Bloom Filter
代码位于:util/bloom.cc
接口位于:include/leveldb/filter_policy.h
接口中的三个函数:
1
2
3
|
virtual const char* Name() const = 0;
virtual void CreateFilter(const Slice* keys, int n, std::string* dst) const = 0;
virtual bool KeyMayMatch(const Slice& key, const Slice& filter) const = 0;
|
构造函数
1
2
3
4
5
6
|
explicit BloomFilterPolicy(int bits_per_key) : bits_per_key_(bits_per_key) {
// We intentionally round down to reduce probing cost a little bit
k_ = static_cast<size_t>(bits_per_key * 0.69); // 0.69 =~ ln(2)
if (k_ < 1) k_ = 1;
if (k_ > 30) k_ = 30;
}
|
这里的k_是哈希函数的个数,固定为 1 - 30
bits_per_key 表示每个元素使用的 位个数
布隆过滤器的存储空间大小m,哈希函数个数k和元素总的个数n之间存在如下一个计算公式
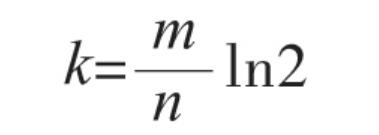
创建 过滤器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
void CreateFilter(const Slice* keys, int n, std::string* dst) const override {
// Compute bloom filter size (in both bits and bytes)
size_t bits = n * bits_per_key_;
// For small n, we can see a very high false positive rate. Fix it
// by enforcing a minimum bloom filter length.
if (bits < 64) bits = 64;
size_t bytes = (bits + 7) / 8;
bits = bytes * 8;
const size_t init_size = dst->size();
dst->resize(init_size + bytes, 0);
dst->push_back(static_cast<char>(k_)); // Remember # of probes in filter
char* array = &(*dst)[init_size];
for (int i = 0; i < n; i++) {
// Use double-hashing to generate a sequence of hash values.
// See analysis in [Kirsch,Mitzenmacher 2006].
uint32_t h = BloomHash(keys[i]);
const uint32_t delta = (h >> 17) | (h << 15); // Rotate right 17 bits
for (size_t j = 0; j < k_; j++) {
const uint32_t bitpos = h % bits;
array[bitpos / 8] |= (1 << (bitpos % 8));
h += delta;
}
}
}
|
向上取整,为 8的倍数,然后将 bloom filter 函数个数,push 到 dst 中
遍历 n 个元素,对每个元素计算 哈希值
这里并没有计算k个哈希,而是只计算了一次,获得了一个原始值h
之后遍历k次,然后计算h的增量
这样的话,效率会高很多,而且准确率也不差
查找的匹配函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
bool KeyMayMatch(const Slice& key, const Slice& bloom_filter) const override {
const size_t len = bloom_filter.size();
if (len < 2) return false;
const char* array = bloom_filter.data();
const size_t bits = (len - 1) * 8;
// Use the encoded k so that we can read filters generated by
// bloom filters created using different parameters.
const size_t k = array[len - 1];
if (k > 30) {
// Reserved for potentially new encodings for short bloom filters.
// Consider it a match.
return true;
}
uint32_t h = BloomHash(key);
const uint32_t delta = (h >> 17) | (h << 15); // Rotate right 17 bits
for (size_t j = 0; j < k; j++) {
const uint32_t bitpos = h % bits;
if ((array[bitpos / 8] & (1 << (bitpos % 8))) == 0) return false;
h += delta;
}
return true;
}
|
也是类似的
读取出 bloom filter的数据,以及长度,构建出 array 数组
首先计算出 hash值
然后遍历k次,也就是k个函数,然后跟创建的时候类似
通过h % bits,就得到了具体的位下标
然后看看数组中的这一位 是否设置为1,非1直接返回 false
否则计算增量,如果k次计算都满足,则返回 true
布隆过滤器的使用,两个类
- FilterBlockBuilder,创建布隆过滤器,并写入到 SSTable中
- FilterBlockReader,读取元数据块,调用 BloomFilterPolicy 检查是否匹配
FilterBlockBuilder
- 首先调用 Add,将 key进去,将所有的key直接拼在一起,比如 aa、bb、cc、dd,拼在一起就是aabbccdd,中间没有分割
- 记录没每个key的起始位置,根据每个key的起始位置,前后相减,就得到了长度
- 根据起始位置和长度,就封装出了 Slice,将这些 key都临时保存
- 如果数据超过了 2K,则生成 布隆过滤器,也就是调用 policy_->CreateFilter 创建
- 传入的是之前 生成的三个参数
- std::vector tmp_keys_、std::string result_、num_keys
FilterBlockReader
- 首先构建出 布隆过滤器
- 然后根据 key的偏移量,计算出这个key,封装为 Slice,调用 KeyMayMatch 进行判断
LRU缓存
包含了四个关键类
- LRUHandle
- HandleTable
- LRUCache
- ShardedLRUCache
ShardedLRUCache 是对 LRUCache 的封装,包含了 16个 LRUCache,目的是减少锁粒度
1
|
Cache* NewLRUCache(size_t capacity) { return new ShardedLRUCache(capacity); }
|

其 查找函数如下:
1
2
3
4
5
6
7
8
|
static const int kNumShardBits = 4;
static const int kNumShards = 1 << kNumShardBits;
Handle* Lookup(const Slice& key) override {
const uint32_t hash = HashSlice(key);
return shard_[Shard(hash)].Lookup(key, hash);
}
static uint32_t Shard(uint32_t hash) { return hash >> (32 - kNumShardBits); }
|
HashSlice 就是根据 key 返回一个 hash值
Shard,则取这个 hash 值的 高 4位,这样就可以找到对应的 LRUCache 了
LRUHandle 是双链表的节点
1
2
3
4
5
6
7
8
9
10
11
12
13
|
struct LRUHandle {
void* value;
void (*deleter)(const Slice&, void* value); // 释放 key,value 空间的用户回调
LRUHandle* next_hash; // 用于 hashtable 中链表处理冲突
LRUHandle* next; // 用于双向链表中维护 LRU 顺序
LRUHandle* prev;
size_t charge; // TODO(opt): Only allow uint32_t?
size_t key_length;
bool in_cache; // 该 handle 是否在 cache table 中
uint32_t refs; // 该 handle 被引用的次数
uint32_t hash; // key 的 hash 值,用于确定分片和快速比较
char key_data[1]; // key 的起始
}
|
HandleTable 则是一个 hash 表,通过 双链表 + 自定义简单的 hash 表,就组成了 LRU
主要函数:
1
2
3
4
|
LRUHandle* Insert(LRUHandle* h)
LRUHandle* Remove(const Slice& key, uint32_t hash)
LRUHandle** FindPointer(const Slice& key, uint32_t hash)
void Resize()
|
有好几处都调用了 FindPointer
1
2
3
4
5
6
7
8
9
10
11
12
13
|
LRUHandle** list_; // hash 表中的 list_ 定义
// 返回前驱节点的 next_hash 指针的指针
LRUHandle** FindPointer(const Slice& key, uint32_t hash) {
// 找到 hash表的某个桶的开头
LRUHandle** ptr = &list_[hash & (length_ - 1)];
// 一直往后遍历,直到找到 hash 和 key 匹配为止
while (*ptr != nullptr && ((*ptr)->hash != hash || key != (*ptr)->key())) {
ptr = &(*ptr)->next_hash;
}
// 返回的是 next_hash
return ptr;
}
|
比如删除的时候,只要改变 next_hash 的地址内容就可以了
因为 FindPointer 返回的是 next_hash 的指针的指针,通过 *ptr 判断这个值是否为空
不空,则用下一个节点的 next_hash 值 替换掉即可
1
2
3
4
5
6
|
LRUHandle** ptr = FindPointer(key, hash);
LRUHandle* result = *ptr;
if (result != nullptr) {
*ptr = result->next_hash;
--elems_;
}
|
LRUCache 内部的几个重要变量
1
2
3
4
5
6
|
size_t capacity_;
mutable port::Mutex mutex_;
size_t usage_ GUARDED_BY(mutex_);
LRUHandle lru_ GUARDED_BY(mutex_);
LRUHandle in_use_ GUARDED_BY(mutex_);
HandleTable table_ GUARDED_BY(mutex_);
|
内部维护了两个链表,in_use、lru
in_use 表示正在使用的,是乱序的
lru 就是正常的 lru 链表,有序的,如果空间不够了,则从这里删除
table_ 就是 hash 表
这几个的关系如下:
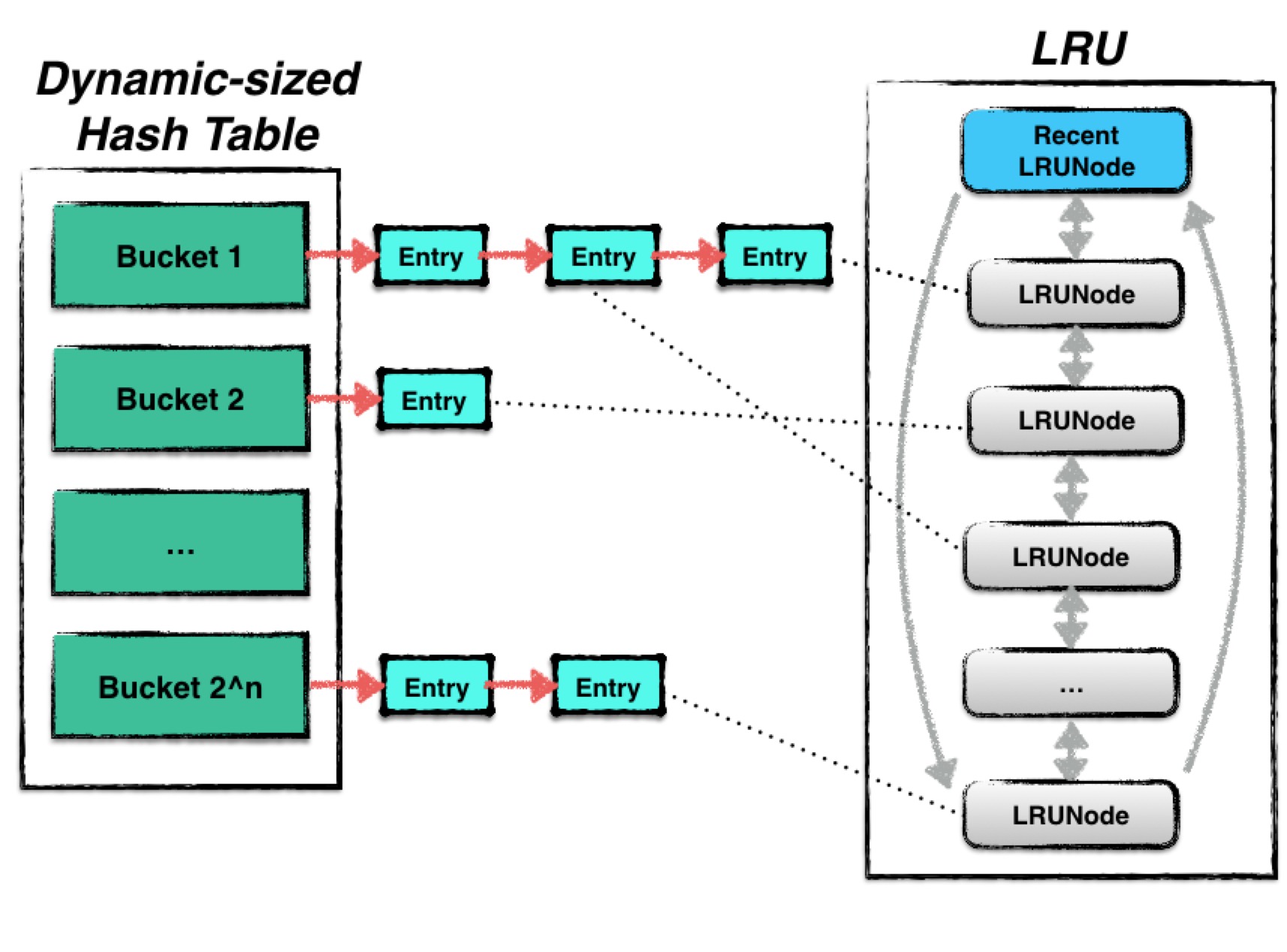
in_use 和 lru、hash 表的另一种视图
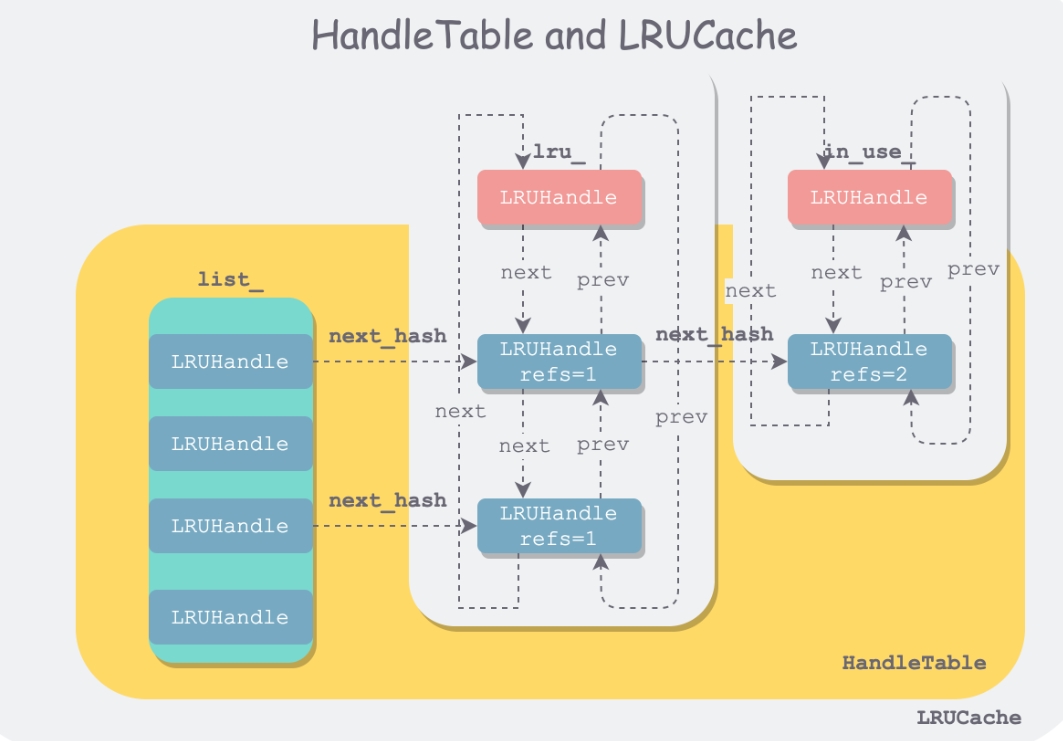
一开始的插入会放到 lru 链表中,如果 ref++,则会放到 in_use 链表中
同理,如果 unref,则会判断是否没有引用了,然后从 in_use 中删除,放到 lru 链表中
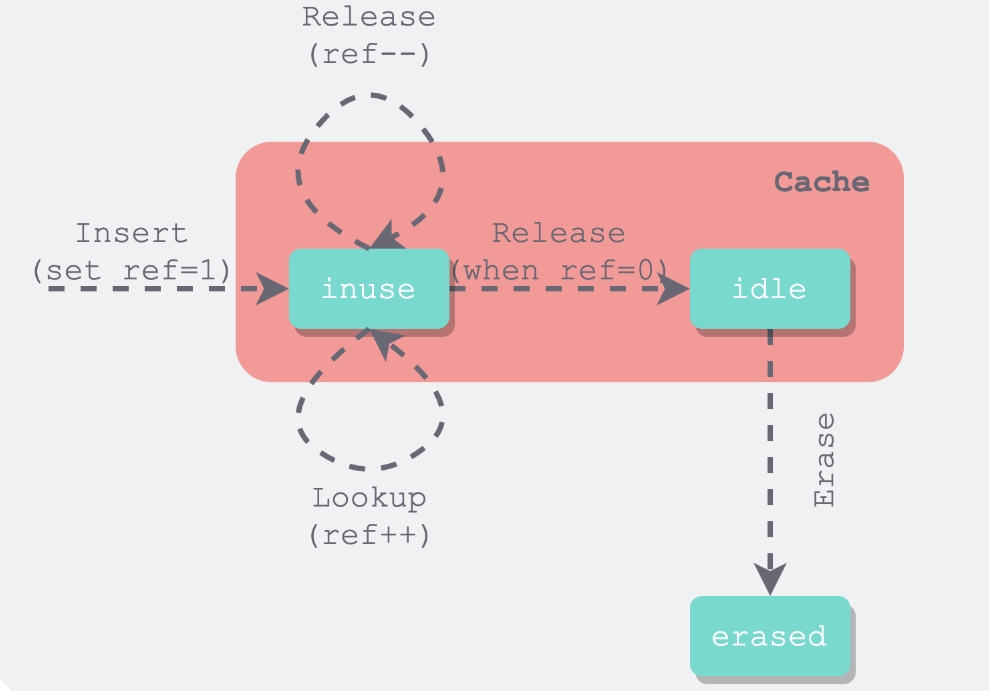
LRUCache 的主要变量
-使用两个双向链表将整个缓存分成两个不相交的集合:被客户端引用的 in-use 链表,和不被任何客户端引用的 lru_ 链表。
- 每个双向链表使用了一个空的头指针,以便于处理边界情况。并且表头的 prev 指针指向最新的条目,next 指针指向最老的条目,从而形成了一个双向环形链表。
- 使用 usage_ 表示缓存当前已用量,用 capacity_ 表示该缓存总量。
- 抽象出了几个基本操作:LRU_Remove、LRU_Append、Ref、Unref 作为辅助函数进行复用。
- 每个 LRUCache 由一把锁 mutex_ 守护。
LRUCache的函数
1
2
3
4
5
6
7
8
9
|
// 插入到 in_use 中,并插入到 hash 表中,如果插入完 超过阈值,从 lru 链表中 while 删除不需要的
Cache::Handle* Insert(const Slice& key, uint32_t hash, void* value, size_t charge, void (*deleter)(const Slice& key, void* value))
// 从 hash 表中查找,并 更新 ref
Cache::Handle* Lookup(const Slice& key, uint32_t hash);
void Release(Cache::Handle* handle); // ref--
void Erase(const Slice& key, uint32_t hash); // 全部清空
void Prune();
|
LRUCache 中的私有函数
1
2
3
4
5
|
void LRU_Remove(LRUHandle* e);
void LRU_Append(LRUHandle* list, LRUHandle* e);
void Ref(LRUHandle* e);
void Unref(LRUHandle* e);
bool FinishErase(LRUHandle* e) EXCLUSIVE_LOCKS_REQUIRED(mutex_);
|
LRUCache 的使用是在 db/table_cache.cc 中
这里包含了变量cache_,
1
2
3
4
|
struct TableAndFile {
RandomAccessFile* file;
Table* table;
};
|
引用的回调函数
1
2
3
4
5
6
7
8
|
static void DeleteEntry(const Slice& key, void* value) {
TableAndFile* tf = reinterpret_cast<TableAndFile*>(value);
delete tf->table;
delete tf->file;
delete tf;
}
cache_->Insert(key, tf, 1, &DeleteEntry);
|
主要函数:
1
2
3
4
5
6
7
8
|
Iterator* NewIterator(const ReadOptions& options, uint64_t file_number, uint64_t file_size, Table** tableptr = nullptr);
Status Get(const ReadOptions& options, uint64_t file_number, uint64_t file_size, const Slice& k, void* arg,
void (*handle_result)(void*, const Slice&, const Slice&));
void Evict(uint64_t file_number);
Status FindTable(uint64_t file_number, uint64_t file_size, Cache::Handle**);
|
FindTable流程:
- 首先去 LRU 中查找,如果找不到,则创建一个随机文件的读写对象
- 然后 SSTable 打开,之后将其插入到缓存中
1
2
3
4
|
TableAndFile* tf = new TableAndFile;
tf->file = file;
tf->table = table;
*handle = cache_->Insert(key, tf, 1, &DeleteEntry);
|
一些工具类
arena.cc,内存分配
- 使用一个char *的vector保存每个块;
- 当需要分配一块内存时,查看alloc_bytes_remaining_(就是当前块还有多少内存未分配)是否大于等于所需内存;
- 如果大于等于,直接分配,这时候只需要移动指针即可;
- 如果小于,要分两种情况,看所需要分配的内存是否大于1KB;
- 如果大于1KB,直接分配相应大小的块,并且插入到vector中;
- 如果小于等于1KB,则分配一个4KB的块,插入到vector中,从4KB的块上分配相应的内存;上一个块里没有分配的内存就浪费了
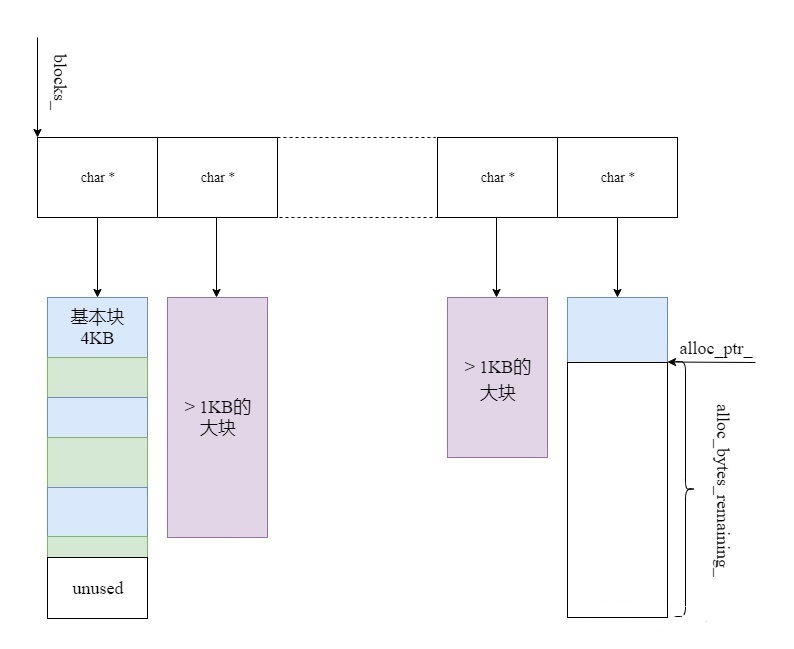
coding.cc
- 如果编码值 v < 1 « 7,只需要7位即可编码,可使用0 + v的方式;
- 如果编码值 1 « 7 <= v < 1 « 14,需要两个字节编码,第一个字节使用1 + v的低7位,表示需要查看下一个字节,下一个字节使用0 + v的高7位,表示不需要查看下一个字节;
- 以此类推
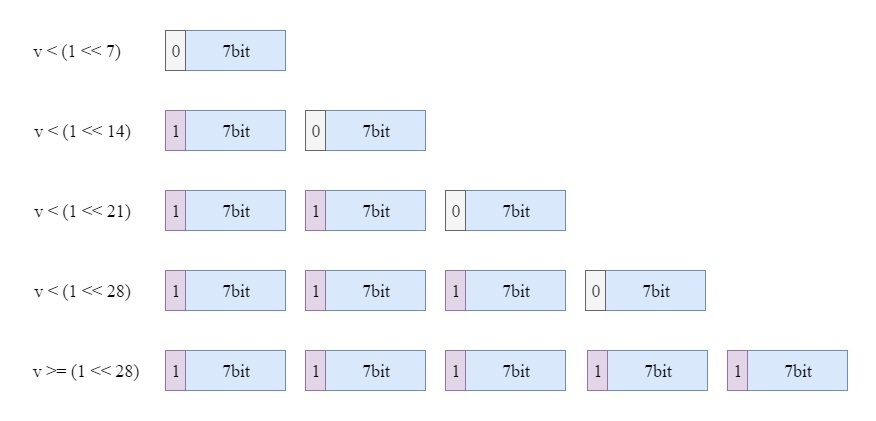
include/leveldb/slice.h
- Slice有一个字段char* data_保存字符串的指针
- 另一个字段size_t size_表示字符串的长度,也就是Slice指向另外一个字符串
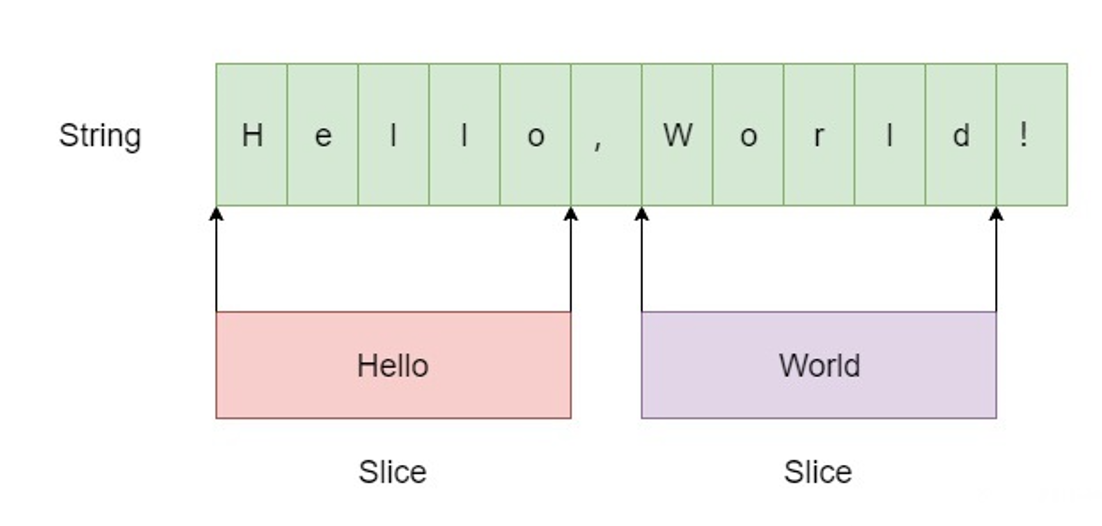
其他
hash
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
uint32_t Hash(const char* data, size_t n, uint32_t seed) {
// Similar to murmur hash
const uint32_t m = 0xc6a4a793;
const uint32_t r = 24;
const char* limit = data + n;
uint32_t h = seed ^ (n * m);
// Pick up four bytes at a time
while (data + 4 <= limit) {
uint32_t w = DecodeFixed32(data);
data += 4;
h += w;
h *= m;
h ^= (h >> 16);
}
// Pick up remaining bytes
switch (limit - data) {
case 3:
h += static_cast<uint8_t>(data[2]) << 16;
FALLTHROUGH_INTENDED;
case 2:
h += static_cast<uint8_t>(data[1]) << 8;
FALLTHROUGH_INTENDED;
case 1:
h += static_cast<uint8_t>(data[0]);
h *= m;
h ^= (h >> r);
break;
}
return h;
}
|
logging 主要函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
void AppendNumberTo(std::string* str, uint64_t num);
// Append a human-readable printout of "value" to *str.
// Escapes any non-printable characters found in "value".
void AppendEscapedStringTo(std::string* str, const Slice& value);
// Return a human-readable printout of "num"
std::string NumberToString(uint64_t num);
// Return a human-readable version of "value".
// Escapes any non-printable characters found in "value".
std::string EscapeString(const Slice& value);
// Parse a human-readable number from "*in" into *value. On success,
// advances "*in" past the consumed number and sets "*val" to the
// numeric value. Otherwise, returns false and leaves *in in an
// unspecified state.
bool ConsumeDecimalNumber(Slice* in, uint64_t* val);
|
comparator
histogram
crc32c
参考