LevelDB 公开的接口
概览
LevelDB总体模块架构主要包括
- 接口API(DB API与POSIX API)
- Utility公用基础类,如内存管理Arena、布隆过滤器、缓存、CRC校验、哈希表、测试框架等
- LSM树(Log、MemTable、SSTable)3个部分
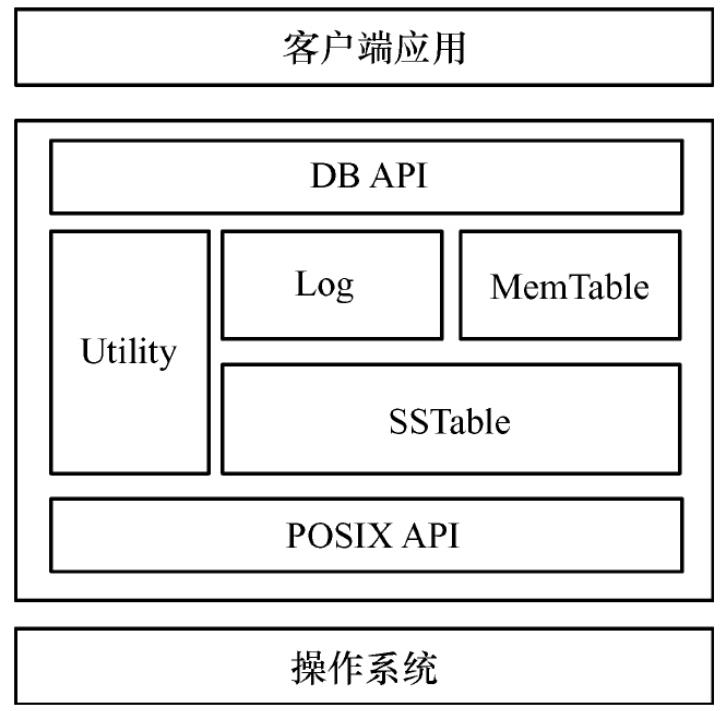
主要接口之间的关系
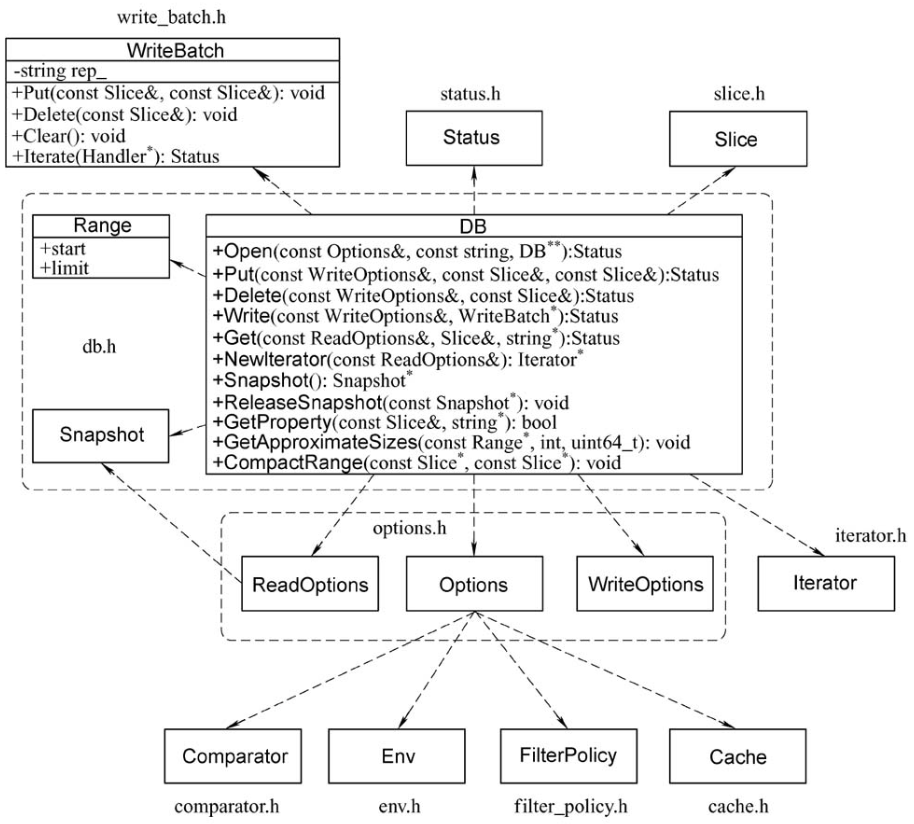
主要接口
c.h
- 兼容 c 的api
- 包括 close、put、delete、write、get、迭代操作、snapshot、approximate_sizes、compact_range
- 以及一系列的 options、还有 comparator、filter、读写策略、cache、env
cache
- 拷贝构造、= 重载 都是delete
- 包括 insert、lookup、release、value、erase、newId、prune(删除所有缓存)
- 以及total-charge操作
Comparator
- 用于比较 Slices对象,全局有序比较,用于 sstable、数据库级别
- 需要保证线程安全,多个线程会同时调用
- 每个比较器都有一个唯一的名字,用来检查比较器是否匹配
- 一些高级操作,如返回
[start, limit)中的短字符 - 找到短字符串的后继
- 默认的比较是按字节一位一位比较的
|
|
DB
- 包括 Options、ReadOptions、WriteOptions、WriteBatch 四个结构体
- Snapshot(不可变的对象)、Range
- DB是一个持久的有序map,并且是多线程安全的
- 包括put、delete、write、get、迭代器
- 快照、释放快照、属性、获取近似size、范围比较
- 销毁DB、修复DB
dumpfile
- 将指定的文件,以文本形式 dump 到 dst* WritableFile中
filter_policy
- DB::Get()的时候,可以使用 filter策略做过滤,降低 读放大
- CreateFilter、KeyMayMatch等重要接口
- 默认实现为 BloomFilterPolicy
iterator
- 获取元素的迭代器
- 支持向前、向后、获取key、value等操作
options
- create_if_missing、error_if_exists、paranoid_checks
- info_log、write_buffer_size、max_open_files
- block_cache(为null自动创建8M缓存)
- block_size、block_restart_interval、max_file_size
- 以及 ReadOptions、WriteOptions
Slice
- 对外部string类型的简单包装
- 有一个指针,指向外部string,以及对应的长度
- 各种操作只是操作指向,所以非常轻量
Status
- 函数包括:OK、NotFound、Corruption、NotSupported、InvalidArgument、IOError
- static Status IOError(const Slice& msg, const Slice& msg2 = Slice())
TableBuilder
- 用于提供一个接口,来创建表
- 所有的const函数不用同步,非const需要额外的同步
Table
- 不可变的,持久的,有序的map[string, string]
- NewIterator、ApproximateOffsetOf
- 私有的:BlockReader、InternalGet、ReadMeta、ReadFilter
write_batch
- 支持函数包括:Put、Delete、Clear
- ApproximateSize、Append、Iterate
环境和移植相关接口
env
env.h 内部包含了这么一些类
|
|
这些都是跟具体 操作系统相关的
env.h 中就包含了创建上述几个类的函数(除 Slice)
env.h 中包含了很多类似这样的定义,这里是创建一个 Logger的实现
- 如果创建成功,Status为空,Logger** 指针 指向实现对象
- 如果创建失败,Logger** 指向空,Status包含具体的错误信息和状态码
|
|
env.h 中包含了一个 EnvWrapper类,对所有的函数做一个包装,指向其代理的真正 Env 的实现类
|
|
port.h 中包含了不同操作系统之间的接口抽象
LevelDB为支持多种操作系统,方便的跨平台,LevelDB提供了一些依赖 操作系统的最小接口
通过宏定义,然后自定义实现新的操作系统接口支持,就可以跨平台了
包括
- 系统相关的大头派、小头派
- mutex 锁、convar 条件变量、AtomicPointer 原子读写屏障
- AtomicPointer 在 C++ 中有 std实现,这个类就没用了,直接用 标准库实现即可
- Snappy的跨平台封装
- 其他如,GetHeapProfile 堆内存快照
- 加速 CRC的 AcceleratedCRC32C
平台的具体实现放在了
- util/env_posix.cc
- util/env_windows.cc
在env_posix.cc中定义了
- unix 环境的 读、写文件、lock文件、创建Log、检查文件、创建文件等
- 其中读操作,包括顺序读接口、随机读接口,对应的随机读有 posix实现,以及使用
mmap的实现 - 线程相关的创建,这里使用了 std::thread,以及线程同步相关操作
- 还定义了 Limit 相关操作,避免 LevelDB把资源全部占用
不同平台的 内存屏障实现
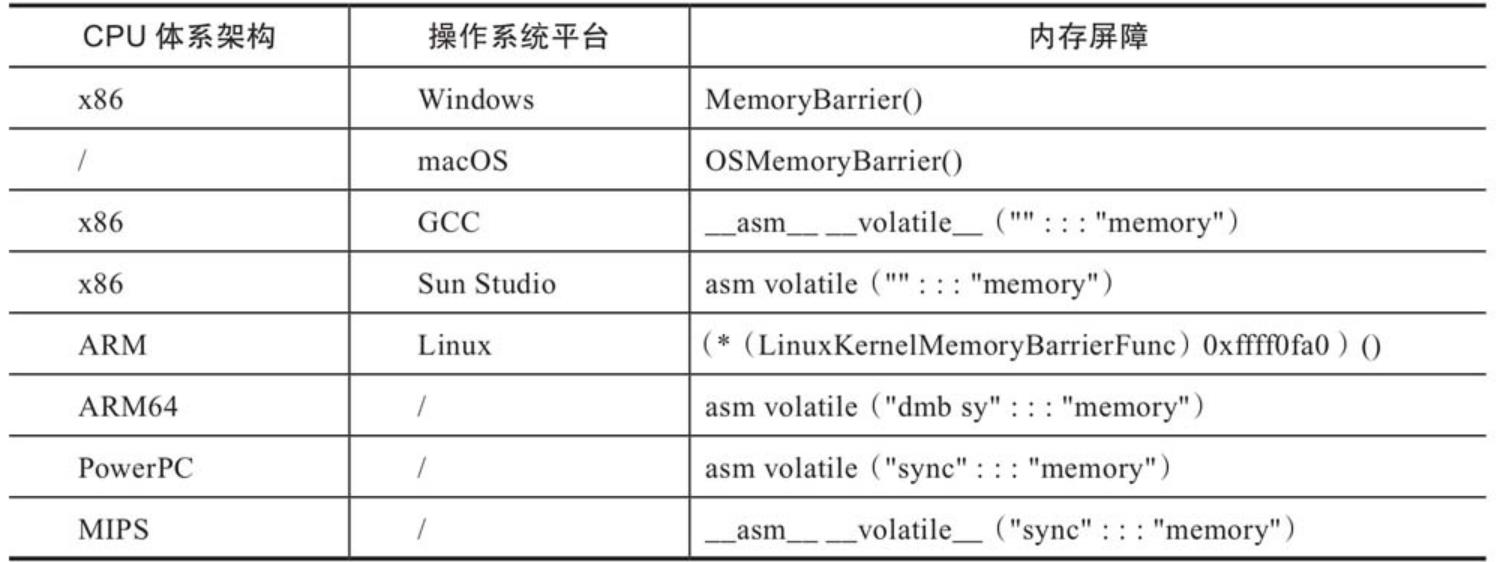
实现相关的函数,env_posix.cc 中的:
- NowMicros
- SleepForMicroseconds
env.h 还有一个基于 in-memory的实现,是调用memenv.cc完成的
其内部保存了std::vector<char*> blocks_ GUARDED_BY(blocks_mutex_);
其内部保存了std::vector<char*> blocks_ GUARDED_BY(blocks_mutex_);
读写流程
open
对应的实现为 /db/db_impl.cc 的函数:Status DB::Open(const Options& options, const std::string& dbname, DB** dbptr)
- 初始化一个DBImpl的对象impl,将相关的参数选项options与数据库名称dbname作为构造函数的参数
- 调用DBImpl对象的Recover函数,尝试恢复之前存在的数据库文件数据
- 进行Recover操作后,判断impl对象中的MemTable对象指针mem_是否为空,如果为空,则进入 4,不为空则进入 5
- 创建新的Log文件以及对应的MemTable对象。这一步主要分别实例化log::Writer和MemTable两个对象,并赋值给impl中对应的成员变量,后续通过impl中的成员变量操作Log文件和MemTable
- 判断是否需要保存Manifest相关信息,如果需要,则保存相关信息;如果不需要,则跳到 6
- 判断前面步骤是否都成功了,如果成功,则调用DeleteObsoleteFiles函数对一些过时文件进行删除,且调用MaybeScheduleCompaction函数尝试进行数据文件的Compaction操作
Get
函数:Status DBImpl::Get(const ReadOptions& options, const Slice& key, std::string* value)
- 首先获取SequenceNumber,从options中获取,为空则使用VersionSet#LastSequence()
- SequenceNumber的主要作用是对DB的整个存储空间进行时间刻度上的序列备份
- 即要从DB中获取某一个数据,不仅需要其对应的键key,而且需要其对应的时间序列号
- 创建LookupKey,然后从 MemTable、ImmutMemTable、SSTable中获取
- 判断是否需要压缩
写操作
包括 put、delete、write
所有写操作都会封装成一个批量写,然后调用 write
Write里面还封装了是否同步,条件变量等
|
|
具体流程
- 创建 Writer 对象,并插入队列中
- 线程wait,等待队列中前面的任务完成
- 预先分配相应的内存空间
- 写入Log文件
- 更新 MemTable
- 更新 SequenceNumber
- 发送 singnal信号,唤醒其他线程
快照
调用 db->GetSnapshot() 获取当前数据库的一个快照备份
修改和读取的是快照,不会破坏当前数据
快照创建的是一个备份记录的 序列号
|
|
SequenceNumber 是 uint64_t 类型
创建和删除快照,实际操作的是 这个 双链表
读取数据的时候,除了用户 Key,还需要 SequenceNumber,这个序列号来自 options,或者当前最新的序列号
参考
- github index
- Bloom Filters by Example
- 漫谈 LevelDB 数据结构(一):跳表(Skip List)
- 漫谈 LevelDB 数据结构(二):布隆过滤器(Bloom Filter)
- 漫谈 LevelDB 数据结构(三):LRU 缓存( LRUCache)
- LevelDB源码剖析
- SF-Zhou’s Blog
- leveldb-handbook
- 庖丁解LevelDB
- rust使用
- LevelDB使用介绍
- LeveLDB维基百科
- dbdb.io的LevelDB介绍
- MariaDB的插件
- 书籍:精通LevelDB
- leveldb 实现解析
- POSIX™ 1003.1 Frequently Asked Questions (FAQ Version 1.18)
- Spurious wakeup
- Memory barrier
- Memory Barriers: a Hardware View for Software Hackers
- Bean Li的LevelDB文章汇总