Materialization Strategies in the Vertica Analytic Database: Lessons Learned
原文
https://15721.courses.cs.cmu.edu/spring2020/papers/13-execution/shrinivas-icde2013.pdf
介绍
列存在物理上是完全隔离的,查询的时候会通过物化技术,将不同的列柔和为一行
这种也叫tuple的重建策略(物化策略)
具体来说有两种实现方式
- 早期物化,Early materialization
- 延迟物化,Last materialization
一般来说,延迟物化的性能会比 早起物化要好,但是实现起来会更复杂,需要维持更多的参数
而物化的本质上,是对 join 来说的,他们不适合放在内存,产生了 spilling join,也就是join溢出
通过对早起物化的一些优化也能达到不错的性能
早起物化又细分为两种
- EM并行化
- EM流水线化
他们的区别如下:
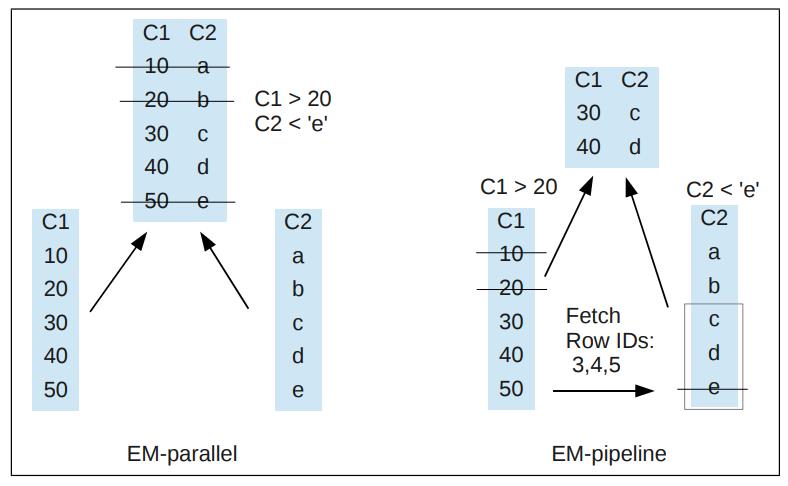
Fig. 1. Early materialization strategies
所谓的并行化,就是同时去查两个列,然后列拼在一起,最后做数据过滤,取出想要的行
而流水线化,则是直接去列中过滤数据,这样取出来的就已经过滤掉很多数据了
Vertica 使用的就是 EM-流水线的方式
延迟物化,是只抓取查询计划中需要的列,对于多个join来说,只抓取join中需要的列
join的输出是只匹配那些需要的行,并用来匹配剩下的查询
Vertica采用hash join的方式来做早起物化
下面是 早期物化 vs 延迟物化
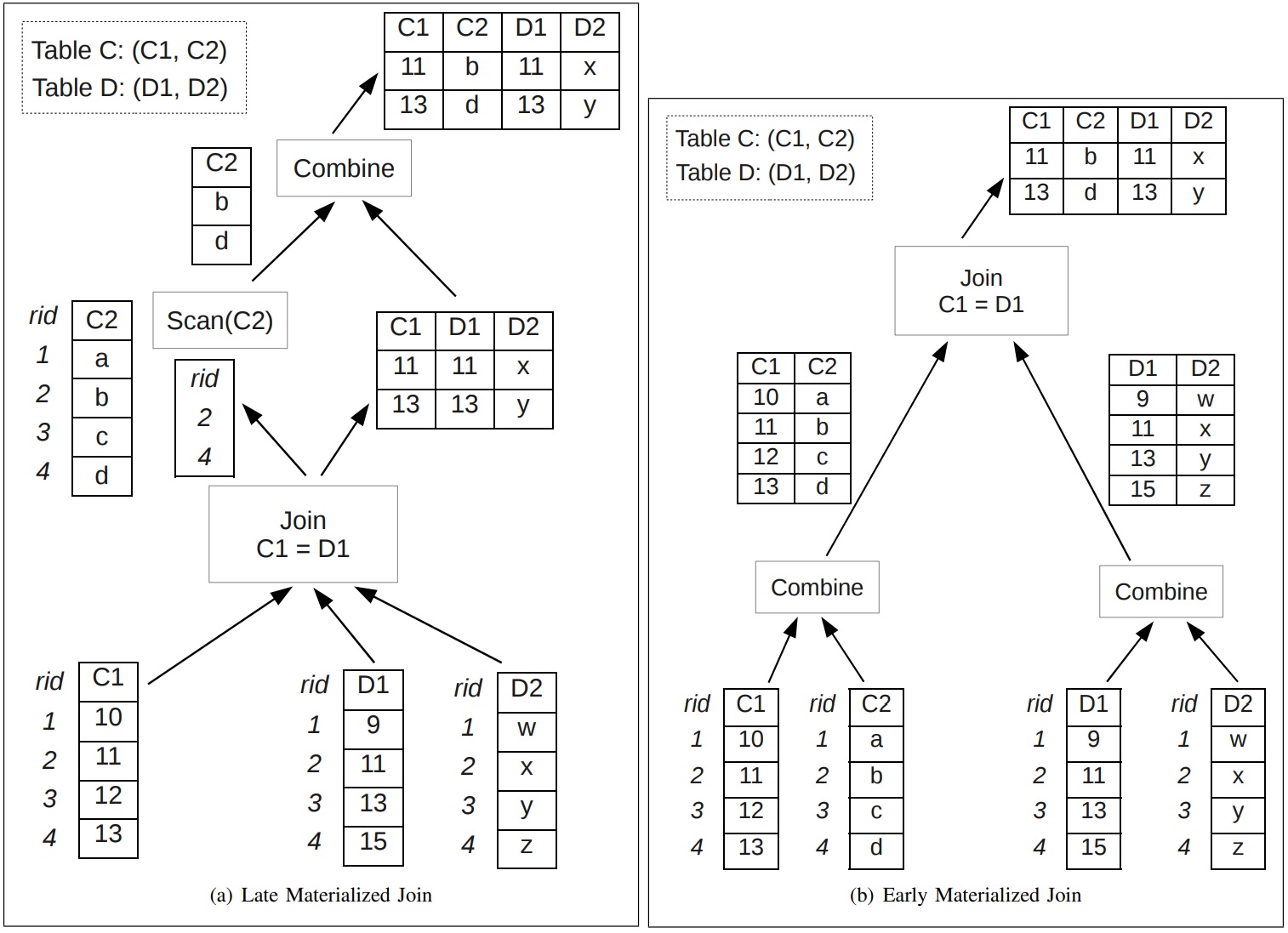 Fig. 2. Late and Early Materialized Joins in Vertica for the query “SELECT C1,C2,D1,D2 FROM C,D WHERE C1=D1”
Fig. 2. Late and Early Materialized Joins in Vertica for the query “SELECT C1,C2,D1,D2 FROM C,D WHERE C1=D1”
延迟物化的优点
- 可以大幅度提升性能
- 对于join来说,可以大幅度减少需要scan的I/O数量
缺点
- 需要跟踪哪些列需要在什么时间点做物化
- 执行引擎也需要跟着配合
- 对于部分聚合来说,实现起来非常困难,因为需要评估 基数减少后的收益,需要对聚合的额外列做评估
- 对于多个列中不同值做评估也非常困难,特别是存在谓词的情况
延迟物化在join两边输入数据都无法放到内存时,还不如早期物化
- 此时需要sort-merge-join,或者混合hash-join
- 混合hash-join,根据join的key做重分区,放入一个桶中,这样数据就能放到内存中了
- 如果join只输出row id,那么在join之后的tuple重构,需要多次扫描外部输入,和桶的数量一样多
- 类似的,sort-merge join也需要根据join的key排序
- 如果join只输出row id,那么它就是乱序的,因此重构tuple需要根据row id排序,或者除join本身之外的随机I/O
当join会溢出时,想对其评估使用早期物化、或者延迟物化非常困难
Vertica最初是将这个锅甩给用户,让用户自己决定,如果join溢出那么延迟物化会执行出错,于是退回到早期物化重新执行
最近修改了策略,都采用延迟物化,如果出错则退回到早期物化,这样用户就不用选择物化策略了
Sideways Information Passing (SIP) 是一系列的技术集合,可以用于改进join的性能
它将查询计划的一部分信息,传递给其他部分,允许尽早过滤不必要的信息,这些技术包含
- Bloom joins,跟半连接类似,只是缓存了bloom方式
- two-way semi joins,比如R和S,R的属性会存储起来,当发生join时会去查找并重建tuple
- magic sets
这些策略可以对所有查询找到最佳的性能
相当于是早期物化的增强
比如,对于Figure 2(b),如果能将D1传递给C1,那么在扫描C2时就可以过滤不必要的信息
对于早期物化EM、延迟物化LM、侧边信息传递SIP,得到的结论是
- 延迟物化实现起来更困难,优化器需要保存更多的信息,来记录在哪些列在什么时间点做物化,在查询优化期间还需要记录代价模型
- 延迟物化的性能更好,除了一种场景:溢出join(两边输入信息内存都放不下)
- SIP结合EM比普通EM性能更好,而且没有溢出join的情况,基本跟LM性能差不多
相关的列存数据库
- HANA
- MonetDB
- Blink
数据模型和磁盘存储
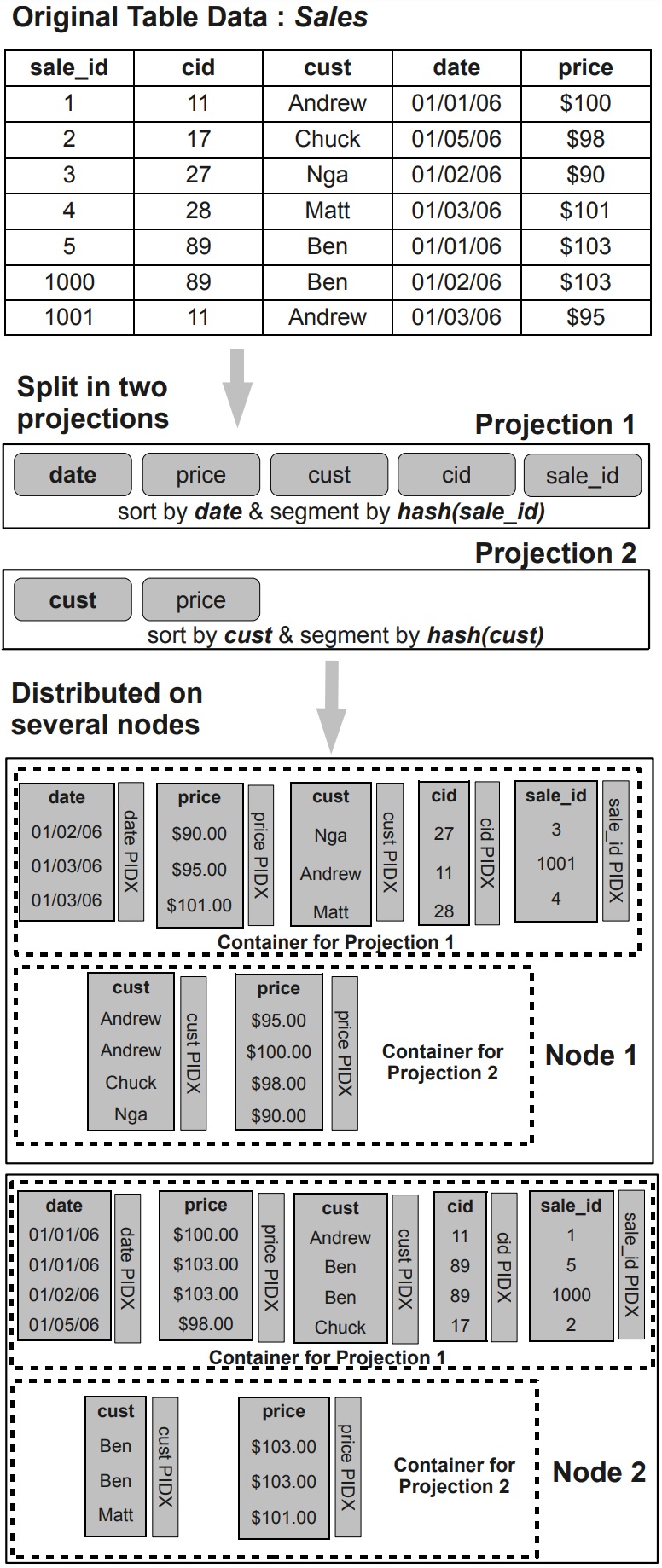
Vertica 中的数据是按照投影来存储的,每个表至少要包含一个 超级投影,它包含了每列的位置
这种投影 projections 不同于标准的物化视图,它是一种数据的物理存储结构,而不是辅助索引结构
解释
- 投影可以分为 replicated、segmented
- 复制是将tuple的copy存储到每个投影node上
- 分片是 hash(col),将数据分布到不同node上,一般按照 primary key分片
- 数据存储在标准文件系统上的多个container中
- 每个容器逻辑上包含一定数量的tuple,根据投影的排序顺序存储
- Vertica是按列存储的,每个列包含 数据文件、元数据文件、位置索引
- 位置信息是隐式包含的,还包含 min、max信息
- 完整tuple通过获取相
边信息传递
一个具体的例子
|
|
Fig. 4. Example Join Query 1.
在没有 边信息传递 SIP时,join的情况如下,此时需要扫码实事表的每个tuple
有SIP的情况时,跟之前差不多,变化是 node2,这里会做一个SIP的过滤
|
|
检查 实事表 的FK 是否在 维度表的PK中,如下图所示:
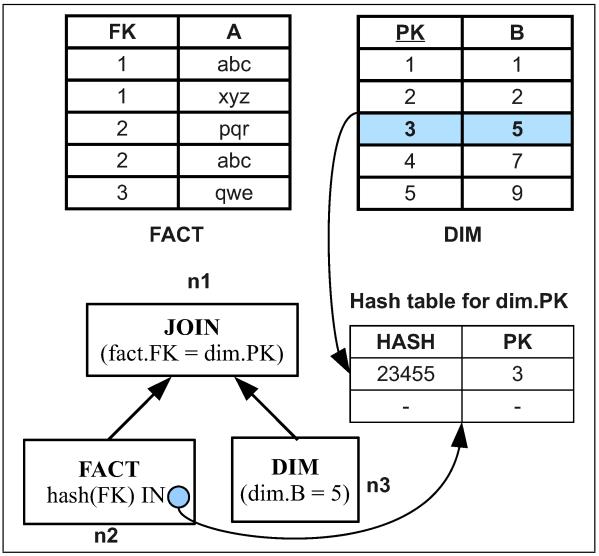 Fig. 6. SIPS Evaluation for Query 1
Fig. 6. SIPS Evaluation for Query 1
算法
1、SIP 过滤器的创建
会创建 表达式数量 + 1个 SIP filter,比如:
|
|
这里有3个表达式,分别创建,再加上一个表达式合并,一共4个
- fact.A1 IN (检查是否在hash dim.B1中)
- fact.A2 IN (检查是否在hash dim.B2中)
- fact.A3 IN (检查是否在hash dim.B3中)
- fact.A1, fact.A2, fact.A3
2、SIP 过滤器的分布
- 首先是根据每个join操作来创建过滤器
- 然后按照规则进行push down
规则
- 如果当前操作时 left outer join、full outer join、anti-join(由NOT IN生成)、设置ALL操作的semi-join,则停止push down
- 如果当前是join,且outer部分(join左边)不包含SIP filter谓词评估的所有列,则停止push down
- 如果当前是join,且outer部分需要跨网络发送数据,则停止push down
- 如果当前是group-by,且SIP filter包含任何聚合函数(不仅仅是对表达式分组),则停止push down
比如下图,查询计划包含 n1 和 n2,n2包含的条件为:fact.FK1 = dim.PK,n4表示对事实表scan,n5对DIM1做scan
n1的条件就是 fact.FK2 = dim2.PK,n2是作为n1 的outer,而n1的inner是scan DIM2表
之后根据n1、n2分别创建SIP filter,之后开始 push down,它也满足4个rule
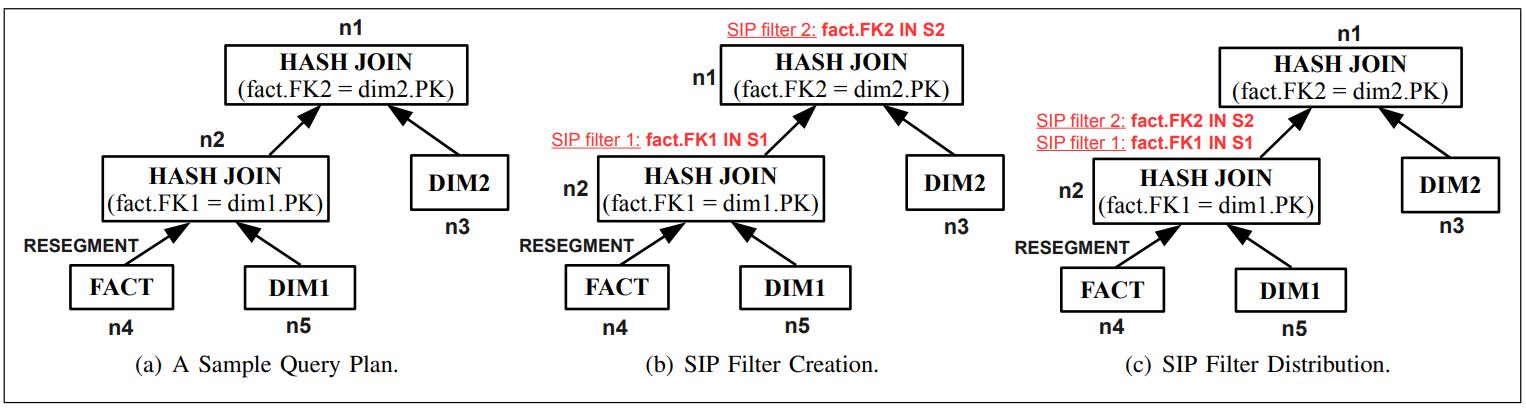
Fig. 7. SIP Filter Creation and Distribution Example.
下图中 两个SIP
- fact.FK1 = dim1.PK
- fact.FK2 + dim1.C = dim2.PK
filter2被下推到 n2 的位置,filter1 被下推到 n4 的位置
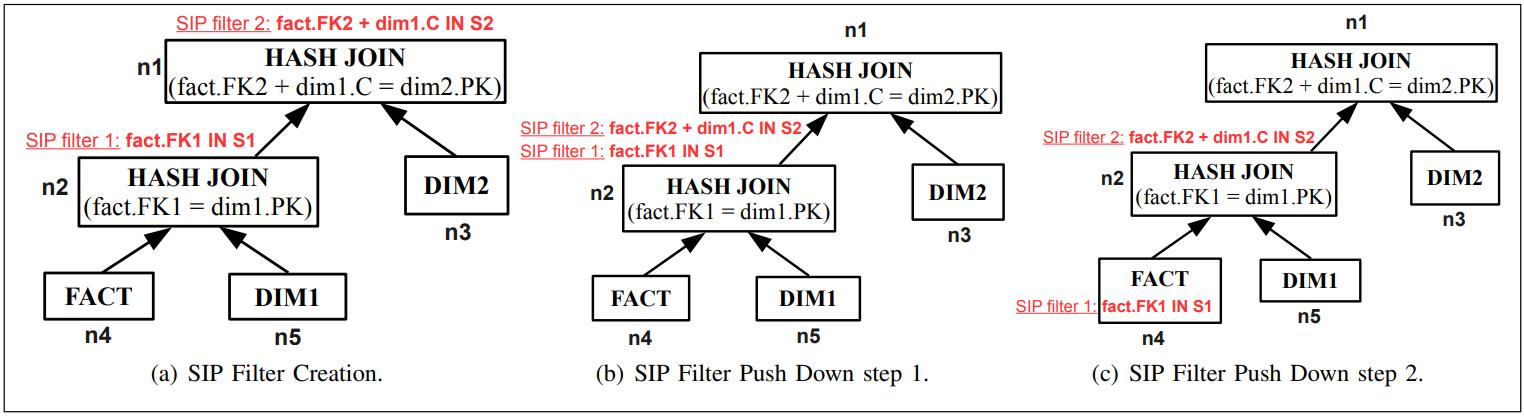 Fig. 8. An Example Push Down Avoided by Rule 2.
Fig. 8. An Example Push Down Avoided by Rule 2.
SIP filter评估
这里使用了多种手段来加速
- hash表 是基于之前创建的
- 每个列存储文件中还包含了 min、max信息
- 而数据是按照hash分片的,根据min、max就可以过滤掉很多不需要读取的block
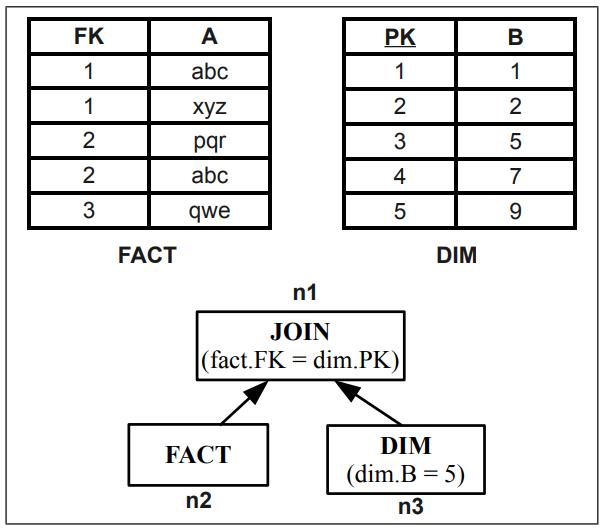
假设条件为: fact.FK = dim.PK
谓词条件为: dim.B = 5
根据谓词从 dim 表中查找合适的条件,找到 min = 3,max=8
也就是[3,8]这段满足 dim.PK,根据这些PK 建立hash表
之后事实表去hash表中匹配,完成 merge join操作
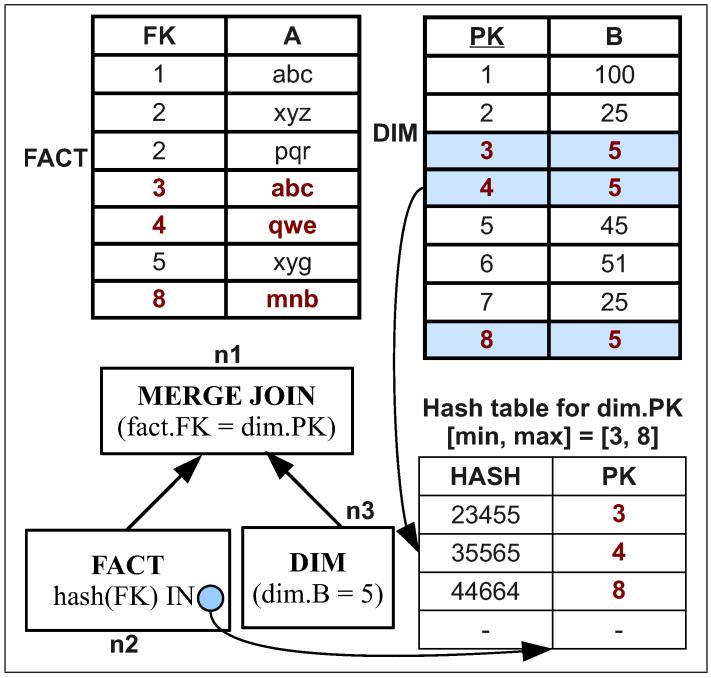
Fig. 9. SIP Evaluation for Merge Joins.
还有一些特殊场景:
|
|
比如选择性很高的时候,建立SIP再评估就有点浪费了,此时会评估 输入/输出 数据的比例,如果高于0.9则不建立 SIP
Algorithm 1 The SIP Filter Creation Algorithm, CreateSIPFilters
Input: Root R of a Query Plan P.
Output: Query Plan, Ps with initialized SIP Expressions.
伪代码如下:
|
|
Algorithm 2 The SIP Filter Distribution Algorithm, DistributeSIPFilters
Input: Root R of Query Plan Ps with initialized SIP Expressions.
Output: Query Plan, Pd with distributed SIP Expressions.
伪代码如下:
|
|
额外收益
这里介绍边信息传递 SIP的两种特殊场景,用的好可以提升性能
1、谓词评估顺序
- 列存对于 push down的顺序,其重要性大于行存
- 如果按照投影扫描的顺序来评估谓词,其效率更高
- 比如(o_orderdate, o_shippriority) 这样的列
- 如果先评估o_orderdate 则效果更好,因为靠近前面的列压缩比更高,可以节省I/O
- 延迟物化时,评估的列顺序跟 扫描时的列顺序可能不同
- 而延迟物化是在 join的时候才评估列的,这可能会导致其性能比push down时要差
- 本质上这是一种权衡:基于投影的顺序执行join VS 基于评估的选择性、代价执行join
实际执行时
- 优化器根据选择性、成本来执行join
- 而执行引擎根据投影扫描的顺序应用 SIP过滤器和下推谓词
2、编码的影响
- 使用的是 run-length 编码,可以直接作用到数据,省去了解码的时间
- 下面的SQL会创建 3个SIP
- 如果 fact.a1 经过run-length编码,而 fact.a2 没有,则需要解码
- 如果执行SIP下推,fact.a1 IN
- 可以直接作用于编码数据,如果hash表数据很少,又能提升很多性能
|
|
性能评估
对比:
- 早期物化 EM
- 延迟物化 LM
- 带有边信息传递的早期物化 EMSIP
将 EM 作为基准,测试 TPC-DH 的几个查询用例
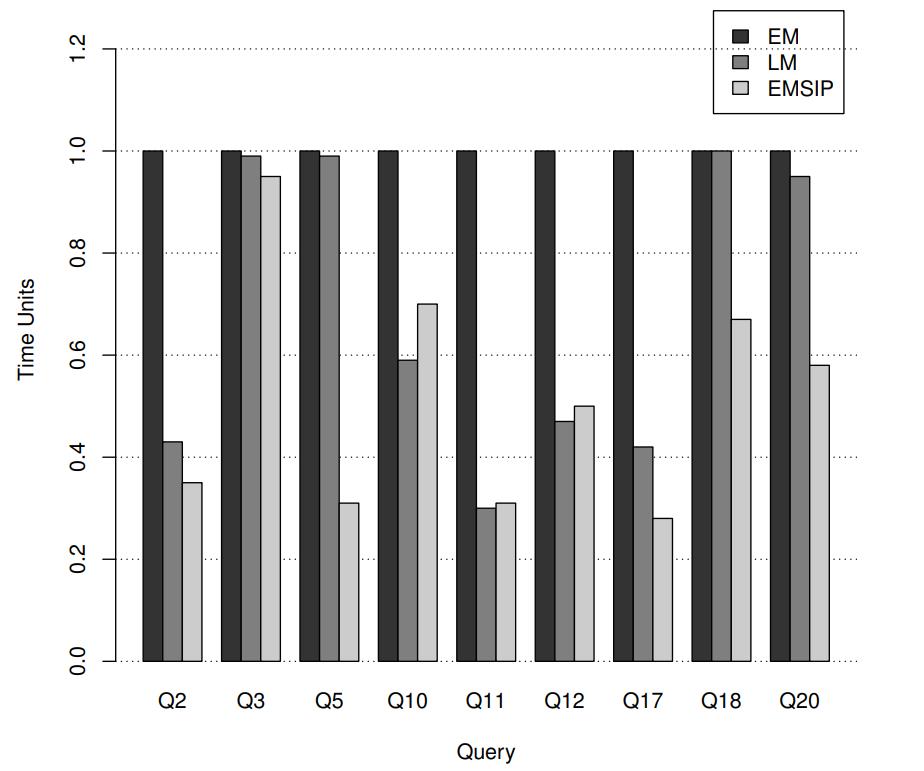 查询 5 的LM性能并不好,因为出现了 join溢出
查询 5 的LM性能并不好,因为出现了 join溢出
这里使用的都是冷缓存,而query5执行后,相当于把数据加载到cache中了,虽然join溢出重新执行了 ME
但是数据在缓存中,加速其查询速度
查询17、18、20 采用了SIP下推,得到了很好的效果,比LM性能更好
查询10 显示了 EMSIP比LM有些场景下要差,但是比 EM还是有30%的性能提升
|
|
该查询本质上计算每个订单优先级的订单数量,对于在单独的表中指定的订单日期列表,其中每个订单超过1000美元
一般由 BI 工具生成
对比 Table II, EMSIP相比EM、LM有了50倍的性能提升
这是因为执行引擎在应用普通谓词之前,先将SIP应用于o_orderdate
o_orderdate是投影扫描顺序的第一列,也是 run-length 编码的,因此执行谓词评估非常快
而 LM 评估的第一个谓词不是o_orderdate,因此浪费了很多时间
考虑如下查询:
|
|
该查询本质上是查找在订购后一天发货的行项目的数量,对于高价的订单(大于550000美元)
投影在lineitem列上,也是 run-length 编码的,这个查询跟上面的查询类似
使用 EMSIP会带来巨大的性能提升,大概比 EM、LM有两个数量级提升