Photon A Fast Query Engine for Lakehouse Systems
原文
https://cs.stanford.edu/~matei/papers/2022/sigmod_photon.pdf
背景
传统的数仓中保存的都是结构化数据,方便治理
而数据湖中存储的是非结构化数据,治理起来也比较麻烦
于是 Databricks 搞出了一个新玩意,Lakehouse
“Lakehouse”, which implements the functionality of structured data warehouses on top of unstructured data lakes
这个解释还是很清晰的,不像那些整PPT搞概念的,lakehouse就是在 数据湖之上,提供了事务和ACID的数据仓库
也就是让 数据湖中的数据更方便管理
Photon要解决的问题
为什么要引入Photon?
- 近些年因为新硬件的引入,如SSD、NVMe,存储层的性能有大幅度提升
- 自动shuffle、Delta Lake存储格式,都可以大幅度减少I/O
- 想要继续提升性能,需要在内存、CPU这块继续提升,但这很难
- 因为整个语言都是基于JVM的,想要提升性能就需要对JVM内部非常熟悉,才能充分利用SIMD指令
- JVM因为编译的限制,如果宽表>100字段,可能会导致code-gen失败退回火山模型,性能急速下跌
两个问题
- 数据湖中保存的是非结构化数据,非常不统一,缺乏物理布局,没有统计信息
- 需要兼容Spark DataFrame API的语义
对于1),其解决思路是采用向量化的执行引擎
对于2),相当于把Spark的一些物理查询计划重写一遍
Photon 在Lakehouse架构中的位置
- 最底下的是存储层,这里将计算和存储分离,存储层使用的都是云厂商提供的
- 这里就是Delta Lake存储格式,支持分区和数据skip,能减少大量I/O
- 执行层使用的是云厂商的VM,Photon 位于这一层
- 用户接口层
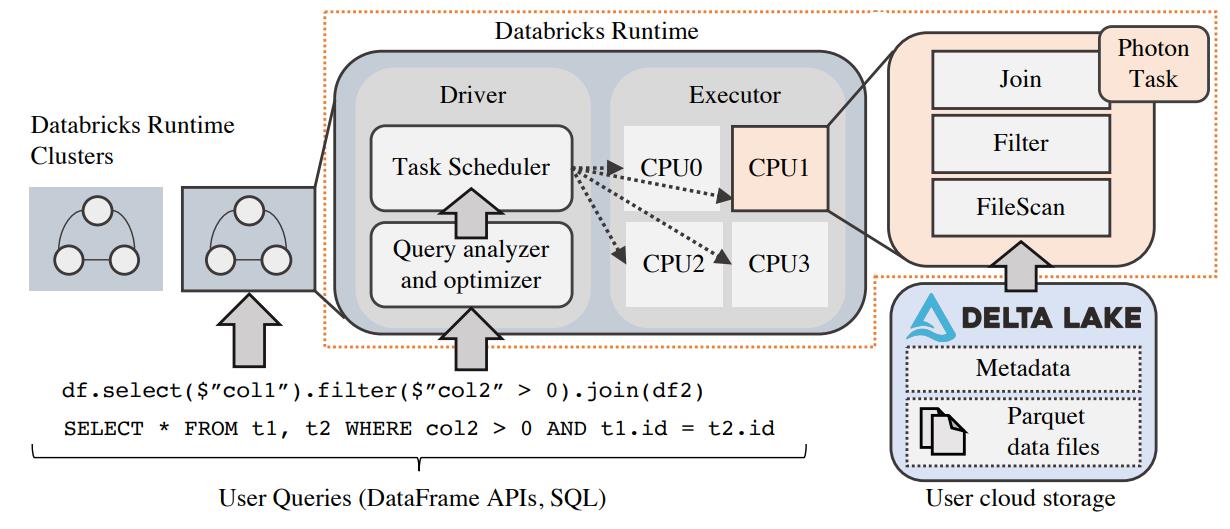
Figure 1: Databricks’ execution layer. Photon runs as part of the Databricks Runtime, which executes queries on a distributed
cluster of public cloud VMs. Within these clusters, Photon executes tasks on partitions of data on a single thread.
这里还有一个SQL的例子
|
|
Listing 1: An example SQL query. This query can benefit from both storage optimizations such as file clustering, as
well as runtime engine optimizations that Photon provides, such as SIMD vectorized execution.
使用 Interpreted Vectorization的包括
- MonetDB
- X100
使用 Code-Gen的包括
- Spark SQL
- HyPer
- Impala
向量化的优点
- 代码生成很难跟踪调试、而向量化毕竟是普通代码,可以方便用现有工具调试
- 增加观察指标更容易,方便跟metrics集成
- 扩展起来更容易
- Code-Gen用于复杂的表达式和子表达式,而向量化也能做到部分,就是增加一些不同的算子
Photon 是
- 基于列的,这样可以更好的使用Parquet文件格式
- 由于Spark社区有大量的更新,全部替代不可能,只能先替代一些核心重要的
- 对于不支持的算子,会优雅的退回到原生Spark的执行方式
Photon的细节
使用列的布局方式,这里每列中有一个特殊的标识,用来标识这一列中的某个值是否为NULL
此外还会记录string的编码类型,如ASCII,或者UTF-8,以便更好的优化
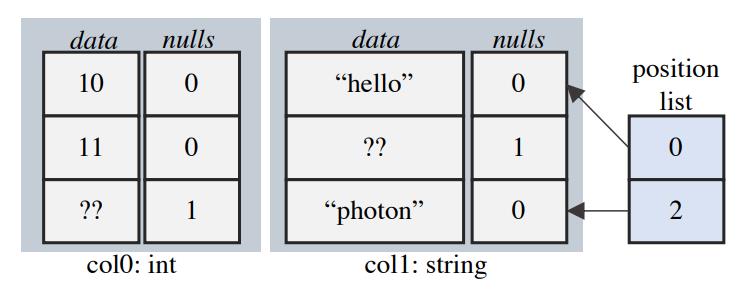
Figure 2: A column batch in Photon. This batch represents the schema {int, string} with the tuples (10, “hello”) and (null, “photon”). Data at inactive row indices may still be valid.
column vector再加上一个 postion list,就组成了逻辑上的一行
对于filter来说,可能会优化掉很多行,但不会真的只生成几条数据,而是用 position list做标记
用来标记这行是否是 avtive 的
执行引擎是构建在kernel层面的,数据的所有操作都是在非常底层的层面实现了一个个kernel函数
比如shuffle数据的序列化,针对数据的hash操作等等,而这些底层的kernel函数有些场景会显式使用SIMD指令进行优化,更多的时候则是依赖编译器的自动向量化优化
kernel 有两个因素来调节
- 这个batch是否为null
- 这个batch是否有不活跃的数据
这里使用了 RESTRICT 让编译器自动实现向量化
向量化内存管理,使用自定义的内存池,而不是反复向操作系统申请内存
|
|
Listing 2: A Photon kernel that is specialized on the presence of NULLs and inactive rows. Branches over compiletime constant template parameters are optimized away
整合到Databricks场景
首先是将spark的执行计划转为photon的执行计划
这里需要从最下层开始转换,因为从中间转换就会有很多 行-列的 转换开销不值得
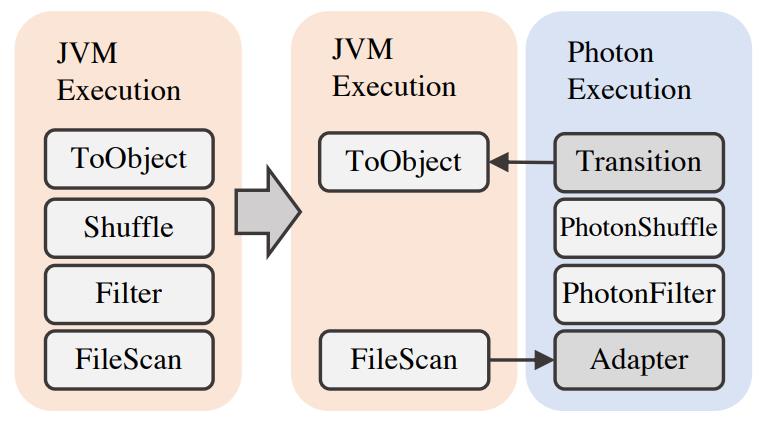
如果发现photon不支持,则插入一个转换节点,将photon转换回spark的执行计划
执行过程:
- 通过 JNI调用C++库,然后将 photon部分的执行计划通过 protobuf做序列化吹了
- 之后反序列化并转为 photon内部的执行计划
- 每个算子都有 HasNext、GetNext
- 执行计划结束photon会将结果shuffle到文件中,使用spark的shuffle协议
- 之后一个新的photon task会读取之前的文件,而文件格式是自定义的不兼容spark格式,
- JVM和C++之前的传递都是指针,列数据文件被存储到非JVM堆中,开源的 OffHeapColumnVector
- JVM和C++共享这篇数据所以不用copy,JNI会调用来消费这些数据
- 每次JNI调用大概 23ns,跟一次C++虚函数调用时间类似
- photon的执行计划最后,会将 列数据转为行数据
内存管理
- photon 和 spark是共享一套集群的,其内存视图也要保持一致,避免OOM
- 为此需要满足预留的内存,此时可能会出现排序,聚合等需要溢出的场景
- 两阶段分配内存
- 先通过reserve进行申请,再通过allocate进行实际的内存分配
- reserve不足时,会溢出到磁盘
- 这步也是要跟Spark保持一致,将内存消耗从小到大排序,然后溢出最多使用的
- 这个策略是尽可能少的发生溢出
- photon使用了广播,如广播hash join,会受到GC影响,为此在photon生命周期结束时执行一个清理操作
整合
- photon可以将其执行信息导出,这样后面可以更好的优化
- 还可以将这些信息导出到 spark-ui 上
- 各种算子实现的细节都需要保证语义上的一致性,也就是C++和Java产出一样的行为
- 比如integer -> float,以及时间处理部分,如果产生的结果不一样,会导致不一样的查询结果
- 为了保证这种行为需要三种测试
- 单元测试、端到端的测试,随机化的测试
测试评估
需要了解三件事情
- 哪种情况的查询收益最大
- 跟其他引擎做端到端的对比
- 自适应的优化有什么影响
加速依赖CPU的算子:join、agg
加速数据编码:shuffle写还有parquet write

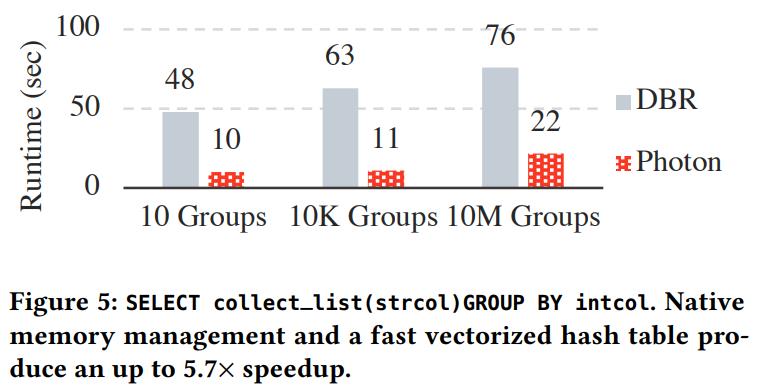
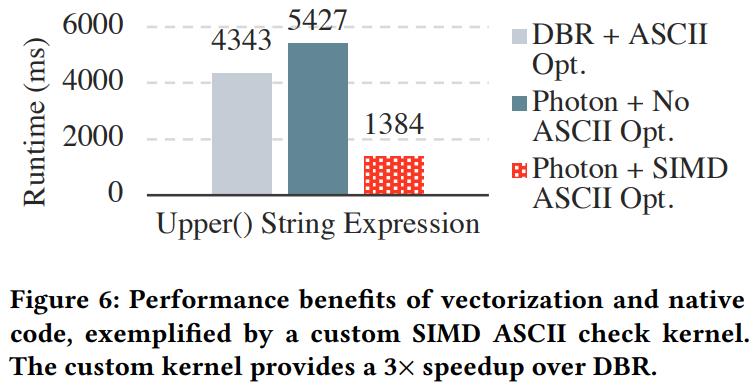
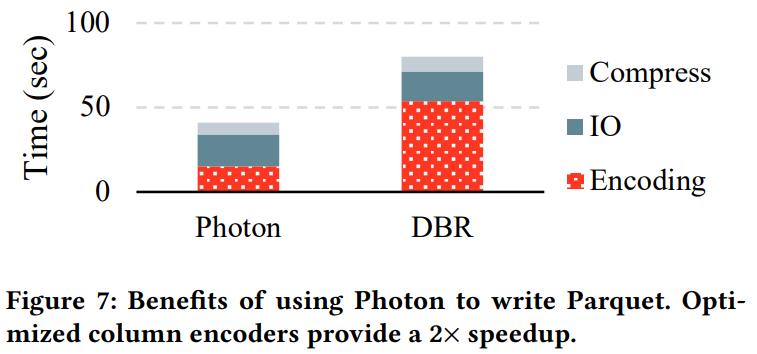
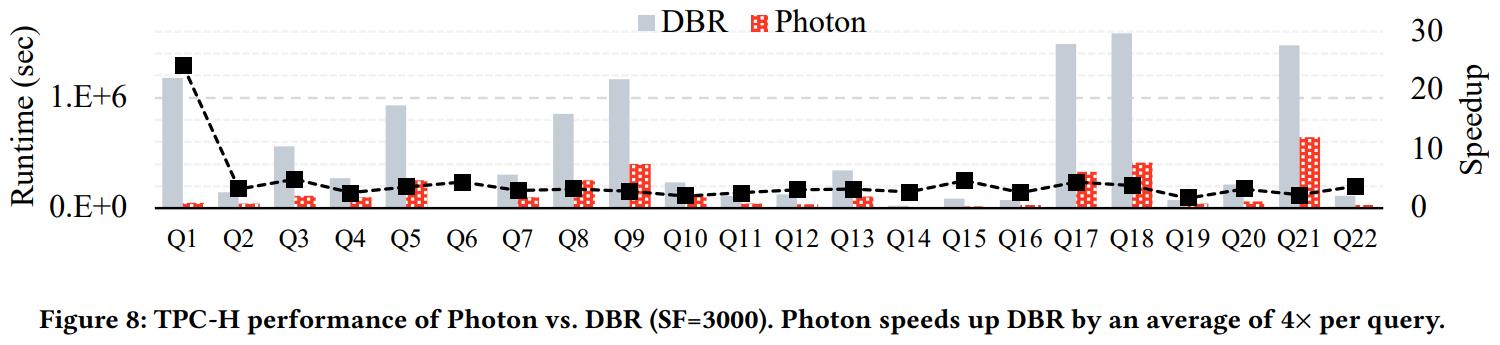
TPC-H 大概有 8 - 23倍的性能提升
大概有 0.06%的 JNI调用的开销
Q1的提升来自decimal类型的处理,DBR使用的是JDK的BigDecimal,性能非常差
另外稀疏场景需要做压缩,不然性能还不如原生的