SIMD-Scan: Ultra Fast in-Memory Table Scan using onChip Vector Processing Units
原文
https://15721.courses.cs.cmu.edu/spring2023/papers/08-vectorization/willhalm-vldb2009.pdf
背景
随着硬件容量的提高,面向磁盘的数据库 开始转向 面向内存的数据库
SAP® Netweaver® Business Warehouse Accelerator BWA 利用轻量级的压缩来进一步提升内存带宽
比如
- run-length编码
- 固定长度编码的多版本
- bit位编码的字典压缩,默认算法,通过字典来引用列,而且引用是 run-length编码的
访问都是直接基于压缩数据的,会隐式的解压数据,所以数据解压就很重要,变成查询执行的一部分了
CPU处理能力的 增加 > 数据带宽的增加,这就引入了更多的复杂算法,用来全表扫描
这就将 I/O 瓶颈转移到了 CPU瓶颈
为了能在内存中尽可能多的处理更多的压缩数据,出现了一些新的研究领域,也就是利用多核处理能力,用各种并行化能力加速表扫描
但是其 向量处理单元 Vector Processing Units VPU 并没有真正发挥其能力
这篇论文就引入SIMD的能力,为每个核提供有效的 解压内存表列数据,并以低延迟方式搜索数据
当然这些技术就只限于多线程场景
SIMD技术如下,利用一个指令,来实现并行化数据处理
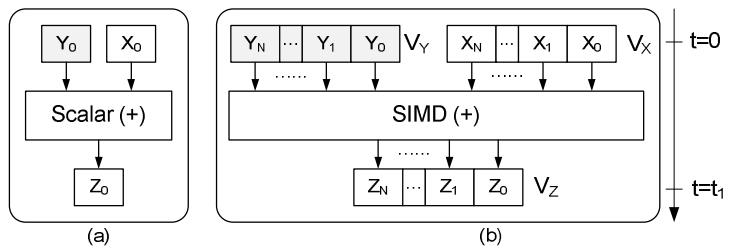 Figure 1. SIMD execution model: In (a) scalar mode: one operation produces one result. In (b) SIMD mode: one operation produces multiple results
Figure 1. SIMD execution model: In (a) scalar mode: one operation produces one result. In (b) SIMD mode: one operation produces multiple results
全表扫描是主内存列式数据库中一个很重要的操作,它可以避免创建索引减少内存消耗
论文中提出了两项改进操作
- Vectorized Value Decompression,这里使用一种快速的SIMD解压方式,用于轻量级数字压缩技术
- Vectorized Predicate Handling,用于等值、范围查找,这里也是使用SIMD方式
这些方式都比较通用,对于大多数数据库都是适用的
Figure 2. Vectorized table scan operations
数据库压缩研究集中在两个方面
- 压缩算法、以及将它们整合到数据库系统中
- 压缩性能方面,如对查询响应时间加速,节省磁盘存储空间等
相关论文
- 《The Implementation and Performance of Compressed Databases》,一个轻量级的压缩算法,整合到DB中并提速
- 《Data Compression and Database Performance》,尽可能长的保持数据压缩,只有当需要时才解压
- 《How to Barter Bits for Chronons: Compression and Bandwidth Trade Offs for Database Scans》压缩和带宽之间的权衡,将压缩数据拆分成bolock,不同线程并行处理
- 《Row-wise parallel predicate evaluation》,通过高效布局实现谓词求值
轻量级压缩算法包括
- 数值压缩
- string压缩
- 字典压缩
这些压缩算法可以用于文件级别,page,row,以及最小的字段级别
也就是说每个字段都可以独立的 压缩/解压缩,没有任何依赖
比如LWC-NC压缩,对于4字节的整数 3,可以存储为11b,忽略其他 30个 0
对于整数数组,假设这个数字包含了 1024个 无符号整数,需要1024 * 32 = 4K存储量,假设最大数字为 511
则最多只需要 9个bit就可以了 $n = \lfloor log_{2}m \rfloor$
其压缩比例为 $r = \frac{n}{sizeof(int)}$
这里的压缩比例为 0.28,也就是可以节省 72%的空间
前缀压缩,对于0可以忽略,这是变长压缩
帧引用,保留一个block中的最小值,然后每个值 - 最小值
使用向量化的方式有四种
- 内嵌汇编
- intrinsics,硬件厂商提供的跨平台库函数
- 编译器指示符,如 #pragma simd
- 编译器自动优化
每种方式都是在 可用性、可控性之间的权衡
比如编译器自动优化的可用性最高,但是可控性最低
SIMD提供了如下一些操作:
- Arithmetic Operations: 加减乘除等
- Logic Operations: and、or、移位等
- Compare Operations: string压缩,block压缩等
- Data Movement: Load/Store, String copy, Block copy等
- Miscellaneous Operations: Data-type conversion, Shuffling, Concatenation, Cache-ability
假设系统是32位的,所有的整数(压缩和未压缩的)都存储在按字节访问的内存中,是按地址连续存储的
那么32bit的数据,开始地址为 a,结束地址为 a’ + ( 4 * n)
也允许我们将两个 64位整数,当做一个 128位数来访问
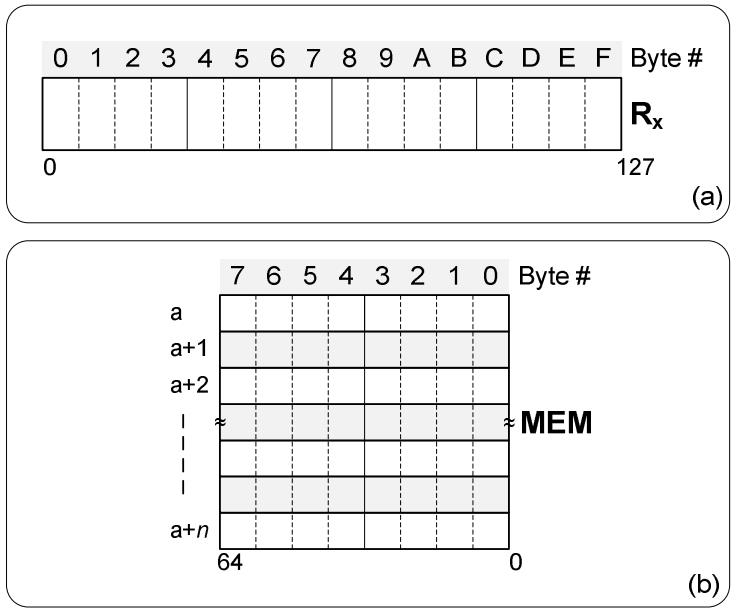
Figure 3. System model: (a) the SIMD register model, (b) the memory layout model
概念和实现
Vectorized Value Decompression
这里通过SIMD来优化 内存中解压LWC-NC压缩数据,主要分为三个阶段
- 16字节对齐
- 4 字节对齐
- bit对齐
16-Byte Alignment
主要用来处理 loading、copy(shuffling)、extracting(shifting)、按顺序存储压缩值
对应的 SIMD 解压算法代码如下:
 上述算法中几个重要变量介绍
上述算法中几个重要变量介绍
n是最大的bit数,计算公式为:$n = \lfloor log_{2}m \rfloor$- max_index = sizeof(input),max_index 除以 128,表示一次可以处理 128个bit
- 变量 $b_{a}$、$c_{a}$、$b_{b}$、$c_{b}$,这是向量变量持有的四个 LWC-NC压缩整数
- shuffle掩码 $m_{a}$、$m_{b}$是移位的总量,依赖于 n,而不是 j
将128位的压缩数据,拷贝到 RL寄存器中,拷贝数量 n 取决于要表示多少bit
如果用 9-bit,可以保持14个压缩整数值,注意第 15个值,它是不完整的,所以不能被解压
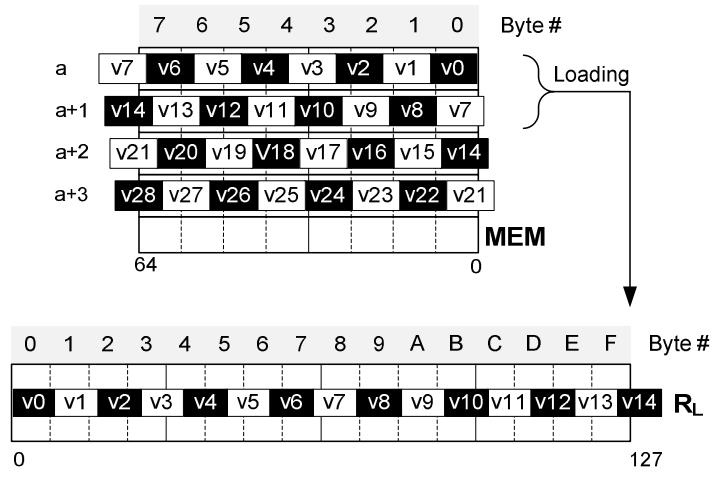
Figure 4. Loading 128-bit compressed block to a SIMD register (9-bit compression).
上图中,一次加载 a、a + 1,但是v14是不完整的,解决办法
- 第二次加载时,从v13开始加载,这样前面6个bit是无效的,这样就能得到完整的整数,缺点是这样就不对齐了效率会降低
- 将两个128位的寄存器 拼接在一起,放到 256位的寄存器中,再做移位操作,这种是对其的
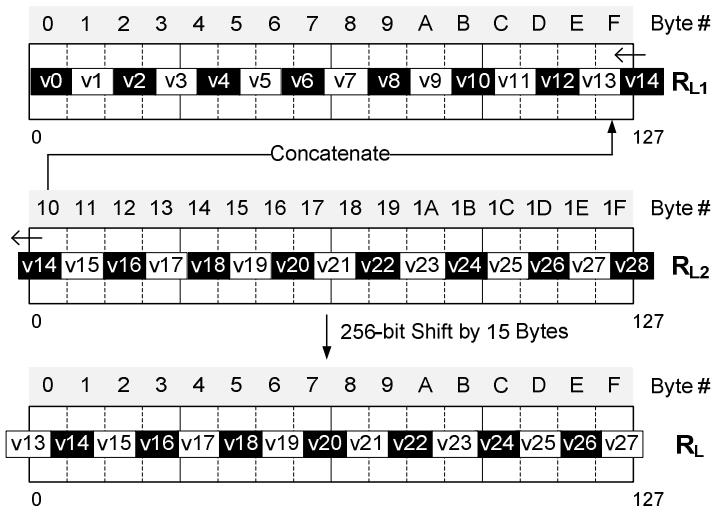
Figure 5. Concatenating two SIMD registers for value alignment in one hardware instruction
如上,将两个寄存器拼接,然后 256寄存器做移位,移位15字节
将v13放在新 RL 的第一位,这样整体就是完全对其了,效率就有保证
4-Byte Alignment
这里是拷贝四个独立的 压缩整数到 寄存器RC 中
使用 shuffle 和掩码指令,将 RL 拷贝到 RC中
下面所有 黑色的都是有效的,但这不是对齐的,后面会继续使用 bit对齐的方式来修正
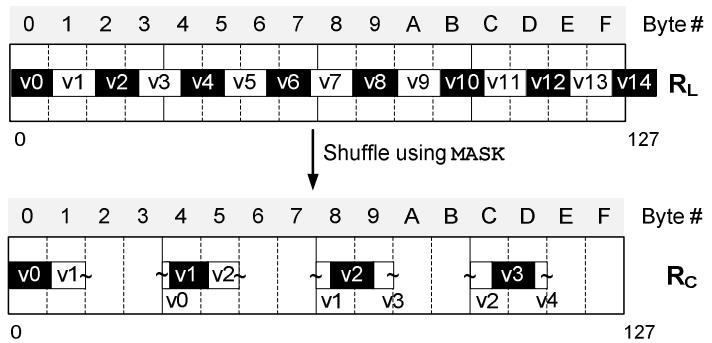
Figure 6. Copying four 9-bit values to separate DWs
另一个问题是,有些元素是横跨了几个寄存器的
这时可以用shuffle指令,将前面 4个值拷贝到 RC1,然后做一次右移指令
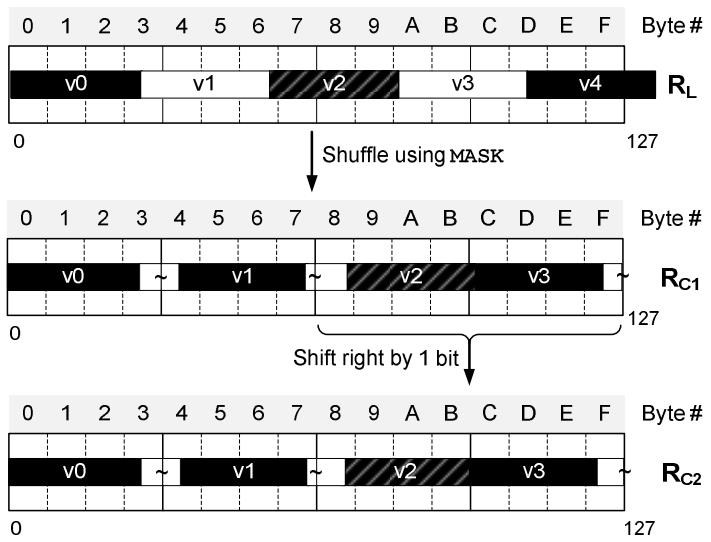 Figure 7. Spanning-value issue with 27-bit compression
Figure 7. Spanning-value issue with 27-bit compression
Bit Alignment
目标是对其四个值,并屏蔽掉尾部的无效位
如下所有独立的值都做 左移位,然后将无效的bit清除
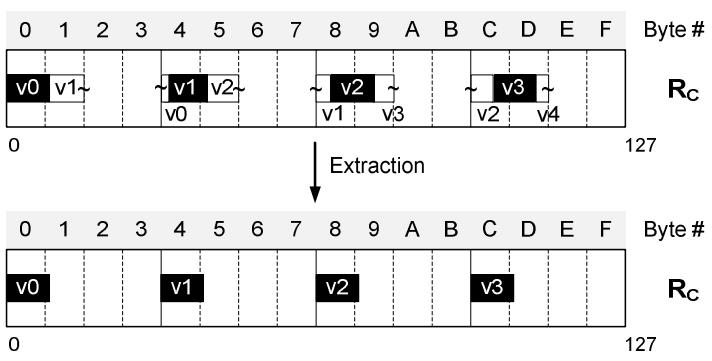
Figure 8. Extracting the four 9-bit values
之后将寄存器中 四个对其的提取后的 解压值,存储回内存位置
这样后续的执行引擎就可以继续使用这些整数值了
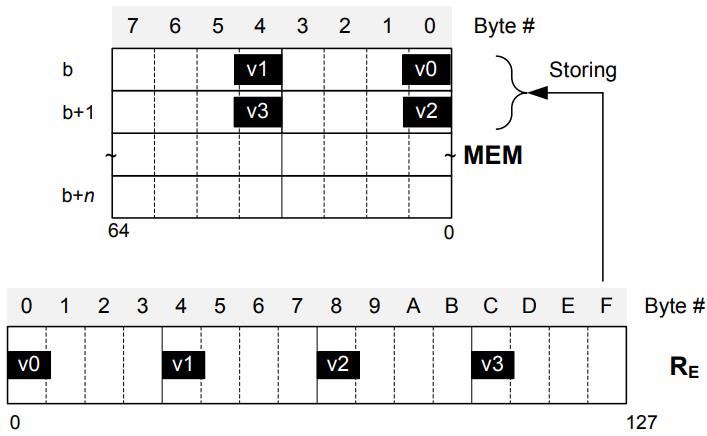 Figure 9. Storing the decompressed integer values
Figure 9. Storing the decompressed integer values
Vectorized Predicate Handling
表扫描操作中,用于决定一个值,或者一个值范围
搜索算法会返回搜索范围内的压缩值索引,也可以使用bit位来映射查找范围
比如数组范围是升序的 0d – 255d,查找条件是 1d to 5d
查找结构是256bit的向量,如 011111000…0b, 数组索引是1d、2d、3d、4d、5d
这里不是解压整个数据然后 从头搜索,而是基于一个查找条件(谓词),直接在LWC-NC的压缩数据上比较
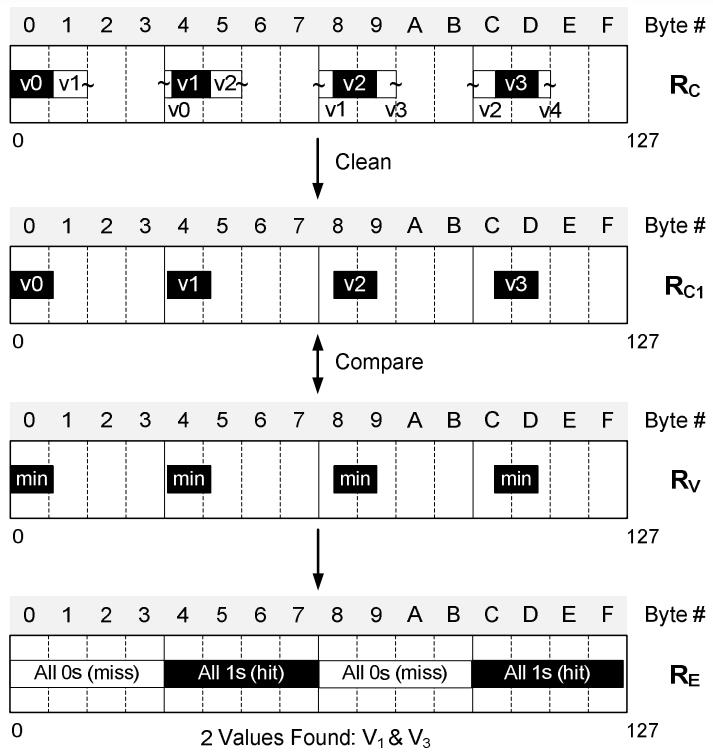 Figure 10. Vectorized scan-value search with predicate
Figure 10. Vectorized scan-value search with predicate
如上,通过对RC做 min值 的比较指令,结果寄存器会保持4个结果,如果对应的结果为0,表示没有落在这个范围内
这样就可以生成一个索引数组的位向量
搜索算法的代码如下:
 n 的值是通过公式 $n = \lfloor log_{2}m \rfloor$ 计算出来的
n 的值是通过公式 $n = \lfloor log_{2}m \rfloor$ 计算出来的
$min_{a}$、$min_{b}$、$max_{a}$、$max_{b}$、$b_{a}$、$c_{a}$、$b_{b}$、$c_{b}$ 是向量变量,用来存储4个整数
实现和评估
SIMD的实现包括
- Inter的SSE,SSE2、SSE3、SSE4
- AMR的 3DNow!
这里选择SSE指令集,并预抓取内存中的128bit 压缩数据到内存中
使用了 Inter提供的 <intrinsic.h> 库函数
使用之前介绍的 concatenate/shift 指令,避免未对齐的情况,而 Intel® Xeon® Processor 5500 提供了快速的未对齐访问方式
4字节对齐通过选择拷贝的值,到独立的目的地址
通过shffule和mark指令完成
bit字节也是类似的,先提取出来,将无效的bit去掉,然后重新存储到内存中
实现中海油其他的一些压缩对齐方式,他们也有加速效果,但只能用于特定的case
乘法可以用于所有场景,而且效果都很好
也不是所有的SIMD实现都支持假设指令,需要用不同方式替代
之后要讲这些实现整合到 SAP® Netweaver® Business Warehouse Accelerator (BWA)
这是SAP 和 Inter联合开发的
- 它用一个高度压缩的索引结构来加载内存中的用户请求数据
- 使用高性能的聚合技术,在内存中处理请求
- 并将结果导回到 BWA中
具体实现包括两种,使用SSE实现
- 只解压缩表的列
- 将查询谓词整合到scan中,但不解包数据
图11 显示了,经过优化的,使用了最小化cache丢失比例、海量的循环展开,允许预计算位移参数,以及掩码
对比未优化的没有做循环展开的版本,这个未优化的有很大延迟
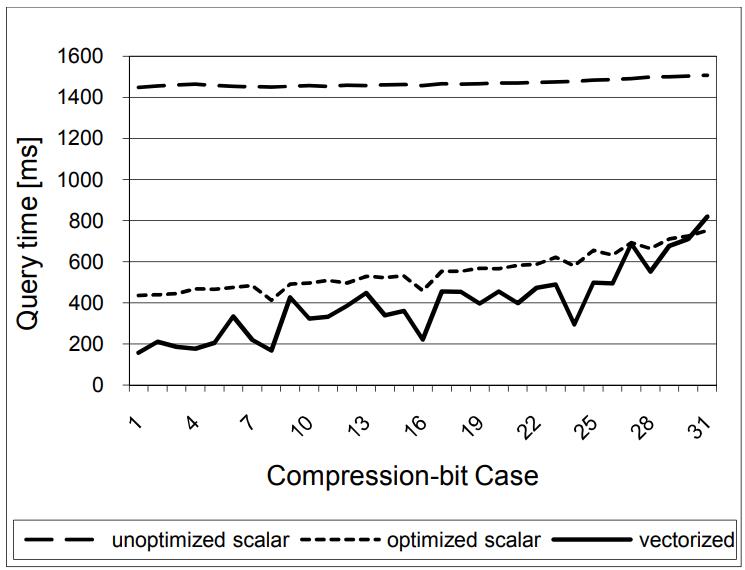
Figure 11: Time to decompress 1B integers
图12 显示了并行8个bit的处理,这里使用的是SSE寄存器,平均有 1.58倍的提升
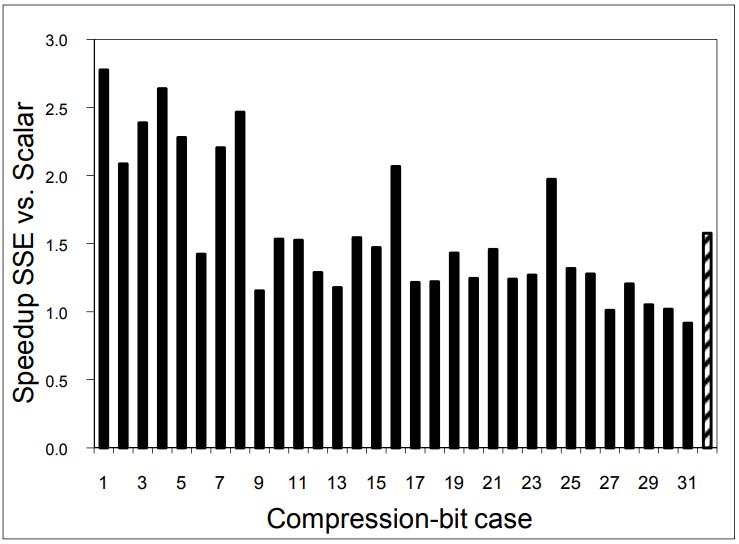
Figure 12. Speedup for decompression by vectorization
图13 是全表扫描的情况,31bit的情况下,向量化还不如scalar扫描,平均有2.16倍加速
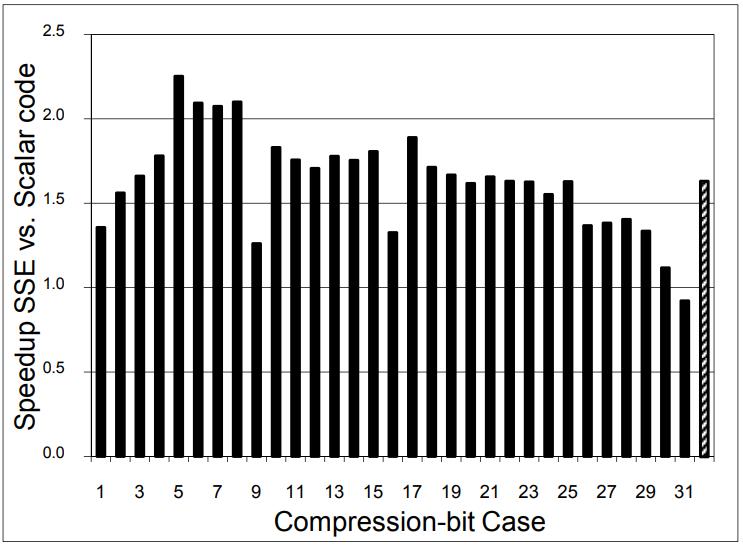
Figure 13. Speedup of full-table scan by vectorization
图14是全表扫描,但加入了选择率这个条件,下图中每个黑点代表加速比列,平均有1.63倍的加速
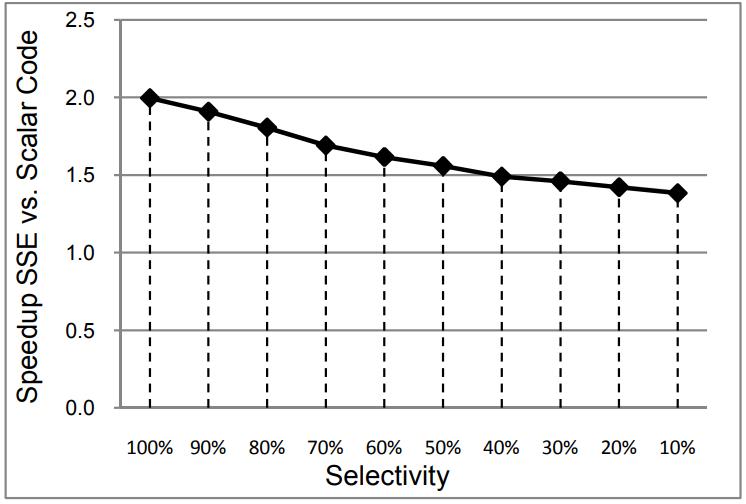
Figure 14. Speedup of full-table scan by selectivity
下面是整合到真实场景中的加速情况
一般来说 8 - 16bit是比较好的,平均来说,全表扫描有 2.45倍加速
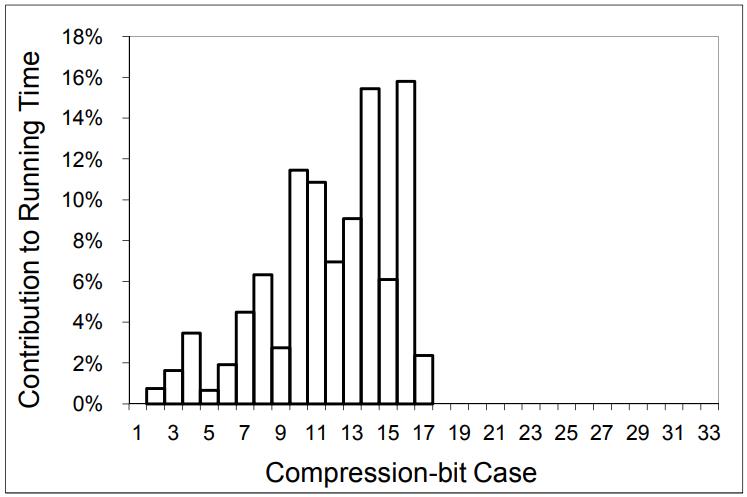
Figure 15: Running time distribution for customer workload
下面是 8核,测试可扩展情况,基本上是使用带宽是线性扩展的
最高能达到 13.1G/s
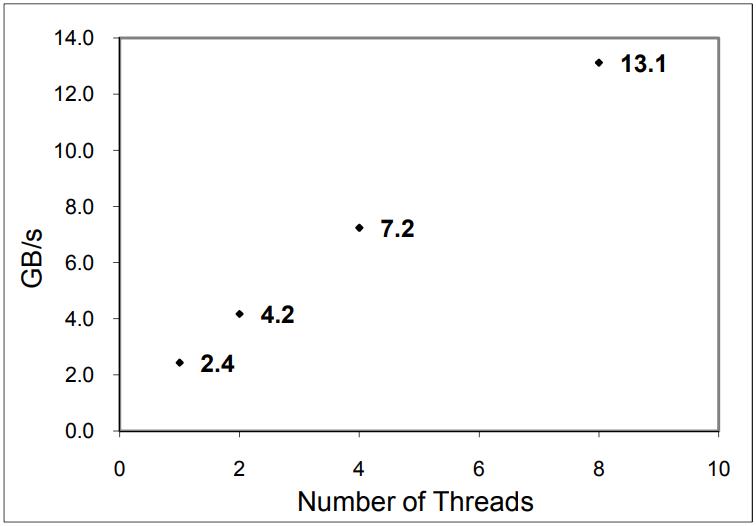
Figure 16. Scalability of vectorized full table scan
参考
相关文章
- Make the most out of your SIMD investments: counter control flow divergence in compiled query pipelines
- Accelerating Analytics with Dynamic In-Memory Expressions
- Materialization Strategies in the Vertica Analytic Database: Lessons Learned
- MonetDB/X100: Hyper-Pipelining Query Execution
- Access Path Selection in Main-Memory Optimized Data Systems Should I Scan or Should I Probe