关于云环境中多租户问题的论文
Multi-Tenant Cloud Data Services: State-of-the-Art, Challenges and Opportunities
https://web.archive.org/web/20220614215931/https://dl.acm.org/doi/pdf/10.1145/3514221.3522566
背景
通过大量企业上云之后,所带来的架构上的挑战
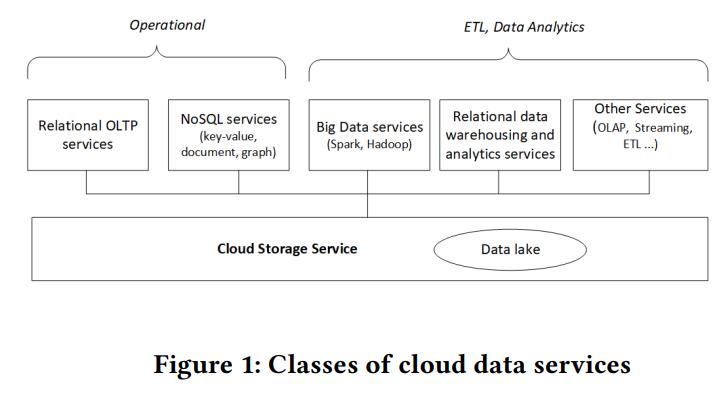
先看下数据库的分类
- OLTP类型的包括:Amazon Aurora、Azure SQL Hyperscale、Google Cloud Spanner
- NoSQL包括:Google BigTable、Amazon Dynamo DB、Azure Cosmos DB、MongoDB AtlasApache Cassandra
- 数据分析: AWS Redshift、Azure Synapse、Google BigQuery、Snowflake、基于Spark的Databricks
- 剩下的包括OLAP:如Amazon Athena;ETL等等
目前有三个挑战:
- disaggregation,存储和计算分离的架构
- multi-tenancy,共享资源需要解决的问题
- serverless,不需要预定资源,随用随付费
所以,除了高性能、高可用、扩展性之外,serverless也是一个很大的挑战
分析
首先架构是要根据数据中心而变化的,还要考虑到 zone、region这些因素
因此所有类型的数据库都需要考虑到存储计算分离
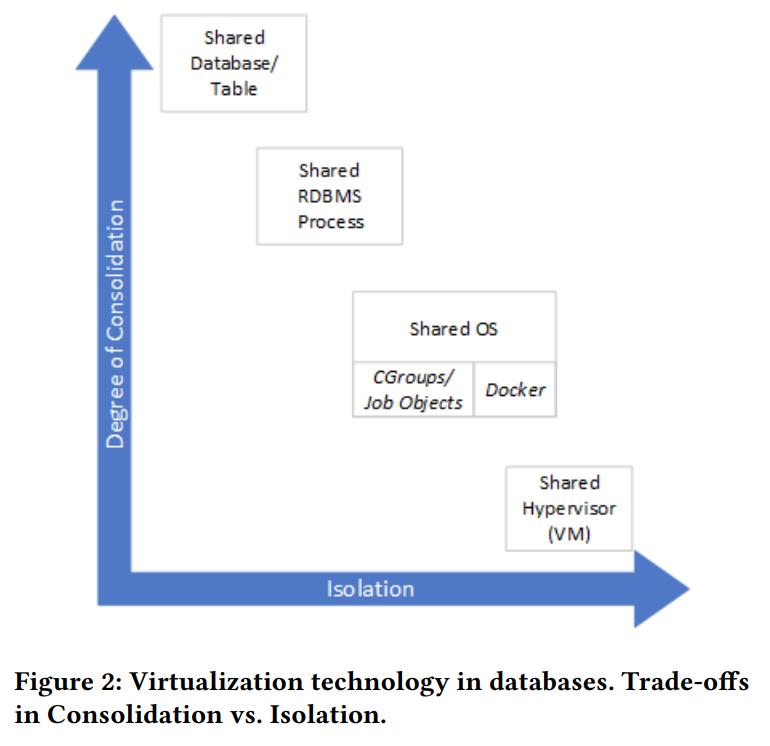
Multi-Tenancy
- 这里需要考虑到 隔离 vs 整合
- 整合程度越高,也就是虚拟化stack越高,其便捷性越好,价格也更低
- 而隔离程度高,意味着更安全,性能也更好,但是价格会更贵
- 此外还需要考虑到故障失败(计划和非计划的,软硬件)对租户的影响
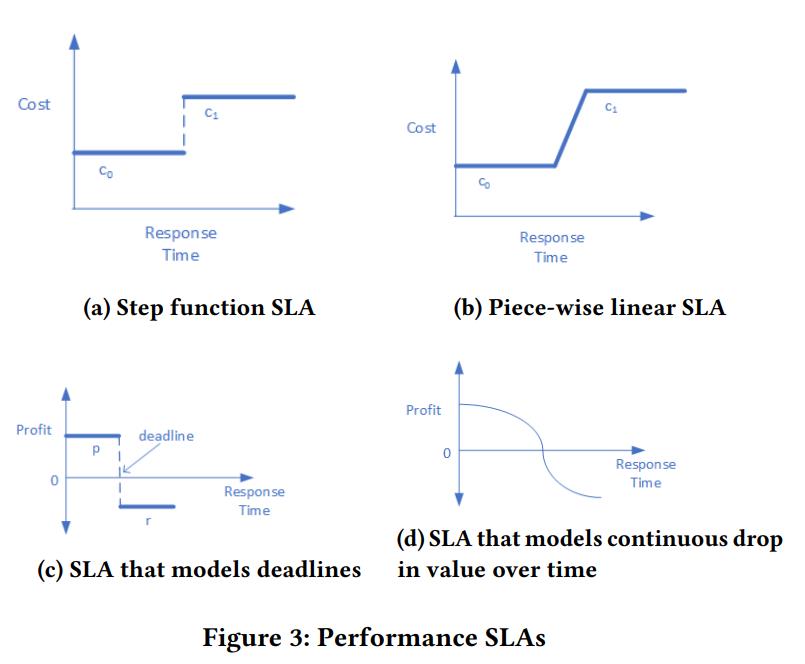
Quality of Service and Pricing Models
- 老的场景下客户自己搭建网络、机器,这时候服务质量、SLA基本都能确定
- 但在云环境中因为共享资源这可能就不是一个固定值了
- 一般云厂商会提供 可用性保证,而端到端的吞吐量、延迟这些一般不提供保证,API也有限制
- 如果想获得更高的服务质量,那就需要预定资源,这样价格也就更高
- 厂商也推出了定价、以及抢占模式,可以让客户买到更低价格的机器,只是更没有质量保证
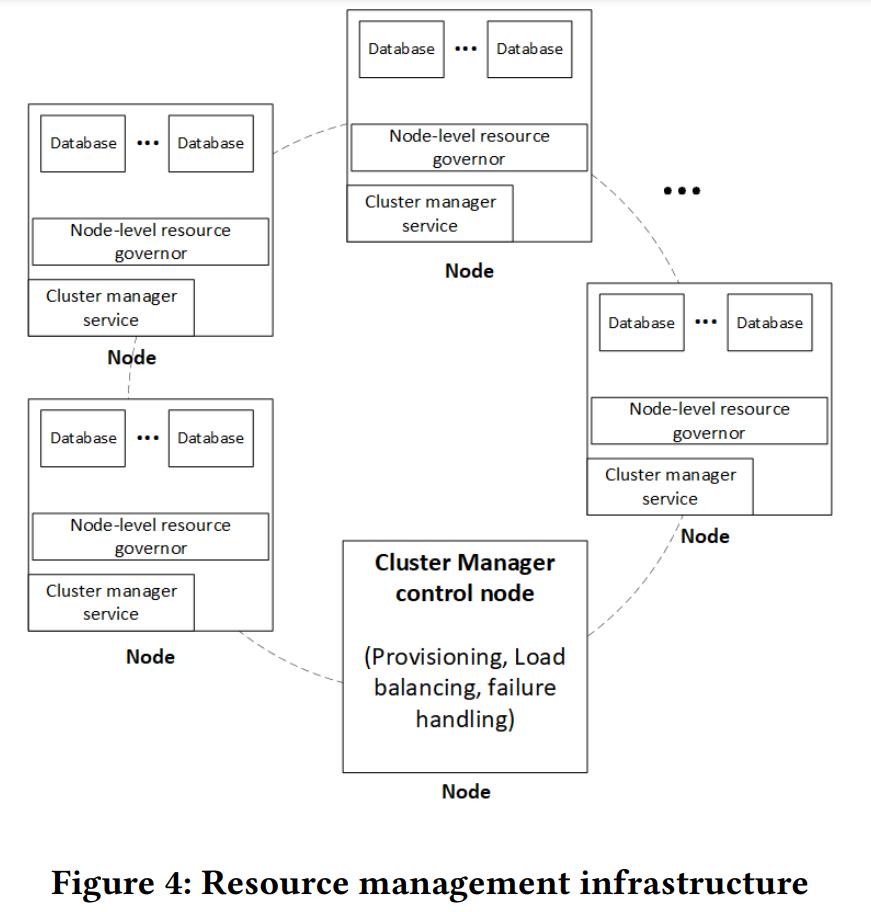
Multi-Tenant Resource Management
- 这里需要两种技术 cluster manager 、 node-level resource governor.
- cluster manager,类似Kubernetes,根据需要给数据库相应的资源,并且处理失败的节点,做资源平衡迁移等
- node-level resource governor,用来防止某个数据库抢占了太多的资源,这里需要资源评估技术,对于分析性、机器学习场景需要的评估技术也不同
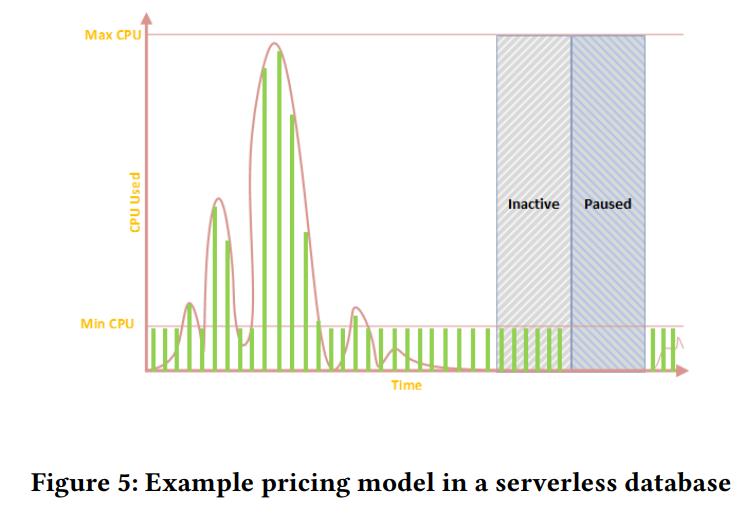
Serverless Databases
- 这几年学术界、工业界的热门话题
- 对于客户来说,可以提供更大的弹性,更低的成本
- 如下图,在不使用的时,完全都不计费了
挑战和开放性问题
Disaggregation
- 除了存储和计算分裂之外,现在还在研究CPU的扩展和内存之间的分离是否有益
- 另一个是组件之间的解耦,比如Snowflake的多租户模型,将元数据和查询处理当做单独组件做了隔离
- Azure SQL Hyperscale使用了独立的日志、缓存组件
- 这种功能性的分解,可能会影响未来的架构
Caching
- 存储计算分离带来的问题就是计算性能的下降,因此需要增加缓存层
- 而缓存层则带来了成本问题,需要在成本和性能之间做权衡
- 另外还要考虑到缓存的多租户问题
- 缓存的动态迁移,以及数据库动态迁移(自动、更快的能提升体验)是未来的工作重点
Optimizing Use of Cloud Services
- 云厂商有很多服务,每种服务有不同的定价模式
- 还有包含预定资源、无服务、枪占式的,这几个定价模式差别很大
- 对于CRM、ERP厂商来说,他们的服务本身就是基于云的,所以会带来很大挑战,而这也是基于
- 比如分析性应用:用更便宜的架构买下更多的抢占式的机器,但又能提供高可靠保证,则很吸引人
Auto Tuning
- 云环境中,因为有多少不同的机器型号,不同的数据库所以自动调优就更重要
- 比如对于数据库所运行的特定机器,校准查询优化的成本
- 自动调优可以基于 A/B测试的方式来运行评估,这样也不会影响实际使用
Impact of new hardware
- RDMA,远程版本的DMA,本地应用可以绕过CPU和网络栈,直接读远程机器内存,远程机器也不消耗CPU
- 其他如FPGAs、GPU、NVRAM 这些会很大程度上改变软件栈
- 比如说,RDMA就使远程内存访问更高效,所以跨节点共享资源就更容易,也能加速查询处理
- 同样访问远程缓存,以及本地SSD这种延迟比列在降低,对存算分离更有利
- 如果NVRAM被用于数据库,那么获得的优势就更大
Resource Estimation
- 相关的研究很多,但是真正使用的并不多,主要是缺乏鲁棒性
- 而云数据库可以收集大量的资源使用情况,甚至对立的查询
- 对于ad-hoc,快速变化或不可变的数据集很有用
参考
这篇论文参考的文献非常多,170+,这里先列出一些感兴趣的
- Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases
- Spanner: Becoming a SQL System
- Consistency Tradeoffs in Modern Distributed Database System Design
- Oracle Multitenant - White Paper
- Multi-Resource Packing for Cluster Schedulers
- CPU Sharing Techniques for Performance Isolation in Multi-tenant Relational Database-as-a-Service
- Sharing Buffer Pool Memory in Multi-Tenant Relational Database-as-a-Service
- Service fabric: a distributed platform for building microservices in the cloud
- POLARIS: The Distributed SQL Engine in Azure Synapse
- Amazon Athena
- Amazon Aurora Serverless
- Azure SQL Database serverless
- BigQuery
相关论文:
- Resource Sharing for Multi-Tenant NoSQL Data Store in Cloud 2016
- Cloud Data Services: Workloads, Architectures and Multi-Tenancy 2021
- An Updated Performance Comparison of Virtual Machines and Linux Containers