Make the most out of your SIMD investments: counter control flow divergence in compiled query pipelines
原文
https://15721.courses.cs.cmu.edu/spring2023/papers/08-vectorization/lang-vldbj2020.pdf
背景
最近十年,越来越多的数据库系统使用了SIMD,主要用于这几种操作
- SELECT
- JOIN
- 分区
- 排序
- CSV 解析
- 正则表达式匹配
- 压缩/解压缩
SIMD主要用于解释执行数据库,对于编译执行的数据库,如HyPer则使用的很少
而现代CPU的寄存器更宽了,并行度更高了
比如AVX-512,可以使整个向量化查询流水线化,得到更高的并行度,同时可以将整个CPU cache放入单个指令中,多个64位指令可以打包到单个指令中
使整个查询流水线会带来很多挑战
- 在查询求值期间,保持所有的SIMD执行都繁忙
- 但有些动态的tuple不满足控制流,比如不满足谓词计算,那么对应的SIMD流水线就会受到影响
- 一个非向量化的流水可以返回一个 分支控制流,然后抓取下一个tuple
- 但是向量化的不行,要不就全满足、或者全不满足;只有部分满足的会导致其他指令会继续执行,从而影响效率
- 一种方式:忽略那些不规范的tuple,不引入分支逻辑,通过bitmap来记录那些不满足的tuple,当中间结果需要物化,那些不规范的tuple就不写
- 这种方式缺点是,活跃和不活跃的元素都被执行了,也影响了开销
- 关键点在于,有些vector-processing units VPC,向量处理单元并非充分利用
- 好的算法需要统计这些未充分利用的向量处理单元
- 一般的做法是将tuple物化到内存中,但这会使管道断开也影响了效率
- 这篇论文中引入的算法、策略是尽量不断开管道
AVX512指令集
这里简单的介绍下AVX512指令集
- 掩码指令
- 排列指令
- 压缩/扩展指令
1、掩码指令
一个add指令需要 a、b两个操作符,以及目标寄存器
AVX512中,变成这样:
|
|
这是在原始add指令基础上,增加了掩码操作
对 掩码指定的a、b中的向量执行加法,其余掩码为 0 的元素,从src 复制到 dst
掩码指令可以预防单个向量组件被修改
掩码指定被用于比较指令,存储到特定的掩码寄存器中,现在的宽度为256bit
2、重排列
相当于一个shuffle操作,根据给定的index 向量,来shuffle输入的向量
这个指令在之前的版本中就有了,能实现一次两个元素操作,现在是四个

3、压缩/扩展
这是 AVX512指令集中新引入的
压缩指令,存储掩码指定的活跃元素,将他们连续保存到目标寄存器中
扩展指令,根据0、1指定目标位置是否有元素,然后将连续的 src填充上

向量化流水线
对于编译型数据库如 Hyper,它的控制流无论到达哪个算子,都能确定当前肯定是 只有一个tuple被执行
但是向量化就不同了,因为同时会执行多个tuple,他们的控制流可能不同,这就导致了一个问题
- 当触发一个分支操作时,某些 SIMD 的执行可能不是活跃的,如果至少有一个tuple满足条件,分支就会被触发
- 如果向量长度为 n,那么最多可能会有 n - 1 个元素是不活跃的
比如下面的操作,包含scan、select、join
初始时,所有的scan都是活跃的,因为执行select、join某些元素可能会变得不活跃(由 x 标记),但是没有走到 no match分支,因为一些元素仍是活跃的
比如道路4第一次就找到了join的伙伴,但是1和6要迭代三次才行,这就导致了出现等待
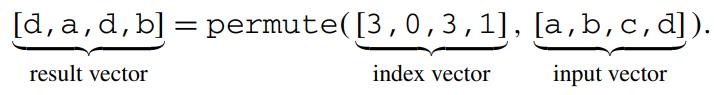 Fig. 1 During query processing, individual SIMD lanes may (temporarily) become inactive due to different control flows. The resulting underutilization of vector-processing units causes performance degradations. We propose efficient algorithms and strategies to fill these gaps
Fig. 1 During query processing, individual SIMD lanes may (temporarily) become inactive due to different control flows. The resulting underutilization of vector-processing units causes performance degradations. We propose efficient algorithms and strategies to fill these gaps
填充算法
这个算法的本质是,将新元素 复制到目标寄存器中所需的位置
这里期望的位置,就是不活跃元素的位置,活跃/不活跃 是通过比特位控制的,如果设置了这个bit,就表示活跃的
需要识别两种情况
- 新元素是从源内存地址中拷贝的
- 元素已经在向量中了
Memory to register
从内存中填充一般出现在scan算子中,从内存中读取连续的元素
这里需要两个指令
- 一个掩码指令,里面包含的是活跃的元素,取反就能获得哪些元素是不活跃的
- 一个向量指令 expand load,用来执行实际的加载
总体上,这些操作可以直接使用 AVX512提供的指令来完成
 Fig. 2 Refilling empty SIMD lanes from memory using the AVX-512 expand load instruction
Fig. 2 Refilling empty SIMD lanes from memory using the AVX-512 expand load instruction
table scan会产出一个额外的输出向量,包含最新加载属性的tuple标识符 TID
TID是从当前读位置导出并使用的,延迟加载不同列的属性值、或重建tuple顺序
下图说明如何使用 图2中的读位置、掩码位置更新 TID向量寄存器内容
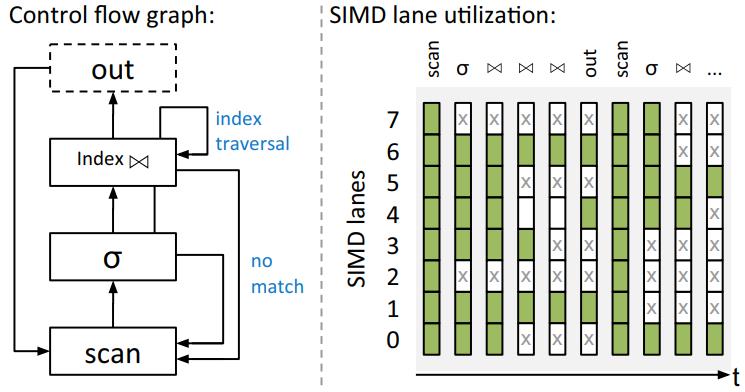
Fig. 3 TIDs are derived from the current read position and assigned to a TID vector register
Register to register
这是要求在两个 向量寄存器之间移动,主要使用了 compress 和 expand 两个指令
- 首先从 源寄存器中找出活跃的元素
- 通过掩码、compress指令,将源中 活跃的元素写入中间存储
- 之后计算目标寄存器中 不活跃 的元素
- 通过expand指令,将中间结果写入到目标寄存器中
- 更新目标寄存器的 bitmark
- 如果要更新多个源/目标寄存器,则计算 排列的开销会跟后面的源/目标寄存器 平摊
- 可能需要拷贝多个属性
- 如果不是所有元素都要移动,则需要更新源寄存器
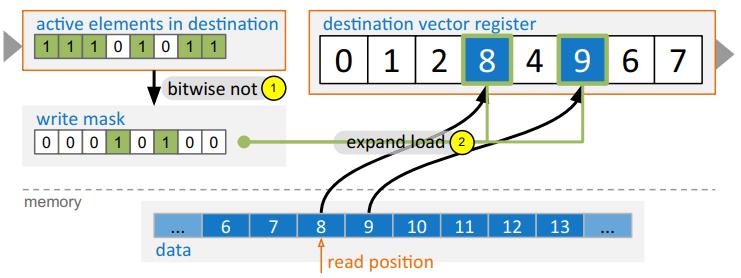
Fig. 4 Computation of the permutation indices and the permutation mask based on positions of the active elements in the source register and the inactive elements in the destination register
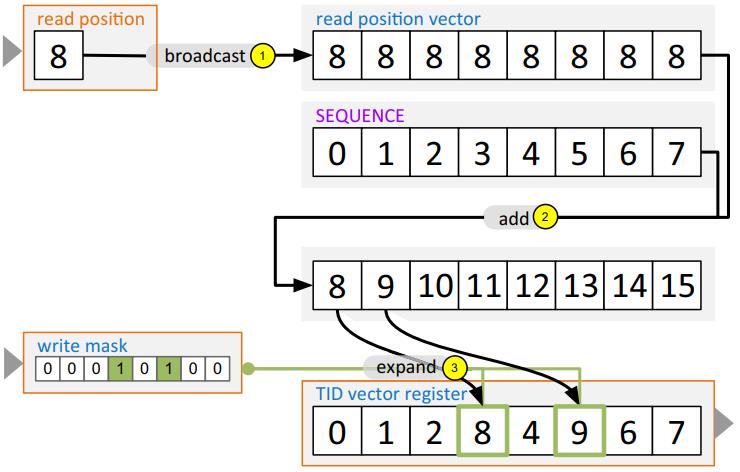 Fig. 5 If not all elements could be moved from the source to the destination register, the source mask needs to be updated accordingly
Fig. 5 If not all elements could be moved from the source to the destination register, the source mask needs to be updated accordingly
下面是填充代码
|
|
Variants
下面是两个填充算法
- 第一个是普通的,第二个是带压缩的
- 这里适配了所有场景
- 活跃元素存储在随机位置
- 活跃元素连续存储 Listing 1 Generic refill algorithm
|
|
Listing 2 Refill algorithm for compressed vectors
|
|
重填充策略
将填充算法整合到查询中
这里主要包含两个策略consume()和produce()
采用的是DFS遍历
生成顺序是
- produce父节点
- produce子节点
- consume
由 if语句来控制,确保只有在 SIMD 寄存器足够满的情况下才执行
Consume everything
主要策略
- 这里使用了一个额外的
buffer寄存器 - 如果if条件不满足则会推迟执行
- 当触发到 else分支时,将所有 活跃的 tuple移动到 buffer中
- 这里采用的就是之前提到的 填充策略算法
- 并将buffer中的tuple 加载到未使用的SIMD管道中
- 这里还会使用一个 阈值来控制触发填充的动作
当控制流返回的时候,SIMD所有管道都是空的,所以叫做:consume everything
核心策略如下:
Listing 3 Code skeleton of a buffering operator.
|
|
Partial consume
在这个场景下,就不再处理全部输入了,consume 会推迟执行,并返回给前面的算子
另外活跃的管道中包含了推迟的tuple,所以不能覆盖、不能重写,需要有保护机制
也就是管道的拥有者,当然,如果tuple不满足条件的话,会放弃这个所有权
tuple包含机制需要额外的记录信息
- 刚刚到达的tuple
- 被早起迭代算子本身保护起来了
- 已经走到流水线的后期阶段
这里需要两个额外的掩码
- 识别当前算子拥有的管道
- 识别延迟算子拥有的管道
Listing 4 Code skeleton of a partial consume operator
|
|
对比
- 6-a 是没有充分利用的场景,6-b是充分利用的场景
- 这里包含了 scan、select、join几种典型的场景
- 在6-b中,紫色、黑色的线表示读、写buffer,设置阈值为75%利用率
- 6-c 中,紫色的线是保护状态,利用率阈值设置为 50%
- 但6-c中,如果把保护状态,当做 空闲的,那么利用率总体是下降的,这也是缺点
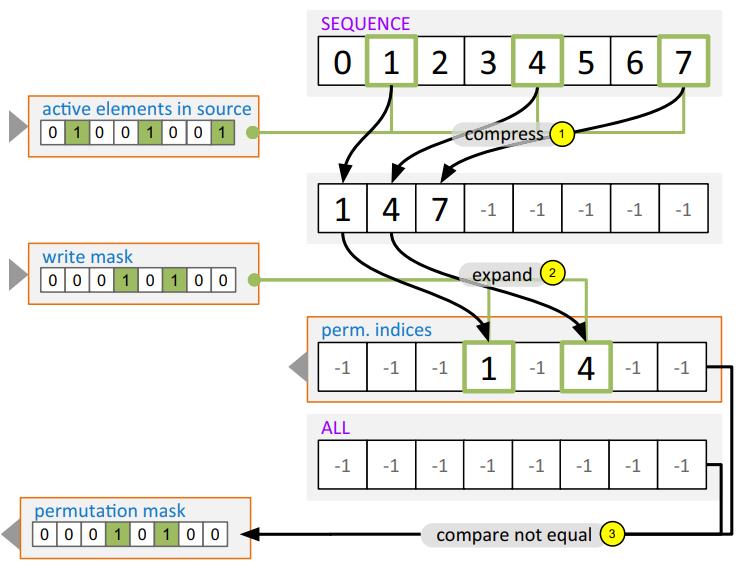
Fig. 6 SIMD lane utilization using different strategies. - In a, no refilling is performed to visualize the divergence.
- b Uses the consume everything strategy, which performs refills when the utilization falls below 75%. The dashed purple lines indicate a write to buffer registers, black lines a read.
- c shows a partial consume throughout the entire pipeline with the minimum required utilization set to 50%. Lanes colored in purple are protected (color figure online)
对两种策略的讨论
- 这两种策略不是排斥的,是可以共存的
- 只要buffer能感知到,就可以包含这个管道,混合策略
- 当然,如果处理的代价很低,则不做任何策略处理也是可以的
- 消费所有,需要额外的寄存器,如果寄存器不够,会溢出到内存
- 消费部分也需要额外寄存器,但用的是掩码,需求量要小一些
- 消费部分第一个算子用来填充空的管道,但如果其他算子处于非充分利用时,就会将控制流返回到前面算子
- 这个流程增加会导致效率降低
- 全部消费是写到buffer中,只跟buffer大小有关,buffer大小依赖于
- 沿着管道传递的属性数量、保存算子内部状态的寄存器数量
性能评估
主要包括这几种
- scan中带有谓词求值的
- hash join
- 近似地理位置join
软硬件环境
- Intel Skylake-X
- Intel Knights Landing
- 都支持512位的向量
- GCC5.4 + -O3
- tuple是2^16 – 2^20
Table scan
使用 TPC-H的 Q1,这是一个单表查询,基于group by的聚合的几个算数操作
几乎所有的tuple都被选择了,选择率为 0.98
为了对比,改变扫描谓词对shipdate属性的选择性
这里包含了好几组不同的实现
- scalar,非SIMD实现
- divergent,根据《Exploring Query Execution Strategies for JIT, Vectorization and SIMD》这个论文做了一些修改,原始版所有tuple都通过流水线,不满足的会被忽略,这里是允许,16个元素并行处理
- Partial/Buffered,使用了重填充算法,不再使用SIMD对其加载,而使用gather指令,都设置了最小利用率阈值
- Materialization,使用内存作为输出,当buffer满了就执行
7-a看起来整体差别不大
7-b时,当选择率大于 0.001时,divergent 比 scalar要慢
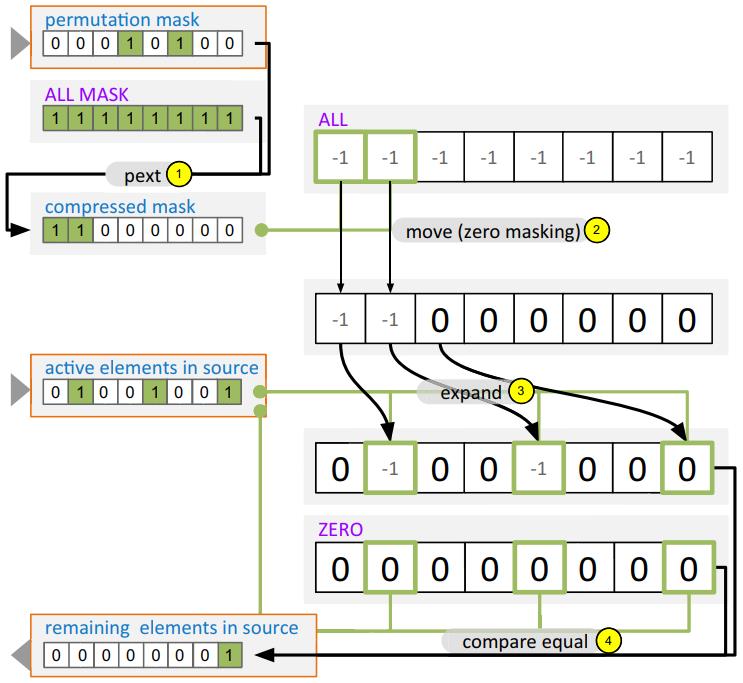
Fig. 7 Performance of TPC-H Q1 with varying selectivities
8-a,这里固定了选择性为 0.01,物化方式的峰值在 >= 1024 时最好
8-b,buffer(全消费)方式 >=6,性能就开始不断增加,16时到达峰值
而 部分消费,太小太大 时性能都不是最好的
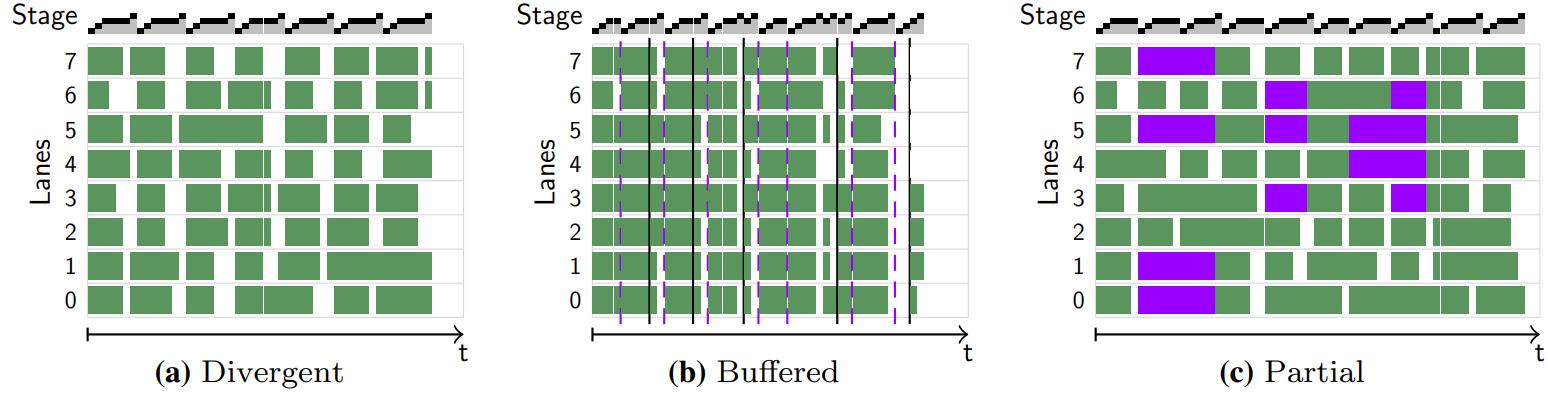 Fig. 8 Performance of TPC-H Q1 performance on SKX when varying algorithm parameters
Fig. 8 Performance of TPC-H Q1 performance on SKX when varying algorithm parameters
Hashjoin
仍然是几种不同的实现对比
- scalar,非SIMD实现
- Divergent,8个tuple并行处理
- Partial/Buffered,重填充算法
图9 - 图10显示了性能结果
hash表size为 10K - 45M,依赖于输入大小
9-a,9-b来看,随着hash size增大,性能也变差,这是因为L1、L2装不下了,变差L3或者内存了
使用20线程时,buffer方式提高了32%,部分方式提升了19%
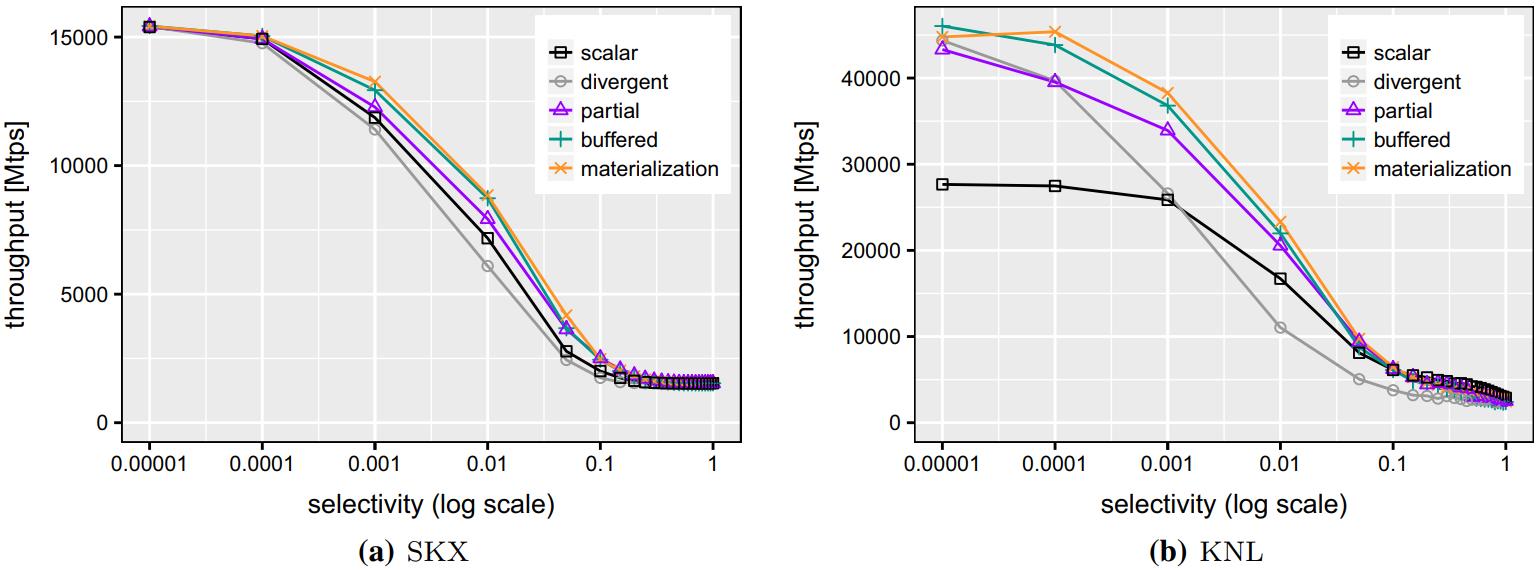 Fig. 9 Hashjoin performance when varying build sizes. SKX
Fig. 9 Hashjoin performance when varying build sizes. SKX
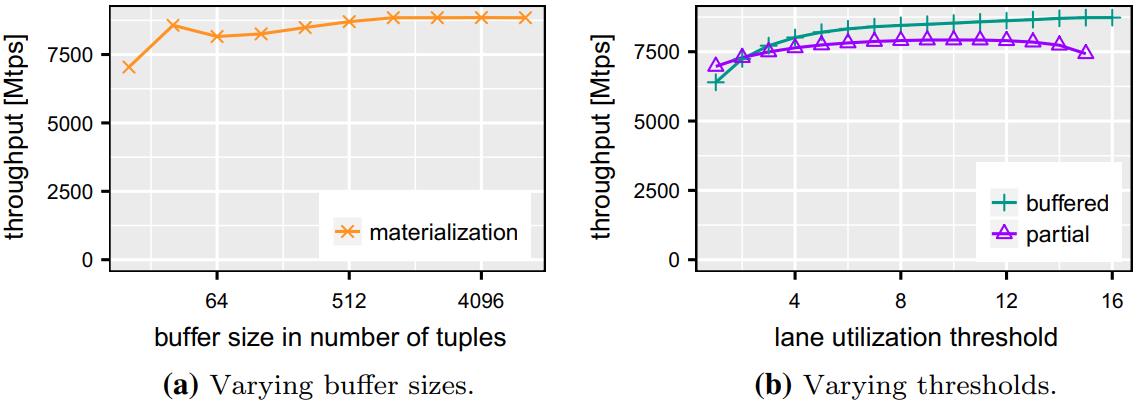 Fig. 10 Hashjoin performance when varying build sizes. KNL, 128 threads
Fig. 10 Hashjoin performance when varying build sizes. KNL, 128 threads
当使用20线程时,吞吐量比 10线程提高了一倍
部分方式跟buffer的有些不同,差不多在5线程时比较好
物化时 128 - 1024时,是最佳的
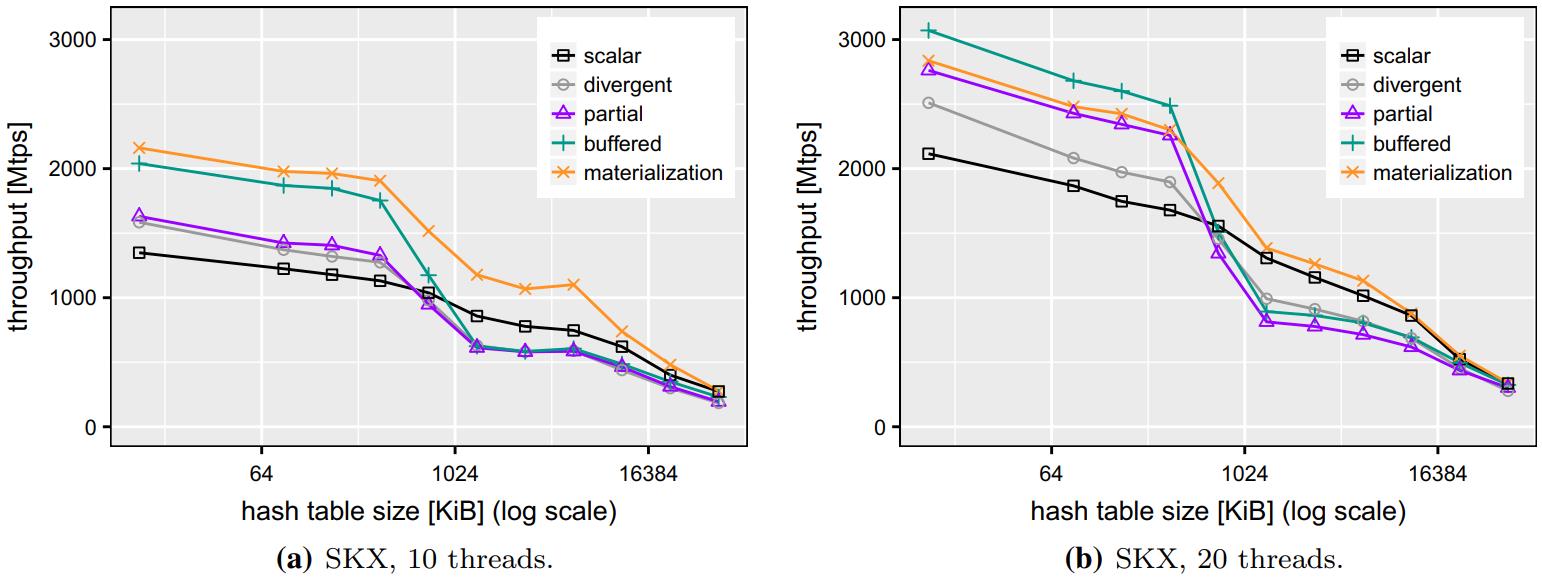 Fig. 11 Hashjoin performance when varying algorithm parameters
Fig. 11 Hashjoin performance when varying algorithm parameters
影响吞吐量的其他因素包含
- 匹配概率
- 填充因子
scalar方式在低匹配率时表现较好,达到50%时最差
匹配概率为100%时,也不是很好,会在其他地方浪费时间
divergent、以及两个填充算法,当匹配概率变高时效率也变好,因为有更多活跃元素
但因为要查找冲突链表,效率也不会好很多
装载因子是,hash表桶的数量 / hash表中key数量
装在因子小碰撞也高
更大的装在因子,其吞吐量是 小的 3倍
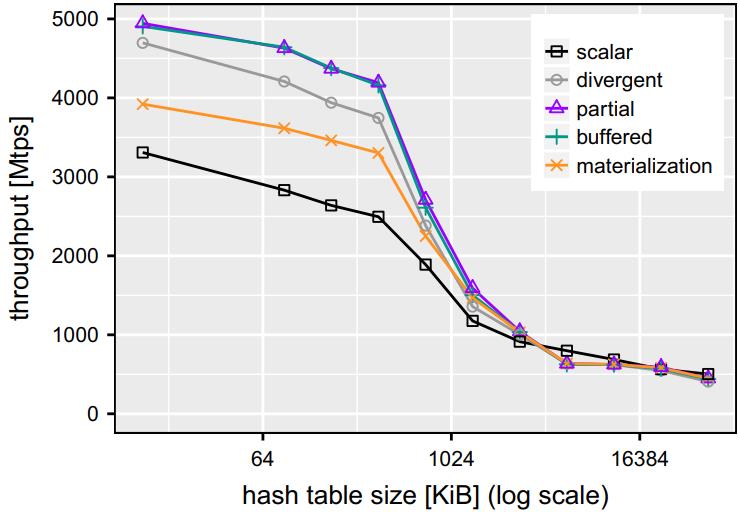 Fig. 12 Hashjoin performance for varying match probabilities (a), hash table load factors (b). SKX, 20 threads
Fig. 12 Hashjoin performance for varying match probabilities (a), hash table load factors (b). SKX, 20 threads
Approximate geospatial join
利用四叉树,加上基数树,显示的NY临近图布局
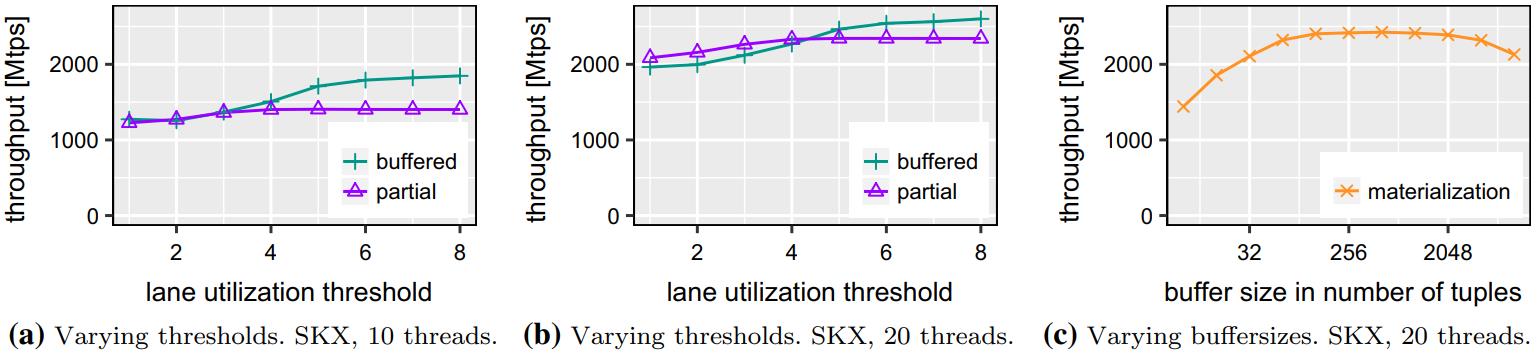 Fig. 13 Quadtree-based cell-approximation of neighborhood polygons in NYC
Fig. 13 Quadtree-based cell-approximation of neighborhood polygons in NYC
查询流水线包括
- Scan point data (source)
- Prefix check
- Tree traversal
- Output point-polygon pairs (sink)
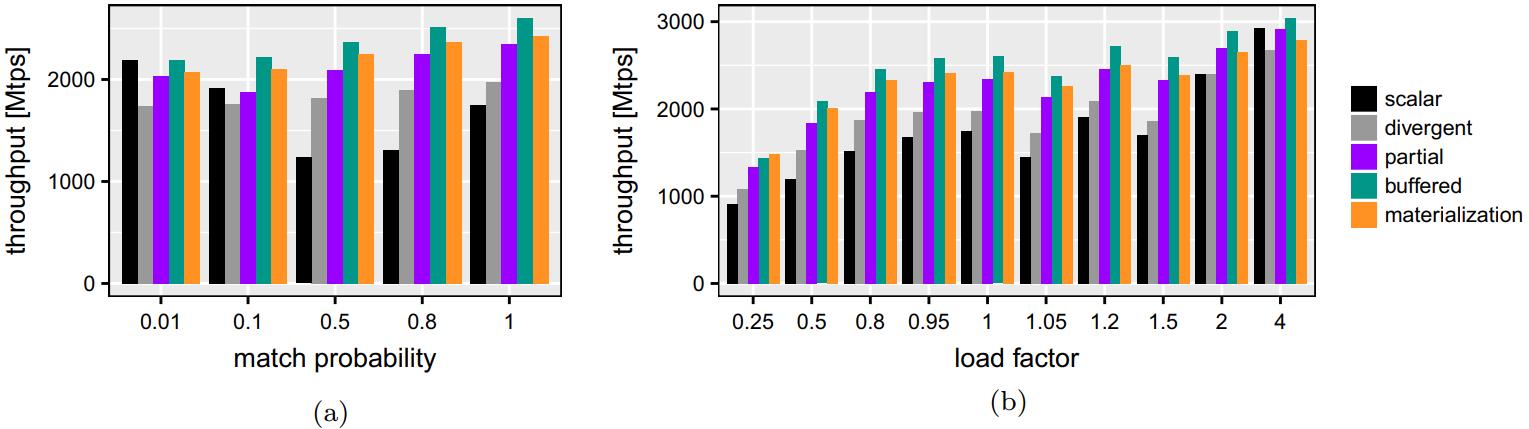 Fig. 14 Geospatial join performance for varying workloads and precisions
Fig. 14 Geospatial join performance for varying workloads and precisions
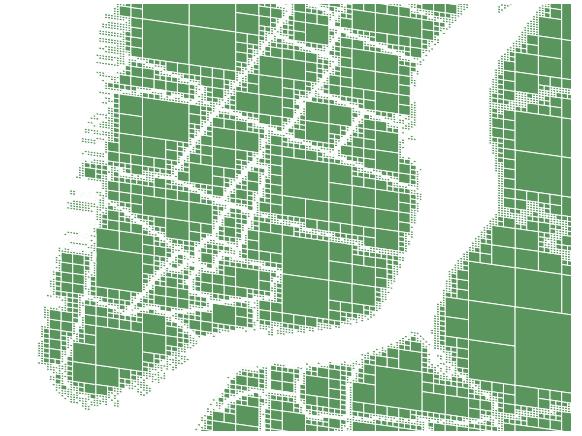
Fig. 15 Varying thresholds. KNL, 128 threads
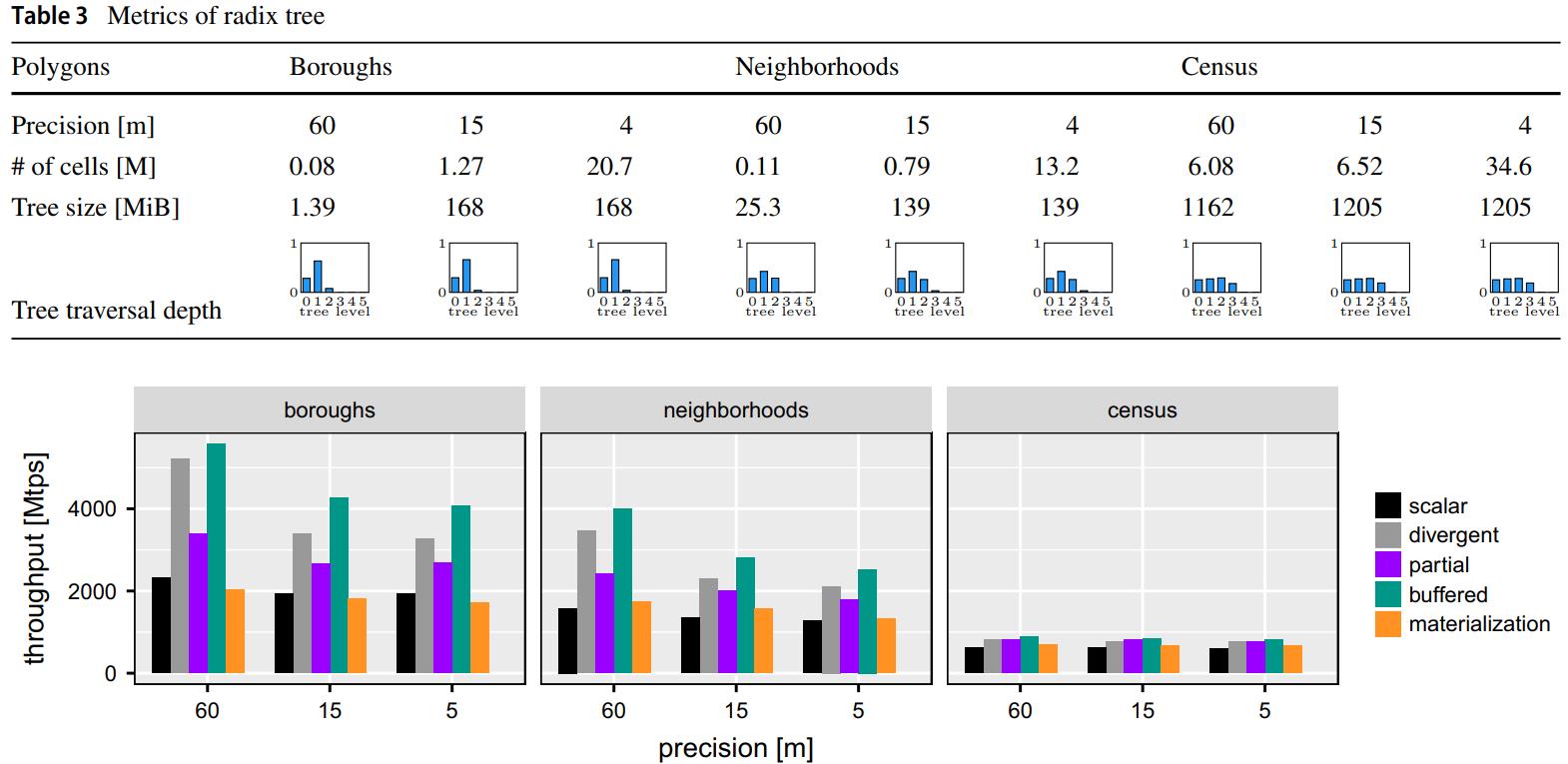 Fig. 16 2-Way divergence handling
Fig. 16 2-Way divergence handling
Overhead
使用一个简化的查询
|
|
两种选择率
- sel = 1
- sel = 0.125
sel=1时,几种方式表现的差不多,而当属性数量增加时,物化方式越来越差 、
bffer的方式也有点差,因为要物化到内存中
sel=0.125时,总体表现跟之前的差不多
部分消费随着属性的增加没有出现性能影响,这是因为受保护的记录开销相对是 恒定的
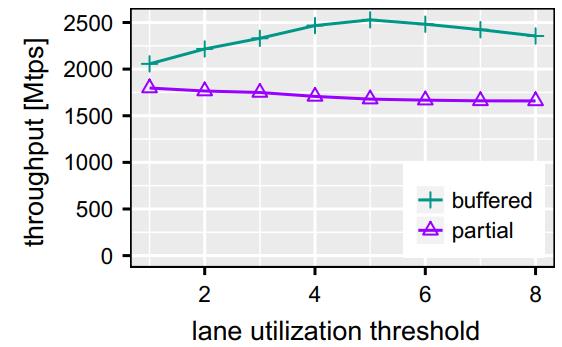 Fig. 17 Overhead of divergence handling for varying number of attributes
Fig. 17 Overhead of divergence handling for varying number of attributes
summary
部分消费表现的不错,但是在复杂场景,如近似地理位置join表现会下降
原因如下
- 包含SIMD管道的内在开销,导致利用率下降
- 重填充管道源是基于内存的
- 部分消费只读取了一些元素,会导致并行利用率不高
- 未对其会导致性能下降,在scan重的场景下会更严重,顺序扫描会下降25%
物化方式
- 对于底层的硬件非常敏感
- 如果作用于算子的边界,读/写一次,则性能比in-register更好
- 如果多次随机访问(hash table)会导致内存延迟,不能将数据放入L1、L2
- 如果数据能放入缓存,或者重计算的场景,in-register方式会很好
buffer
- 全消费场景中,较大的buffer一般会来带更好的性能
- 但对于部分消费影响就不大了
开放问题,如何设置阈值
- 通过运行时自动调整
- 重填充的代价
- 未充分利用的线路成本
- 输入数据
虽然SIMD是并行执行的,但是因为利用率问题,并不能真正的做到完全并行化
在能放入cache的场景中,两个填充策略表现的很好,是scalar的两倍
参考
相关文章
- Accelerating Analytics with Dynamic In-Memory Expressions
- Materialization Strategies in the Vertica Analytic Database: Lessons Learned
- MonetDB/X100: Hyper-Pipelining Query Execution
- Access Path Selection in Main-Memory Optimized Data Systems Should I Scan or Should I Probe
- Photon A Fast Query Engine for Lakehouse Systems