MySQL文件存储结构
InnoDB Architecture
总体上是分为磁盘上的数据结构,以及内存中的数据结构
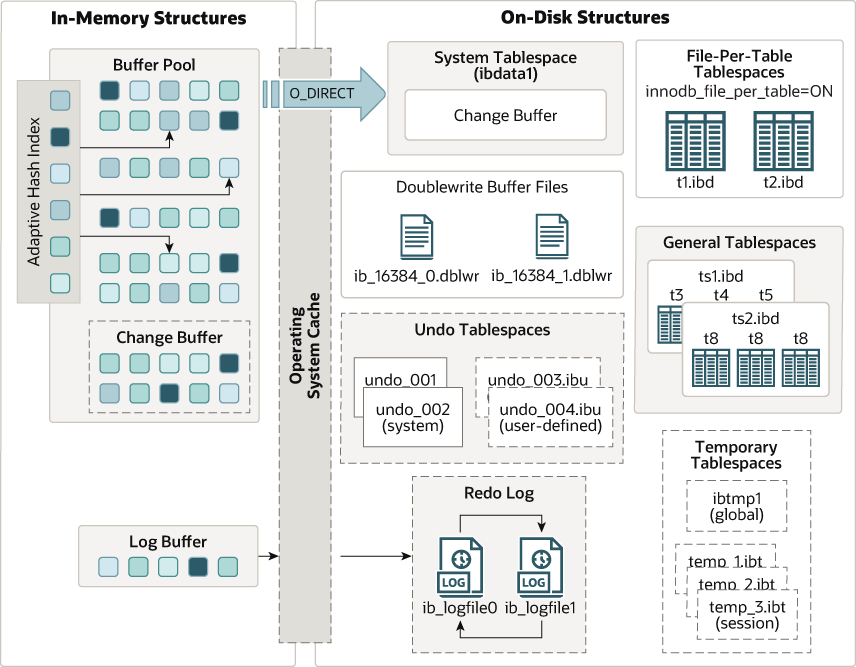
磁盘数据结构包括
- 系统表空间,也就是 ibdata1、ibdata2 这样的文件,用于存储用户表的元数据:表、列、索引信息等
- 双写buffer,保持原子性的
- 用户表空间,create table xx 后会创建一个xx.ibd文件
- 通用表空间,多个表之间可以共用这部分
- undo、redo跟事务相关的
- 掐还有临时表空间
基于内存的数据结构
- buffer pool
- change buffer
- adaptive hash index
表空间
通用头信息

InnoDB 表空间
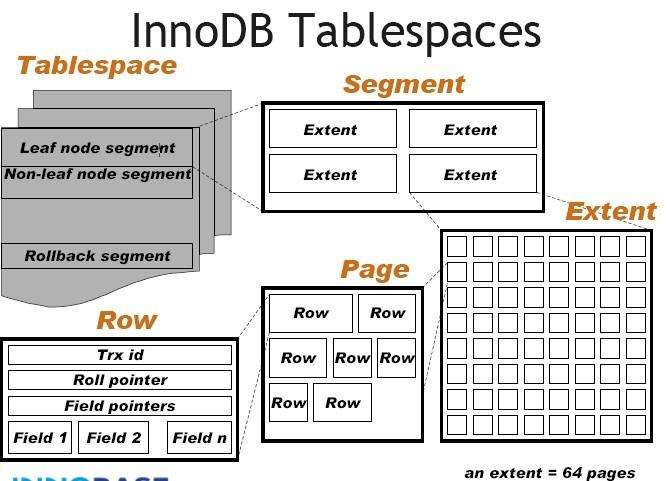
一个不恰当的比方
- 库:类似星球
- 表空间:类似星球中的某个国家
- 段:国家中的省
- extent(区):对应市,由64个page组成
- page(页):小区
- row(行):一个家庭
一个索引,比如聚集索引会对应 两个区 extent
- 上图有点老了,rollback segment现在是有独立的空间
- segment是一个逻辑概念,InnoDB设计者考虑到了空间优化问题
- 默认分配32个16K page,如果分配满了则分配一个extent(1M,64个page)
- 超过32M数据后,一次分配4个 extent
表空间的管理
表空间主要是用 FSP_HDR、XDES(extent descriptor)、INODE来管理、分配各个page
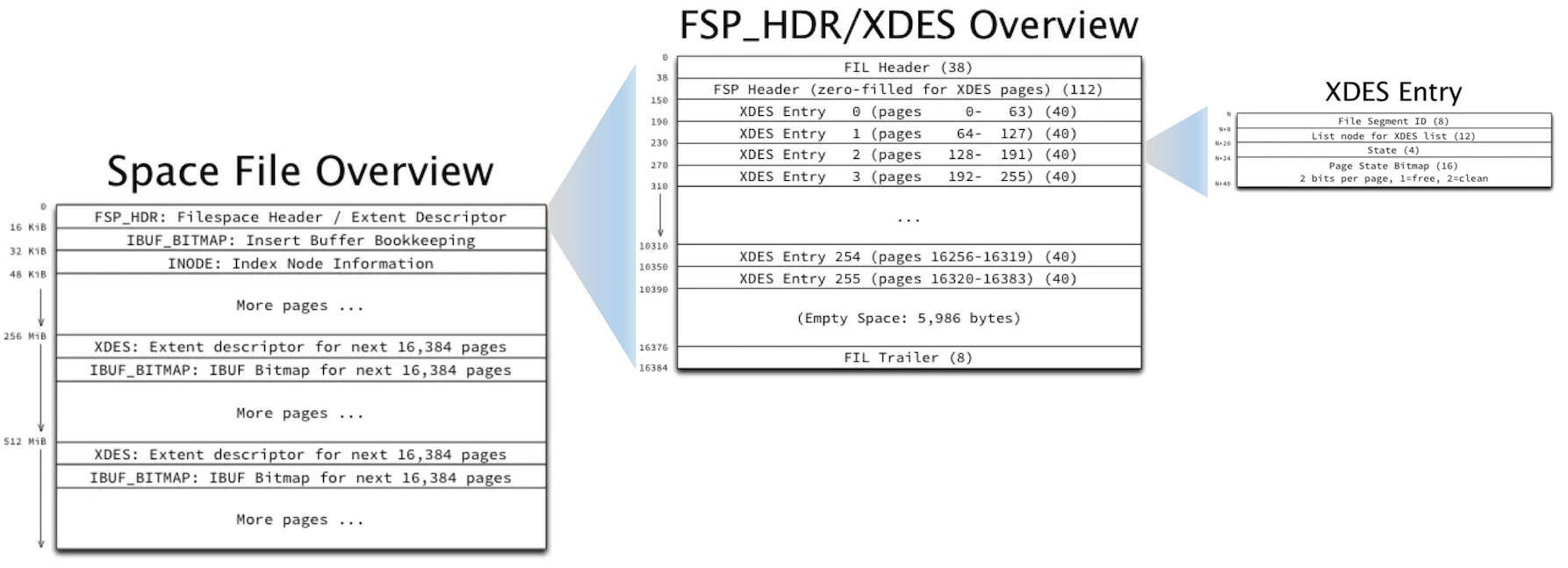
简单说明下
- 256个extent一组,一组一共256M
- 0 - 255组比较特殊,这一组的 0号page FSP_HEAD 用来记录表空间的一些信息
- 第一组的 1号page ibuf_bitmap 用于插入缓冲区
- 第一组的 inode 用来记录段信息
- 第二组 256 - 511, 第三组 512 - 767,以此类推
- 第二组、第三组,以及之后的组,其 0号、1号page都是固定的
- 第二组的0号page 是FIL_PAGE_TYPE_XDES,用来记录extent的一些信息
- 第二组的1号page,是FIL_PAGE_INODE,用来记录segment 段信息
区的分类
- 空闲的区:现在还没有用到这个区中的任何页面
- 有剩余空间的碎片区:表示碎片区中还有可用的页面
- 没有剩余空间的碎片区:表示碎片区中的所有页面都被使用,没有空闲页面
- 附属于某个段的区。每一个索引都可以分为叶子节点段和非叶子节点段
对应于四种状态
| 状态名 | 含义 |
|---|---|
| FREE | 空闲的区 |
| FREE_FRAG | 有剩余空间的碎片区 |
| FULL_FRAG | 没有剩余空间的碎片区 |
| FSEG | 附属于某个段的区 |
FIL_PAGE_TYPE_FSP_HDR 介绍
页面中各个字段含义
| 名称 | 中文名 | 占用空间大小 | 简单描述 |
|---|---|---|---|
| File Header | 文件头部 | 38字节 | 页的一些通用信息 |
| File Space Header | 表空间头部 | 112字节 | 表空间的一些整体属性信息 |
| XDES Entry | 区描述信息 | 10240字节 | 存储本组256个区对应的属性信息 |
| Empty Space | 尚未使用空间 | 5986字节 | 用于页结构的填充,没啥实际意义 |
| File Trailer | 文件尾部 | 8字节 | 校验页是否完整 |
File Space Header介绍

File Space Header部分
| 名称 | 占用空间大小 | 描述 |
|---|---|---|
| Space ID | 4字节 | 表空间的ID |
| Not Used | 4字节 | 这4个字节未被使用,可以忽略 |
| Size | 4字节 | 当前表空间占有的页面数 |
| FREE Limit | 4字节 | 尚未被初始化的最小页号,大于或等于这个页号的区对应的XDES Entry结构都没有被加入FREE链表 |
| Space Flags | 4字节 | 表空间的一些占用存储空间比较小的属性 |
| FRAG_N_USED | 4字节 | FREE_FRAG链表中已使用的页面数量 |
| List Base Node for FREE List | 16字节 | FREE链表的基节点 |
| List Base Node for FREE_FRAG List | 16字节 | FREE_FRAG链表的基节点 |
| List Base Node for FULL_FRAG List | 16字节 | FULL_FRAG链表的基节点 |
| Next Unused Segment ID | 8字节 | 当前表空间中下一个未使用的 Segment ID |
| List Base Node for SEG_INODES_FULL List | 16字节 | SEG_INODES_FULL链表的基节点 |
| List Base Node for SEG_INODES_FREE List | 16字节 | SEG_INODES_FREE链表的基节点 |
Space Flags
| 标志名称 | 占用空间(单位:bit) | 描述 |
|---|---|---|
| POST_ANTELOPE | 1 | 表示文件格式是否大于ANTELOPE |
| ZIP_SSIZE | 4 | 表示压缩页面的大小 |
| ATOMIC_BLOBS | 1 | 表示是否自动把值非常长的字段放到BLOB页里 |
| PAGE_SIZE | 4 | 页面大小 |
| DATA_DIR | 1 | 表示表空间是否是从默认的数据目录中获取的 |
| SHARED | 1 | 是否为共享表空间 |
| TEMPORARY | 1 | 是否为临时表空间 |
| ENCRYPTION | 1 | 表空间是否加密 |
| UNUSED | 18 | 没有使用到的比特位 |
ListNode结构体

字段介绍
- List Length表明该链表一共有多少节点
- First Node Page Number和First Node Offset表明该链表的头节点在表空间中的位置
- Last Node Page Number和Last Node Offset表明该链表的尾节点在表空间中的位置
FSP header中最重要的几个链表,其中3个是归属表空间的,2个是指向段的
- 当一个Extent中所有page都未被使用时,挂在FSP_FREE list base node上,可以用于随后的分配
- 有一部分page被写入的extent,挂在FREE_FRAG list base node上
- 全满的extent,挂在FULL_FRAG list base node上
- 归属于某个segment时候挂在FSEG list base node上,又成free、full两个头结点
FIL_PAGE_TYPE_XDES 介绍
page中的各个字段
- File Header 38 Byte
- NULL 112 Byte
- XDES Entry,一共256个,一共10240字节
- Empty Space,5986Byte
- File Trailer 8Byte
XDES Entry的结构
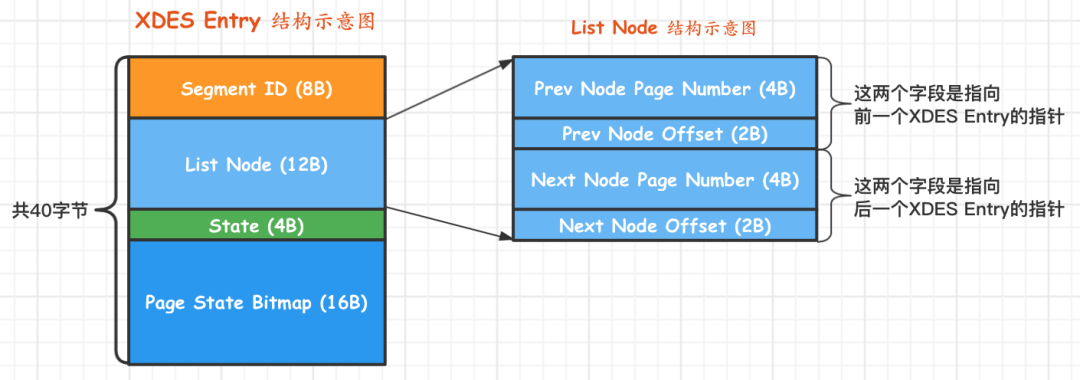
XDES(全称就是Extent Descriptor Entry)
每一个区都对应着一个XDES Entry结构,这个结构记录了对应的区的一些属性
介绍
- Segment ID(8字节),每一个段都有一个唯一的编号
- List Node(12字节),XDES的前后指针,指向前一个页的页号,以及页的偏移量
- State(4字节),表示这个区的状态,对应的值为:FREE、FREE_FRAG、FULL_FRAG和FSEG
- Page State Bitmap(16字节),128bit,两个bit对应一个page,第一个bit对应是否被使用,第二个bit暂时没用
表空间的三个链表
- 把状态为FREE的区对应的XDES Entry结构通过List Node来连接成一个链表,这个链表我们就称之为FREE链表
- 把状态为FREE_FRAG的区对应的XDES Entry结构通过List Node来连接成一个链表,这个链表我们就称之为FREE_FRAG链表
- 把状态为FULL_FRAG的区对应的XDES Entry结构通过List Node来连接成一个链表,这个链表我们就称之为FULL_FRAG链表
FIL_PAGE_INODE 介绍
各个字段含义
| 名称 | 中文名 | 占用空间大小 | 简单描述 |
|---|---|---|---|
| File_Header | 文件头部 | 38字节 | 页的一些通用信息 |
| List_Node_for_INODE_Page_List | 通用链表节点 | 12字节 | 存储上一个INODE页面和下一个INODE页面的指针 |
| INODE_Entry | 段描述信息 | 16320字节 | 存储段描述信息,最多85个INode Entry |
| Empty_Space | 尚未使用空间 | 6字节 | 用于页结构的填充,没啥实际意义 |
| File_Trailer | 文件尾部 | 8字节 | 校验页是否完整 |
INode Entry结构体
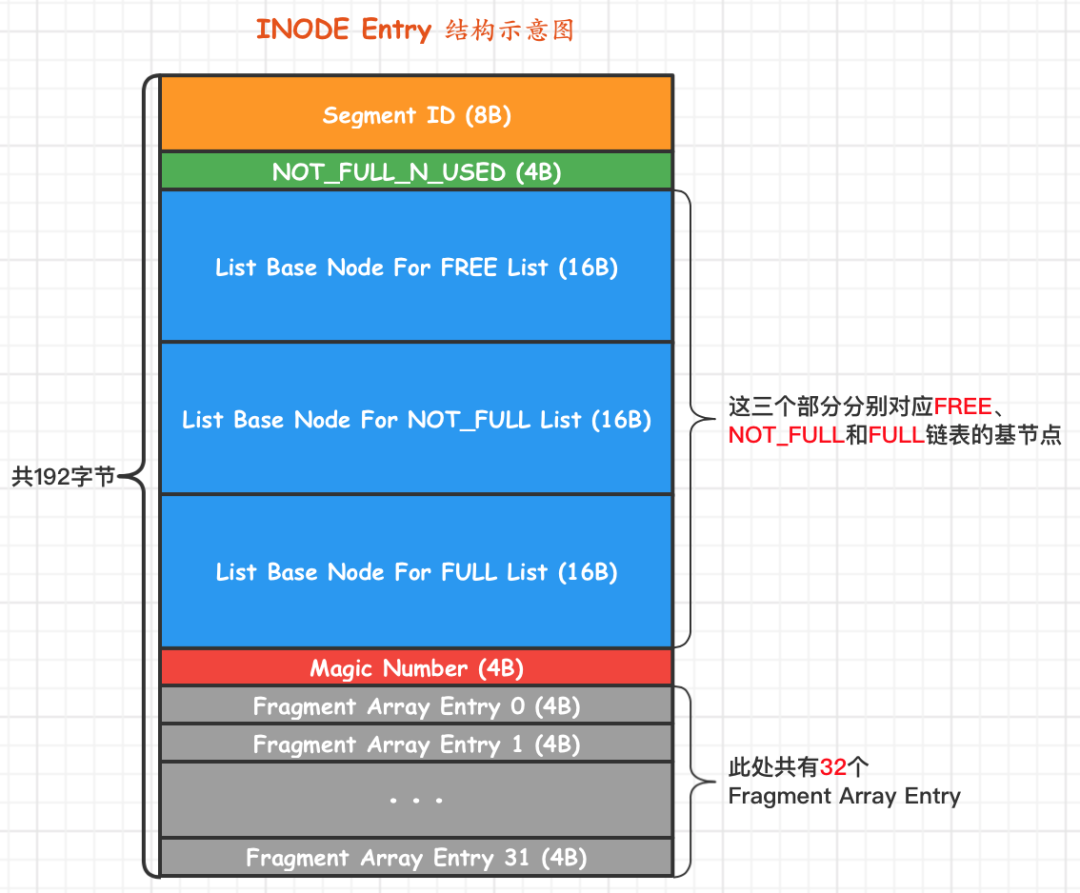
- Segment ID,就是指这个INODE Entry结构对应的段的编号(ID)。
- NOT_FULL_N_USED,这个字段指的是在NOT_FULL链表中已经使用了多少个页面。
- FREE链表,一个ListNode类型,指向一个 XDES entry
- NOT_FULL链表,同上
- FULL链表,同上
- Magic Number,标记这个INODE Entry是否已经被初始化了
- Fragment Array Entry,32个零散的page,每个都指向一个page
表空间的整体结构
如下图
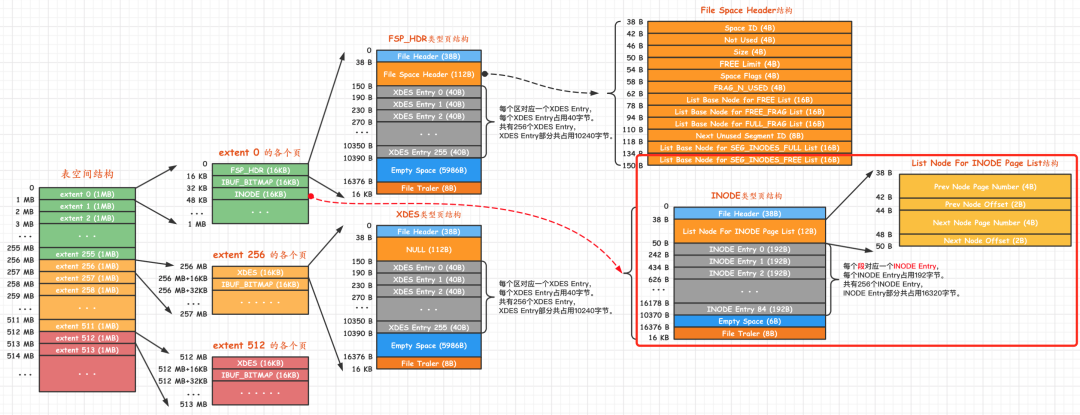
绿色部分是255个区,黄色部分、红色也是255个区
绿色部分比较特殊,它的前三个跟其他区不一样
- page0是 FSP_HDR
- page1是 change buffer
- page2是 INODE
黄色、红色,以及后面多的区,整体结构都是类似的,每个区的前面 2个比较特殊
- page0是 XDES_HDR
- page1是 change buffer
从另一个角度看表空间的结构
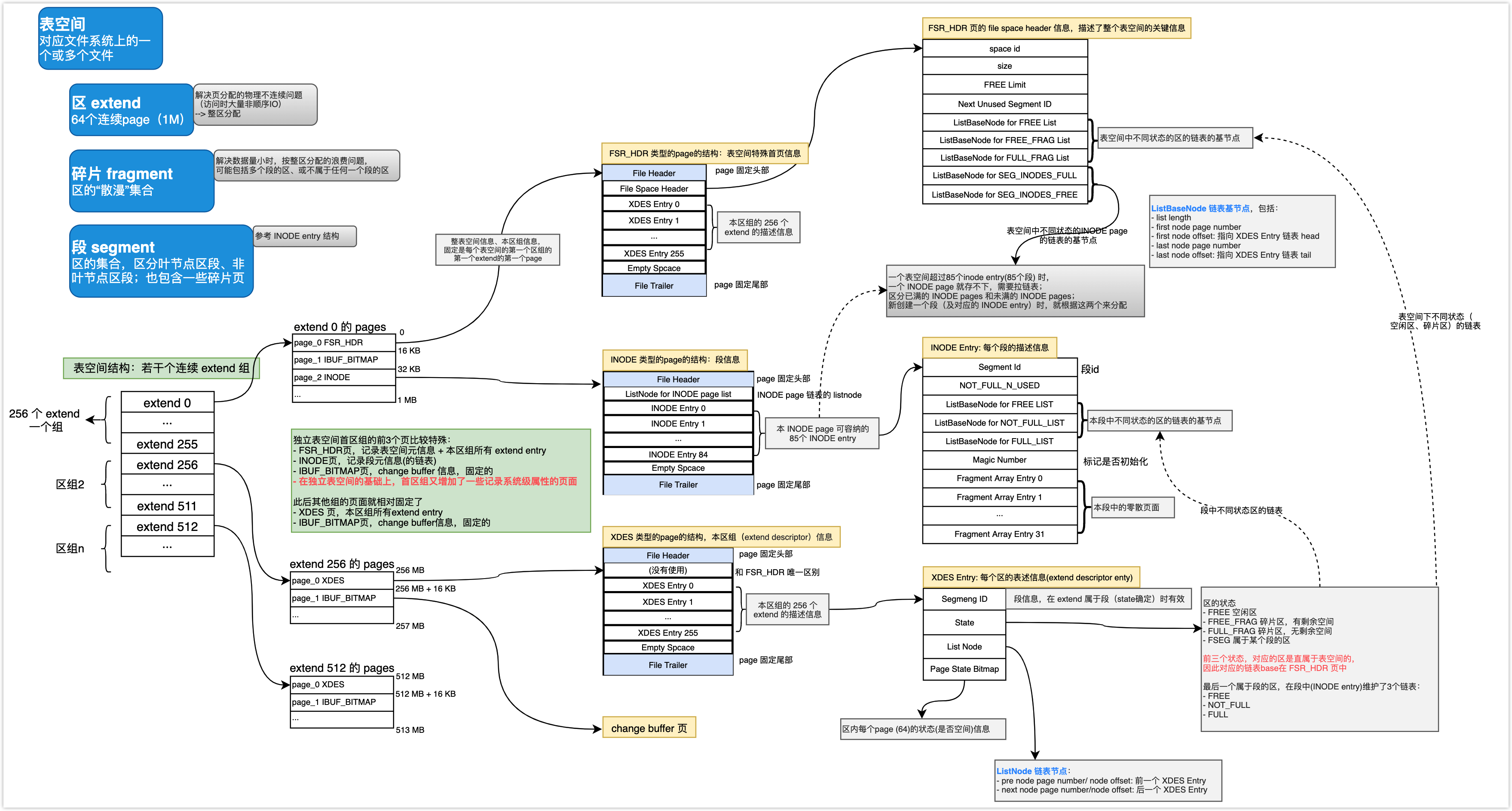
一个完整的图,将整个结构串联起来
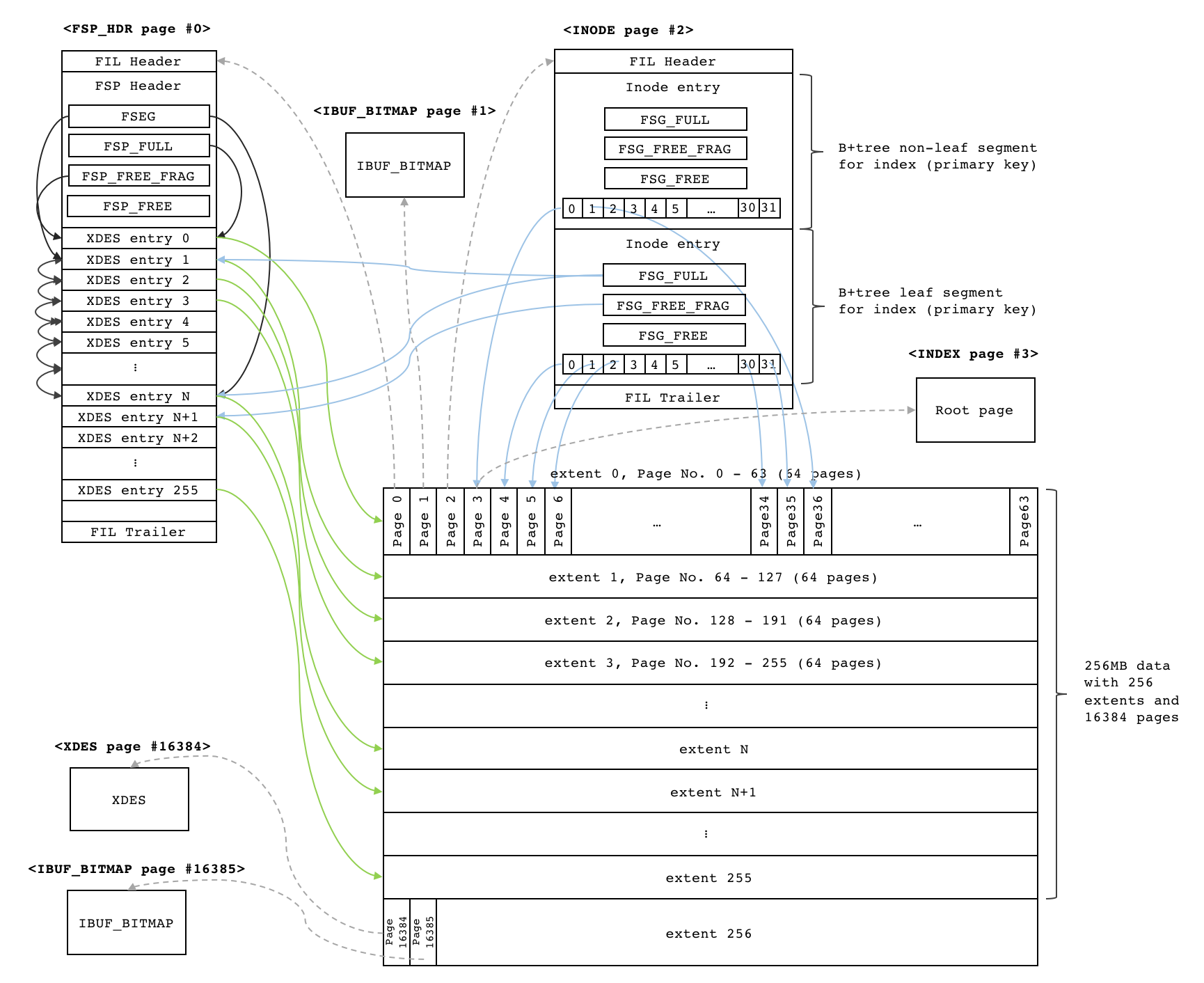
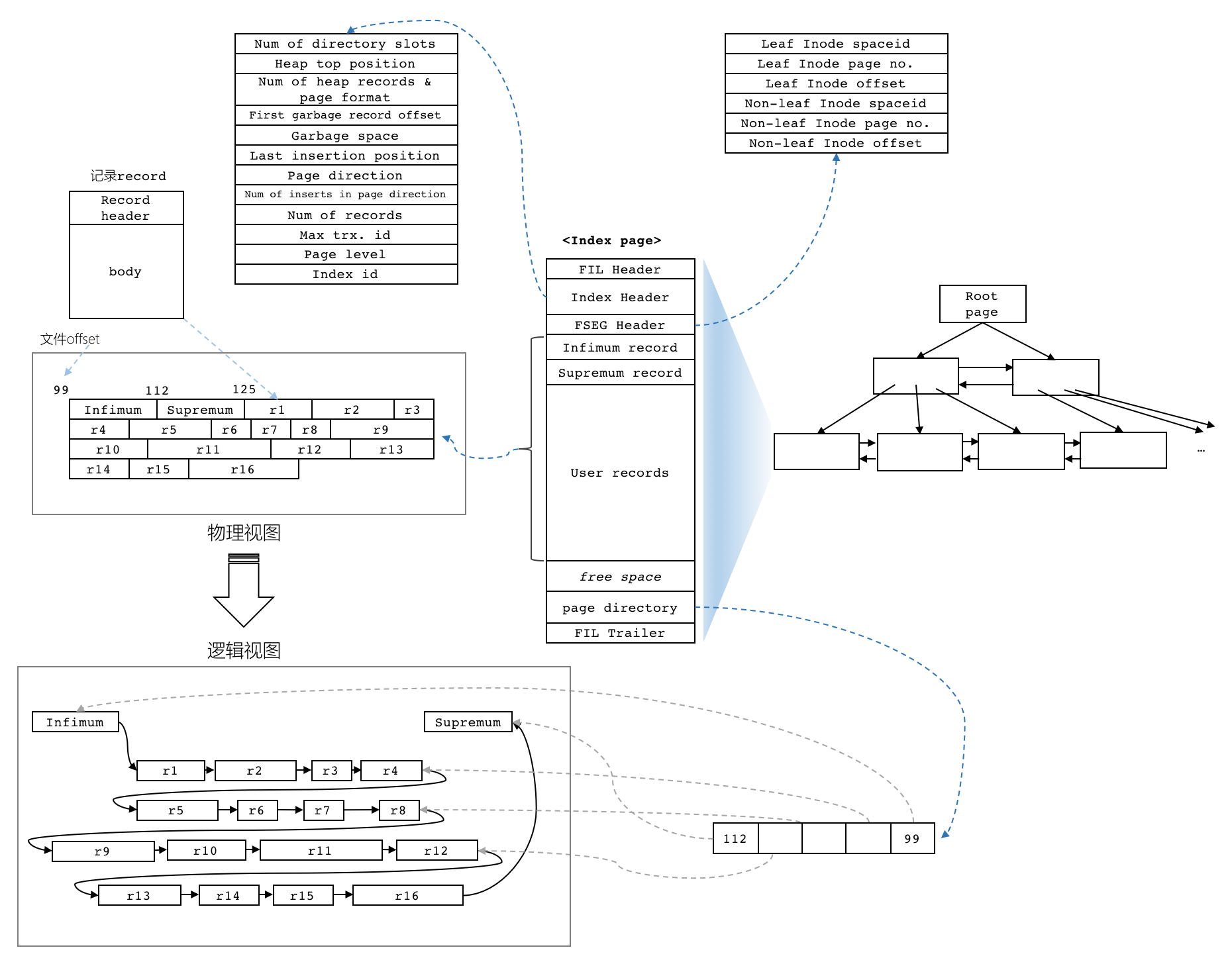
数据页 FIL_PAGE_INDEX
一行数据是存储在 数据页中的,InnoDB中定义了很多页类型
默认情况下,每个页大小为 16K
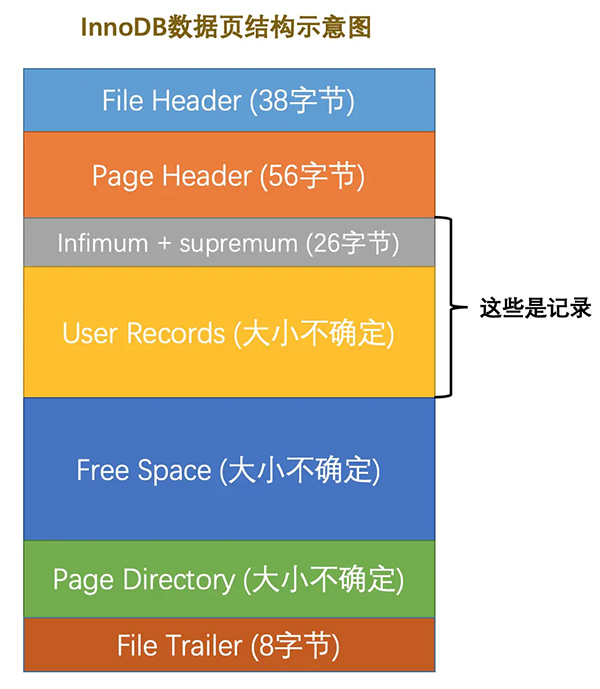
上图中,File Header、File Trailer是通用的,也就是每种类型的页都会有这种结构
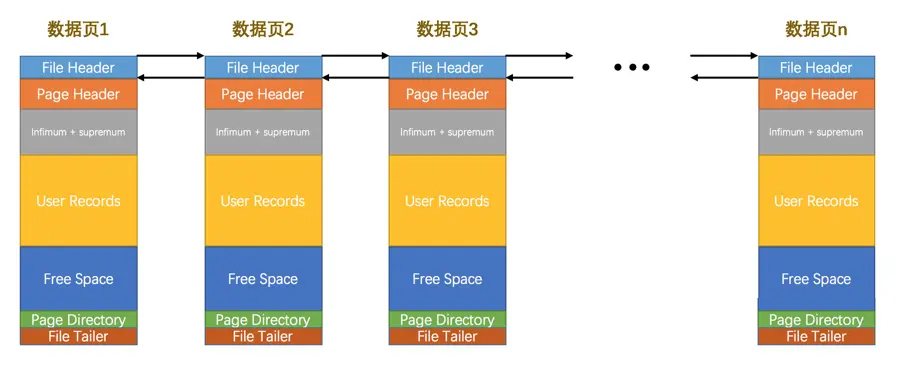
File Header中,包含了上个页、下个页的指针
但是有些类型的页其 前后指针是空的
数据页通过前后指针就可以很快定位到相邻记录,所以数据page之间是双链表结构
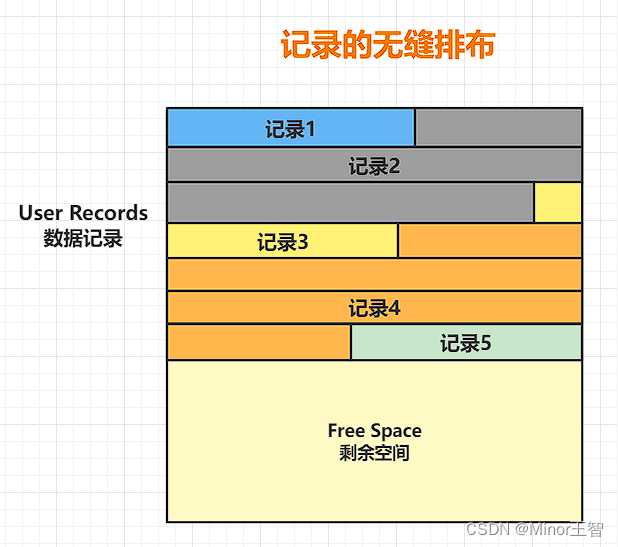
数据的插入过程,先从空闲空间中分配
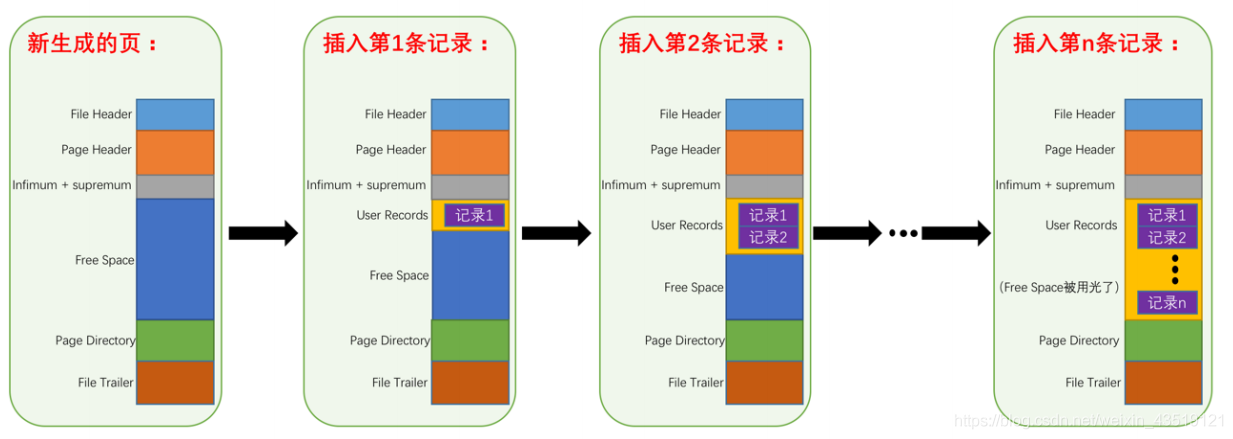
不同数据页之间的连接关系
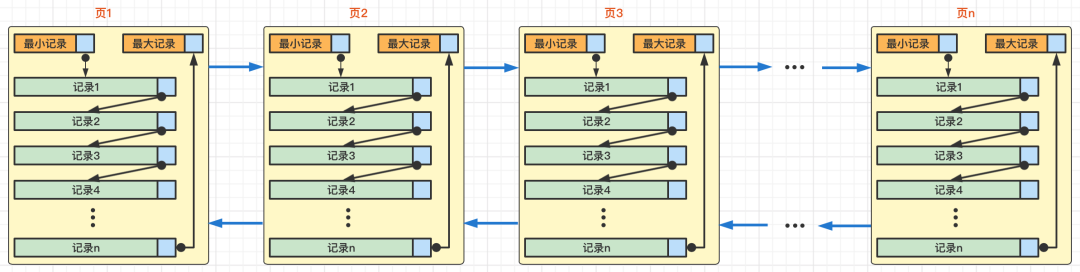
数据页的头信息
File Header定义如下:
| 名称 | 大小(单位:B) | 描述 |
|---|---|---|
| FIL_PAGE_SPACE_OR_CHKSUM | 4 | 页的校验和(checksum值) |
| FIL_PAGE_OFFSET | 4 | 页号 |
| FIL_PAGE_PREV | 4 | 上一个页的页号 |
| FIL_PAGE_NEXT | 4 | 下一个页的页号 |
| FIL_PAGE_LSN | 8 | 页面被最后修改时对应的日志序列位置(英文名是:Log |
| FIL_PAGE_TYPE | 2 | 该页的类型 |
| FIL_PAGE_FILE_FLUSH_LSN | 8 | 仅在系统表空间的一个页中定义,代表文件至少被刷新到了对应的LSN值 |
| FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID | 4 | 页属于哪个表空间 |
File Trailer 定义如下:
- 前4个字节代表页的校验和,这个部分是和File Header中的校验和相对应的
- 后4个字节代表页面被最后修改时对应的日志序列位置(LSN)
Page Header 定义如下:
| 名称 | 大小(单位:Byte) | 描述 |
|---|---|---|
| PAGE_N_DIR_SLOTS | 2 | 页目录的插槽数 |
| PAGE_HEAP_TOP | 2 | 还未使用的空间最小地址,也就是说从该地址之后就是Free Space |
| PAGE_N_HEAP | 2 | 第1位表示本记录是否为紧凑型的记录,剩余的15位表示本页的堆中记录的数量(包括最小和最大记录以及标记为删除的记录) |
| PAGE_FREE | 2 | 各个已删除的记录通过next_record组成一个单向链表,这个单向链表中的记录所占用的存储空间可以被重新利用;PAGE_FREE表示该链表头节点对应记录在页面中的偏移量 |
| PAGE_GARBAGE | 2 | 已删除记录占用的字节数 |
| PAGE_LAST_INSERT | 2 | 最后插入记录的位置 |
| PAGE_DIRECTION | 2 | 记录插入的方向 |
| PAGE_N_DIRECTION | 2 | 一个方向连续插入的记录数量 |
| PAGE_N_RECS | 2 | 该页中记录的数量(不包括最小和最大记录以及被标记为删除的记录) |
| PAGE_MAX_TRX_ID | 8 | 修改当前页的最大事务ID,该值仅在二级索引中定义 |
| PAGE_LEVEL | 2 | 当前页在B+树中所处的层级 |
| PAGE_INDEX_ID | 8 | 索引ID,表示当前页属于哪个索引 |
| PAGE_BTR_SEG_LEAF | 10 | B+树叶子段的头部信息,仅在B+树的Root页定义 |
| PAGE_BTR_SEG_TOP | 10 | B+树非叶子段的头部信息,仅在B+树的Root页定义 |
Page Directory
数据页中有一个 Page Directory,可以用这个做二分查找,快速定位
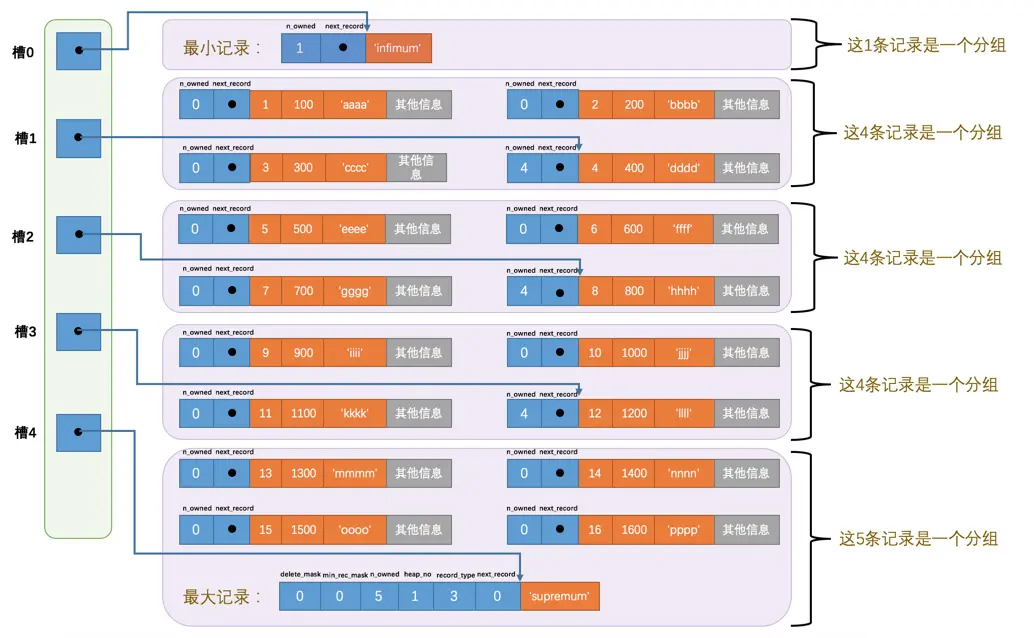
这里规定,虚拟的最小值分为一组,里面只有一条记录也就是最小值本身
最大值分为一组,里面的记录数有1-8之间
其他的分组只能是4-8条之间
比如槽子指向的分别是 1、3、5、7、9
如果要查8,那么根据二分定位到9,这个值比9小,所以找9前面的7这个槽子
根据7 这个槽子就定位到一个具体的记录了,然后再按照 单链表往后遍历,就能找到 8这条记录了
B+树索引
完整的结构如下:
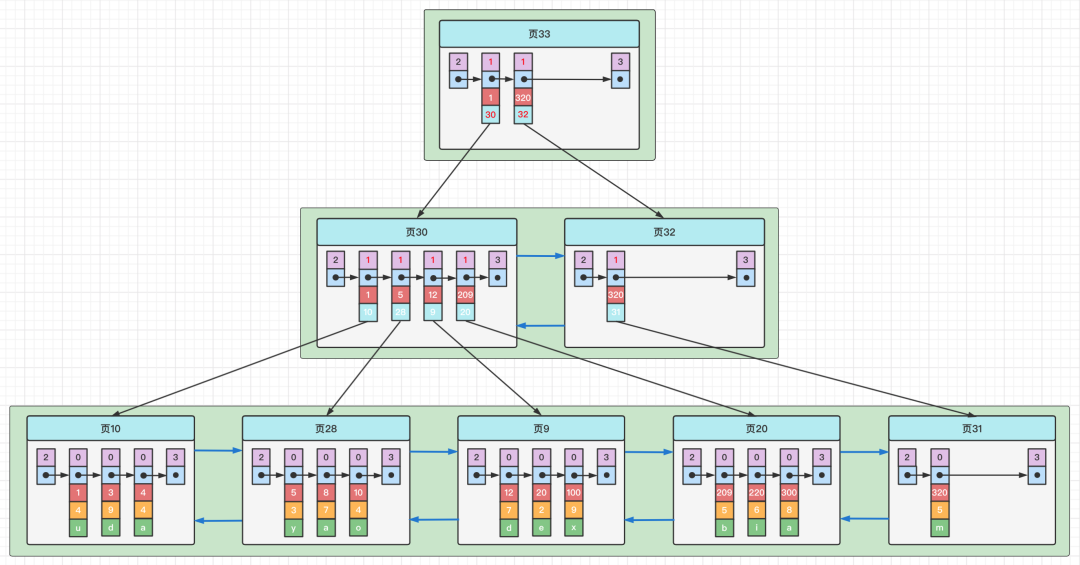
MySQL的数据页、索引页用的都是 FIL_PAGE_INDEX 这种类型的页
也就是:数据即索引,索引即数据
再说说 记录头信息里的record_type属性
- 0:普通的用户记录
- 1:目录项记录
- 2:最小记录
- 3:最大记录
一些注意事项
- 根页面永不动窝
- 普通二级索引内节点,包含三个值:索引列的值、主键值、页号
- 这样就能保证B+树每一层节点中各条目录项记录除页号这个字段外是唯一的
- 二级索引的叶子节点,存储了索引列的值、主键值,找到主键后,再回表查询
- 联合索引(c2、c3),非叶节点存储了c2+c3,如果c2相同则按照c3排序
- 联合索引(c2、c3)的叶子节点存储了c2、c3、主键
和INode关联
如何找到 某个具体的 段?
每个 数据页都有两个字段
- PAGE_BTR_SEG_LEAF
- PAGE_BTR_SEG_TOP
都占用10个字节,它们其实对应一个叫Segment Header的结构
| 名称 | 占用空间大小 | 描述 |
|---|---|---|
| Space ID of the INODE Entry | 4字节 | INODE Entry结构所在的表空间ID |
| Page Number of the INODE Entry | 4字节 | INODE Entry结构所在的页面页号 |
| Byte Offset of the INODE Entry | 2字节 | INODE Entry结构在该页面中的偏移量 |
数据页的完整结构
一个数据页的完整结构
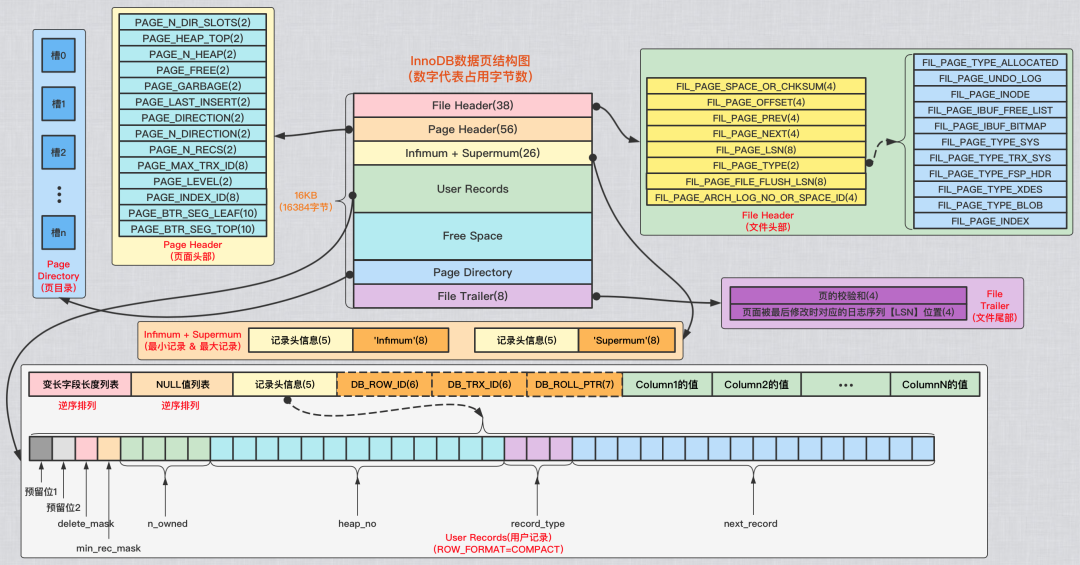
从另一个角度观察,数据页和其他页的关联
系统表空间
系统表空间除了第一组,其他跟 普通的表空间差不多
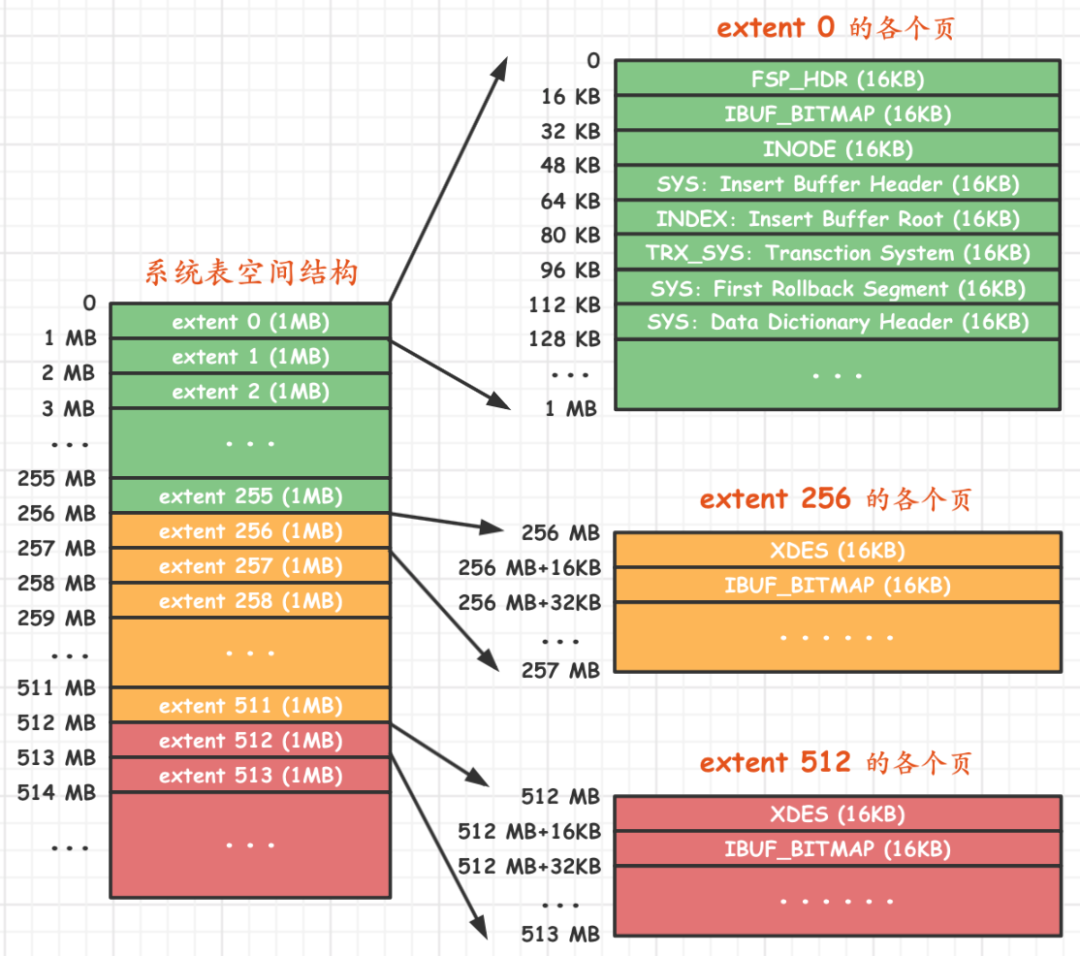
系统表空间和独立表空间的前三个页面(页号分别为0、1、2,类型分别是FSP_HDR、IBUF_BITMAP、INODE)的类型是一致的
只是页号为3~7的页面是系统表空间特有的
| 页号 | 页面类型 | 英文描述 | 描述 |
|---|---|---|---|
| 3 | SYS | Insert | Buffer |
| 4 | INDEX | Insert | Buffer |
| 5 | TRX_SYS | Transction | System |
| 6 | SYS | First | Rollback |
| 7 | SYS | Data | Dictionary |
除了这几个记录系统属性的页面之外,系统表空间的extent 1和extent 2这两个区
也就是页号从64~191这128个页面被称为Doublewrite buffer,也就是双写缓冲区
Data Dictionary Header 页面
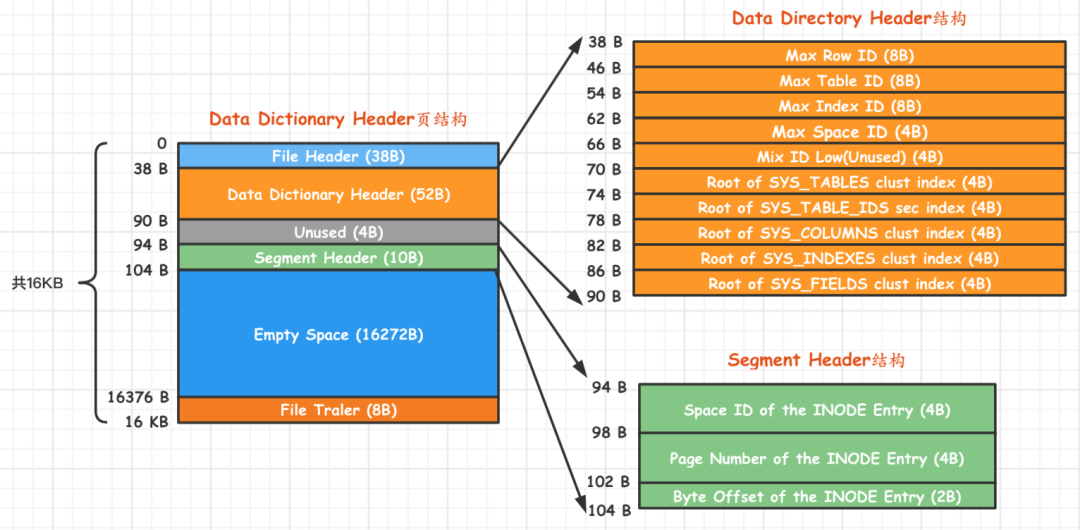
| 名称 | 中文名 | 占用空间大小 | 简单描述 |
|---|---|---|---|
| File_Header | 文件头部 | 38字节 | 页的一些通用信息 |
| Data_Dictionary_Header | 数据字典头部信息 | 56字节 | 记录一些基本系统表的根页面位置以及InnoDB存储引擎的一些全局信息 |
| Segment_Header | 段头部信息 | 10字节 | 记录本页面所在段对应的INODE |
| Empty_Space | 尚未使用空间 | 16272字节 | 用于页结构的填充,没啥实际意义 |
| File_Trailer | 文件尾部 | 8字节 | 校验页是否完整 |
主要字段解释:
- Max Row ID,全局共享的默认row_id最大值,每次会++
- Max Table ID:每次新建一个表时,就会把本字段的值作为该表的ID,然后自增本字段的值,全局共享
- Max Index ID:每次新建一个索引时,就会把本字段的值作为该索引的ID,然后自增本字段的值,全局共享
- Max Space ID:每次新建一个表空间时,就会把本字段的值作为该表空间的ID,然后自增本字段的值,全局共享
- Mix ID Low(Unused):暂时没有
- Root of SYS_TABLES clust index:SYS_TABLES表聚簇索引的根页面的页号
- Root of SYS_TABLE_IDS sec -index:SYS_TABLES表为ID列建立的二级索引的根页面的页号
- Root of SYS_COLUMNS clust index:SYS_COLUMNS表聚簇索引的根页面的页号
- Root of SYS_INDEXES clust index:SYS_INDEXES表聚簇索引的根页面的页号
- Root of SYS_FIELDS clust index:SYS_FIELDS表聚簇索引的根页面的页号
表中之表,四个:
- SYS_TABLES
- SYS_COLUMNS
- SYS_INDEXES
- SYS_FIELDS
SYS开头的表,默认是无法访问的,InnoDB提供了information_schema库,里面包含了对应的系统表
|
|
注意! MySQL8.x 之后,information_schema 中对应的系统表名字又变化,不过大体含义都是类似的
information_schema 各个表介绍
- INNODB_SYS_DATAFILES,表空间对应的系统文件路径信息
- INNODB_SYS_VIRTUAL,虚拟生成的列信息
- INNODB_SYS_INDEXES,索引信息,对应 SYS_INDEXES
- INNODB_SYS_TABLES,所有表信息,对应 SYS_TABLES
- INNODB_SYS_FIELDS,索引对应的列信息, 对应 SYS_FIELDS
- INNODB_SYS_TABLESPACES,所有表空间系统
- INNODB_SYS_FOREIGN_COLS,所有外键对应的列信息
- INNODB_SYS_COLUMNS,所有列信息,对应 SYS_COLUMNS
- INNODB_SYS_FOREIGN,外键信息
- INNODB_SYS_TABLESTATS,表状态信息
查找 SYS_TABLESPACES 的过程:
- 根据表名去 SYS_TABLES 表中找到对应的 SYS_TABLESPACES表的ID
- 根据TABLE_ID 去 SYS_COLUMNS 表中获取该表的列信息
- 根据TABLE_ID 去 SYS_INDEXES 表中获取所有 索引信息,索引信息包括对应的 B+树 是哪个表空间的哪个页面
- 在SYS_INDEXES 表通过 INDEX_ID 去 SYS_FIELDS表中获取索引对应的列信息
Antelope 和Barracuda区别
- Antelope是innodb-base的文件格式
- Barracude是innodb-plugin后引入的文件格式,同时Barracude也支持Antelope文件格式
- Antelope(Innodb-base)支持的格式:ROW_FORMAT=COMPACT,ROW_FORMAT=REDUNDANT
- Barracuda(innodb-plugin),ROW_FORMAT=DYNAMIC,ROW_FORMAT=COMPRESSED
通用表空间
创建语法
|
|
再建立一个
|
|
去 INNODB_SYS_DATAFILES 表中就能看到最新创建的表空间了
行格式
行格式介绍参考官网 -> 这里
行格式有4种
- REDUNDANT
- COMPACT
- DYNAMIC
- COMPRESSED
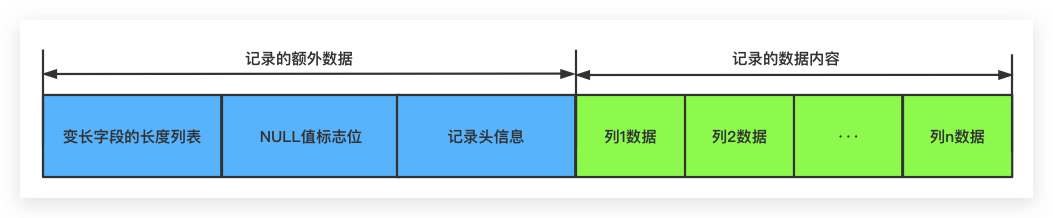
变长字段的长度列表
- 存储像 varchar这种的,其长度是可变的
- 在这个列表中存储了对应字段的长度
- 如果存储的最大字节不超过255,则使用1个字节
- 如果实际使用的字节不超过127,则用 1个字节表示
- 否则用2个字节表示
- 对于varchar(M),字符类型为ascii,其长度为 M * 1,而UTF为M * 3,UTFmb4为M * 4
- 变长字段的长度列表不存储值为NULL的长度信息
- 变长字段的长度列表不是一定存在的
- 变长字段的长度列表中各字段长度信息是按列的顺序逆序排列的
- char类型字段的长度信息是否需要存储在 变长字段的长度列表 中取决于其所使用的字符集是否为变长字符集
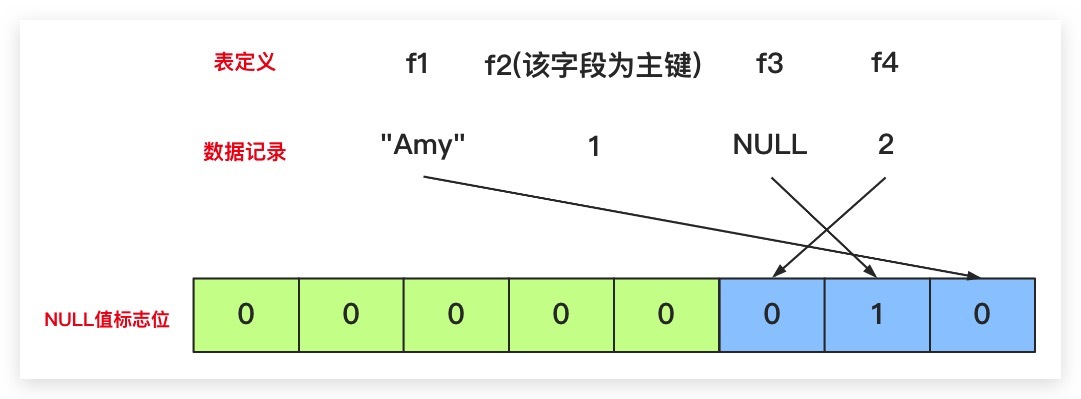
比如,ascii字符集,各字段为f1、f2、f3、f4
其值为 “a”、NULL、“ccc”、99
变成字段f1为1、f3长度为3,则变成字段列表内容为 0x03、0x01
NULL值标志位
- 也是反向存储的
- 对于向量位不足 1个字节,则补0
- NULL值标志位不是一定存在的
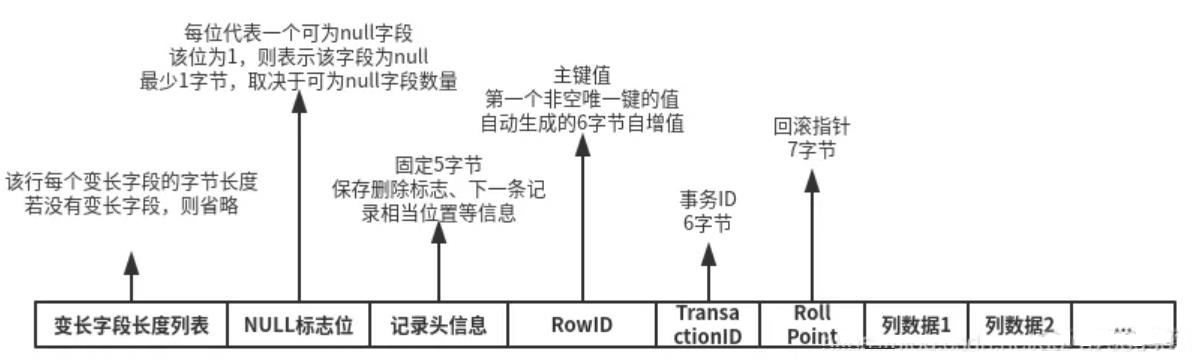
更完整的行信息如下:
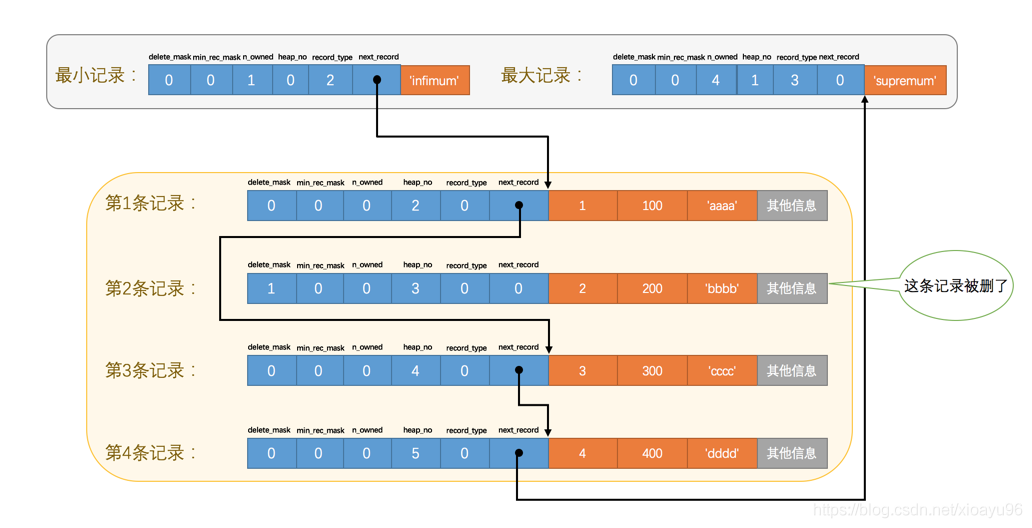
头记录信息如下:

头记录说明
- 预留位1、2:暂未使用
- delete_mask:当前记录被删除的标志位
- min_rec_mask:B+树的每层非叶子节点中的最小记录的标志位
- n_owned:当前记录拥有的记录数
- heap_no:当前记录在记录堆中的位置
- record_type:当前记录类型。具体地,0: 普通记录;1: B+树非叶子节点记录(即所谓的目录项记录);2: 最小记录;3: 最大记录
- next_record:下一条记录的相对位置
记录的数据内容
- DB_ROW_ID:该字段占6个字节,用于标识一条记录
- DB_TRX_ID:该字段占6个字节,其值为事务ID
- DB_ROLL_PTR:该字段占7个字节,其值为回滚指针
next_record 是按照单链表的方式,指向了下一条记录
其中 infimum 是最小记录、supermum是最大记录

删除记录2 后的结果,并不会真正删除,后面如果再插入数据,会复用这个空间
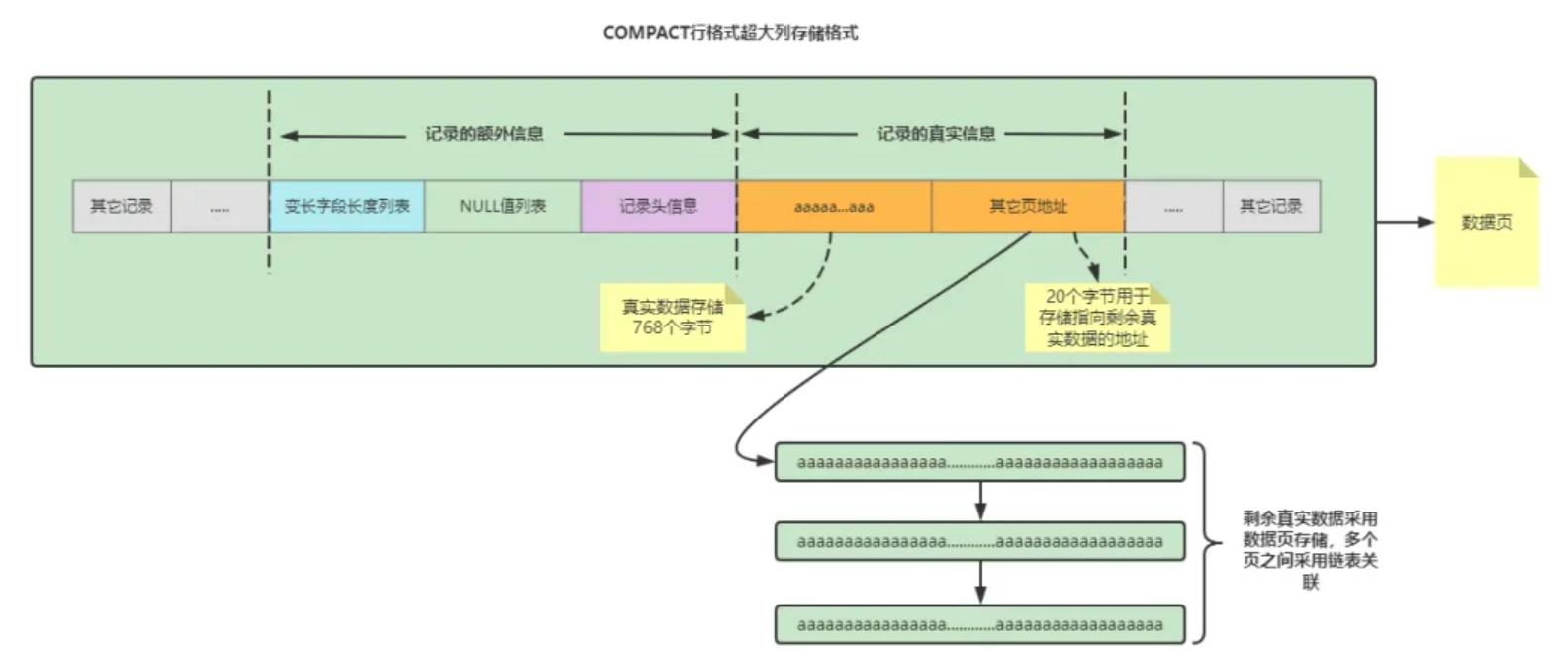
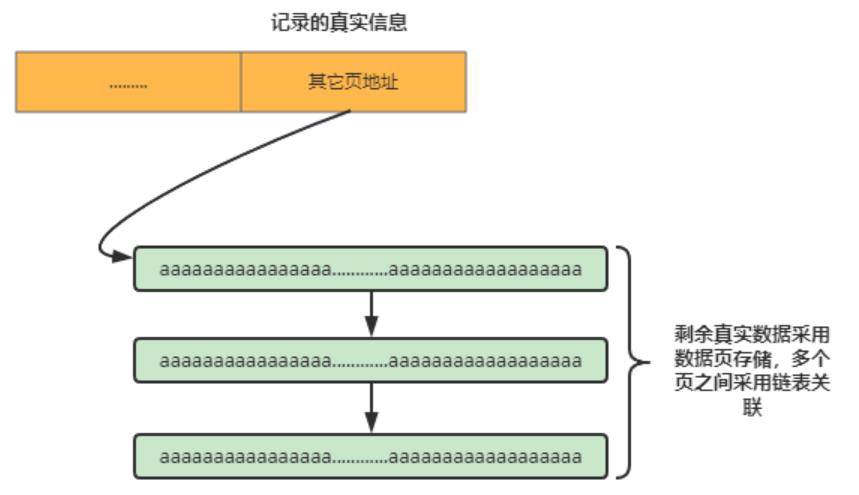
COMPACT格式中,如果超过了 768字节,则会用产生溢出页,并用20字节指针,指向溢出页
DYNAMIC格式跟COMPACT的区别是,不再存储768字节了,直接用20字节指向溢出页
各种page定义
这个头文件的位置是:mysql-8.0.28/storage/innobase/include/fil0fil.h
|
|
参考
- MySQL之InnoDB存储引擎:Row Format行格式
- GrowthDBA
- MySQL工具之innodb_ruby:探究InnoDB存储结构的利器
- MySQL工具之binlog2sql
- MySQL 八股文之 MVCC 实现原理
- MySQL之Server层的“Buffer”和“Cache”
- MySQL各种“Buffer”之InnoDB Buffer Pool
- MySQL各种“Buffer”之Change Buffer
- MySQL各种“Buffer”之Log Buffer
- MySQL各种“Buffer”之Doublewrite Buffer
- MySQL各种“Buffer”之Adaptive Hash Index
- MySQL工具之innblock:一文搞懂表空间碎片是如何产生的
- MySQL之InnoDB表空间
- 从MySQL InnoDB物理文件格式深入理解索引
- Jeremy Cole的InnoDB介绍
- innodb-java-reader工具
- innodb_ruby工具
- Antelope 和Barracuda区别
- InnoDB INFORMATION_SCHEMA System Tables