列,来产生tuples
- 更复杂的方式实现,包括客户端游标缓存,DBMS客户端存储将为可能的结果,而不是依赖OS通讯缓存
lock table:
- lock table在所有的worker中是共享的,被Lock 管理器使用
- 这是用来实现数据库的锁语义
- 共享锁表和buffer pool的技术相同,相同的技术也可以支持其他共享数据结构
DBMS Threads
前面假设OS有高性能可用的线程,DBMS只针对单个处理器
后面放宽第一个限制,多处理器和并行在后面章节讨论
现代的DBMS都源自1970年代的研究系统,以及1980年代的商业化努力
最初DBMS构建时,都没法用到现代OS的一些特性
1990年代,OS线程才被广泛的使用,即使今天,实现也有很大差异,OS线程实现也不能完全支持各种DBMS负载场景
因为历史、移植性、扩展性等原因,还是有很多DMBS没有使用OS线程,他们使用的还是进程模型
这样就避免了内核支持不够好导致的一些问题,一些DBMS使用了自己实现的线程模型,也就是轻量级线程
每个DBMS线程管理自己的状态、通过异步、非租塞方式执行可能阻塞的I/O操作
有调度线程来负责分发任务
轻量级线程不是什么新概念,曾经广泛的使用于 用户态的事件驱动程序
这种架构提供了快速的任务切换、方便移植,但需要将OS中的很多逻辑,在DBMS中重新实现
Standard Practice
我们对流行的数据库 IBM DB2、MySQL、Oracle、PostgreSQL、SQLServer做了一些总结
- 每个进程一个worker
- 所有的商用数据库中,最有意思的当属 IBM DB2
- 如果OS能很好支持线程,则默认使用每worker一个线程模型,可选的是线程池模式
- 如果OS不能支持,则默认使用每worker一个进程模型,可选的是进程池模式
- Oracle也支持进程模式
- PostgreSQL只支持进程模型
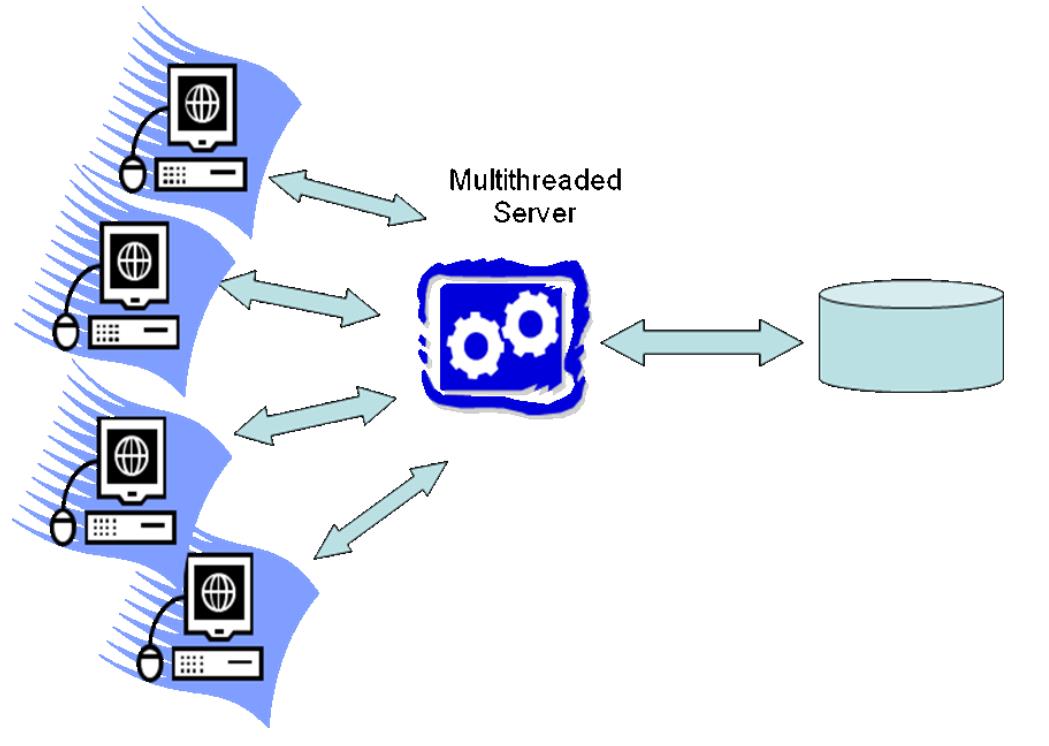
- 每个线程一个worker
- OS线程模式:像DB2 默认就支持(如果OS对线程支持很好的话),MySQL也是这种
- DBMS线程,通过在OS进程、或OS线程上执行轻量级线程,调度DBMS线程
- 这种模型避免了扩展和性能问题,但代价是实现成本很高,维护成本高,相关开发工具支持较差
- 基于OS进程的轻量级线程:Sybase、Infomix使用这种模型,DBMS调度线程基于多个OS进程,以便发挥多处理器功能,这种模式不能很好做线程的load balance
- 基于OS线程的轻量级线程:SQLServer使用这种模式,在线程池上做多路复用
- 线程/进程池
- 之前是进程池,后面又衍生出线程池模型,是在一个OS线程池之上做多路复用
- 基于进程池的多路复用:比进程模式更好,能支持更多连接,Oracle可选支持,通过这种方式Oracle支持超过80多种不同的OS
- 基于线程的多路复用:SQLServer默认使用这种模式,90%的SQLServer都配置了这种模式,也支持之前提到的DBMS线程模型
现代的商业DBMS,都支持内部查询并行化,也就是将单个查询的多个部分由多个处理器并行支持
这需要临时分配多个DBMS工作线程/进程,来负责单个SQL查询
底层的工作模型不会受这种特性的影响
Admission Control
这章快结束时,我们来讨论下支持多并发请求,在并非场景下,吞吐量的增长可能会接近某个极限值
此外,当系统快要崩溃时,它就会急速下跌,对于OS来说,崩溃场景通常是内存压力
DBMS不能将数据库的工作集的page放到buffer pool中,需要频繁的替换
特别是在查询处理如:排序、join时,需要花费大量的内存
在锁竞争时也会发生,事务连续的死锁,需要回滚并重启,因此任何良好的系统都需要admission control策略
有了这种控制,当系统负载超标时,不接受请求直到系统可用为止,这样系统可以优雅的降级,事务延迟会成比例的增加,但仍然能保持一个峰值
入场控制有两个层级
- DBMS的dispather进程来负责管理,如果连接到达阈值后,就停止接受
- 对于不支持这种模式的DBMS,需要由其他层来负责,如应用服务器、事务处理监控、web服务等
- 第二层控制由DBMS的关系查询处理层来负责
- 在查询解析和优化之后,会决定是否需要延迟执行,只分配部分资源,以及不做任何额外的限制
- 入场控制通过半自动的信息来做决策,这些是基于请求查询的优化资源评估、以及当前可用的系统资源
- 查询优化可以指定:查询将要访问的磁盘设备、随机和顺序I/O的评估数量
- 基于查询计划算子 评估请求的CPU负载,需要处理的tuple数量
- 评估请求查收数据结构的内存占用,如排序的空间,大数据量集的hash join,以及其他查询任务
- 上面的评估往往是关键,因为很多资源抖动都是上述问题导致的
- 因此大多数DBMS,使用内存占用、活跃的工作线程作为入场控制指标
Discussion and Additional Material
处理器模型选择,在DBMS扩展、移植方面有重大影响,三个主要的商业数据库都支持多种处理模式
从工程角度看,单处理器模型的移植性、扩展性都很好也很简单
但是,由于使用模式的巨大差距,以及目标OS的不统一,商业数据库都支持多种模式
近些年,人们对新处理模型有了很大兴趣
这主要是源于硬件的瓶颈、以及互联网场景的规模和可变性引起的
这种设计将一个服务系统拆分为独立的多个调度 引擎,每个引擎之间都异步的传递批量消息
这有点像之前提到的处理器池,工作者可以跨请求重用
这种方式的创新是worker采用了一个更细粒度的任务指定风格
这种调度关系是 多对多的,多个worker对应多个SQL请求,每个worker都有特定的task对于多个SQL请求
这种架构有了更灵活的选择
- 可以让单个worker有完全的task对于多个请求,可能改进整个系统的吞吐量
- 让一个请求由多个worker完成,改进了请求的延迟
在一些列子中,显示了这种架构的优势,可以利用处理器的cache本地性
也可以让CPU从缓存miss导致的空闲变成繁忙
最近的研究项目是: StagedDB
Parallel Architecture: Processes and Memory Coordination
现代服务都是基于并行化硬件的,这章总结了各种DBMS术语,并讨论了处理器模型,每种的内存协调
Shared Memory
所有的处理器都访问相同的内存和磁盘,获得大致相同的性能
这种架构在今天已经很标准了,大部分服务器硬件都有 2-8个处理器
高端机器有十多个处理器,但性价比不高
高端的并行化共享内存的机器,是硬件厂商最后的摇钱树
这种一般用于大并发的在线事务处理应用,硬件花费比维护成本还低,所以购买一些小数量的、价格昂贵的系统,有时时一种权衡
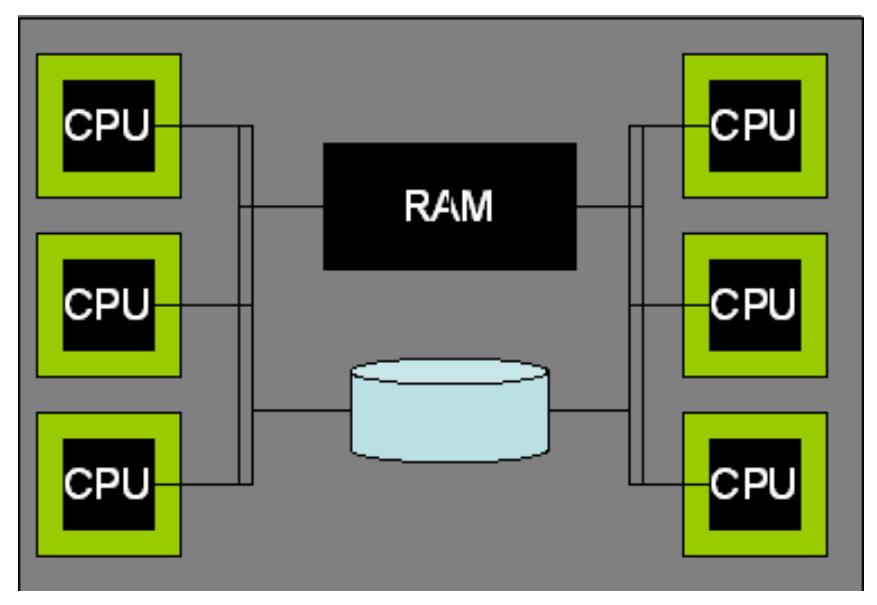
多核处理器支持多个进程在单个芯片上,同时也共享相同的基础设施,如共享内存架构
今天所有重要的数据库都部署了多核,每个处理器都有超过一个CPU,DBMS需要完全利用这种潜能
之前介绍的三种价格模式,在现代硬件上也能很好的支持
对于共享内存机器的处理器模型,也是十分自然的跟随了单处理器的方式
大多数数据库的演进方式,都是从单处理器架构,到共享内存架构的
在共享内存架构中,OS支持透明的跨进程分配worker,所有人都可以持续的访问共享数据结构
所有这三种模式在这种系统上都运行很好,支持多个、独立的SQL请求并行执行
最大的挑战是修改查询执行层,使的利用并行化的能力,让单个查询跨多个CPU执行
Shared-Nothing
这种架构由一组独立的机器组成,他们之前的通讯由高性能网络连接,现在也使用商业网络
除了网络,一个系统没法直接访问另一个系统的内存和磁盘
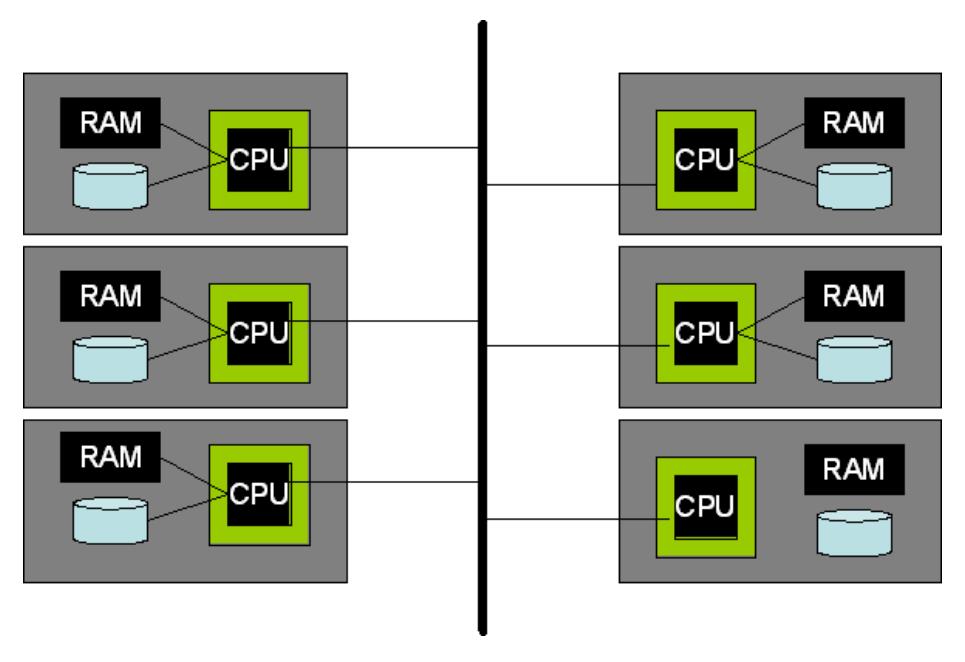
这种架构提供了一种非硬件的共享抽象,把各种机器的协调全部交给DBMS来处理
最通用的方式,DBMS在每个机器/节点上,运行他们的标准处理模型,每个节点都能接受请求SQL,访问需要的元数据,编译SQL请求,执行数据访问,这些跟共享内存系统类似
最主要的不同是,集群中的每个节点都存储部分数据
请求会发到多个节点上,所有参与的节点都会在他们存储的数据上做查询
表被分布到集群中的多个节点上,使用了水平分区的方式,这样每个节点都彼此独立的执行
数据库中的每个tuple被分配到独立的机器上,每个表都被水平分区到多个节点
典型的数据分区为:
- 基于tuple属性的hash的分区
- 基于tuple属性的range分区
- round-robin
- 混合hash和range的分区
每个机器负责管理本地磁盘的访问、锁、日志等
查询优化器需要选择如何水平重分区这些表,跨节点的中间结果如何满足请求
也分配给每个worker一个逻辑分区
各个机器上的执行器,彼此发送数据请求和tuple,但是不需要传输任何线程状态和其他低级别信息
这种基于数据库tuple值的分区,可以最小化协调者的需求,想要好的性能,就需要好的数据分区
这给DBA带来了很大负担,来重新智能布局表分布,查询优化器也需要做好工作负载的分区
这种简单的分区方式不能处理所有问题
- 为了完成事务处理,必须显示的处理跨节点协调、提供负载均衡、支持确定的维护任务
- 处理器必须显示的交换控制信息,用来检查像分布式死锁检查、两阶段提交等问题
- 这需要额外的处理逻辑,如果处理不好会带来性能瓶颈
失败的情况
- 部分失败需要考虑的,对于内存共享系统来说,失败的处理器会导致整个机器关闭,影响整个DBMS
- shard-nothing架构,失败的节点不会影响其他节点,但是部分数据失败还是会影响整个DBMS的行为
- 第一种,类似shard-memory架构,失败了就将所有节点关闭
- 第二种,Infomix方式,对于失败的节点,跳过这些数据,这对数据完整性要求不高,对可用性要求更高的场景
- 第二种设计并不是最好的方式,因为工作负载场景往往有多层,数据库被当做存储仓库,决定可用性vs一致性的决策往往是在高层级-应用服务器这里
- 第三种方式采用冗余机器来实现容错,细粒度的冗余如 链式分解
- tuple的拷贝会跨节点复制,相比于简单的schema,优势为
- 需要更少的机器部署,来保证可用性
- 当一个节点挂了,剩余 n-1个节点会做原来worker的 n/(n-1) 份工作
- 当前的数据库系统采用了粗粒度和细粒度之间的冗余方式
shared-nothing架构在如今非常普遍,有着非常好的伸缩性和性能成本,用于非常高端的机器,比如决策系统,数据仓库等等
一般是硬件和架构的结合,这种架构通过由多个节点组成,每个节点由是shared-memory的多处理器结构
Shared-Disk
这种架构允许所有的处理器访问磁盘,获得大致相同的性能,但是不能访问其他节点的内存
这种架构中有两个非常重要的例子
- Oralce RAC
- IBM DB2 for zSeries SYSPLEX
因为存储区域网络的流行,这种架构也变得流行起来
SAN允许一个或多个主机挂载一个或多个逻辑磁盘,使的创建共享磁盘配置很容易
这种架构的优势
- DBA不需要数据表分区实现并行化这种情况了,管理成本降低了
- 单个节点的失败不会影响其他节点,对于shared-memory会导致全部失败,shared-noting会丢失一些数据(除非有冗余部分)
缺点
- 如果数据在达到存储系统之前,因为硬件、软件的问题导致数据损坏,那么所有的节点都会访问这些损坏数据
- 如果配置了RAID,或其他数据复制技术,则损坏的page会被冗余的复制到其他节点
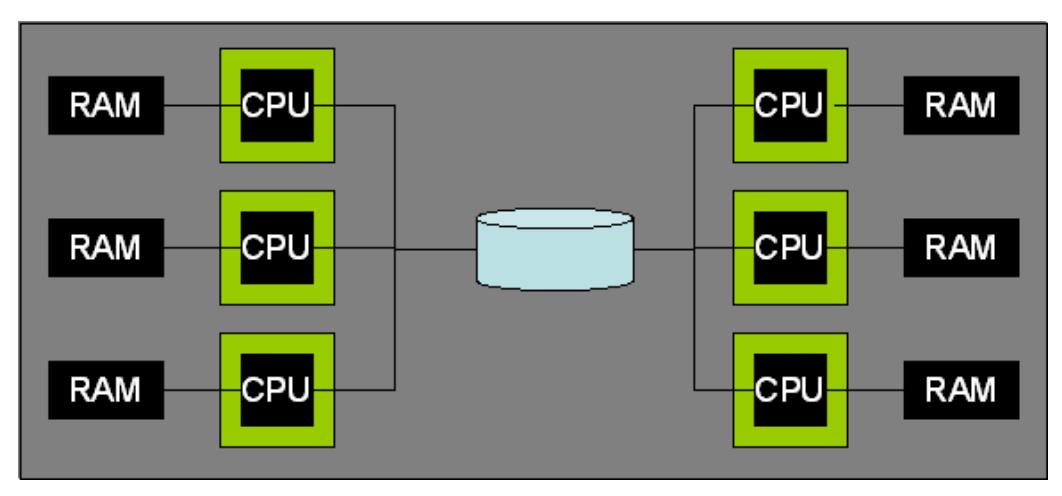
因为这种架构不需要关心分区问题,数据可以拷贝到RAM,并在多个分机器上修改
跟共享内存架构不同,这种架构没有可以协调的共享数据位置,需要每个机器有它自己用于锁和buffer pool页的内存
因此需要显示的跨多个机器的数据共享,这种架构依赖一个分布式锁管理设施,以及 用于管理分布式buffer pool缓存一致性协议
这些组件很复杂,在大量竞争情况下容易出现瓶颈
IBM zSeries SYSPLEX 在硬件上实现了锁管理
NUMA
Non-Uniform Memory Access (NUMA) 非一致性内存访问 在独立的内存集群系统之上,提供了共享内存的程序模型
每个系统都可以快速访问本地内存,也可以通过集群的高速内部连接,访问外部内部(会有些延迟)
这个架构的名称来自于,内存访问时间的不一致性
NUMA的硬件架构是 shared-nothing 和 shared-memory 的中间地带
- 他比shared-nothing更容易编程
- 可以比shared-memory扩展更多的处理器,它避免了共享内存总线的竞争
NUMA集群被成功的应用到很多商用场景,但是NUMA没有被shared memory 多处理器采纳
共享内存多处理器可以扩展到很多处理器,这种架构显示了增长的不一致性
large shared memory multi-processors将其内存拆分为多份,每份都关联到一批处理器子集
每份内存子集和CPU相当于一个pod,访问本地内存比远程pod内存要快
NUMA的这种设计架构模式可以将共享内存系统扩展到非常多的处理器
- NUMA的共享内存多处理器非常通用
- 但NUMA的集群从来没有获得过什么大的市场份额
DBMS访问UNMA共享内存系统的方式是,忽略非一致性内存的访问,只要非一致性较小,就可以接受
当近内存:远内存的访问比例从 1.5:1 上升到 2:1 时DBMS就要考虑优化,避免内存瓶颈,优化主要是两方面
- 当给处理器分配内存时,优先使用本地内存
- 确保worker总是跟之前的worker调度到相同的硬件处理器上
使用这种方式,就可以确保DBMS在非一致性内存访问的共享内存系统上,运行良好
尽管NUMA集群几乎消失了,但是程序模型、优化技术仍然被保留到当前的DBMS系统中了
因为很多高可扩展共享内存系统,他们的内存访问性能都非常不一致
DBMS Threads and Multi-processors
之前假设的那些问题都是单处理器的,现在这种场景下就会出现问题了
之前讨论了,轻量级DBMS线程,所有的线程都运行在单个OS进程中,但是一个进程在一次只能在单个处理器上执行
所以,在多处理器系统上,DBMS一次只会使用一个处理器,剩下的处理器都是空闲的,早期的Sybase SQL Server就受到这种限制
随着90年代,共享内存多处理器流行,Sybase也很快修复了这个问题,使得可以利用多OS进程了
当DMBS线程运行在多进程中,可能会出现:某个进程要执行大量的任务,而某个进程确实空闲的
为了处理这种场景,DBMS必须要实现线程在不同处理器之间迁移
Informix在 6.0版本实现了这个功能
将DMBS的线程映射到多个OS进程中,需要决定:
- 如何使用多个OS进程
- 如何分配DBMS线程到OS线程
- 如何跨多个OS进程分布
一个最好的做法是,一个进程运行在一个物理处理器上,这样可以在硬件上最大化物理并行度,也能最小化每个进程的内存开销
Standard Practice
为了支持并行性,跟上一节的趋势类似,主要的DBMS都支持多并行模块
由于共享内存系统SMP,多核系统,以及他们两者的结合体,在商业上都比较流行,主要的DBMS商场对于共享内存并行化支持的都很好了
我们看到了多借点集群并行性中的区别,其中广泛的使用了shared-disk 和sharednothing架构
- Shared-Memory,支持的商场有IBM DB2、Oracle、SQLServer
- Shared-Nothing,DB2、Informix、Tandem、Teradata、Greenplum提供了PG的定制版,支持Shared-Nothing
- Shared-Disk,Oracle RAC、RDB(Oracle从DE公司收购的)、IBM DB2 for zSeries
IBM 售卖多个不同的DBMS产品,并选择实现了shared disk和shared nothing支持某些场景
目前位置,没有哪个厂商在同一个代码库中,同时支持shared-disk和shared-nothing
微软的SQL Server这两者都不支持
Discussion and Additional Material
上面讨论的表示,各种系统中软硬件架构模块的选择
他们在DBMS领域率先使用,这些想法现在也出现在其他数据密集型领域:
- 后端的低级别程序数据处理,map-reduce,越来越多的用户使用他们做定制化的数据分析任务
即使这些新想法影响了广泛的计算领域,但 数据库系统并行设计中出现了新问题
未来10年并行软件架构的关键挑战是,利用处理器厂商的新一代多核架构愿望
这种设备引入了新的硬件设计点,可以在单个芯片上包含一沓子、一百,甚至上千个处理单元,处理单元之间的通讯由处理器之上的高速网络连接
但是访问处理器之外的内存、磁盘仍然存在很多瓶颈
结果就是,在磁盘和处理器之间的内存路径,出现了新的补平衡和瓶颈
这肯定需要重新检查DBMS架构,以满足硬件的性能潜力
某些相关架构正转移到可以预见的,更宏观的尺度 在面向服务计算领域
这里,这个想法在有一万个计算机的大型数据中心,为用户提供处理(包含软件和硬件)
如果是高度自动化的,那么这种规模下的应用和服务的管理就是可以接受的
非管理任务不能随着服务数量的增加而扩展,因为通常使用的是小于可靠性的商用服务器,失败会更常见
所以从失败中恢复需要完全自动化
在每天都有磁盘损坏,每周都有几个服务器故障的这种规模场景下,管理数据库备份通常被整个数据的在线拷贝替换,它由不同服务存储在不同磁盘上
依靠数据的值,冗余的拷贝、副本甚至存储在不同的数据中心,自动的下线备份仍然被用于从应用、管理、用户错误中恢复
然而,从更通用的错误和失败中恢复,快速的故障转移到冗余的在线副本,可以由多种方式实现
- 复制在数据存储级别,SAN
- 数据复制在数据存储引擎级别
- 查询处理器 通过 冗余的查询执行
- 冗余的数据库请求自动生成在客户端软件级别,如被web服务器和应用服务器
在更解耦的层次上,实践中十分通用的做法是,多个具有DBMS功能的服务被部署到不同层次中,努力最小化DBMS记录的I/O请求比列
这种方案包括 用于SQL查询的各种形式的中间层数据库缓存
- 专用的主内存数据库,如Oracle TimesTen
- 更传统的配置服务用于此目的
在部署堆栈,很多面向对象的应用服务架构,支持EJB这样的编程模型,可以配置 与DBMS一致的应用对象的事务缓存
然而,选择,设置,管理这些各种方案仍然是非标准的而且是复制的,这种优雅统一、一致性的模型,仍然难以捉摸
Relational Query Processor
前面的章节关注于DBMS的宏观设计,现在开始要调整方向了,关注于一系列的细粒度部分,处理每个DBMS的主要组件
现在开始讨论查询处理部分,然后是存储管理,事务,通用工具
一个关系查询处理器 接受一个申明式SQL语句,校验它、优化它,变为一个程序数据流执行计划(子主题为准入控制),之后代表客户端执行数据流程序
客户端之后获取tuples结果,通过一次一个或小批次
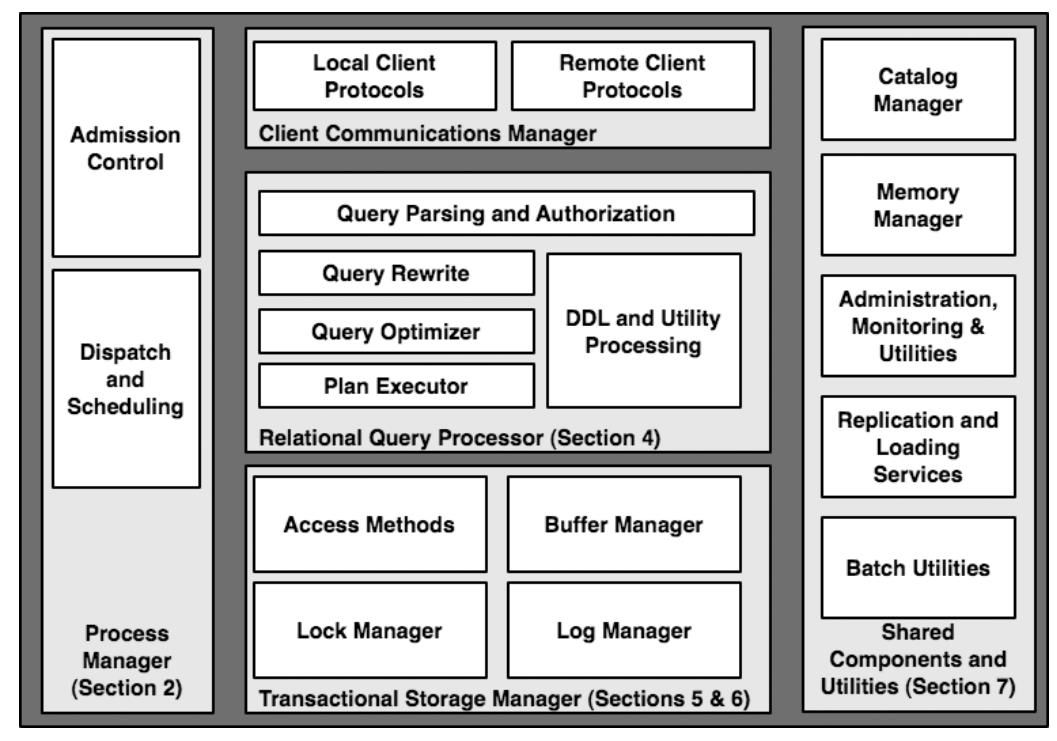
关系查询处理器的主要组件展示在 图1.1中,本章节中主要关系查询处理器、存储访问模式的非事务部分
关系查询处理可以当做一个单用户、单线程的任务,并发控制透明的由底层系统支持
这个规则的例外是,DBMS必须显示的pin和unpin buffer pool的page,同时对他们操作,以便他们简短的、关键的操作时驻留在内存中
本节中,我们主要焦点在通用的SQL命令
- 数据管理语言DML声明,SELECT、INSERT、UPDATE、DELETE
- 数据定义语言DDL声明,CREATE TABLE、CREATA INDEX,没有被查询优化处理
这些声明通常在静态DBMS逻辑中通过显示调用 存储引擎、目录管理器 程序化实现的
一些产品开始在小范围的DDL申明上做优化,我们预计这种趋势会继续下去
Query Parsing and Authorization
对于给定的SQL申明,SQL解析的主要任务
- 检查这个查询是正确的指定
- 解释名字和引用
- 通过优化器,将查询转换到内部格式
- 校验用户是否有查询权限
有些DBMS会推迟一些、或所有的安全检查到执行时再执行
解析器仍然有责任,收集执行时安全检查所需的数据
对于给定的SQL,解析器首先考虑每个表在FROM句子中的引用
- 对表名做规范化处理
- 变成 四部分
- server.database.schema.table
- 对于查询不支持跨多个系统的,规范化的名字可以限定为:database.schema.table
- 对于每个DBMS只支持一个数据库的,规范化名字可以限定为: schema.table
- 这个限定是必须的,用户可以使用上下文环境的默认值,这样后面只需要填写 table名字就可以了
- 有些系统对于一个表有多个名字,如别名,这种的也需要做 全限定表名
在规范化表名之后,查询处理器会调用 catalog-manager,在这个阶段中,系统会在内部查询数据结构中,缓存表的元数据
基于表的信息,使用catalog来确保属性引用的正确性,属性的数据类型被使用来消除重载表达式的不确定性的逻辑,比较算子,常量表达式
比如:
- (EMP.salary * 1.15) < 75000
这里有乘法函数和比较算子,假设数据类型和string的内部格式 1.15,75000,这需要依赖EMP.salary的数据类型
这个类型可能是 integer、float、money
额外的标准SQL语法检查也被应用
- 包括tuple变量的一致性使用
- 通过集合算子 UNION/INTERSECT/EXCEPT 组合的表的兼容性
- 在聚合查询SELECT 列表中使用属性
- 内嵌的子查询等等
如果查询解析成功,下一个阶段就是认证,确保用户有合适的权限 SELECT/DELETE/INSERT/UPDATE 在这个表上,用户定义函数、或者其他在查询中的对象引用等
一些系统在申明解析阶段执行完全的认证检查,并不总是这样
系统支持行级别的安全,比如 直到执行期间才能做完全的安全检查,因为安全检查依赖数据类型
即使理论上可以在编译期间做静态校验,但推迟这个执行到查询执行期间会更有优势
推迟安全检查到执行期间的查询计划,可以在用户之间共享,并且当安全改变时不需要重新编译
基于这个结论,部分安全校验通常推迟到查询计划执行时
同样在编译期间,也可能约束检查常量表达式,比如一个UPDATE有一个子句
- SET EMP.salary = -1
如果对salary做了整型约束指定正数值的限定,那么查询甚至不需要被执行
将这个工作推迟到执行期间是非常常见的
如果查询解析并传递校验,之后查询的内部格式 传递给查询重写模块做进一步处理
Query Rewrite
这个模块有责任简化、规范化查询而不需要改变其语义,它依赖查询和catalog的元数据,不需要访问表中的数据
尽管叫重写查询,但实际上是操作查询的内部表示,而不是操作原始的SQL声明文本
查询重写模块各通常产生一个 相同内部格式(来自输入数据)的查询内部表示
重写在很多商业系统中是一个逻辑组件,真实的实现
- 查询解析的后期阶段
- 查询优化的早起阶段
比如DB2,查询重写是一个方独立的组件,而SQLSserver中查询重写是 查询优化的早起阶段
尽管如此,单独考虑查询重写仍然是有用的,即使显示的架构边界不存在任何系统中
查询重写的主要责任
- view expansion
- 视图重写是主要的传统角色,对于每个出现在FROM中的视图引用,重写器从catalog中找出视图的定义
- 重写视图,用表和谓词引用替换视图
- 替换任何对视图列的引用,到表的引用
- 处理使用递归的方式执行,直到表达式中仅包含表或者没有视图
- 视图展开技术,在基于QUEL语言的INGRES中被提出,需要在SQL中处理去重,内嵌查询,NULL和其他麻烦细节
- constant arithmetic evaluation
- 查询重写可以简化常量算数表达式
- R。x < 10 + 2 +R.y 被重写为 R.X < 12 + R.y
- logical rewriting of predicates
- 应用基于WHERE子句中的谓词和常量
- 简单的bool逻辑通常应用在 表达式 和 基于索引访问模式之间的匹配
- 一个谓词如 NOT EMP.salary > 1000 可以重写为 EMP.salary <= 1000
- 逻辑重写甚至可以短路查询执行,如: EMP.salary < 7500 AND EMP.salary > 10000
- 这种的就直接返回FLASE,系统会返回空的查询结果而不需要访问数据库
- 谓词可能会隐藏在视图定义中,而外部使用的人并不知道
- 对于上述例子,结果可能来自叫:Executives视图的低薪水员工
- SQLServer在并行化查询中,如果某些谓词不满足,则可以过滤掉一些分区
- 当一个关系是通过range谓词,水平分区跨多个磁盘的,如果range分区谓词不满足查询谓词连接,则无需此磁盘上运行
- 重写谓词传递性,来引导另一个谓词, R.x < 10 AND R.x = S.y,建议添加额外的谓词 AND S.y < 10
- 添加传递性谓词,可以增加优化器在选择早期 过滤数据的计划能力。特别是基于索引的访问模式
- semantic optimization
- schema的完整性约束一般是存储在catalog中,可以用来帮助重写一些查询,比如 消除冗余的join
- 比如一个外检约束绑定到 EMP.deptno 表的一个列上
- 通过这个外键约束,可以确切的知道,一个Dept对应每个EMP,并且在没有对应的Dept tuple情况下,不存在EMP的tuple
- 有这样的SQL: SELECT emp.name, emp.salary FROM emp, dept WHERE emp.deptno = dept.dno
- 如果emp.deptno 被约束为非null,则可以移除掉 dept这个表
- 这种场景一般在视图中出现,可以提交一个员工查询的请求,它是基于empdept这个视图的,底层join了这两个表
- Siebel使用非常宽的表,如果底层数据库不支持足够宽的表,那么使用带有视图的多个表
- 在没有冗余join消除时,这种基于视图的宽表实现,性能会很差
- 当表上的约束和查询谓词不兼容时,语义优化可以 回避整个查询执行
- subquery flattening and other heuristic rewrites
- 查询优化是当代商业数据库最复杂的组件之一
- 为维持这种复杂性,优化器通用操作独立的 SELECT-FROM-WHERE查询块,而不会跨块操作
- 很多系统重写查询到一个更合适优化的形态,而不是继续复制的查询优化
- 这类转换通常是规范化,通常是重写语义等价的查询到一个规范化形态,语义等价查询会被优化到相同的查询计划
- 另一个重要的启发式扁平化内嵌查询,以最大化为查询优化器的单快优化提供机会
- 这种类型的SQL很棘手,比如重复的语义,子查询,NULL
- 早期子查询展开是纯粹的启发式重写,不过现在的产品用基于代价分析的方式决定重写
- 其他的重写可能会跨查询块,如谓词传递,允许谓词被跨子查询拷贝
- 展开关联子查询是非常重要,在并行架构中可以实现很好的性能
- 关联子查询结果在 跨查询块的 nested-loop比较风格中,它序列化子查询执行,尽管有并行资源可以
Query Optimizer
查询优化器的任务是转换一个内部的查询表示,到一个高效的查询计划,提供给查询执行
一个查询计划可以认为是一个数据流图,通过查询算子的图来传递表数据
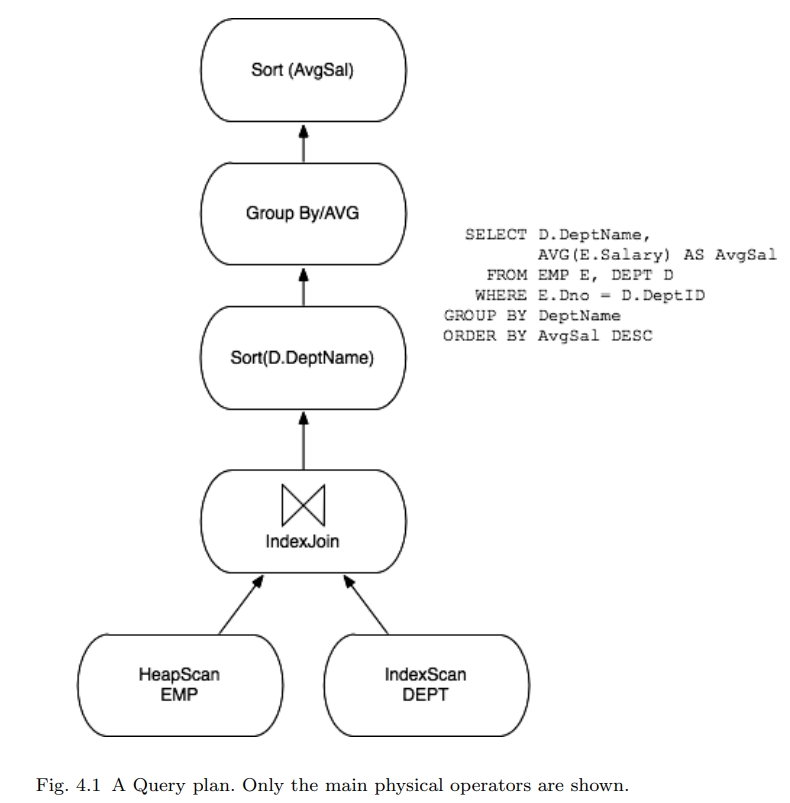
大多数系统首先将查询分解为:SELECT-FROM-WHERE 查询快
每个独立的查询快优化 使用已有的技术做优化,这个技术来自于System R优化器,这是1979年的一篇著名论文:《Access
path selection in a relational database management system》
在完成时,一些算子通常被增加到每个查询块的顶部,以为后续的计算GROUP BY、ORDER BY、HAVING、DISTINCT子句(如果他们存在的话),各种块用简单的方式缝合在一起
可以有多种方式表示查询计划
- 原始的System R编译查询计划到机器代码
- 早期的INGRES生成一个可解释的查询计划
查询解释被当做一个错误,1980年早期的INGRES作者在他们的论文中报告
摩尔定律和软件工程证明了INGRES的正确性
讽刺的是,编译成机器代码被System R的一些研究人员认为是错误的;当System R的代码变成商业化DBMS后,开发团建首先用解释器替换了 机器代码执行
为了支持跨平台迁移能力,每个主要的DBMS现在编译他们的查询到各种可翻译类型的数据结构,他们之间唯一的却别是中间形式的抽象级别
查询计划在一些系统总非常轻量,不像关系代数表达式那样,它用访问方式的名称、join算法等对名称做了注释
其他一些系统使用了低级别语言 op-code,有点类似于 Java的字节码,而不是关系代码表达式
为了简化我们的讨论,在后续论文的后续部分,将重点讨论类似代数查询的表示
《Access path selection in a relational database management system》这篇论文被认为是查询优化领域的圣经,不过这篇论文只是初步研究
所有的系统都显著扩展了这项工作,主要包括这几个扩展:
- Plan space
- 早期的System R限制了查询空间,强制使用了 left-deep查询计划
- join中输入的右边必须当做基表
- 笛卡尔积会被推迟,直到所有的数据流join之后才会出现
- 现代的系统,使用茂密树bushy trees,内嵌的右输入
- 早期的笛卡尔积在某些情况下是有用的
- 因此大多数系统,只是某些情况下才会考虑这两种选择
- Selectivity estimation
- 在论文中,选择性评估计算,只基于简单表和索引基础,符合当前生成的标准
- 现代系统分析、总结属性中的值分布,通过直方图和其他汇总信息
- 因为牵涉到访问每个列中的每个值,代价可能很高
- 所以现代的系统很多实用了采用技术,获取分布的评估,而不需要代价啊很高的详细扫描
- 通过选择join列上的柱状图,来选择性的评估基于表的join
- 为了支持超过一个列,最近有学者提出了更复杂的方案,类似列之间的依赖性等问题
- 这些方案被缓慢采用的原因是,很多工业界的基准测试中都存在长期的缺陷
- 基准测试(TPC-D、TPC-H)的数据生成器,在列上生成了独立的统计值,因为不鼓励采用新技术处理真实数据分布
- 基准测试中的这些问题在TPC-DS中已经处理了
- 尽管采用率较低,但改进的选择性评估的好处被广泛认可
- 有学者注意到,在优化早期,选择性的错误沿着计划树的乘法式传播,导致可怕的后续评估
- Search Algorithms
- 一些商用系统如微软、Tandem,放弃了动态规划方式,采用了目标导向,使用级联中基于 自顶向下的查找模式
- top-down的优化方式可以减少查询计划的数量,但是这种方式会增加内存开销
- 如果实际的成功是质量指标,那么选择top-down或者DP都是无关紧要的
- 他们两在最近的优化器中都能很好工作,但是表数量一旦增加,运行时间和内存需求都呈指数增加
- 当有太多表时,退化到启发式搜索,商用的的启发式搜索都是专有的,跟随机化查询优化文献中并不相同
- 一个有意义的试验是检查开源的MySQL,它的最后检查完全是启发式的,主要利用索引和外键约束(早期的Oracle也是这样)
- 在某些系统中,如果FROM子句中有太多的表,只有用户显示指定优化器如何选择一个计划(hints提示),这个语句才能执行
- Parallelism
- intra query,将单个查询在多个处理器上执行
- 这种方式就需要考虑如何调度算子,如果将某些算子并行化,并利用多核的能力
- 为了避免调度的复杂性,Stonebraker等人将其分为两个阶段调度
- 首先用传统的单系统优化器,找到最佳的单系统执行计划;然后跨多个系统调度该执行计划
- 有些系统尝试对集群的网络拓扑、数据分布建模,然后产生一个但阶段的执行计划
- 使用单个查询优化带来的复杂性,是否跟优化后的能力相匹配不得而知
- Oracle的RAC使用两阶段,DB2是最早使用两阶段的,后来目标是一阶段
- 论文:《Optimization of parallel query execution plansin xprs》
- Auto-Tuning
- 这是工业界的努力方向,通过收集数据来让DBMS实现自动调优
- 优化器会做各种假设分析,比如使用其他索引会怎样,改变数据布局会怎样?
- 需要对优化器做一些调整,才能支持此活动
A Note on Query Compilation and Recompilation
SQL支持查询准备,将其传递给解析器、重写器、优化器,并存储查询执行计划,用于后续的执行声明
可以支持动态查询,如web表单传递过来的,只是对于选择性评估有点弱
提供的表单由优化器假定可以接受典型的值
当非表示的典型值被选择后,会出现非常糟糕的查询执行计划
查询准备对于表格驱动的数据非常有用,可以公平的预测数据:当应用编写的时候,查询就开始准备了
当应用开启时,就不需要体验额外的解析、重写、优化开销
查询准备可以提升性能,但是受应用程序模型限制,很多应用程序使用类似Ruby on Rails这样的工具
在程序执行期间,动态的建立SQL,所以预编译不是可选项,因为太常见了
DBMS将查询计划缓存,后续如果发现有相同、或者非常类似的提交,就使用缓存中的查询计划
这个技术类似于执行一个静态SQL预编译,但是没有应用模型限制,可以被大量使用
随着时间推移,数据库可能发生改变,比如索引被删除了,那么对应的查询计划就需要改变
新的查询计划需要更新到缓存中以便下一次可以使用
这里出现了两种不同的设计方式
- IBM非常努力的在多个调用之间预测执行能力,以牺牲每次调用执行时间为代价,所以不需要再优化
- SQLServer则是努力让他们的系统能自动调优,以便能更新优化器,比如表的基数变了,就会触发重编译,因为这会影响索引的选择、join的顺序
这种设计上的差异是市场策略导致的
- IBM的客户当时都是高端的,有高端DBA和编码能力,一般会自己调优很长时间,所以不需要DBMS再改变优化器
- SqlServer则是低端客户,希望DBMS能自动调优
但随时间推移,双方的市场策略都会有重合,IBM也出现自动化调优
SQLServer也有高端用户了
Query Executor
查询执行是操作一个已经完全定义好的查询计划
查询计划一般是一个链接了各种算子的数据流图,而算子是对表访问、查询执行算法的封装
某些系统中数据流图是直接编译到低级别的op-code中了(优化器编译的)
在本例中,查询执行是基于一个运行时的解释器
在有些系统中,查询执行器接受一个数据流图的表示,然后产生基于图布局的算子
我们主要讨论后者,op-code的方式本质上市将我们讨论的逻辑编译到一个程序中
大部分现代查询执行器使用 迭代模型,这也是最早的关系型数据库中使用
迭代模型在面向对象风格中可以简单表示 ,下面就是一个迭代模型的伪代码
|
|
Iterator superclass pseudocode.
每个算子都定义了一个输入,也就是数据流图中的边的定义
一个查询计划中的所有算子,数据流图中的节点,可以作为迭代器类的自类来实现
这一系列的子类,一般包括:
- filescan
- indexscan
- sort
- nested-loops join
- merge-join
- hashjoin
- duplicate-elimination
- grouped-aggregation
迭代器模式有一个重要的特点:任何一个迭代器的子类可以当做另一个的输入
因此迭代器的逻辑跟其父节点、子节点都是独立的,也不需要为特殊的case做适配
PostgreSQL为大多数标准查询执行算法,使用了适当复杂度的迭代器实现
相关论文:《Query evaluation techniques for large databases》
Iterator Discussion
迭代模型有一个重要的特点,数据流、控制流是耦合的
get_next()是一个标准的程序调用,通过调用栈,将返回的tuple引用给调用者
所以,当控制返回时,一个tuple会确切的返回给它的父节点,这也暗示了DBMS中只有单个线程来执行整个查询,多个查询、或者迭代器之间的速率匹配则不需要
这个好处是关系查询的实现逻辑很清晰,也很容易debug
相比其他的数据流架构,比如网络中,依赖各种协议在并发的生产者和消费者之间排队和反馈
迭代模型在单系统,也就是非集群模式下是很有效的,对于大多数应用来说,优秀的指标包括
- 查询完成的时间
- 其他也包括:DBMS的最大吞吐量
- 交互式应用中:第一行的返回时间
对于单个处理器环境中,给定的查询完成时间,是在资源得到完全利用时实现的
在迭代模式中,迭代器总是活跃的,所以资源利用率是最大化的
现代DBMS支持并行化,在迭代模型、查询架构不需要太大改动的情况下,是可以执行并行化的
并行化、网络通讯可以被封装到一个特殊的 exchange 迭代器中,相关论文:
《Encapsulation of parallelism in the volcano query processing system》
这篇论文中,实现了网络风格的 push 迭代器,它对于DBMS迭代器是不可见的,当然也保留了 pull 风格的 get_next()
有些系统也可以显示的在他们的系统中实现 push 逻辑
Where’s the Data?
迭代模式可以规避动态内存分配问题,不需要指定内存中有多少tuple,也不需要迭代器之间传递多少tuple
实际上,每个迭代器都预先分配了一个固定大小的 tuple 描述符,一个用于输入,一个用于输出
tuple 描述符通常是一个 列引用数组,每个列引用下面组成:
- 引用到内存中其他地方的tuple
- 引用的那个tuple的偏移量
迭代器模式的超类也不会动态分配内存,那么问题是,实际被引用的 tuple 是存储在哪里的?
有两种可能
1、tuple是驻留在buffer pool的 pages中的,也叫做 BP tuple
一个迭代器构建了tuple描述符,那么就会引用到BP tuple
在引用期间,必须要增加 pin 的数量,它 钉住的是 page上正在被引用的tuple,当tuple 描述符清空时,pin 数量也就减少
2、迭代器实现可能在 内存堆上为tuple 分配空间,这叫:M-tuple
- 迭代器可以通过从buffer pool拷贝列,来创建M-tuple,通过引脚递增/递减 来拷贝副本
- 通过查询规范中的评估表达式,如EMP.sal * 0.1
- 一个通用的方式是,立即从buffer pool中拷贝出数据,到M-tuple中
- 这种设计将M-tuple当做动态tuple结构,并可以简化执行器的代码
- 可以规避掉bug,这些bug是从隔离的buffer pool pin和unpin中返回的,他们是被程序长期周期执行的
- 一个通用的bug可能就是忘记unpin了,内存泄露
- 独占的M-tuple是一个主要的性能问题,因为频繁的拷贝,对于高性能系统是一个严重瓶颈
另一方面,构造一个 M-tuple在某些场景下会有用
只要BP-tuple直接被迭代器引用,那么BP-tuple上的page必须保留pin,这会消耗掉bufer pool内存的一个page,也限制了buffer的替换策略
如果tuple在很长一段周期内被持续引用,那么从buffer pool中拷贝tuple也是有益的
讨论的结果是,最有效的方式支持 tuple描述符,是可以引用
- BP-tuples
- M-tuples
Data Modification Statements
目前为止,只讨论了查询,这些都是只读的,对于 DML 来说,还有 insert、update、delete
这些语句的执行计划看起来都比较简单,类似一条直线
使用单一访问方法作为源,修改申明一般在pipeline都末尾
对于包含了读和更改的查询,他们公用一份数据需要特别小心,比如 IBM System R 发现的万圣节问题
给每个低于 2W美元的人加10%薪水
如下,索引的scan迭代器扫描 Emp.salary 后交给更新的迭代器,由于tuple是从B树中获得的,因此性能很不错
这里会出现一些问题
- 这种pipeline的方式,可能会导致 索引扫描 重新发现之前被修改过的tuple,这些之前被修改过的tuple是往右移动的
- 这样会导致每个员工都被多次加薪
- 在这个例子中,这些员工会一直加薪直到他们的薪水超过了 2W
查询的SQL:
|
|
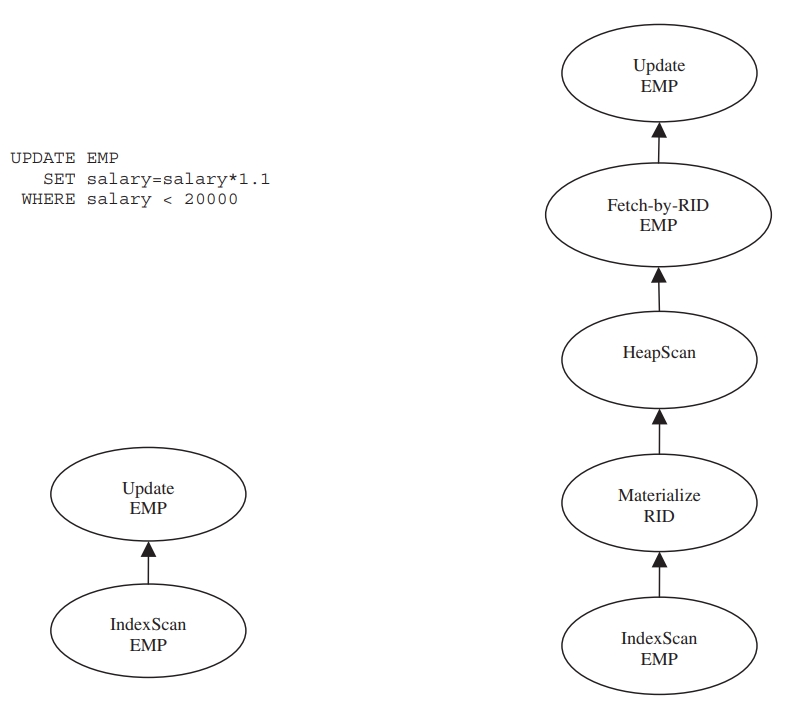
Fig. 4.3 Two query plans for updating a table via an IndexScan. The plan on the left is susceptible to the Halloween problem. The plan on the right is safe, since it identifies all tuples to be updated before actually performing any updates.
SQL语义禁止的行为:单个SQL不允许 看到 他自己的更新,需要确保这个可见性的规则
一个简单安全的实现是,查询优化器避免在更新列上建立 查询计划,但这回导致非常低效的查询
另一种实现方式是:批量的读和写
- 他是在数据流中的 索引扫描 和 数据修改操作之间,插入Record-ID物化和抓取这样的动作
- 物化操作是将所有被修改的tuple ID存储到临时文件中
- 之后扫描临时文件,通过RID获取每个物理tuple ID,再将结果交给修改算子
- 如果优化器选择索引,那么大多数情况下智慧更新少数一些tuple
- 这种实现看起来会很低效,因为要写到临时文件中,但可以将所有待修改的tuple全部放到buffer pool中
pipeline更新的方式也是可能的,但需要存储引擎的多版本支持(有点奇怪)
Access Methods
访问方式:管理访问各种基于磁盘数据结构的方式,通常包括
- 未排序的文件,heap
- 各种类型的索引
所有主要的商业系统都实现了 heap 和B+树索引,Oracle和PG支持hash索引和等价的查找
有些系统开始引入还不太成熟的 多维索引,比如 R树
PG支持扩展索引:通用查找树 GiST,当前使用 R树来支持多维索引,用 RD树 支持文本数据
IBM引用多维聚集索引 MDC 来支持多维上的范围访问
以读为目标的 数据仓库,使用索引的变种 bitmap
基础API,访问方法提供基本的迭代API,init()被扩展为接受单表列算子常数的搜索参数(System R术语SAGR)
NULL SARG用来扫描所有的tuple,当没有tuple满足搜索参数时, get_next()返访问模式层返回 NULL
有两个原因需要传递 SARG 到访问方式层
- 索引方式类似B+树,可以提供有效性能
- 一个不易察觉的性能问题,它适用于 heap扫描,也适用于索引扫描
假设 SARG 由访问方法层来做检查,那么每次访问方式从 get_next()返回都需要(二选一)
- 返回一个驻留在buffer pool帧中的句柄,并且钉住这帧中的page,避免替换
- 创建tuple的拷贝
如果调用查找 SARG没有满足,那么(二选一)
- 减少page上的pin
- 删除tuple的拷贝
同时继续调用 get_next() 尝试获取下一次tuple,这种逻辑在调用/返回时,会消耗大量的CPU
- 不必要的在buffer pool中钉住page,会产生不必要的buffer 帧的竞争
- 创建不必要的tuple拷贝
在有几百万tuple传输时,会有大量的CPU负载
heap 扫描会访问给定page上的所有tuple,对于每个page会有交互式的多次迭代
如果所有的逻辑都在访问方式层中完成,那么重复的调用/返回 对和 pin/unpin或者copy/delete都可以被SARG在一次一个page中避免
对于满足SARG的tuple,都可以只从get_next()调用中返回
SARG这种架构很清晰,保持了存储引擎 和 关系引擎的边界,有着很好的性能
很多系统都对SARG有支持,这种主要是应用了CPU性能,而不是磁盘性能
所有的DBMS需要一种方式指向基表中的行,以便索引条目可以引用这些行
在很多DBMS中,这种实现是使用 rows ID做的,也就是基表中行的 物理磁盘地址
- 这种方式的好处是,查询很快
- 缺点是,基表中的行移动开销很大,因为所有的二级索引都需要更新
更新和查询的行都有代价
- 当一个更新改变了行的size,刚刚更新的page上也没有可用空间了
- 当 B+ 树分裂时,很多行需要移动
DB2使用 forwarding指针来避免第一个问题,不过这需要第二次I/O来发现需要移动的页,但是避免了二级索引的更新
对于第二个问题,DB2不支持基表tuple用 B+树作为主存储,SQLServer和Oracle支持B+树作为主存储,并且能高效处理row的移动
这种方式避免在 二级索引中使用物理行地址作为,而使用 主键key,如果没有唯一key则使用内置唯一key
当使用二级索引访问基表时,会有性能损失,但是避免了行移动的问题
Oracle通过保持一个主键的物理指针,来避免这些性能问题:如果行没有移动,则使用物理主键指针,这样可以快速找到数据;否则行移动了,使用较慢的主键技术
Oracle避免移动heap文件中的行,允许行跨page
当行更新一个很大的值,同时原page也没有足够空间时,不再强制移动行,而是:
将合适的空间存储在原始page,而剩下的数据可以跨page存储
相比于其他迭代器,访问方式跟并发控制,恢复逻辑有深度的交互
Data Warehouses
数据仓库:对于决策分析支持的 海量历史数据库,周期性的加载新的数据
现在已经发展到需要专门的查询技术来支持,这个话题之所以相关,有两个原因
- 数据仓库是DBMS中非常重要的应用技术,据说占据了DBMS活动的 1/3
- 当前的查询优化,执行引擎,都不能很好的在数据仓库中工作,所以需要一些修改来实现更好的性能
1970年第一个关系型数据库架构出现
1980年代出现了很多商业数据处理应用的需求,这在当时是主要需求
1990年代,数据仓库,商业分析出现,并且快速增长
1990年代 OLTP已经替代了批量商业数据处理,称为数据库的主要范式
但是大多数OLTP需要银行操作员提交事务
- 终端客户的电话会话
- 从打印纸上执行数据条目
于是自动执行这些任务就变成迫切的了,允许客户端支持和机器交互,而不需要操作员
响应时间变得非常重要,称为重要生产力,尤其像web也因为快速发展,终端客户更需要自动化处理
与此同时,企业像捕获销售数据,将其存储 1-2年
这是历史数据可以发现,购买者想要什么,以及不想要什么,这些信息也可以利用影响采购模式
这些数据可以促进决策提升,哪些需要打折的,哪些是需要返厂的
当时普遍的看法是,历史数据仓库可以通过改善存储管理、货架、以及存储布局,可以几个月左右回收成本
数据仓库应该被部署到跟 OLTP独立的硬件中,按照这种方法论
商业智能的查询不会干扰到 OLTP响应时间,同样他们的数据页非常不同
数据仓库处理的是历史数据,OLTP处理的是现在的数据
最终会发现,对于历史数据期望的模式,跟当前数据所需的模式不匹配,需要将数据从一处转移到另一处
处于这样的原因,需要对OLTP的数据做抓取,加载到数据仓库中,于是出现了 ETL这种系统
流行的ETL包括 data stage IBM的, PowerCenter Informatica的
ETL厂商还扩展了他们的ETL产品,比如去重工具,面向质量的交付等
数据仓库环境需要解决一些问题需要处理,我们接下来讨论
Bitmap Indexes
B+树 是被优化作为快速insert、delete、update使用的,而数据仓库做了数据初始化之后,可能很长时间都不会更新
另外,数据仓库的某些列可能只包含很小的值,比如客户的性别,这里只有两个值
这种情况可以用bitmap来表示,只需要一个bit就可以了
相反,如果用B+树, 每个记录都需要(value,记录指针),这样每个记录会消耗掉40bit
bitmap还对于联合的filter条件也有利:
|
|
这个结果由相交的 bitmap来确定
bitmap还有很多例子用来提升分析查询的性能,可以参考论文:
《Improved query performance with variant indexes》
当前Oracle使用bitmap索引来对B+ 树做补充,DB2只提供了有限的版本;Sybase广泛使用了bitmap
bitmap对于更新场景代价很大,所以只适用于数据仓库环境
Fast Load
通常数据仓库在半夜将事务数据加载进来
因为零售商一般是白天开门;另外整夜导入避免了用户的交互影响
商业分析师可能希望做某些ad-hoc查询,比如探索飓风对于用户购买行为的影响;通常这样的查询后面还会跟着后续的探索行为,比如分析大暴风对于购买行为的影响
这两类查询应该是兼容的,也就是说他们应该是基于相同的数据之上做的;如果此时数据还在不断加载,那么查询会包含当前的历史数据,就有问题了
对于数据仓库来说,必须要快速的加载数据
数据仓库可以使用传统的 insert方式来批量插入,但是实际从不会这么用
数据仓库会将大量流数据导入存储中,而不需要经过SQL层的开销,这是利用了特殊的buld-load方式,类似B+树这样的
这种方式大约比SQL插入块一个数量级,所有的驻留厂商都提供了高性能的bulk loader
随着世界向电子商务和24小时全天候销售转移,这种批量导入的策略,但是走向 实时数仓还是有一些问题
- 无论是批量导入还是insert,都需要写锁,在查询时会跟读锁冲突,导致查询卡主
- 多个查询要保持兼容性可能会有问题
这两个问题可以通过避免原地更新,提供提供历史数据来规避掉
如果保持了之前、之后的值,并加上合适的时间戳,那么就可以提供最近的查询
运行同一历史时间的查询集合,可以保持兼容的结果,相同的历史查询在执行时也不需要读锁
多版本并发控制,MVCC 隔壁级别如:SNAPSHOT ISOLATION
Oralce就提供了这种功能,实时的数仓就变的流行起来,而其他的供应商可能也会跟进
Materialized Views
数据仓库通常非常大,而且带有多个表的join查询,会执行非常长的时间,为了加速查询,很多供应商提供了物化视图
不像普通的逻辑视图,物化视图是可以被查询的实际表,但是对应于一个真实表之上的逻辑视图
查询一个物化视图,可以避免在运行期间执行join查询,但是物化视图必须在数据更新时保持最新的数据
物化视图的使用有三个
- 选择一个视图做物化
- 维持一个视图的新鲜数据
- 把物化视图当做ad-hoc查询
(a)是4.3节中讨论的数据库自动调优的高级方案
(c)在不同产品中有不同的实现,即使对于简单的单块查询,也有挑战
对于带有聚合和子查询的通用SQL更是如此
对于(b)大多数供应商提供多种刷新技术
- 对于物化视图导出的表的每次更新,再执行一个物化视图更新
- 定期丢弃并创建新的物化视图
这两种方案需要做权衡,第一种实时性好但是会有运行时开销
第二种开销小,但是会有数据一致性问题
OLAP and Ad-hoc Query Support
一些数据仓库有预测查询,比如,对于每个月末,会运行一个总结的销售报告,对于零售链中每个销售区域部门
在此工作负载中穿插着由业务分析人员动态制定的特别查询
显然,这可以构造物化视图来支持,更一般的来说,大多数企业的查询要求聚合
这样可以使用物化视图,对每个商店按部门汇总销售额,如果指定了上述区域查询
可以通过 每个区域中的独立商店做 rolling up来满足
这种聚合通常被称为:数据立方体 data cube,是一种有趣的物化视图
在1990年代的产品如 Essbase 提供了定制工具,以优先级cube格式来存储数据,并提供基于cube 的用户接口,来导航数据
这种能力被称为 OLAP
随着时间推移,data cube被添加到全功能的关系数据库系统中,经常称为 关系OLAP ROLAP
很多提供ROLAP的DBMS,现在已经演化为可以内部实现一些早期的OLAP风格的存储模式(特殊case下),结果就变成了 HOLAP,混合的OLAP
data cube为可以预测的场景提供了高性能,但对于 ad-hoc 场景,通常没什么帮助
Optimization of Snowflake Schema Queries
很多数据仓库都有一个特别的模式设计方法
他们存储了事实集合在销售环境中,一条记录类似:
客户 X 买了产品 Y 来自商店 Z,时间为 T
一个中央的事实表记录了每次事实的信息,如采购架构,折扣,销售税率信息等等
事实表通过外键关联到每个维度表,维度表可以包括
- 客户
- 产品
- 商店
- 时间
- 等等
一种经常使用的模式叫做:星型模型
因为它有一个中央的事实表,其他维度表都环绕着它
事实表有 1:N的 主键-外键的关联,在实体关系图中绘制这种模式是星型的
很多维度表有天然的层次关系,比如 商店可以聚合到一个区域,那么商店的维度表,可以增加一个外键,到区域维度表
类似的层次如属性引用时间,月、日、年,管理的层级系统等等
在这个case中,是一个 多级的星型,也叫做:雪花模型
本质上,所有的数据仓库查询都需要在这些表的某些属性上,过滤一个、多个雪花模型维度
在join这个结果到中央事实表,在事实表、维度表上做group,然后计算SQL聚合
随着时间推移,供应商们在他们的 优化器中,有一类特殊的查询,因为这些很流行,而对于长时间运行的命令来说,选择一个好的查询计划非常重要
Data Warehousing: Conclusions
我们已经看到了,数据仓库跟传统的OLTP非常不同
- 相比于B+树,他需要bitmap索引
- 相比于通用目的的优化,它需要特别注意雪花模型之上的聚合查询
- 相比于普通视图,它需要物化视图
- 相比于快速的事务更新,它需要快速的批量导入等等
相关文章:
《An overview of data warehousing and olap technology》
一开始主要的供应商提供面向 OLTP的架构,之后增加了数据仓库特性
之后,各种小的供应商提供了 DBMS的解决方案,如:
- Teradata
- Netezza
他们使用的是 shared-nothing的专有硬件,其他的厂商有:
- Greenplum,并行化的PG
- DATAllegro
- EnterpriseDB
他们可以运行在廉价的硬件机器之上
有些人宣称列存储在数据仓库领域有巨大的优势,传统的存储引擎是行存的
当表很宽时,并且只需要访问少数几个列时,使用列存就很有效
列存对数据压缩也很有效,因为都是相同类型的数据
挑战
- 跨多列存储时,表中行位置需要保持一致性
- 需要额外的机制实现多个列的join
这对于OLTP来说是一个大问题,但对于大多数都是append场景的数据仓库、日志存储系统来说,不是什么问题
主要的供应商有
- Sybase
- Vertica
- Sand
- Vhayu
- KX
几个文章
- 《Performance tradeoffs in read-optimized databases
- 《C-store: A column oriented dbms》
- 《One size fits all: An idea whose time has come and gone》
Database Extensibility
关系型数据库传统上被认为是存储数据类型有限制,在公司和管理记录系统中,存储事实和数字
不过今天有各种各样的数据类型,出现在各种程序语言中
这是通过DBMS的各种方式扩展来实现的,这章来简单介绍下各种扩展数据
在交付实现时候会出现各种扩展,强调交付此可扩展性时出现的一些体系结构问题
这些特性在今天的大多数商业DBMS中都有不同程度的出现,在开源的PostgreSQL DBMS中也有
Abstract Data Types
理论上,关系模型与可以放置在模式列上的标量数据类型的选择无关
但是,最初的关系数据库系统只支持一组静态的字母数字列类型,而这种限制与关联模型本身有关
DBMS可以在运行时扩展数据类型,正如早起的Ingres ADT系统,以及后期的跟随者 Postgre系统
DBMS类型系统,解析器需要从系统目录驱动,维持已知的类型列表,指向被使用的method(code),来维持这些类型
这种方式,DBMS不需要解释类型,只是在表达式求值的时候,适当的调用其method,因此叫做:抽象数据类型
比如,可以注册一个二维空间类型 矩形,然后提供矩形的相交、并集等操作
这就意味着系统必须为用户代码提供一个运行时引擎,并且要确保执行的安全性,比如代码不能导致数据库崩溃或者数据损坏
今天主要的DBMS都允许用户通过 一个重要的“存储过程”现代SQL子语言,来订阅他们的功能
大多数都支持至少一种语言,如C、Java
在windows平台中,SQLServer和DB2支持代码编译到 .net运行环境,可以用各种语言来书写,比如VB、C++、C#等
PG支持C、perl、python、Tcl、并允许在运行时增加一个新语言,如流行的第三方插件 ruby和统计包R
未确保抽象数据类型在运行期间的高效,查询优化器需要在 select、join时候谨慎对待用户定义的代码
有些case会推迟 selelct,直到join完成后
为了使 ADT 事件更有效,会在其上定义索引,比如,B+树 需要扩展到 ADT上的索引表达式,而不是仅仅是列(有时叫:函数索引),当他们被应用时,优化器会扩展选择他们
对于线性顺序以外的谓词,如非 < 、>、=,此时B+ 树就不再有效,系统需要支持扩展的索引模式
- 原始的PG扩展访问模式接口
- GiST
Structured Types and XML
ADT被设置全完兼容关系模型,不需要修改任何基本的关系代码,只需要改变属性值之上的表达式
过了多年之后,又提出了很多激进的提案,希望DB能支持 非关系结构类型
- 内嵌的列类型如数组、sets、tree
- 嵌套的tuple
- 关系
可能今天这些提案中最相关的是,通过XPath、XQuery等语言支持XML
处理XML这样的结构化类型大概有三种方式
- 建立一个自定义的数据库系统,对结构化类型的数据进行操作;从历史上看,这些尝试都被适应传统关系DBMS中的结构化类型的方法所掩盖,XML也遵循了这个趋势
- 用ADT的方式存储复杂类型,比如定义XML类型列的关系表,然后每行存储一个XML文档,这意味着搜索XML,使用XPath树匹配的方式,这个执行方式对优化器是不透明的
- 将内嵌结构规范化,在insert的时候,将用外键将子对象和父类连接起来;这种方式叫分解XML,它导出所有数据结构到DBMS关系框架中,但增加了存储开销,在查询时需要重新连接这些数据
今天大多数供应商都提供了 ADT 和分解方式来存储,并允许数据库设计者选择他们
XML例子中,分解方式也很常见,它提供了删除同层级XML元素之间排序信息的 选项
它提升了查询性能:允许join重排序、其他关系优化
一个相关问题是,对关系模型做适度的扩展,用于处理内嵌的表和tuple,以及数组
这杯广泛的用在Oracle里面,这些设计的权衡跟处理XML类似
Full-Text Search
传统上,关系数据库对于处于富文本数据,以及关键检索方面被认为是比较差的
理论上,在数据库上建立自由文本搜索很简单,需要存储文档,用tuple的元祖(word,documentID,position)定义反向文件关系,并在word列上建立B+ 树索引
这些基本上是任何搜索引擎都会做的事情,为单词添加一些语言规范化,并添加一些额外的元组属性,以帮助对搜索结果进行排序
但是除了模型之外,大多数文本索引引擎都实现了许多针对该模式的性能优化,这些优化在典型的DBMS中是无法实现的。
这包括去 规范化的模式,让每个单词只出现一次,并列出每个出现单词的列表,如(word,list<documentID,position>)这样的
这允许对list做更激进的增量压缩(posting list)这对于典型的倾斜是至关重要的(Zipfian)文字在文献中的分布
不过文本数据库倾向于数据库仓库风格,他绕过了DBMS的事务管理,人们普遍认为,DBMS中的文本搜索,普遍比 自定义的文本搜索引擎 慢一个数量级
今天,大多数DBMS都会使用一个独立的子系统来处理文本索引,或者用单独的引擎来完成这些工作
文本索引工具通常包含全文文档,也可以包含短文本属性,大多数情况下,全文索引更新都是异步的,也就是爬虫方式,不需要事务
不过PG提供了一个额外的选项,具有带事务的全文搜索索引
在大多数系统中,全文索引是存储在DBMS之外的,因此需要独立的工具来备份和恢复
在关系DB中处理全文搜索的一个关键挑战是,用有效、灵活的方式,将关系查询语义(未排序和完整的结果集),和使用关键对文档进行搜索排名(有序的、不完整的结果)连接起来
比如,当每个关系上都有关键词搜索谓词时,就不知道如何对 两个关系上的join查询结果做排序
这个问题在目前的 ad-hoc 查询中仍然有
给定一个查询输出的语义,对于关系查询优化器的另一个挑战是,对文本索引的选择性、成本估算进行推理
以及判断一个查询的合适成本模型,该查询的答案集在用户界面中进行了排序和分页,并且可能无法完全检索
Additional Extensibility Issues
除了针对数据库可扩展性的三个驱动使用场景之外,我们还提出了引擎中的两个核心组件,它们通常可扩展到各种各样的用途。
已经有一些查询优化的提案,包括设计和支持DB2优化、支持Tandem、微软优化
所有这些模式都提供规则驱动的子系统,用来生成或者修改查询计划,并允许新的优化规则独立注册
当有新的需求、或者增加一个查询执行器,以及新为特定的查询重写、查询计划优化开发新想法时,这些技术可以简单的去扩展优化
这些通用的架构,对于启动上述多个特定的扩展类型功能,非常有用
从早期系统开始出现的另一种横切的可扩展性形式是,数据库可以在 schema内包装远程数据源,就好像是原生表一样,并能在查询过程中访问他们
一个挑战是,优化器处理的数据源不支持 scan,但是需要响应请求分配一个变量值,这需要泛化匹配索引 SARG请求谓词的优化逻辑
另一个挑战是,执行器高效的处理源端数据源,这些数据源可能是很慢的,或者是突发的产生输出
这概括的设计挑战是,查询执行一个异步的磁盘I/O 的挑战,增加了一个数量级或更多的访问时间可变性
Standard Practice
本质上,所有关系数据库的粗略架构,跟System R的原型类似,论文:
《System R: Relational approach to database management》
多年来,查询处理的研究和开发一直专注于该框架中的创新,以加速越来越多的查询和模式类
跨系统的主要设计差异出现在优化器搜索策略(top-down vs. bottom-up)和查询执行器控制流模型中
特别是对于shared-nothing 和 shared-disk并行性(迭代和exchange算子 vs 异步生产者/消费者 模式)
在细粒度级别上,混合模式上的优化器、执行器、访问模式有很大不同,
可以为不同的工作负载,OLTP,决策支持的数据库仓库OLAP 实现很好的性能
商业产品中的秘密武器决定他们在特定场景下的性能表现,但大致上所有的商业系统在各种工作负载场景下都能很好工作,可能在某些特定工作负载场景下会执行很慢
在开源领域,PG有一个很复杂的查询执行器,并由传统的CBO优化器,一系列的执行算法,以及一系列的扩展特性,这些在商业产品中并没有
MySQL的查询执行器非常简单,就是索引之上的nested-loop join
mysql的查询优化器专注于分析查询,以确保通用的查询可以轻量和高效,别特是
- key,外键 join
- outer join 到 join重写
- 只要结果集前几行的查询
通读MySQL手册和查询处理代码,并将其与更复杂的传统设计进行比较,记住MySQL在实践中的高采用率和它似乎擅长的任务,这是有指导意义的。
Discussion and Additional Material
因为查询优化,执行的清晰模块化,这么多年来出现了非常多的算法、技术、技巧被开发出来,关系查询处理的研究一直持续到今天
好消息是,很多已经在实践中使用的方法,以及没有使用的,都可以在文献中找到
Chaudhuri的简短调查是查询优化研究的一个很好的起点。对于查询处理研究,Graefe提供了一个非常全面的调查,论文
《An overview of query optimization in relational systems》
除了传统的查询处理,这些年有大量的工作,将丰富的统计方式整合到大型数据集处理中
一种自然的扩展是使用抽样或汇总统计信息为聚合查询提供数值近似,可能以持续改进的在线方式
然而,尽管已有相当成熟的研究成果,但市场对这一技术的接受相对较慢
DB2 和 Oracle都提供了简单的基于表的采用技术,但是没有提供多表统计上的可靠估值
大多数供应商没有关注这些特性,而是丰富了他们的OLAP平特性,这限制了他们的查询速度,但可以提供100^%的查询正确性
另一个很重要但是更基础的扩展时包括:DBMS中的数据检索技术
流行的技术包括:
- 统计聚类
- 分类
- 回归
- 关联规则
除了研究文献中的这些技术的独立实现,整合这些技术使得丰富关系查询也存在架构上的挑战
社区也出现了很多并行的计算框架,谷歌的Map-Reduce、微软的Dryad,以及开源的Hadoop
这些系统跟shared-nothing并行关系查询执行很像,由程序员实现自定义的查询算子实现
它们还包括用于管理参与节点故障的简单但设计合理的方法,这在大规模情况下是常见的
这一领域最有趣的问题是,它被创造性的适用于 计算中的各种数据密集型问题,包括文本和图像处理,以及统计方法
数据库引擎中的其他想法,是否会被框架的用户借鉴倒是很有趣
比如,早起雅虎就扩展了Hadoop,使用了声明式查询和优化,构建在这些框架上的创新也可以整合回到数据库中
Storage Management
有两种基本的 DBMS存储管理类型,使用在如今的商业产品上
- DBMS直接跟低级别的块模式设备驱动交互,比如底盘,也叫做原始模式访问
- DBMS使用标准的OS文件系统功能
这个决策影响了DMBS控制空间和时间的能力 我们依次考虑这两个维度,并继续更详细地讨论存储层次结构的使用
Spatial Control
从磁盘到磁盘的顺序带宽 是 随机访问的 10 - 100倍,而且这个比例还在增加
磁盘密度大约18个月会翻倍,带宽上线的大概是密度的平方根,跟转速呈线性关系
然后磁盘臂移动,其改进速度要缓慢很多,大概每年7%
对于DBMS存储管理非常关键的是,磁盘上的块放置,这样大数据量的请求可以顺序执行
DBMS对自身的访问模式非常清楚,比OS更能理解工作负载情况,DBMS的架构是,可以对磁盘上数据块的控制位置做完全的控制
对于DBMS最佳的方式是控制它的数据空间位置,直接存储到原始磁盘设备上,避免文件系统的干扰
这是因为原始设备地址通常与存储位置的物理距离密切相关
大多数商业数据库都提供了这种功能,获得最佳性能,但是也有一些缺点
- 他需要DBA将整个磁盘分区交给DBMS,这使得它们对需要文件系统接口的实用程序(备份等)不可用
- 原始磁盘接口通常是OS特定的,这使得DBMS很难移植,不过大多数商业数据库很多年前就克服了
- 存储行业的发展,如RAID、storage区域网络(SAN)和逻辑卷管理器已经变得流行起来。
如今,我们处在一个虚拟磁盘设备的时代,原始设备接口实际被软件和应用拦截了,他们会重新定位数据到一个、或更多的物理磁盘
于是,DBMS显示控制物理磁盘的优势,随着时间推移被稀释了
除了原始的磁盘访问之外,DBMS还可以再OS文件系统中创建一个非常大的文件,之后管理该文件上的数据位置作为偏移量
这个文件本质上被当做了驻留在磁盘上的页面线性数组,这避免了原始设备访问的一些缺点,并能提供很不错的性能
在大多数场景中,如果分片了一个在一个空的磁盘上分配了一个非常大的文件,那么这个文件的偏移量,与存储区域的位置位置会非常接近
因此这是一种很好的访问方式,不需要再直接访问原始设备接口了
大多数虚拟化存储系统也被设计为 在附近的物理位置的文件中 存放接近的偏移量
随着时间推移,使用大文件而不是原始磁盘就不那么重要了,使用这个文件系统接口,对于时间控制也有其他影响
我们比较了在主要的商业DBMS上,直接的原始访问,以及基于中间系统的大文件访问
对比发现在运行TPC-C性能测试时,大概有6%的性能损失,对于少量的I/O密集型负载来说几乎没有负面影响
DB2在报告中说,在使用直接I/O和其变体并发I/O时,其文件系统开销低于 1%
供应商很少推荐原始存储了,现在很少有有客户运行在这样的配置之上
它在主要的商业系统中仍然是受支持的特性,主要用于基准测试
有些供应商还支持自定义的page大小,如Oracle和DB2,其他商业系统微软的则不支持多page大小,这会增加管理的复杂度
如果page大小是可调整的,一般应该是文件系统(原始文件系统)的数倍
关于适当选择页面大小的讨论在" 5分钟规则"的论文,后来被更新为“30分钟法则”
如果正在使用文件系统而不是原始设备访问,可能需要特殊的接口来写入与文件系统不同大小的页面;例如,POIX mmap/msync调用就提供了这种支持。
Temporal Control: Buffering
除了控制数据在磁盘上的位置之外,DBMS还必须控制何时将数据物理地写入磁盘
DBMS包含了重要的逻辑:理解关于何时写入数据块 到磁盘
大多数文件系统也提供了内建的I/O 缓冲区机制,来决定何时对数据块做读写
如果DBMS使用了标准的文件系统接口来写入,则因为静默的推迟写入、或者重排序写入,OS可能会混淆DBMS的逻辑意图
第一组问题涉及到DBMS的 ACID事务保证
在没有对时间、磁盘写入顺序有显示的控制时,DBMS就不能保证软件、硬件故障后的原子恢复
预写日志WAL协议要求:写入到日志设备必须在写入到数据库设备之前,直到提交日志记录已经被可靠的写入到日志设备之后,才能将commit请求返回给用户
第二组问题跟性能有关,但不影响正确性
现代OS文件系统一般内置了支持预先读(投机性的读取),以及延迟写(延迟批量写入)
但是这些不合适DBMS模式
文件系统的逻辑依赖于 文件中物理字节偏移量的连续性,来决定预读取决策
DBMS-level I/O工具可以支持基于未来读请求的逻辑预测性I/O决策
这些请求在SQL查询处理级别是已知的,但在文件系统级别不容易识别
比如,当scan B+树的不一定连续的叶节点时(行存储在B+树的叶子中),可以请求dbms级别的预读
逻辑的预读取在DBMS逻辑中很容易实现,比如让DBMS提前发出I/O请求
查询执行计划包含关于数据访问算法的相关信息,并包含关于查询的未来访问模式的完整信息
DBMS可能希望基于 混合了锁竞争和I/O吞吐量等问题的考虑,自己决定何时刷新log,
这种详细的未来访问模式知识可用于DBMS,但不能用于OS文件系统
最后一组性能问题是,双缓冲区、高内存副本的CPU开销
考虑到DBMS必须小心地进行自己的缓冲以确保其正确性,任何额外的缓冲由操作是多余的
这种冗余导致两个开销
- 它浪费了系统的内存,这些本可以用于正常工作的
- 浪费时间和处理资源,导致额外的拷贝
- 数据从磁盘读到OS buffer,再拷贝到DBMS的buffer,写也是类似
拷贝数据到内存会引起严重的瓶颈,引起延迟、消耗CPU周期、flood CPU的cache
对于没有做过数据库操作和实施的人来说,这非常让人惊讶,因为人们会认为相比磁盘,内存操作非常廉价
但通常经过调整优化的事务处理DBMS,其吞吐量不受I/O限制
这在高端安装中是通过购买足够的磁盘和RAM来实现的,这样重复的页面请求就会被缓冲池吸收,磁盘I/ o 就会以能够满足系统中所有处理器的数据需求的速率跨磁盘臂共享
一旦实现了这种“系统平衡”,I/O延迟就不再是主要的系统吞吐量瓶颈,其余的主内存瓶颈则成为系统中的限制因素
内存副本正在成为计算机体系结构中的主要瓶颈:这是由于每美元每秒的原始CPU周期(遵循摩尔定律)和RAM访问速度之间的性能演化差距(这明显落后于摩尔定律)
操作系统缓冲问题在数据库研究文献和业界中已经广为人知
大多数现代OS现在提供了hook(例如,POSIX mmap套件调用或平台特定的DIO和CIO API集),以便数据库服务器等程序可以避免对文件缓存进行双缓冲。
这确保了写操作在请求时经过磁盘,避免了双重缓冲,并且DBMS可以控制页面替换策略。
Buffer Management
为了提供高效的访问数据库的page,每个DBMS都在其自己的内存空间中,实现了很大的共享buffer pool
早起这些buffer pool大小都是固定的,由管理员创建,限制DBMS都可以动态分配,根据系统需要和可以资源
buffer pool被组织为一个帧的数组结构,每个帧都是数据库磁盘块大小的内存区域
数据块从磁盘拷贝到buffer pool,不需要改变格式,在内存中维持原始格式,然后之后写回磁盘
这种没有转换的方式,避免了数据往返于磁盘的marshalling、unmarshalling的CPU开销
更重要的是,固定大小的帧也避免了 额外的碎片、通用的压缩产生的内存管理复杂性
与buffer pool帧数组关联的是hash表
- 内存中的page编号 是他们在帧表中的位置
- 磁盘上存储了page的位置
- 关于这些page的元数据
元数据包括了
- 自它从磁盘读取之后,是否被修改过,这是一个bit位
- 页的替换策略,当buffer pool满了之后需要选择驱逐的页的相关信息
- 也包含pin信息,表示这个page被钉在内存中,如果pin的size不为0,则表示内存中有些page不能被换出
这允许DBMS的工作线程在操作页面之前增加针数,然后在操作页面之后减少针数,从而在缓冲池中固定页面
其目的是在任何固定的时间点上只固定缓冲池的一小部分。有些系统还提供将表固定在内存中的功能,作为一种管理选项,这可以提高对小型的、使用频繁的表的访问时间
然而钉住的page会减少buffer pool正常活跃可用的page数量,当钉住的比例增加时,对性能也有负面影响
关系系统早期的许多研究都集中在页面替换策略的设计上,因为dbms中发现的数据访问模式的多样性使简单的技术变得无效
例如,某些数据库操作往往需要全表扫描,当扫描的表比缓冲池大得多时,这些操作往往会清除池中所有常用引用的数据
对于这样的访问模式,引用的最近性不能很好地预测未来引用的概率
对于一些知名的OS替换策略如LRU、CLOCK等,他们对于数据库方式模式来说表现会很差
现在有各种备选方案,包括一些尝试通过查询执行计划信息调优替换策略的方案
大多数系统使用对LRU方案的简单增强来全表扫描的情况,一种出现在研究文献中并已在商业系统中实现的方法是LRU-2
另一种在商业DB中的替换策略是依赖于page的类型,比如B+树的 root就跟堆文件中的page有不同的替换策略
这让人想起Reiter的域分离方案
64位寻址和内存价格不断下降,使得非常大的缓冲区在经济上能负担的起了
这为大内存提高效率提供了机会,与之对应的是,一个庞大且非常活跃的缓冲池也会在重启恢复速度,和高效检查点等方面带来更多挑战
Standard Practice
在过去的十年中,商业文件系统已经发展到可以很好地支持数据库存储系统的地步
在标准使用模型中,系统管理员在DBMS中的每个磁盘或逻辑卷上创建一个文件系统,然后使用像mmap这样的低级接口来控制在该文件中的位置
DBMS本质上是将每个磁盘、逻辑磁盘卷当做(几乎)连续的page的线性数组
在这种配置中,现代文件系统为DBMS提供了合理的空间和临时控制,而且这种存储模型基本上在所有数据库系统实现中都可用
原始磁盘现在变成了一个对于高性能模式的可选项,不过现在基本只用于基准测试了
Discussion and Additional Material
数据库存储子系统是一项非常成熟的技术,但是近年来出现了一些关于数据库存储的新考虑因素,它们有可能在许多方面改变数据管理技
一个关键的技术变化是,闪存作为经济上可行的随机访问持久存储技术
从数据库系统研究的早期开始,就一直在讨论数据库管理系统设计中因新存储而产生的巨大变化技术取代磁盘
闪存在实现上是可行的,而且经济上也得到了市场的认可,相比于磁盘和内存,出现了一种有趣的中间的 成本/性能的权衡
Flash是三十多年来在这方面取得成功的第一种新的持久存储介质,因此它的特殊性可能对未来的DBMS设计产生重大影响
另一种,最近出现的传统主题是,对数据库的数据做压缩
这个话题的早期工作集中在数据磁盘压缩上,这样在读的时候可以最小化延迟,也能最大化缓冲区的容量
随着处理器性能的提高和RAM的延迟没有跟上,考虑在计算过程中保持数据压缩变得越来越重要,从而最大化数据在处理器缓存中的驻留
但是这需要压缩的表示,它适应于数据处理,以及操作压缩数据的查询处理内部。关系数据库压缩的另一个问题是,数据库是可重新排序的元组集,而大多数压缩工作关注字节流而不考虑重新排序。
最近关于这一主题的研究表明,在不久的将来数据库压缩有很大的前景
最后,在传统的关系数据库市场之外,人们对大规模但稀疏的数据存储技术更感兴趣,在这种技术中,逻辑上有数千列,其中大部分对于任何给定行都是空的
这些场景通常通过某种属性-值对或三元组来表示
实例包括谷歌的BigTable[9],微软使用的标记列 Active Directory和Exchange产品,以及资源描述 为“语义Web”提出的框架(RDF)
这些方法的共同点是使用按照数据表的列(而不是行)组织磁盘的存储系统。面向柱存储的思想在最近的一些数据库研究工作中得到了复兴和详细探讨
Transactions: Concurrency Control and Recovery
数据库系统一般被认为是巨大的,无法拆分、重用的单体软件应用
实际上,数据库系统–他们的开发者团队,实现和维护者,是被拆分为独立的团队维护独立的组件,他们之间通过文档接口来交互
关系查询处理,事务存储引擎之间的接口尤其如此
在大多数商业数据库中,这些组件由不同的团队编写,他们之间的接口都有良好的定义
DBMS真正的整体是事务性存储管理器,它通常包含四个深度交织的组件
- 锁管理,用于并发控制
- 日志管理用于恢复
- buffer pool用于处理数据库I/O
- 用于在磁盘上组织数据的访问模式
关于数据库系统中事务存储算法和协议的繁琐细节,已经花了大量篇幅进行描述。希望了解这些系统的读者至少应该阅读
- Database management systems
- 关于ARIES 的日志协议 《Aries: A transaction recovery method supporting fine-granularity locking and partial rollbacks using write-ahead logging》
- 关于事务索引并发性和日志记录的严肃文章
- 《Concurrency and recovery in generalized search trees》
- 《Aries/kvl: A key-value locking method for concurrency control of multiaction transactions operating on b-tree indexes》
- 更高级的读者会想咨询Gray和Reuter’s的事务书籍
- 《Transaction Processing: Concepts and Techniques》
- 想要称为专家,在阅读后就必须有效的实践
这里我们不详细讨论算法和协议,而是研究这些不同组件的作用
我们将重点放在教科书中经常被忽略的系统基础设施上,强调组件之间的相互依赖关系,正是这些组件导致了使简单协议可行的许多微妙和复杂性
A Note on ACID
许多人都熟悉“ACID交易”这个术语,这是Haerder和Reuter[34]的助记词。ACID代表原子性、一致性、隔离性和持久性。这些术语没有正式定义,也不是结合起来保证事务一致性的数学公理
因此,仔细区分术语及其关系并不重要
但是,尽管ACID这个缩写是非正式的,但是它对于组织交易系统的讨论还是很有用的,并且非常重要,所以我们在这里回顾一下:
- Atomicity,这就是对事务 all or nothing的保证,要不事务的所有行为都提交,或者什么都没做
- Consistency,这是用户定义的保证,SQL完整性约束通常用于在DBMS中捕获这些保证,SQL给定一组约束提供的一致性定义,事务只有在数据库处于一致状态时才能提交
- Isolation,保证在并发情况下,两个并发的事务不会看到彼此正在进行(还没提交)的更新;应用不需要编码防御性代码防止脏数据,程序好像只是独占了数据库访问
- Durability,一个已提交事务的更新将在数据库中对后续事务可见,而不受后续硬件或软件错误的影响,直到它们被另一个已提交事务覆盖
大致来说
- 现代DBMS实现 isolation,通过锁协议实现
- Durability,通过日志和恢复来实现的
- Isolation and Atomicity,通过锁定(防止数据库临时状态的可见性)和日志记录(确保可见数据的正确性)的组合来保证的
- Consistency,通过查询执行器中的运行时检查来管理的,如果事务的操作将违反SQL完整性约束,则事务将中止并返回错误代码
A Brief Review of Serializability
现在通过回顾数据库并发事务的主要目标,来讨论事务,下一章会介绍在多用户事务存储管理中,两个实现这个概念的最重要的构建块
- lock
- latch
Serializability:是定义良好的教科书式并发事务正确性概念。它规定,多个提交事务的交叉操作序列必须对应于事务的某些串行执行——就好像根本没有并行执行一样
序列化是一种描述一组事务所需行为的方法
从单个事务的角度来看,隔离也是同样的思想;如果一个事务看不到任何并发异常,则可以说他执行了隔离性
可序列化性是由DBMS并发控制模型强制执行的
有三种广泛的并发控制实施技术
这些在教科书和早期的调查论文中都有详细的描述,但我们在这里非常简要地回顾一下
- Strict two-phase locking 2PL,读之前需要共享锁,写之前需要排斥锁;所有的lock被会持有直到事务终止,此时自动释放,其他事务在等待获取锁时,会阻塞在等待队列中
- Multi-Version Concurrency Control MVCC,事务不持有锁,而是保证在过去某个时间点上,数据库状态的一致性视图,即使在固定的时间点上发生了行变更
- Optimistic Concurrency Control OCC,多个事务允许读写一个条目而不需要锁,事务管理他们的读写历史记录,在提交前检查可能出现隔离冲突的历史,如果出现冲突事务则回滚
大多数商业DBMS实现完全可串行化是通过 2PL
为了减少锁和锁冲突,一些DBMS支持MVCC、OCC,作为2PL的附加
在MVCC模型中,读锁是不需要的,不过通过经常作为不提供完全串行化为代价而实现
为了避免在读取之后阻塞写操作,允许在保存前一个版本的行之后继续进行写操作,或者保证可以通过其他方式快速获取该行的前一个版本
运行中的读事务继续使用前一个行值,就好像它被锁定了,不能被更改一样
在商业MVCC实现中,这个稳定的读值被定义为
- 读事务开始时的值
- 或者该事务最近的SQL语句开始时的值
虽然OCC避免等待锁,但在事务之间发生真正的冲突时,它可能导致更高的惩罚
在处理跨事务的冲突时,OCC与2PL类似,只是它将2PL中的锁等待转换为事务回滚
在冲突不常见的场景中,OCC性能非常好,避免了过于保守的等待时间
然而,由于冲突频繁,过多的回滚和重试会对性能产生负面影响,使其成为一个更差的选择
Locking and Latching
数据库锁只是系统中约定使用的名称,用来表示DBMS管理的物理项(如磁盘页)或逻辑项(如元组、文件、卷)
注意,任何名称都可以有一个与之关联的锁—即使该名称表示一个抽象的概念
锁定机制只是提供了一个注册和检查这些名称的地方。每个锁都与一个事务相关联,每个事务都有一个惟一的事务ID。锁有不同的锁
这些模式与锁模式兼容性表相关联
在大多数系统中,此逻辑基于Gray关于锁粒度的论文中介绍的众所周知的锁模式。这篇文章还解释了在商业系统中如何实现分层锁。分层锁允许使用单个锁来锁定整个表,同时有效且正确地支持同一表中的行粒度锁,论文:
《Granularity of locks and degrees of consistency in a shared data base》
锁管理支持两种基本调用:
- lock (lockname,transactionID, mode)
- remove transaction (transactionID)
注意,对于严格的2PL协议不允许有独立的资源释放,所以remove_transaction 将释放事务关联的所有资源
然而,SQL标准允许较低程度的事务隔离,因此需要解锁
- unlock (lockname, transactionID)
也有一个锁升级,允许事务升级到一个更高的锁模式
- lock upgrade (lockname, transactionID, newmode)
允许事务以两阶段的方式“升级”到更高的锁模式(例如,从共享模式升级到独占模式),而不删除和重新获取锁
有些系统还支持条件锁:
- conditional lock (lockname, transactionID, mode)
这个调用总是立刻返回,并指定是否成功获取锁,如果不成功则DBMS线程不需要入队列等待
条件锁对于索引并发讨论的论文:
《Aries/im: An efficient and high concurrency index management method using write-ahead logging》
为了支持这些调用,锁管理器支持两种数据结构
- 一个全局的 lock table 维护了锁定名字 -> 他们关联的信息
- 表是动态的hash表,key是锁名字,关联的每个lock是一个mode标志,指明了锁模式
- 以及一个 锁请求对(事务id,模式)的等待队列
- 锁管理器维护了 事务表,key为事务id,每个事务包含了两个条目
- 指向T的DBMS线程状态,当获得了正在等待的锁时允许重新调度
- 一个指针列表,指向锁表中所有T的锁请求,以便删除特定事务关联的所有锁(事务提交或终止)
在内部,锁管理器使用死锁检测DBMS线程,该线程定期检查锁表,以检测等待周期(每worker都在等待下一个,从而形成一个循环)
在检测到死锁后,死锁检测器将中止其中一个死锁事务。中止哪个死锁事务的决定基于研究文献中已经研究过的启发模式
锁相关论文:
《System level concurrency control for distributed database systems》
《Transaction Processing: Concepts and Techniques》
在 shared-nothing 和 shared-disk系统中,需要分布式死锁检测[61]或更基本的基于超时的死锁检测
更详细的描述参考上面的 事务处理:概念和技术 一书
作为数据库锁的辅助,还提供了较轻的latch以实现互斥,latch更类似于监视器或信号量,而不是锁
它们用于提供对内部DBMS数据结构的专属访问,比如,缓冲池页表有一个与每个帧相关联的锁存器,以确保在任何时候只有一个DBMS线程替换给定的帧。锁存用于锁的实现,并短暂稳定可能被并发修改的内部数据结构
latches 和 lock 的不同:
- lock保存在锁表中,通过哈希表进行定位;latch驻留在它们所保护的资源附近的内存中,并通过直接寻址访问
- 在严格的2PL实现中,锁受限于严格 2PL协议,在基于特殊情况内部逻辑的事务中,可以获取或删除latch
- lock获取完全由数据访问驱动,因此锁获取的顺序和生命周期在很大程度上掌握在应用程序和查询优化器手中。latch是由DBMS内部的专门代码获得的,DBMS内部代码战略性地发出锁存请求和释放
- lock允许出现死锁,而死锁的发现和解决通过事务重启;latch的死锁必须避免,如果出现表示有bug
- latch是通过原子的硬件指令实现的,如果罕见的不可用,可以通过OS内核的互斥实现
- latch调度大概几十个CPU周期,而lock请求大概几百个CPU周期
- 锁管理器会跟踪事务持有的所有锁,并在异常时候自动释放;DBMS内部持有的latch必须小心处理,并将手动清理作为异常处理的一部分
- latch不会被跟踪,因此在任务出错时不能自动释放
latch API支持包括
- latch(object, mode)
- unlatch(object)
- conditional latch(object, mode)
大多数情况下,选择的latch模式包括共享和独占
latch维护一个模式,等待latch的DBMS线程的等待队列,latch和unlatch调用的工作原理和预期的一样
条件latch()调用类似于上面描述的条件lock()调用,也用于索引并发
Transaction Isolation Levels
很早的时候就有了交易概念的发展,尝试通过提供比可序列化性更弱的语义来增加并发性
挑战在于在这些情况下提供健壮的语义定义。在这方面最有影响力的努力是格雷的早期作品《一致性的程度》(Degrees of Consistency
这项工作试图提供一致性程度的声明性定义和锁定方面的实现。受此影响,ANSI SQL标准定义了四个“隔离级别”:
- READ UNCOMMITTED:事务可以读任何版本的数据,提交、未提交的,这是通过不获取任何锁的读请求来实现的
- READ COMMITTED:事务可以读任何已经提交的数据版本,重复读一个对象可能有不同(提交)版本,在访问对象之前获取一个读锁来实现,访问之后会立刻释放锁
- REPEATABLE READ:事务只会读到提交数据的一个版本,一旦读了一个对象,之后总是会读到相同版本,通过在访问之前获取一个读锁,并在事务终止前一直持有锁来实现的
- SERIALIZABLE:完全可序列化的访问是有保证的
第一个困惑是:可重复,它好像提供了可串行的保证,但并非如此,早起的System R引发了一个被称为幻读的问题
一个事务访问一个关系超过一次,在相同事务中带有相同谓词,但是再次访问时看到了第一次没有出现的幻影tuple数据
这是因为在元组级粒度上的两阶段锁定并不会阻止新元组插入到表中
两阶段锁在表级别可以预防幻读问题,但是表级别的锁会有很大限制,事务通过索引只能访问几个tuple
商业系统通过基于锁定的并发控制实现提供上述四个隔离级别。不幸的是,正如Berenson等人[6]所指出的,无论是Gray的早期工作还是
ANSI标准实现了提供真正声明性定义的目标。两者都以微妙的方式依赖于一个假设,即使用锁定方案进行并发控制,而不是乐观的或多版本并发方案
这意味着所提议的语义定义不清
我们鼓励有兴趣的读者看看Berenson的论文,它讨论了SQL标准规范中的一些问题,以及Adya等人的研究,它提供了一种新的、更清晰的方法来解决这个问题
除了标准的ANSI SQL隔离级别之外,各种供应商还提供了在特定情况下很受欢迎的其他级别
- CURSOR STABILITY:
- 这是要解决更新丢失问题,lost update
- 假设有两个事务T1、T2,T1运行的模式为 READ COMMITTED
- T1读一个银行账户值,记住这个值,做一些操作之后,再 + 100
- T2也是读和写,这次是减去 300,如果T2的行为发生在 T1的读-写之间,则T2的更新就丢失了
- 从结果看,这个账户增加了100,但实际应该是减少了200(增加100,又减去300)
- CURSOR STABILITY 是在读游标中,lock住最近读的条目,当事务终止,或下一次fetch时候自动释放锁
- CURSOR STABILITY 允许事务做 对条目做:读-思考-写 这样的顺序操作,而不用关系其他事务的交叉操作
- SNAPSHOT ISOLATION:
- 事务开始时获得一个当前版本,后续的更新对其他事务不可见
- 主要是依靠 MVCC 来实现的,而不是锁,在支持SNAPSHOT ISOLATION的系统中,这些方案通常是共存的
- 当事务开始时,从单调递增的计数器中获得一个唯一的 start-timestamp,结束时从计数器中获取唯一的 end-timestamp
- 只有其他事务跟当前事务 开始-结束对没有重叠时,才会提交此事务
- READ CONSISTENCY:
- Oracle的MVCC定义,跟SNAPSHOT ISOLATION有轻微的不同
- 在Oracle方案中,每个SQL语句(单个事务中可能有多个SQL语句)看到的是该语句开始时最近提交的值
- 对于从游标获取的语句,游标集基于打开时的值
- 通过维护独立tuple的多个逻辑版本来实现,单个事务可能引用单个tuple的多个版本,而不是存储需要的每个版本
- Oracle只存储最新版本,如果需要获取老版本,则通过回滚undo log实现
- 修改是通过维护长期写锁实现的
- 当两个事务写同一个对象时,第一写获胜;第二个写则需要等待第一个写完成
- 对比,SNAPSHOT ISOLATION 是第一个提交获胜,而不是第一个写获胜
由于弱隔离级别可以提供更高的并发性,很多DBMS甚至默认就使用弱一致性
SQLServer默认使用了READ COMMITTED,缺点就是不能保证 ACID意义上的隔离性
开发人员需要知道这个模式的微妙原因,才能确保事务运行的正确性
由于这些微妙的语义定义,导致应用在多个DBMS之间迁移是很困难的
隔离级别相关论文:
《Granularity of locks and degrees of consistency in a shared data base》
《Generalized isolation level definitions》
Log Manager
日志管理的责任是维护提交事务的持久化,并促使终止事务的回滚,确保原子性,使系统从失败或非计划宕机中恢复
为提供这些特征,日志管理维护了磁盘上的日志记录序列,以及内存中的数据结构
为了支持crash之后的正确性,驻留内存的数据结构需要从日志和数据库的持久数据中,重新创建
数据库日志是一个极其复杂,非常细节的主题,数据库日志的正规引用论文是: ARIES
ARIES的论文不仅解释了日志记录协议,还提供了替代设计可能性的讨论,以及它们可能导致的问题
作为更易于理解的介绍,Ramakrishnan和Gehrke的教科书提供了基本ARIES协议的描述,没有附加讨论或改进
在这里,我们讨论恢复的一些基本思想,并试图解释教科书和期刊描述之间的复杂性差距。
标准的数据库恢复主题使用了Write-Ahead Logging (WAL)协议,它由三个非常简单的规则组成:
- 对数据库page的每次修改都会生成一个日志记录,日志记录会在page刷新之前写入日志设备
- 日志记录必须按顺序flush,如果
r之前的记录没有被flush,则r也不能flush - 在提交请求返回成功之前,必须先将日志记录fulsh到日志设备
很多人只想到了第一个规则,但这三种都是正确行为的必要条件
第一个规则确保:在事务终止时,不完整的事务行为可以被撤销,确保了原子性
规则二、三 是联合起来使用的,确保了持久性,在系统crash后如果其行为没有反应到数据库中,一个提交的事务行为可以被重做
考虑到这些简单的原则,高效的数据库日志记录是如此微妙和详细,这是令人惊讶的
然而,在实践中,由于对极限性能的需求,上述简单的故事变得复杂起来
挑战在于保证提交事务的“快速路径”中的效率
- 需要提供高性能的回滚,对于终止事务
- 在crash之后需要快速恢复
当添加特定于应用程序的优化时,日志记录会变得更加复杂,例如,为了支持只能增加或减少的字段(“托管事务”)的性能改进
为了最大户快速路径的速度,大多数商业系统提供了:DIRECT, STEAL/NOT-FORCE 操作
- 数据库对象原地更新
- unpinned的buffer pool帧可能被窃取(修改的数据页会写入磁盘),即使包含了未提交的数据
- 在提交请求返回给用户之前,不必将缓冲池页面“强制”(刷新)到数据库
这些策略将数据保存在DBA所选择的位置,并给予缓冲区管理器和磁盘调度器充分的自由度来决定内存管理和I/O策略,而无需考虑事务正确性
这些特性可以带来很大的性能优势,但需要日志管理器有效地处理 从终止事务中窃取的page刷新的微妙行为
并对在崩溃时丢失的已提交事务的no-force 页面重新进行更改
一些dbms使用的一种优化是将DIRECT、STEAL/NOT-FORCE系统的可伸缩性优势 与 DIRECT NOT-STEAL/NOT-FORCE系统的性能结合起来
在这些系统中,页面不会被窃取,除非缓冲池中已经没有干净的页面了,在这种情况下,系统将降级回STEAL策略,并增加上面所述的额外开销
另一种快速路径的挑战是:保持日志记录尽可能小,以便增加日志I/O的吞吐量
一个自然的优化是,记录日志逻辑操作,如:insert (Bob,$25000) into EMP
而不是物理操作:通过tuple插入所有的字节范围被修改,包括堆文件和索引块上的字节
这里需要做一个权衡,因为逻辑的undo redo操作可能会非常慢,可能会在事务终止和事务恢复期间,严重降低性能
在ARIES规则中
- 物理操作通常支持 REDO
- 逻辑操作通常支持 UDDO
在ARIES规则部分中,在恢复过程中重放历史,达到crash的状态,然后从这一点开始回滚事务
crash恢复需要在系统失败或者非人为宕机后恢复数据库到一致性状态
实现原理大致是:重放历史记录,然后从第一个日志记录一直到最近记录 逐步执行来实现的
这种技术是正确的,但是可能会很慢,因为日志可能会非常大,实际并不是从开始
而是从以下两个最老的记录开始恢复,得到正确结果的:
- 描述缓冲池中最早脏页的最早更改的日志记录
- 日志记录表示:系统中最老事务的开始,这个点的序列号称为恢复日志序列号(恢复LSN)
计算和恢复LSN会带来开销,因为恢复LSN是单调递增的,我们并不总是需要保持最新的,而是周期性的调用:checkpoint
checkpoint 将强制所有脏缓冲池页,然后计算并存储恢复LSN
对于较大的缓冲池,这可能会导致完成挂起页面的I/O的延迟数秒
因此,需要一种更有效的检查点“模糊”方案,以及通过处理尽可能少的日志来正确地将检查点提高到最近的一致状态的逻辑
ARIES使用了一种非常聪明的方案,其中实际检查点记录非常小,只包含足够的信息来启动日志分析过程,并支持重新创建在崩溃时丢失的主内存数据结构
在ARIES模糊检查点期间,计算恢复LSN,但不需要同步写入缓冲池页。使用一个单独的策略来确定何时异步写出旧的脏缓冲池页
注意,回滚将要求写入日志记录。这可能会导致困难的情况,即运行中的事务由于耗尽日志空间而无法继续进行,但它们也无法回滚
这种情况通常可以通过空间保留方案来避免,但是,随着系统经过多个版本的演进,这些方案很难获得和保持正确
事实上数据库不仅仅是磁盘page上的用户数据tuple集合,它也包含了各种物理信息,如管理内部的基于磁盘的数据结构,这使得日志任务和恢复更加复杂化
相关论文:
《Aries: A transaction recovery method supporting fine-granularity locking and partial rollbacks using write-ahead logging》
《Principles of transaction-oriented database recovery》
Locking and Logging in Indexes
索引是物理存储结构,用于访问数据库中的数据,素银本身对于数据库应用开发者来说是不可见的,除非它们提高了性能或强制了惟一性约束
开发人员和应用程序不能直接观察或操作索引中的条目
这允许通过更有效(和更复杂)的事务方案来管理索引
索引并发和恢复需要保持的唯一不变性是:索引总是从数据库中返回事务一致性的tuple
Latching in B+-Trees
关于这个问题,一个研究得很好的例子出现在B+树latch中。B+树由缓冲池访问的数据库磁盘页组成,就像数据页一样
因此,索引并发控制的一种方案是在索引页上使用两阶段锁
也就是说,每个事务都需要锁住B+树的root,直到提交才释放,这严重限制了并发
已经开发了各种基于latch的方案来解决这个问题,而不需要在索引页上设置任何事务锁
这些方案的关键点是修改树的物理结构(如spliting page)可以用非事务的方式进行,只要所有非并发事务继续在叶子处找到正确的数据
大致有三种实现方式:
- 保守的模式:
- 多个事务可以访问相同的page,只要能保证不发生冲突
- 一个读事务在遍历中间节点,此节点满了,而并发的插入事务操作下面的page,这可能导致split
- 保守的模式牺牲了太多的性能,跟下面的方案比差了很多
- latch耦合模式:
- 遍历逻辑在访问节点之前,先latch住,只有下一个节点被成功的latch住,才释放本节点的latch
- 这种模式也叫做:latch crabbing
- 这种抓住有点像移动holding树中的节点,先抓子节点,再释放父节点,如此重复
- 也有商业实现,IBM ARIES-IM
- ARIES-IM包括一些相当复杂的细节和极端情况——有时它必须在拆分后重新启动遍历,甚至设置(非常短期的)树级闩锁
- Right-link方案:
- 简单的增加一些结构到 B+树中,以便最小化latch和重新遍历
- 每个节点向其右手边节点增加一个链接
- 跟latch耦合不同,每个节点都是latch、read、unlatch
- 如果一个遍历事务跟随一个指针 指向节点n, 发现n 在中间被分割了
- 遍历事务可以检测到这一点,通过right-link找到树中新节点的正确位置,通过右链接向右移动
- 有些系统也支持back-link,支持反向遍历
Kornacker等人[46]详细讨论了锁锁耦合和右链接方案之间的区别,并指出锁锁耦合只适用于B+-树,而不适用于更复杂数据的索引树,例如,没有单一线性顺序的地理数据
PostgreSQL通用搜索
树(GiST)的实现基于Kornacker等人的可扩展右链接方案
Logging for Physical Structures
除了特殊情况并发逻辑之外,索引还使用特殊情况日志逻辑
这种逻辑使得日志记录和恢复更加有效,但代价是增加了代码的复杂性
其主要思想是,在关联事务中止时不需要撤消结构索引更改,这样的更改通常对其他事务所看到的数据库tuple没有影响
比如,B+树page在插入事务执行中被split,而后事务被终止;在中止处理期间,不迫切需要撤消split
这就提出了将一些日志记录标记为 redo-only 的挑战,在日志的任何undo处理过程中,都可以保留redo-only的更改
ARIES为这些场景提供了一种优雅的机制,称为nested top actions,它允许恢复过程在恢复期间“跳过”物理结构修改的日志记录,而不需要任何特殊情况代码
在其他上下文中也使用了相同的思想,包括堆文件,插入堆文件可能需要在磁盘上扩展该文件 为了捕获这个,必须对文件的extent map.进行更改,这是磁盘上的一个数据结构,指向构成文件的连续块的运行 如果插入事务终止,则不需要撤消对区段映射的这些更改 文件变大这一事实是事务不可见的副作用,实际上可能有助于吸收未来的插入流量
Next-Key Locking: Physical Surrogates for Logical Properties
现在接近本章的最后了,讨论索引并发问题,这是一个不易差距但是非常重要的问题
这个挑战是提供完全串行化,包括预防幻读问题,允许tuple级别的锁和索引使用,这个技术 只应用于完全的串行化,对于宽松的隔离模式不需要
当事务通过索引访问tuple时,就可能出现幻读问题
- 事务不会锁住整个表
- 只是锁住表中通过索引访问的tuple,比如:“Name BETWEEN ‘Bob’ AND ‘Bobby’
- 由于没有表级别锁,另一个事务可以插入新tuple到表中,如Name=‘Bobbie’
- 新插入的值落入到查询谓词的值范围中,后续通过谓词访问就会出现
- 幻读问题涉及数据库tuple的可见性,因此是lock问题,而不是latch问题
原则上,需要某种方式 锁住原始查询谓词 表示的逻辑空间,比如字典顺序 落在 Bob 和 Bobby之间的的所有可能的strings范围
但是这样的代价太大了,因此需要以某种方式比较 任意的谓词的重叠,基于hash的锁表不能实现这一点
对于幻读问题,一个通用的解决方案是: next-key locking
In next-key locking,这了要修改索引的插入逻辑,索引键 k 的tuple的插入,必须在 索引中存在的下一个键的tuple上分配一个排斥锁,下一个tuple的最小key大于 k
该协议确保后续插入不会出现在之前返回给活动事务的两个元组之间;它还确保元组不能插入到前面返回的最低键元组的下面
例如,如果在第一次访问中没有找到“Bob”键,那么在同一事务中的后续访问中就不应该找到“Bob”键
还有一种情况,将tuple插入到前面返回的最高键tuple之上,为了防止这种情况,下一个键锁定协议要求读事务在索引中的下一个键元组上也获得共享锁
在此场景中,next-key tuple是不满足查询谓词的最小键tuple,更新在逻辑上表现为删除后插入,尽管优化是可能的,也是常见的
Next-key locking定虽然有效,但会受到过度锁定的影响,这在某些工作负载下可能会出现问题
比如,扫描的范记录时从 key 1 到 10,但是被索引的列只存储了key 1、5、100
整个范围1 - 100都会被读lock,因为100是 10的next key
一键锁定不仅仅是一个聪明的hack。这是一个使用物理对象(当前存储的元组)作为逻辑概念(谓词)代理的示例
这里的好处是,简单的系统基础结构如 基于hash的锁表,只需要修改锁协议,就可以用于更复杂的目的
复杂软件系统设计者可以保持这种逻辑代理的通用方式(在他们的技能包中),当语义信息可用时
相关论文:
《Concurrency and recovery in generalized search trees》
Interdependencies of Transactional Storage
在这一章的早期,我们说过事务存储系统是单体的,深度缠绕的系统
在这里我们讨论在 事务存储系统中的三个主要概念的一些交互性:
- 并发控制
- 恢复管理
- 访问方式
在一个更美好的世界里,可以在这些模块之间识别狭窄的api,从而允许这些api背后的实现是可交换的
我们在本节中的例子表明,这并不容易做到。我们不打算在这里提供一个详尽的相互依赖性列表;生成和证明这样一个列表的完整性将是一项非常具有挑战性的工作
不过,我们确实希望阐明事务性存储的一些扭曲逻辑,从而证明由此产生的商业整体实现是正确的
我们首先只考虑并发控制和恢复,而不考虑访问方法的进一步复杂性
即使是这样的简化,组件仍然是紧密交织在一起的
并发性和恢复之间关系的一个表现形式是,预写日志对锁定协议进行了隐式假设。预写日志需要严格的两阶段锁,在非严格两阶段锁的情况下将无法正确操作
要了解这一点,要考虑在取消事务的回滚期间发生了什么
恢复代码开始处理被终止事务的日志记录,undoing其修改。通常,这需要更改事务之前修改的page 或tuple
为了进行这些更改,事务需要在这些页面或元组上拥有锁。在非严格的2PL方案中,如果事务在中止前丢弃任何锁,它可能无法重新获得完成回滚过程所需的锁
访问方法使事情更加复杂。采用教科书式的访问方法算法(例如,线性哈希[53]或r树[32])并在事务系统中实现一个正确的、高并发的、可恢复的版本,这是一个重大的智力和工程挑战
由于这个原因,大多数主流dbms仍然只实现堆文件和B+树作为事务保护的访问方法;PostgreSQL的GiST实现是一个明显的例外
正如我们前面为B+-树演示的那样,事务性索引的高性能实现包括用于锁定、锁定和日志记录的复杂协议。
严肃的dbms中的B+树充满了对并发性和恢复代码的调用
即使是访问模式像堆文件这也的,也需要棘手的并发控制和恢复围绕在其描述的内容(区段map)
这些逻辑不是对 所有访问方式通用,对于访问方式的特殊逻辑,它的特定实现都是非常定制化的
访问方法中的并发控制只在面向锁定的方案中得到了很好的发展。
其他并发方案(例如,乐观或多版本并发控制)通常根本不考虑访问方法,或只以随意和不切实际的方式提及它们[47]。因此,为给定的访问方法实现混合和匹配不同的并发机制是很困难的
访问方法中的恢复逻辑特别与系统相关:访问方法日志记录的时间和内容依赖于恢复协议的细节,包括结构修改的处理(例如,在事务回滚时它们是否被撤销,如果不能,如何避免),以及物理和逻辑日志的使用
即使对于像B+-树这样的特定访问方法,恢复和并发逻辑也是交织在一起的。在一个方向上,恢复逻辑依赖于并发协议:如果恢复管理器必须恢复树的物理一致状态,那么它需要知道可能会出现什么不一致的状态,用日志记录适当地括住那些状态,以实现原子性(例如,通过嵌套的顶部操作)
相反,访问方法的并发协议可能依赖于恢复逻辑。例如,B+-树的右链接方案假设树中的page在split之后永远不会重新合并;这一假设要求恢复方案使用一种机制,如嵌套顶部操作,以避免撤销由中止事务生成的split
这里也有一个亮点,就是buffer管理和存储管理的剩余组件之间隔离性做的比较好
只要页面被正确固定,缓冲区管理器就可以自由封装其逻辑的其余部分,并根据需要重新实现它
例如,缓冲区管理器可以自由选择要替换的页面(由于STEAL属性)和调度页面刷新(由于NOT FORCE属性)。当然,实现这种隔离是并发性和恢复中许多复杂性的直接原因。所以这个点可能没有看起来那么亮
Standard Practice
现在所有的生产数据库都支持ACID事务。作为一种规则,它们使用WAL以保证持久性,而使用两阶段锁定来实现并发控制
PG是例外,它始终使用MVCC的,Oracle率先将锁和有限的MVCC一起使用,并提供了一种宽松的一致性模型,类似:Snapshot Isolation 、Read Consistency
这些模式在用户中很流行,所以很多数据库厂商都采用了,而Oracle中是默认的
B+树索引在所有数据库中都是标准的,大多数商业数据库都提供了多维索引,通过内嵌或者插件的方式提供
只有PostgreSQL通过其GiST实现提供了高并发的多维和文本索引
MySQL的独特之处是,底层支持各种存储引擎,DBA可以在相同库的不同表中使用不同的引擎
默认是MyISAM,只支持表级别锁,对于读模式的高性能场景来说不错
对于读写场景,则使用InnoDB引擎,它提供行级别锁,几年前被Oracle收购,不过目前仍然是开源的
两个MySQL存储引擎都不提供为System R[29]开发的著名的分层锁定方案,尽管它在其他数据库系统中得到普遍使用
这样的话选择这两个引擎就比较困难,在一些混合工作负载的情况下,这两个引擎都不能提供良好的锁粒度
这要求DBA开发一个使用多个表和/或数据库复制的物理设计,以支持扫描和高选择性索引访问
mysql也支持内存和集群的存储引擎,一些第三方厂商宣称支持mysq兼容的存储引擎,不过大多数用于还是选择myisam或者innodb
Discussion and Additional Material
事务机制如今是一个非常成熟的话题,多年来各种可能的技巧都被一种或另一种方式尝试过,新的设计方案趋向于:基于现有方案的 排列组和或者联合使用
这一领域最大的变化是内存价格下降,于是产生了这样的动机:把数据库中大部分热数据放到内存中加速运行
这使的经常将数据flush到持久设备以保持更低的重启时间的挑战更复杂
闪存在事务管理中的作用是这种不断发展的平衡行为的一部分
这些年一个有趣的发展是,OS圈子内广泛的采用了WAL机制,通常是文件日志系统,今天基本是所有OS系统的标准选项了
因为这些文件系统是不支持文件数据上的事务,那么他们如何使用WAL得到持久性和原子性就很有意思了
有兴趣的读者可参考[62,71]进一步阅读。另一个有趣的方向是关于停滞的工作
[78],它试图更好地模块化aries风格的日志记录和恢复,并使其可供系统程序员广泛使用
Shared Components
这一章节介绍各种共享的组件,他们几乎出现在所有的DBMS中,但是文件中却很少谈论
Catalog Manager
数据库的cataog会持有系统中关于数据的信息,这是元数据的一种形式
catalog记录系统中基本条目的名字(比如users, schemas, tables, columns, indexes等等),以及他们的关系
它本身是当做数据库中的一系列表来存储的,通过将元数据保持与数据相同的格式
使用这种方式可以很大程度上简化使用:
- 用户可以使用相同的语言和工具来探索元数据,就跟普通数据差不多
- 内部系统的代码,对于管理元数据跟管理普通数据 大体差不多
这种代码和语言级别的重用,在早起阶段经常被忽视,因而是一个重要教训,开发人员通常会感到很后悔
其中一位作者在过去十年的工业环境中再次见证了这个错误
因为效率原因,基本的catalog数据和普通表在处理上会有一些不同
为了应对大量访问,需要将catalog驻留在内存中,数据结构也是非规范化存储的,将catalog这种关系化的结构变成内存对象的网络
内存中这种缺乏独立性的结构是可行的,因为这种结构只是被查询解释器、优化器使用
额外的catalog数据在解析时缓存到查询计划中,同样通常以适合查询的非规范化形式存在
catalog中的表需要用特殊的事务技巧来最小化事务处理中的热点问题
catalog在商业应用中可以变得异常庞大
例如,一个主要的Enterprise Resource Planning应用程序有60,000多个表,每个表有4到8列,每个表通常有2到3个索引
Memory Allocator
传统教科书上,对于内存管理主要趋向于buffer pool,但实际上,DBMS也会给其他任务分配大量内存
正确的内存管理既是编程负担,也是性能问题
Selinger风格的查询优化会使用大量的内存,如在动态规划期间建立状态
查询操作如hash-join和排序也会在运行期间分配大量内存
通过使用 基于上下文的内存分配器,可以使商业系统中的内存更加高效和便于调试
内存上下文是一个内存的数据结构,它维护了一个连续的虚拟内存区域列表,也叫做:内存池
每个区域都有一个小的头部,它包含了:一个上下文标签、或者指向上下文头部的结构
内存上下的基本API包括:
- Create a context with a given name or type
- 这个上下文类型被告知分配器,如何高效的处理内存分配
- 查询优化器上下文需要分配一个小的增量
- 而hash join需要分配大批量内存
- 基于这些知识,分配器可以选择一次分配更大或者更小的区域
- Allocate a chunk of memory within a context.
- 这个分配会返回一个指针到内存,非常类似传统的malloc()
- 该内存可能来自上下文中的现有区域。或者,如果任何区域都不存在这样的空间
- 分配器会告诉OS,分配一个新的内存区域并标记它,然后链接到上下文
- Delete a chunk of memory within a context
- 这可能会导致上下文删除相应的区域,也可能不会
- 从内存上下文中删除有些不寻常,一个更典型的行为是删除整个上下文
- Delete a context
- 这首先释放与上下文关联的所有区域,然后删除上下文head
- Reset a context.
- 这将保留上下文,但将其返回到最初创建的状态,通常是通过释放以前分配的所有内存区域
内存上下文提供了重要的软件工程优势。最重要的一点是,它们可以作为较低级别的、由程序员控制的垃圾收集替代方案
例如,编写优化器的开发人员可以在优化器上下文中为特定查询分配内存,而不必担心以后如何释放内存。当优化器选择了最佳计划后,它可以将计划从查询的单独执行器上下文中复制到内存中,然后简单地删除查询的优化器上下文中
这省去了编写代码仔细遍历所有优化器数据结构并删除它们的组件的麻烦。它还避免了这类代码中可能由错误引起的棘手的内存泄漏。该特性对于查询执行的自然“分阶段”行为非常有用,其中控制从解析器进行到优化器再到执行器,每个上下文中都有一些分配,然后删除上下文
注意,内存上下文实际上比大多数垃圾收集器提供了更多的控制,因为开发人员可以控制回收的空间和时间局部
上下文机制本身提供了空间控制,允许程序员将内存分离为逻辑单元。时间控制源自程序员在适当的时候被允许发布上下文删除
相比之下,垃圾收集器通常处理程序的所有内存,并自己决定何时运行。这是尝试用Java编写服务器质量代码的一个问题
在malloc()和free()开销相对较高的平台上,内存上下文也提供了性能优势
特别是,内存上下文可以使用关于如何分配和释放内存的语义知识(通过上下文类型),并可以相应地调用malloc()和free()以最小化操作系统开销
数据库系统的一些组件(例如解析器和优化器)分配大量的小对象,然后通过上下文删除一次性释放它们。在大多数平台上,调用free()许多小对象是相当昂贵的。内存分配器可以调用malloc()来分配大的区域,并将得到的内存分配给它的调用者
相对缺乏内存释放意味着不需要malloc()和free()使用的压缩逻辑。当删除上下文时,只需要几个free()调用就可以删除大区
感兴趣的读者可能想要浏览开放源码的PostgreSQL代码。这利用了一个相当复杂的内存分配器
A Note on Memory Allocation for Query Operators
对于空间密集型操作如hash join,sort,供应商在他们的内存分配模式的概念上有差别
一些系统(例如,DB2 forzSeries)允许DBA控制这些操作将使用的RAM数量,并确保每个查询在执行时都获得相应的RAM数量
准入控制策略确保了这一保证。在这样的系统中,算子通过内存分配器从堆中分配它们的内存。这些系统提供了良好的性能稳定性,但迫使DBA(静态地)决定如何在各种子系统(如缓冲池和查询操作符)之间平衡物理内存
其他系统(例如,MS SQLServer)从DBA手中接管了内存分配任务,并自动管理这些分配。这些系统试图在查询执行的各个组件之间智能地分配内存,包括缓冲池中的页面缓存和查询操作符内存使用
用于所有这些任务的内存池就是缓冲池本身
因此,这些系统中的查询算子,通过DBMS实施的内存分配器,从buffer pool中获取内存,对于连续请求 大于缓冲池的page,使用OS分配器
这种区别与我们在6.3.1节中对查询准备的讨论相呼应。前一类系统假设DBA参与复杂的调优,并且系统的工作负载能够接受对系统内存“按钮”的精心选择的调整
这种区别与我们在6.3.1节中对查询准备的讨论相呼应。前一类系统假设DBA参与复杂的调优,并且系统的工作负载能够接受对系统内存“按钮”的精心选择的调整
在这些条件下,这样的系统应该总是表现良好
后一类假设DBA没有或不能正确设置这些按钮,并试图用软件逻辑替换DBA调优
它们还保留自适应地改变其相对分配的权利。这为不断变化的工作负载提供了更好的性能
说明了这些供应商希望如何使用他们的产品,以及他们的客户的管理专业知识(和财务资源)
Disk Management Subsystems
DBMS教科书倾向于将磁盘视为同构对象。实际上,磁盘驱动器是复杂且异构的硬件部件,它们的容量和带宽相差很大。因此,每个DBMS都有一个磁盘管理子系统来处理这些问题,并管理表分配,以及其他的跨原始设备、逻辑卷、文件的存储单元
该子系统的一个职责是将表映射到设备和/或文件。表到文件的一对一映射听起来很自然,但在早期的文件系统中引发了严重的问题
- 操作系统文件传统上不能大于一个磁盘,而数据库表可能需要跨越多个磁盘
- 分配太多的系统fd会很糟糕,OS会有限制,许多用于目录管理和备份的操作系统实用程序不能扩展到非常大的文件数量
最后,许多早期的文件系统将文件大小限制为2 GB。这显然是一个无法接受的小表限制。许多DBMS供应商使用原始IO完全绕过OS文件系统,而其他供应商则选择绕过这些限制。因此,所有主要的商业DBMS都可能将一个表分散到多个文件中,或者将多个表存储在一个数据库文件中。随着时间的推移,大多数操作系统文件系统已经超越了这些限制。但是遗留的影响仍然存在,现代dbms仍然典型地进行处理 操作系统文件作为抽象存储单元,可以任意映射到数据库表
更复杂的是处理维护时间和空间控制的设备特定细节的代码,如第4节所述。当今存在着一个庞大而充满活力的行业,其基础是“假装”为磁盘驱动器的复杂存储设备 但实际上是大型硬件/软件系统,其API是遗留的磁盘驱动器接口
SCSI。这些系统包括RAID系统和存储区域网络(SAN)设备往往具有非常大的容量和复杂的性能特征
管理员喜欢这些系统,因为它们很容易安装,而且经常提供容易管理的、比特级的可靠性和快速故障转移。这些特性为客户提供了一种显著的舒适感,超越了DBMS恢复子系统的承诺。例如,大型DBMS安装通常使用SANs
不幸的是,这些系统使DBMS实现复杂化
例如,RAID系统在出现故障后的表现与所有硬盘都正常工作时的表现非常不同
这可能会使DBMS的I/O成本模型复杂化。有些磁盘可以在启用写缓存的模式下运行,但这可能会在硬件故障期间导致数据损坏。先进的san实现了由电池支持的大型缓存,在某些情况下接近1tb,但这些系统带来了远远超过100万行的微码和相当大的复杂性。随着复杂性的增加,出现了新的故障模式,这些问题很难检测和正确诊断
RAID系统在数据库任务上表现不佳,这也使数据库设计人员感到沮丧。RAID是为面向字节流的存储(如UNIX文件)而设计的,而不是数据库系统所使用的面向页面的存储
和跨多个物理设备的分区和复制数据的DBMS方案对比,RAID设备的性能就比较差了
例如,Gamma[43]的链式聚类方案与RAID的发明大致一致,在DBMS环境中性能更好。
而且,大多数数据库提供DBA命令来控制跨多个设备的数据分区,但是RAID设备通过将多个设备隐藏在一个接口后面
许多用户将他们的RAID设备配置为最小化空间开销(“RAID级别5”),而如果通过磁盘镜像(“RAID级别1”)等更简单的方案,数据库的性能会好得多。RAID级别5的一个特别令人不快的特性是写性能很差。这可能会给用户带来意想不到的瓶颈,而DBMS供应商通常要负责解释或提供这些瓶颈的解决方案。无论好坏,RAID设备的使用(和误用)是商业dbms必须考虑的一个事实。因此,大多数供应商都要花费大量的精力
在过去十年中,大多数客户部署都将数据库存储分配给文件,而不是直接分配给逻辑卷或原始设备。 但是大多数dbms仍然支持原始设备访问,并且在运行大规模事务处理基准测试时经常使用这种存储映射。而且,尽管上面列出了一些缺点,大多数企业DBMS存储现在都是san托管的
Replication Services
通常需要通过定期更新在网络中复制数据库。这经常用于额外程度的可靠性:复制的数据库充当稍微过时的“热备用”,以防主系统出现故障。在一个物理上不同的位置保持温暖的待机状态有利于在火灾或其他灾难后继续工作
复制还经常用于为大型、地理上分布的企业提供一种实用形式的分布式数据库功能
大多数这样的企业将其数据库划分为较大的地理区域(例如,国家或大陆),并在数据的主副本上本地运行所有更新
查询有两种选择,可以继续在主副本上查询,也可以在远程副本上查询,不过可能会有轻微的过时
忽
略硬件技术(例如EMC SRDF),使用了三种典型的复制方案,但只有第三种方案提供了高端设置所需的性能和可伸缩性。当然,它是最难实现的
- Physical Replication
- 最简单方式,每个复制周期都物理的复制整个数据库
- 这个模式不能扩展到很大的规模,因为需要发送大量数据,并在远端重建
- 此外,保证数据库的事务一致性快照是棘手的
- 因此,物理复制仅在低端用作客户端解决方案,大多数供应商不鼓励通过任何软件支持这种方案
- Trigger-Based Replication
- 触发器被放置在数据库表上,对于任何修改操作都会关联到触发器
- 触发器将数据记录另一个表上,这个表可以是远程表,然后在远程重放
- 这个方案解决了(1),但是某些场景下会带来很大的性能问题
- Log-Based Replication
- 基于日志的复制方案一般是首选
- 这里有一个日志嗅探进程会拦截日志写入,然后将其交付到远程系统
- 远程系统一般有两种选择
- 读取日志并构建出SQL语句,然后针对目标系统重放
- 读日志记录然后传送他们到远端系统
- 它处于永久恢复模式,在日志记录到达时重新播放
- 这两种机制都有价值,所以Microsoft SQL Server、DB2和Oracle都实现了这两者。SQL Server调用第一个日志发送,第二个数据库镜像
该方案克服了之前备选方案的所有问题:开销低,对运行系统造成的性能开销最小或不可见;它提供增量更新,因此可以随数据库大小和更新速率优雅地扩展;它重用了DBMS的内置机制,而没有显著的额外逻辑;最后,它通过日志的内置逻辑自然地提供事务一致性副本。
大多数主要供应商为自己的系统提供基于日志的复制。提供跨供应商工作的基于日志的复制要困难得多,因为在远程端驱动供应商重播逻辑需要理解该供应商的日志格式
Administration, Monitoring, and Utilities
每个DBMS都提供一系列的工具用于管理系统,这些工具很少提供基准,但是提供了支配管理系统的能力
大多数主要供应商为自己的系统提供基于日志的复制。提供跨供应商工作的基于日志的复制要困难得多,因为在远程端驱动供应商重播逻辑需要理解该供应商的日志格式
凌晨时分传统的“重组窗口”通常不再可用。因此,大多数供应商近年来在提供在线公用事业方面投入了大量精力。我们在这里简要介绍一下这些实用程序:
- Optimizer Statistics Gathering
- 每个主要的DBMS都有一些方法来扫描表并构建这样或那样的优化器统计信息
- 一些统计数据,比如直方图,在不占用内存的情况下,一次就可以构建
- 例如,参见Flajolet和Martin关于计算列中不同值的数量的工作[17]
- Physical Reorganization and Index Construction
- 随着时间推移访问方式可能变得低效,因为插入、删除导致了一些无效的空间
- 用户希望偶尔的重新组织这些表(后台)
- 比如在不同列上重建聚集索引,或跨多个磁盘重建分区
- 在线重新组织文件和索引很麻烦,因为要持有锁很长时间,以维护物理的一致性
- 在这个意义上,它与用于索引的日志记录和锁定协议有一些相似之处,如第5.4节所述。这已经成为几篇研究论文[95]和专利的主题
- Backup/Export
- 所有DBMS都支持将物理数据库dump到备份存储中
- 同样,由于这是一个长期运行的流程,所以它不能简单地设置锁
- 相反,大多数系统执行某种“模糊”转储,并使用日志逻辑对其进行扩充,以确保事务一致性
- 可以使用类似的方案将数据库导出为交换格式
- Bulk Load
- 在许多场景中,需要将大量数据快速地输入数据库
- 供应商提供了针对高速数据导入优化的批量加载实用程序,而不是每次插入一行
- 通常,存储管理器中的自定义代码支持这些实用程序
- 例如,用于B+-树的特殊批量加载代码比重复调用树插入代码要快得多
- Monitoring, Tuning, and Resource Governers
- 即使在受管理的环境中,查询消耗的资源多于所需的资源也是很正常的
- 因此多数DBMS提供了一个工具来辅助DBA来识别这一类的问题
- 通常提供一个类似SQL的接口,通过虚拟表去DBMS查看性能
- 比如显示系统状态的临时故障(查询导致的),或者死锁的资源,内存,临时存储空间等
- 在某些系统中,还可以查询这些数据的历史日志
- 许多系统允许在查询超过某些性能限制(包括运行时间、内存或锁获取)时注册警报
- 在某些情况下,警报的触发可能导致查询中止
- 最后,像IBM的预测性资源调控器这样的工具试图完全阻止资源密集型查询的运行
Conclusion
从本论文中可以看到,现代商业数据库系统有基于学术研究,也有为高端客户开发工业产品的经验
编写和维护一个高性能、全功能的关系型数据库,如果是从零开发,则需要在时间和精力上巨大投入
但是,关系dbms的许多经验可以转化为新的领域。Web服务、网络附属存储、文本和电子邮件存储库、通知服务和网络监视器都可以从DBMS的研究和经验中受益
数据密集型服务 如今是计算的核心,数据库系统设计的知识 也是一个被广泛应用的技能
无论是在数据库圈子内或者圈子外
新的方向也为数据库管理领域抛出了一些研究问题,并未数据库社区和其他计算领域的交互指出了道路
Reference
- Oracle RAC技术简介
- Architecture of a Database System阅读
- Access path selection in a relational database management system
paper
- System R优化器(1979年的一篇著名论文):《Access path selection in a relational database management system》
- 查询优化的圣经 《Access path selection in a relational database management system》
- 《Optimization of parallel query execution plansin xprs》
- 《Query evaluation techniques for large databases》
- 《Encapsulation of parallelism in the volcano query processing system》
- 《Improved query performance with variant indexes》
- 《An overview of data warehousing and olap technology》
- 《Performance tradeoffs in read-optimized databases
- 《C-store: A column oriented dbms》
- 《One size fits all: An idea whose time has come and gone》
- 《Rethink the sync》
- 《Analysis and evolution of journaling file systems》
- 《Statis: Flexible transactional storage》