深入数据库系统: History of Databases
原文 https://15721.courses.cs.cmu.edu/spring2023/papers/04-olapindexes/hentschel-sigmod18.pdf
背景
相关资料
论文总结
课程总结
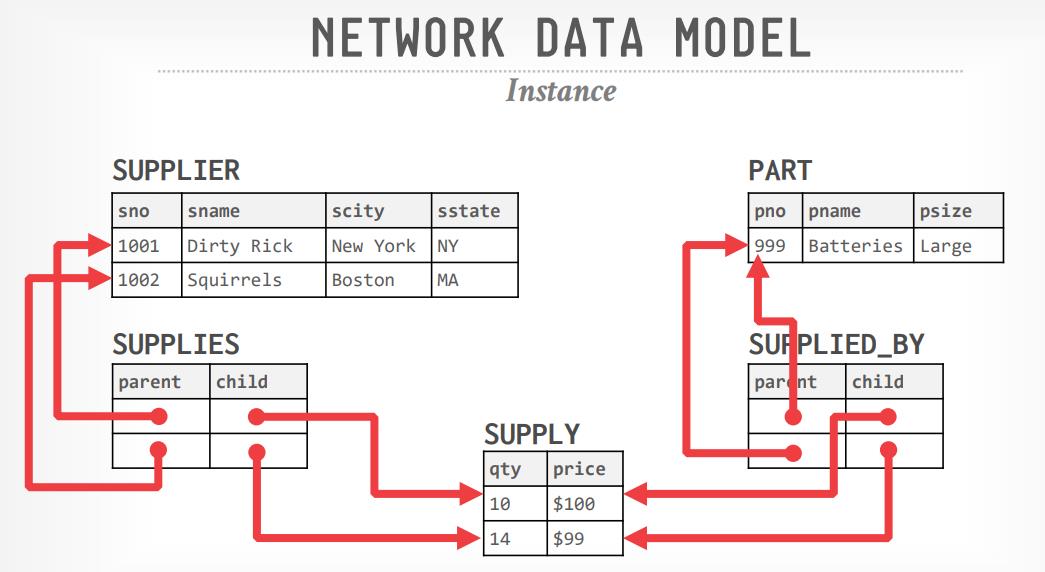
网络模型
- 1960年代,Integrated Data Store IDS,GE开发的后卖给Honeywell
- 网络模型,一次一个tuple
- 1960年代,CODASYL,网络数据库查询语言
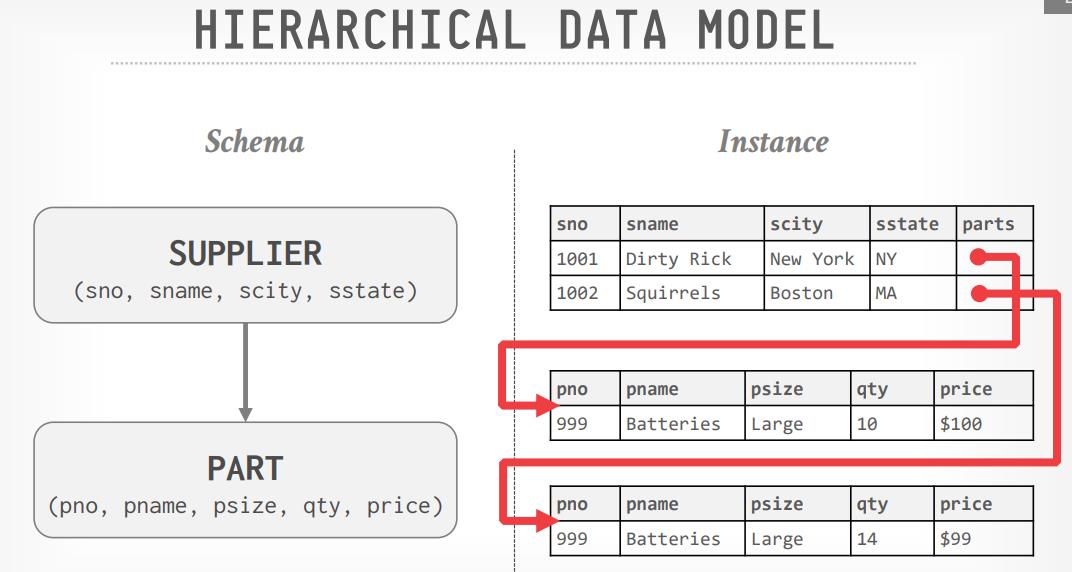
层次模型
- Information Management System IMS
- 为阿波罗登月计划开发的维护采购订单的数据库
- 层次数据库,逻辑、物理紧耦合结构
- 一次查询一个tuple
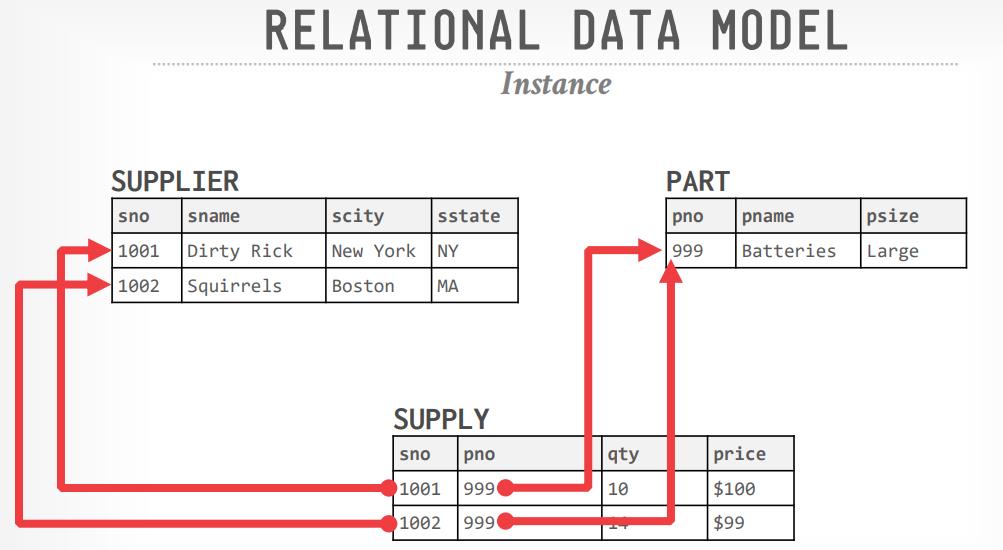
关系模型
- Codd 是 IMB研究院的数学家,他发现每次数据库模型变更,或者布局改变后,都需要重写逻辑
- 用简单的数据结构存储数据集、访问数据通过高级别API
- 物理存储、逻辑实现分离
1970年代关系模型先驱
- Peterlee Relational Test Vehicle – IBM Research (UK)
- System R – IBM Research (San Jose)
- INGRES – U.C. Berkeley
- Oracle – Larry Ellison
- Mimer – Uppsala University
- 三位先驱者:Gray、Stonebraker、Ellison
1980年代
- 关系模型 vs 网络模型 争论中,前者获胜,IBM推出商业产品
- SEQUEL 演化成 SQL 标准
- Oracle 赢得数据库市场
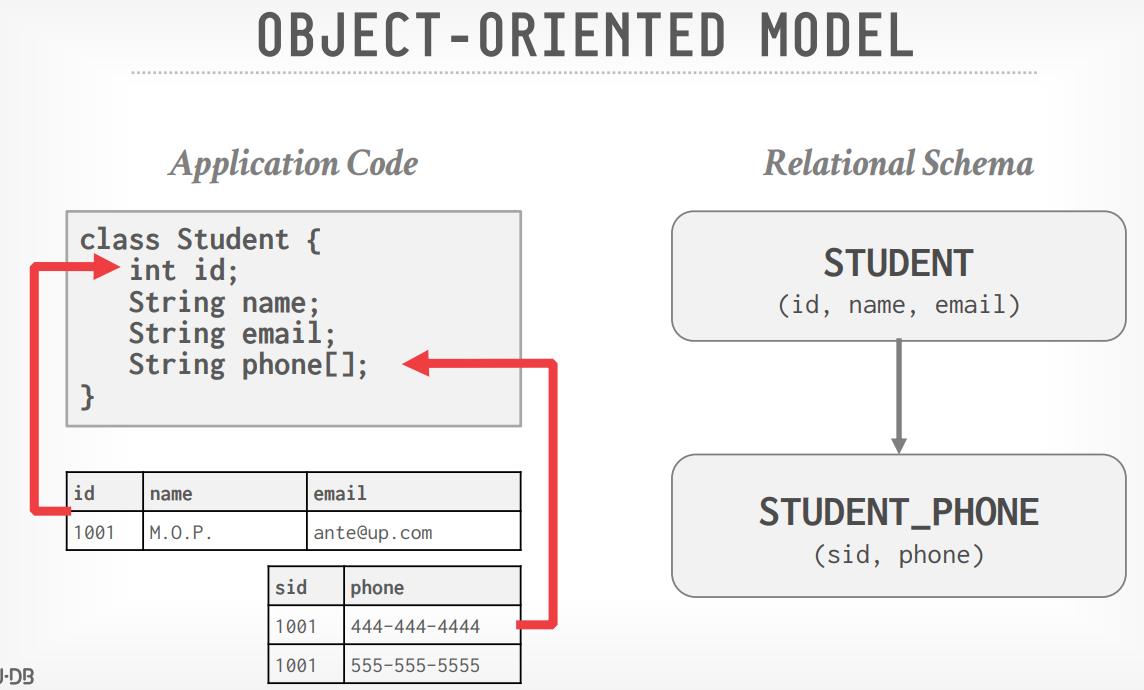
- Stonebraker 创建了 Postgres,一个对象关系 数据库
- 为避免对象、关系阻抗不匹配,出现了一批面向对象数据库
- VERSANT、ObjectStore、MarkLogic
1990年代
- 没有什么重大进展
- 微软 fork 了 Sybase,创建了 SQL Server
- mSQL 的替代者 MySQL
- PostgreSQL 增加 SQL功能
- SQLLite 在2000早期创建
- 一些数据库引入了预计算的 data cubes,加速分析
2000年代
- 互联网的出现,数据库支持的并发量激增
- 商业数据库太贵了,出现了很多开源产品方案
- 很多厂商开发自己的中间件,来扩展数据库节点
- 数据参数,支持 OLAP 场景
- 分布式、shared-nothing、都是闭源的
- 列存格式
- 相关产品:NETEZZA、Greenplum、PARACCEL、DATAllegro、monetdb、VERTICA
- MapReduce 系统,谷歌开源的论文,雅虎开源的 Hadoop实现
- 由于太底层,后面出现了很多SQL的高层级支持,Hive
- Nosql,无模式、非关系模型(文档、KV、列簇)、无ACID保证、API替代SQL,都是开源产品
- 相关产品:HBase、DynamoDB、mongoDB、redis、RethinkDB、CouchDB、cassandra
- riak、Couchbase、ravendb
2010年代
- NewSQL、支持SQL、ACID,天然分布式
- 相关产品:Spanner、MemSQL、H-Store、voltdb
- TiDB、CockroachDB、YugaByte
- Clustrix、noudb、foundationdb、codefutures、scalebase
- 云数据库,database-as-a-service
- 相关产品:snowflake、redshift、dynamoDB、aurora
- Spanner、Azure SQL
- shard-disk架构,存储计算分离,偏向日志结构方式,data lake
- 相关产品:apache Drill、presto、druid、redishift、snowflake
- impala、spark、pinot、trino
- 图数据库、类似CODASYL的查询语言,图查询API,SQL2023也支持了图查询语法
- 相关查询:neo4j、mem-graph、tigerGraph、nebulaGraph
- JanusGraph、IndraDB、Dgraph、TerminusDB
- 时序系统,用于支持时序、事件数据
- 这些系统的设计对数据分布和工作负载查询模式做了深入的假设
- 相关产品:influxdb、ClickHouse、TimeScale、GreptimeDB
- VICTORIA METRICS、Prometheus
- 特殊主题系统
- 嵌入式数据库、多模型数据库、硬件加速、数组/矩阵/向量数据库
2020年代
- 区块链数据库
- 带有增量日志checksum maerkle tree的区中心分布式系统
- 使用拜占庭容错算法 BFT,确定要追加到日志的下一个条目
- 不能使用传统 DBMS 的验证和外部身份验证 来解决
- 相关产品:fluree、BIGCHAINDB、Condensation、CovenantSQL
不同种类的数据库不断扩展自己的能力边界,于是各种特定类型的数据库边界变得越来越模糊了
除了 Redis,其他各种NoSQL 都支持 SQL了
关系模型、声明查询语言对数据引擎更好
数据库历史和论文总结
What Goes Around Comes Around
- 介绍了数据模型发展的 35年历史,一共有9种模型
- 网络模型、层次模型、关系模型这几个是主导的
- 实体关系、R++、语义模型、OO、对象关系,是对关系模型的一些补充
- schema-last 是个很不错的补充
- 严格机构化、严格结构+半结构、半结构、文本数据
- 第1、第2都有很多场景,第4 用于文本信息检索
- 第3 种场景实际不多
历史的轮回
- 数据模型的发展历史,从复杂、到简单,简单模型最后获胜
- 可见简单模型、逻辑-物理结构、高层级API 是非常有用的
- 随后就是一系列的功能增强,但这些没能吸引市场,因为增加了很多复杂度,但却没能带来更多的好处
- 比如 XML 倡导者 vs关系模型,就很像 关系模型 vs CODASYL
- 只有 UDF,以及自定义访问方式 能吸引人注意
- 以及 code in data base、schema last 真正新的发明
- 大多数新发明则是对过去的模型的重新发明而已
总数据库的历史看
- 最初是有三种形态的数据模型,网络模型、层次模型、关系模型(出现更靠后)
- 网络模型和层次模型都有它的优点,相对于关系模型,这两个最大的问题是 逻辑数据、物理数据耦合
- 也没有提供一种高层级别 API
- 所以关系模型出现后,提供了一种更简单的数据结构、更高层级别API、更重要的是 物理、逻辑数据解耦
- 很快关系模型就占据市场主导地位了
- 商业市场的 IBM、Oracle,以及学术界的 PostGRE都相继出现,但这个时候还是商业主导
- 之后出现了各种对关系模型的补充
- 实体关系模型、R++模型、OO模型、对象关系模型,这些模型都不能算主导地位
2000年之后
- 互联网的出现,使的数据库并发大增,商业数据库显得太贵了,开源 + 自研就称为主导了
- 这时候出现了一批开源的 NoSQL数据库,他们只能解决一类问题,并对关系模型、事务做了减法
- 这些数据库都是互联网头部公司搞出的开源产品,加上MapReduce的出现,看起来在数据库之外可能要有一条新的路线
- 但是过了十年后,这些NoSQL还是缺乏一些基本保障、纯MapReduce 太底层了,跟最初的 CODASYL 一样是跟底层紧耦合的
- 所以从历史看,这就是一个错误的选择,高层级 API、尽可能的抽象是数据库发展的一个必经之路
2010年之后
- NewSQL的出现,因为有更大的业务需求,所以一定要分布式,但是关系模型还是很好用的
- 一个大的趋势是单纯的自建Hadoop 集群成本太高,远不如云厂商的对象存储划算,在替代Hadoop 的同时,出现了存储计算分离
- 存储计算分离之后,就是各种云数据库,有云厂商的、有独立新兴公司、以及老牌公司转型的
- 此外基因数据库、流计算、图数据库、时序数据库、区块链数据库、向量数据库等等各种专业方向的数据库也出现了
- 随着业务规模的变大,各种更细分主题的主题的数据库也跟着出现,他们都用来解决一些特定场景的问题,而这些特定场景的市场也不小
可能以后会有更多的数据库,但是解耦、高层级 API 应该是一个不变的主题
每种数据库都会各自的解决场景,但又会扩大自己的领域,都会支持SQL,所以边界也模糊了
而关系模型,SQL这种声明式语言,则又进一步增强了
参考
- Charles Bachman
- Culliane Database Systems
- Paper: Derivability, redundancy and consistency of relations stored in large data banks
- Paper: A relational model of data for large shared data banks
- The difference between God and Larry Ellison
- Data Cube
- The (sorry) State of Graph Database Systems
- Duck PGQ: Efficient Property Graph Queries in an analytical RDBMS
- Merkle Trees