Accelerating Analytics with Dynamic In-Memory Expressions
原文
https://15721.courses.cs.cmu.edu/spring2020/papers/13-execution/p1437-mishra.pdf
介绍
Oracle Database In-Memory DBIM使用
- 内存列存格式
- SMID向量化处理
- 内存索引
来加速访问,能达到数量级的提升
而在Oracle12.2中,又引入了一个新技术,Dynamic In-Memory Expressions DIME
对于那些频繁访问的表达式,使用 DIME优化后,可以避免表达式编译,而DIME是基于内存的,对于 DBIM完全兼容,底层表结构也不需要变动
由于省去了 列计算、物化视图、cubes的开销,又能带来数量级的性能提升
Oracle Database In-Memory(DBIM)对scan、join、谓词评估、聚合做了优化,来适配分析场景
比如下面SQL
|
|
如果sales是列存格式的,那么扫描household速度会非常快,大概十亿/秒
但是price * (1 – discount)会牵扯到 数值计算,其计算成本就比较高了
通常的解决办法有这么一些
- 对于基表增加 预计算列
- 创建物化视图
- 预定义 cubes
这些方式不太适合ad-hoc这种场景,而且一旦底层表结构变化,维护成本也很高
另一个优化手段是:common subexpression elimination(CSE),将一个查询的表达式缓存,后续同样的查询就可以复用了
缺点是,对并发场景不好,其他查询可能用不上
而Oracle Database In-Memory(DBIM),会表达式的计算结果放到 Expression Statistics Store(ESS)中
随后的相同的查询表达式就可以利用这个结果避免重复计算
DBIM 采用了混合的双重格式,持久存储层是按照ro来存储的,而内存中是按columnar存储的
内存中的列不需要log和checkpoint,DML的修改直接作用于底层的 行表上
对列的修改通过事务保持一致性
高选择性(如scan)就执行用行模式完成,而分析场景使用内存优化的列格式
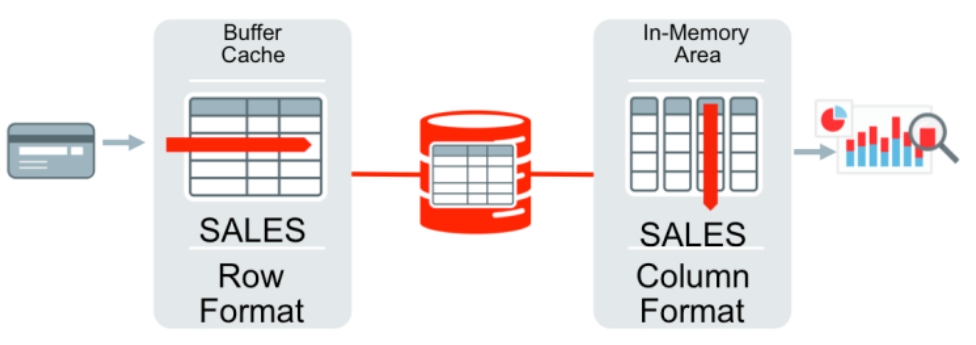
Figure 1. Dual-Format In-Memory Database
磁盘上的行经过处理转为内存中的列格式 In-Memory Compression Units,同时会对列做压缩处理,压缩方式也是自定义
可以存储 50 - 100W行数据,并使用SIMD来处理 IMCU
每个IMCU还包含了 min、max等信息,用来跳过不需要的scan
每个IMCU还关联了 Snapshot Metadata Unit(SMU),SMU跟踪 自IMCU创建以来的所有DML更改
这里的隔离模式使用的是:Consistent Read(CR),每个操作都关联一个 System Change Number(SCN)
只允许修改者自身,或者已经提交过的SCN可见,而当 IMCU的更改超过了一个 阈值,会再创建一个新版本的 IMCU
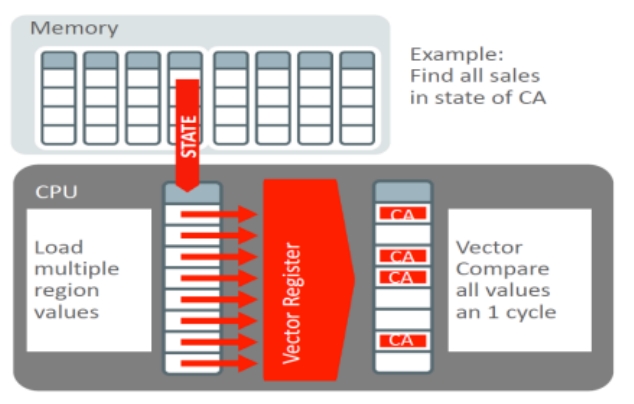
Figure 2. SIMD vector-processing in the IM column store
识别候选表达式
所谓的表达式就是SQL查询中的一部分,比如算数运算、逻辑运算等
比如+、-,以及内置的SQL函数、UDF函数
表达式可以出现在 SELECT、WHERE、GROUP BY、HAVING中,如下:
| ID | QUERY |
|---|---|
| Q1 | SELECT (sal + bonus) FROM emp |
| Q2 | SELECT SUM((sal + bonus)*(1-taxrate)) FROM emp WHERE UPPER(job) = ‘MANAGER’ |
| Q3 | SELECT MAX(sal) FROM emp GROUP BY EXTRACT(year FROM hiredate) |
查询1 中的(sal + bonus)
查询2 中的(sal + bonus)*(1-taxrate) i,以及UPPER(job)
查询3 中的EXTRACT(year FROM hiredate)
有些表达式是 根表达式,又包含很多子表达式,比如
- (sal + bonus)*(1-taxrate) 是根表达式
- 子表达式:(sal + bonus)
- 子表达式:(1-taxrate)
有些时候,优化器会生成一些隐式的表达式,用于加速复杂分析查询,以及join操作,比如:
- c1=c2,会变成 c1 - c2 = 0这样的
- 数据转换
- hash计算
- 列拼接
而为了识别这些重复的表达式,就通过一个新组件 Expressions Statistics Store(ESS),由它来管理维护各种查询表达式的统计信息
之后可以利用 SIMD向量化来加速查询
Expression Statistics Store是由优化器来维护的,SQL引擎生成各种表达式后就会交给优化器
优化器会做转换、消除、并生成新的表达式,而在完成了这一系列动作之后,就会将这些信息保存到 ESS中
ESS会为每个表达式生成唯一的ID
- 这里的表达式是需要做过滤处理的
- 比如对表A 的(a + b) 和 (b + a) 是一个意思,所以要对表达式做规范化处理
- T1、T2两个表都有一个upper(c)表达式,会被认为是不同的表达式
ESS包含两种类型,静态和动态
- 静态属性,特殊表达式的固定信息,不同查询的表达式不会改变
- 如 表达式中的SQL文本表示,表达式中的列引用列表,优化器的预计算等
- 动态属性,比如不同查询中会变的信息,表达式counts计算,表达式时间戳计算、基于运行时反馈的动态代码
- 动态属性计算count,最精确的方式是:跟踪表达式中count结果,也就是跟踪计算处理的计数器,复杂而且影响性能
- 另一种实现方式是 基于启发式方式
- 这里采用了一种:row source statistics 方式,它是一个迭代控制结构,会统计子节点输入、父节点的输出
- SQL引擎中的行源包括:scan、join、分区的行源,会计算其流入流出row数量,用于后续的count统计计算
- 比如,scan行源有两个表达式:round(price)、upper(item_name)
- 通过计算前面一个,其结果可能就是几行,这样第二个计算时就只需要扫描几行即可,大大节省了时间
- 表达式的静态、动态属性会存储到 System Global Area(SGA)中,这个每个Oracle实例都可以共享读取的地方,重启实例后可以继续读取
- ESS根据时间维度维护了两种统计快照
- 累计值,也就是第一次计算至今的统计值,当前值(比如最近24小时的)
- 每隔一段时间就会将当前值合并到累计值中
对表达式做排名
- ESS中会保存所有表达式中的统计信息、元数据等
- 给每个表达式一个权重,当前值的权重 比 累计值的权重更高
- 计算成本是重要的评判标准
- 后台会有模块周期的统计表达式排名,并统计 top N
- 统计全部表达式并物化能让所有查询性能提升,但是代价很多,所以根据权重选择重要的表达式

Virtual Columns
- 用于表示 表的一个、多个列,不占用实际物理存储空间
- 查询计划执行到对应表达式后,会自动替换
- 隐藏虚拟列是系统自动生成的,用户无法感知也操控不了
- 热表达式会随工作负载的变化而改变,因此冷的表达式需要从内存中移除,此时可以用 虚拟列来标记
- 这里还支持用户定义的虚拟列,用于设置对某些虚拟列的压缩行为,以及是否存在在内存中
- 比如包括:FOR DML、FOR QUERY、FOR CAPACITY
DIME的创建和维护
InMemory Expression Units
- 动态内存表达式 会被物化到内存中,叫做:IMEU
- IMEU来自于共享全局区域 SGA
- 回想一下 IMCU,它把一行数据按照列存储,放到内存中
- 而 IMEU是IMCU的逻辑扩展,存储的是列的表达式
- IMCU 和 IMEU是分开存储的,每个IMEU大概存储50W行
- IMCU 有一个指针,指向 IMEU
- IMEU 跟 IMCU 有相同的分区、复制方式,所以同样具有高可用、容错性、扩展性
- IMEU 也具有类似的压缩模式、优先级顺序等
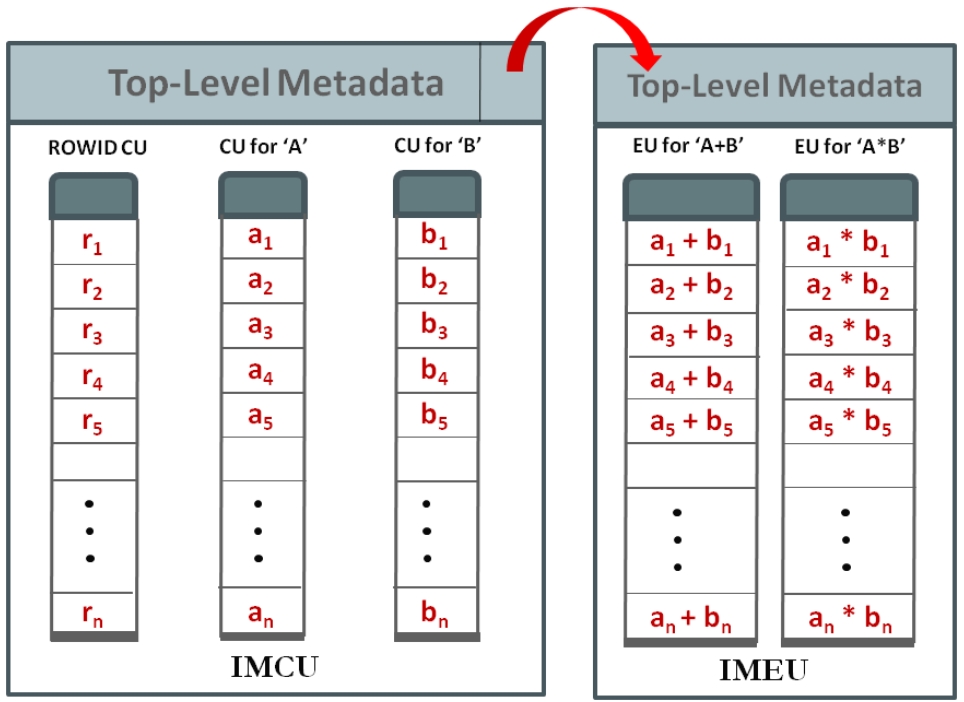
Figure 4. Columns A and B in an IMCU with n-rows and expressions A+B and A*B in the corresponding IMEU
IMEU创建
- IMEU 是由后台模块创建的,这种创建机制跟 IMCU类似
- IMCU读取了磁盘上的某些数据块(分区),而IMEU跟 IMCU横跨相同的行
- 所以IMCU跟IMEU有相同的并发保证,比如ALTER/DROP TABLE、DROP TABLESPACE的影响都是一样的
- 后台模块会从磁盘上数据块中读取行,转为列格式,并应用压缩模式
- 之后IMCU就变为在线状态,就可以跟踪这些状态,然后应用IMEU
- 由于IMCU 和 IMEU创建的时间有延迟,这里时间闪回技术,来保证数据的一致性
- 这里的闪回利用的是 SCN,也就是undo log来实现的
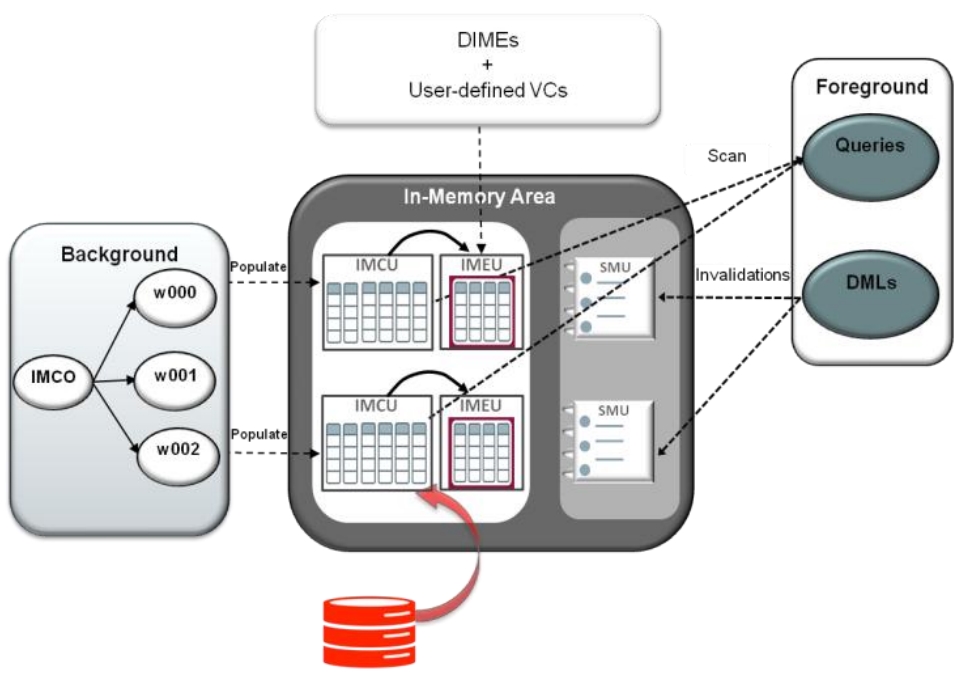
Figure 5. Top-level IMEU population (with IMCU and SMU)
重新填充IMEU
- 一旦IMEU被物化到内存中,查询就可以直接访问内存的值了
- 而DML操作会使row无效,此时就不能直接查询IMEU了,需要重新计算,此时性能就会下降
- 这时候需要有后台模块,周期性的刷新 IMCU-IMEU,并重建SCN
- 刷新基于两种方式,操作数量的阈值、时间戳
- 当新增一个DIME或者删除一个冷的DIME时,就需要重新填充IMEU了
- 而IMCU不需要动,这就是IMCU 和 IMEU分离的好处
- 如果热表达式集合发生了很大变化,也需要重新填充
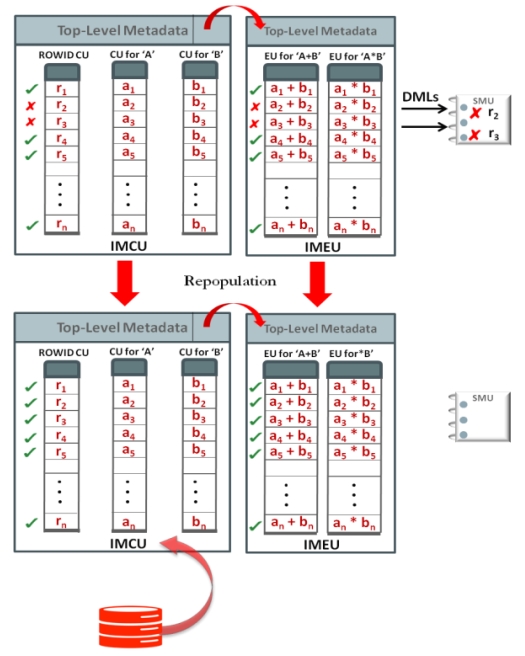 Figure 6. Repopulation of IMCU-IMEU
Figure 6. Repopulation of IMCU-IMEU
利用IDME加速查询
当 DIME 被填充完毕后,就可以被访问了
下一个阶段就是,重写SQL编译器生成的查询计划,变为:在表达式执行期间利用DIME的 运行时执行计划
当scan的时候,虚拟列会识别出对应的列,然后只需要很的修改,就可以实现加速效果
SQL编译和优化
比如对于下面这个SQL
|
|
SELECT中包含了表达式:UPPER(item_name)
WHERE中的表达式:price * (1-discount) > 1000
根据这个SQL生成的查询计划如下:
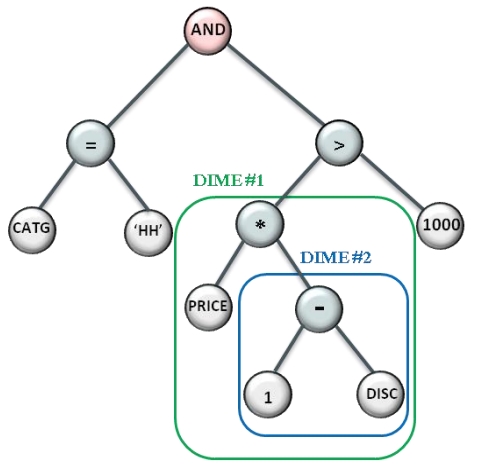 Figure 7. Logical expression tree showing top-level expression
Figure 7. Logical expression tree showing top-level expression price*(1-discount) as DIME#1 and sub-expression (1-discount) as DIME#2
之后会评估 DIME是否在内存中,是否内存执行开销更小等
如果都满足则替换子树,否则还是按照原始的执行计划执行,如下:
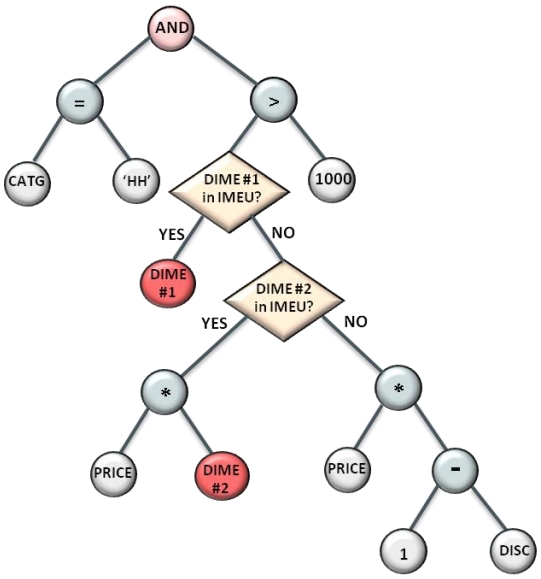
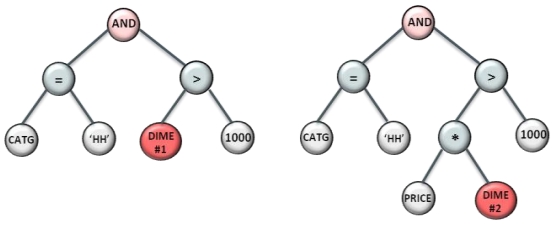
如果DIME1 满足则变成下面左边的执行计划
如果DIME1 不满足,但是 DIME2 满足,则变成下面 右边的执行计划
其他一些优化
- 存储索引中包含了min、max,在扫描时候可以跳过不需要的 IMEU
- 向量化执行
- 字典编码格式化,如:upper(substr(a, 1, 3)) = ‘DOG’,如果substr(a,1,3)在 DIME中,则可以替换为 upper(DIME) = ‘DOG’
- 延迟物化
性能评估
主要有以下改善:
- 改进响应时间
- 减少CPU使用率
- OLTP、OLAP混合场景下提高吞吐量
In-Memory Virtual Columns
- 1亿行,8G大小,采用内存压缩配置
- 四个虚拟列、5个查询如下
Table 2. List of user-defined VCs
| VC Name | Expression |
|---|---|
| VC1 | (rand64k/1000)+(rand1m/1000) |
| VC2 | ((1-(rand15/100))+(rand1m/10)+rand64k) |
| VC3 | (0.3*rand15) |
| VC4 | SUBSTR(randstringsize26,10,5) |
Table 3. Point queries on Atomics table
| ID | QUERY |
|---|---|
| Q1 | SELECT MAX(rand15) FROM atomics WHERE((rand64k/1000)+(rand1m/1000))=10; |
| Q2 | SELECT MAX((1-(rand15/100))+(rand1m/10)+rand64k) FROM atomics; |
| Q3 | SELECT MAX(uniq100m) FROM atomics WHERE ((1-(rand15/100))+(rand1m/10)+rand64k)=10000; |
| Q4 | SELECT MAX(uniq100m) FROM atomics WHERE (0.3*rand15)+((rand64k/1000)+(rand1m/1000))<100; |
| Q5 | SELECT MAX(rand15) FROM atomics WHERE UPPER(SUBSTR(randstringsize26,10,5))=‘limja’; |
发现 top-level 的表达式有了 1000倍的加速(图10-a),而子表达式有 2倍 加速(图10-b)
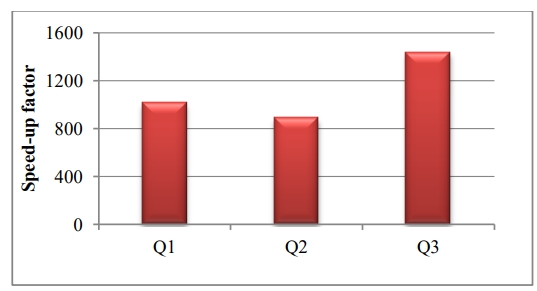
Figure 10a. Speed-up in Atomics queries with top-level expressions materialized as DIMEs
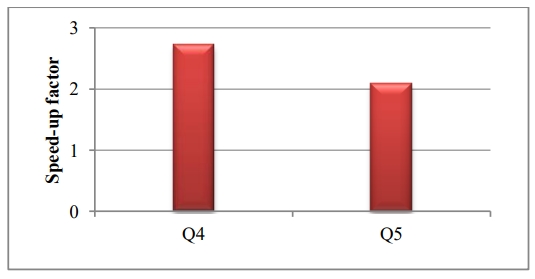
Figure 10b. Speed-up in Atomics queries with only subexpressions materialized as DIMEs
Analytic Workload: Auto-capture of DIMEs and Query Acceleration
这里使用了 TPC-H 的测试集,TPC-H一共包含了 8 个表
下面展示了 LINEITEM 和 ORDERS 两张表的表达式,以及相关的 3个查询
- Q1是执行基于表达式的过滤
- Q2是基于表达式的聚合
- Q3更复杂,执行聚合和分组
由于Q1 和 Q2都在 DIME中,加速效果最好,其中Q2加速最好
Table 4. Top expressions captured by ESS
| Table Name | Expression |
|---|---|
| LINEITEM | l_extendedprice * (1-l_discount) |
| LINEITEM | l_extendedprice * (1-l_discount) * (1+l_tax) |
| ORDERS | CASE when (o_orderpriority<>(1-urgent) and o_orderpriority<>(2-high)) then 1 else 0 END |
| ORDERS | CASE when (o_orderpriority<>(1-urgent) and o_orderpriority<>(2-high)) then 1 else 0 END |
| LINEITEM | CASE when l_receiptdate > l_commitdate then 1 else 0 END |
| ORDERS | SYS_OP_BLOOM_FILTER(:BF0000, o_custkey) |
| LINEITEM | SYS_OP_BLOOM_FILTER(:BF0000, l_partkey) |
| ID | QUERY |
|---|---|
| Q1 | SELECT SUM(l_quantity) FROM lineitemWHERE (l_extendedprice*(1-l_discount))> (SELECT AVG(l_extendedprice*(1-l_discount)) FROM lineitem); |
| Q2 | SELECT MAX(l_extendedprice*(1-l_discount)) FROM lineitem; |
| Q3 | SELECT l_returnflag, l_linestatus, SUM(l_quantity),SUM(l_extendedprice), SUM(l_extendedprice*(1-l_discount)),SUM(l_extendedprice*(1-l_discount)(1+l_tax)), COUNT() FROM lineitemGROUP BY l_returnflag, l_linestatus; |
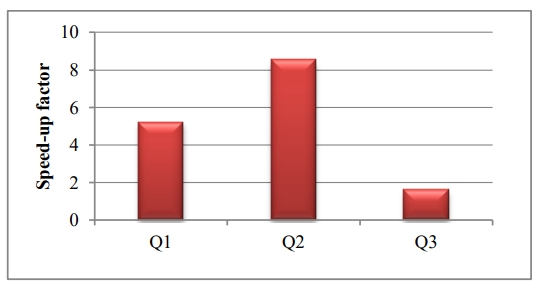
Figure 11. Speed-up in analytic queries on LINEITEM with l_extendedprice * (1-l_discount) materialized as a DIME
JSON Query Acceleration
Oracle于2014年引入JSON支持,支持其存储格式,以及SQL透明查询
JSON_VALUE是 json值到SQL值的桥接
总数据大概 40G,两个表达式
- JSON_VALUE(jobj, ‘$.num’ RETURNING NUMBER)
- JSON_VALUE(jobj, ‘$.dyn1’ RETURNING NUMBER)
| ID | QUERY |
|---|---|
| Q1 | SELECT COUNT(*) FROM nobench_main WHERE json_value(jobj,’$.num’ returning NUMBER) BETWEEN 1 AND 1000; |
| Q2 | SELECT COUNT(*) FROM nobench_main WHERE json_value(jobj,’$.num’ returning NUMBER) BETWEEN 1 AND 100000 GROUP BY json_value(jobj, ‘$.thousandth’); |
| Q3 | SELECT COUNT(*) FROM nobench_main WHERE json_value(jobj, ‘$.dyn1’ returning NUMBER) BETWEEN 1 AND 1000; |
Q1 和 Q2 直接基于内存物化的结果,可以达到20倍的加速,而Q3需要基于JSON_VALUE表达式再聚合,提升 5倍性能
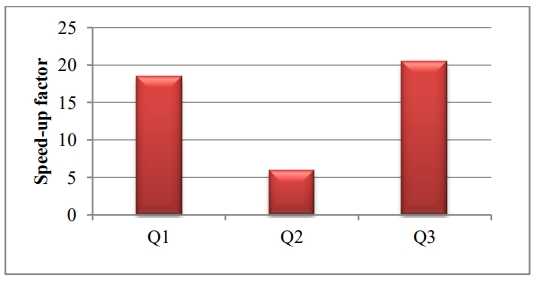
Figure 12. Performance boost in JSON query processing with JSON_VALUE DIMEs
Accelerate OLTAP Mixed Workloads
Oracle是第一款工业级别的混合 行 和 列格式存储的数据库
使用内存中的列来加速分析场景,使用 DIME 来加速OLTP场景
吞吐量的为 2000/s, 99%的DML操作,1%的分析操作
Table 7. List of DIMEs materialized in-memory
| ID | Expression |
|---|---|
| E1 | ROUND(n2 /1000000+n3/1000000) |
| E2 | 1+(n2/1000000)+(n3/1000000)+(n4/1000000) |
Table 8. Analytic queries in synthetic OLTAP workload
| ID | Expression |
|---|---|
| Q1 | SELECT MAX(( 1+(n2/1000000)+(n3/1000000)+(n4/1000000))) FROM c101_6p1m_hash; |
| Q2 | SELECT MAX(n2) FROM c101_6p1m_hash WHERE ROUND(n2 /1000000+n3/1000000)= 10; |
| Q3 | SELECT MAX(n3) FROM c101_6p1m_hash WHERE (1+(n2/1000000)+(n3/1000000)+(n4/1000000))= 8; |
Q1、Q2、Q3是分析查询,在OLTP场景中,其中值有200倍提升,吞吐量为 2000/s
CPU使用率为 28.6%,而没有DIME时,吞吐量下降,CPU使用率达到100%
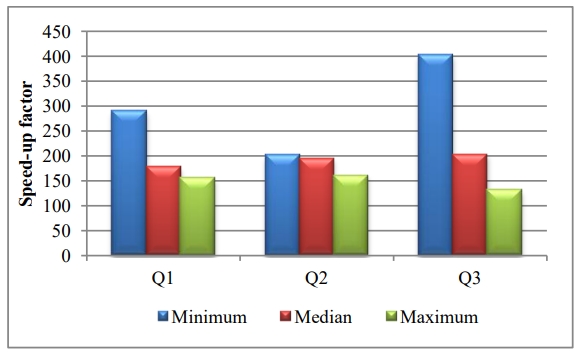 Figure 13. Speed-up in minimum, median and maximum response times of queries in OLTAP workload with DIMEs
Figure 13. Speed-up in minimum, median and maximum response times of queries in OLTAP workload with DIMEs