Generating code for holistic query evaluation
原文
https://15721.courses.cs.cmu.edu/spring2023/papers/09-compilation/krikellas-icde2010.pdf
背景
传统的数据库都是基于磁盘的,所以查询处理算法的主要优化重点是 磁盘I/O
而现代数据库的内存都很大,可以将大量的数据,甚至全部数据都放到内存,于是查询优化的方向变了,从磁盘I/O转向内存
所以优化的目标就是如何最大化利用CPU和内存
而传统的迭代模型很清晰,但是CPU利用率较低,因为有频繁的函数调用
为了解决上述问题,论文提出了 代码生成技术,用来处理查询求值,这个技术叫:holistic query evaluation
它会整体的评估并优化然后生成一份源码,并由编译器主动优化生成最终的机器代码
这种技术可以适用于各种查询类型,而且可以更好的利用硬件特性
它的优点包括
- 查询求值期间,最大限度减少函数调用
- 增加了数据本地性,可以更好的将数据驻留在cache中
- 针对每个独立查询做单独的性能优化,可以使用额外的编译器优化技术
- 可以达到跟手写代码一样的效果
- 这种模型也很灵活,不会影响现有系统(如存储管理、并发管理等)
代码生成是通过魔板技术生成的,根据不同的查询类型,最终生成一份源代码
现代CPU是有很多流水线的,通过乱序执行能最大化并发度
通过各种L1、L2、L3缓存,就能低效寄存器和内存之间的延迟
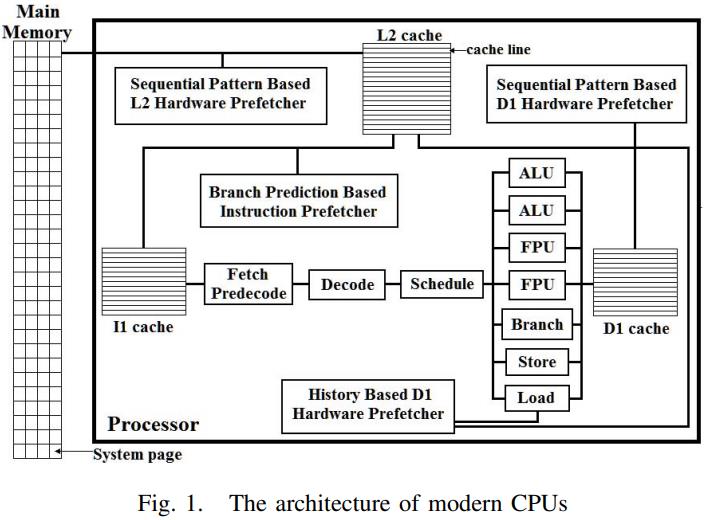
如上,现代CPU一般有L1、L2、L3三种cache
其中L1又包含数据cache、指令cache
为了最大化并行度,两种L1 cache还增加了预测模块,也就是基于分支的预测、以及基于顺序访问的预测,也测也就是预抓取
此外还包括了基于历史维度的预抓取
同样L2也包含了预测,也就是预抓取的功能
通过测试顺序、随机访问场景
- L1的数据指令都是3个CPU cycles
- L2的顺序是9个,随机是14个
- 内存访问顺序是28个,随机是77个
迭代模型的问题
- 获取一条数据至少两次函数调用,一次的请求,一次是返回
- 虚函数的调用进一步增加开销,需要频繁的更新CPU cache
- 维护数据也需要开销,数据从子节点获取然后父节点做更新,也会触发 cache miss
- 条件判断包生成了跳转指令,也不利于CPU并行化
- 以上这些都不利于CPU的prefetch
编译器优化
- 通过编译器技术,将源码转为更适合目标机器的机器代码
- 保持了指定的独立性,可以最大限度流水线化
- 优化变量->寄存器的分布,使的可以重用寄存器
- 对相同访问的数据分组,可以最大化cache本地性
相关场景
- 行存NSM对于查询分析并不好,改为列存DMS就更合适
- 但这样需要修改查询算法,改动挺大的
- 另一种方式是:Partition Attributes Across PAX,它的page按照行存,page内是列布局,这样更容易适配NSM、DSM
- 也有人对迭代模型做优化,增加buffer减少了函数调用次数,但是在函数体内的求值调用则去不掉
- MonetDB是最早该为列存的,基于物化方式将中间结果缓存了,之后又做了优化,改成向量化
- 于抓取也是一个研究领域,需要对CPU的频率、cache延迟、运行时负载来动态计算,但是评估错误的代价也不小
- IBM System-R是最早使用代码生成技术的,不过后来火山模型成为主流
实现
系统的整体架构
整体架构
- C++ 和GUN
- 存储模型是NSM但不是绑死的,PAX和SDM也支持,包含buffer pool、LRU、表管理、元数据管理、B+树等
- 查询解析目前只支持等值join、group、sort,子查询和聚合不支持,但不影响评估效果
- 解析完语法生成查询计划后,优化器会使用贪心算法,以最小化中间代码size为目标做优化;也会对每个算子做优化,生成代码
- 输出对算子列表 O,做拓扑排序,每个Oi 是一个表,或者是Oj的输出,也就是这个算子是一个scan算子,或者是其他算子的输出
- 代码版本组织顺序是 先处理join,然后是聚合、排序
- 最终生成一份代码
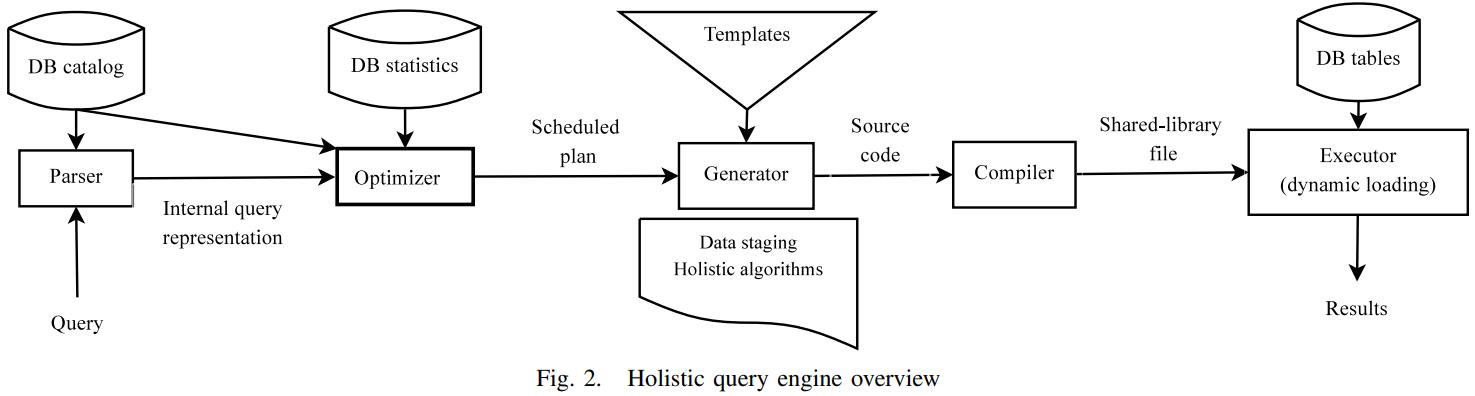 每个算子分成两步完成
每个算子分成两步完成
- 数据阶段,处理所有scan、选择谓词,过滤不需要的列,排序和分区需要预处理,跟scan代码是交织处理的,结果会被物化到磁盘/内存
- 整体算法,为每个算子生成代码,生成的是一份完整的代码
- 这段代码相当于一个函数,包含了每个算子的具体执行细节,然后查询引擎会调用这个函数
- 之后,代码生成器将所有生成的函数,插入到 一个新的 C源码中
- 编译器会编译这段代码,还会做一些激进的优化,然后产生动态链接库
- 查询引擎会加载这个动态库 并执行,并将结果重定向返回给客户端
实现
根据不同的查询计划,会调用到不同的模板,再产出不同的源代码
代码生成器 把优化器的输出,作为输入,之后产生 针对特定查询的 C源代码

代码生成器会将模板中的参数补填上,这些参数信息包括:谓词的数据类型、算子的输入、主表/中间结果、输出schema
之后产生join、聚合、sort
每个输入表执行对应的生成函数,最后会有一个main函数,来调用所有这些函数
所有生成的函数会被放到一个新的 C源文件中(按照他们生成的顺序)
生成的目标代码
- 确保输入数据能放到L1的数据cache、或者L2中
- 最大化重用缓存数据
- 尽量将随机访问限制到L1数据cache中
下面这段代码,就是将scan和filter整合到一起了,这样就减少了函数调用
而短小的inner loop逻辑让编译器可以进一步优化

Input staging
- 包括sort、partition、以及hybrid方式(一种优化的quick-sort),适用于L2
- 分区可以是细粒度的(value到分区),或者粗粒度的(hash、取模)
- 目标是将输入数据映射到合适的L2-cache中
Join evaluation
使用的是 nested-loop join方式
join之前先将输入数据做排序,其实应该是 merge join + nested-loop

另一种是 partition join,他是以 Grace hash join为基础的
所有的输入数据都被适当的排序、分区,以适应cache大小,然后读page,在page上生成循环
之后再遍历所有tuple,这样就是顺序操作,保持所有操作都在流水线中,有cache本地性
Aggregation
依赖输入数据的排序,排序完之后就可以线遍历,然后做分组
也可以用 hybrid hash-sort 方式
也就是先分区,再对分区内的数据做排序,可以保证数据足够小,能放入cache中

代码生成面临的问题
- 模板是通用的,所有的交互都是一个接口
- 如何根据不同的操作,找到合适的模板
- 生成代码的正确性如何严重
生成的不同阶段之间,通过物化方式交互
阶段1 的结果物化后,阶段2将其作为输入
评估
包含这几个方面
- 生成代码 对比传统迭代模式的 好处
- 编译器优化对代码生成代码的影响
- 和其他商业、学术产品的对比
- 运行期间 生成代码、编译、链接的消耗
table-1 是测试使用的CPU和内存环境
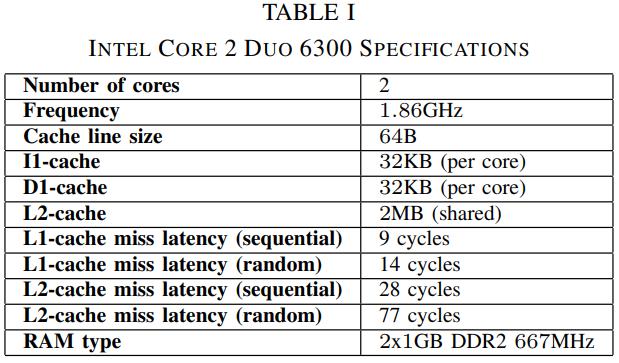
cache 延迟测量工具使用的是:RightMark Memory Analyser
OProfile性能测试工具,可以测试cache miss,
Iterators versus holistic code
迭代、迭代+inline优化、手写、手写优化、代码生成的比较
code-gen消除了停顿时间,减少了几乎2/3多的指令调用,减少2/3的数据访问,函数调用只有迭代的 1% Figure 5(c)
Query-2 是两个大表,选择率很低,所以花在输入上的时间就很多了,几个版本都是使用了相同的算法,所以时间看起来都比较类似
code-gen差不多是迭代的2倍
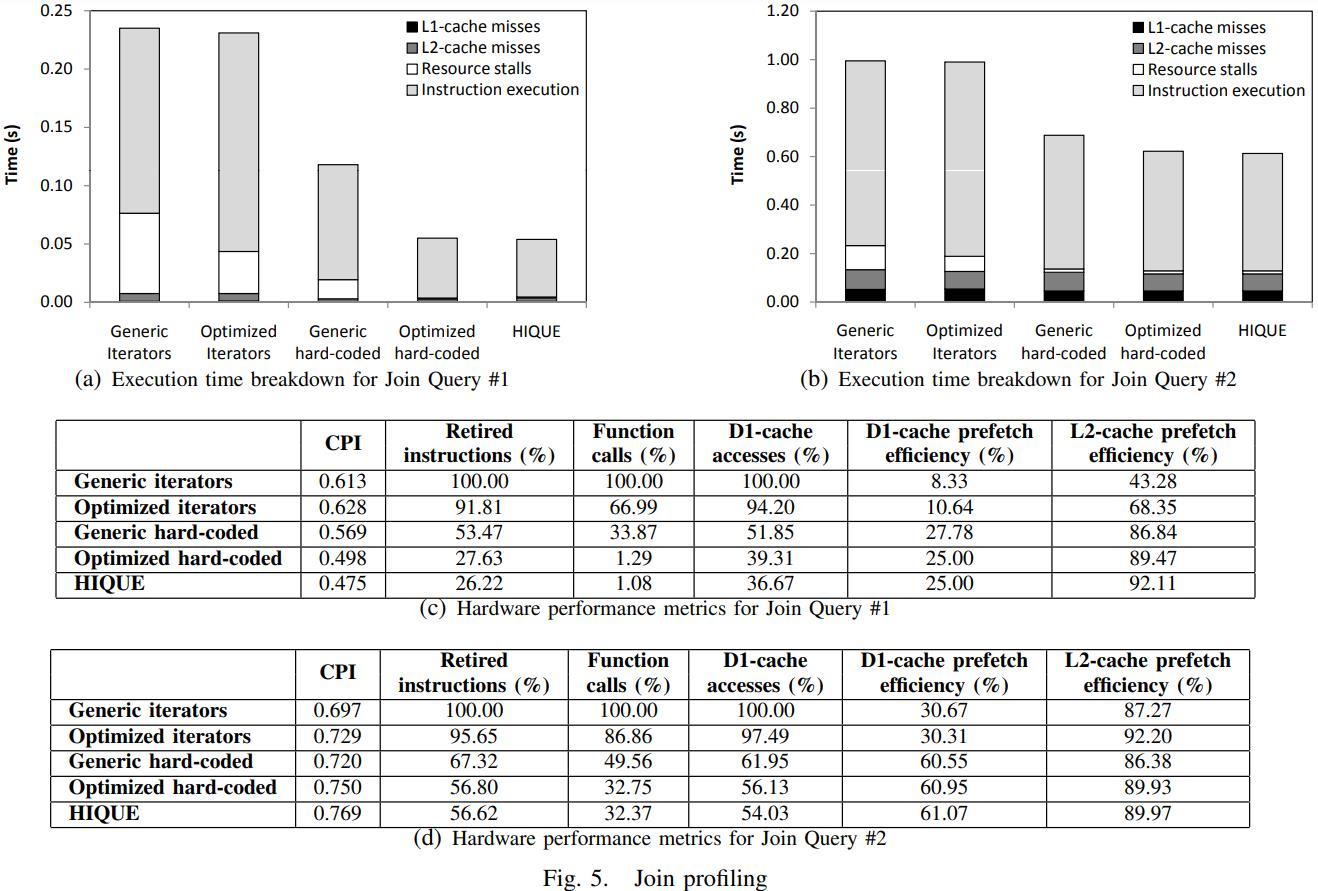
下面是聚合的比较,code-gen是迭代的 1.6倍,主要是减少了调用,数据访问,和函数调用
figure-6(c)显示 D1-cache预抓取相比迭代 增加了3倍时间
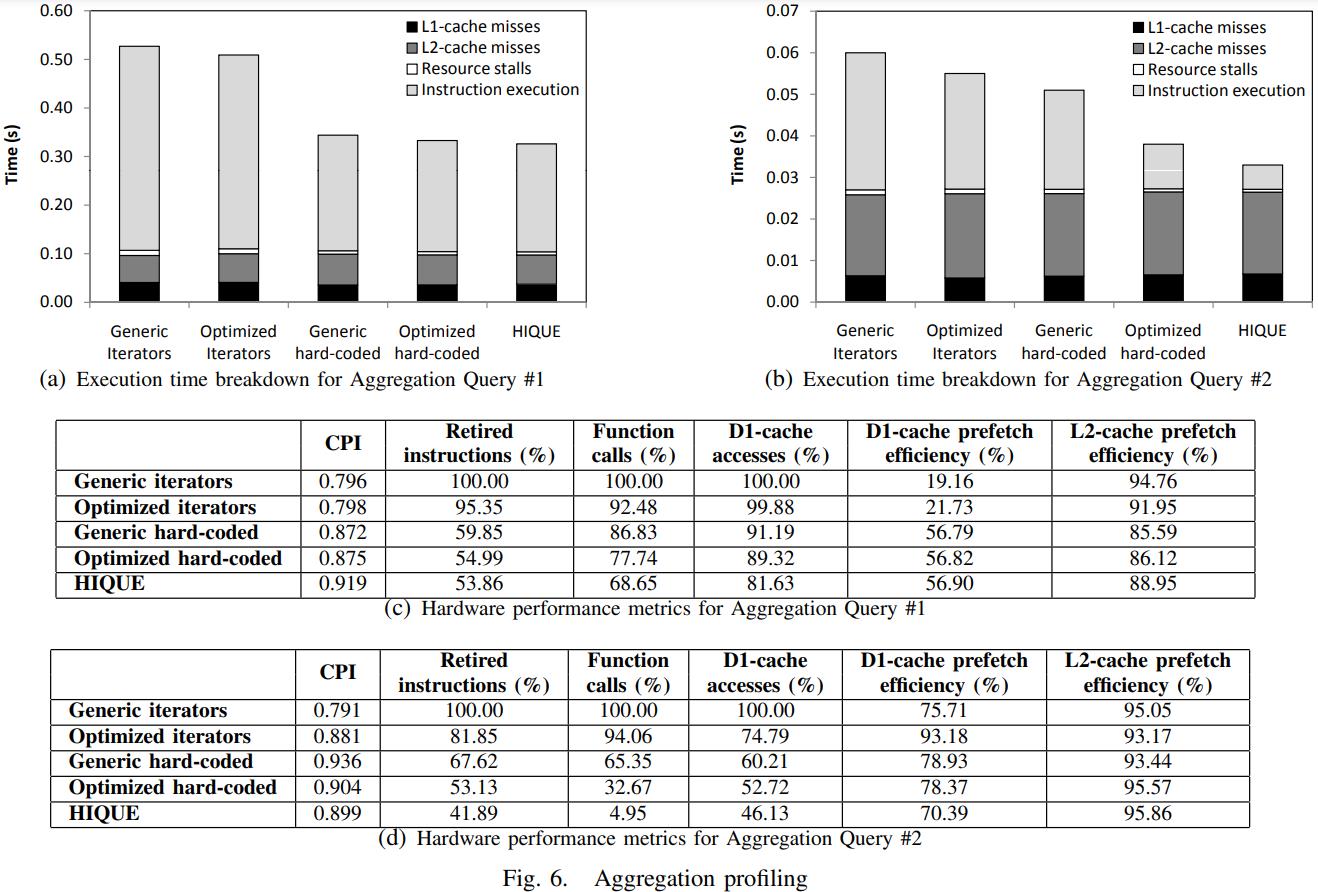
下面是对比编译器优化的效果
join的两个查询,聚合的两个查询,分别用 -O0 和-O2选项
手写代码优化效果就没有迭代那么明显了,因为手写的代码已经比较优了
Performance of holistic algorithms
下面比较输入数据的各种变化
figure7(a)显示merge join、以及hybrid版本,基本上hybrid版本的HIQUE是最好的
figure-7(c)显示,随着选择率的增加,迭代模型的性能下降非常多
figure-7(d)是聚合,在小数量场景下 hash表现的最好,但随着数据增大就不行了
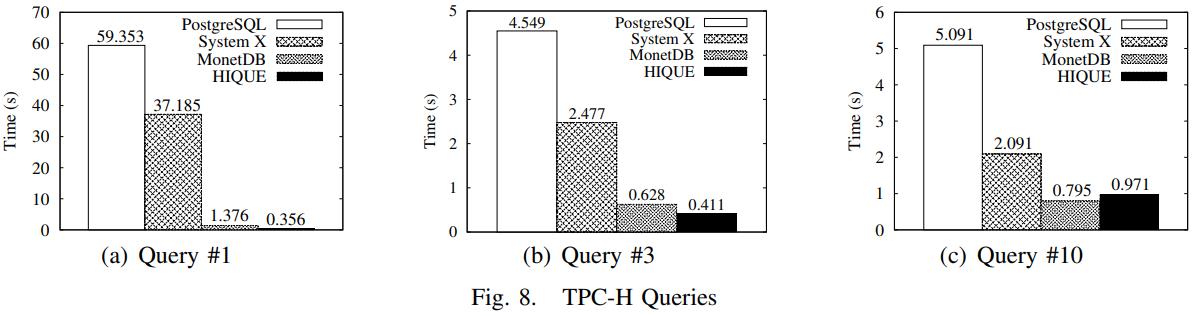
TPC-H benchmark
对比了三种数据库
- PostgreSQL 8,那时候用的还是火山模型,代表传统I/O数据库
- System X,不知道是啥商业数据库,使用了软件预抓取,混合I/O和CPU
- MonetDB,使用DSM,面向主内存的
由于使用了列存,MonetDB在分析场景下比其他两个数据库更好
HIQE相比PG有167倍的提升
而通过上述优化,使的NSM系统能在分析场景下达到 DSM系统的性能
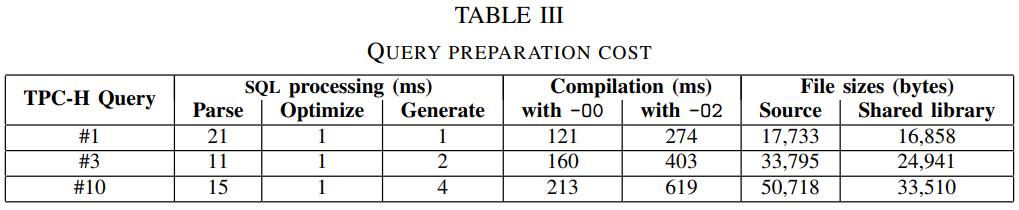
Code generation cost
code-gen的问题是需要编译代码,还包括编译器优化,以及生成动态库,并将动态库导入
下图中可以看到,解析SQL、优化的时间并不长,编译的时间是比较长的
而生成的C 源码数量也很大,1W多 - 5W多行,大小都是小于 50Kb
对于小查询来说,编译时间就太长了,这需要关闭编译器优化
参考
- 内存延迟检查工具:RightMark Memory Analyser
- Linux内核性能分析工具:OProfile
相关文章
- Implementing Database Operations Using SIMD Instructions
- Rethinking SIMD Vectorization for In-Memory Databases
- SIMD-Scan: Ultra Fast in-Memory Table Scan using onChip Vector Processing Units
- Make the most out of your SIMD investments: counter control flow divergence in compiled query pipelines
- Accelerating Analytics with Dynamic In-Memory Expressions