Access Path Selection in Main-Memory Optimized Data Systems Should I Scan or Should I Probe
原文
https://15721.courses.cs.cmu.edu/spring2020/papers/13-execution/kester-sigmod17.pdf
介绍
对于传统系统来说
- 如果有主索引,那么查询时肯定是走索引了
- 如果没有索引,那么就是全表扫描
对于 二级索引,就不同了,它是需要回表的,有多次I/O
而现代化的硬件,可能 顺序扫描比 走二级索引更好
- 现代数据系统都是列存的,只需要访问指定的列就行了
- 向量化模型,一次一批效率更高
- 列存的数据压缩更好
- 顺序scan在并发情况下,是可以共享的
- SIMD执行让顺序scan效率也提高很多
由于大内存的出现,现代分析系统往往不再考虑二级索引,而专注于对scan更多的优化,他们往往只提供单个路径访问方式
本论文要回答两个问题
- 现代分析系统中,仍然需要使用二级索引吗?
- 随着硬件和系统的进步,我们如何做 access path selection?
本文主要关注 主内存系统,大多都是读场景,写只有append-only,以及单独的线程去做合并,写入到 读优化的文件系统中
在现代系统中,访问路径的选择性不是一个固定值,而是一个斜率,具体跟并发数量、硬件特性、数据布局有关

访问路径选择
首先需要考虑一些预备的参数
- select 算子
- 参数和符号
- 查询工作负载的建模
- 建模数据布局
- 硬件特性
- 其他扫描增强,如zone-map
- 压缩
- B+ 树
Table 1: Parameters and notation used to model access methods and to perform access path selection.

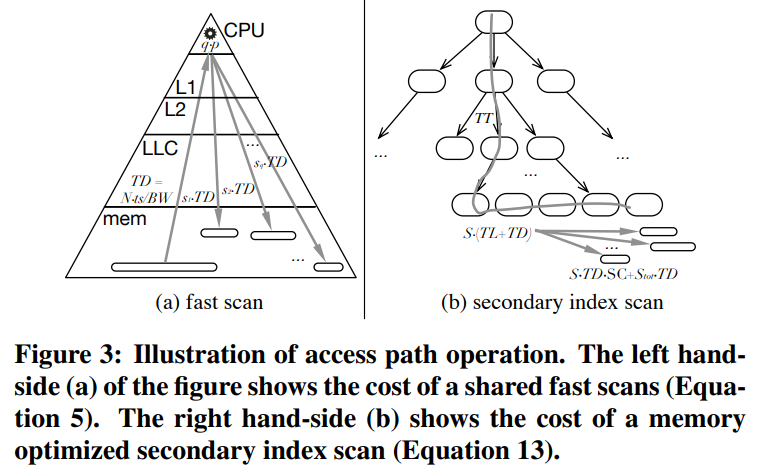
Modeling In-Memory Shared Scans
- 数据移动 $T_{DS} = \frac{N·ts}{BW_{S}}$
- 谓词评估 $PE = 2·f_{p}·p·N$
- 写入结果 $TD_{R} = \frac{N·rw}{BW_{R}}$
- 单个查询的开销(4) $SingleQueryCost = max(TD_{S}, PE) + si·TD_{R}$
- 共享查询的开销(5) $SharedScan = max(TD_{S}, q·PE) +S_{tot}·TD_{R}$
Modeling In-Memory Secondary B+-Trees
- 树的遍历,$TT = (1 + \lceil logb(N) \rceil) · (C_{m} + \frac{b·C_{A}}{2} + \frac{b·f_{p}·p}{2})$
- 遍历叶节点,$si· TL, where, TL = \frac{N·C_{M}}{b}$
- 二级索引的数据访问, $si· TD_{I}, where, TD_{I} = \frac{N·(aw+ow)}{BW_{I}}$
- 写结果, $RW = si·N·\frac{rw}{BW_{R}}$
- 结果排序,$SC_{i} = si·N·\log2(si·N)$
- 单个索引的探测时间, $SingleIndexProbe = TT + si · (TL + TD_{I}) + RW + SC_{i}$
- 并发的索引访问, $ConcIndex = q·TT + S_{tot} · (TL + TD_{I}) + S_{tot}·TD_{R} + SF·CA, where$
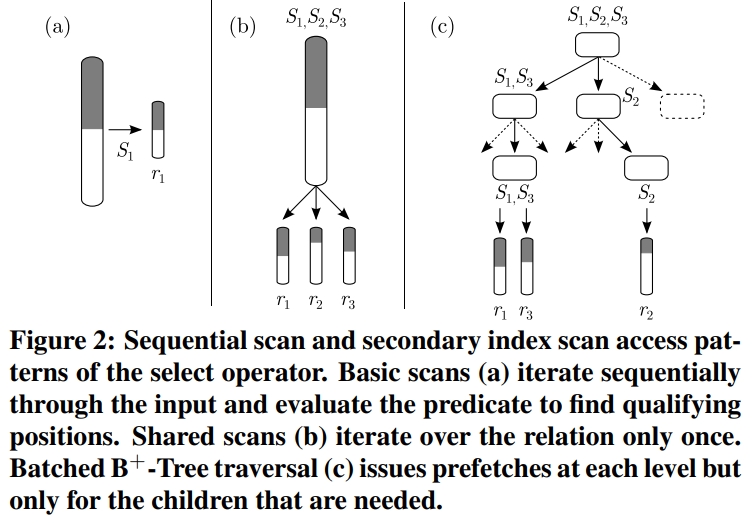
访问路径的选择
Access Path Selection = $APS = \frac{ConcIndex}{SharedScan}$
这里的选择性是因子,如果很高,说明要扫描很多tuple 倾向于scan;否则倾向于index
- 当APS >= 1,倾向于使用scan
- 当 APS < 1,倾向于使用索引
测试
下面几张图,首先的硬件参数:
- HW1,ng CM = 180ns, CA = 2ns, BWS = 40GB/s, BWI = 20GB/s, and BWR = 20G
- HW2,2, withCM = 100ns, and bandwidth BWS = 160GB/s, BWI = 80GB/s, and BWR = 80G
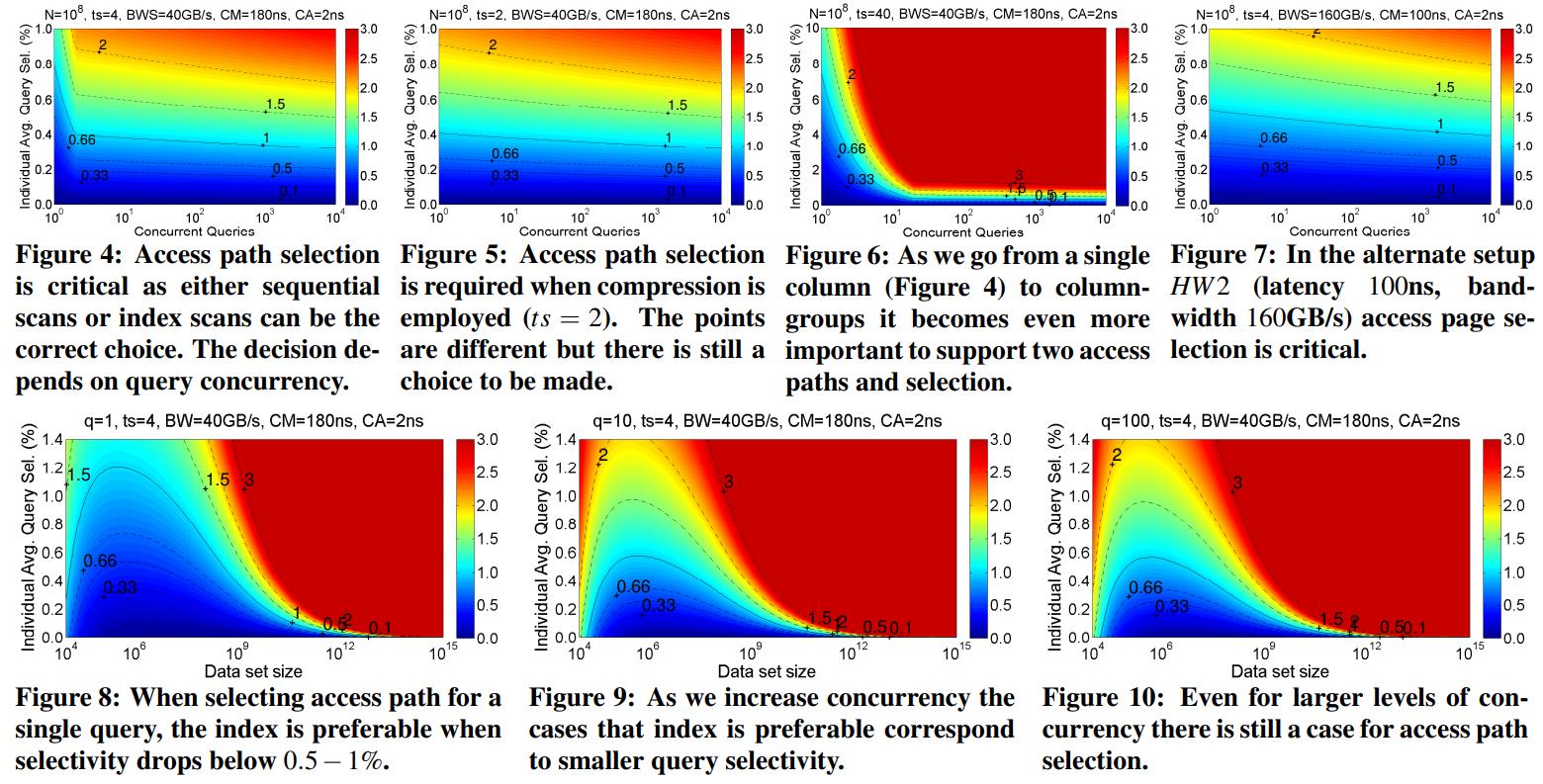
上图 4- 7的x轴是查询并发度,y轴是每个查询的独立选择性
图8 - 10,x轴是数量N,y轴依然是选择性
深蓝色的表示表示 APS很低,会选择二级索引,亮蓝色的表示二级索引有 2-3倍的加速
中间蓝绿过度表示 scan和index差不多
黄色部分表示 scan有1.5 - 2倍的加速
红色区域,尤其是深红色表示用共享scan 有3倍的加速
上图中
- 4 - 8中,随着并发的增加,就更偏向于scan,图4、图5是压缩和不压缩看起来都差不多
- 图6是更多列的影响,图7的 另一种硬件场景
- 图8是随着数据集大小的增大,更偏向于scan
- 图9、10是增大了并发度
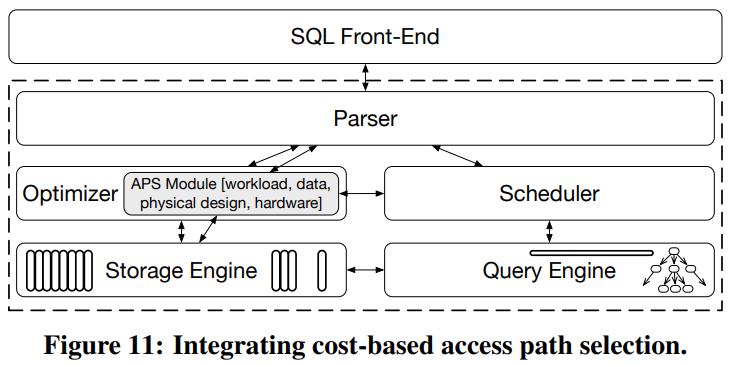
现在我们将 访问路径选择,跟查询优化器做整合,这时候APS 就称为优化器的一部分
- 为了实现此功能,需要更好的收集相关数据
- 比如数据布局、硬件特征、查询并发性
- 因为现代系统是基于主内存的,响应时间很快,因此需要高效的收集,快速的做出决定
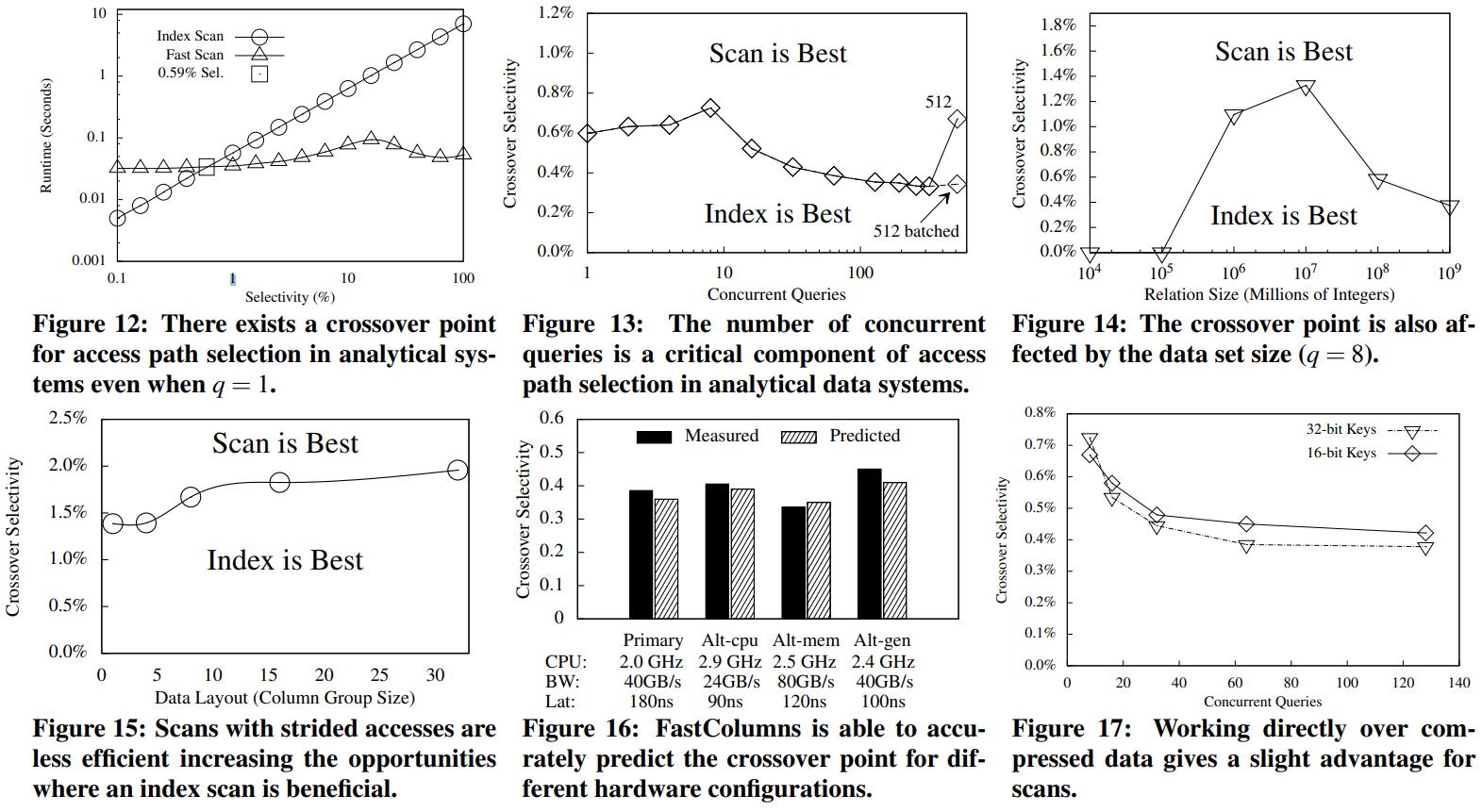 解释上图
解释上图
- 图12、图13都是类似的,图12是单个查询,图13是1 - 512并发查询
- 图12中随着并发的增加,使用索引的代价就很高了
- 图13中,上面是scan更合适,下面是索引更合适,在选择性较低的情况下,索引都比较合适的
- 这也解释了图1, 这条线并不是单纯的直线,总的来说随着并发的增加,共享scan的效果就更好,被平摊了
- 图14是数据大小对其影响,一开始索引合适,随着数据量增大,索引的效果也在降低
- 图15是混合列的布局,随着列数量增加,二级索引就更像是面向行的情况,可以过滤掉更多数据
- 图16是各种硬件不同的场景,路径选择需要监控适配不同的硬件场景才能达到更好的性能
- 图17是压缩场景下,scan会略好一点,但是两种访问路径都仍然有用
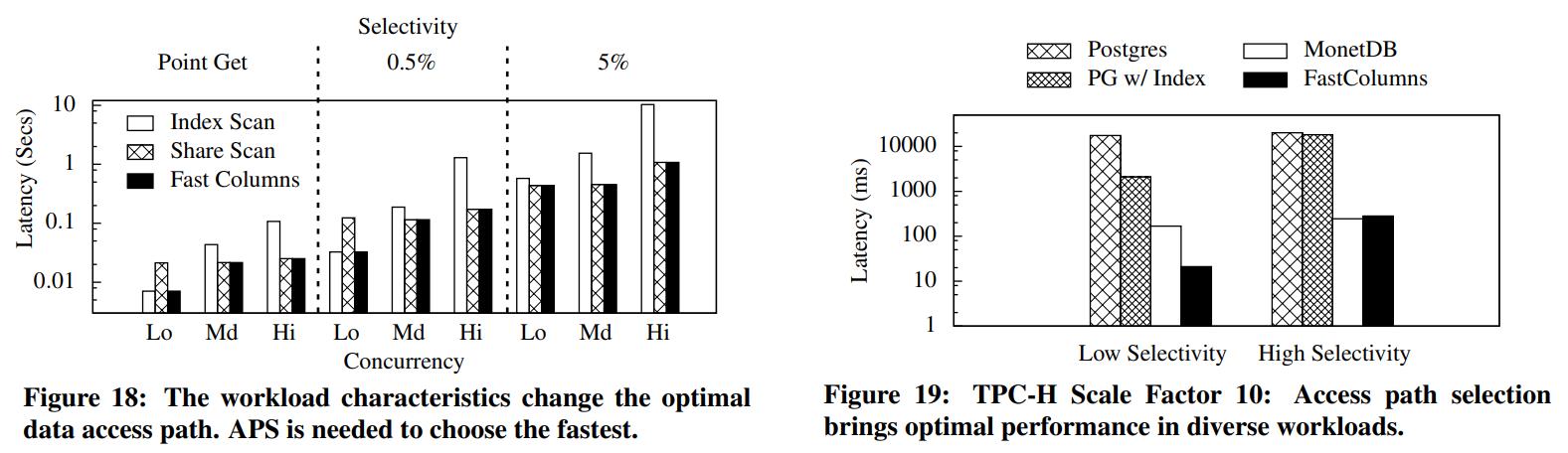 解释
解释
- 图18中,是混合了9种场景,包括并发的 low、middle、high,以及选择性很低的点查,选择性中等,较高等场景
- 图18中可以看到没有哪个路径选择对于所有场景都通吃的
- 在不同场景下各种路径选择都用,所有优化器需要根据不同的场景做出合理的选择
- 图19,TPC-H场景,包含了MonetDB、PG
结论
近些年来,访问路径选择,交叉点的变化
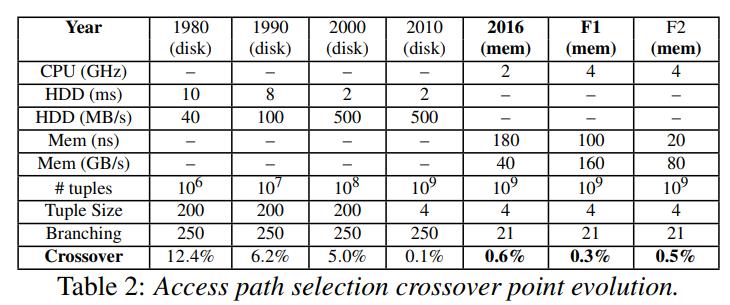
总结
- 即使在主内存中,消除了磁盘I/O的影响,二级索引在某些情况下仍然是非常不错的
- 细粒度的访问路径决策,除了选择性、硬件参数、系统设计、数据布局,还需要考虑并发性
- 对于小数据集场景下,scan的效果很好,而随着数据集变大,索引更有效,因为完整的scan成本很高
- 访问路径的交叉点虽然比过去低了,但它仍然有不断增长的基数,如在5亿整数中选择0.6%的查询,就是300W个tuple
- 共享数据访问可以最小化重复读的开销,但也包含了分发的开销;因为保持记录和分配的开销,在一定量的批处理大小时共享结果最高效
- 访问路径选择对于列存是很重要的,但对于混合存储来说会更重要
- 随着cache和内存延迟降低/内存带宽降低,有利于index;而慢的cache/内存/快内存总线有利于scan;访问路径需要平衡硬件参数