MySQL查询分析
准备工作
SQL脚本
|
|
RBO优化
一些预制的经典RBO规则
- 移除不必要的括号
- 常量传递
- 移除没用的表达式
- 表达式计算
- HAVING 子句和 WHERE 子句的合并
- 常量表检测
左外连接、右外连接的位置不能互换
但是 内连接可以,选择驱动表、被驱动表就很关键
被驱动表 WHERE 子句合并空值拒绝条件时了,外连接 和 内连接可以相互转换
子查询根据维度的不同,可以分为:
- 标量子查询,单列单值
- 行子查询,只有一行
- 列子查询,一列但有多个值
- 表子查询
子查询在语句中的位置
- SELECT 子句中
- FROM 子句中
- WHERE 或者 ON 子句中
- ORDER BY 子句中
- GROUP BY 子句中
一些 boolean 语句
- IN、NOT IN,判断某个操作数是否存在于子查询结果集合中
- ANY(SOME),只要结果中存在一个值就符合条件
- ALL,结果集中必须所有条件都符合
- [NOT] EXIST,仅仅判断子查询的结果集中是否有记录,而不在乎其记录具体是什么
ANY的一些优化
|
|
ALL的一些优化
|
|
按照与外层查询关系分类
- 不相关子查询
- 相关子查询
IN 子查询优化,先尝试转为半连接,如果可以则继续用下面 5种规则优化
- Talbe pullout,表上提,必须是主键
- Duplicate Weedout,用临时表去重
- LooseScan
- Semi-join Materialization
- FirshMatch
talbe pullout优化
|
|
loose scan优化
|
|
如果不能转为 半连接,则:
- 先将子查询物化,再执行查询
- 执行 IN 到 EXIST 的转换
派生表,也就是 FROM 后面跟着的查询
- 优先尝试跟外层查询进行合并
- 如果不能合并,则物化处理
CBO 优化
查看表状态
|
|
这里有两个很重要的字段:
- rows,表中记录的行数,InnoDB并不精准
- Data_length,InnoDB聚集索引占用的存储空间大小
默认page 是16K,所以反推出 page数量:
聚集索引页面数量 = 1589248 / 16 / 1024.0 = 97个page
索引扫描成本分析
假设查询语句如下:
|
|
下面要分析各种情况的成本
- 全表扫描
- 使用key1的 idx_key1 索引成本
- 使用key2的 uk_key2 索引成本
- 其他如 key3 不是常数比较用不到索引;key_part1也用不到;common_field没有索引
全表扫描成本
IO成本:
97 * 1.0 + 1.1 = 98.1
这里的97是 page 数量, 1.0是加载一个page的常数成本,后面的1.1是微调值
CPU成本:
9748 * 0.2 + 1.0 = 1950.6
这里的 9748 是总记录数,InnoDB中是一个估算值, 0.2是访问一条记录所需的常数成本,后面的.1.0是微调值
总成本 = 98.1 + 1950.6 = 2048.7
所以 扫描全表的成本是 2048.7
唯一索引 uk_key2的成本
对于需要回表的情况要依赖两方面因素:
1、扫描区间数量
2、需要回表的记录数
MySQL粗暴的认为,扫描一个区间的I/O成本跟 一个方页面的I/O成本一样
这里只扫描了一个区间所以:
扫描区间的成本:
1 * 1.0 = 1.0
需要回表的数量
计算 key2 > 10 AND key2 < 1000 这个索引页面的记录数
非叶节点的记录数就对应 叶子节点的page数
递归B+ 数到最左边10这个非叶结点,再递归到最右边1000这个非叶节点
如果 10 和 1000正好在一个页面就直接统计,否则再递归往下遍历
回表的CPU: 95条记录 * 02. + 0.01 = 19.01 0.01 是微调值
根据这些记录到 聚集索引中的成本
InnoDB中,每次回表相当于访问一个page
I/O成本: 95 * 1.0 = 95.0
CPU读取记录的成本
95 * 0.2 = 19.0
使用 uk_key2的总成本
I/O 成本: 二级索引扫描区间成本 + 预估回表扫描成本 = 1.0 + 95 * 1.0 = 96.0
CPU成本: 读取二级索引记录数 + 回表读取聚集索引记录成本 = 95 * 0.2 + 0.01 +95 * 0.2 = 38.01
uk_key2 总成本 = 96.0 + 38.01 = 134.01
普通索引 idx_key1的成本
查询条件为: key1 IN (‘a’, ‘b’, ‘c’)
索引扫描区间成本
3个 单点扫描 = 3 * 1.0 = 3.0
需要回表的记录数,要分别统计’a’,‘b’,‘c’ 三个区间的
方法还是遍历最左非叶节点,最右非叶节点,再统计数量
假设分别为 35、44、39,总回表记录数为: (35 + 34 + 39) * 0.2 + 0.01 = 23.61
回表去聚集索引的成本
I/O 成本 = 118 * 1.0 = 118.0
CPU成本 = 118 * 0.2 = 23.6
idx_key1 的总成本
I/O成本:3.0 + 118 * 1.0 = 121 扫描二级索引区间数量 + 预计二级索引记录数量
CPU成本:118 * 0.2 + 0.01 + 118 * 0.2 = 47.21 读取二级索引记录的成本 + 回表检查的成本
总成本 : 121 + 47.2 = 168.21
其他情况,预估可能使用到的 索引合并
对比各种情况:
- 全表扫描成本 2048.7
- 使用uk_key2的成本: 134.01
- 使用idx_key1的成本: 168.21
所以会选择uk_key2来执行查询
基于统计信息的成本计算
扫描区间大于某个阈值,就使用基于统计信息的计算:
|
|
| Variable_name | Value |
|---|---|
| eq_range_index_dive_limit | 200 |

字段含义:
- Table:索引所在的表名
- Non_unique:0表示该索引是唯一索引,1表示该索引不是唯一索引
- Key_name:索引的名称
- Seq_in_index:索引列在索引中的位置,从1开始。对于组合索引来说,这个字段很重要。
- Column_name:索引列的名称
- Collation:索引列的值以什么方式存储在索引中。在MySQL中,A 表示有排序,B+树索引使用该方式;NULL 表示无序的,Heap索引使用该方式;
- Cardinality:索引中唯一值的数目的估计值。通过运行ANALYZE TABLE或myisamchk -a可以更新。基数根据被存储为整数的统计数据来计数,所以即使对于小型表,该值也没有必要是精确的。基数越大,当进行联合时,MySQL使用该索引的机会就越大。索引列所有值去重后的数量。该值除以该表的行数越接近1越好,如果非常小,则需要考虑是否可以删除该索引!
- Sub_part:数值 N 表示只对该列的前 N 个字符进行索引;NULL 表示索引整个列的值
- Packed:指示关键字是否被压缩,NULL 表示没有压缩
- Null:索引列是否可以为空
- Index_type:索引类型,BTREE 表示B+树索引。一共有四种(BTREE, FULLTEXT, HASH, RTREE)。
- Comment:注释
- Index_comment:注释
这里主要使用到两个值:
- SHOW TABLE STATUS中的 rows
- SHOW INDEX中的 cardinalit
一个值的重复次数 = row / cardinality
假设单点扫描区间有 1W个,如
|
|
rows 为9748,key1的cardinality为256
所以key1的每个值平均重复次数为: 9748 / 256 = 38.0
扫描区间1W 个,乘以 38(平均重复值),所以回表是 38W次
统计数据的收集
基于磁盘的永久统计信息存放在两个表中
- mysql.innodb_table_stats
- mysql.innodb_index_stats
innodb_table_stats 信息如下:
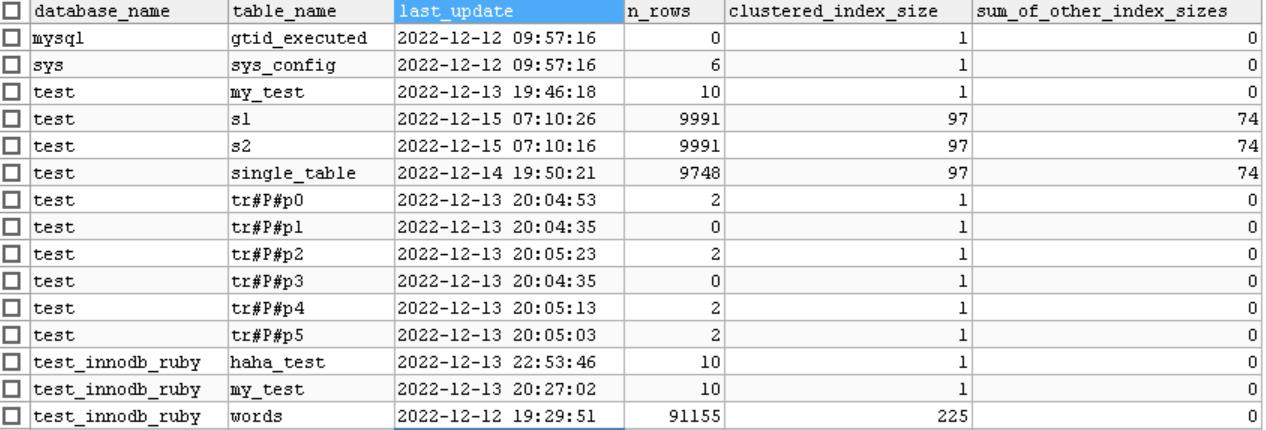 主要字段介绍
主要字段介绍
- n_rows表中记录数量
- clustered_index_size 聚集索引占用的page数量
- sum_of_other_sizes 其他索引占用的page数量
n_rows统计信息收集
通过系统变量:
|
|
来控制的
默认值是20,然后计算出 这 20个page中平均每个page包含的记录数量 avg_page
之后,统计全部叶子节点数量 N
总记录数 = N * avg_page
clustered_index_size、sum_of_other_sizes 统计信息
通过系统表空间的 SYS_INDEXES 找到各个索引对应的 根page
每个根page 都有这两个信息:
- PAGE_BTR_SEG_LEAF,B+树叶子段的头部信息,仅在B+树的Root页定义
- PAGE_BTR_SEG_TOP,B+树非叶子段的头部信息,仅在B+树的Root页定义
通过这个信息就可以找到 INode etnry
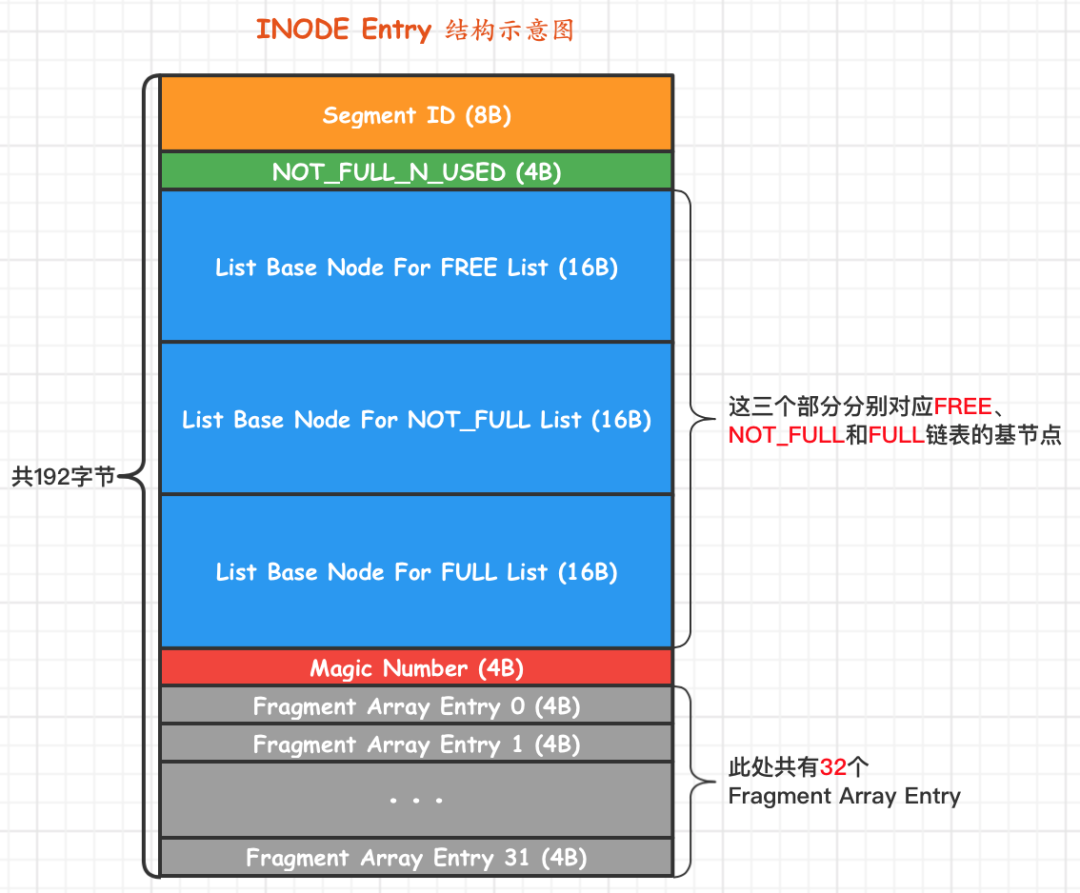
这里包含了三个 list base node 结构体

每个 list base node都包含了 List Length,也就是链表长度
每个节点对应一个区,一个区 64个page,那么链表节点 * 64 就是占用的page数量
因为一个区的page可能有些是空闲的,所以这里统计出来的会比实际的要大
如果想完全精准统计,需要继续遍历每个链表指向的 XDES entry
每个 XDES entry包含了一个 bit map,统计了当前区中64个page使用情况
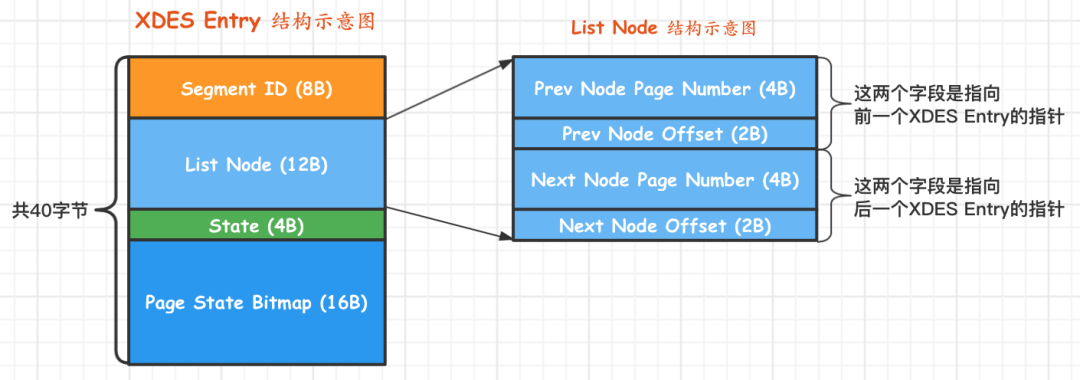
以上统计的是 clustered_index_size,sum_of_other_sizes也是同样的思路
innodb_index_stats 统计信息如下:
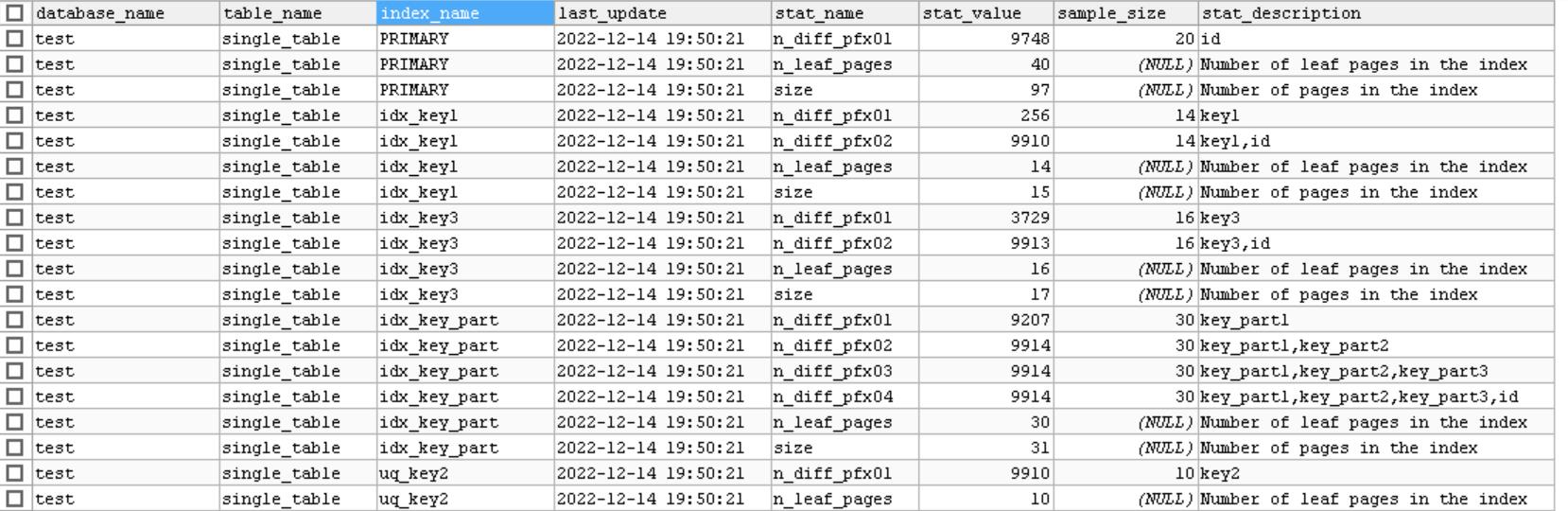 主要字段介绍
主要字段介绍
- stat_name,统计项的名称
- stat_value,对应的统计项的值
- sample_size,为生成统计数据而采样的page数量,统计索引中包含多少不重复的值的采样
- stat_description,统计项描述信息
stat_name信息
- n_leaf_pages,该索引的叶子节点实际占用的page数量
- size,该索引占用多少page,包括分配给叶子和非叶节点 但还没使用的page
- n_diff_pfxNN,索引不重复的值有多少
n_diff_pfxNN
- 对于主键、唯一索引,这一项只有一个
- idx_key1是普通索引,n_diff_pfx01 表示key1不重复的个数,n_diff_pfx02表示key1+id 不重复的个数
- idx_key_part有4个,n_diff_pfx01是key1不重复的,n_diff_pfx02是 key1 + key2不重复的,n_diff_pfx03 是key1 + key2 + key3 不重复的
- n_diff_pfx04是 key1 + key2 + key3 + id 不重复的
联合索引的采样 = innodb_stats_persistent_sample_pages * 索引中包含的字段个数
统计信息的更新
开启更新
|
|
如果表发生的数据变更超过了 10%,就会自动更新
也可以单独为表设置更新方式
手动更新
|
|
innodb_table_stats、innodb_index_stats 这两个表跟普通表一样,也是可以直接通过SQL更新的
更新完后要刷新
|
|
对待NULL的方式
|
|
三种方式
- nulls_equal,认为所有NULL都是相等的,默认值,如果某个列NULL很多,导致列平均重复次数很多,优化器不倾向于用索引
- nulls_unequal,认为所有NULL值都不等,倾向于使用所以
- nulls_ignored,忽略NULL值
调节成本常数
mysql.server_cost 表信息:
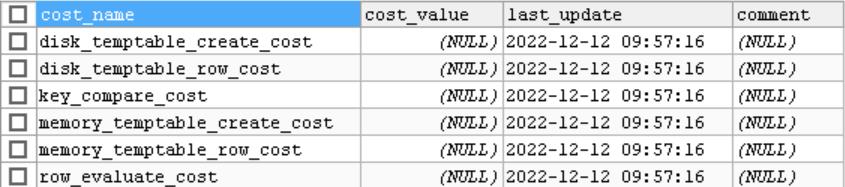
server层的操作成本常数
- disk_temptable_create_cost (default 40.0) 内部myisam或innodb临时表的创建代价
- disk_temptable_row_cost (default 1.0) 向基于磁盘的临时表写入、读取一条记录的成本,增大这个值会让优化器尽可能减少创建磁盘临时表
- key_compare_cost (default 0.1) 两个记录比较的代价,多用在排序中,增大此值会提升filesort成本,让优化器更倾向于使用索引
- memory_temptable_create_cost (default 2.0) 创建基于内存的临时表成本,增大会让优化器尽可能减少创建基于内存的临时表
- memory_temptable_row_cost (default 0.2) 向基于内存的临时表读、写一条记录的成本,增大此值会让优化器尽可能减少创建内存临时表
- row_evaluate_cost (default 0.2) 读取并检查一条记录是否符号搜索条件的成本,增大这个值会让优化器倾向于使用索引,而不是全表扫描
手动修改
|
|
这样查询的时候,就更倾向于使用基于磁盘的临时表
mysql.engine_cost 表信息:

这里增加一个了 device_type,用来区分机械硬盘、固态硬盘的,只是没用到
engine层操作成本常数
- io_block_read_cost (default 1.0) 从磁盘读数据的代价,对innodb来说,表示从磁盘读一个page的代价
- memory_block_read_cost (default 1.0) 从内存读数据的代价,对innodb来说,表示从buffer pool读一个page的代价
从磁盘和从内存中读取的成本都是 1.0,这是因为MySQL不能很好的预测,当前的数据page,到底是在硬盘上,还是在内存中
所以粗暴的认为都是从硬盘读,所以都是 1.0
JOIN优化
MySQL的JOIN实现方式
- 循环嵌套连接
- 使用索引加速
- 基于块的循环嵌套
查看 join_buffer_size,默认256K:
|
|
条件过滤 conditionfilering
两个表连接的成本
- 单词查询驱动表的成本
- 多次查询被驱动表的成本
这里把查询 驱动表后,得到的就称为:扇出,fanout,这个值越小越好
如果驱动表是全表扫描,那么扇出的值就是 表的记录数
如果有索引,就需要预估,比如主键、二级索引的 范围,单点区间扫描的成本预估等
如果查询条件中还有非索引的列,就只能用启发式搜索,预测了
查询:
|
|
要分区 s1还是s2 作为驱动表
- 假设uk_key2作为s1中索引成本最低的
- 使用uk_key2访问s1的成本 + s1的扇出值 * 使用uk_key2访问 s2的成本
- 使用uk_key2访问s2的成本 + s2的扇出值 * 使用Idx_key1访问s1的成本
优化重点:
- 进来减少驱动表的扇出
- 访问去被动表的成本尽可能低,也就是使用索引,最好是主键或者唯一索引
N表连接问题,$O(N!)$ 时间复杂度
- 提前结束某种连接顺序的成本评估
- 系统变量 optimizer_search_depth
- 启发式规则,即忽略某些连接规则
|
|
EXPLAIN
各个字段
explain中的各个字段
| 列名 | 描述 |
|---|---|
| id | 在一个大的查询语句中,每个SELECT关键字都对应一个唯一的ID |
| select_type | SELECT关键字对应的查询类型 |
| table | 表名 |
| partitions | 匹配的分区信息 |
| type | 针对单表的访问方法 |
| possible_keys | 可能用到的索引 |
| key | 实际使用的索引 |
| key_len | 实际使用的索引长度 |
| ref | 当使用索引列等值查询时,与索引列进行等值匹配的对象信息 |
| rows | 预估需要读取的记录数量 |
| filtered | 针对预估的需要读取的记录,经过搜索条件过滤后剩余记录的百分比 |
| Extra | 一些额外的信息 |
select_type
含义如下:
| select_type Value | JSON Name | Meaning |
|---|---|---|
| SIMPLE | None | Simple SELECT (not using UNION or subqueries) |
| PRIMARY | None | Outermost SELECT |
| UNION | None | Second or later SELECT statement in a UNION |
| DEPENDENT UNION | dependent (true) | Second or later SELECT statement in a UNION, dependent on outer query |
| UNION RESULT | union_result | Result of a UNION. |
| SUBQUERY | None | First SELECT in subquery |
| DEPENDENT SUBQUERY | dependent (true) | First SELECT in subquery, dependent on outer query |
| DERIVED | None | Derived table |
| DEPENDENT DERIVED | dependent (true) | Derived table dependent on another table |
| MATERIALIZED | materialized_from_subquery | Materialized subquery |
| UNCACHEABLE SUBQUERY | cacheable (false) | A subquery for which the result cannot be cached and must be re-evaluated for each row of the outer query |
| UNCACHEABLE UNION | cacheable (false) | The second or later select in a UNION that belongs to an uncacheable subquery (see UNCACHEABLE SUBQUERY) |
SIMPLE
不包含 UNION或者子查询的都是 SIMPLE
|
|
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | s1 | NULL | ALL | NULL | NULL | NULL | NULL | 9958 | 100.0 | NULL |
PRIMARY
包含UNION、UNION ALL、或者子查询的大查询,其由好几个部分组成,最左边的select_tupe就是PRIMARY
|
|
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | PRIMARY | s1 | NULL | ALL | NULL | NULL | NULL | NULL | 9958 | 100.0 | NULL |
| 2 | UNION | s2 | NULL | ALL | NULL | NULL | NULL | NULL | 9958 | 100.0 | NULL |
| NULL | UNION RESULT | <union1,2> | NULL | ALL | NULL | NULL | NULL | NULL | 9958 | 100.0 | NULL |
UNION
UNION RESULT
这两个在上面已经展示了,其中 UNION RESULT用作去重的,如果是 UNION ALL则没有这一步
SUBQUERY
如果子查询不能转为半连接查询,并且该子查询是 不相关子查询,则将子查询物化执行
如下外层的是PRIMARY,内层的子查询会被物化,只执行一次
|
|
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | PRIMARY | s1 | NULL | ALL | NULL | NULL | NULL | NULL | 9958 | 100.0 | Using where |
| 2 | SUBQUERY | s2 | NULL | ALL | NULL | NULL | NULL | NULL | 9958 | 100.0 | NULL |
DEPENDENT SUBQUERY
如果包子查询不能转为半连接,该子查询能被转为相关子查询
这种子查询意味着可能会被执行多次
|
|
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | PRIMARY | s1 | NULL | ALL | idx_key3 | NULL | NULL | NULL | 9991 | 100.0 | Using where |
| 2 | DEPENDENT SUBQUERY | s2 | NULL | ref | uq_key2,idx_key1 | uq_key2 | 5 | test.s1.key2 | 1 | 100.0 | Using where |
DEPENDENT UNION
其子查询可能会被执行多次
大查询包含子查询,子查询又包含UNION 的两个小查询,其select_type就是 DEPENDENT SUBQUERY
而SELECT key1 FROM s1 WHERE key1 = 'b' 这个小查询的 select_type 就是 DEPENDENT UNION
|
|
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | PRIMARY | s1 | NULL | ALL | NULL | NULL | NULL | NULL | 9991 | 100.0 | Using where |
| 2 | DEPENDENT SUBQUERY | s2 | NULL | ref | idx_key1` | idx_key1 | 103 | const | 1 | 100.0 | Using where |
| 3 | DEPENDENT UNION | s1 | NULL | ref | idx_key1 | idx_key1 | 103 | const | 1 | 100.0 | Using where |
| NULL | DEPENDENT RESULT | <union2,3> | NULL | ALL | NULL | NULL | NULL | NULL | NULL | NULL | Using temporary |
再看这个SQL
|
|

DERIVED
|
|
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | PRIMARY | NULL | ALL | NULL | NULL | NULL | NULL | 9958 | 100.0 | Using where | |
| 2 | DERIVED | s1 | NULL | ALL | NULL | NULL | NULL | NULL | 9958 | 100.0 | Using temporary; Using filesort |
MATERIALIZED
将子查询物化之后,与外层查询进行连接查询
如下第3 条记录就是 MATERIALIZED,优化器将子查询转为物化表,前两条记录的id 都是1,说明对应的表是连接查询
第二条记录的table是,说明对物化之后的表做的查询,然后再将s1和该物化表做连接查询
|
|
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | s1 | NULL | ALL | NULL | NULL | NULL | NULL | 9958 | 100.0 | Using where |
| 1 | SIMPLE | <subquery2> | NULL | eq_ref | <auto_key> | <auto_key> | 103 | test.s1.key1 | 1 | 100.0 | NULL |
| 2 | MATERIALIZED | s2 | NULL | ALL | NULL | NULL | NULL | NULL | 9958 | 100.0 | Using temporary; Using filesort |
partitions
准备数据
|
|
查询
|
|
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | tr | p5 | ALL | NULL | NULL | NULL | NULL | 9958 | 100.0 | Using where |
type
system
只有一条数据,并且统计是精准时
|
|
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | t | NULL | system | NULL | NULL | NULL | NULL | 1 | 100.0 | NULL |
const
当使用主键 或者唯一二级索引 进行常数匹配
|
|
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | t | NULL | const | PRIMARY | PRIMARY | 4 | CONST | 1 | 100.0 | NULL |
eq_ref
被驱动表通过 主键、唯一二级索引列进行等值匹配时
|
|
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | s1 | NULL | ALL | idx_key1 | NULL | NULL | NULL | 9991 | 100.0 | Using where |
| 1 | SIMPLE | s2 | NULL | ref | idx_key1 | idx_key1 | 103 | test.s1.id | 39 | 100.0 | NULL |
ref
对普通二级索引与常量等值匹配时
|
|
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | s1 | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.0 | NULL |
| 1 | SIMPLE | s2 | NULL | eq_ref | PRIMARY | PRIMARY | 4 | test.s1.id | 1 | 100.0 | NULL |
单表查询
|
|
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | single_table | NULL | ref | idx_key1 | idx_key1 | 103 | const | 1 | 100.0 | NULL |
fulltext
全文索引
ref_or_null
对普通二级索引与常量等值匹配时,并且该索引列的值也可以为NULL时
|
|
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | s1 | NULL | ref_or_null | idx_key1 | idx_key1 | 103 | const | 2 | 100.0 | Using index condition |
index_merge
一般只会为单个索引生成扫描区间,但某些情况下会生成索引何彪
- Intersection
- Union
- Sort-Union
- 注意,MySQL 没有Sort-Intersection,不过 mariadb 有这个功能
|
|
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | s1 | NULL | index_merge | idx_key1,idx_key3 | idx_key1,idx_key3 | 103,103 | NULL | 2 | 100.0 | Using union(idx_key1,idx_key3);Using where |
unique_subquery
类似于eq_ref,针对一些包含IN子句的查询语句
如果可以将IN转为EXIST,并使用主键,或者唯一二级索引时
|
|
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | PRIMARY | s1 | NULL | ALL | idx_key3 | idx_key1 | NULL | NULL | 9991 | 100.0 | Using where |
| 2 | DEPENDENT SUBQUERY | s2 | NULL | unique_subquery | PRIMARY | PRIMARY | 4 | func | 1 | 10.0 | Using where |
index_subquery
跟unique_subquery类似,使用的是普通索引
|
|
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | PRIMARY | s1 | NULL | ALL | idx_key3 | NULL | NULL | NULL | 9991 | 100.0 | Using where |
| 2 | DEPENDENT SUBQUERY | s2 | NULL | index_subquery | idx_key3 | idx_key3 | 103 | func | 2 | 10.0 | Using where |
range
范围查询
|
|
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | s1 | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 4 | 100.00 | Using where |
index
使用覆盖索引
|
|
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | s1 | NULL | index | NULL | id_key_part | 309 | NULL | 9991 | 10.00 | Using where; Using index |
下面这种情况,对id做排序,也会变成index类型
|
|
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | s1 | NULL | index | NULL | id_key_part | 4 | NULL | 9991 | 10.00 | NULL |
ALL
全表扫描
|
|
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | s1 | NULL | ALL | NULL | NULL | NULL | NULL | 9991 | 100.00 | NULL |
EXPLAIN其他字段
key_len:实际使用的索引长度
比如某次查询 key_len为 103,100是varchar长度,ascii类型的
因为是变长,所以+2,又因为允许为NULL,又+1, 所以是 103
如果扫描区间为 SELECT key_par1 = ‘a’ AND key_part2 > ‘b’
则使用key_len 为 103 * 2
ref
当访问方式是 const、eq_ref、ref、ref_or_null、unique_subquery、index_subquery中的一个时
ref列展示的就是与索引等值匹配的东西是什么
比如一个常数,一个具体的列名字: test.s1.id、或者是一个函数(显示为func)
filter
主要用在多表连接时
- 使用全表扫描的方式执行单表查询,驱动表扇出就是全部搜索记录是多少条
- 使用索引时,计算驱动表扇出时要预估满足形成索引扫描区间的搜索条件外,还满足其他搜索条件的记录有多少条
|
|
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | s1 | NULL | ALL | idx_key1 | NULL | NULL | NULL | 9991 | 10.0 | Using where |
| 2 | SIMPLE | s2 | NULL | ref | idx_key1 | idx_key1 | 103 | test.s1.key1 | 39 | 100.0 | Using where |
id = 1的是驱动表,rows为:9991
filter的10.0表示:对s1 的扇出值为: 9991 * 10% = 999条
Extra
官方解释 -> 这里
No tables used
查询语句中没有FROM 子句时
|
|
Impossible WHERE
查询语句的WHERE 为FALSE时
|
|
No matching min/max row
当查询列表处有 MIN、MAX时,但并没有记录符合WHERE 子句中的搜索条件
|
|
Using index
使用覆盖索引
|
|
Using index condition
使用索引下推,只适合二级索引,下面SQL会查找出key1 > ‘z’,但是不回表,继续判断是否满足 ‘%a’,提高效率
|
|
Using WHERE
在 server层做判断时
|
|
Using join buffer(Block Nested Loop)
被驱动表不能有效利用索引时,分配了一块连接缓冲区
|
|
Using intersect
还包括Using union、Using sort_union
说明使用了索引合并的方式
|
|
Zero limit 当limit子句的参数为0时
|
|
Using filesort
使用排序时
|
|
Using temporary
使用临时表时
|
|
下面这种语句就会使用临时表 + 排序,虽然没有排序,但是Mysql 默认对于使用 GROUP BY 加了 ORDER BY
|
|
Start temporary, End tmporary
优化器会尝试将 IN子查询 转为半连接,当执行策略为 Duplicate Weedout时,是通过建立临时表来做去重
驱动表的执行计划Extra会显示 Start temporary提示,被驱动表的Extra会提示 End temporary
LooseScan
当 IN子查询转为半连接时,采用松散扫描时
|
|
FirstMatch
将 IN子查询转为半连接时,采用 first-match方式,被驱动表的Extra则会有提示
|
|
JSON格式的执行计划
查询:
|
|
执行结果:
|
|
optimizer trace
查看状态
|
|
开启:
|
|
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | s1 | NULL | range | uq_key2,idx_key1,idx_key3 | idx_key1 | 103 | NULL | 1 | 5.0 | Using index condition; Using where |
查询:
|
|
查询结果
|
|
优化过程:
|
|
参考
- MySQL的EXPLAIN官方介绍
- MySQL工具之innodb_ruby:探究InnoDB存储结构的利器
- Yum 安装 mysql 5.7
- py_innodb_page_info
- CREATE TABLESPACE Statement
- ANALYZE TABLE Statement
- SHOW INDEX Statement
- MySQL · 特性分析 · 5.7 代价模型浅析
- 庖丁解牛-MySQL查询优化器之JOIN ORDER
- EXPLAIN Extra Information
- MySQL之表连接原理
- MySQL之单表访问方法
- MySQL之单表查询成本
- MySQL之连接查询成本
- MySQL之执行计划详解(一)
- MySQL之执行计划详解(二)
- MySQL之基于规则的优化特性(一)
- MySQL之基于规则的优化特性(二)
- MySQL之基于规则的优化特性(三)
- MySQL之profiling、optimizer trace