MillWheel
论文:
MillWheel: Fault-Tolerant Stream Processing at Internet Scale
INTRODUCTION
MillWheel是谷歌搞的一套分布式、低延迟的数据处理框架
- 支持各种数据模型
- 天生支持容错
- 低延迟
- 可以做到精确一次
其他的如
- Spark Streaming、Sonora限制了用户代码能力
- S4 不提供完全容错的持久状态
- Strom提供精确一次
- Trident 限制了事务操作的顺序
谷歌内部有这个需求:需要统计热点趋势信息,比如电视收视率情况
这需要根据查询构建出历史信息,而且新来的数据需要存储下来,为以后的查询使用
查询可以反映出波峰和低谷的,如果统计出有异常,需要报告给其他系统并发出通知
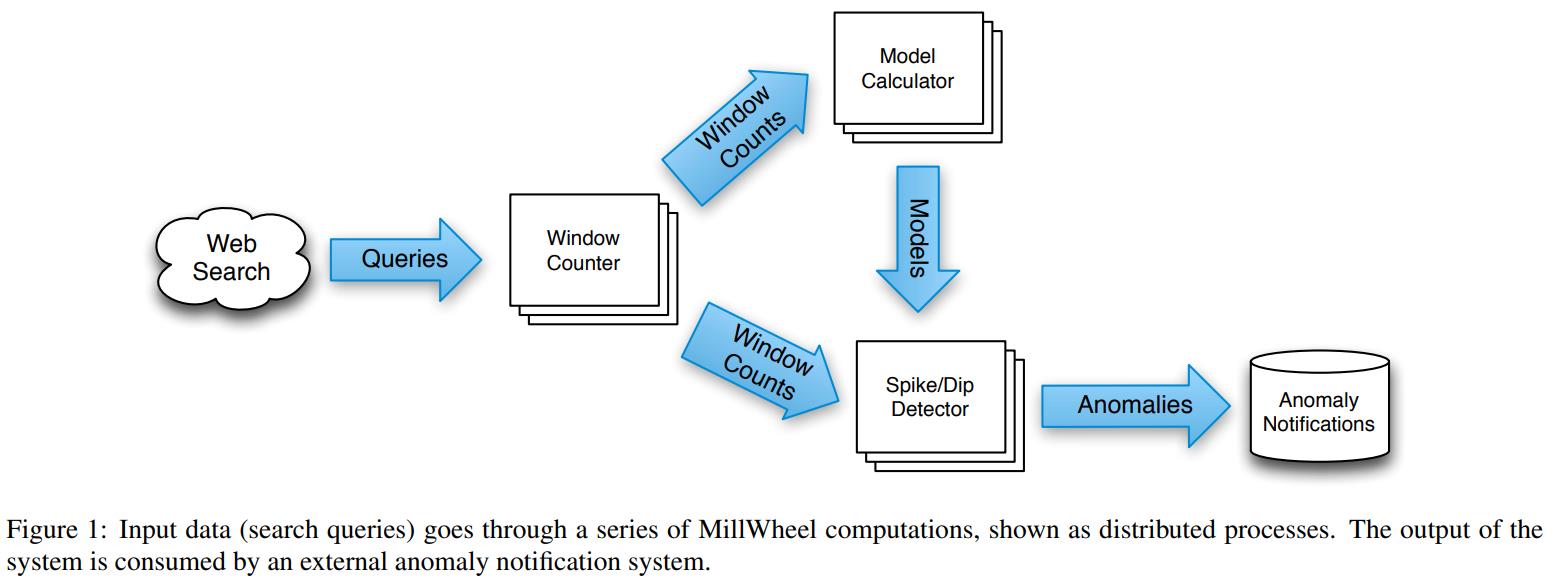
MillWheel需要实现如下逻辑
- 当数据可用时,需要立刻被发布出去
- 需要提供持久状态,并整合到系统的一致性模型中
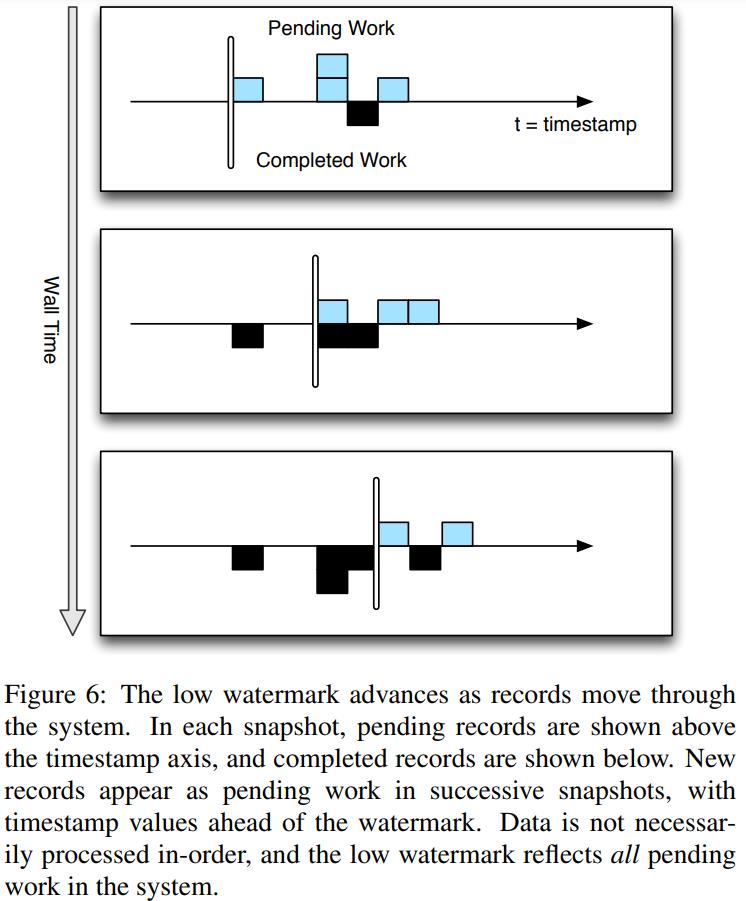
- 要能处理乱序数据
- 系统能根据一个单调递增的低水印时间戳来计算
- 当增加更多机器时,延迟应该继续保持常数不变
- 系统能提供精确一次的记录交付
SYSTEM OVERVIEW
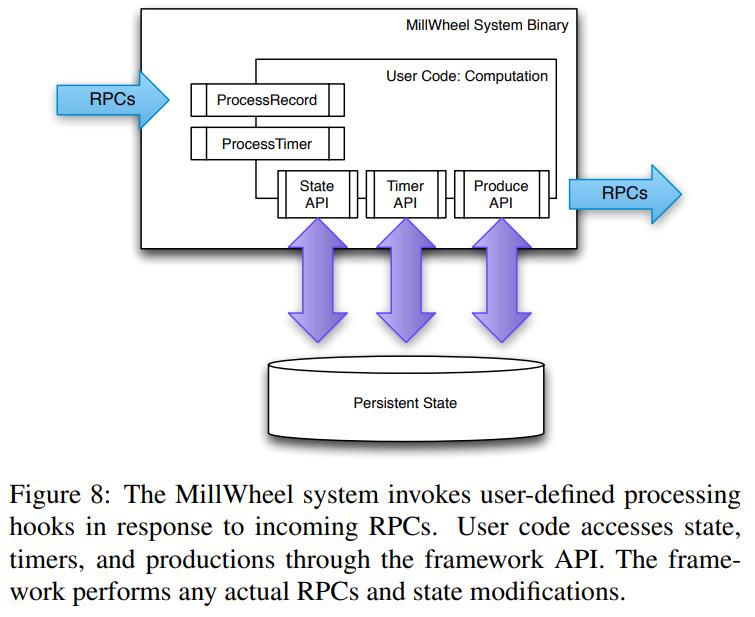
从一个高层的角度看,MillWheel就是 基于输入数据的用户定义的转换图
这里会自动搞定底层的那些事情,而用户无需关系
输入和输出表示为:(key, value, timestamp) 三元组
- key是系统内部的元数据字段
- value表示真实数据的字节数组,可以是任何的值
- timestamp是用户设置的任意值,一般为墙上时钟
MillWheel 根据这些值来计算 低水印
比如,用户想聚合搜索词的每秒计数,他们可能希望在执行搜索时分配一个对应的时间戳
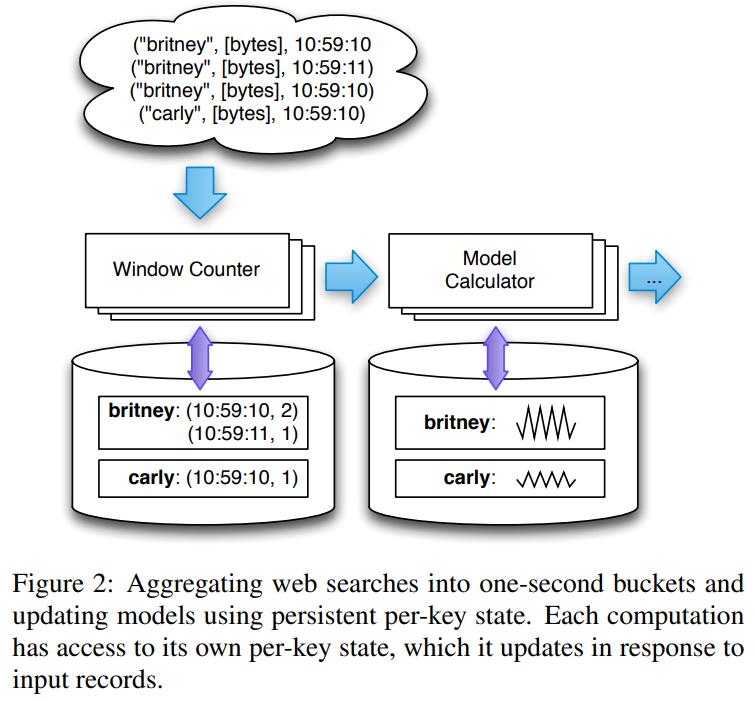
概念
- 用户的计算会形成一个 计算流图、
- 用户可以随意添加、删除计算逻辑,不用重启系统
- 每条数据的处理是冥等的
- 所有的记录都保证精确处理一次
CORE CONCEPTS
用户可以定义他们自己的逻辑,对应到MillWhell中,就是一堆输入、输出,对应的是有向图中的边
|
|
Figure 3: Definition of a single node in a MillWheel topology. Input streams and output streams correspond to directed edges in the graph
计算
- 用户的逻辑被封装到计算中,当有输入数据时,就会触发到用户逻辑
- 用户逻辑可以是任意代码,包括连接外部系统、管理MillWhell、输出数据
- 连接外部系统时,需要由用户自己保证冥等性
- 处理key是串行执行的,但是多个key可以并行执行
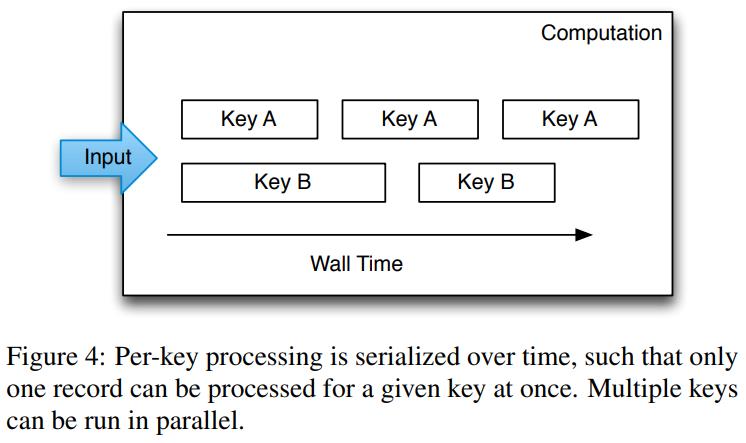
key
- 主要是用来比较两条记录,以及做聚合使用的
- 消费者会指定一个key来提取这些记录
- 计算逻辑只处理跟key相关的上下文
- 比如可以用cookie作为指纹当做key来计算是否为垃圾邮件
- 多个计算逻辑,可以从相同的流上提取不同的key,而key是被流的消费者指定
streams
- MillWhell中不同计算之间的传递机制
- 一个计算可以订阅0 到多个输入流,并产生1 到多个输出流
- 每个消费者在每各流上,基于指定的key来消费
- 所以多个消费者可以订阅相同的流,然后以不同的方式处理(聚合)这些数据
- 流是由他们的名字做唯一识别的
persistent state
- 最基本的格式,是一个不透明的byte string,基于每个key管理
- 用户提供序列化/反序列化方式,如Protocol Buffers,将其转为基本格式
- 持久化状态则由底层的分布式高可用存储来保证,如BigTable、Spanner,其确保数据完整性的保证对终端用户完全透明
- 状态一般包括: 在记录窗口之上的聚合统计,join的buffer数据等
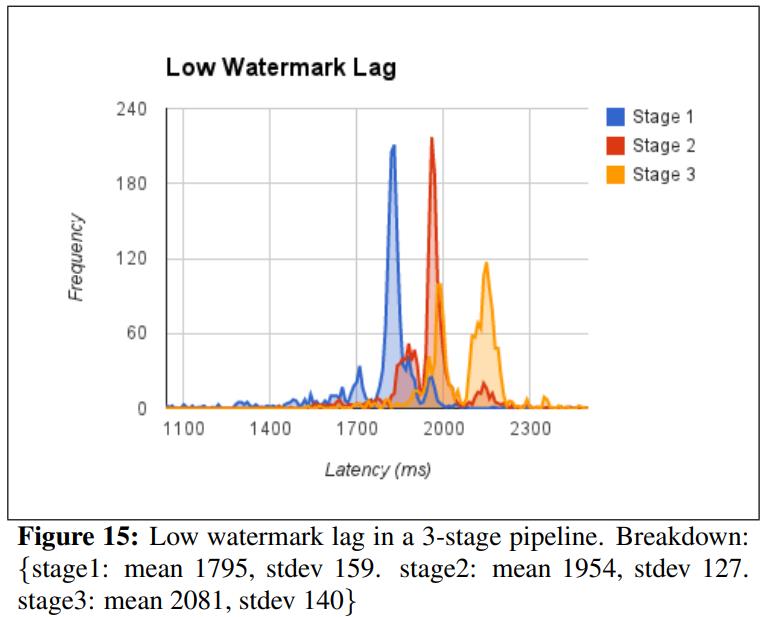
其他图片