BigTable论文
原文
Bigtable: A Distributed Storage System for Structured Data
背景
BigTable是一个分布式存储系统,用于管理结构化数据,可以运行在几千台机器上,存储数据达几PB
谷歌内部的:谷歌地球、谷歌金融、web索引都在跑在BigTable之上的
这些服务所需要的数据大小、要求差别都很大,目前运行都很好
BigTable提供了高性能、灵活的解决方案
BigTable有这几个目标
- 适用各种场景
- 扩展性
- 高性能
其他特点
- 目前用于谷歌大概60个产品和项目,包括金融、搜索、谷歌地球等
- 从面向吞吐的批处理job、到低延迟的用户应用
- BigTable使用内存来实现可扩展和高性能,跟关系型数据库有些类型,但也有很大不同
- 不支持完整的关系型数据模型,只为客户提供了一个简单的模型,支持数据布局和格式的动态调整
- 允许用户推断底层存储的数据和位置属性
- 索引使用row,而列名可以是任意字符串,客户可以序列化各种结构、半结构数据转为字符串
- 客户也选择是从内存中提取数据,还是从磁盘提取数据
数据模型
概述
- BitTable是一个稀疏的、分布式的、多维度持久化的排序map
- map由row key、column key、timestamp建立索引
- 每个value都是未解释的字节数组
- (row:string, column:string, time:int64) → string
- 我们尝试了各种方案最终确定了这个模型
- 需要保存被不同项目使用的大量网页和相关信息的copy,假设叫他为 web-table
- 在web-table中使用URL作为row key,将网页的特种特点保存在 column name中
- 将网页内存存储在 contents:clumn 中,并有时间戳概念
- figure1 的这种模型 反转的URL相当于主键
- 有两个列,一个是 content,用于存储内容
- 另一个是 anchor,这是一个列簇,anchor:cnnsi.com 表示 cnnsi.com 指向cnn
- anchor:my.look.ca 表示 my.look.ca指向 CNN.com
- contents有三个版本, anchor有一个版本
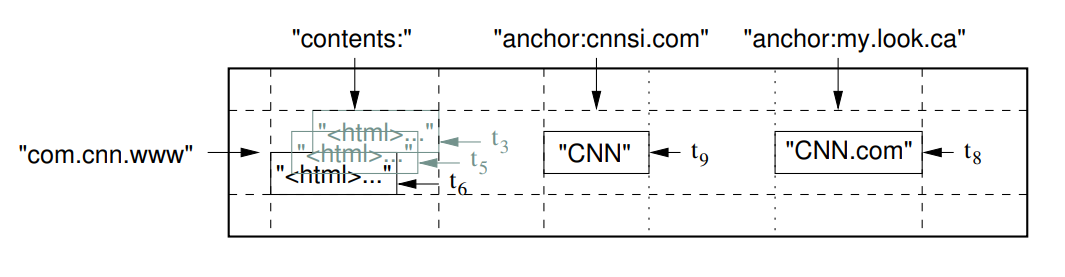
Figure 1: A slice of an example table that stores Web pages. The row name is a reversed URL. The contents column family contains
the page contents, and the anchor column family contains the text of any anchors that reference the page. CNN’s home page
is referenced by both the Sports Illustrated and the MY-look home pages, so the row contains columns named anchor:cnnsi.com
and anchor:my.look.ca. Each anchor cell has one version; the contents column has three versions, at timestamps t3, t5, and t6.
行
- 可以是任意的stirng内容,最大为64K,大部分用户的key为10-100字节
- 读写单行内容是原子的
- BigTable的数据是按字典排序的,一段范围的row key组成了tablet,它是分发和重平衡的最小单位
- 读取一段范围的数据只需要跟少数机器通讯
- 客户端可以利用这个特性来分布他们的rowkey,比如将URL做倒排序
- map.google.com/index.html变成了 com.google.maps/index.html,相同域名下的网页存储在一起使得查询分析更高效
列簇
- 列簇是将一系列的列分组在一起,并存储在一起,通过他们类型相同
- 数据在存储之前,必须先创建列簇
- 列簇最多只能有几百个,但列的数量不限制
- 语法是 family:qualifier,列簇的名字必须是可打印的string,而qualifier可以是任意字符串
- 列簇的一个例子是网页的语言,另一个是anchor,表示哪些网页指向 x
- 访问控制和磁盘、内存都是在列簇这个级别执行的
- 允许我们管理不同类型的应用程序,一些添加基本数据、一些读取数据并创建衍生的列簇、一些是只读(甚至没有查看其他列簇的权限)
Timestamp
- BigTable中的每个cell 包含相同数据的多个版本
- 每个版本都是64bit的整数
- 时间戳可以由BigTalbe分配,这样就代表了真实的时间;也可以由用户指定
- 用于指定的时间版本必须保证唯一性
- 时间按照降序排列,这样最近的就是最新的版本
- 为使版本管理的数据尽可能少,BigTable支持自动垃圾收集
- 客户端可以指定最近n个版本,或者只保留足够新的版本(如最近7天的)
- 在webtable例子中,将爬虫存储的网页保存在contents列中,设置3个版本,页面是实际被抓取的时间
- 这样垃圾收集机制就允许我们只保存每个页面的三个最新版本
API
BigTable API 提供如下:
- 创建、删除表列簇的函数
- 改变集群、表、列簇元数据的函数
- 客户端可以在BigTable之上写、删除数据,查找数据,以及迭代数据
- figure2 展示了一系列变更操作,增加一个 anchor 到 www.cnn.com,以及删除另一个 anchor
- figure3 展示了在特定row上迭代所有的anchors,也可以限制行、列、时间戳的范围
- 如限制只产生 anchor:*.cnn.com 或者时间戳低于当前时间10天的数据
- 支持原子的 读-修改-写 这样的事务处理,但只对但行有效,目前还不支持多行事务
- 允许将单元格用作整数计数器
- 支持在线服务器的地址空间中执行客户端脚本,脚本语言是用 Sawzall 写的
- 支持map/reduce,map/reduce的输入端、输出端都可以是BigTable
Figure 2: Writing to Bigtable
|
|
Figure 3: Reading from Bigtable.
|
|
构建块
BigTable是在其他几个谷歌产品之上构建的
- 底层是基于GFS的,BigTable集群在一个共享的机器池中运行,执行各种分布式应用
- 也依赖一个集群调度系统,基于共享的机器之上去调度job、管理资源,处理机器失败、监控机器状态等
- BigTable内部使用 SSTable来存储数据,它是一个不可变map,key/value都是任意字符串
- SSTable按64K划分每个块,块索引存储在SSTable末尾,用于定位其他数据块
- 当SSTable被打开时,这个索引就被加载到内存,用于seek磁盘,通过二分查找去找到合适的块并读取
- SSTable也可以完全加载到内存,这样就没有I/O了
BigTable还需要依赖高可用以及持久化的分布式锁服务
- Chubby分布式锁,由5个活跃部分组成
- 使用Paxos算法来实现容错,当前只有一个节点被选举为master
- 当大多数节点都在运行,并可以相互通信时,整个服务就是可用的
- Chubby提供了类似UNIX的名称空间方式,文件和目录都可以加锁,读写文件是原子的
- 客户端维护一个session,并缓存它,直到会话过期了
- 也支持回调函数,当目录更改或者会话过期就会触发回调函数
BigTable使用Chubby实现各种功能:
- 确保任何时候最多只有 1个master
- 存储bootstrap数据的位置
- 发现tablet服务,确认tablet宕机
- 存储schema信息,每个表的列簇信息
- 存储访问控制列表
- 14个BigTable集群共享11个Chubby实例
- 由Chubby不可用导致BigTable不可用的平均小时数 0.0047%,最大为0.0326%
return Math.max(Math.min(dfs(dungeon, m, n, i + 1, j), dfs(dungeon, m, n, i, j + 1)) - dungeon[i][j], 1)
实现
BigTable包含三个组件
- 客户端
- 一个master,检测tablet状态、平衡tablet服务、回收GFS上的数据,用处schema变更
- 多个tablet服务,可以动态的删除、增加
tablet服务管理一系列tablet,范围可以是10-1000个
客户端不依赖master获取tablet位置,所以大多数客户端不与master通讯
初始时table只有一个 tablet,随着数据增长,会动态的分割tablet
表定位
- 使用类似B+树那样的三级存储结构
- root表的位置存储在 chubby中,root表只有一个不会分片,存储metadata表的位置
- metadata表存储用户表的位置,row-key的开始和结束范围
- 每个metadata表的row大概为1K
- 三级存储结构大约可以存储 2^34 个tablet,2^61数据,差不多是 2EB的数据量
- metadata 表中还存储了诊断信息,如tablet的事件日志,启动时间等,可以用于调试
- 客户端会缓存位置信息,如果缓存是空的那么需要 三次网络I/O,还有查找chubby的一次
- 如果缓存失效了,那么最多会查找6次
- 查找的方式是递归的往上找,用户表缓存 -> meta-data缓存 -> root缓存
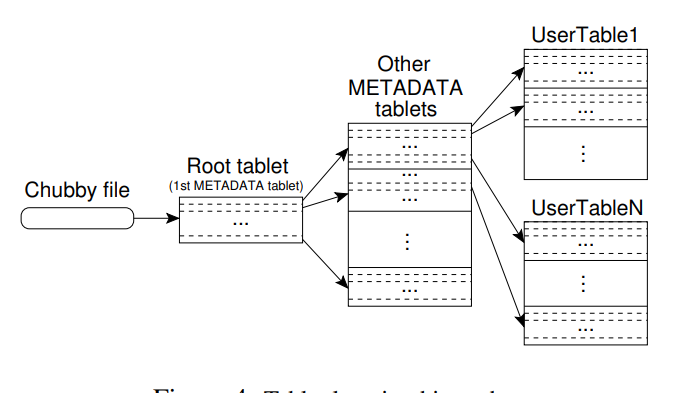
Figure 4: Tablet location hierarchy.
表的分配
- master会将每个tablet分配给 tablet-server
- master会跟踪每个tablet的分配情况
- 如果某个tablet没有被分配,master就将其分配给有足够资源的tablet-server
- 当一个tablet-server启动时,会在Chubby的分布式锁上注册一个排斥锁(文件目录结构)
- master会实时监听这个目录,从而能发现tablet-server
- 如果发生网络分区,tablet-server无法获取排斥锁,会将自己stop掉
- 只要文件还在,tablet-server就会尝试获取锁,如果文件不在了,则获取失败
- 当tablet-server从集群中移除时,会释放这个锁,之后master就会检测到并重新分配tablet给这个服务器
tablet服务
压缩