LevelDB SSTable
文件格式
doc/table_format.md 中介绍了 表格式
|
|
sstable 按照 4K大小,分为若干个 block,每个block除了数据外,还有压缩类型,CRC

footer 固定为 48个字节,因为采用了变长编码,如果不足长度,需要填充 0
|
|
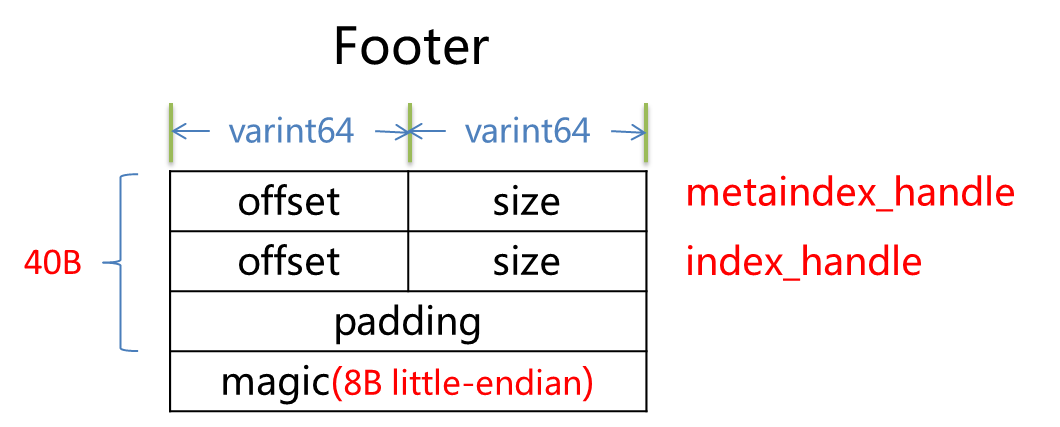
其中最后的magic number是固定的长度的8字节: 0xdb4775248b80fb57ull
BlockHandle 指向文件的某个位置和偏移量,用于自解释,一个 varint64 最多10个字节,所以 footer 包含了 4个最多40字节,不够级补 0
|
|
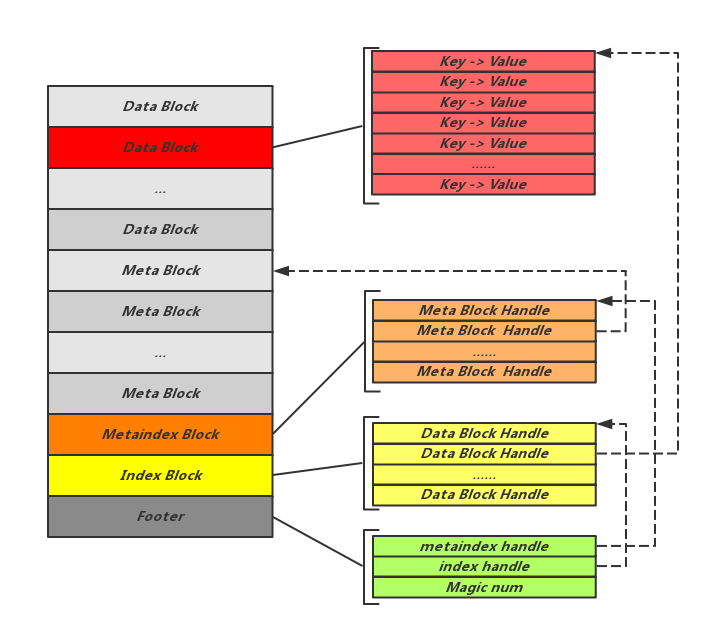
各个文件块的含义
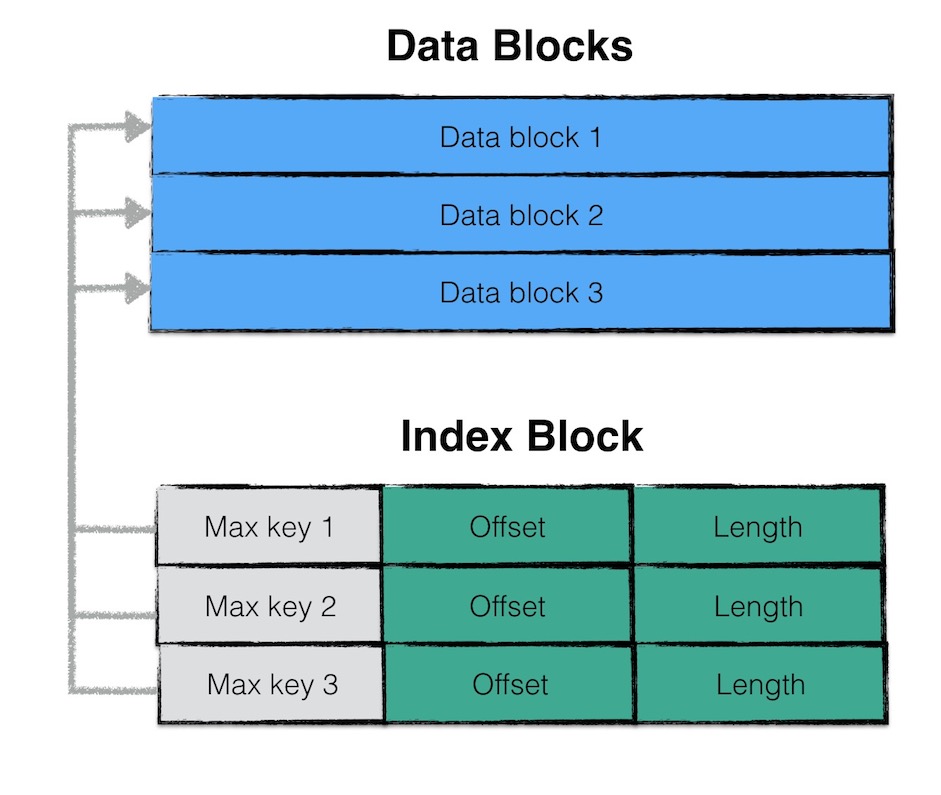
- Data Blocks: 存储一系列有序的key-value
- Meta Block:存储key-value对应的filter(默认为bloom filter)
- metaindex block: 指向Meta Block的索引
- Index BLocks: 指向Data Blocks的索引
- Footer : 指向索引的索引
文件块的物理格式,这里采用了前缀压缩的方式
先存储一个完整的key,后面的 key存储时,记录公有部分,只存非公有部分即可
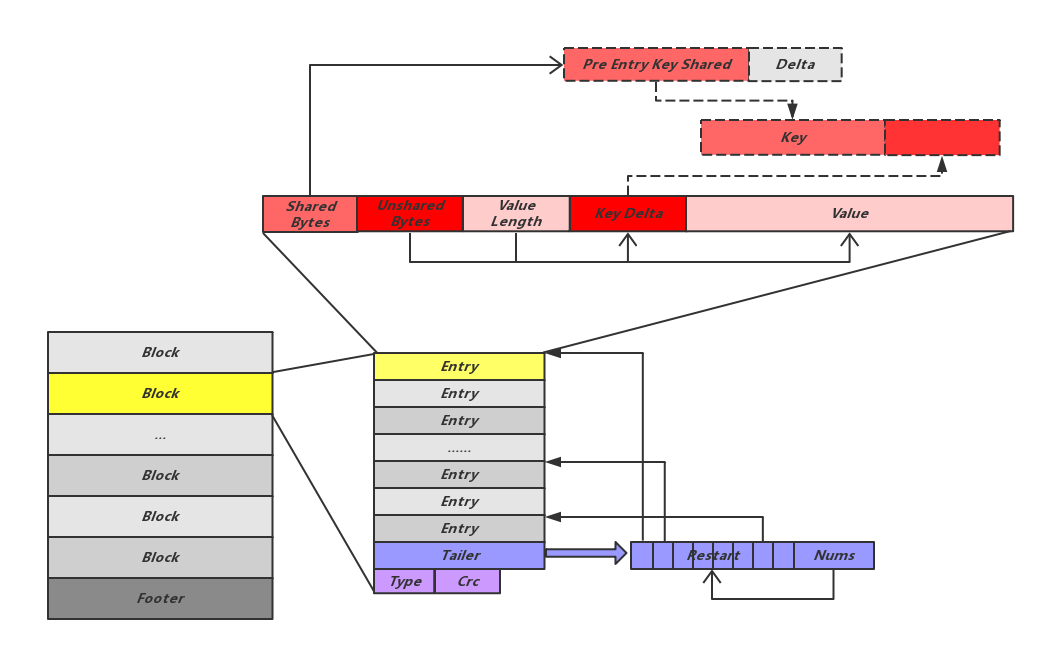
逻辑格式
数据块的构建
构建数据块的实现在 table/block_builder.cc 中
主要函数
|
|
Add过程
- 如果小于重启点阈值,默认为16,则求出当前 key 和 last_key 的公共部分长度
- 如果大于重启点,则直接将整个 key 的长度记录下来,并清空 重启点 counter
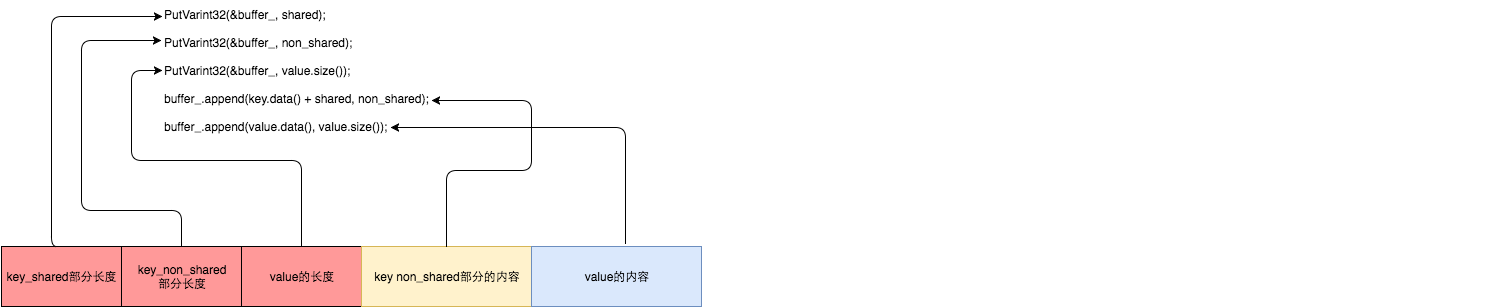
- 记录非公共部分,然后记录变长 int32的 shared、non_shared 长度,value长度
- 追加到 std::string buffer_ 中
- 更新 last_key_ 为当前 key 的公共部分
Finish
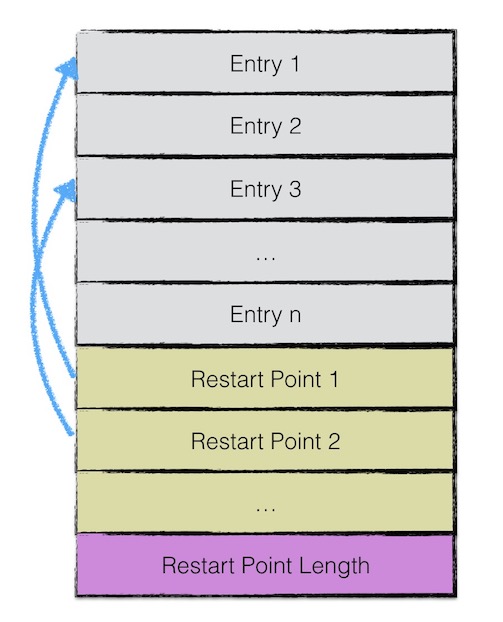
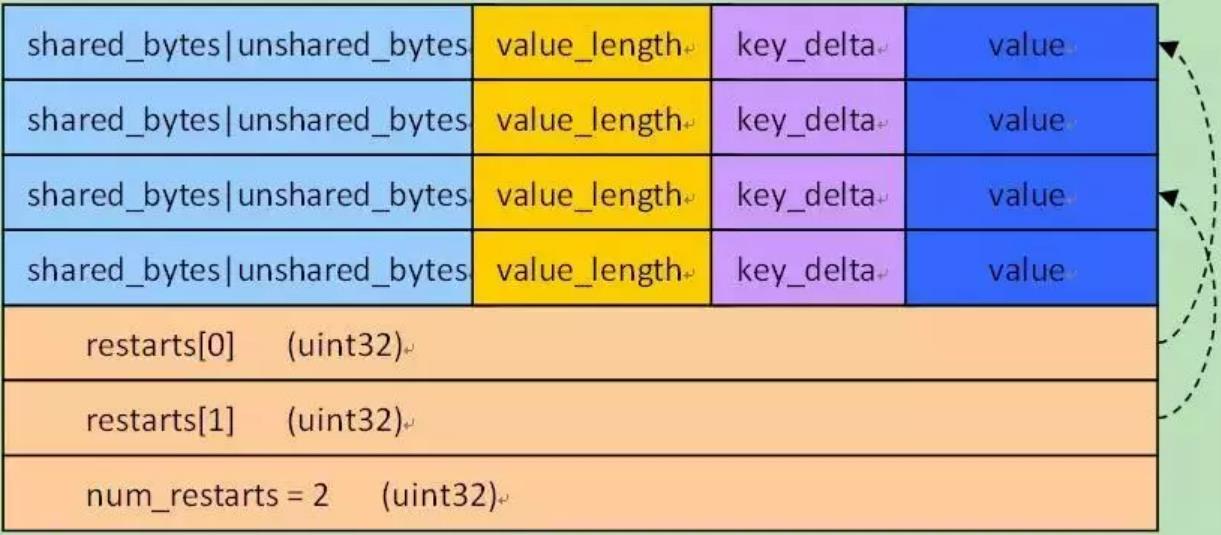
- 将所有每个重启点都记录下来,保存为 fixed32
- 记录所有充重启点数量
- 重启点变量:std::vector<uint32_t> restarts_; // Restart points
- 重启点变量中记录的是长度,对应的就是 key-value 的偏移量
数据块的组织
key_shared、non_shared,value的组织结构
数据的查找
|
|
查找入口
|
|
- 这里会在 重启点中,做二分查找
- 找到key < target的最后一个重启点
- 找到后,跳转到重启点
- 自重启点线性向下,直到遇到key>= target的k/v对
索引的构建
索引的构建实现,在 table/table_builder.cc 中
这个文件中的 主要函数为
|
|
Add流程
- 上一个块的最后一个 key,和当前要写入的(也就是后面一个块的第一个 key),计算这两个 key非分割
- 假设上一个块的最后一个key是:“the quick brown fox”,当前的块第一个key是:“the who”
- 分割的key就是 “the r”,正好比"the qu…" 的"q" 的 ASCII + 1
- 如果上一个key 正好是当前key的前缀,那么直接返回 上一个key
- 增加到 索引块中
- 根据情况增加 filter块
- 将 last_key 设置为 当前key,为后面做准备
- 总数量++,写入到 data_block 中
- 如果大于阈值,则 flush
Flush流程
- 调用 WriteBlock 写入数据
- 如果写成功,则将 pending_index_entry 设置为true,后面再写新的块,Add 流程的时候就会用到这个变量
- 刷新到磁盘,处理filter 块
WriteBlock,写入的格式为:
|
|
- 首先将 重启点写入到 buffer中
- 是否要压缩,只支持 snappy 压缩类型
WriteRawBlock
- 这个就是将待写入的内容,append到磁盘文件上
- 最后补充 5个字节的内容,1个字节是 压缩类型,4个字节是CRC
索引块的组织
读取
读取相关的实现在 table/table.cc
重要函数
|
|
读取返回的是一个 两层的迭代器
|
|
两层迭代器中的两个变量
|
|
Open过程
- 调用系统的文件 API,随机读 Footer 部分
- 读取 index block,读取 meta block,并设置对应的变量保存
ReadMeta过程
- 读取 meta 部分的 block,封装成一个 Block 对象
- 创建一个两层迭代器,读取 meta中的 filter
- 读取第一个 filter block块,封装为 BlockContents 对象
- 再在第一个 filter block的基础上,创建 FilterBlockReader 对象
BlockReader过程
- 这个就是调用系统的 文件API,随机读数据部分
- 先 new 一个固定大小的buffer,然后读进去,再 CRC检查,并确定压缩类型,看是否要解压
- 最后封装到 BlockContents 中返回
- BlockContents 中包含了一个 Slice,数据就放在这里了
InternalGet过程
- 先创建一个两层迭代器
- index 迭代器根据 key,返回数据块迭代器
- 在数据库迭代器上如果有 filter,则检查 这个key是否匹配 filter,也就是 bloom-filter是否匹配
- 匹配的话,则读取这个数据块,跳转到对应的位置,具体处理逻辑是一个回调函数,回调函数内处理 key,value
- 检查 status,并返回
参考
- github index
- Bloom Filters by Example
- 漫谈 LevelDB 数据结构(一):跳表(Skip List)
- 漫谈 LevelDB 数据结构(二):布隆过滤器(Bloom Filter)
- 漫谈 LevelDB 数据结构(三):LRU 缓存( LRUCache)
- LevelDB源码剖析
- SF-Zhou’s Blog
- leveldb-handbook
- 庖丁解LevelDB
- rust使用
- LevelDB使用介绍
- LeveLDB维基百科
- dbdb.io的LevelDB介绍
- MariaDB的插件
- 书籍:精通LevelDB
- leveldb 实现解析
- POSIX™ 1003.1 Frequently Asked Questions (FAQ Version 1.18)
- Spurious wakeup
- Memory barrier
- Memory Barriers: a Hardware View for Software Hackers
- Bean Li的LevelDB文章汇总
- LevelDB设计与实现 - Compaction
- LevelDB设计与实现 - MVCC等
- leveldb源码剖析 系列
- HBase file format with inline blocks (version 2)