LevelDB MemTable
跳表
跳表是一种可以取代平衡树的数据结构
跳表使用概率均衡而非严格均衡策略,从而相对于平衡树,大大简化和加速了元素的插入和删除
跳表的结构
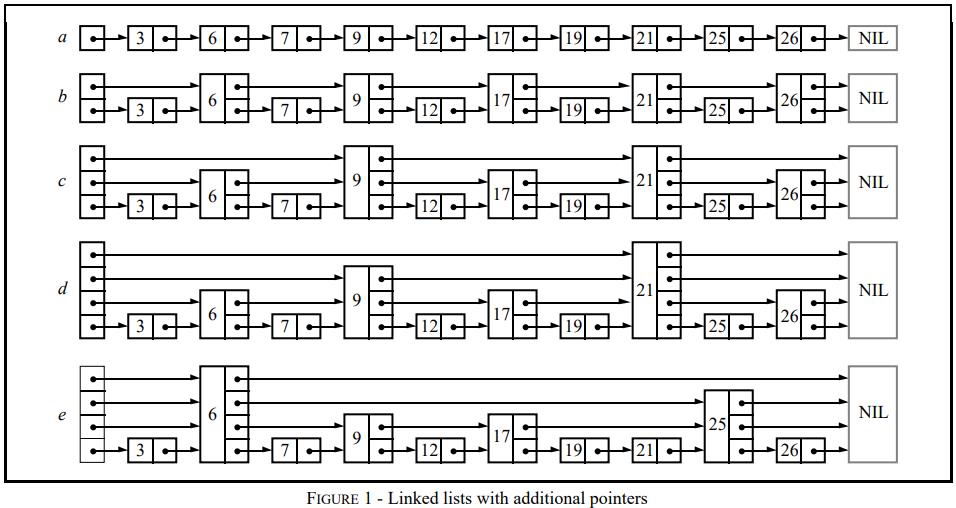
最底下一层都包含完整的数据,从第二层开始,节点的高度是随机产生的
越往上的节点,其出现的概率越低
- 作者从链表讲起,一步步引出了跳表这种结构的由来。
- 图a中,所有元素按序排列,被存储在一个链表中,则一次查询之多需要比较N个链表节点;
- 图b中,每隔2个链表节点,新增一个额外的指针,该指针指向间距为2的下一个节点,如此以来,借助这些额外的指针,一次查询至多只需要⌈n/2⌉ + 1次比较;
- 图c中,在图b的基础上,每隔4个链表节点,新增一个额外的指针,指向间距为4的下一个节点,一次查询至多需要⌈n/4⌉ + 2次比较;
- 作者推论,若每隔2^ i个节点,新增一个辅助指针,最终一次节点的查询效率为O(log n)。但是这样不断地新增指针,使得一次插入、删除操作将会变得非常复杂。
- 一个拥有k个指针的结点称为一个k层结点(level k node)。按照上面的逻辑,50%的结点为1层节点,25%的结点为2层节点,12.5%的结点为3层节点。若保证每层节点的分布如上述概率所示,则仍然能够相同的查询效率。图e便是一个示例。
查找和插入
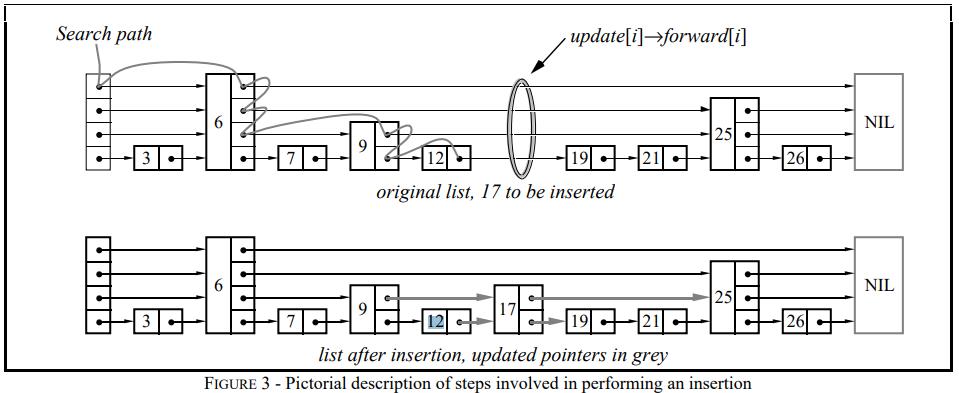
查找 12
- 通过头结点,找到 6,再后面是null,所以 6 下降一层
- 6下降一层,下一个节点时 25,大于 12,6这个节点再下降一层
- 6的下一个是9,9的下一个是25,所以 9这个节点再下降一层
- 9的 下一个是12,找到
插入17
- 首先要定位到 17 的前面一个,这个过程跟上面的一样
- 再将 17放到 12后面
LevelDB 的 插入实现
|
|
随机产生的高度
|
|
查找前一个节点
|
|
由于 LSM 树的特性,跳表中没有删除操作,只有 插入、查找操作
同时也提供了 遍历操作
包括 向前、向后遍历,由于 LevelDB的跳表是单链表结构,所以向前操作的成本比较高
LevelDB的跳表中,使用了很多 内存屏障的操作,都是 C++11 中的标准
- std::memory_order_relaxed:不对重排做限制,只保证相关共享内存访问的原子性。
- std::memory_order_acquire: 用在 load 时,保证同线程中该 load 之后的对相关内存读写语句不会被重排到 load 之前,并且其他线程中对同样内存用了 store release 都对其可见。
- std::memory_order_release:用在 store 时,保证同线程中该 store 之后的对相关内存的读写语句不会被重排到 store 之前,并且该线程的所有修改对用了 load acquire 的其他线程都可见。
相比于平衡树,LevelDB采用跳表的优势
- dump的时候需要快速的顺序扫描,链表更有优势
- 不需要删除操作,平衡树的功能显得多余了
- 最大限度的并行,使用了内存屏障,如果要在平衡树中最类似功能,代价会更大
MemTable
MemTable 内部维护了一个跳表的迭代器
|
|
还有内存分配类,向前、向后迭代器
|
|
一些重要的函数
|
|
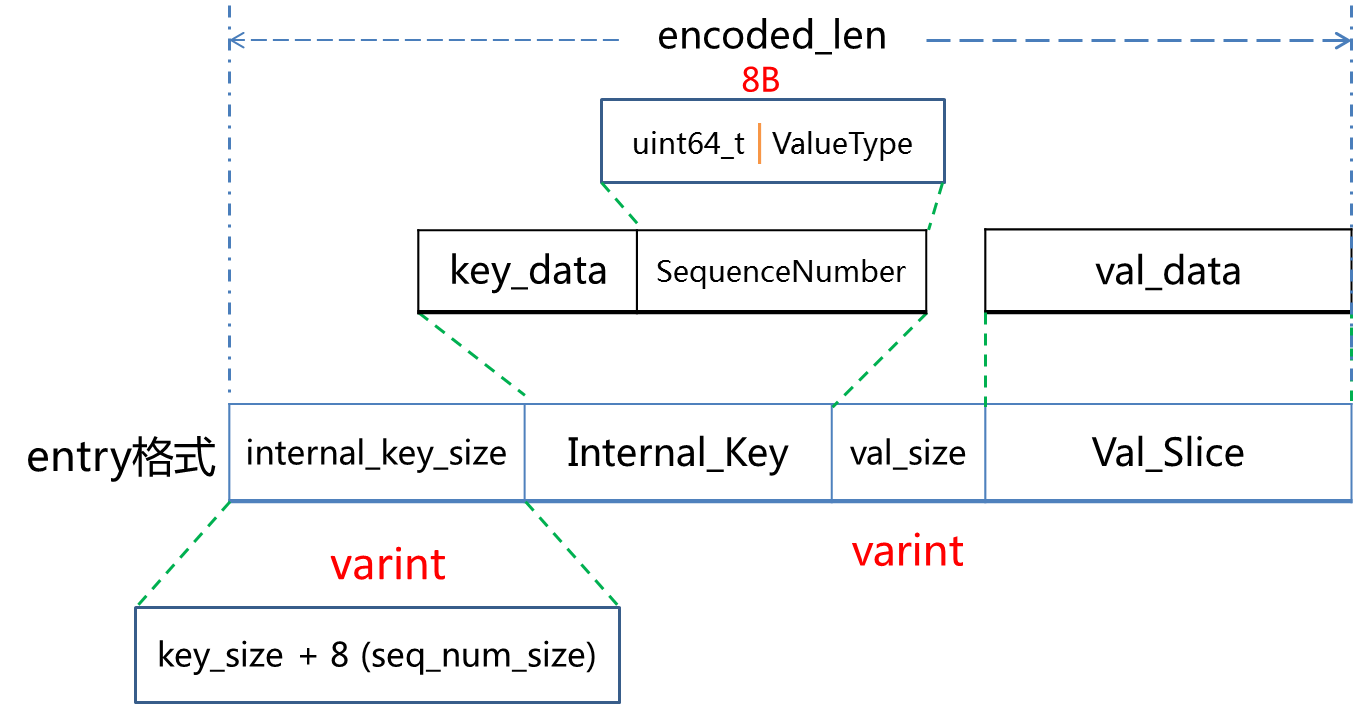
插入 和 查询 都是调用 sikp-list 实现的 SkipList中单条数据存放一条Key-Value数据,定义为:
|
|

插入操作,源码中给出的 一条记录格式
|
|
- 获取编码后的一条记录长度
- Arena分配对应的内存
- 将 一条记录 拷贝到Arena 分配的内存中
- 调用 SkipList 完成插入
插入时的 key,value结构
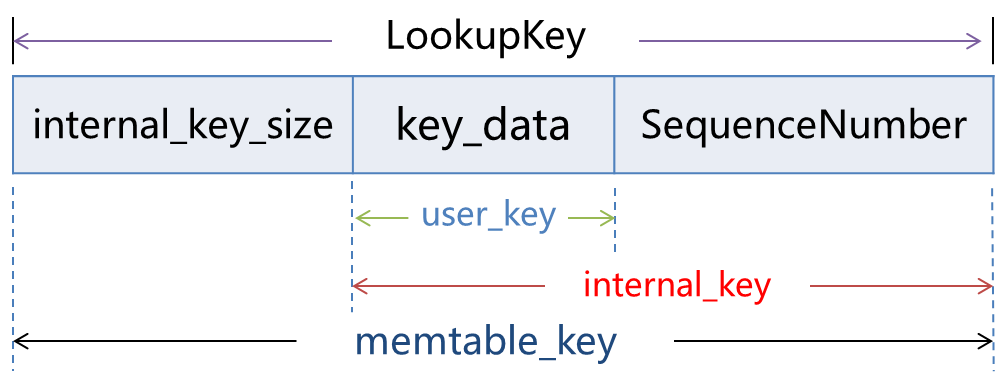
查找
- 根据传入的 key,去 skip-list 中查找
- 比较传入的 key 和 找到的 key 是否相等
- 如果相等,检查 type,如果是 delete,则返回空
- 否则 解析出 value,存入 str::string 中并返回
查询时,函数参数封装的 key结构
生成SSTable
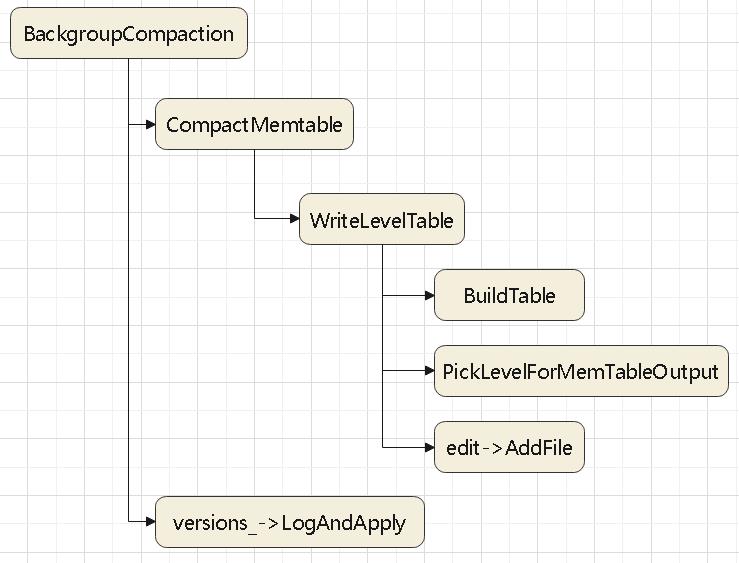
mem-table 写 sstable的过程,在
db/db_impl.cc 的 WriteLevel0Table 函数中
调用过程:
|
|
CompactMemTable 还会调用 RemoveObsoleteFiles,用来删除无用的 LOG 文件
根据代码中的注释,文件类型包括:
|
|
CompactMemTable过程:
- 获取当前版本 Version* base = versions_->current();
- 执行 WriteLevel0Table
- 设置 VersionEdit 的log编号,并将此次修改增加到 VersionSet 中
- 调用 RemoveObsoleteFiles
RemoveObsoleteFiles 过程:
- 去 DB 路径下拿到文件列表,然后解析这些文件
- 主要解析出这些文件的 number:dbname/MANIFEST-[0-9]+、dbname/[0-9]+.(log|sst|ldb)
- 如果 number < 当前日志 && number < 前一个版本日志,这个日志就可以删除了
- 如果 manifest 小于 当前 manifest 编号,这个 manifest 文件也可以删除了
- 获取 VersionSet 中所有的活跃文件,对于 kTableFile、kTempFile 如果不在活跃文件中,也可以删除
获取活跃文件的过程:
- Version是通过双链表组织的
- 获取每层的元数据集合 std::vector<FileMetaData*>,默认最大层为 7,也就是遍历 7 次
- 对每层的元数据列表,将其插入到 活跃列表中 std::set<uint64_t>*
WriteLevel0Table过程
- 得到一个新的 FileMetaData 编号,就是 VersionSet->next_file_number_++
- 调用 BuildTable,其生成的 TableFileName 是根据 FileMetaData的编号得到的
- 获取 min、max key,然后确定将 ss-table 推入哪个层级,调用 PickLevelForMemTableOutput
- 将 压缩状态存入 CompactionStats[level] 中,这里的 level 固定为 PickLevelForMemTableOutput 返回的层级
BuildTable 过程:
- 从 skip-list 的第一个元素开始遍历,一直到结束,将这些 key-value 加入到 TableBuilder
- 同时记录 FileMetaData 的最大、最小、key数量、文件size
- 将数据写入到磁盘
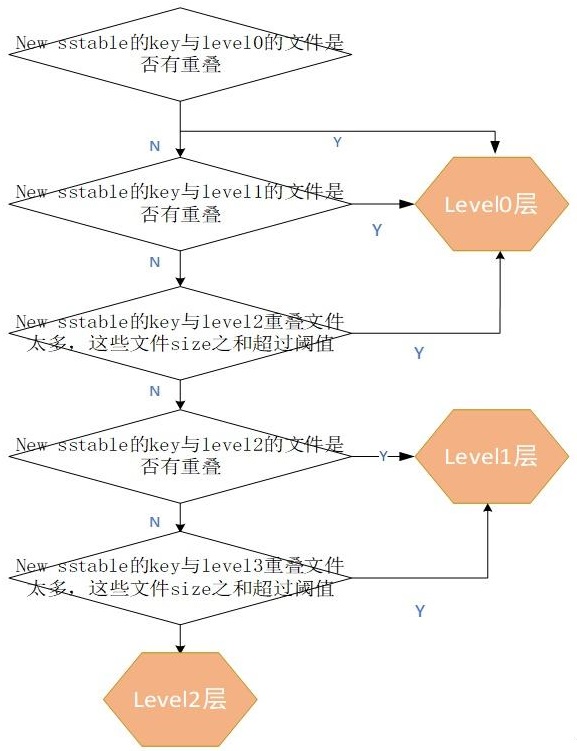
PickLevelForMemTableOutput
- 如果跟 0层的有重叠,则推入 0层
- 检查方式是,对于 level0,需要遍历所有文件,检查每个文件跟min、max key 是否有重叠
- 非 level 0的,则使用 二分查找 当前层的所有文件
- 还会检查 level 0、level 1 在其祖父层级(对应的就是 level 2、level 3中,是否重叠太多
- 默认的最大单个文件大小为 2M,如果一次重叠的数量 > 20M,PickLevelForMemTableOutput 会继续往更深层级查找
- 不过限制了最大查找层级为 2,这也是做了一个权衡
后台压缩合并过程
min、max-key在不同层级的查找

PickLevelForMemTableOutput的检测过程
参考
- Skip Lists: A Probabilistic Alternative to Balanced Trees
- Skip Lists: Done Right
- github index
- Bloom Filters by Example
- 漫谈 LevelDB 数据结构(一):跳表(Skip List)
- 漫谈 LevelDB 数据结构(二):布隆过滤器(Bloom Filter)
- 漫谈 LevelDB 数据结构(三):LRU 缓存( LRUCache)
- LevelDB源码剖析
- SF-Zhou’s Blog
- leveldb-handbook
- 庖丁解LevelDB
- rust使用
- LevelDB使用介绍
- LeveLDB维基百科
- dbdb.io的LevelDB介绍
- MariaDB的插件
- 书籍:精通LevelDB
- leveldb 实现解析
- POSIX™ 1003.1 Frequently Asked Questions (FAQ Version 1.18)
- Spurious wakeup
- Memory barrier
- Memory Barriers: a Hardware View for Software Hackers
- Bean Li的LevelDB文章汇总
- LevelDB设计与实现 - Compaction
- LevelDB设计与实现 - MVCC等