Rethinking SIMD Vectorization for In-Memory Databases
原文
https://15721.courses.cs.cmu.edu/spring2023/papers/08-vectorization/p1493-polychroniou.pdf
背景
实时分析系统推动了大数据的发展
现在的客户不仅要求高吞吐的OLTP,也要求交互式的OLAP系统
现代系统从面向磁盘转向了面向主内存,而主内存系统为了进一步加速也做了一些优化:
- 面向列的更高好的压缩 -整合延迟物化消除不必要的内存列驻留
此外,硬件提供了三种并行化
- 线程并行,对于独立操作,通过拆分输入,将其均摊到;多个操作时,通过查询计划的流水线断开点,将物化数据分发给多个线程
- 指令级别并行,将相同的操作整合到tuple块中,编译器再生成紧密的机器代码
- 数据并行,每个操作使用SIMD指令来实现
主流的 CPU 对上述三种都支持了,超标量流水线、10条指令的乱序执行、SIMD能力
厂商将这些能力放到一个芯片的多个核中
而当前更流行一种:many-integrated-cores MIC架构,将多个简单的核放到一个芯片中
移除掉了超标量流水线、乱序执行、L3-cache,每个核很小、耗电量很低,这样就可以增加更多的SIMD指令、并行线程,来加速并行化
MIC 一开始适用于GPU的,不过现在的目标是高性能计算
本论文中,介绍了基于内存数据库的SIMD设置原则,不需要修改逻辑,也不需要修改数据布局
包括:选择scan、hash table、分区(radix、hash、range)
并使用这些操作组合更复杂的操作: 排序、join
相关论文
- 《Implementing Database Operations Using SIMD Instructions》SIGMOD 2002
- 《hash probes on modern processors》 ICDE 2007
- 《SIMD-scan: ultra fast in-memory table scan using on-chip vector processing units》 PVLDB 2009
- 《A new parallel sorting algorithm for multi-core SIMD processors》PACT 2007
- 《Efficient implementation of sorting on multi-core SIMD CPU architecture》VLDB 2008
- 《 fast architecture sensitive tree search on modern CPUs and GPUs》 SIGMOD 2010
- 《High throughput heavy hitter aggregation for modern SIMD processors》 2013
- 《 A comprehensive study of main-memory partitioning and its application to large-scale comparison- and radix-sort》 SIGMOD 2014
- 《Vectorized Bloom filters for advanced SIMD processors》 2014
- 《Improving main memory hash joins on Intel Xeon Phi processors: An experimental approach》 PVLDB 2015
实现
先是定义4个基本操作,然后用这些基本操作完成一些简单的功能,如
scan、hash-table、分区
再用上面几个操作,构建更复杂的 排序、join
相当于层层的搭积木了
基本操作
首先是两个空间连续的内存访问,以及两个不连续的内存访问
- selective store
- selective load
- gather
- scatter
store是将向量中的一个子集,按照向量寄存器的掩码,或者标量的掩码
写入到一段连续的内存区域中
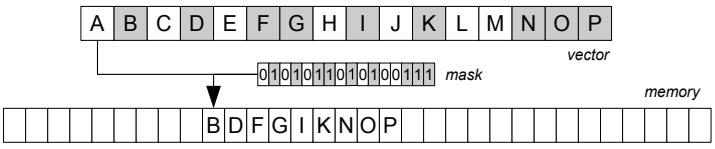
Figure 1: Selective store operation
load跟store类似,也是从内存中读取一段连续的数据
同样,也是基于掩码的,通过掩码将内存值加载到 向量寄存器中

Figure 2: Selective load operation
存储使用的是两个 KNC 函数模拟的:
|
|
加载使用的是这两个函数模拟的:
|
|
gather操作,是非连续的,输入是 索引向量、数组指针
输出是数组元素对应的值 向量,通过定义掩码操作,就有定义selective gather在向量管道子集上的操作
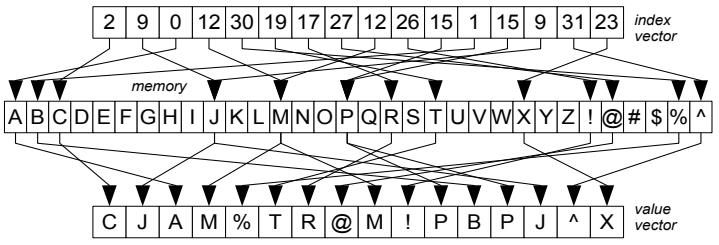
Figure 3: Gather operation
scatter操作也是非连续的
输入也是向量索引、数组指针,值向量,如果多个向量管道指向同一个位置,那么最右边的会写成功
通过定义掩码,就可以实现 selectively store操作
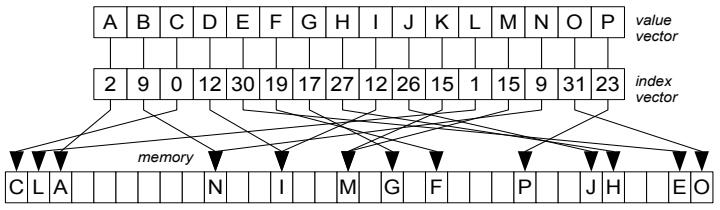
Figure 4: Scatter operation
gather操作要求一次性操作 W个cache,实际上是做不到的,因为每个CPU周期只能执行 1 - 2次的cache访问
gather操作对于现代主流CPU已经支持了,但是scatter没有,而老的CPU两者都不支持
可以通过其他方式来模拟这两个操作,但是性能会有很大损失
主流CPU对于load、store也不支持,但是可以通过 permutation指令来模拟
通过数组索引 来作为掩码,从已生成的table中提取数据,之后会将 活跃的向量数据放到寄存器的一边,不活跃的放到另一边
通过混合load、store来替换不活跃的元素,这种技术最初用于向量化的 bloom filter
gather对应的SIMD函数:
|
|
scatter也有支持的函数,需要的指令集是:
CPUID Flags: AVX512F + AVX512VL
|
|
selection scan
selection scan在现代主内存系统中又重新出现了,用于替代之前的二级索引
使用如下方式做一些优化:
- 轻量级的bit压缩,减少RAM带宽
- 生成统计信息跳过不需要的数据块
- 使用 bitmaps-zonemaps 跳过cache line
传统的线性scan的性能,跟分支预测失败有很大关系
将控制流转为数据流的方式会影响性能,如算法1:

而将分支消除后,可以得到算法2
这个算法消除了 if,在分支情况下如果不满足就直接忽略,而这个就会执行覆盖操作
相当于每次遍历都会有一个覆盖操作,这个操作可能是基于cache所以很快

向量化的版本,算法3
- 使用向量指令,将谓词值存到掩码中,掩码中标记了哪些管道是活跃的
- 使用一个cache来保存index,而不是真实的值
- 当buffer满了,使用gather获取所有列的真实值,输出到内存中
- 使用bypass的方式,绕过cache,将向量寄存器的值,直接写入内存,避免cache污染
- 这里使用的是 _mm512_storenrngo_ps指令

hash table
hash-table用于joi、聚合等场景
使用SIMD方式先构建一个hash-table桶,也就是一次探测多个key,而不是传统上的单个key探测
这里又分为两种方式
- horizontal
- vectorization
有些变种如cuckoo hash支持更高的负载因子
论文中的hash-table跟传统的不同,它的设计思想是:
- 每个向量管道,处理不同的输入key
- 之后访问不同的hash-table位置
Linear Probing
一种开地址方式,可以插入条目,或者当扫描到空位时终止搜索
线性探测Probe标量版本的如下:

线程探测Probe向量版本
- 将多个探测的key放到向量中
- 通过gather去hash-table中拿值
- 优化:某个很早探测到key,可能一直在向量中(后面没有被探测到早期的就一直残留)
- 浪费cpu,当检查到某个管道探测为空时,再加载新的探测key进来

线性探测Build标量版本的如下:

向量的build版本
- 跟probe版本类似,也是一个SIMD处理不同的输入key
- 同样,如果桶是空的则继续加载元素
- 这里会使用scatter将元素加载回内存,同时会检查是否有 冲突
- AVX3 中使用 vpconflictd 指令检查冲突
- 为了处理table生最后剩余的一些数据,需要切换回标量版本

double hash
处理重复key的方式
- 使用独立的table,当大多数key都重复时表现很好
- 存储重复的key,如果都是唯一的则表现很好
double hash如下:

cuckoo hash
使用多个hash表的方式来探测
普通的方式是探索hash1 是否满足,不满足则探测hash2
这样方式会有分支的开销,向量版本是
- 同时获取key1、key2函数
- 然后用gather+key1、gather+key2分别获取桶中的数据
- 使用bit位来比较hash1 是否满足
- 之后将向量中的值,放入hash-table中

build过程更复杂
- 如果选择的两个桶都不是空的
- 此时要创建一个新空间,用来替换其中一个桶中的tuple
- 这个过程可能会重复,直到某个选择的桶为空

bloom filter
一个基本的数据结构,在join之前,会应用跨多个表的选择条件
根据 k 个函数函数判断对应的bit位,来决定对应的tuple是否满足
向量版本
- 使用一个W 个key值的向量
- 对于 k 个hash函数,循环 k 次
- 每次从向量管道中,根据key计算hash bit,得到一个掩码 m
- 再用 掩码去 bloom-filter中探测,如果不满足就淘汰掉
相关论文
《 Vectorized Bloom filters for advanced SIMD processors》 2014
partition
这也是硬件中非常重要的一个操作
比如用 分区函数,将大的数据集,拆分成多个小的,可以驻留内存的子集,并且都是不重叠的
这样就可以实现线性级别的并行操作
Radix & Hash Histogram
在移动数据之前,先计算数据的边界,这里使用直方图
为每个key增加一个计数,而key的分配可能会重复,因此将一列 变成多列,这样就不会冲突了
只有再将多列合并为一列, 每行统计个数

Range Histogram
range分区一般比 radix、hash慢很多
为了将数据分配到连续的区域,一般会有一个与计算的步骤,先统计分区的数量
计算各个分区在连续区域中的偏移量,后续就可以并行的向各个分区填充
range分区使用了并行的二分查找

Shuffling
通过预计算,就得到了每个分区在全局数据中的起始offset,然后就可以真正的移动数据了
首先还要考虑tuple冲突问题
这里使用了 permutation操作,将数据做了翻转
比如 vector lan:key1、key2、key3
hash位置:10、15、10
key1 和 key3冲突了,key3写会被key1覆盖,翻转后世key1被写入,key3的offset+1
这种分区机制对于像 LSM radixsort排序也很重要

shuffling机制如下:

Buffered Shuffling
如果输入数据能保留在cache中则会很快,但随着数据变大性能就会变成
- 如果超出了TLB容量,会出现 TLB抖动
- 可能会出现很多冲突,最坏的情况下会收到 缓存级联的限制
- 触发了cache加载机制,加载会将数据覆盖到cache-line,这相当于减少了带宽
- 因此每个分cache有 W个buffer,将cache和TLB 的miss减少到 1/W
- 向量化+buffer的版本如下,算法15,比 算法14 无buffer的版本更好,使用了cache驻留而不是直接输出
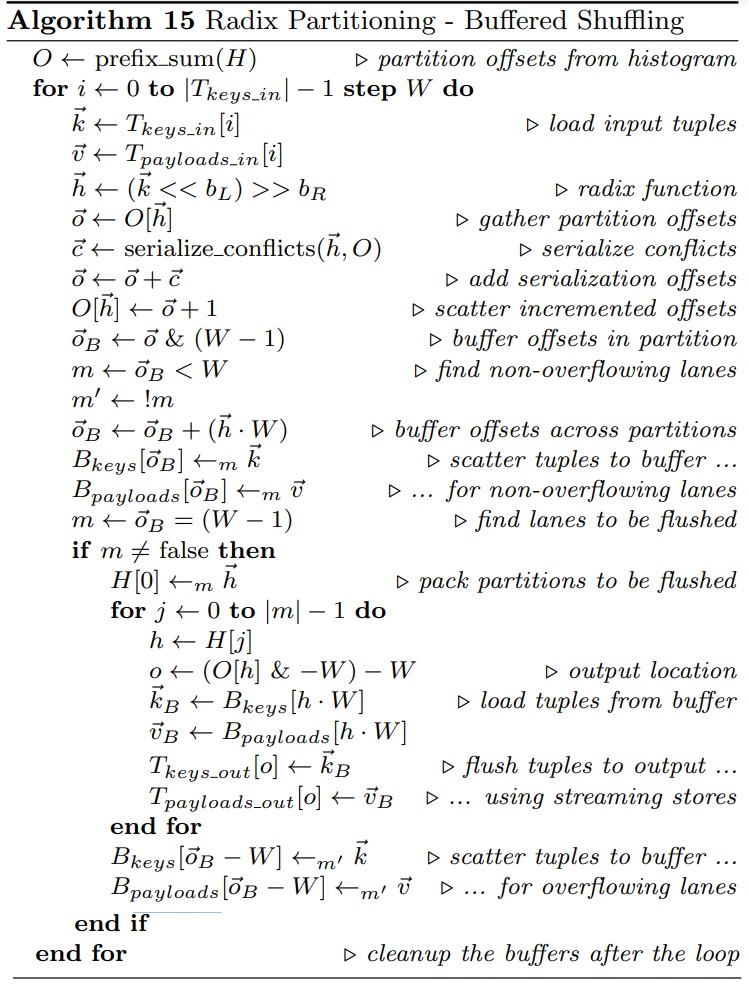
sorting
可以当做 join、聚合的子问题
排序也可以用于
- 去聚合
- 索引构建
- 压缩
- 去重
最近的研究表明,大规模的排序 等同于分区
radix-sort和基于range分区的比较排序,使用最大化扇出,以便最小化分区通过的数量
《A comprehensive study of main-memory partitioning and its application to large-scale comparison- and radix-sort》
least-significant-bit LSB radix-soft是最快的方式(对于32位key来说)
这种方式将输入数据拆分到多个线程中,然后所有线程交错的输出分区
柱状图的生成、shuffling操作时不共享的,这样线程可以最大化并行,使用分区buffer也能最大化数据并行度
hash join
是分析查询系统中使用最频繁的操作,也是最耗时的操作
hash-join,内关系用于构建hash表,而外部关系用于探测hash表,找到匹配的值
分区可以用于hash-join,具有不同程度的优缺点,有三个变种
- no partition,使用原子操作跨多个线程构建共享hash表,使用barrier同步,探测过程是只读的,但构建过程无法向量化,无SIMD原子指令
- min partition,使用分区来消除原子使用(不构建共享hash表),构建关系划分为T部,T是线程数量,不跨线程共享的情况下构建T个hash表,探测时选择要搜索的hash表,所有部分都可以完全向量化
- max partition,将左表拆分直到能完全放到cache中,分区结果使用build和probe都可以放到cache中,可以完全向量化
性能评估
这里选用三种类型的CPU做测试
- MIC架构的CPU
- 多内核的CPU
- 高端的4路CPU
使用了Inter的ICC编译器,以及GCC4.9,所有的case都使用 -O3 优化选型
Haswell CPU使用了 -mavx2 选型
Sandy Bridge使用 -mavx 选型
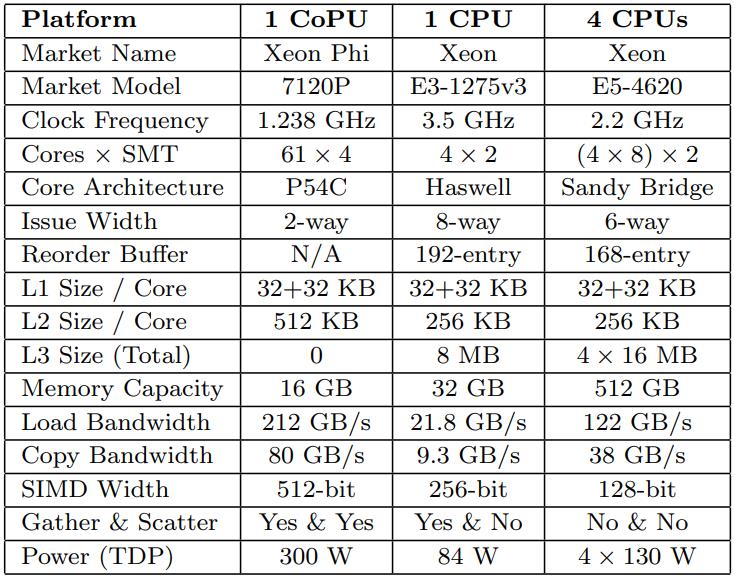
Selection Scans
包含 6个观察目标,2个标量的,4个向量的
Xeon Phi 的branchless版本的标量反而更差了(较慢的set指令),而Haswell的branchless标量版本更好
两种CPU的向量版本都有大幅度提升,MIC架构有数量级的改变,多核架构有2倍提升
随着选择率的上升,向量版也开始下降,因为受到内存带宽的影响
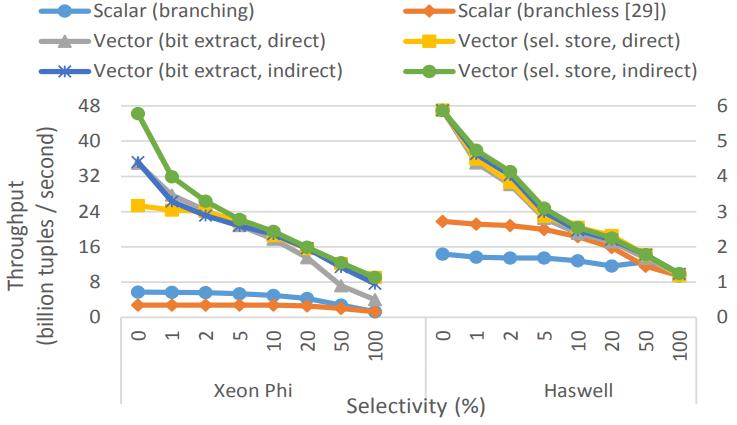
Figure 5: Selection scan (32-bit key & payload)
Hash Tables
比较了线性探测和probe的性能
MIC架构下,线程探测大概提升 6倍性能
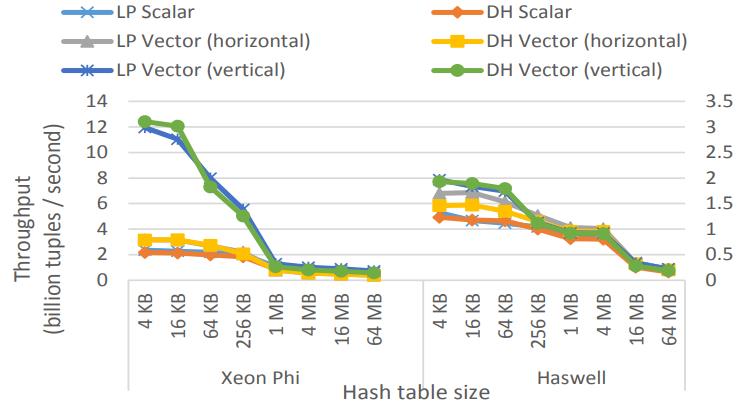
Figure 6: Probe linear probing & double hashing tables (shared, 32-bit key → 32-bit probed payload)
比较cuckoo hash,包括branch和branchless的标量版本
水平、垂直的向量版本,以及混合向量版本
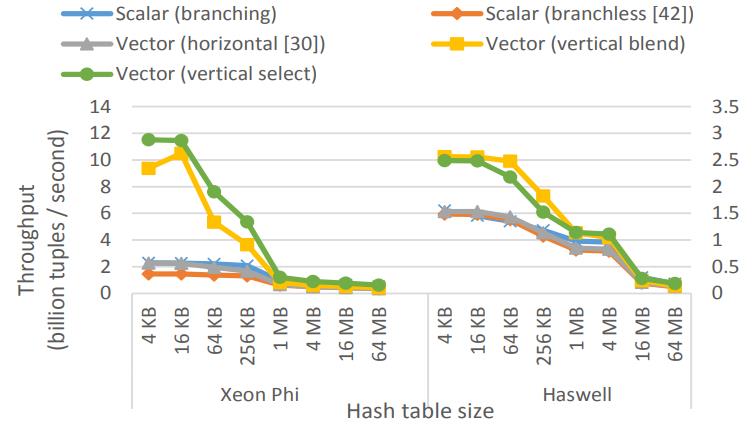
Figure 7: Probe cuckoo hashing table (2 functions,shared, 32-bit key → 32-bit probed payload)
对比了线程探测LP、双hashDH、cuckoo hash CH
build和probe比例为1:1
可以看到放到L1的时候限量版吞吐量最大,而随着cache放不到进入到内存时,向量版本的优势几乎没了
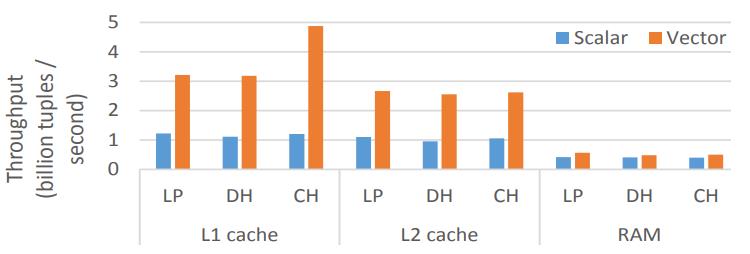
Figure 8: Build & probe linear probing, double hashing, & cuckoo hashing on Xeon Phi (1:1 build– probe, shared-nothing, 2X 32-bit key & payload)
build和probe的比例为1:10
上个测试是没有重复key的,这里包含了重复key,以及不匹配的情况
因为build过程更耗时,在没有重复key情况下有接近7倍加速,5个key重复时有2倍加速
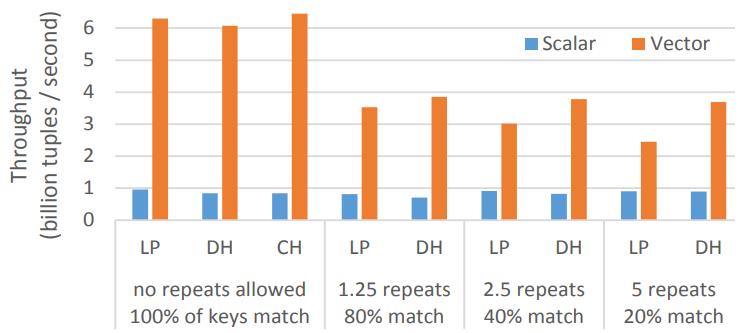
Figure 9: Build & probe linear probing, double hashing, & cuckoo hashing on Xeon Phi (1:10 build–probe, L1, shared-nothing, 2X 32-bit key & payload)
Bloom Filters
选择性load和store
这里关闭了循环展开,增加了buffer
MIC架构下有7.8倍加速,多核架构下有3倍加速
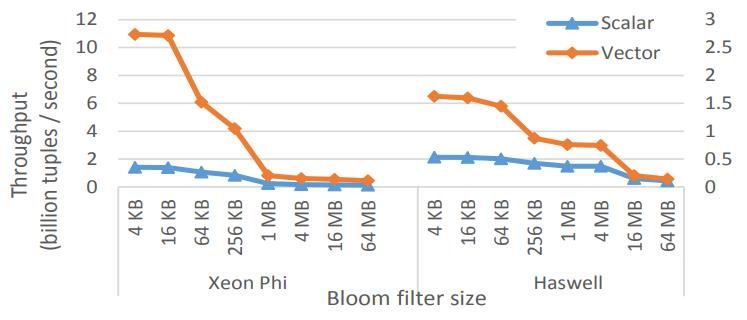
Figure 10: Bloom filter probing (5 functions, shared,10 bits / item, 5% selectivity, 32-bit key & payload)
Partitioning
这里包含了向量化hash/radix的三种版本
随着分区的增加,L1也放不下了,之后性能开始下降
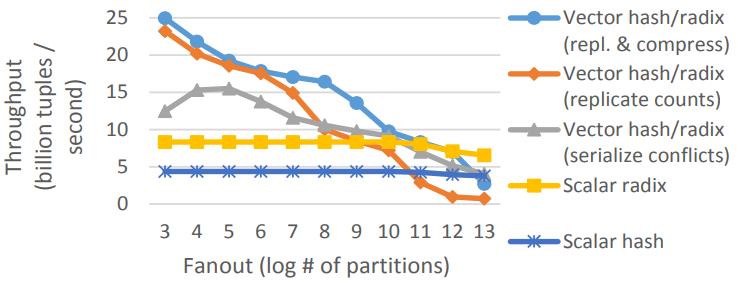
Figure 11: Radix & hash histogram on Xeon Phi
下面是range分区的,MIC架构下有7-15倍的提升
多核架构下有2.4 - 2.8倍提升
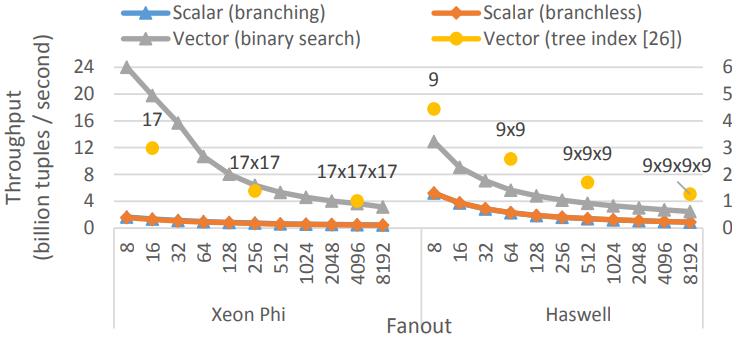
Figure 12: Range function on Xeon Phi (32-bit key)
当输入数据大于cache时,没有缓存的向量版本就不行了
带有缓存的标量版本表现也不错,向量+buffer的两个版本都有几倍的提升
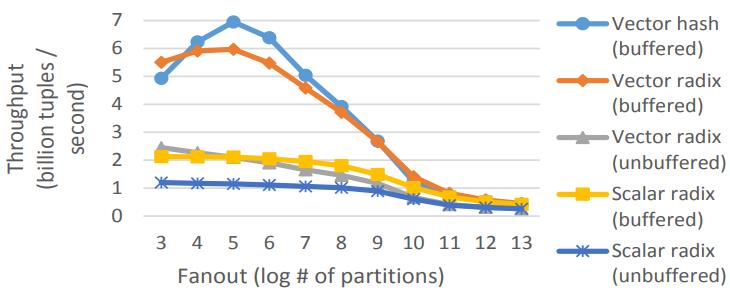 Figure 13: Radix shuffling on Xeon Phi (sharednothing, out-of-cache, 32-bit key & payload)
Figure 13: Radix shuffling on Xeon Phi (sharednothing, out-of-cache, 32-bit key & payload)
Sorting & Hash Join
主要是三点
- 测量MIC架构,并强调向量化对算法设计的影响
- 跟4路高端CPU比较
- 研究多列物化、通用实现的成本
Vectorization Speedup
LBS的radx-sort比标量版本有2.2倍加速
主流的CPU带宽基本都饱和了

Figure 14: Radixsort on Xeon Phi (LSB)
比较了hash join的三种变体,no partition、min、max
no和min只有1.05 - 1.25的加速
而max有3.3倍加速
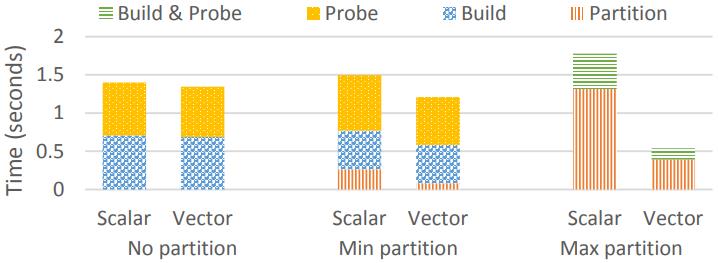
Figure 15: Multiple hash join variants on Xeon Phi(2 · 10^8 ./ 2 · 10^8 32-bit key & payload)
下面是测试线程的扩展性,基本都是达到了线性扩展
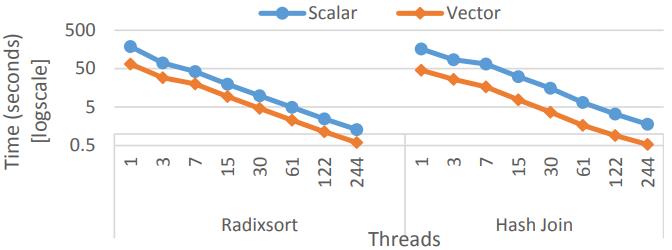
Figure 16: Radixsort & hash join scalability (4 · 10^8& 2 · 10^8./ 2 · 10^8 32-bit key & payload, log/log scale)
Aggregate Performance & Power Efficiency
高端CPU sandy bridge SB,以及MIC架构的
SB高端CPU的内存快饱和了,所以很难利用向量化
高顿CPU的radix-sort、hash-join都有NUMA感知, 只需要跨CPU传输一次
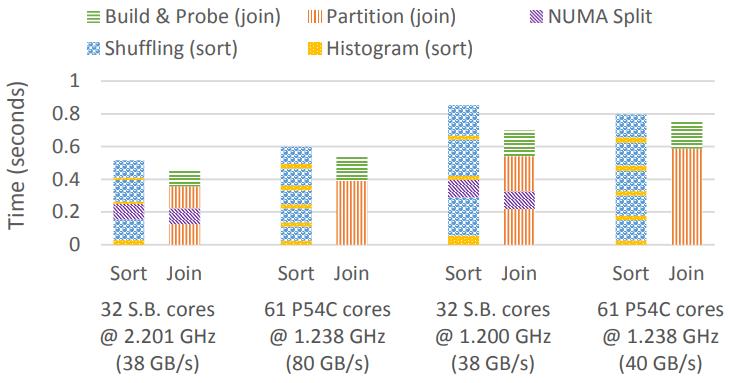
Figure 17: Radixsort & hash join on Xeon Phi 7120P versus 4 Xeon E5 4620 CPUs (sort 4·108 tuples, join 2·108./ 2·108
tuples, 32-bit key & payload per table)
Multiple Columns, Types & Materialization
向量代码不能像标量代码那样容易地处理多种类型
下面是radix-sort对于各种数值类型,宽度的比较
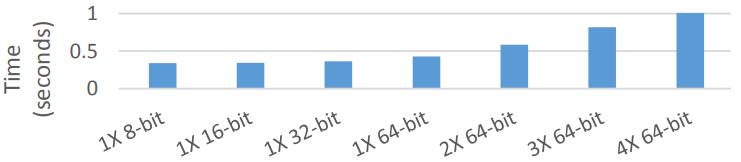
Figure 18: Radixsort with varying payloads on Xeon Payload columnsPhi (2 · 10^8 tuples, 32-bit key)
下面是has-join的比较,左表和右表的比列不同
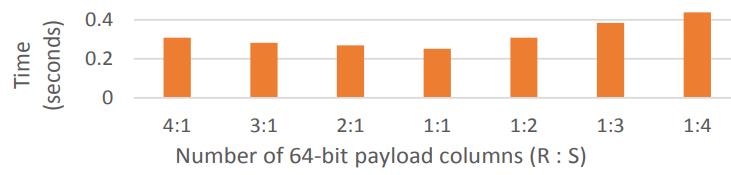
Figure 19: Hash join with varying payload columns on Xeon Phi (10^7 ./ 10^8 tuples, 32-bit keys)
参考
- 深入向量化计算技术
- 《A comprehensive study of main-memory partitioning and its application to large-scale comparison- and radix-sort》
- 英特尔的指令集体系结构_Intel MIC初探(一):MIC架构及编程模型概览
- 常见开源OLAP技术架构对比
- SIMD简介
- 高性能C++ SIMD 学习
- C/C++性能测试工具—-gprof
- c++ SIMD 样例
- C++中使用SIMD
- C++性能优化笔记-11-使用向量操作
- Computer Hardware and Architecture
- Rethinking SIMD Vectorization for In-Memory Databases 论文解读
- Rethinking SIMD Vectorization for In-Memory Databases
- perf性能分析工具命令简单实用
- 虚函数真的就那么慢吗
- 代码里充斥着 if-else 分支有什么不好吗
- 几款好的C/C++编译器
- Implementing Database Operations Using SIMD Instructions
相关文章
- SIMD-Scan: Ultra Fast in-Memory Table Scan using onChip Vector Processing Units
- Make the most out of your SIMD investments: counter control flow divergence in compiled query pipelines
- Accelerating Analytics with Dynamic In-Memory Expressions
- Materialization Strategies in the Vertica Analytic Database: Lessons Learned
- MonetDB/X100: Hyper-Pipelining Query Execution