LevelDB Mulit vesion and compaction
文件类型:
|
|
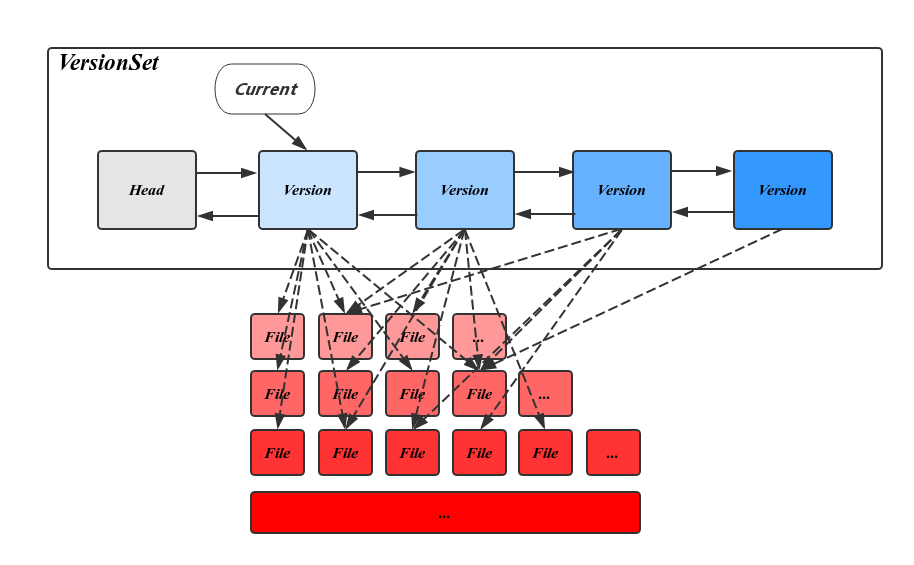
多版本
版本管理中相关的类
- Version标识了一个版本,主要信息是这个版本包含的SSTable信息;
- VersionSet是一个版本集,里面保存了Version的一个双链表,其中有一个Version是当前版本,因为只有一个实例,还保存了其它的一些全局的元数据,Dummy Version是链表头;
- VersionEdit保存了要对Version做的修改,在一个Version上应用一个VersionEdit,可以生成一个新的Version;
- Builder是一个帮助类,帮助Version上应用VersionEdit,生成新版本
VersionSet 是一个双链表结构,每个 Version 代表了一个版本
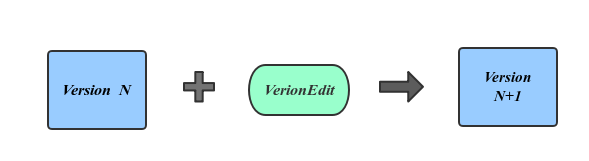
将当前的 版本 和 VersionEdit 合并之后,就得到了一个新的版本
VersionEdit就是一次 Minor Compaction、或者是 Major Compaction的结果
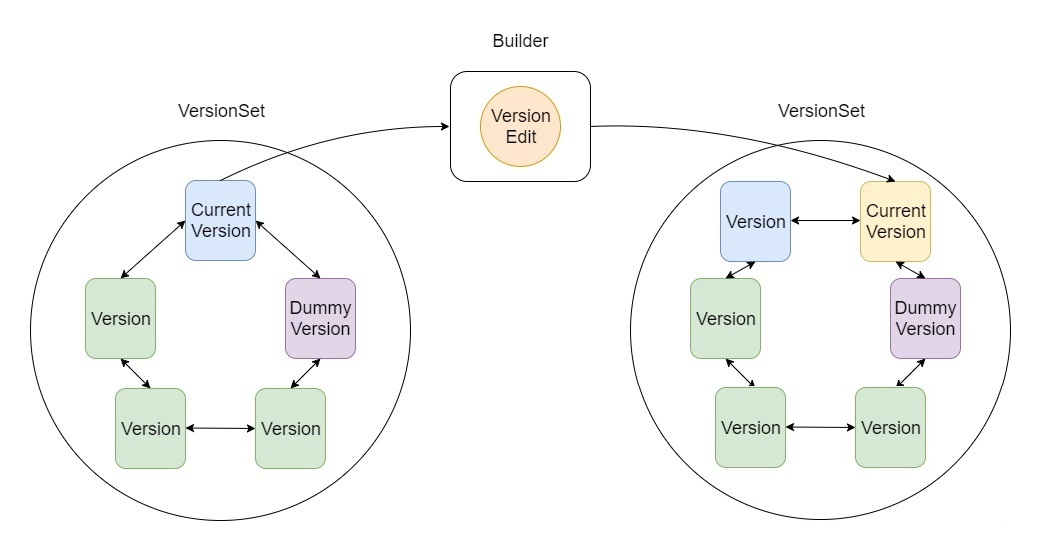
版本管理的工作流程:
- VersionSet里保存着当前版本,以及被引用的历史版本;
- 当有Compaction发生时,会将更改的内容写入到一个VersionEdit中;
- 利用Builder将VersionEdit应用到当前版本上面生成一个新的版本;
- 将新版本链接到VersionSet的双链表上面;
- 将新的版本设置为当前版本;
- 将旧的当前版本Unref,就是引用计数减1。
版本控制中的引用计数:
- 每个Version包含了一个引用,当前版本的 ref 为 1
- 当有迭代器需要遍历数据库时,这个版本的 ref ++ 等于 2
- 其他线程不断写入,触发 compaction,生成新版本
- 新版本 + 1,老版本 - 1
- 因为 老版本为 1,所以不会被删除,直到迭代接受,ref = 0
- 如果 Version 的ref 为0,则可以删除了
实际存储的时候,是存入dbname/MANIFEST-[0-9]+ 这样的文件
CURRENT 指向最新的 manifest 文件
Version 相当于 一个 manifest 文件,VersionSet 则管理多个 manifest 文件
VersionSet 头结点指向最新的 manifest 文件
FileMetaData
sstable的元信息
|
|
Version
位置:db/version_set.h
读取数据库时,就需要 Version 里面的信息
|
|
VersionEdit
|
|
VersionEdit 中包含了两个函数
|
|
这个就是一个 编码,一个解码
将 dst 中的信息,写入到所有变量中,以及从 变量中解码信息到 Slice 中
VersionSet
|
|
VersionSet::Builder辅助类
主要变量:
|
|
LevelFileNumIterator
主要变量
|
|
其中 new 出来的 两次迭代器,就使用到了 LevelFileNumIterator
|
|
builder 版本变迁过程
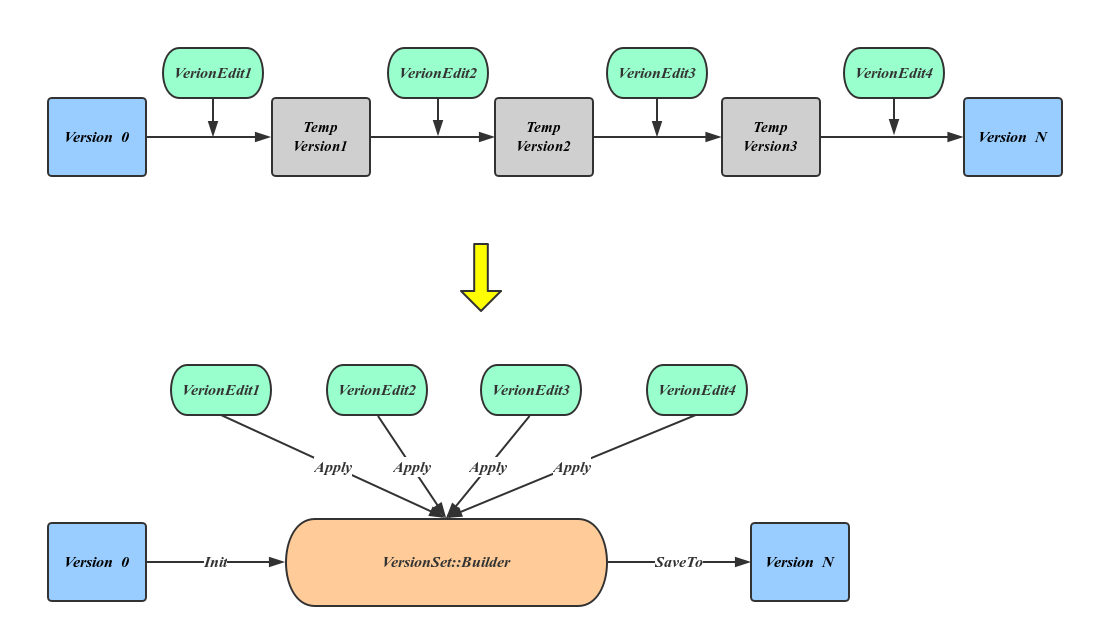
总结一下
- 整体是 VersionSet 的双链表结构,一个版本由 Version 表示
- VersionEdit 是一次变更,比如 sstable新增,删除(通过压缩产生),通过 应用 VersionEdit 就可以得到一个新版本
- builder 会加速变更,可以将多个 VersionEdit 一次性应用
- 每个 Version 内部关联了一个 FileMetaData,表示一个 sstable的元数据,内部包含了 min、max key方便定位
- MANIFEST 实际关联了一个 log 文件,还会将变更的内容当做 log 记录下来,等启动恢复的时候,就会读取这些log文件
压缩
压缩,包含两种
- Minor Compaction,mem-table写满会后刷盘,写入到 level-0 中
- Major Compaction,某个层的文件太多,需要将部分文件推入更高层
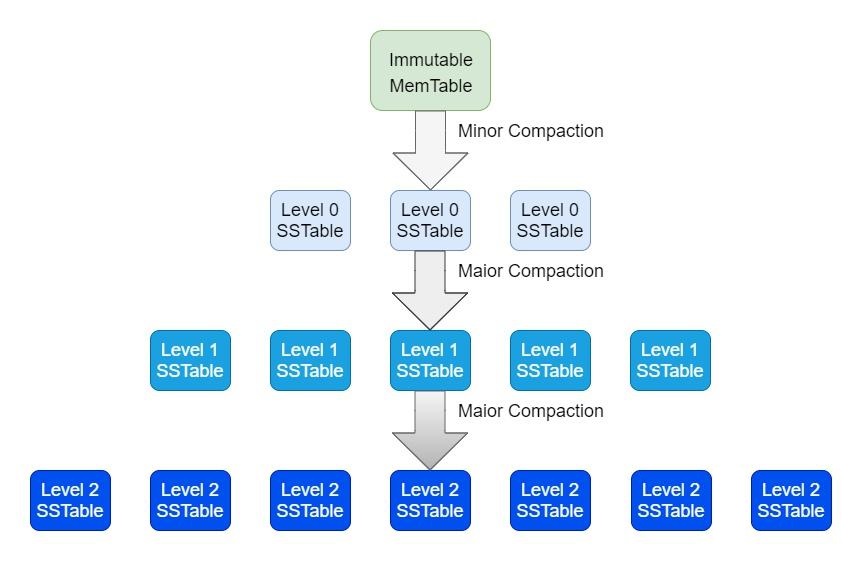
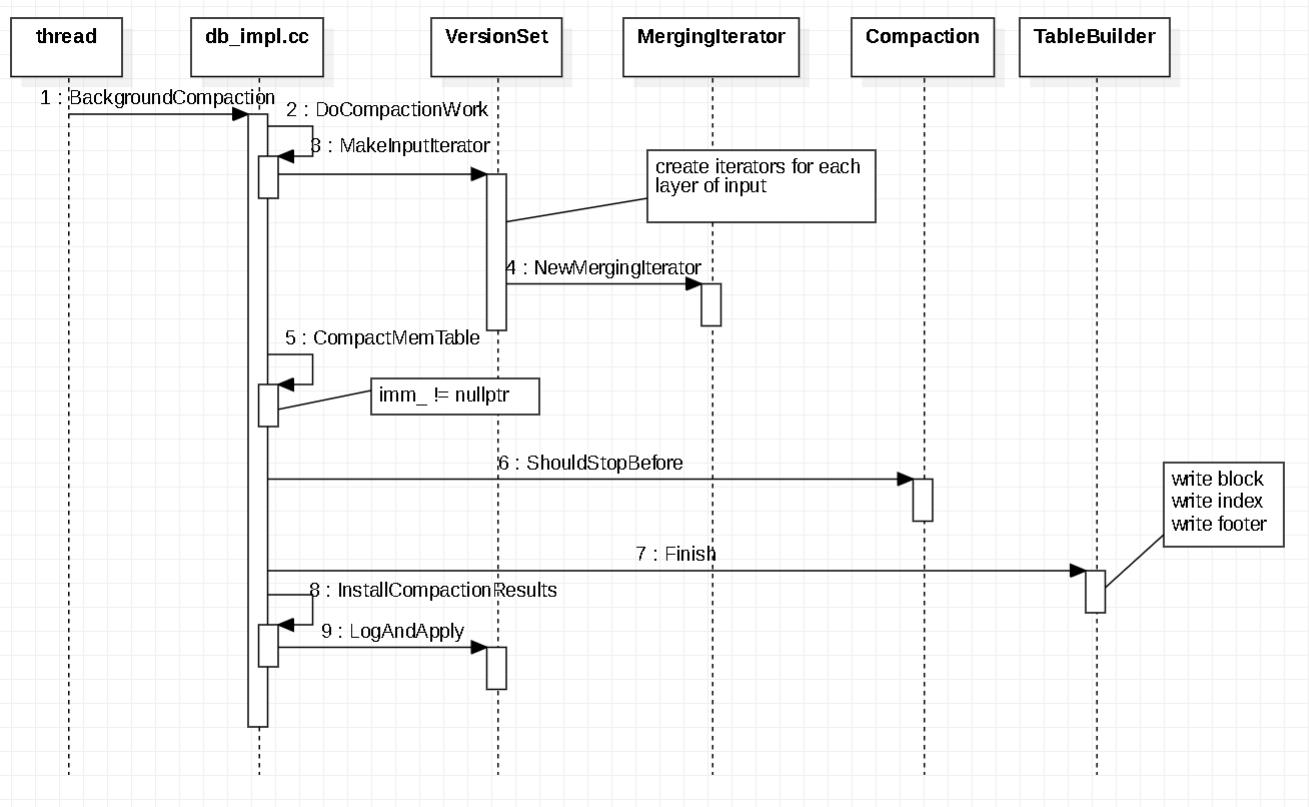
Minor Compaction过程
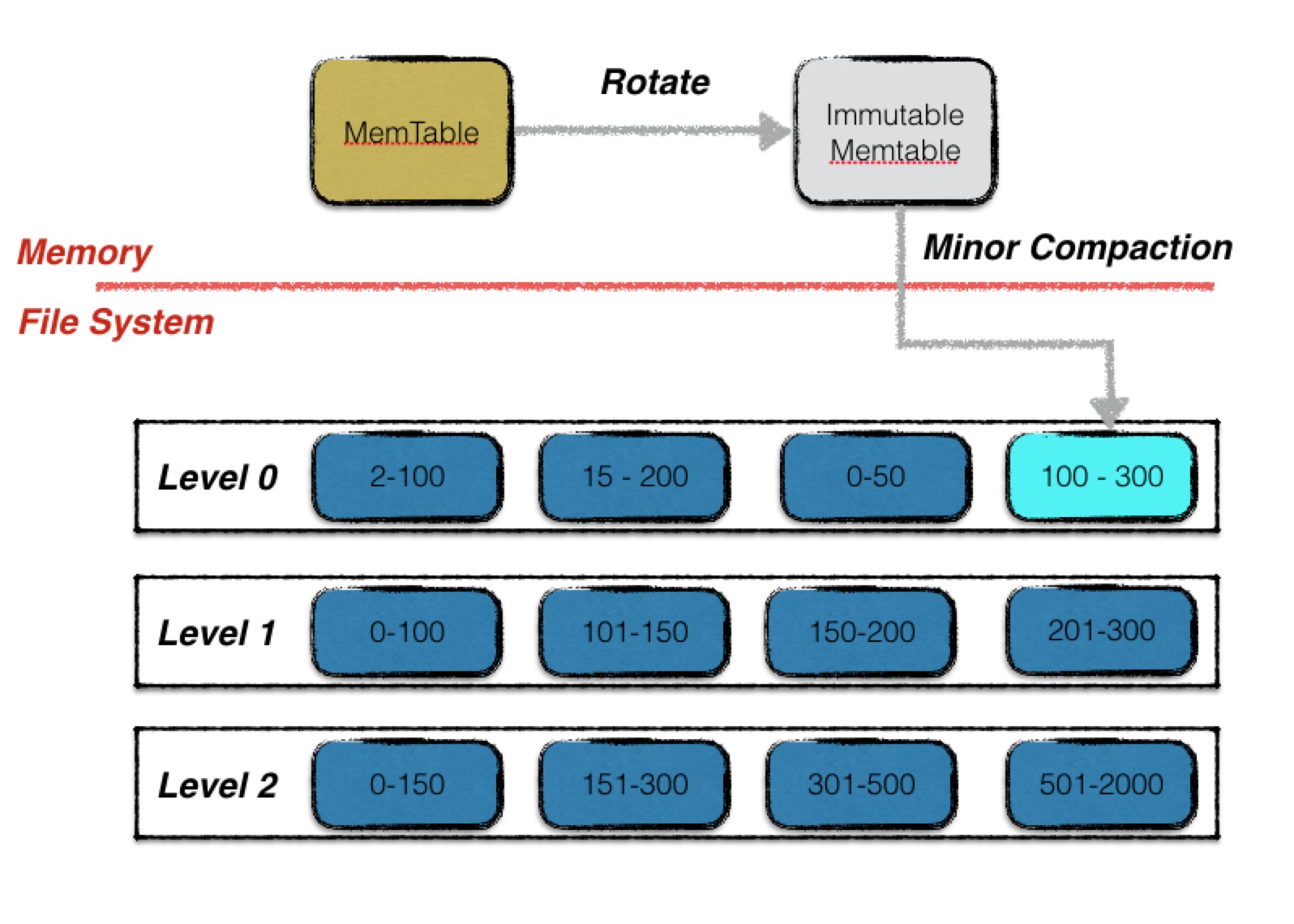
Minor Compaction 时序图
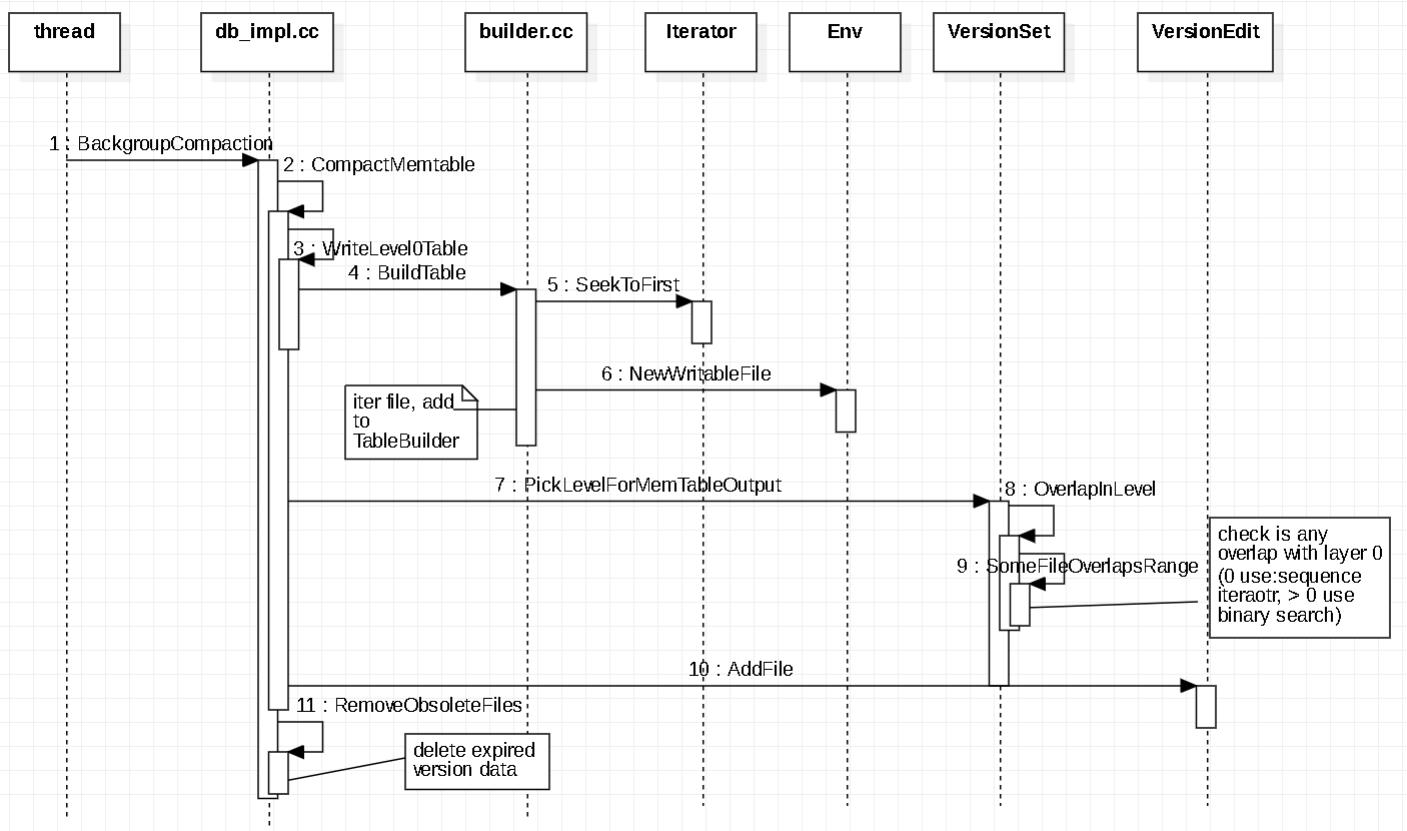
WriteLevel0Table过程
- 得到一个新的 FileMetaData 编号,就是 VersionSet->next_file_number_++
- 调用 BuildTable,其生成的 TableFileName 是根据 FileMetaData的编号得到的
- 获取 min、max key,然后确定将 ss-table 推入哪个层级,调用 PickLevelForMemTableOutput
- 将 压缩状态存入 CompactionStats[level] 中,这里的 level 固定为 PickLevelForMemTableOutput 返回的层级
BuildTable 过程:
- 从 skip-list 的第一个元素开始遍历,一直到结束,将这些 key-value 加入到 TableBuilder
- 同时记录 FileMetaData 的最大、最小、key数量、文件size
- 将数据写入到磁盘
PickLevelForMemTableOutput
- 如果跟 0层的有重叠,则推入 0层
- 检查方式是,对于 level0,需要遍历所有文件,检查每个文件跟min、max key 是否有重叠
- 非 level 0的,则使用 二分查找 当前层的所有文件
- 还会检查 level 0、level 1 在其祖父层级(对应的就是 level 2、level 3中,是否重叠太多
- 默认的最大单个文件大小为 2M,如果一次重叠的数量 > 20M,PickLevelForMemTableOutput 会继续往更深层级查找
- 不过限制了最大查找层级为 2,这也是做了一个权衡
Major Compaction 的过程

Compaction类
|
|
ManualCompaction 类
|
|
Compaction 的触发方式
- Manual Compaction
- Size Compaction
- Seek Compaction
手动压缩的触发函数:
|
|
Size compation
- 实现函数为:
void VersionSet::Finalize(Version* v) - 对于 leve 0,如果 > 4 就会触发
- 超过 0 的,如果超过了 10^n MB 就会触发
- 由于 ss-table 的不变性,只有版本变更的时候才会变化
- 再每次版本变更之后,调用 Finalize,计算出比例最大的 level,下次就从这里开始
- 由于一次压缩要很久,这里会记录一个 level 的key,std::string compact_pointer_[config::kNumLevels];
- 下次再压缩这一层的时候,就从这个 key 开始继续压缩
Seek Compaction
- 为读做的优化,DB::GET、DBIter 时候,如果读取了超过一个 ss-table 则需要优化
- 对于读取 超过一个 的ss-table,对于第一个 ss-table做一个 减操作,如果等于 0了,就需要做压缩
- 所以 seek 是精确到某个 ss-table 的
- 迭代的时候,是每读取 2M数据,就模拟一个key,做对应的 ss-table–
- 初始值,static_cast((f->file_size / 16384U))
- 一次Seek花费10ms;
- 读写1MB的花费10ms (100MB/s);
- 而Compaction 1MB的数据花费25MB左右的IO
执行过程
- 执行优先级是 Manual、Size、Seek
- 前两者是根据 start、end key 选择某一个level的多个文件
- 后者只有确定的一个文件
- 根据 level 层的文件,再确定 level + 1层的文件,之后再反向 level 层扩大 level 的输入范围
- 最后调用多路合并,进行压缩
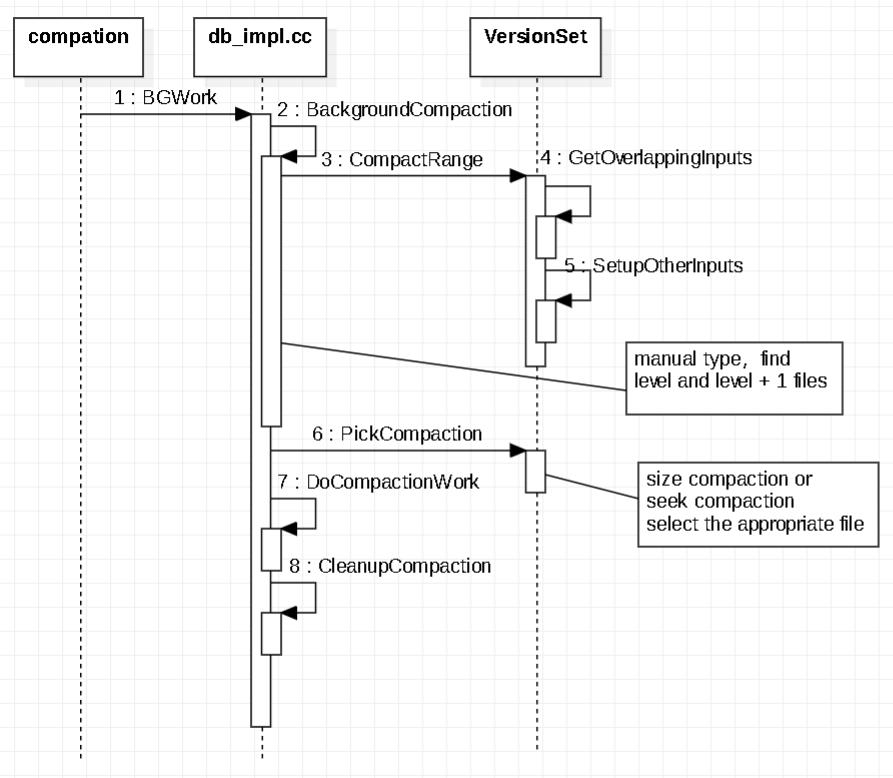
扩大输入文件集合
- 确定起始key、结束key
- 在level i层中,查找与起始输入文件有key重叠的文件,如图中红线所标注,最终构成level i层的输入文件;
- 利用level i层的输入文件,在level i+1层找寻有key重叠的文件,结果为绿线标注的文件,构成level i,i+1层的输入文件;
- 最后利用两层的输入文件,在不扩大level i+1输入文件的前提下,查找level i层的有key重叠的文件,结果为蓝线标准的文件,构成最终的输入文件;
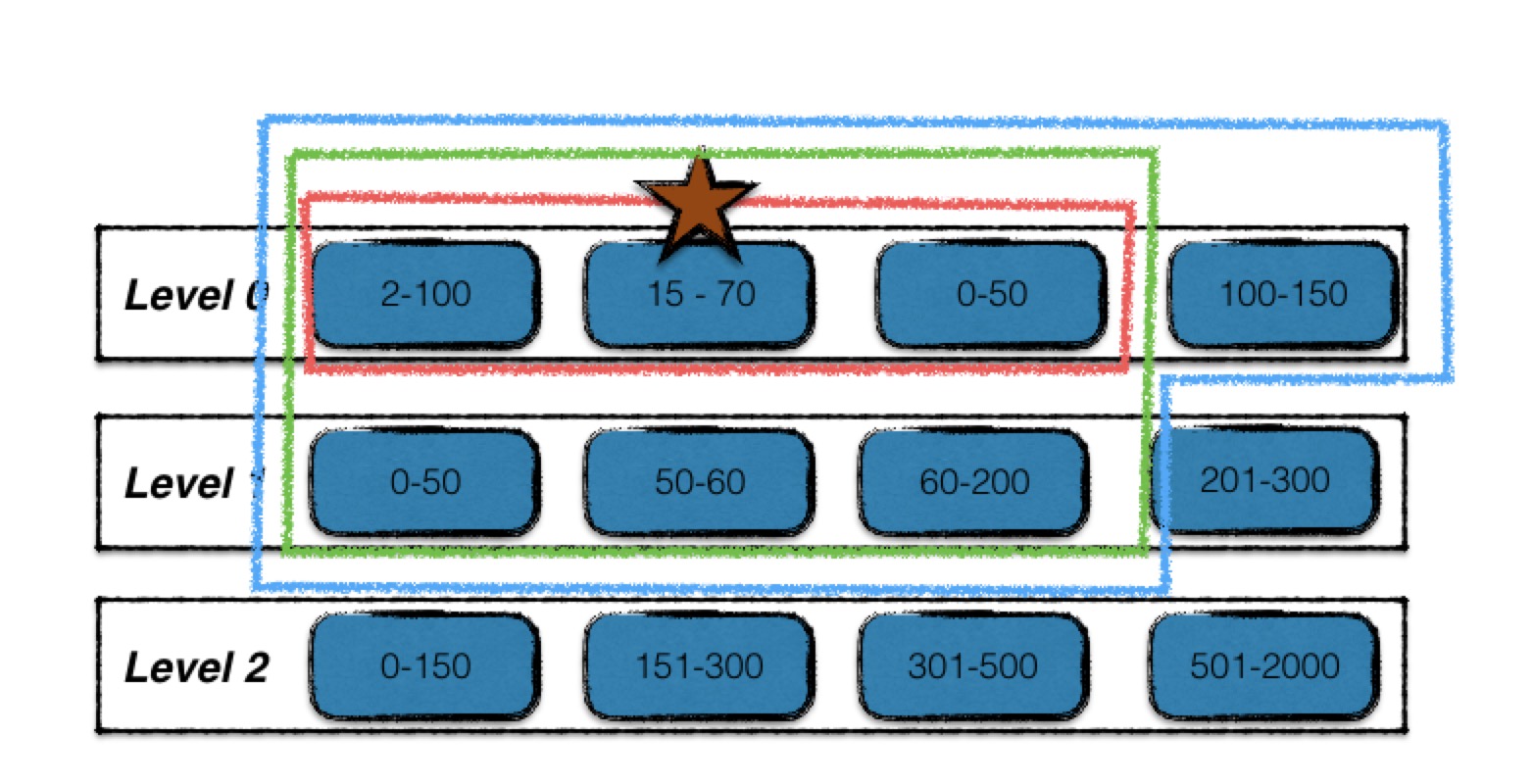
归并的过程:
- 迭代按照Internal Key的顺序进行,多个key则按seq number 降序排列
- 相同的 key只有第一个有效,因为它的 seq 是最大的
- 碰到一个删除时,并且它的 seq_number <= 最新快照,会判断更高层是否有这个key
- 如果有则无法丢弃这个删除操作,因为一旦丢弃,更高层又可见了,不存在可则可以删除
- 如果ss-table达到 2M,或者和上层文件重叠超过 10个,这两个条件任意一个触发就会 生成一个 ss-table写磁盘
数据删除的处理
- 如果是覆盖写入,则当做一个删除处理,即按照降序排序,前面的覆盖后面的,后面重复的key可以忽略
- 如果是删除标记,并且level + 1层没有这个key,则可以删除
- 如果这个key 的seq_number <= 最老快照的序列号,则可以删除,否则不能删除(因为可能被使用中)
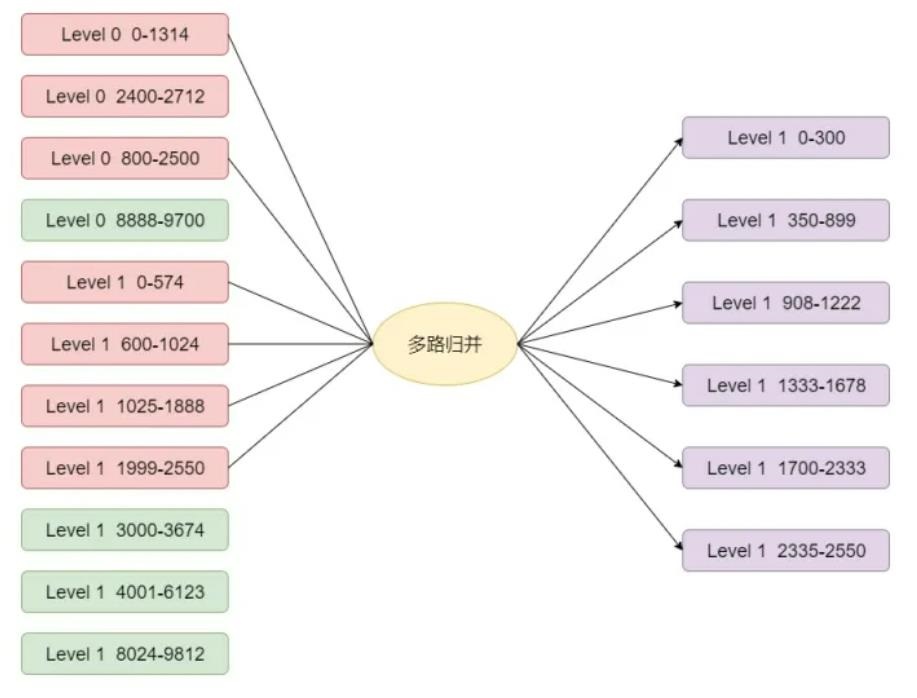
level 0 的压缩过程
- 选择 key 800 - 2500
- 因为 level 0有重叠,遍历所有文件,找到 key 重叠的文件,确定 start、end key
- 选择 level 1 层,根据 start key、end key确定 level 1 层的文件
- 将 level 0 和 level 1的文件做多路归并
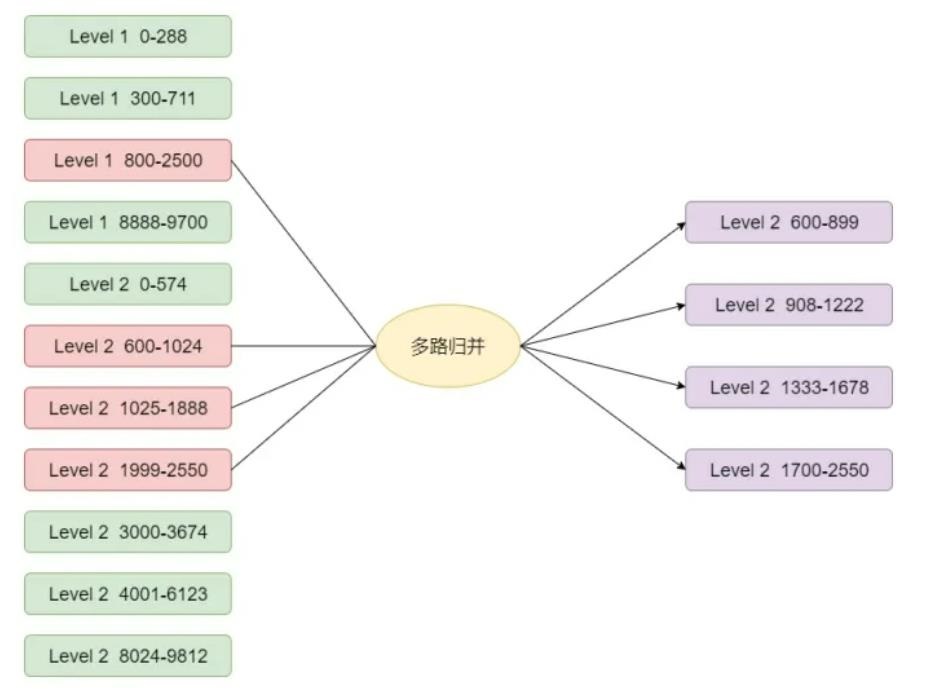
level > 0 的压缩过程
- 选择 key 800 - 2500
- 因为是完全有序的,可以根据二分搜索到确定的范围,确定出 level 层的文件
- 再确定出 level + 1 层的文件
MVCC 数据清理
- 遍历所有文件
- 小于 VersionSet 的 log_number_ 的文件
- 或者不在 遍历列表中的文件,则可以删除
恢复
LevelDB打开需要做以下事情:
- 如果数据库目录不存在,创建目录
- 加文件锁,锁住整个数据库;
- 读取MANIFEST文件,恢复系统关闭时的元数据,也就是版本信息,或者新建MAINFEST文件;
- 如果上一次关闭时,MemTable里有数据,或者Immutable MemTable写入到SSTable未完成,那么需要做数据恢复,从WAL恢复数据;
- 创建数据库相关的内存数据结构,如Version、VersionSet等
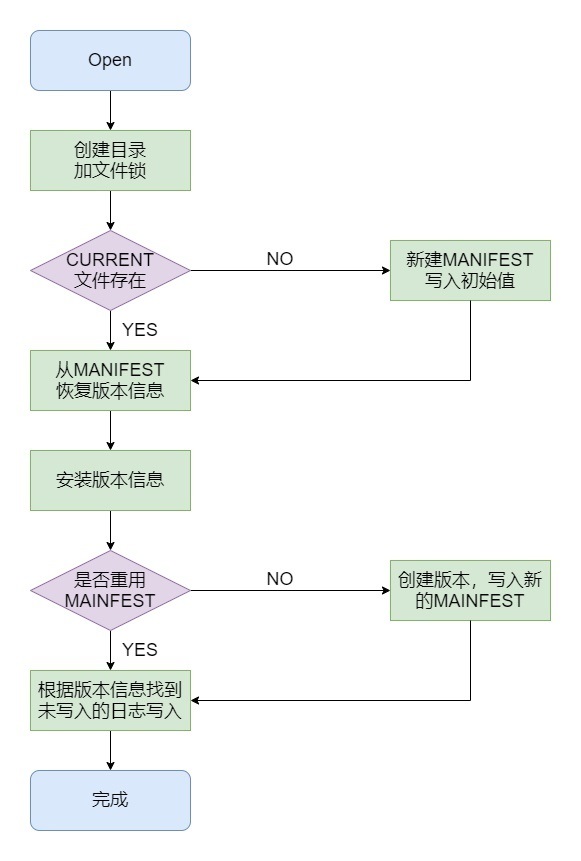
DBImpl::Recover做了以下事情
- 创建数据库目录;
- 对这个数据库里面的LOCK文件加文件锁,单进程的
- 如果数据库不存在,那么调用DBImpl::NewDB创建新的数据库;
- 调用VersionSet::Recover来读取MANIFEST,恢复版本信息;
- 根据版本信息,搜索数据库目录,找到关闭时没有写入到SSTable的日志,按日志写入顺序逐个恢复日志数据
- DBImpl::RecoverLogFile会创建一个MemTable,开始读取日志信息,将日志的数据插入到MemTable
- 并根据需要调用DBImpl::WriteLevel0Table将MemTable写入到SSTable中
异常恢复
- 如果元数据丢了,但是数据还在,也可以恢复的
- 把所有sstable 当做 level 0 层,然后不断做压缩
- 由于sstable 数量会远大于0,这样会大致大量的compaction
- 经过很多次compation最后会稳定下来,形成新的 元数据
- 旧的文件则会删除
参考
- 论文《Less hashing, same performance:Building a better Bloom filter》
- github index
- Bloom Filters by Example
- 漫谈 LevelDB 数据结构(一):跳表(Skip List)
- 漫谈 LevelDB 数据结构(二):布隆过滤器(Bloom Filter)
- 漫谈 LevelDB 数据结构(三):LRU 缓存( LRUCache)
- LevelDB源码剖析
- SF-Zhou’s Blog
- leveldb-handbook
- 庖丁解LevelDB
- rust使用
- LevelDB使用介绍
- LeveLDB维基百科
- dbdb.io的LevelDB介绍
- MariaDB的插件
- 书籍:精通LevelDB
- leveldb 实现解析
- POSIX™ 1003.1 Frequently Asked Questions (FAQ Version 1.18)
- Spurious wakeup
- Memory barrier
- Memory Barriers: a Hardware View for Software Hackers
- Bean Li的LevelDB文章汇总
- LevelDB设计与实现 - Compaction
- LevelDB设计与实现 - MVCC等
- leveldb源码剖析 系列
- HBase file format with inline blocks (version 2)