MonetDB/X100: Hyper-Pipelining Query Execution
原文
https://15721.courses.cs.cmu.edu/spring2020/papers/13-execution/boncz-cidr2005.pdf
介绍
数据库系统的 IPC,也就是 instructions-per-cycle,每秒指令数据都比较低,这是一个不好的现象
最近10年CPU的进化速度很快,按理说 IPC应该很高,但研究分析的结果是数据库的IPC 都很低
目前是两种执行逻辑:
- 经典的火山模型,这种问题是出现了大量的解释开销,导致CPU利用率上不去
- MonetDB的执行模式是一批次的列物化执行,这样避免了解释开销,但是内存带宽也影响了CPU,效率也不高
于是建议将上面两种合并起来,变成混合的向量化执行,从而达到更好的效果
CPU是如何工作的
最近10年CPU的发展史,因为这篇论文也比较老了,所以展示的历史比较久远了
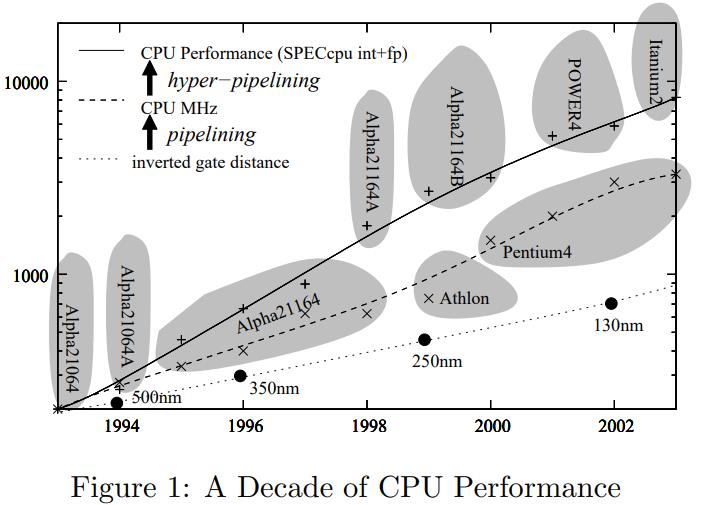
根据摩尔定律,每18个月制造工艺的面积就会缩小一倍,由于制造工艺缩小,芯片之间的电路也在缩短,所以速度也提高了
崩腾四更是带有31级的超长流水,每时每刻都让 CPU指令满负荷运转,但这样的缺点
- 指令流水太长了,如果一个指令要等待前一个指令,就不能并行,必须等前面一个完成才行
- 对if-else非常不友好,如果指令预测错了,就需要flush这个流水线重新进入分支代价挺大的
回到数据库层面,像路径选择这种优化,根本没法预测,所以就会导致CPU效率上不去
现代CPU有两种发展方向
- 像安腾这种,其时钟频率不是很高,但有很多并行的流水线,6个流水线,7个阶段,1.5G的主频
- 而奔腾这种主频很高,并行流水线不多,31个阶段,3个并行流水线
所以算算看,安腾的并行度为:7 * 6 = 42,可以同时运行 42 个独立指令
奔腾是 31 * 3 = 93,可以同时运行 93 个指令
不过这么高的并行度有时候没啥用,如果不能好好利用的话,还不如低并行度的
测试过程中也发现了,两个CPU的并行度差别挺大,但实际跑出来的效果其实差不多
这里有一个概念,叫:loop pipelining,循环流水线
循环中可能会有很多分支预测行为,这对于CPU并不友好,而一般的语法并不会控制CPU指令行为,这些都是编译器的优化行为
所以好的编译器优化,可以最大程度的利用CPU,比如它们生成的指令是完全流水线的,或者乱序的,这样就可以充分利用CPU的流水线行为
这里要提一下安腾的编译器,能最大化的利用CPU的流水线,生成的指令并行度是很高的
像这样的指令:
|
|
经过优化就变成了:
|
|
这样的好处是充分的并行化,假设F会 延迟两个周期,等待G(A[0],按照上面的执行顺序
F(A[0])之后是:F(A[1])、F(A[2]),然后是G(A[0]),中间正好是2个指令,就可以做到完全不等待效率非常高
假设有这么一个查询:
|
|
其 x 随机分布在[0, 100]之间,这就会导致一个分支行为
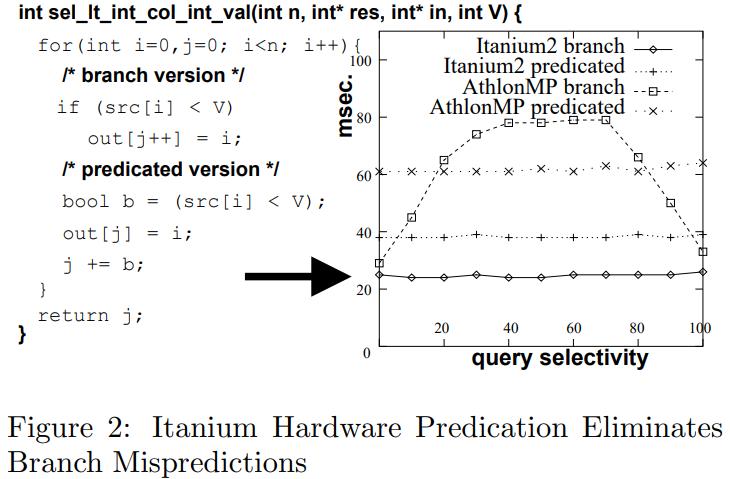
像有的CPU,AthlonMP就会出现很差的行为,50%的执行都是浪费的
而改变了代码,则会大幅度提高CPU使用率
另外一点,CPU中 大概30%的指令是用于 内存 load,store,这也很浪费性能
因为要读主板上的内存,大概会由50纳秒的延迟
像数据库领域中,很多都不是缓存友好的,于是会出现cache misses这种行为,效率低效
所以就出现了如
- 缓存对其的 B树
- 列风格的数据布局,如PAXX、DSM
- 限制查询的随机CPU访问,将查询范围限制在CPU缓存中
- 如基数分区的hash-join 可以大幅提升性能
将下面这些改进之后,可能会提升几个数量级
- 改进分支行为,变成直接/预测机制
- 提升cache的命中率
- 提升内存的loads、stores行为
因为数据库分析领域有大量的CPU计算行为,所以仍然有很大的提升空间
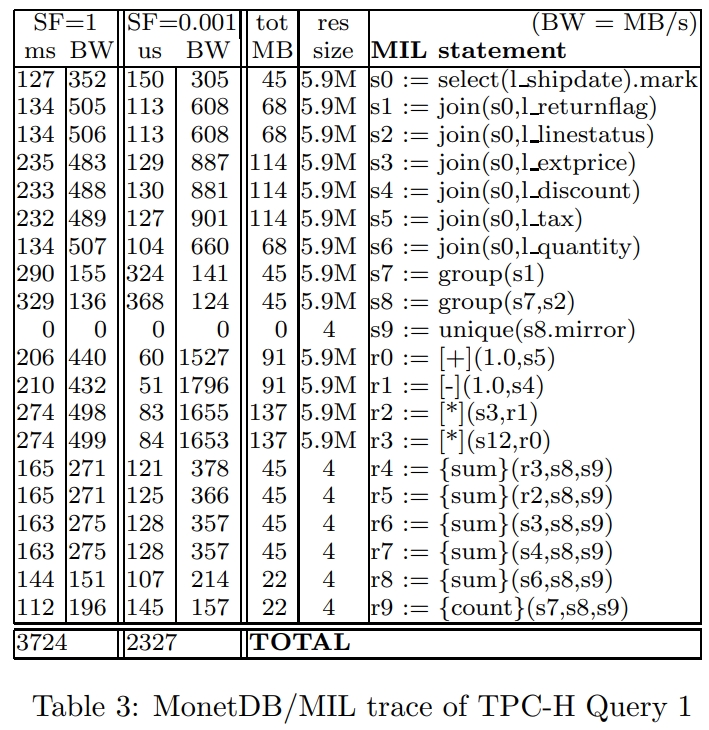
Microbenchmark: TPC-H Query 1
这里选择用 TPC-H 的第一个查询来做分析,选择这个SQL 的原因是相对简单,没有join等复杂场景,就是一个单表查询
- 它有两列相减、一列相加、三列相乘
- 还有8个 聚合函数,其中4个sum、4个avg、1个count
- 聚合只在两个单字符列上,产生4个唯一组,因此可以用小的hash表完成,不需要额外的I/O
|
|
下面部分是TPC-H 官网拿到的商业数据库的测试报告,跟MySQL的比较类似,所以怀疑 同样有MySQL的问题
也就是没有完全流水线化,CPU使用率比较低
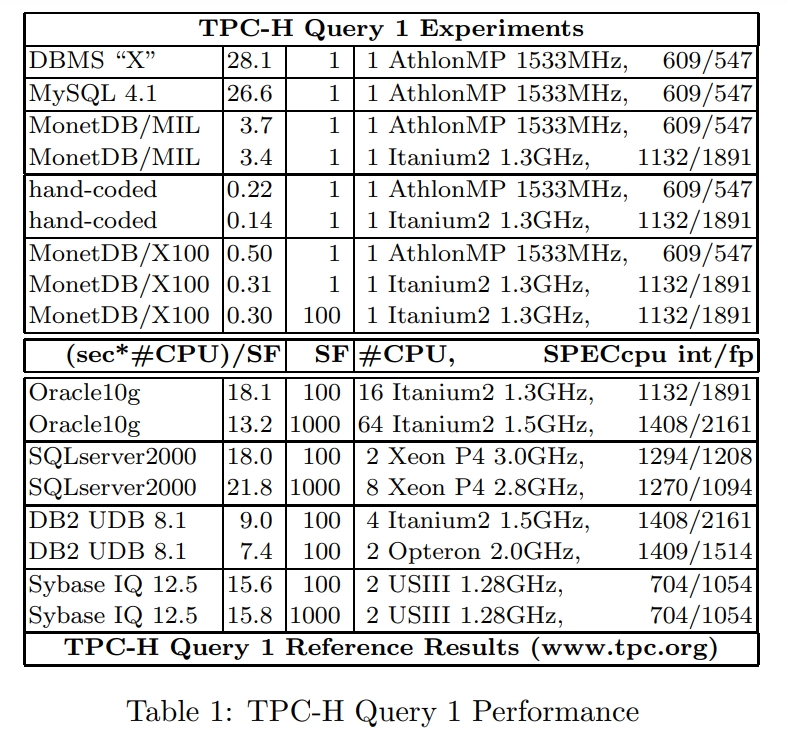
火山模型是一个很不错的设计,但是需要有大量的解释开销
下面是MySQL的执行过程统计
- 第一列是累计的时间
- 第二列执行时间的百分比
- 第三列是call调用的次数
- 第四、第五列是指令的执行时间

首先看看上面 5个加粗的指令,用于完成所有工作的指令,只占到10%
而28%的时间用于hash表中的查找,剩余的68%用于指令调用
每次查询相关的指令是38个,而这个机器每个周期可以执行 3个指令
一个简单的算数操作 + (double src1, double src2) 这样的
其RISC指令如下:
|
|
相当于每 3个周期做一次: one *(double,double)
而MySQL这边是需要 49个周期
一个解释原因是 缺少 循环流水线,很多指令都处理等待状态,导致效率很低
MySQL使用的是一次一个tuple方式
- Item func plus::val只执行了一个加法,限制了编译器做流水线,导致流水线出现等待,3个周期变成20个周期
- 调用的成本分摊到一个操作上,又增加了一倍的成本
MonetDB消除了MySQL 的那些问题,其90%的时间都花在执行上了,但由于使用了物化方式,变成了双刃剑
MonetDB是列存的,它是一个二进制关联表BAT,一个表两个列,head和value
如果计算: join(BAT[tl ,te] A, BAT[te,tr] B) 其结果相当于 tl,tr
相当于把A的头,B的尾结合在一起,这里就是指针反转,几乎没什么开销
而它的另一些计算如:extprice * (1 - tax)
- tmp1 := [-](1, tax)
- tmp2 := [*](extprice, tmp1)
有点像lambda ,把map 映射到每个值上面,然后产生一个物化的中间结果
而就是这个中间结果导致了很多不必要的内存拷贝,导致了很多无意义的工作
这就是双刃剑的原因,避免了MySQL的低效流水线,但是也出现了无意义的工作,最后也变得低效
Query 1: Baseline Performance
下面是一个 Monet的UDF,这里手动加上了 __restrict__ 关键字,告诉编译器不同的指针指向的区域是不重叠的
这样编译器就可以做并行优化
|
|
Figure 4: Hard-Coded UDF for Query 1 in C
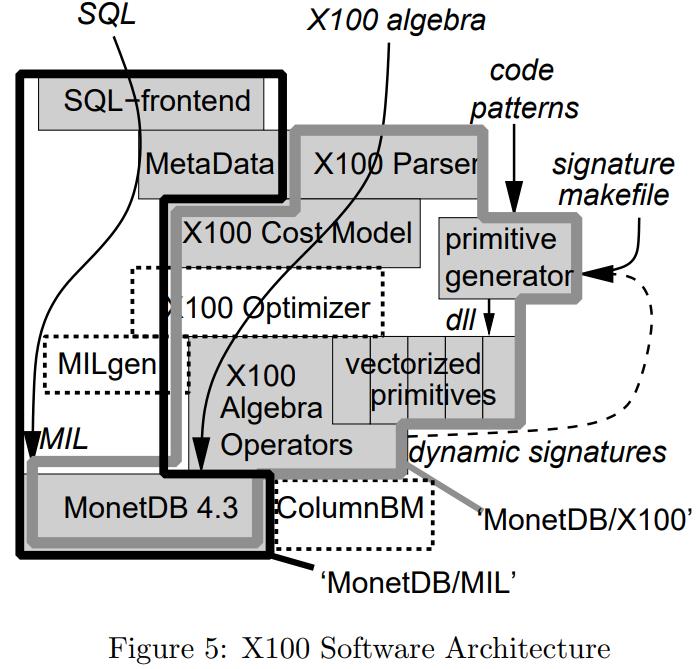
X100: A Vectorized Query Processor
实现了 X100的向量化查询处理模块
- 磁盘,都是顺序扫描,数据是向量化布局的
- 内存,使用SSE预抓取指令,数据压缩,这样节省空间和带宽
- cache,类似火山模型,但一次取1000个,可以放到cache中加速处理,另外压缩/解压也在这里
- CPU,利用并行化执行
整个架构如下:
简化后的查询语句如下:
|
|
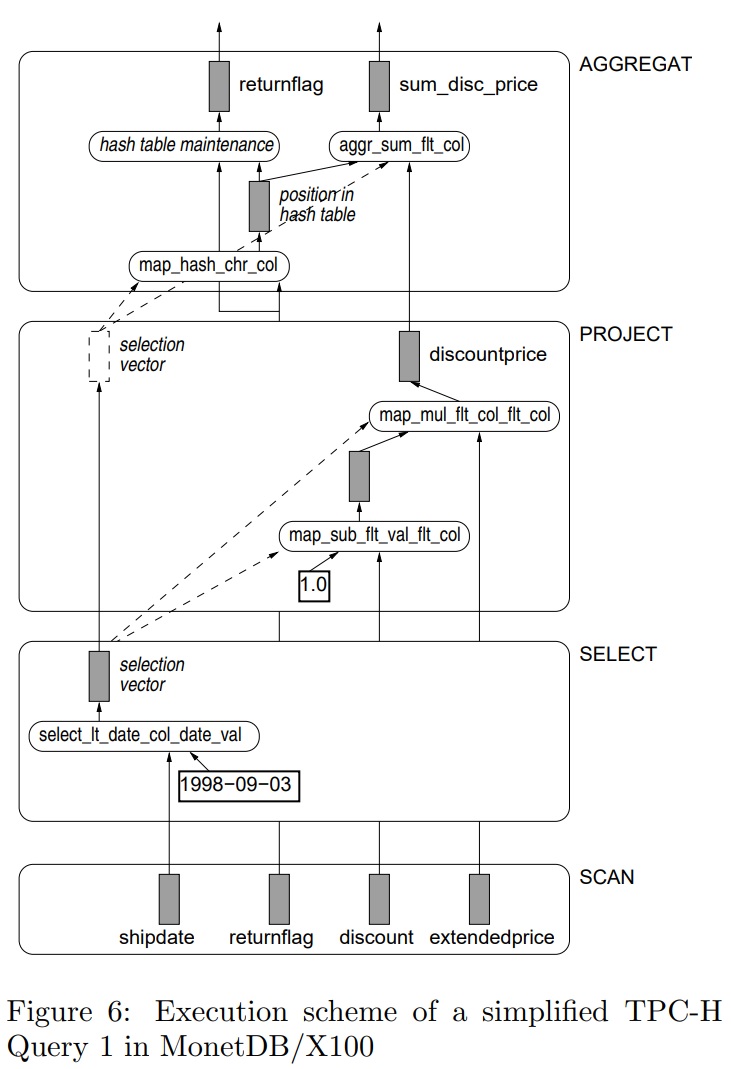
下面是整体的执行过程
- 首先是scan,scan的时候只扫描必要的列
- 之后是select,对于discount这些列不做任何修改,直接转到更上层
- project、agg对列做一些处理,计算每个元组在哈希表中的位置,然后使用这些数据更新聚合结果
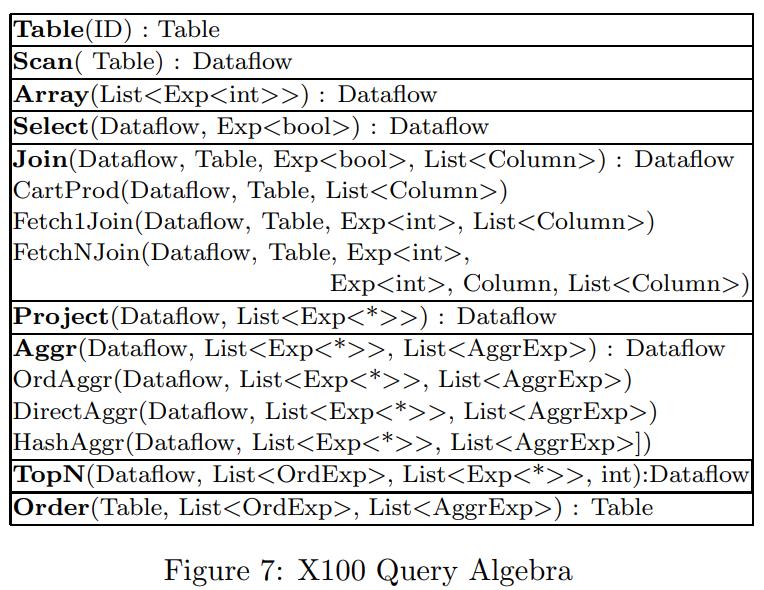
下面是X100支持的关系代数,table是物化关系,而Dataflow只是流水线上流过的tuple
有些操作会产生多组tuple,有些不改变原生形状,有些会产生一些新的形状
聚合包括:直接的聚合、hash、顺序聚合等
join目前只支持 left-deep join
使用列风格并非是优化内存布局,而是为了CPU更好的优化
执行过程中只需要操作对应的列即可,而不需要知道他们的布局,也就是列的offset
通过这种方式编译器就可以最大限度的并行化指令,实现 聚合循环流水线
比如一个向量化的浮点加法
|
|
这里的sel参数可以为NULL,或者是一个数组的位置
X100包含类似这样的原语大概100多个
比如,下面是两个相同类型但没有任何类型限制的加法,并产生相同类型
|
|
比如下面是一个复合运行,求 曼哈顿距离
|
|
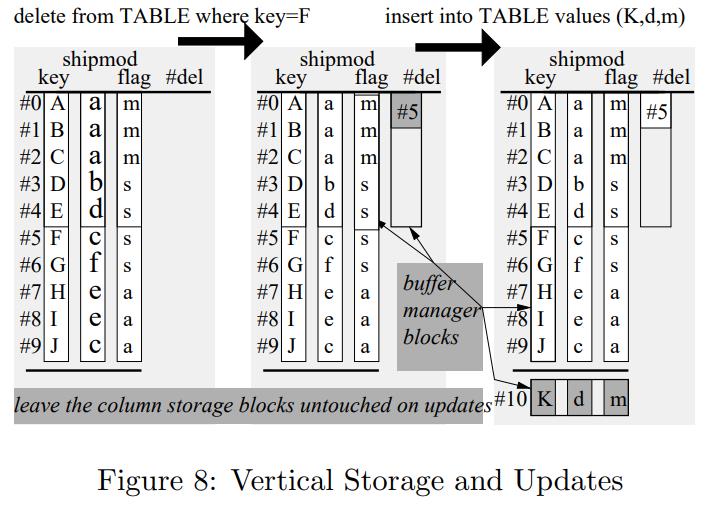
X100的优缺点
- 其存储是不可变的,对于查询来说很好,列存可以避免不必要的检索
- 假设压缩可以进一步减少I/O,内存带宽开销
- 也支持目录索引,比如max、min,在range谓词中可以过滤很多数据
- 但是更新代价会更好,需要额外的列指明是否是删除的
- 插入只是append操作
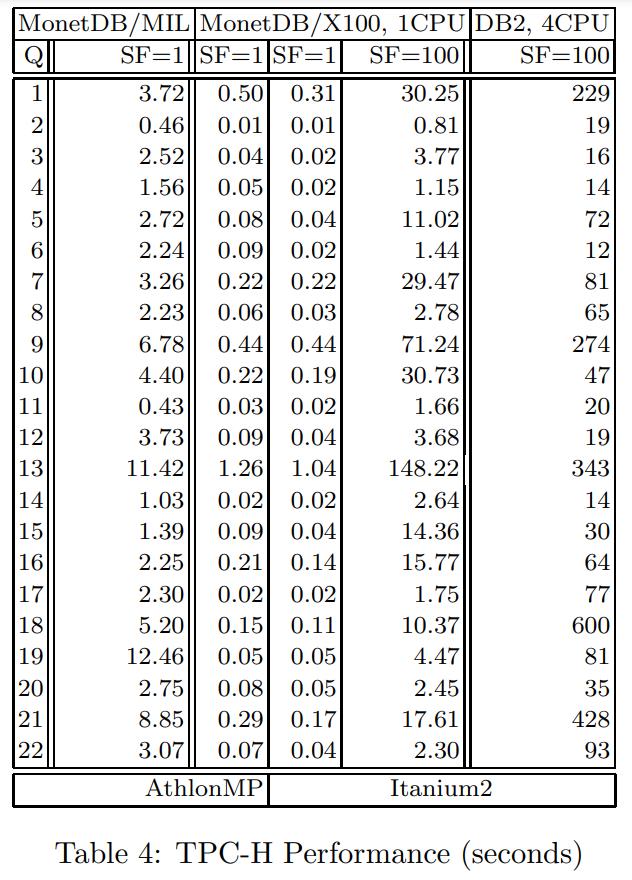
TPC-H 实验
以下是分析结果
下面是 query 1的 X100 关系代数
|
|
Figure 9: Query 1 in X100 Algebra
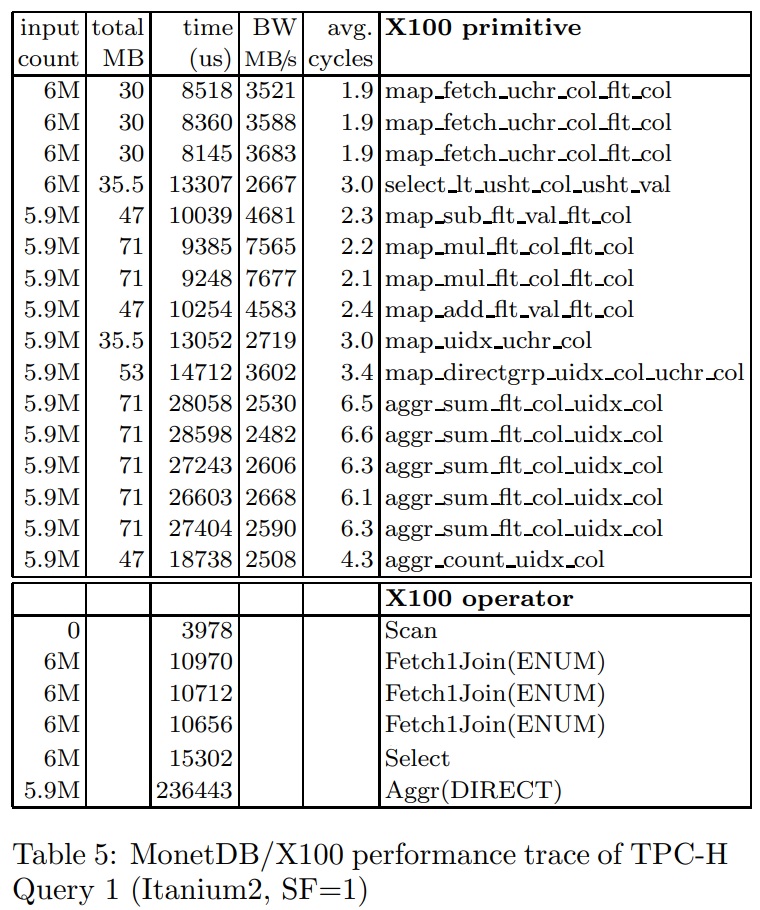
之后发现
- 性能有了明显提升,6个周期一个指令,比之前MySQL的49个周期好很多
- 由于数据都保持在cache中,执行带宽大幅度提高,从500M/s,到现在的7.5G/s
- 枚举值会自动放到 枚举表中,通过Fetch1Joins来检索,大概2个周期
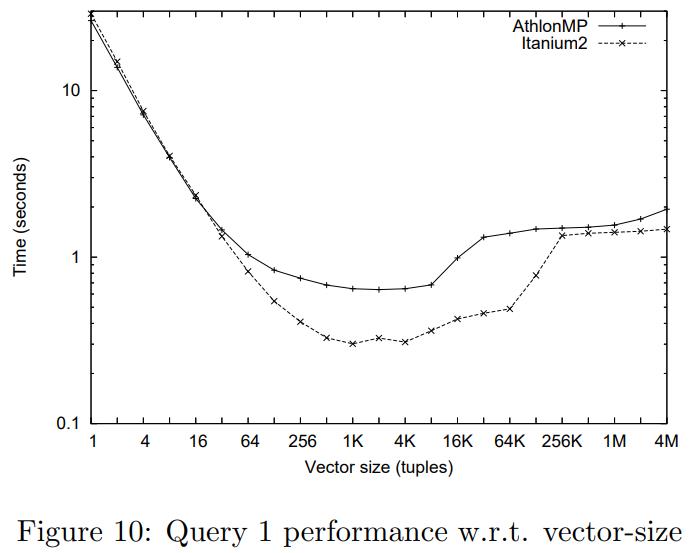
当size = 1时,就退回了当初 一次一个tuple这种模式,性能很差
当size增加时候性能大幅度提升
随着size不断增加,cache已经放不下了,性能开始降低
之后开始用到L2、L3 cache,性能继续下降
直到size 更大,只能放到主内存中,相当于退化到之前的物化模式了,性能进一步降低