MySQL的恢复
redo log
redo log特点
- 直接将数据刷磁盘是 随机I/O行为,redo log则是顺序I/O行为
- redo 本身比 纯数据要小很大,而数据page一写就是 16K为单位写入的
- 基本是纯物理格式,也有物理+逻辑格式,比 binlog更底层
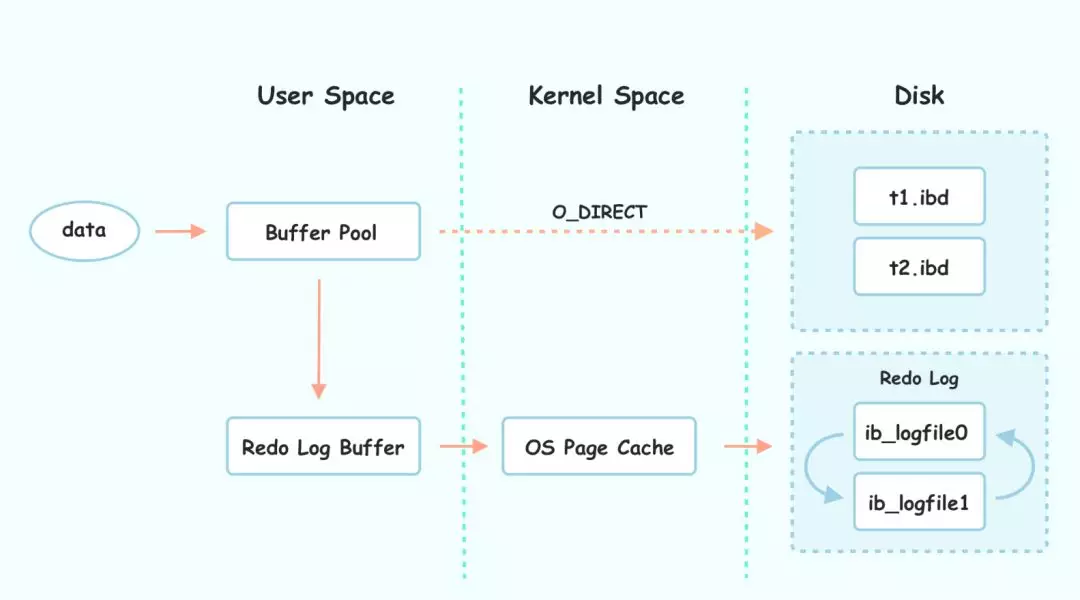
redo log格式
redo log大致可以分为三类
- 作用于Page的REDO,这种占大多数,如:Index Page REDO,Undo Page REDO,Rtree PageREDO
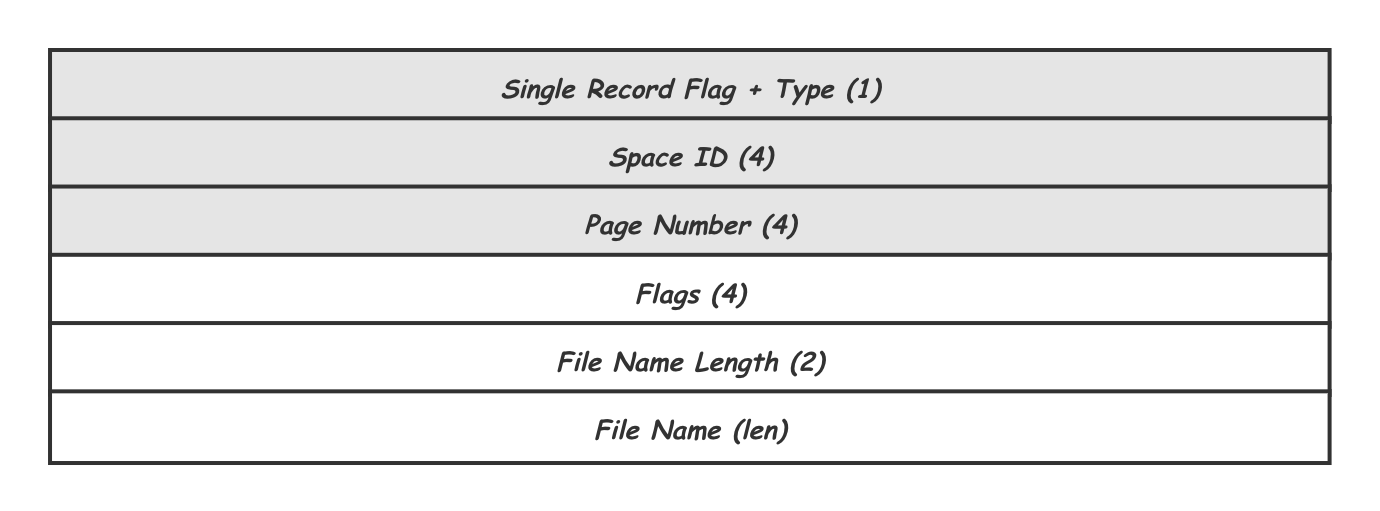
- 作用于Space的REDO,针对space的操作,如:MLOG_FILE_CREATE,MLOG_FILE_DELETE,MLOG_FILE_RENAME
- 提供额外信息的Logic REDO,如MLOG_MULTI_REC_END
通用的redo log格式如下:

如果没有主键,mysql会自动生成 row_id,而每当这个值是 256的倍数,就会刷到系统表空间7号page
这种操作只需要记录,哪个表空间、哪个page、offset是什么就可以了,属于简单格式
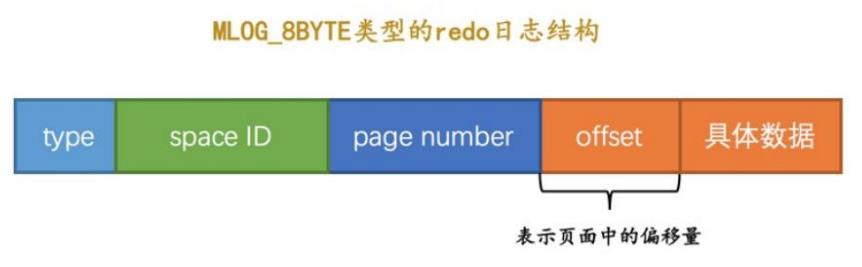
简单格式的redo log如下:
- MLOG_1BYTE(type字段对应的2进制数字为1):表示在⻚⾯的某个偏移量处写⼊1个字节的redo⽇志类型
- MLOG_2BYTE(type字段对应的2进制数字为2)
- MLOG_4BYTE(type字段对应的2进制数字为4)
- MLOG_8BYTE(type字段对应的2进制数字为8)
- MLOG_WRITE_STRING(type字段对应的2进制数字为30)
比如插入的时候,B+ 树分裂了,或者下图这样,更新了一个page的很多记录,这会引发很多更新:
- FileHeader、Page Header、Page Directory
- PAGE_N_DIR_SLOTS,page中的槽子数量
- PAGE_HEAP_TOP,还未使用的最小空间地址
- PAGE_N_HEAP,page中的记录数量
- 下一条记录的next_record指针
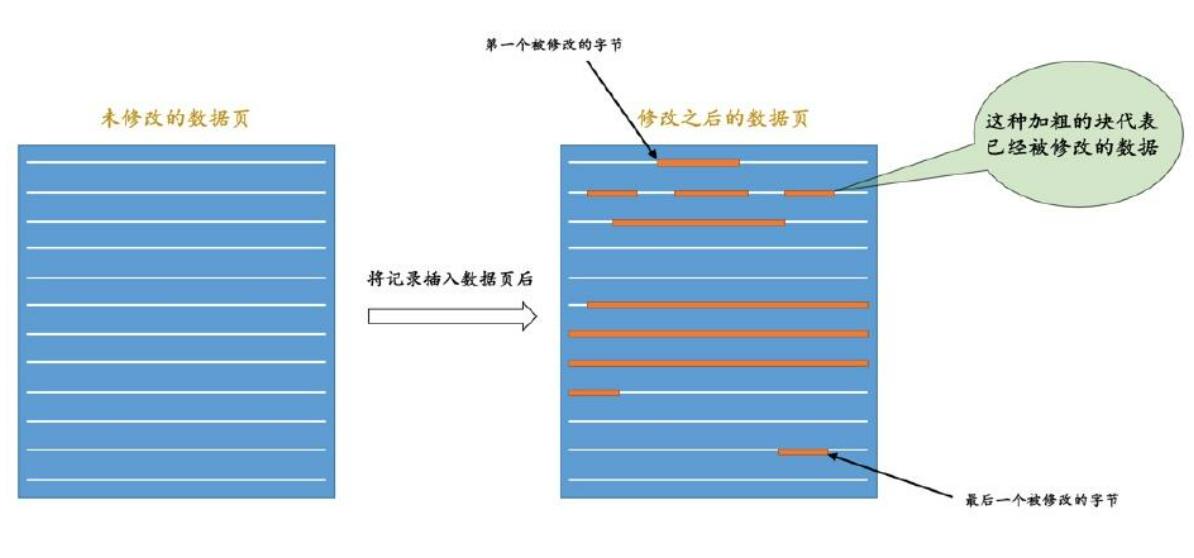
一些复杂的 redo log格式:
| type | description |
|---|---|
| MLOG_REC_INSERT | 表示插以条使非紧凑格式的记录时的redo志类型 |
| MLOG_COMP_REC_INSERT | 插入紧凑格式的记录 |
| MLOG_COMP_PAGE_CREATE | 创建紧凑格式记录 |
| MLOG_COMP_REC_DELETE | 删除一条记录 |
| MLOG_COMP_LIST_START_DELETE | 从这里开始删除记录 |
| MLOG_COMP_LIST_END_DELETE | 跟上面配套使用,表示结束删除 |
| MLOG_ZIP_PAGE_COMPRESS | 一条压缩记录 |
下面是 一条 MLOG_COMP_REC_INSERT 类型的redo log:
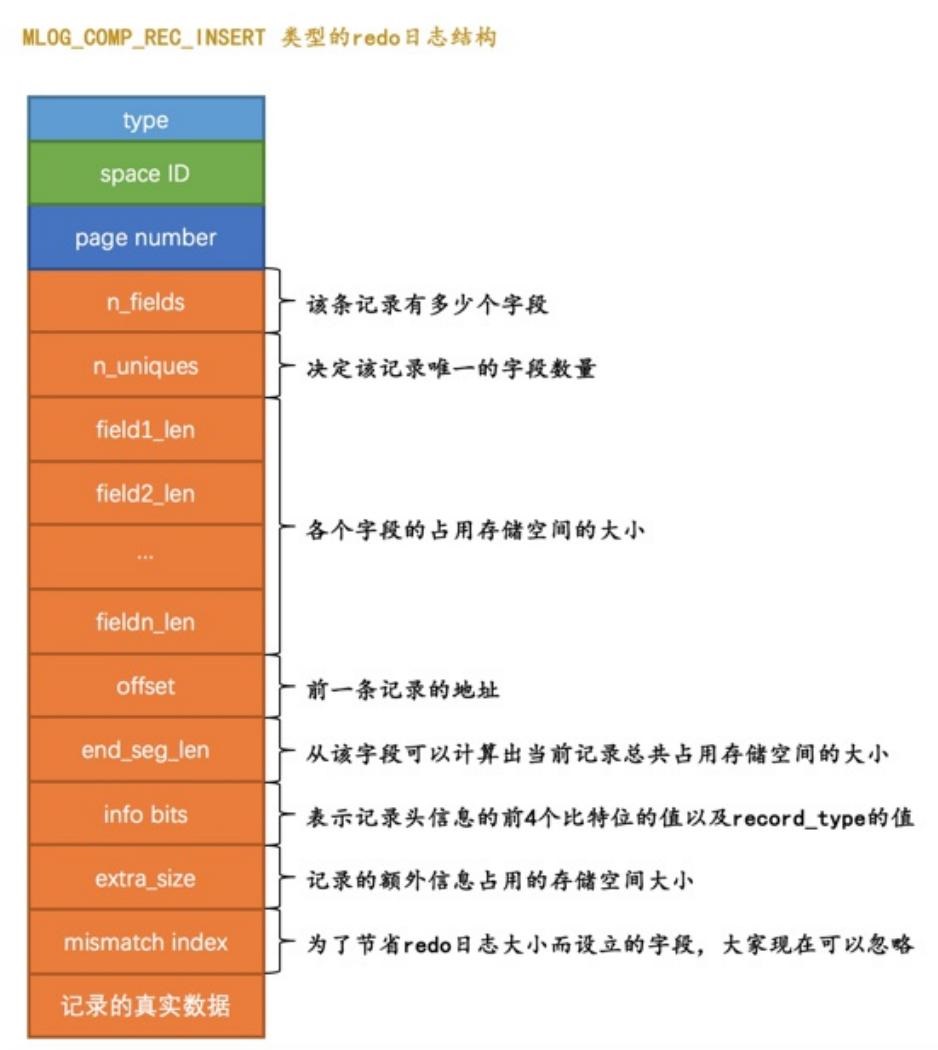
n_uniques,主键是一个字段,联合主键多个,二级索引是包含的列+主键
从这里也可以看到,这种复杂性的redo log是物理+逻辑混合的
物理上,它标注了表空间iD,page号,这种是属于物理级别的
但它记录了并不纯粹是物理信息,相当于是用这些信息,组成了一个逻辑的插入语句
等恢复的时候,通过这些信息,调用对应的恢复函数,变成一次insert插入,就可以真正还原了
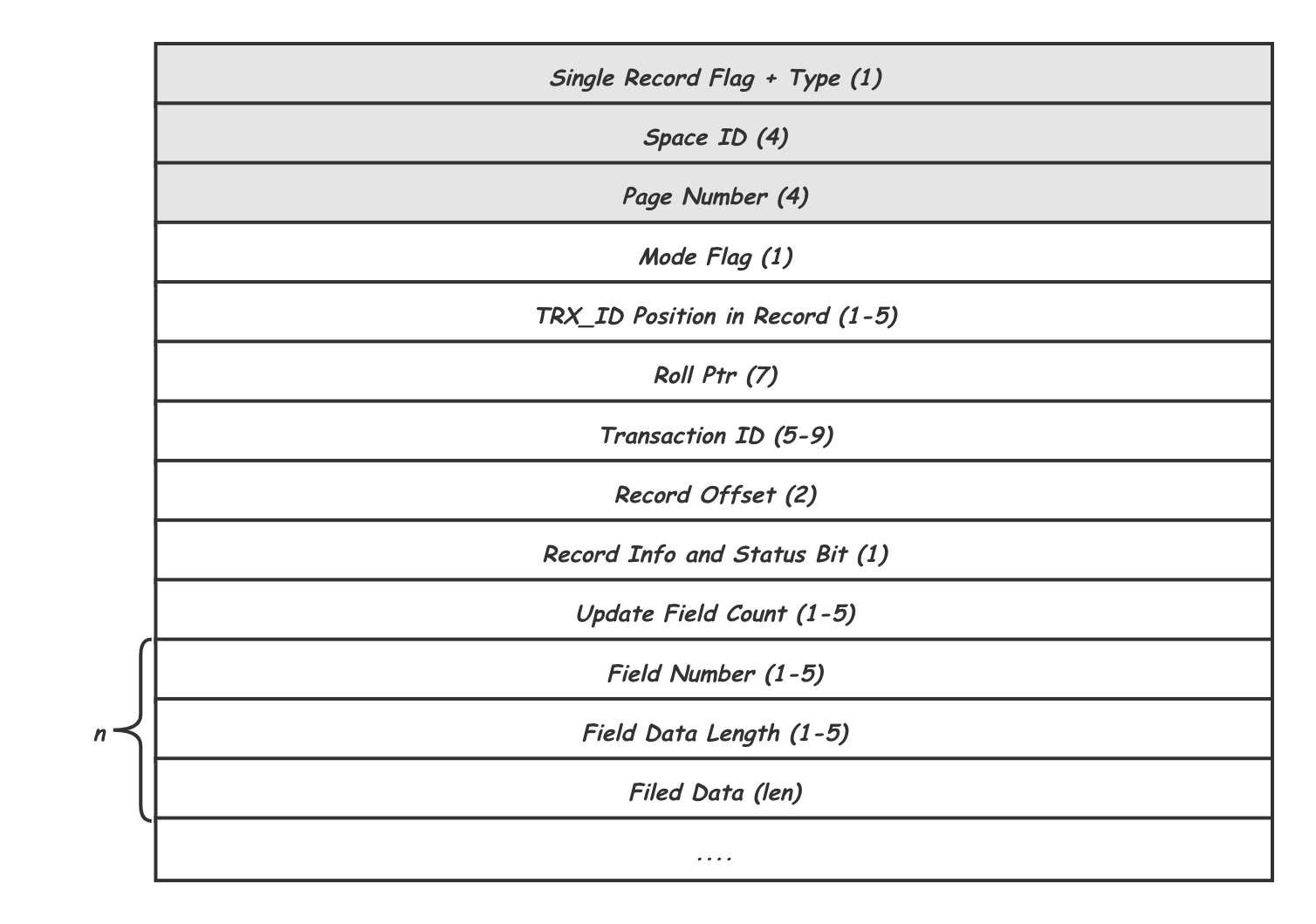
MLOG_REC_UPDATE_IN_PLACE 内容格式
MLOG_FILE_CREATE 内容格式
Mini-Transaction
插入一条数据时,B+树可能会分裂,此时可能需要修改好几个page,也就会记录更多的redo log
这些redo log应该是以事务的方式出现,他们是不可分割的
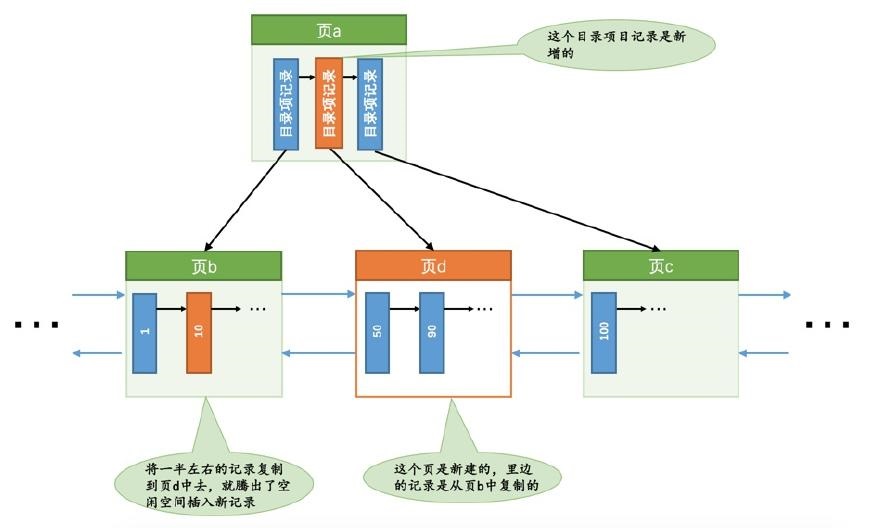
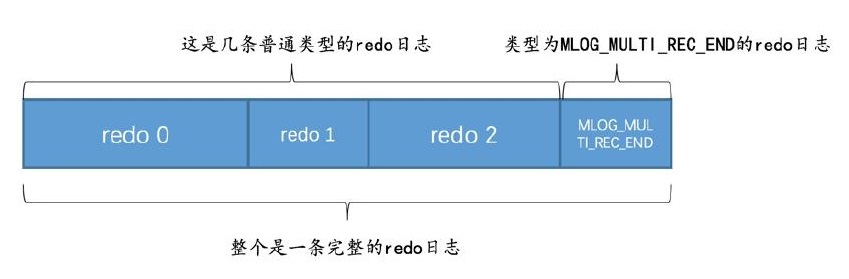
比如上面的分裂,会导致修改很多地方,比如该系一些系统的page,修改各种段、区的统计信息,各种FREE、FSP_FREE_FRAG链表的信息等等
以上这些操作都必须是原子的,组织成一个事务
于是就有MLOG_MULTI_REC_END这种类型的 redo log
它的结构很简单,只有一个typ字段
一组完整的redo log事务,只要后面以 MLOG_MULTI_REC_END结尾即可,当然一个普通的MLOG_8BYTE也可以用 MLOG_MULTI_REC_END结尾
每个redo log类型的第一个bit用来标识是否是原子性的
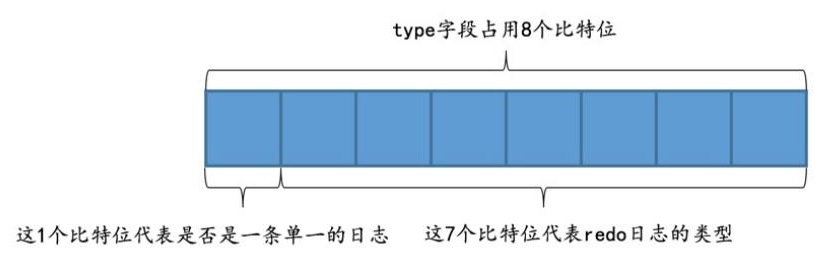
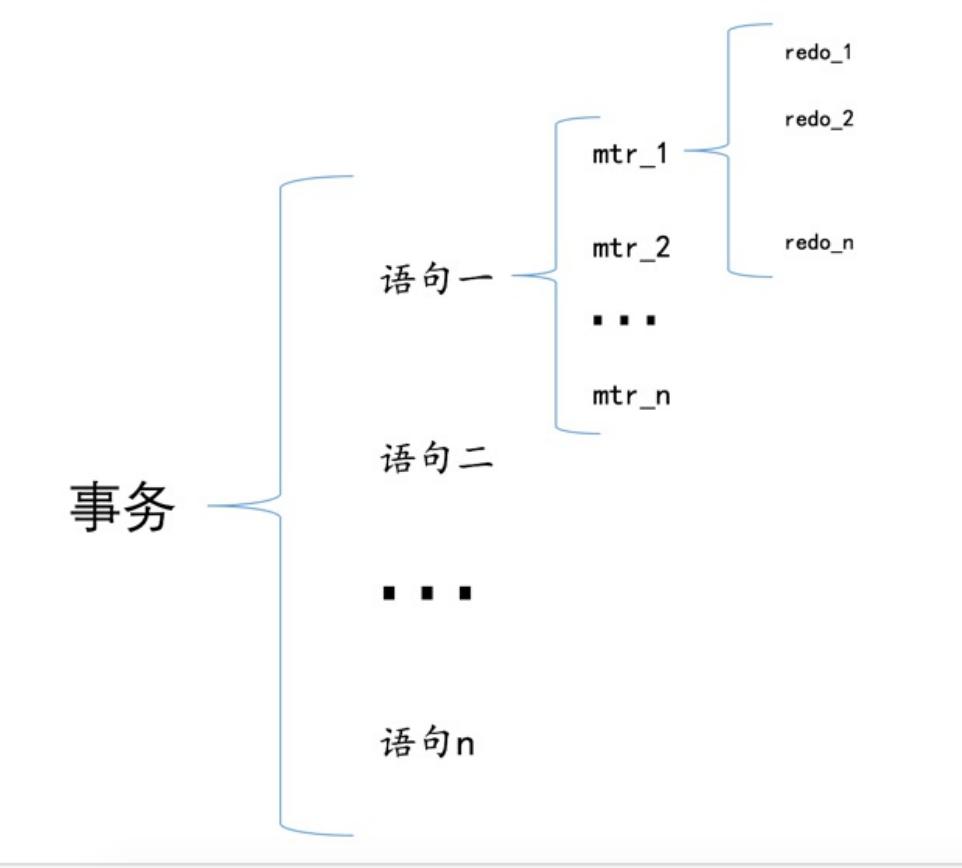
Mini-Transaction,简称mtr
一个mtr可以包含一组redo log,他们表示不可分割
一个事务可以由多个语句组成,而一个语句又包含多个 mtr,一个mtr包含多个redo log
他们的关系如下:
redo log写入过程
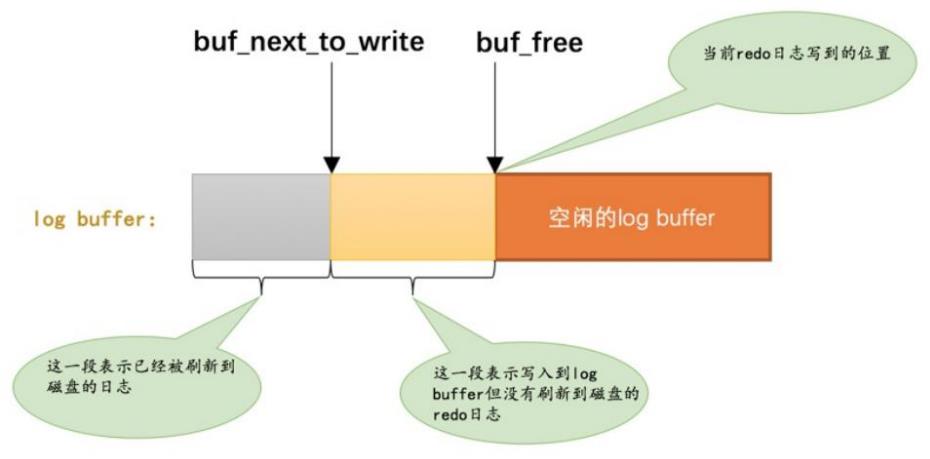
mtr生成的log被放在一个 512字节的块中,格式如下:
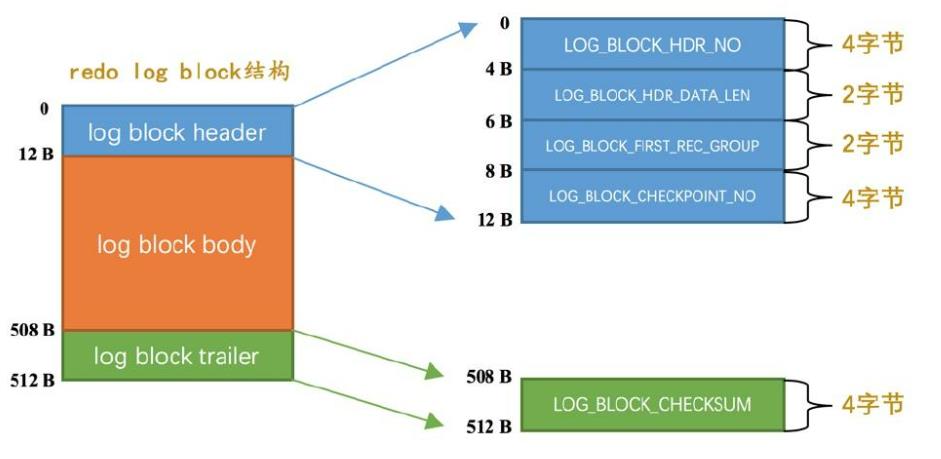
参数解释:
- LOG_BLOCK_HDR_NO,每个block都有一个大于0的唯一标识
- LOG_BLOCK_HDR_DATA_LEN,block中已经使用了多少字节,从12开始,因为头占了12字节,满了就是512
- LOG_BLOCK_FIRST_REC_GROUP,该block中第一个mtr的第一redo log偏移量
- LOG_BLOCK_CHECKPOINT_NO,checkpoint序号
- LOG_BLOCK_CHECKSUM,尾部的校验和
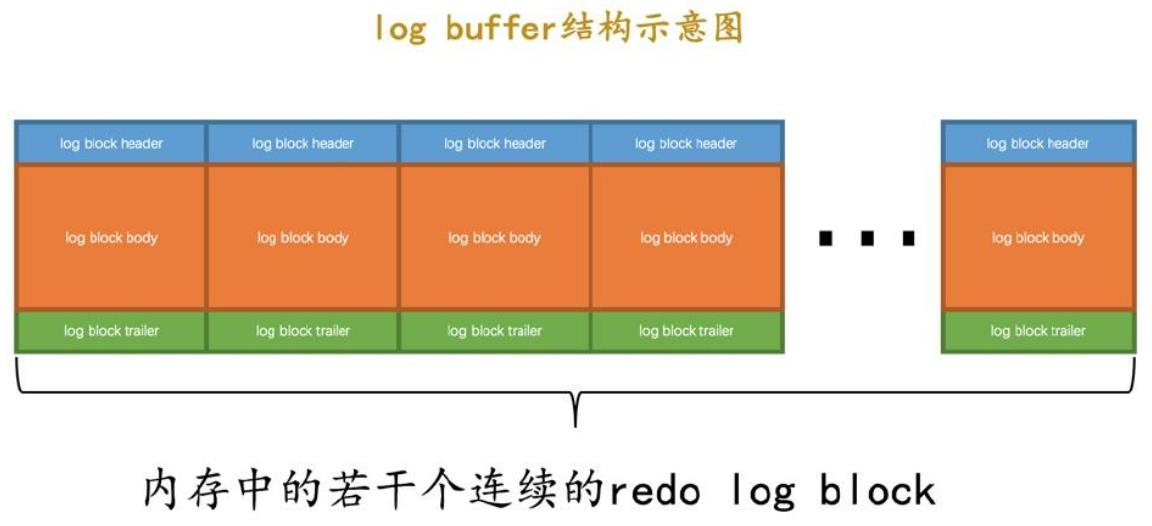
redo log的缓冲区结构如下,就是把一堆 block连在一起而已
查看redo log的缓冲区大小 命令,默认为 16M
|
|
多个事务的写入,是混杂在一起的,交错的连续存放,其中全局变量 buf_free指向的位置,表示后面都是空闲的
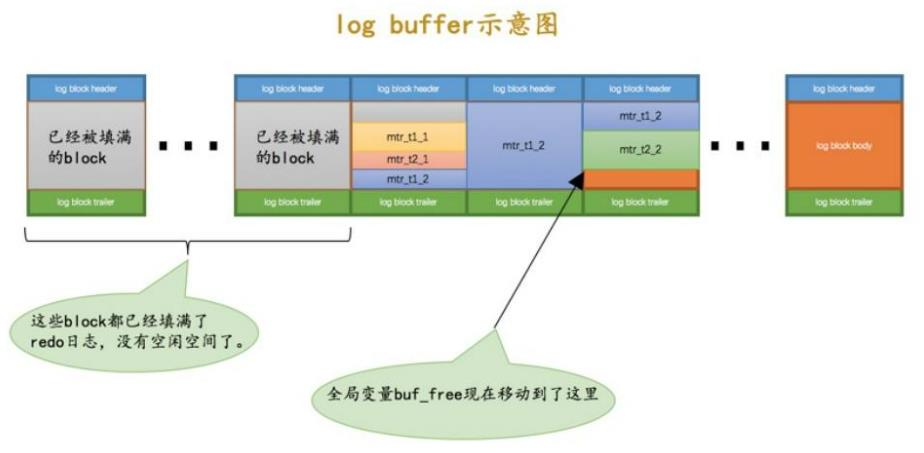
从8.0 开始,设计了一套无锁的写log机制,最大限度的保证了并发性
首先会根据自身的 redo log长度,计算出对应在 log buffer中的占用空间,这部分空间就是独占的,不会有并发
写入 page cache
InnoDB中有单独的log_writer来做这件事情
InnoDB在这里引入一个叫做link_buf的数据结构
link_buf是一个循环使用的数组,对每个lsn取模可以得到其在link_buf上的一个槽位,在这个槽位中记录REDO长度。另外一个线程从开始遍历这个link_buf,通过槽位中的长度可以找到这条REDO的结尾位置,一直遍历到下一位置为0的位置,可以认为之后的REDO有空洞,而之前已经连续,这个位置叫做link_buf的tail
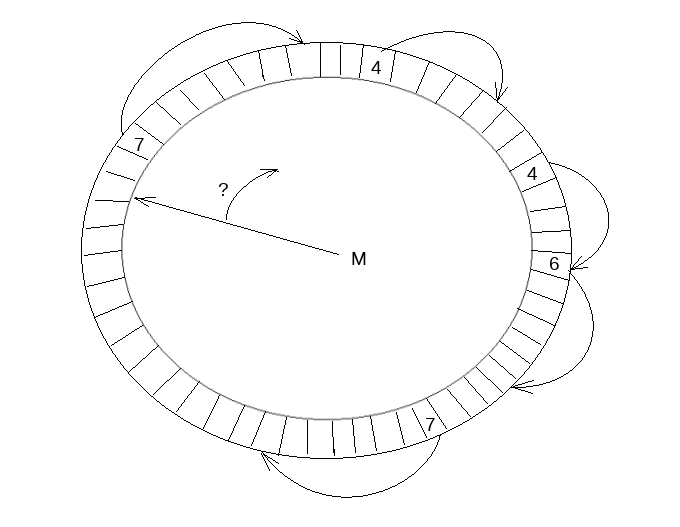
log_writer 和众多mtr利用这个link_buf数据结构完成写入过程:
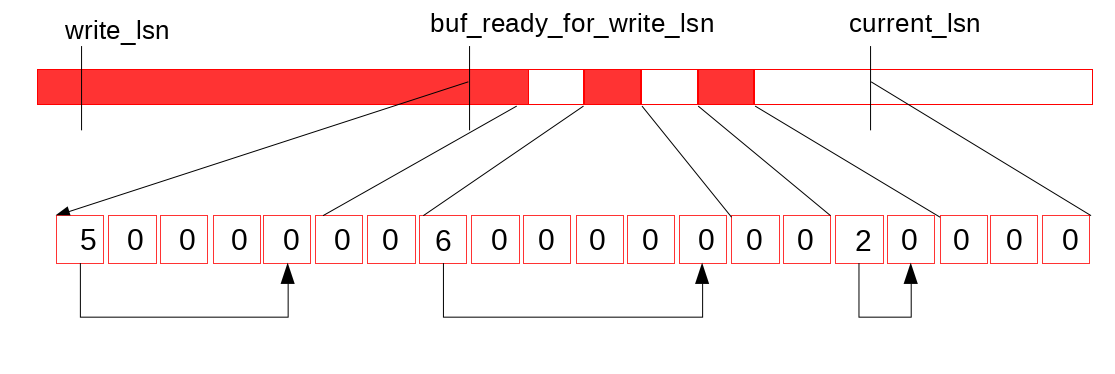
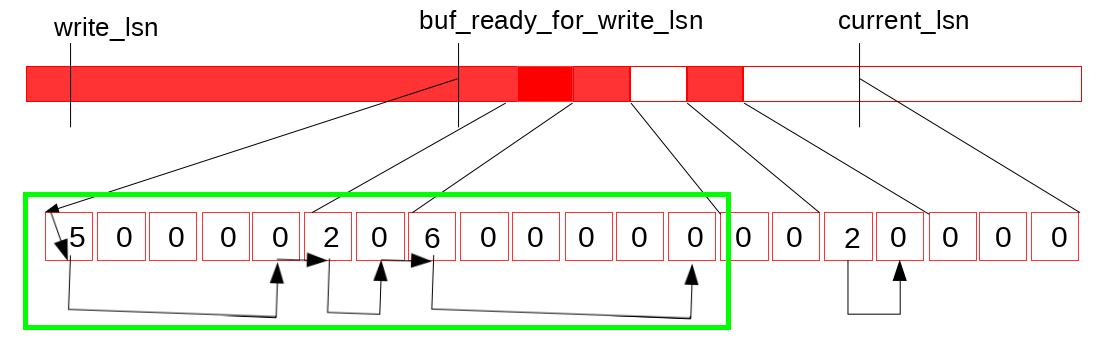
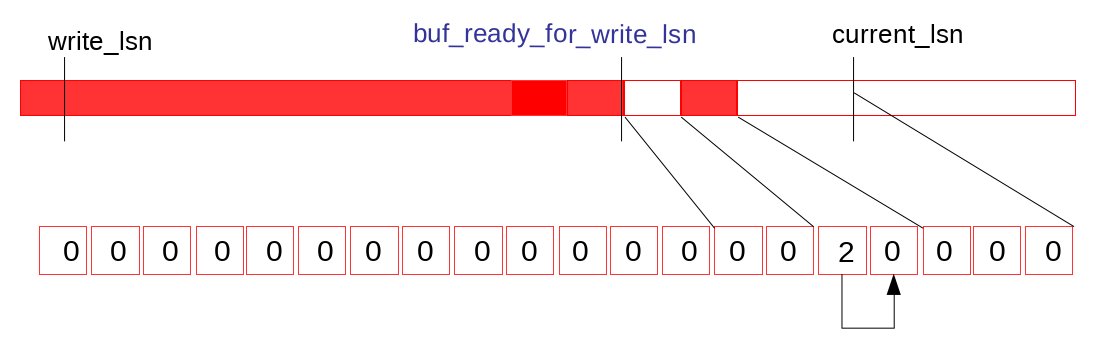
三个变量
- write_lsn是当前log_writer已经写入到Page Cache中日志末尾
- current_lsn是当前已经分配给mtr的的最大lsn位置
- buf_ready_for_write_lsn是当前log_writer找到的Log Buffer中已经连续的日志结尾
从write_lsn到buf_ready_for_write_lsn是下一次log_writer可以连续调用pwrite写入Page Cache的范围
从buf_ready_for_write_lsn到current_lsn是当前mtr正在并发写Log Buffer的范围
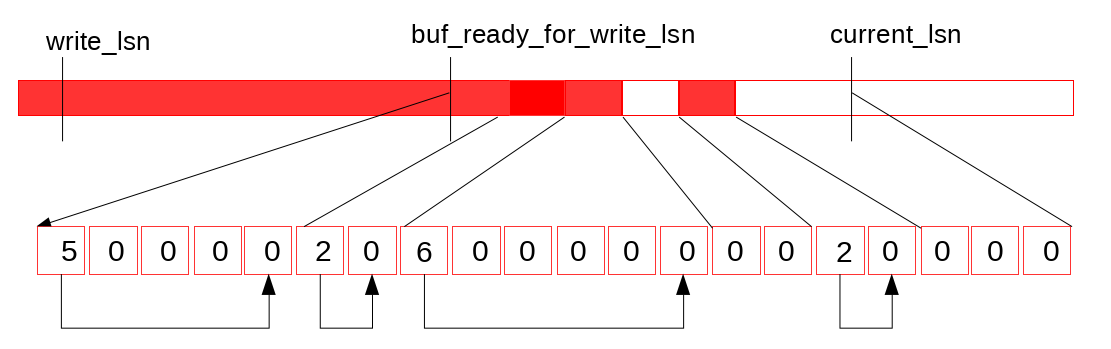
一开始有空洞,就是不连续的红色部分,等写完之后红色部分连续了,将buf_ready_for_write_lsn向前滑动,红色部分清零,就可以重复使用了
紧接log_writer将连续的内容刷盘并提升write_lsn
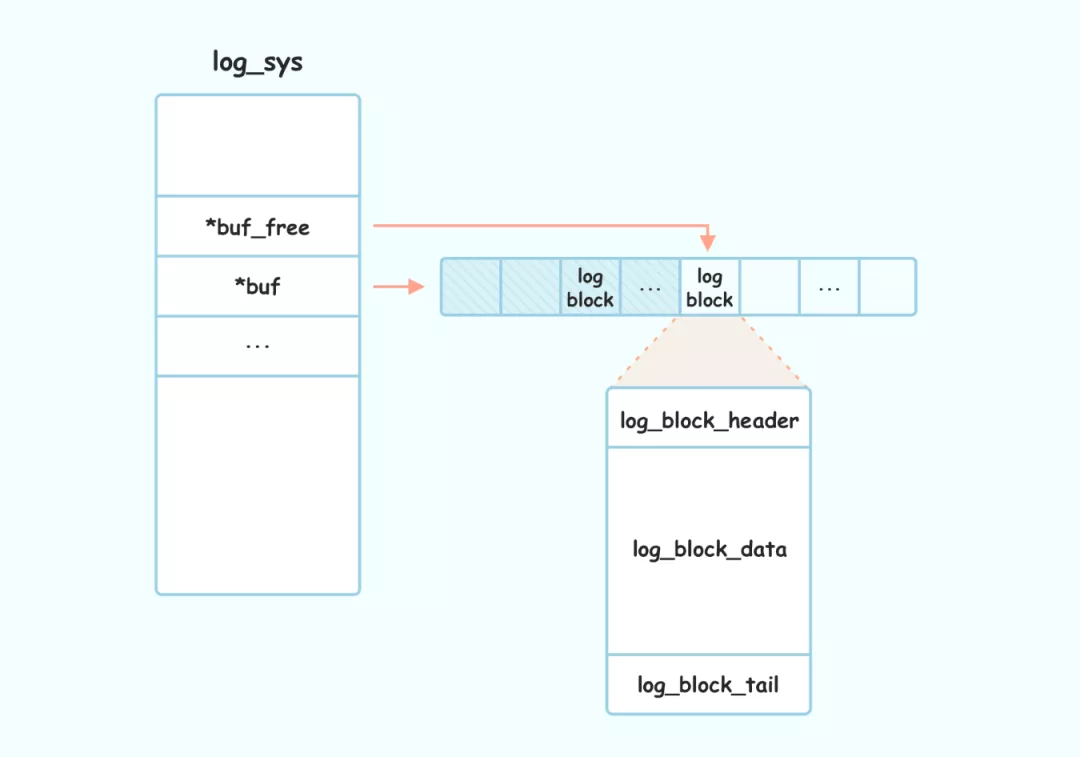
管理redo log的log_sys
InnoDB 使用 log_sys 这个对象来管理 Redo Log Buffer,其结构体为 log_t
log_t路径为: /innobase/include/log0log.h
log_sys 主要包含的元数据:
| 参数 | 描述 |
|---|---|
| lsn | 日志序列号 |
| buf_free | 当前log buffer空闲空间的起始位置 |
| buf | log buffer的起始位置 |
| write_lsn | 最新写入的lsn |
| flushed_to_disk_lsn | 已刷新到redo log文件中的lsn |
| last_checkpoint_lsn | 最近执行检查点的lsn |
log_sys的初始化由log_init()函数实现
位置:/innobase/log/log0log.cc
log_sys 个 log_block的关系如下:
redo log文件格式
也就是存储在硬盘上的redo log格式
几个参数:
- innodb_log_group_home_dir,redo log文件所在目录,默认是数据目录
- innodb_log_file_size,每个redo log文件大小,默认为48M
- innodb_log_files_in_group,文件个数,默认为2个
默认的文件名为:
ib_logfile0、ib_logfile1
redo log总大小就是: innodb_log_file_size * innodb_log_files_in_group
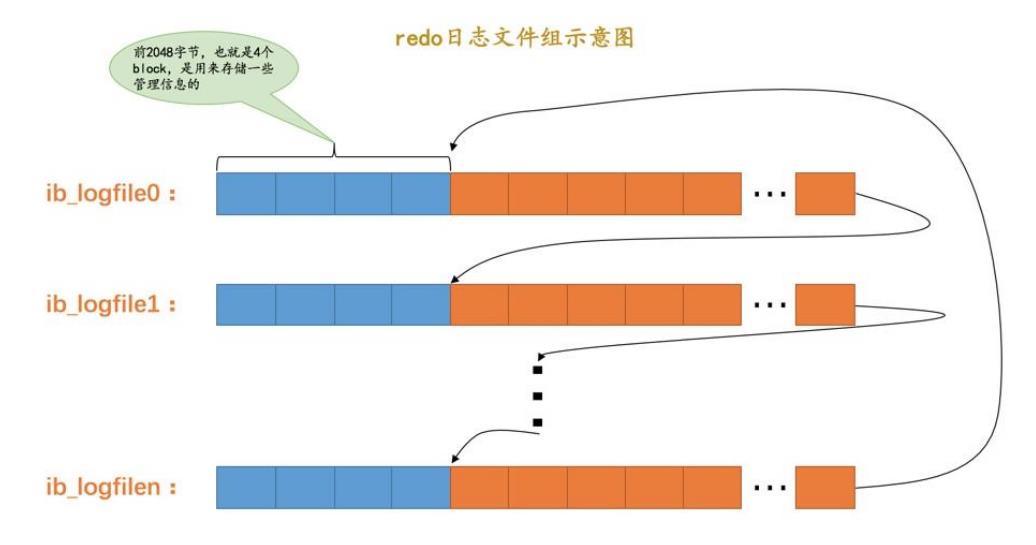
log buffer会将一片连续的内存刷新到磁盘,所以硬盘上的redo log格式跟log buffer的一样
也是按照 512一个block组织的
不过的是前面 4个block,2048字节有特殊用途,后面就跟正常的 block一样了
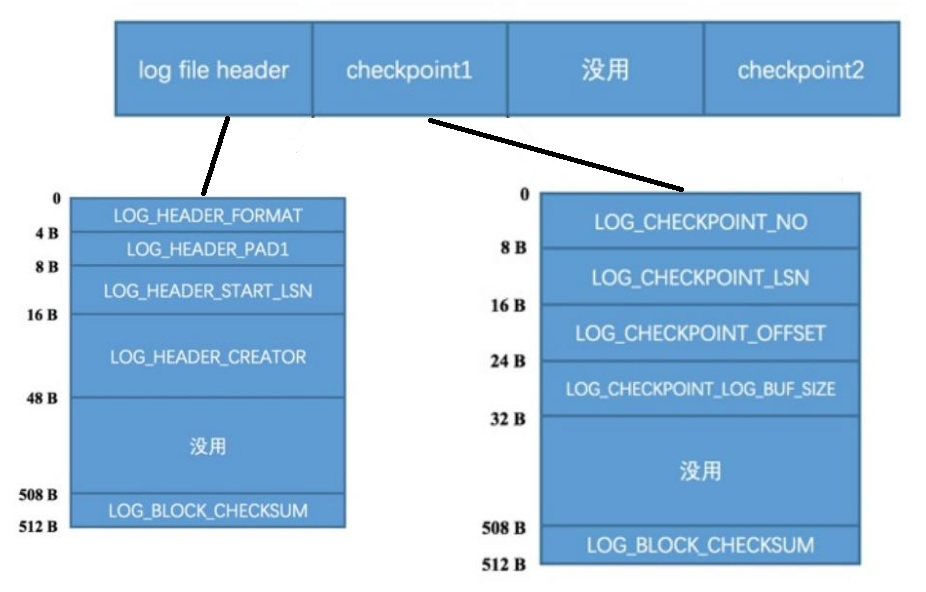
redo log的前4个block
- log file header,512字节
- LOG_HEADER_FORMAT(4B),redo log的版本
- 1LOG_HEADER_PAD1(4B),无意义
- LOG_HEADER_START_LSN(8B),LSN值
- LOG_HEADER_CREATOR(32B),创建者,如"MySQL5.7",“ibbackup”等
- 后面460字节没用
- LOG_BLOCK_CHECKSUM(4B)
- checkpoint1
- LOG_CHECKPOINT_NO(8B),每做一次checkpoint,该值就+1
- LOG_CHECKPOINT_LSN(8B),checkpoint结束后的LSN,崩溃恢复就从这里开始
- LOG_CHECKPOINT_OFFSET(8B),上个属性中的LSN值在redo文件组中的偏移量
- LOG_CHECKPOINT_LOG_BUF_SIZE(8B),服务器在执行checkpoint操作死对应的 log buffer大小
- LOG_BLOCK_CHECKSUM(4B)
- 暂时没有
- checkpoint2,跟checkpoint1格式一样
redo log的三层结构
最上面的混合逻辑+物理结构,然后写入log buffer,再刷新到磁盘
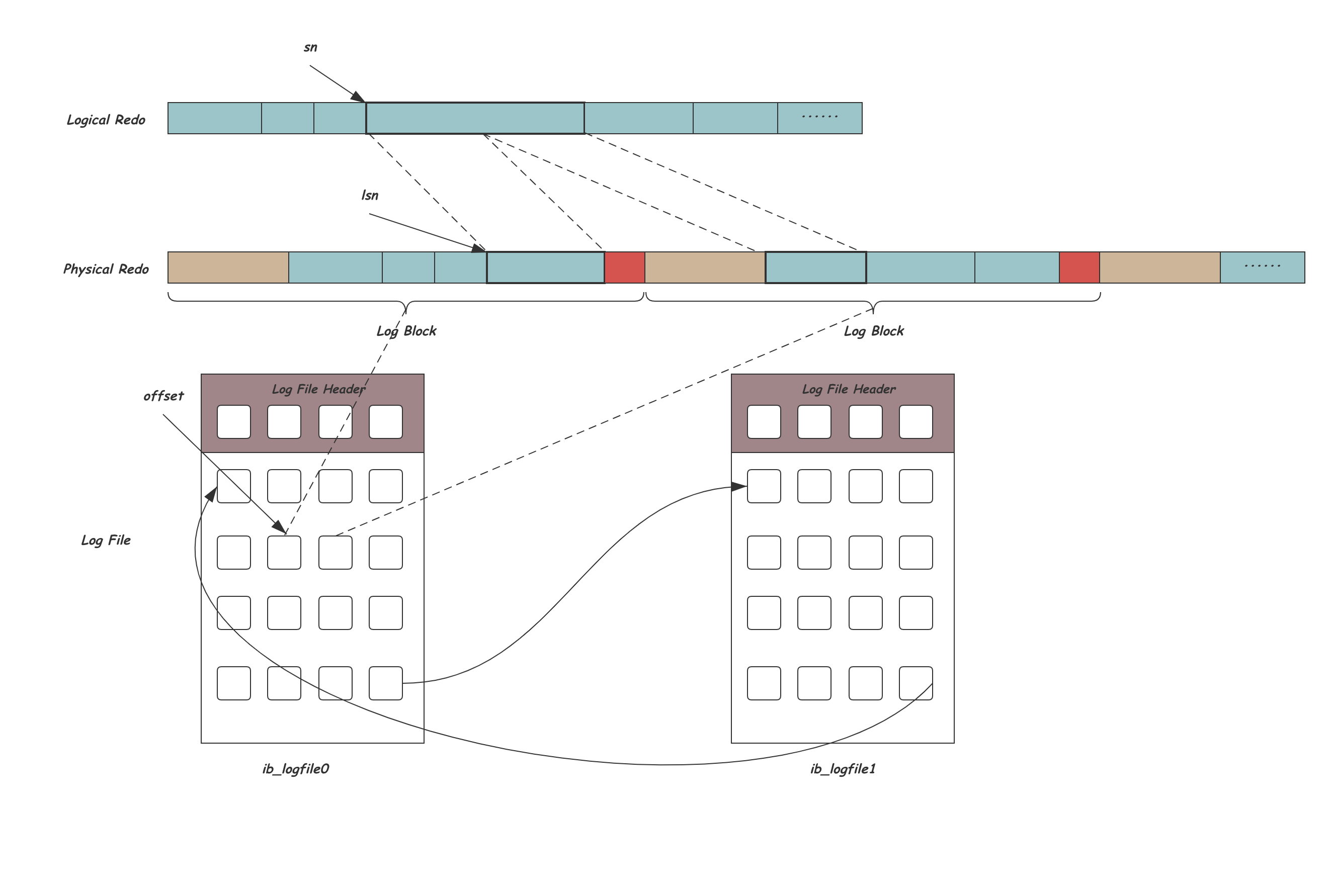
刷新到磁盘
Log Sequeue Number是一个全局递增的值,在一条redo log都没写入时,LSN的值为8704
实际统计LSN时,会把log block header、log block trialer也算上
第一次启动初始化log buffer后,buf_free指向了12字节偏移量,此时LSN = 8704 + 12 = 8716
对于跨多个block的,需要把对应的头和尾的字节都算上
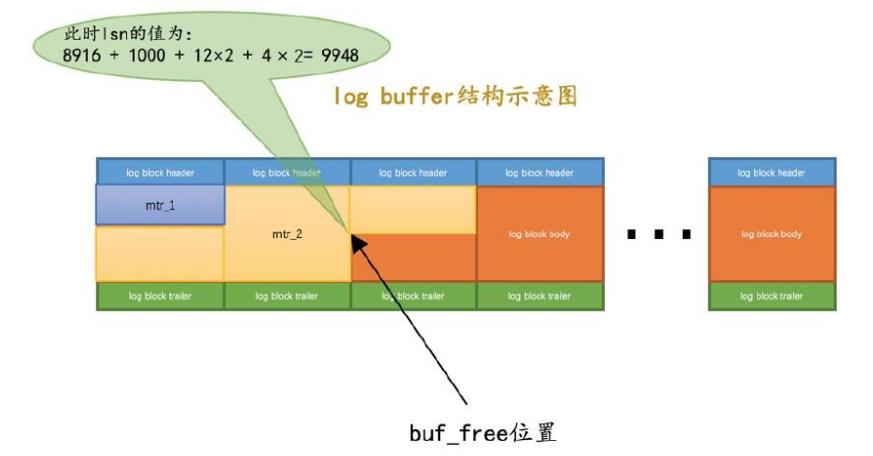
buf_next_to_write这个变量,标记了已经刷新到磁盘上的位置
这里其实有两个值
- write_lsn,表示 log buffer 写入到操作系统缓冲区,但没有fsync()
- flushed_to_disk_lsn,表示写入到操作系统buffer,并且调用了fsync,所以这个值一般会比 write_lsn 要小一些
lsn值和redo⽇志⽂件偏移量的对应关系,如下:
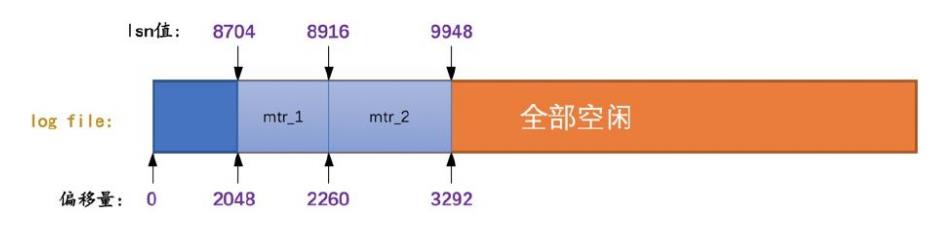
初始时的LSN值是8704,对应⽂件偏移量2048
之后每个mtr向磁盘中写⼊多少字节⽇志,lsn的值就增⻓多少
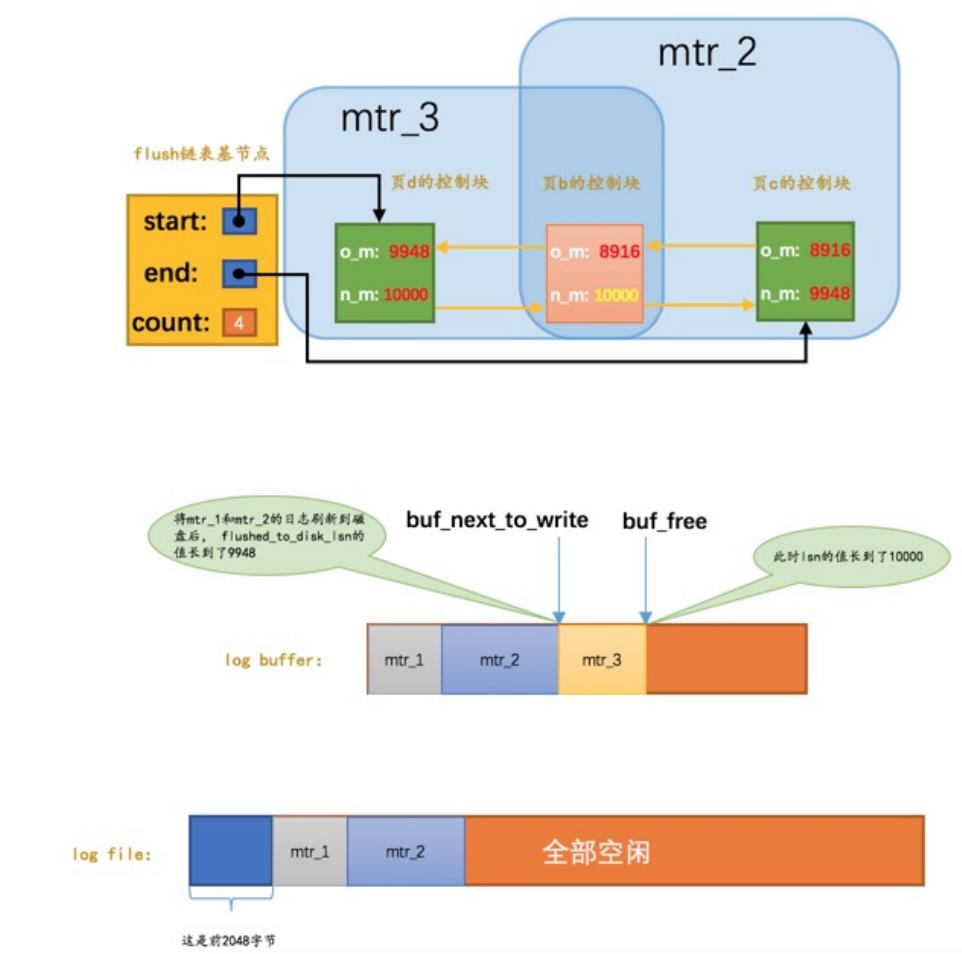
flush链表中的脏⻚是按照⻚⾯的第⼀次修改时间从⼤到⼩进⾏排序的
缓存页的控制块中有两个时间相关的控制属性
- oldest_modification,第一次加载到buffer pool中,该页面的mtr开始时对应的lsn值
- newest_modification,每次修改,将mtr对应的LSN写入
假设mtr1修改了页面 a,之后 mtr2 修改了页面b、c
之后 mtr3 修改了 页面b、页面d,最终效果如下:
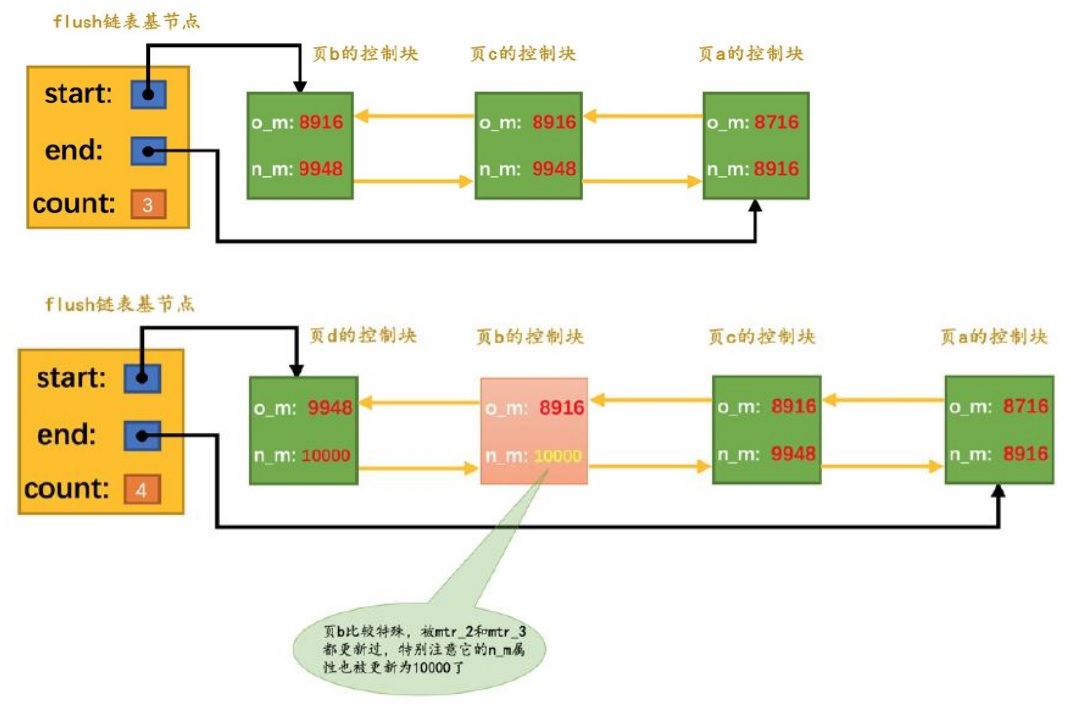
flush链表中的脏⻚按照修改发⽣的时间顺序进行排序
也就是按照oldest_modification代表的LSN值进⾏排序
被多次更新的页面不会重复插入到flush链表中,但是会更新newest_modification属性的值
为了避免大量的唤醒工作影响log_writer或log_flusher线程,InnoDB中引入了两个专门负责唤醒用户的线程:
log_wirte_notifier和log_flush_notifier
当超过一个条件变量需要被唤醒时,log_writer和log_flusher会通知这两个线程完成唤醒工作
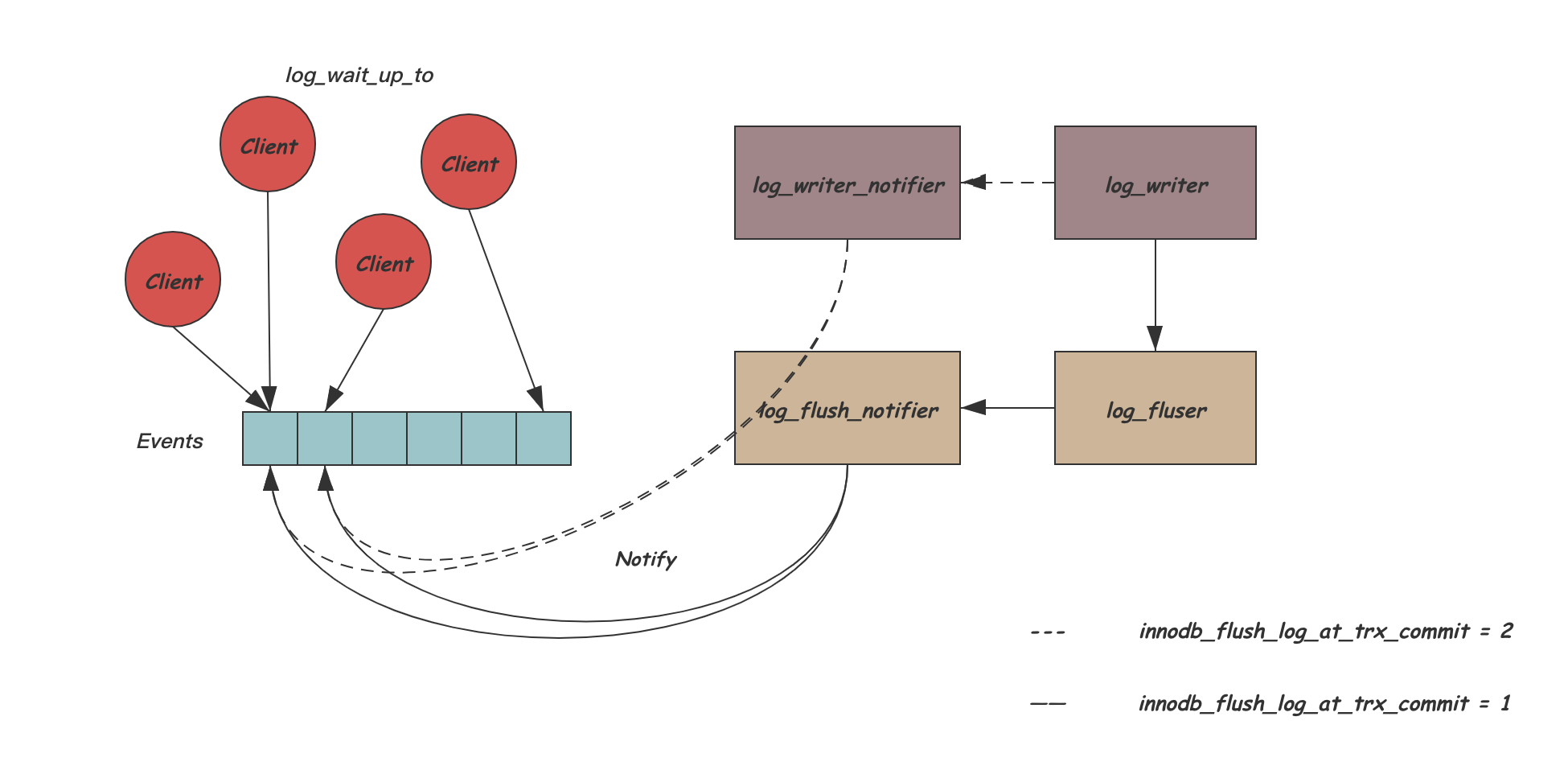
多个线程通过一些内部数据结构的辅助,完成了高效的从REDO产生,到REDO写盘,再到唤醒用户线程的流程,下面是整个这个过程的时序图
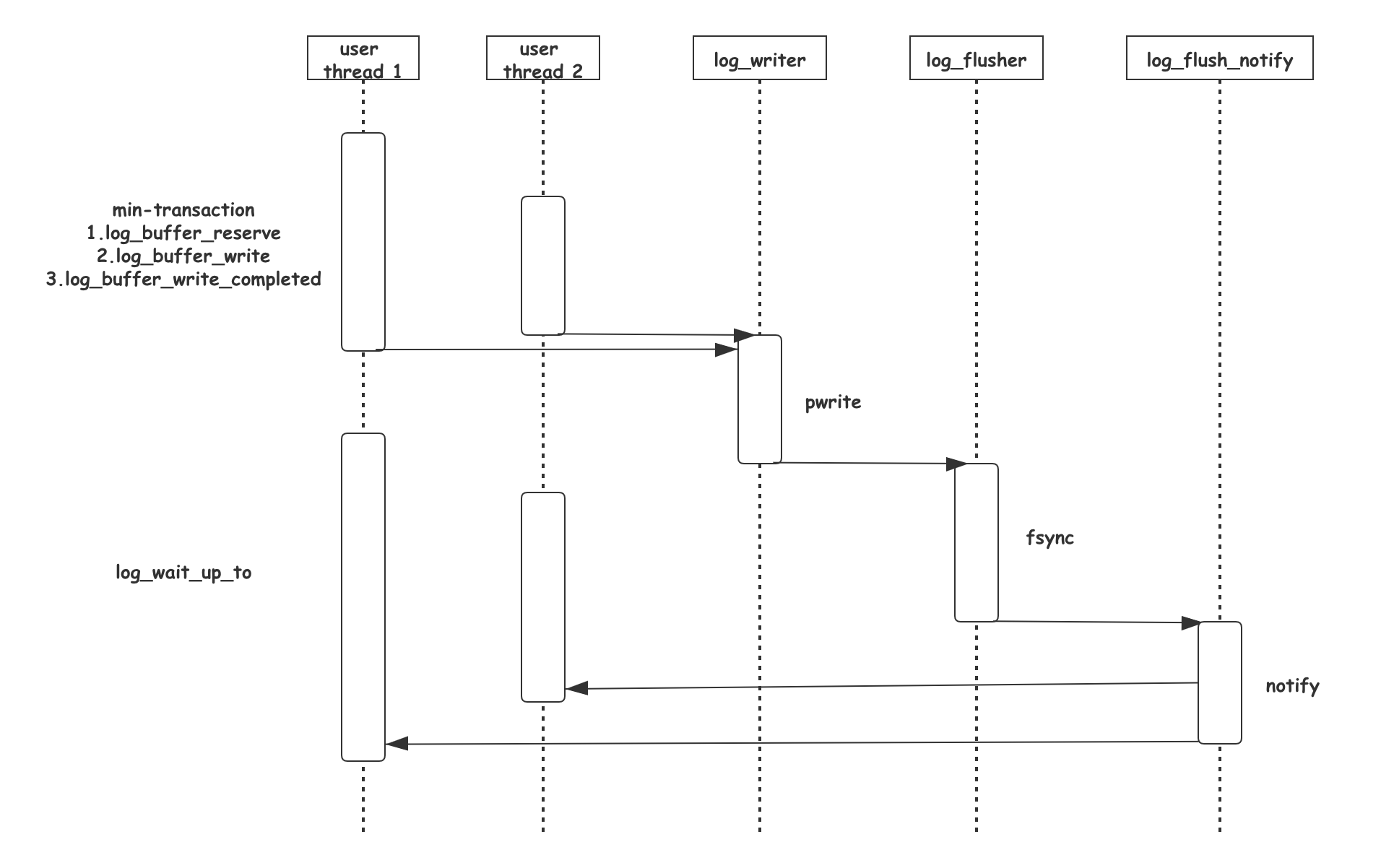 这里的 log_writer完成主要写入工作,调用
这里的 log_writer完成主要写入工作,调用pwrite系统调用完成原子写入
后面再交给log_flusher完成真正的 fsync()系统调用
这里根据innodb_flush_log_at_trx_commit的取值不同,有不同的写入和通知方式
checkpoint
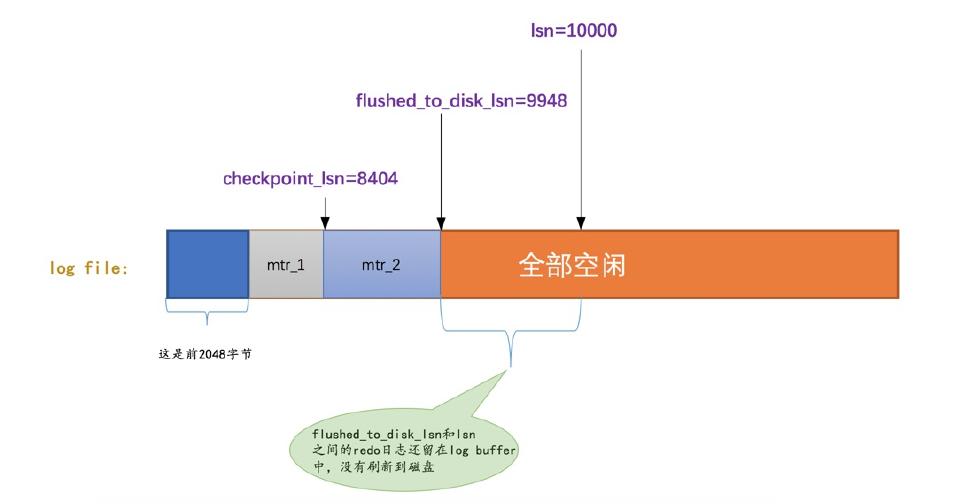
为防止redo log文件追尾,需要定期做 checkpoint
对于已经刷新到磁盘上的数据,其 redo log就可以被覆盖了
比如下面的 mtr1 已经刷新到磁盘了,那么对应的 flushed_to_disk_lsn 就需要增加
这里需要一个全局变量checkpoint_lsn,表示可以被覆盖的 redo log是多少
- 假设页面a被刷新到磁盘,那么页面c就是最老的,其
oldest_modification是 8916 - 那么就把 8916 赋给checkpoint-lsn,凡是小于这个的都可以被覆盖掉
- 更新checkpoint_no,并将checkpoint_lsn 写入到redo log文件组管理信息中
- checkpoint_no是奇数就更新 redo log文件中的checkpoint1、否则更新checkpoint2
记录完checkpoint后,redo log文件组中各个 LSN值关系如下:
刷新脏页、做checkpoint是两个不同的线程
如果系统LSN增长的太快,后面来不及做脏页刷新,最后不得已会同步的从flush链表中同步的刷新脏页到磁盘
当这些脏页刷新完后,系统就可以继续做checkpoint了
|
|
显示结果:
|
|
解释一下
- Log sequence number,当前的LSN
- Log flushed up to,已经刷新到磁盘位置的LSN
- Pages flushed up to,flush链表中最早修改的页面对应的oldest_modification值
- Last checkpoint at,最新的checkpoint值
- pending log flushes,pending chkp writes,还未完成的日志操作及统计信息
- log i/o’s done,log i/o’s/second,已经发生的日志操作统计信息
innodb_flush_log_at_trx_commit取值
- 0,提交事务时不立即同步redo log,由异步线程完成,吞吐量最好,但不安全
- 1,提交事务时也将redo log同步到磁盘,最安全但性能最差
- 2,提交事务的redo log写入到操作系统缓存,如果OS没挂还是能保证持久性

恢复过程
找到checkpoint_lsn,之前的那些 redo log已经刷脏页到磁盘上了,所以不用恢复
redo log文件组有两个checkpoint头,1 和 2,取最新的即可,这样就能拿到恢复的起点位置了
如果一个block是满的,那么 LOG_BLOCK_HDR_DATA_LEN 就是 512字节
一直往后找到 LOG_BLOCK_HDR_DATA_LEN 是非512字节的,就是最后一个block
恢复过程:
- 从初始的LSN开始,顺序往后遍历恢复
- 对于小于LSN的redo log就不用管了,而大于LSN的,可能也被后台线程刷新到磁盘了,需要判断一下是否需要跳过
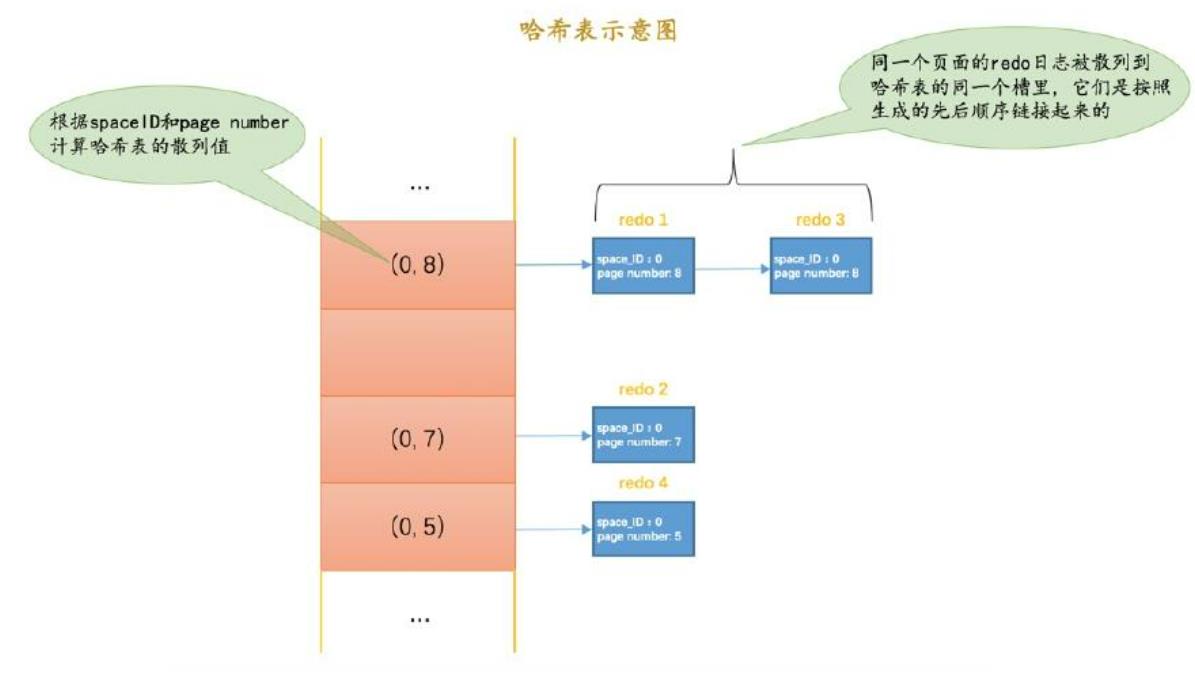
- File Header头部的FIL_PAGE_LSN记录了最近一次修改的LSN,也就是页面控制块的newest_modification,如果大于LSN此页面可以跳过
- 根据表空间 + 页号,组装成hash表,相同的按照链表先来后到排序,这样同一个页面就在一起了合并了,减少了很多随机I/O
LOG_BLOCK_HDR_NO 的计算过程
|
|
所以肯定是在 1~0x40000000之间,后者就等于 1G
所以能产生不重复的LOG_BLOCK_HDR_NO最多只有 1GB个,一个block是512字节,redo log组总文件最大就是 512G
undo log
undo log本身也会被 redo log记录下来
undo log 格式
一般来说,每次对一条记录的改动都会对应一条 undo log,有时候会会对应两条
undo log专门存放在 FIL_PAGE_UNDO_LOG的页面中,可以放在系统表空间中,也可以放在独立表空间中
假设表结构为:
|
|
INSERT的 undo log格式
插入语句:
|
|
insert的undo log格式:

page的开头是 next record offset,结尾是 prev record offset
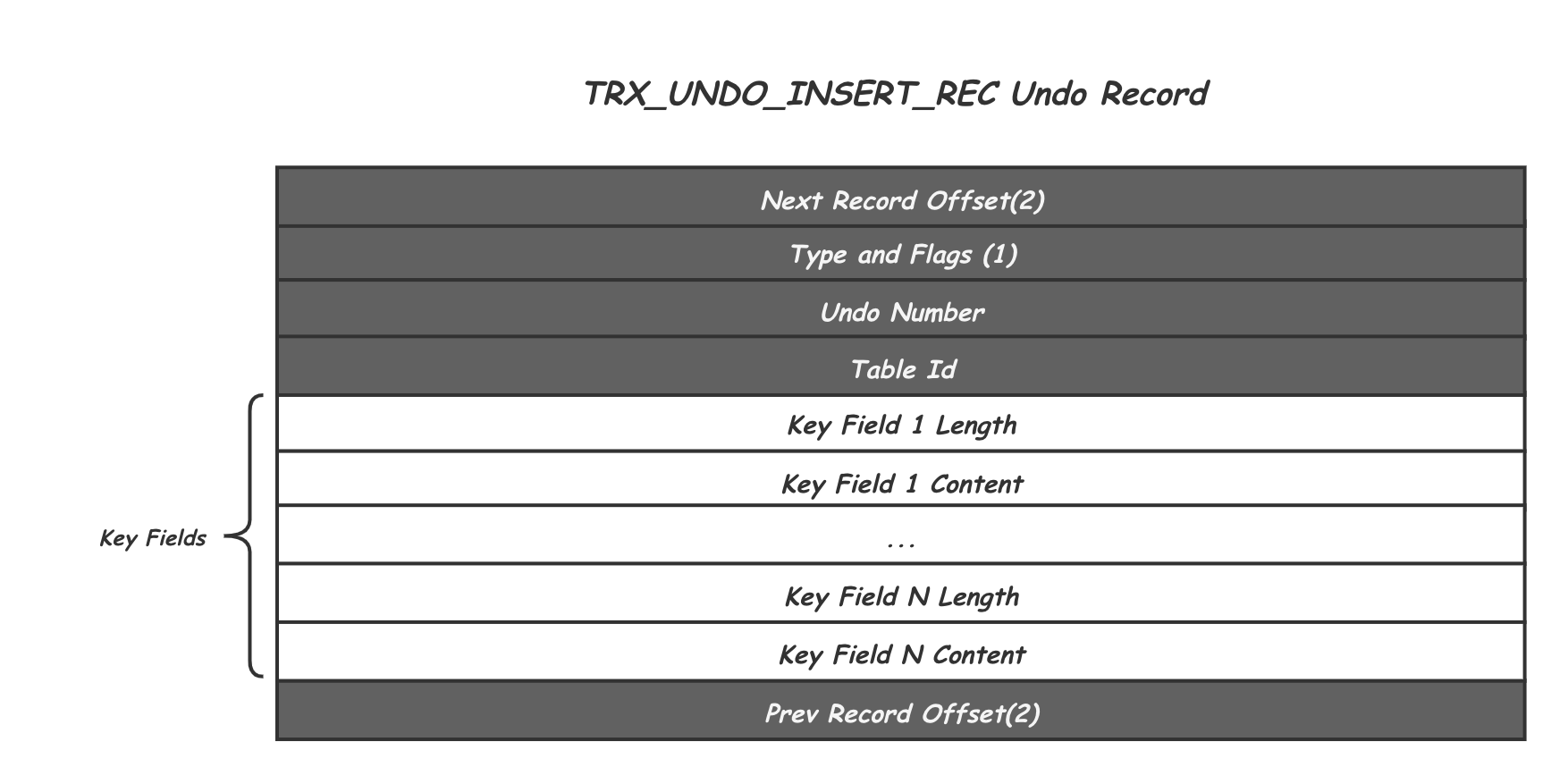
插入2条记录后的 undo log格式如下:
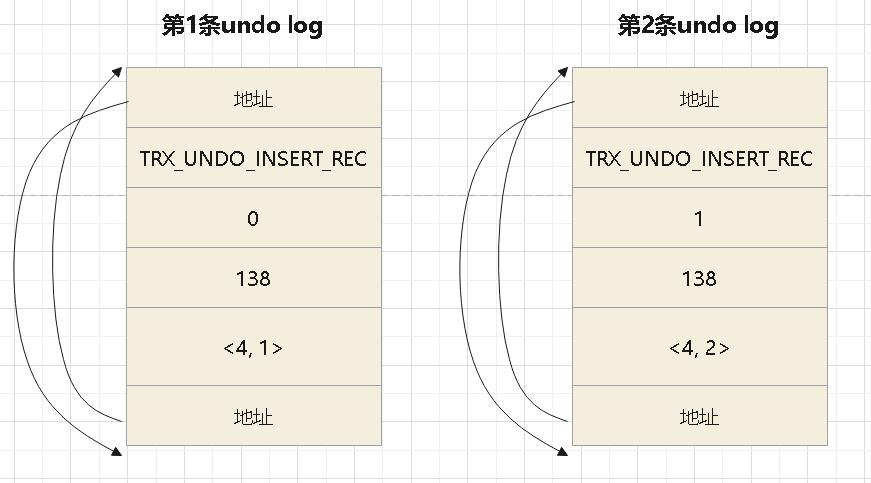
DELETE的 undo log格式
删除一条记录后,并不是立马从数据页中删除,而是有一个中间状态
这样做是为了实现MVCC
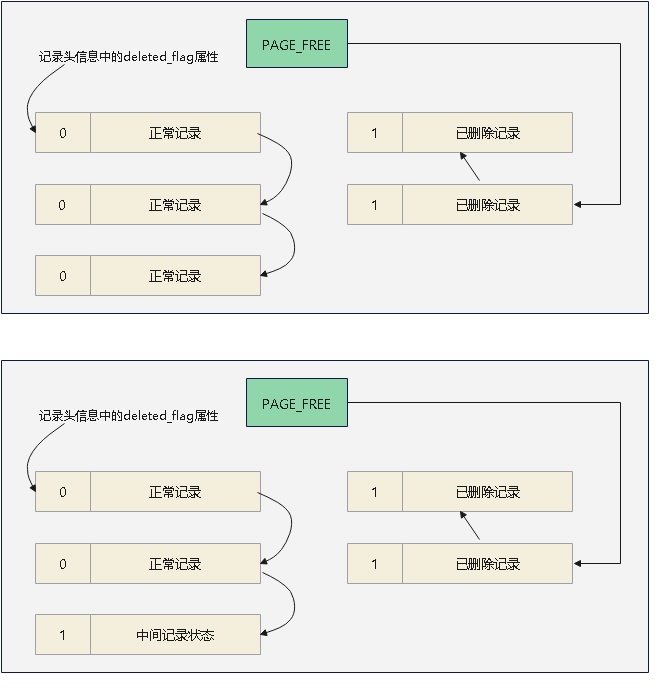
之后会有专门的 purge 线程来完成垃圾清理操作
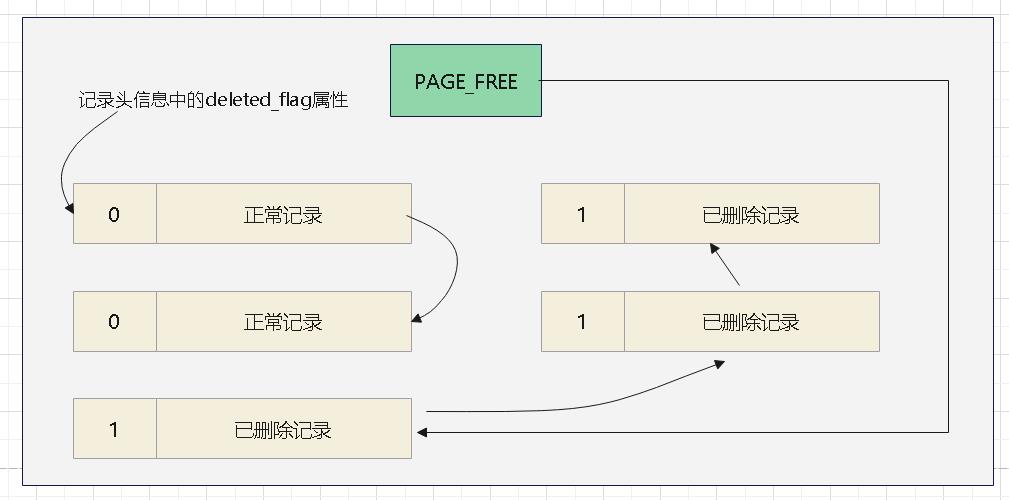
所以删除一条记录分为两个阶段
- 仅仅将这个记录的
deleted_flag做一个标记,然后修改隐藏的 trx_id、roll_pointer值,其他列不改动 - 当事务提交后,purge线程会真正的清理这个记录,从正常记录链表中移除,然后修改页面的PAGE_N_RECS、PAGE_GARBAGE等
PAGE_GARBAGE统计了已删除记录的空间
- 当有新记录插入时,如果剩余空间不够了,则新申请
- 否则就从删除空间中分配
- 如果删除空间中全有很多碎片,但是加起来空间却足够,会申请一个新page,然后全复制page这样就可以清除碎片了
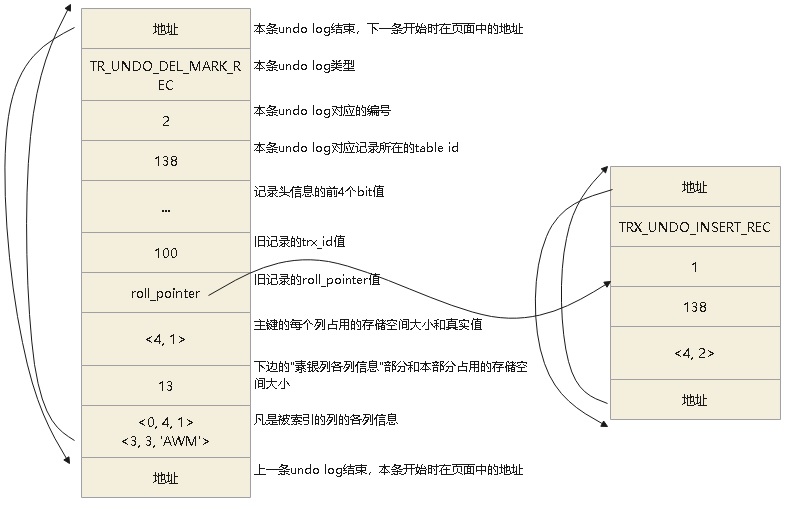
TRX_UNDO_DEL_MARK_REC 类型的undo log格式:
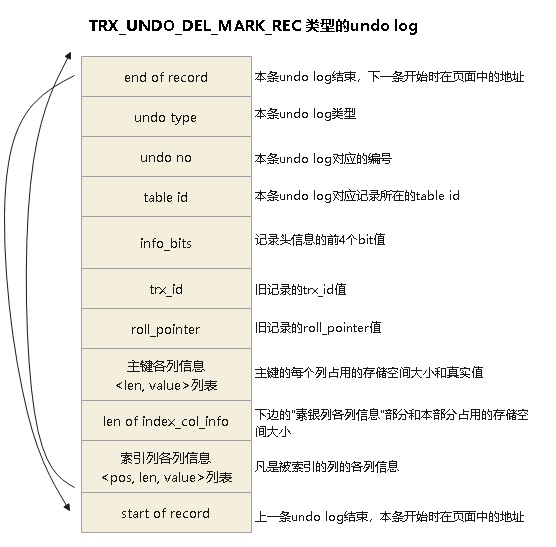
删除语句的delete mark操作对应的undo log结构
roll_pointer指向了 旧的记录
UPDATE的undo log格式
更新要分为两种情况
- 不更新主键
- 更新主键
不更新主键时
- 如果新的update记录数据,跟原先的一样,则原地更新,注意必须是完全相等,不能大 也不能小
- 否则先删除(用户线程同步等待的删除),是真正的删除,不是delete-mark操作,然后再插入一条记录
如果是更新主键
- 对旧记录做delete-mark标记,并非真正删除
- 等update事务提交后,由purge线程完整真正删除
- 这是因为旧记录可能会被其他事务访问,要支持MVCC所以不能立刻删除
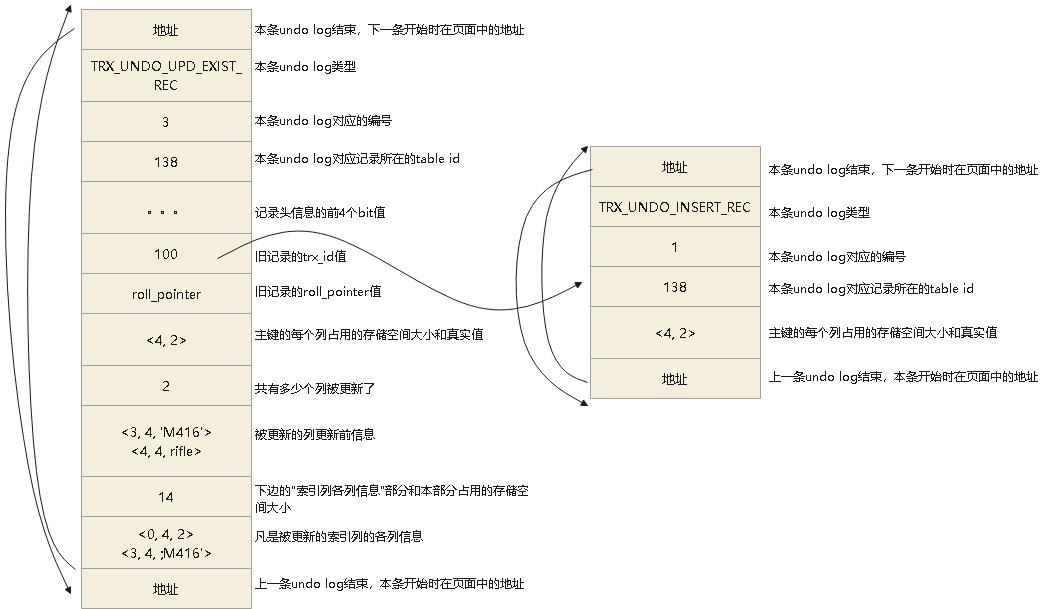
不管是更新主键、还是不更新主键,都会 生成一个 TRX_UNDO_UPD_EXIST_REC 格式的undo log
TRX_UNDO_UPD_EXIST_REC 格式如下:

先插入一条记录,再更新这个记录之后的 roll_pointer指向情况
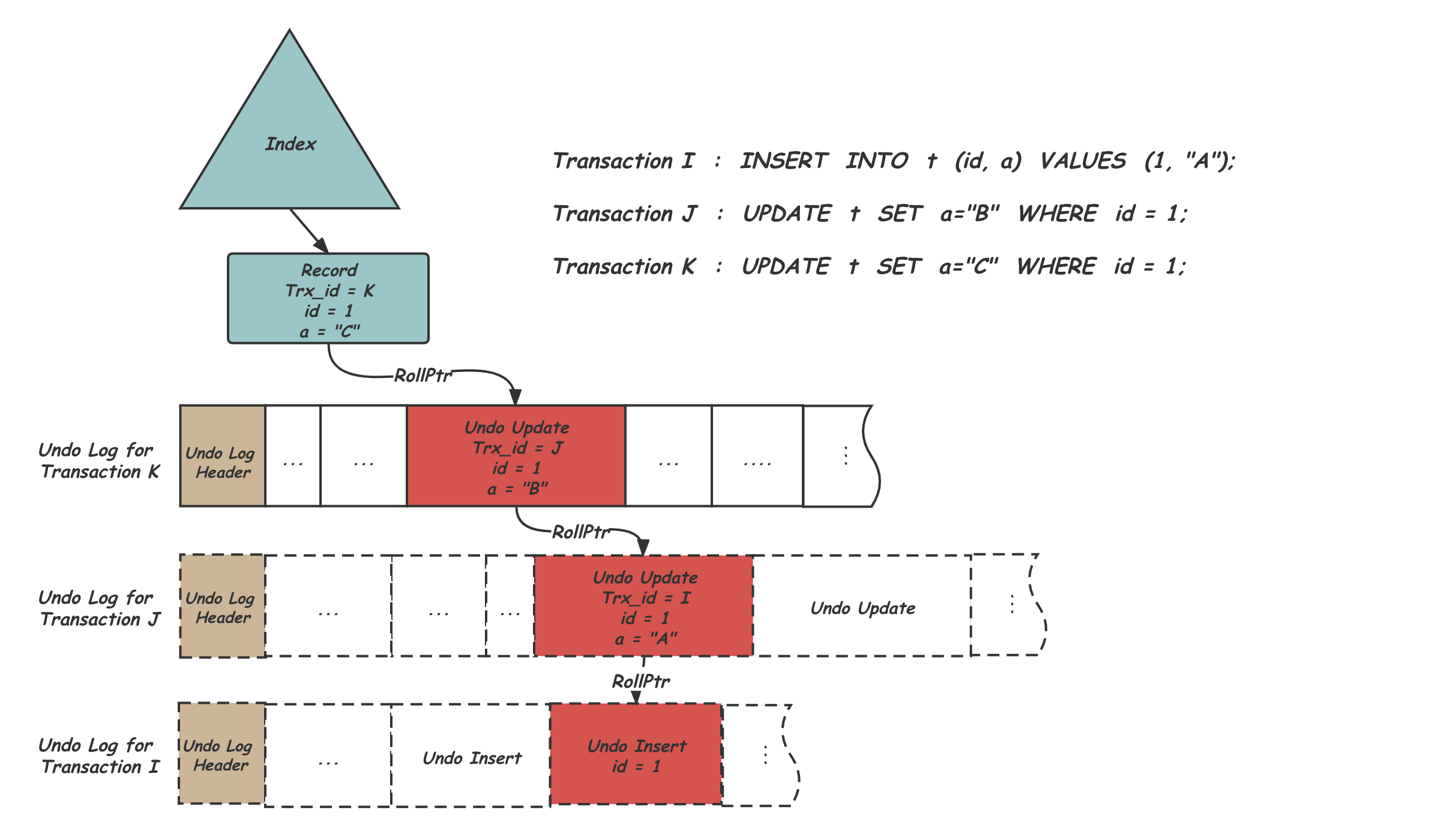
MVCC方式的数据组织,根据事务id,去undo page中对比,如果可见则返回,否则继续遍历链表
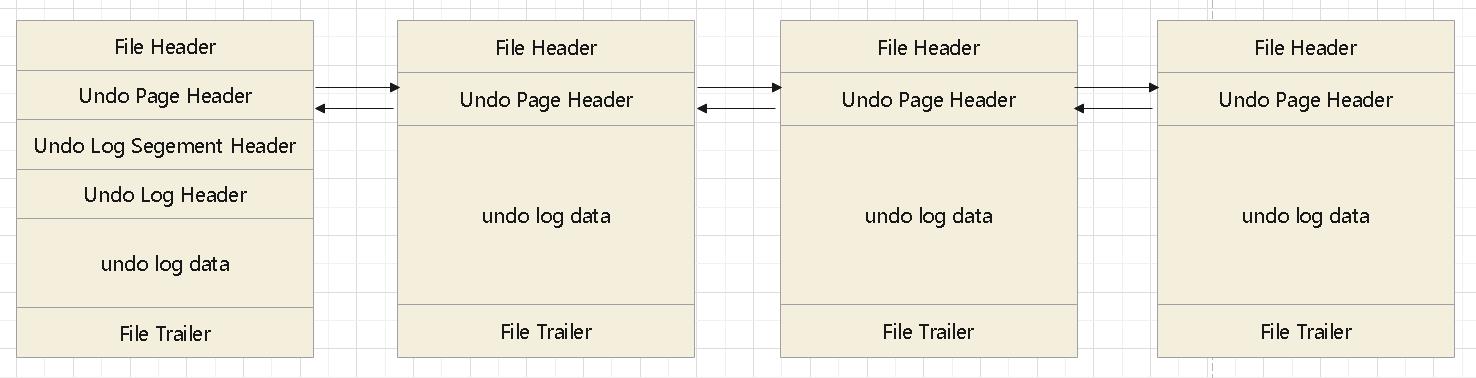
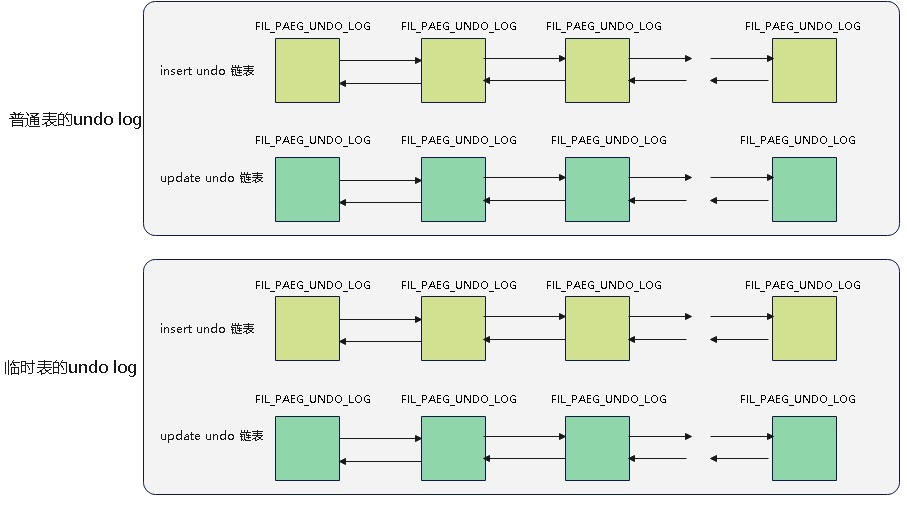
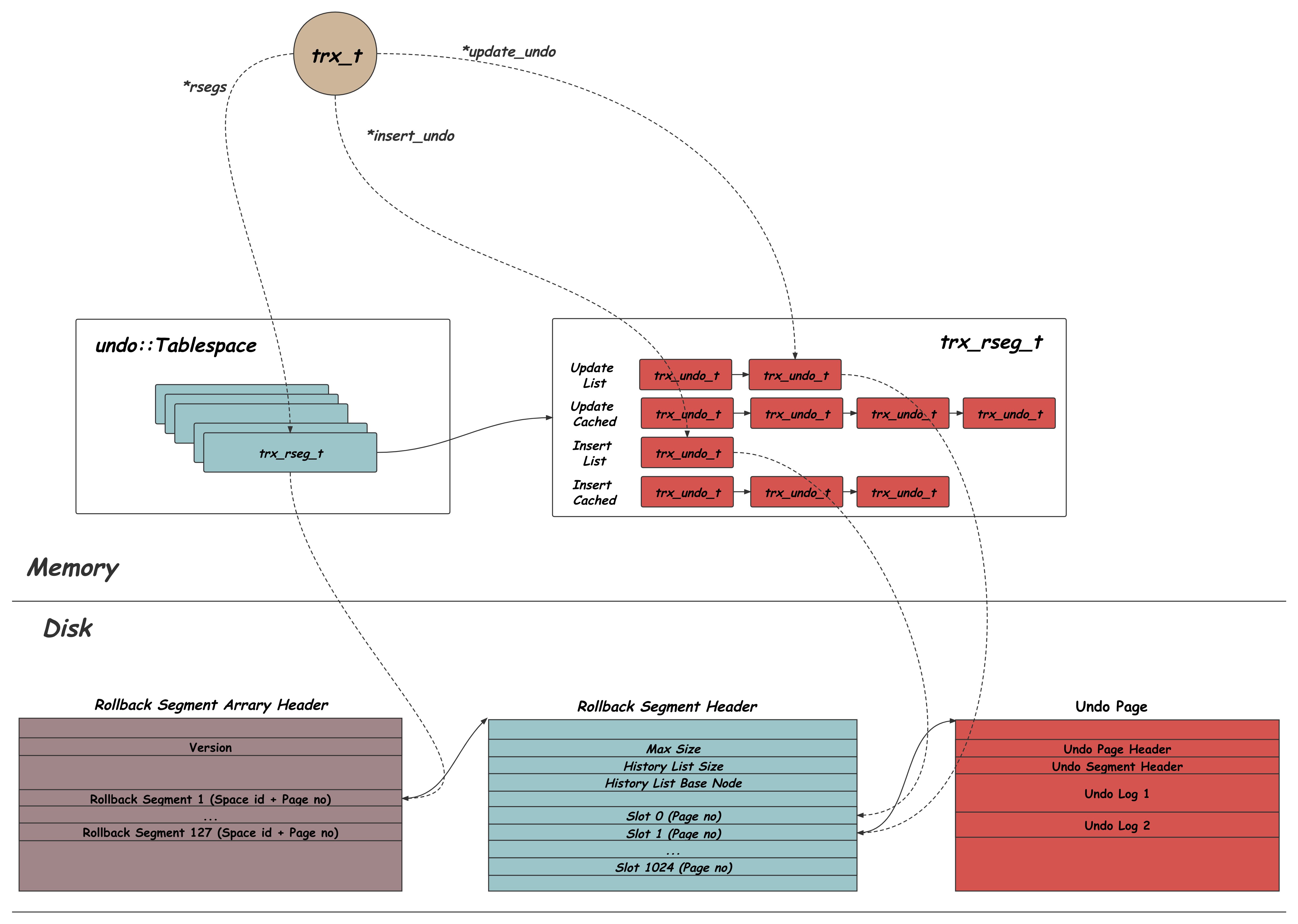
undo log的组织
undo log会按照 双链表的方式组织在一起,链表的第一个节点比较特殊,有有一些特殊的header,其他节点格式都一样
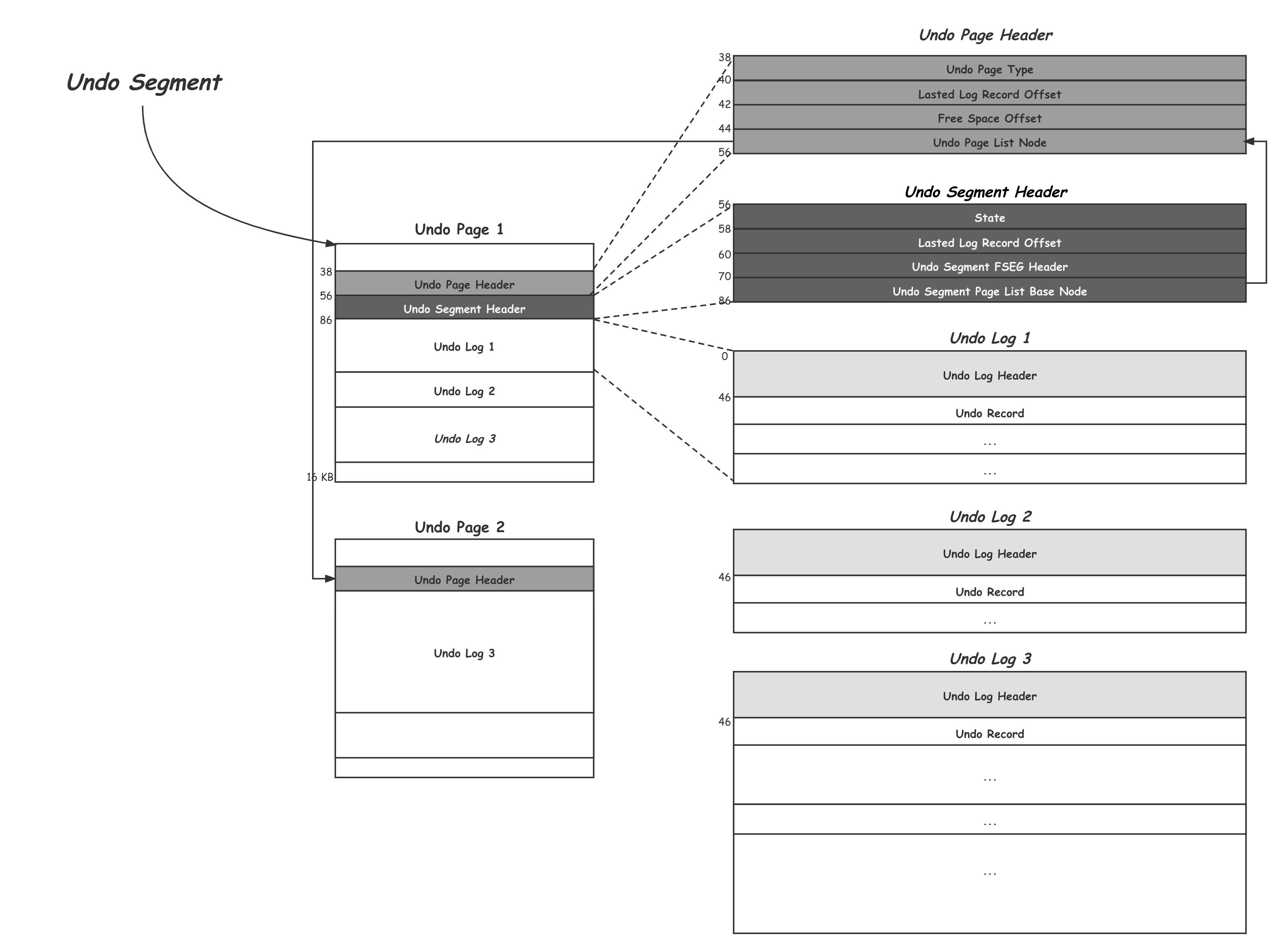
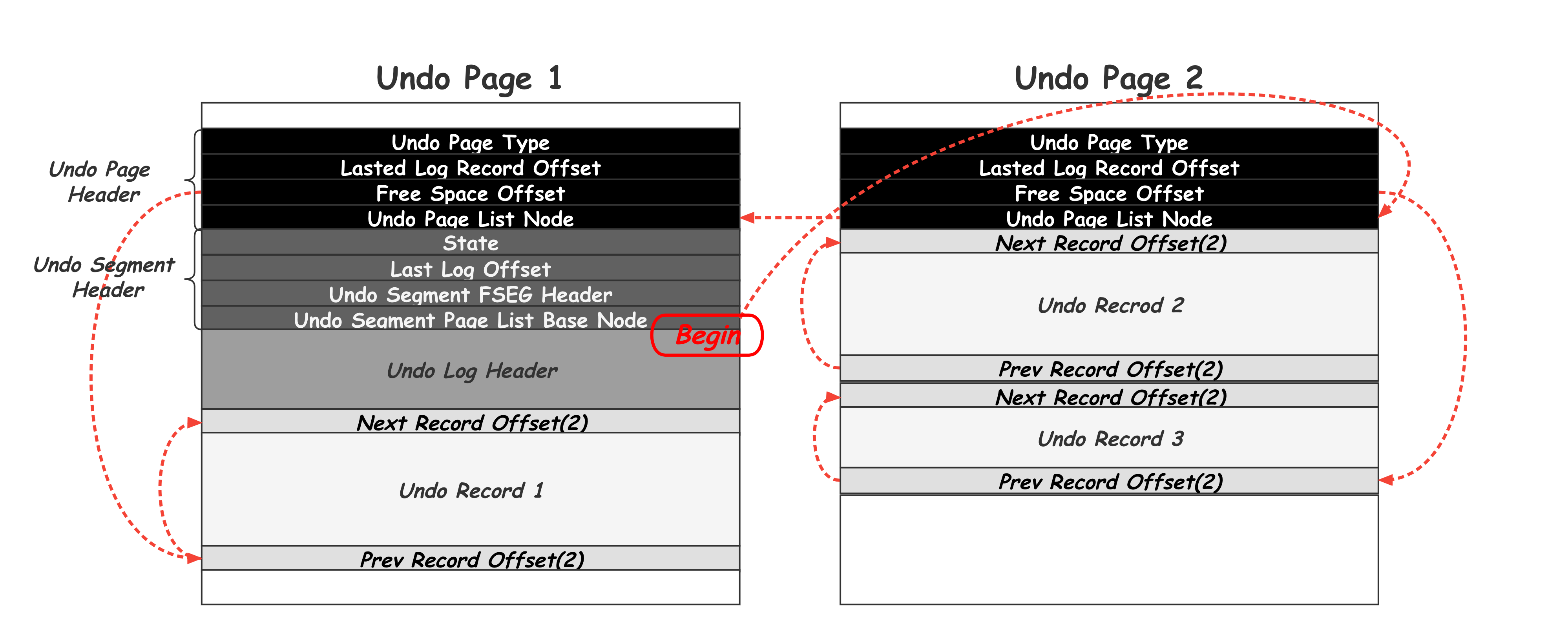
一下就是 FIL_PAGE_UNDO_LOG 页面的格式:

解释一下这几个头
- Undo page Header
- TRX_UNDO_PAGE_TYPE,分为两大类,TRX_UNDO_INSERT一类(事务提交后可以删除),其他类型的归为TRX_UNDO_UPDATE(事务提交后不能删除MVCC)
- TRX_UNDO_PAGE_START,当前页面从这个位置开始存储unod log
- TRX_UNDO_PAGE_FREE,跟上面的参数配对,从这个位置之后都是空闲的
- TRX_UNDO_NODE,代表一个链表节点结构
- Undo Log Segment Header
- TRX_UNDO_STATE
- TRX_UNDO_ACTIVE,活跃状态
- TRX_UNDO_CACHED,可以被后续其他事务重用的page
- TRX_UNDO_TO_FREE,等待被释放的状态,对于insert undo log,事务提交后可以重用
- TRX_UNDO_TO_PURGE,update undo log事务提后不能重用
- TRX_UNDO_PREPARED,处于prepared阶段的undo log
- TRX_UNDO_LAST_LOG,本undo log链表中最后一个undo log header位置
- TRX_UNDO_FSEG_HEADER,对应的是INODE段信息
- TRX_UNDO_PAGE_LIST,undo page链表中的基节点
- TRX_UNDO_STATE
- Undo Log Header
- TRX_UNDO_TRX_ID,生成本组undo log的事务id
- TRX_UNDO_TRX_NO,事务提交后生辰的一个序号
- TRX_UNDO_DEL_MARKS,本组undo log中是否包含由delete mark操作产生的undo log
- TRX_UNDO_LOG_START,本组undo log第一条undo log的偏移量
- TRX_UNDO_XID_EXISTS,本组undo log是否包含XID信息
- TRX_UNDO_DICT_TRANS,本组undo log是否由DDL语句产生
- TRX_UNDO_TABLE_ID,如果产生了DDL,则对应的table id
- TRX_UNDO_NEXT_LOG,下一组undo log在页面中开始的偏移量
- TRX_UNDO_PREV_LOG,上一组undo log在页面中开始的偏移量
- TRX_UNDO_HISTROY_NODE,代表一个history链表节点
undo log的双链表结构
一个事务中最多有 4个链表
undo page的内部组成
回滚段
重用undo log
- 该链表只有一个page
- 该undo log页面已使用的空间小于整个page 的 3/4
- insert链表可以直接覆盖
- update链表只能继续往后面写,因为前面的数据要支持MVCC
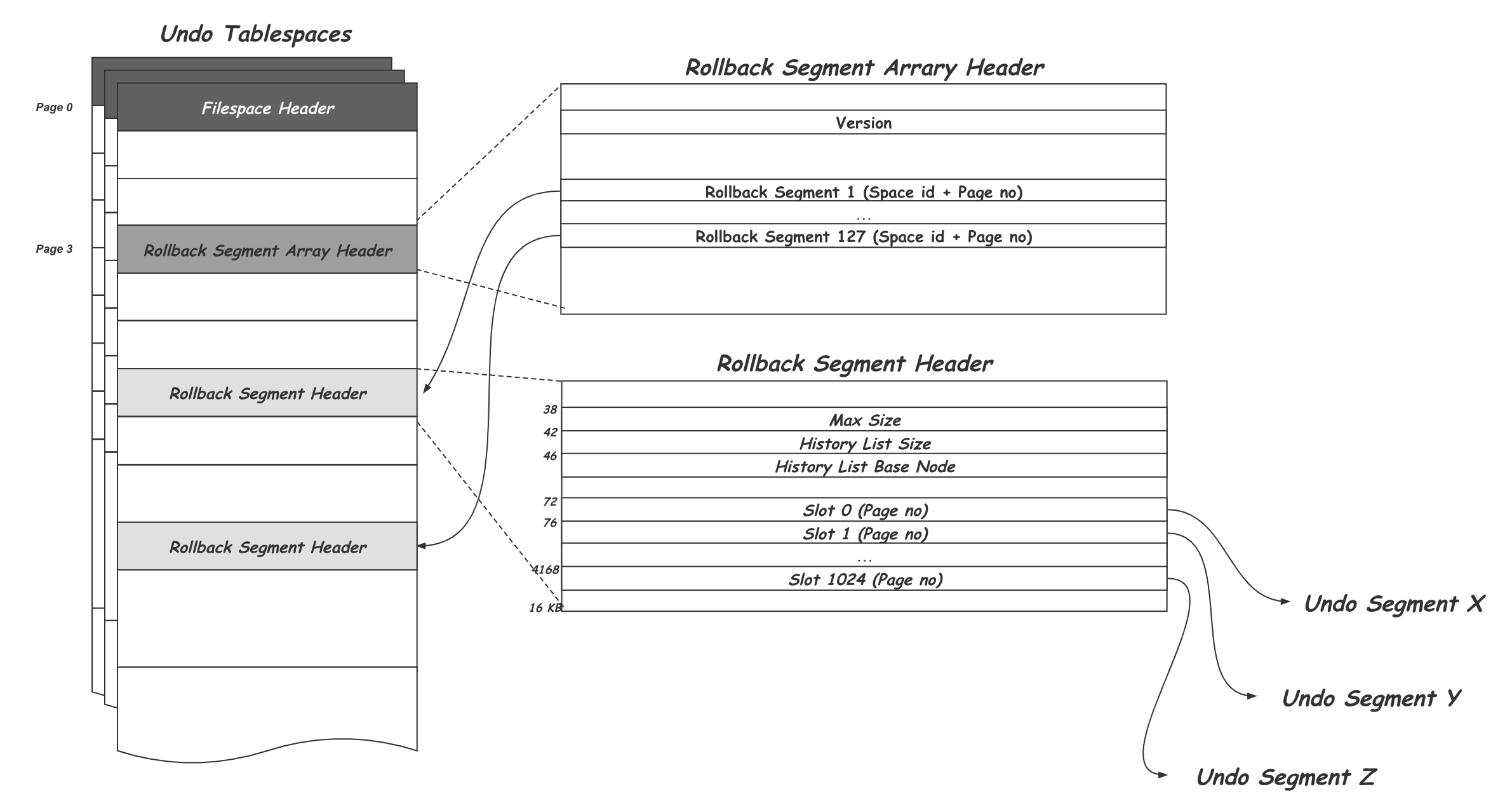
回滚段中存放了各个事务中 undo log链表的first undo page
这些first undo page被放在一个个的 undo slot中
每个Rollback Segment Header页面对应一个段,这个段就是回滚段
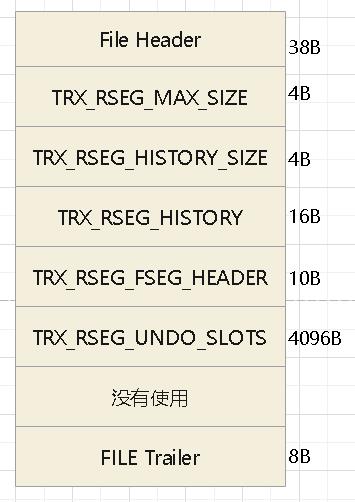 主要字段
主要字段
- TRX_RSEG_MAX_SIZE,所有undo log链表中undo log页面数量总和
- TRX_RSEG_HISTORY_SIZE,history链表占用的页面数量
- TRX_RSEG_HISTORY,history链表的基节点
- TRX_RSEG_FSEG_HEADER,对应10个字节的segment header,通过它可以找到本回滚段对应的INODE entry
- TRX_RSEG_UNDO_SLOTS,一个页号占4个字节,这里最多可以由1024个undo slots
默认回滚段的undo slot值为 FIL_NULL,如果是这个值就申请一个undo log链表,将first undo page赋给这个slot
如果不是FIL_NULL,说明被其他事务占用了,则要继续找
在很早之前,最多只能支持 1024个事务
一个事务提交后,undo solot需要做一些处理
- 如果满足重用条件,则加入到 TRX_UNDO_CACHED 链表队列中
- insert和update会加入到不同的TRX_UNDO_CACHED链表中
- 不满足重用条件的 insert链表就会被回收
- 不满足重用的update则等待purge线程回收
为支持更多事务,MySQL做了扩展,可以支持最多128个 rollback segment header,所以并发数量就是:
128 * 1024 = 131072个并发,所以同时支持这么多个读写事务
在系统表的5号page中,有 128个小槽子,每个操作8个字节,包含
- space ID
- page Number
系统的第5号页面,Rollback Segment Header,undo slot,undo log链表之间的关系
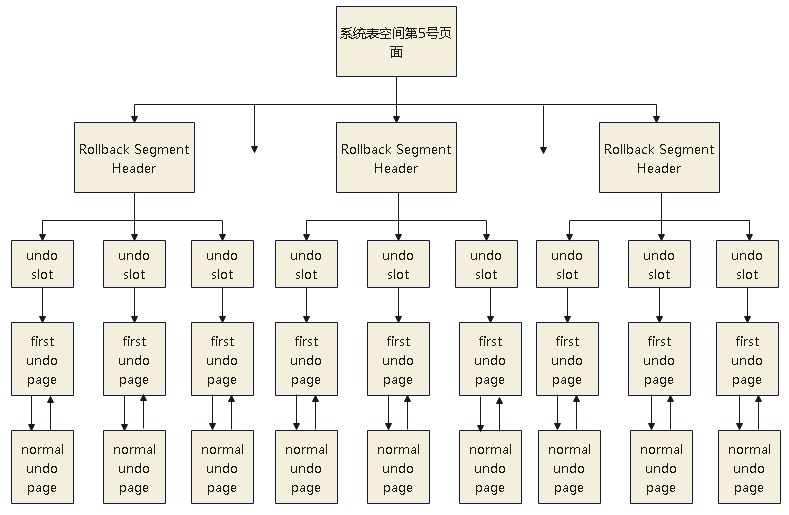
独立表空间下,默认第3个page 固定作为这128个Rollback Segment的目录,也就是Rollback Segment Arrary Header
其中最多会有128个指针指向各个Rollback Segment Header所在的Page
每个Rollback Segment Header又包含了 1024个 slot,指向了一个 Undo Segment 的first undo page
一个事务引用内存中的数据结构,以及磁盘上的物理结构组织
回滚段的分配
- 0号必须在系统表空间,也就是0号对应的 Rollback Segment Header必须在系统表空间
- 33 - 127号跟0号类似,用于普通表,不过这些可以自定义表空间
- 1 - 32号页面用于临时表空间,对应数据目录中的 ibtmp1 文件
- 临时表只在系统运行期间有效,所以不需要记录undo log
为事务分配undo log的过程
- 首先从系统表空间第 5号页面,分配一个回滚段,也就是 Rollback Segment Header,之后这个事务就一致使用这个段
- 分配到回滚段后,看这个回滚段的两个cached链表有没有缓存的undo slot,insert和update要找对应的cached
- 如果没有,则需要从Rollback Segment Header中找到一个空闲的(FIL_NULL)的slot
- 如果找不到就报错了
- 找到的话,如果是从cached分配的,那么对应的Undo Log Segment就已经分配了
- 否则要新分配一个 页面作为undo log链表的first undo page
- 之后事务就开始写这个链表了
- 临时表的操作也是类似的
配置回滚段的数量,默认为 128
|
|
- innodb_rollback_segments 设置为1,只有一个普通表空间回滚段可用,但仍有32个临时表空间回滚段
- 设置为 2- 33之间,跟 1 效果一样
- 设置为 大于33,则针对普通表的可用回滚段数量就是 该值 - 32
设置 undo log表空间
|
|
roll_pointer
聚集索引的记录中包含了 roll_pointer指针,有些类型的undo log中也包含了这个指针
它指向了一个undo log地址,这个字段由7个字节组成
 解释
解释
- is_insert,表示undo log是否为 TRX_UNDO_INSERT 这种大类
- rseg_id,指向undo log回滚段的编号,最大只有128个,所以 7个bit就足够了
- page number,4个字节
- offse,16K页面,2个字节足够了
rollback过程
解释
- 首先通过 redo log,将各个页面恢复到崩溃之前的状态
- 通过系统表空间 5号页面,找到 128个回滚段,每个回滚段中的1024个 undo slot中不为 FIL_NULL的slot
- 每个undo slot对应一个undo log链表,从first undo page中找到Undo Log Segment Header
- 然后就能找到TRX_UNDO_STATE,如果其状态为TRX_UNDO_ACTIVE,则表示当前是一个活跃事务
- 再在Undo Log Segment Header中找到 TRX_UNDO_LAST_LOG,这样就找到了本组中最后一个undo log页面
- 最后一个页面中记录了事务id,这就是未提交的事务
- 从最后一个链表往前,反向回滚,就可以将未提交的事务还原了
源码中的类型定义
redo log所有类型
文件所在位置:
mysql-8.0.28/storage/innobase/include/mtr0types.h
|
|
undo log的所有类型
文件所在位置:
mysql-8.0.28/storage/innobase/include/trx0rec.h
|
|
参考
- 说过的话就一定要办到 —— redo 日志(上)
- 说过的话就一定要办到 —— redo 日志(下)
- 数据库故障恢复机制的前世今生
- 庖丁解InnoDB之REDO LOG
- 庖丁解InnoDB之Undo LOG
- MySQL 8.0: New Lock free, scalable WAL design
- MySQL - redolog 图文详解
- 浅析 InnoDB Redo Log
- show engine innodb status 输出结果解读
- 写作本书时用到的一些重要的参考资料
- 一张log block的大图
- MySQL 是怎样运行的:从根儿上理解 MySQL
- MySQL · 引擎特性 · InnoDB undo log 漫游
- The basics of the InnoDB undo logging and history system
- Deep Dive: InnoDB Transactions and Write Paths
- The Unofficial MySQL 8.0 Optimizer Guide
- 不衰的经典: ARIES事务恢复 [数据库学习的成人试炼]
- Readings in Database Systems, 5th Edition
- 图解数据库Aries事务Recovery算法
{kind=link}