基于存算分离下的Elastic Query Engine
原文 https://15721.courses.cs.cmu.edu/spring2023/papers/02-modern/vuppalapati-nsdi22.pdf
背景
snowflake 基于云环境,创建的 OLAP 数据仓库,设计的动机包括
- 计算存储分离
- 多租户
- 高性能
传统的数据仓库使用的是 shared-nothing 架构,这种架构的问题是
- Hardware-workload mismatch:每个节点都是独立的配置,某些节点可能是高带宽低CPU,有些又是相反的,这样导致利用率就有问题,如果想配置起来不那么麻烦,则需要增加每个节点的配置,这样集群总资源需要更多,而且平均使用率则不高,花费也不小
- Lack of Elasticity,即使某个节点能匹配需求,他们的配置也是静态的,对于一段时间内大量的数据倾斜,CPU不断变化的场景也很难应对,这种架构一般是增加/删除一批机器,然后重新做数据shuffle,比如TeraData,这样不仅需要大量带宽也影响性能
shared-nothing这种架构适合比较明确的场景,比如在企业内部、政府机关,这种场景是可预测,使用多少资源,提前大概能知道
但现在很多场景都是很难预测的,而且场景越来越多,比如 应用日志、社交媒体、web应用,移动系统等等
这就好比是原来 B端 的场景,迁移到了 C端,场景丰富了很多就不适用了
snowflake 为了克服这些问题,提出了 存储计算分离的架构
其存储层使用的是
- Amazon S3
- Azure Blob Storage
- 谷歌云等
除此之外,还有两个系统设计关键
- 自定义的存储系统,用来管理查询期间计算节点之间的 临时/中间数据
- 因为直接使用对象存储来作为中间数据,性能和延迟可能跟不上
- 临时存储系统也作为缓存使用,用来弥补 存储结算分离后的性能问题
为了可能要做的
- Decoupling of compute and ephemeral storage,现在计算和临时存储是紧耦合的
- Deep storage hierarchy,包含内存、SSD两层临时存储,更多的层次如何利用和管理类
- Pricing at sub-second timescales,云厂商提供了亚秒级计费,未来snowflake也会跟进,设计上是一个挑战
公开的测量报告
https://github.com/resource-disaggregation/snowset
架构
snowflake 的数据包括三种
- 持久数据,用户的数据就存在这里,需要有持久性,可靠性保证
- 中间数据,由查询操作产生的,一般是短生命周期的数据,需要有高吞吐和低延迟保证,这个是自研的一套分布式临时存储系统
- 元数据
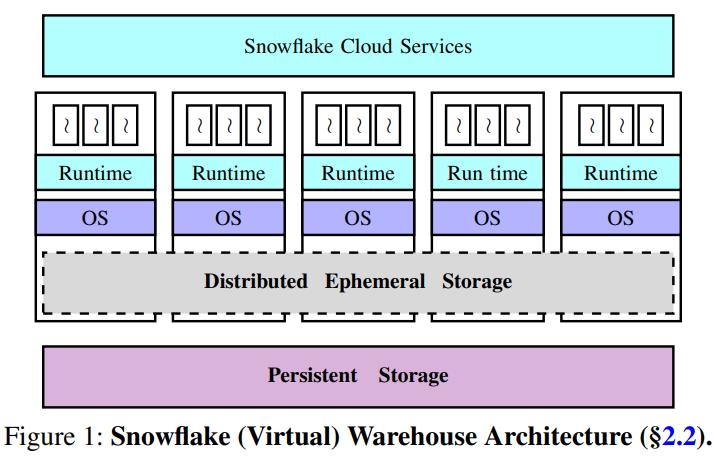
整体架构如下,分为四层
- 一个中心化的服务,用来处理端到端的查询执行
- 集中控制层用来处理:访问控制、查询优化、查询计划、调度、事务管理、并发控制等
- 这一层设计用来支持多租户的,并且有容错保障
- 计算层
- 每个节点都是一个 AWS-EC2,按需计费
- 维护了一个预热池避免了启动时间,每个节点VM之上都可以运行多个查询
- 分布式临时存储层
- S3 不提供低延迟、高吞吐的特性,这个组件是snowflake自研的
- 临时存储跟VM 在一起,并随VM的 增加/销毁自动扩展
- 这里不需要考虑数据分区,shuffle等,每个VM的临时存储都是独有的
- 持久数据存储层
- 数据存储在 S3,文件是不可变的,甚至不能append
- 表数据文件被水平分区,到大的、不可变的文件中
- 每个文件内,独立的值和列被分组到一起,按照 PAX存储
- 每个文件的头包含了每个列的起始offset,方便S3 的部分读取
查询执行对用户的 SQL 做解析,优化
会产生一些执行任务,并将他们调度到 VM 上
每个执行任务都会 读写临时存储、也会读写远端持久存储
CS 控制节点会监控 VM 的状态,收集他们的数据,一旦执行完就会拿到 VM 的返回数据,并响应给客户端
Dataset
控制节点会收集 所有层的统计信息,以便进一步的做优化
统计信息包含 7KW 个查询(14天内的),去掉敏感信息,都已经开源了
https://github.com/resource-disaggregation/snowset
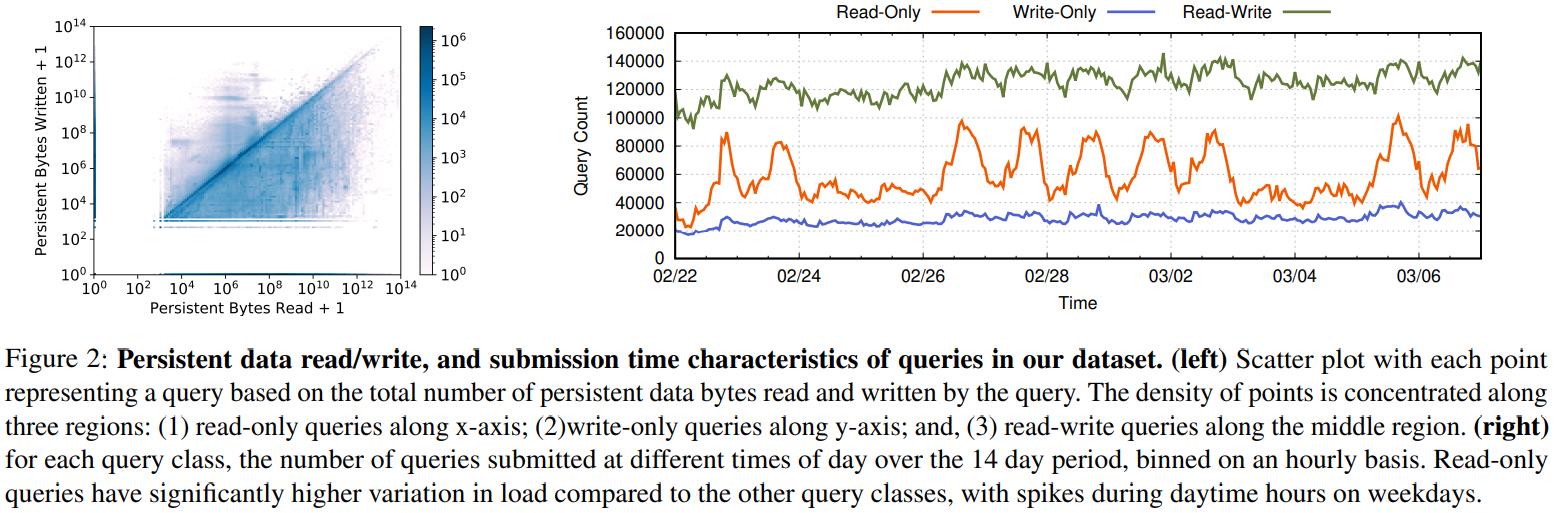
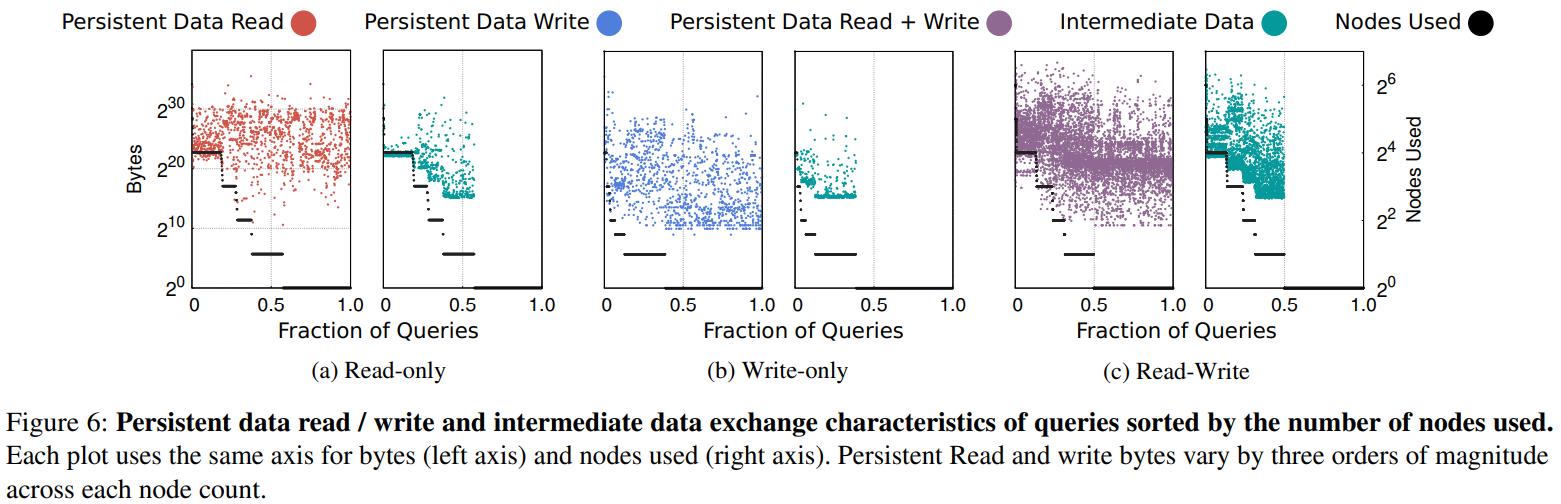
从下图可以看到,左边是 读、写 持久数据的情况
右边是读写趋势,读明显是工作日的白天很高,晚上就降低了
28%是只读的,13%是只写的,59%是读写的
临时存储系统
自研临时存储的原因
- S3 无法做到 低延迟、高吞吐
- S3的文件存储语义太强了,保证了持久和高可用,但临时存储不需要这么强的保证
临时存储分为两层
- 优先选择本地内存,尽可能全部放到内存中
- 如果内存放不下,则溢出到本地 SSD
- 如果本地 SSD也放不下,则溢出到远端存储,S3 中
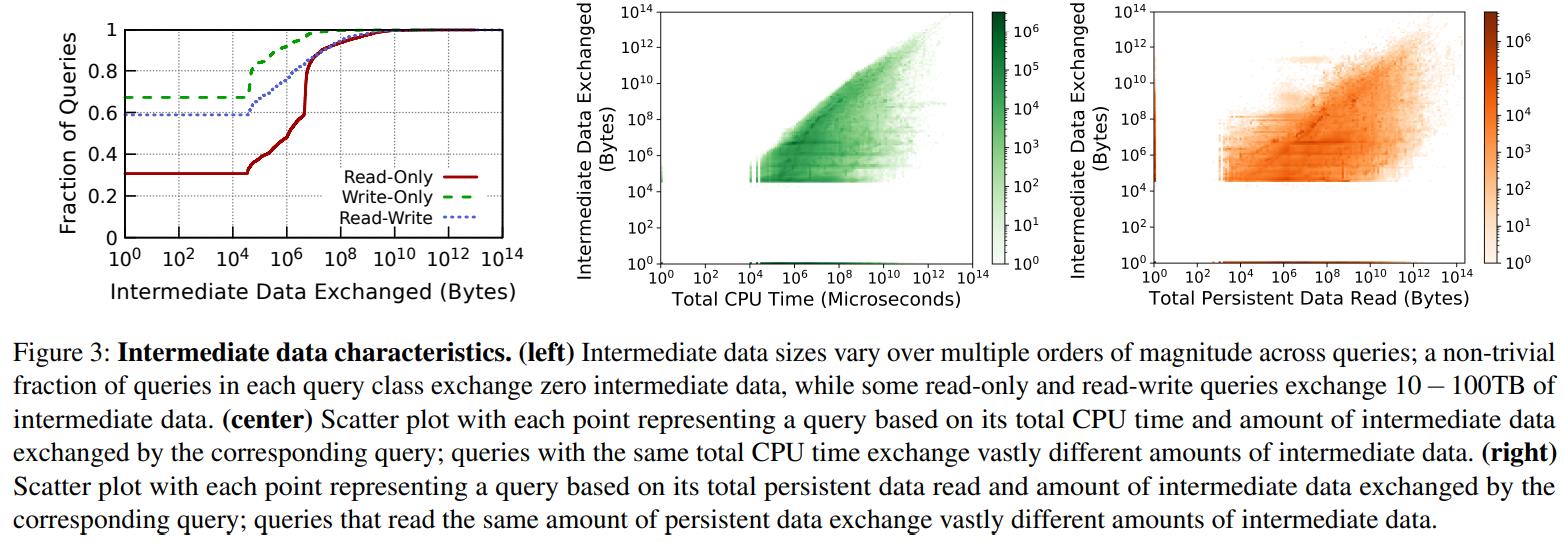
从下图中可以看到 临时存储的读写变化
- 不同请求之间的临时存储的需求变化非常大,有的需要很大,有的则没有
- 具有相同总CPU时间的查询交换的中间数据量相差很大
- 读取相同持久化数据量的查询交换的中间数据量相差很大
因为计算资源和临时存储之间需求变化很大,很难找到完全匹配的
所以要实现更细粒度的控制,同时实现 高利用率、高性能
就需要 计算节点、临时存储之间的解耦合,不过目前还没做到
持久文件也有缓存机制,这里使用的是一致性hash实现的,所以并不是每个节点上都有 持久数据缓存的
由于 VM扩容会导致 缓存数据需要重新分布,所以做了延迟的 一致性hash优化,避免重分布问题
另一个设计要点是,要保持临时存储的数据,持久缓存的数据一致,这是通过缓存透写实现的 write-through cache
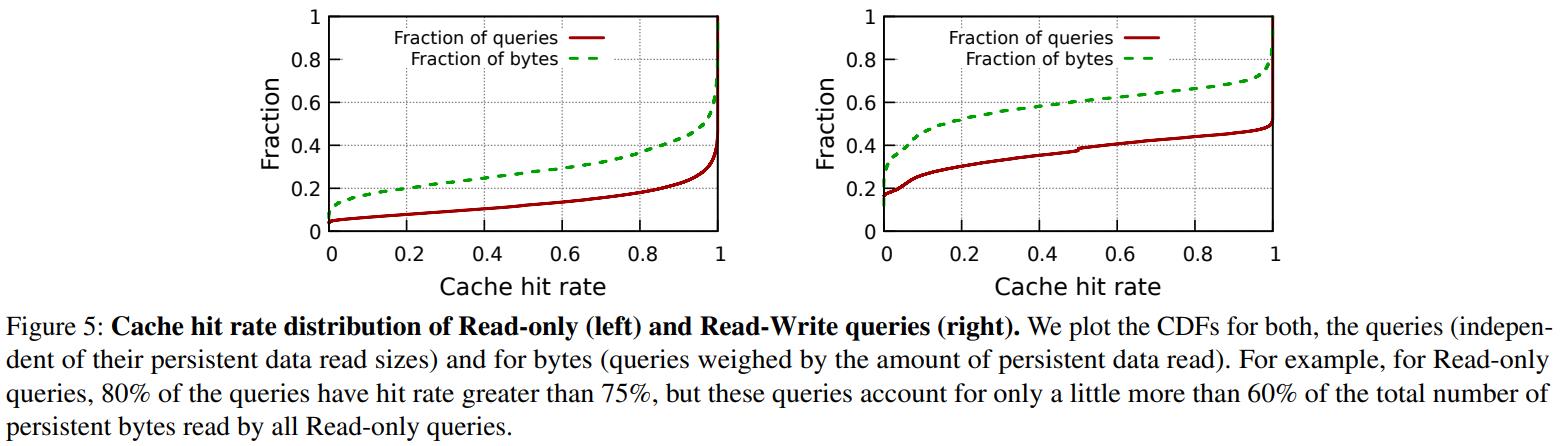
下图是 临时存储和持久存储的 I/O 流量分布

从下图可以看到,大约75%的 只读查询有 超过80% 的命中率
另一些未来要做的优化策略
- 需要在缓存命中率,以及I/O吞吐量之间权衡
- 尤其是多个请求公用的文件,应该被优先缓存
- 目前是三级存储,本地内存 LRU溢出到 SSD,本地 SSD LRU溢出到远程持久存储
- 为了更好的利用这三层存储,缓存机制需要重新设计
查询调度
位置感知的任务调度
- 将持久文件分配给计算节点,用的是 一致性hash
- 为了最大化本地性,这里也是用一致性hash,将任务分配给 持久文件所在的节点上
- 下图解释了持久文件读、写,中间文件交互的查询特点
工作窃取
- 为避免计算节点出现倾斜,允许 对task 做窃取
- 已经完成的节点,可以直接获取未完成节点的工作
- 对于持久爱文件,从远程持久文件中直接拉取
进一步的工作
- 一种极端是将所有的查询调度到所有节点上,不过这样会加剧网络交互的开销
- 另一种极端是将所有task 调度到一个节点上,这增加了读取持久文件的开销
- 所有任务调度都是在这两者之间做一个平衡
资源弹性
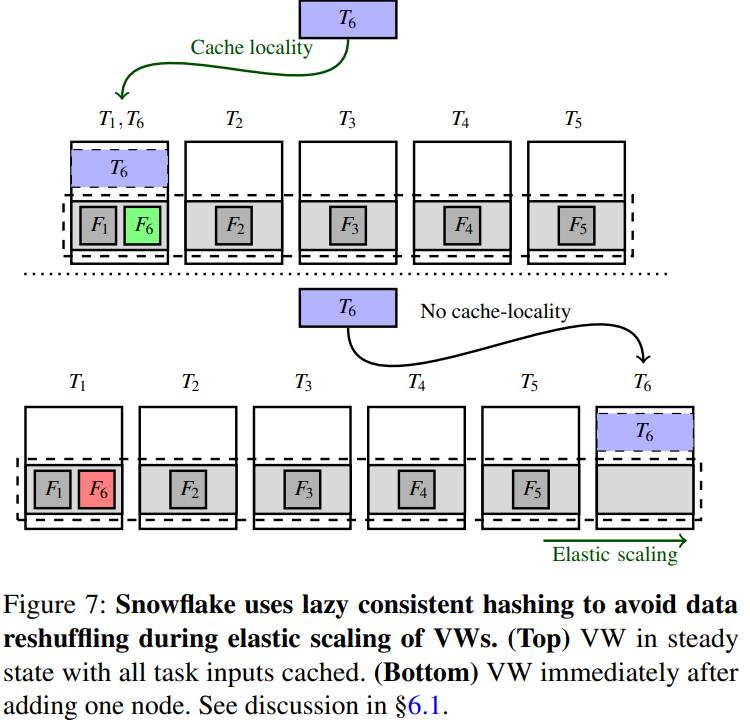
惰性一致性hash
- 缓存的持久文件是基于一致性hash的,如果 VM 节点扩容或者缩容,就会碰到 shared-nothing 一样的问题,缓存文件需要重新 shuffle
- 为了避免这种情况,使用了 延迟的一致性hash策略
- 下图中,5个任务在 5个节点上,同时有 6个 缓存文件
- 当节点扩容时,缓存文件并不是立即加载到 VM 上,而是等需要的时候,再从远程持久存储上读取
- 此时节点 1上的缓存仍然还在,但不会被读取了,之后就自动失效了
- 节点6 在使用的时候,获取了远端的 缓存文件
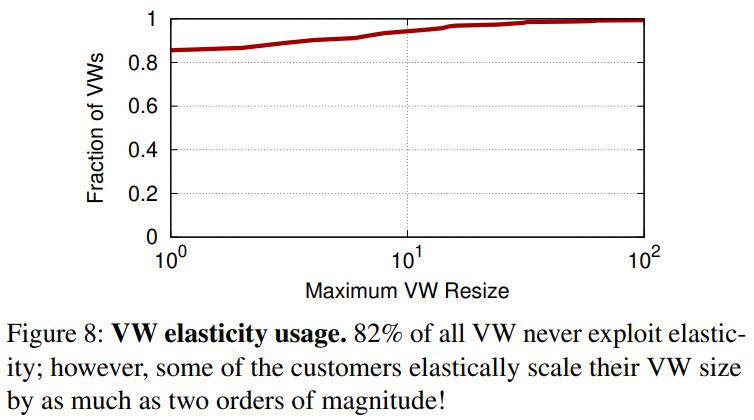
下图是 20% 的用户使用了 VM弹性伸缩机制
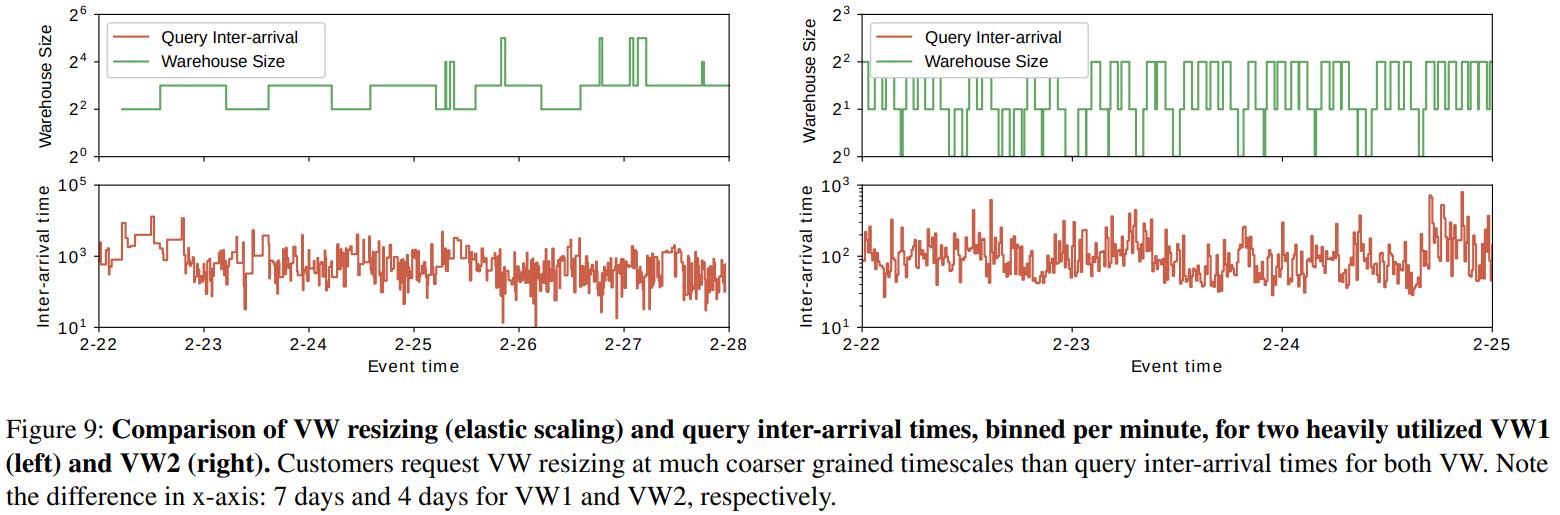
对比 VM resize 和请求到达内部的时间
未来工作
- 让更多的客户使用 VM 弹性伸缩机制
- 查询达到时间的变化粒度,远大于 VM resize 的粒度,需要进一步优化调整
- 再进一步就是 serverless,但是 snowflake 的很多数据是安全敏感的,目前看是缺乏隔离机制保证
- 甚至考虑要自己实现一套 无服务机制,这方面还在探索中
多租户
原先是采用了隔离机制,每个 虚拟仓库 独占一堆节点
然后采用预热机器的方式免去启动加载的时间,但是这样的话利用率就上不去了
下图中前面两排能发现,CPU的利用率还可以,但其他的不行,另外不同 VM 在不同时间段的资源使用率也不同
现在云厂商推出了耕细粒度的按秒计费,这种方式就不行了
预先预热的话,只要一小时内有人使用就可以扣费,现在按秒计费,这段周期内可能没人用就没法收费了
这就要调整架构策略,使用完全共享的资源架构

从这个图看,客户端使用的资源是突发的,也不好预测
如何在 细粒度的控制之上,实现更好的资源利用率
两个挑战 第一个问题
- 因为临时存储包含 缓存持久数据,中间数据
- 需要一种机制来同时管理这两种类型数据,如何在多租户之间保持这些数据的隔离
- snowflake参考了这两个文献
- a dynamic multi-tenant key-value cache. In ATC, 2017
- Near-optimal, fair cache sharing. In NSDI, 2016
- 此外如何预测缓存有效性也是一个挑战,将空闲的缓存给其他租户使用
- 需要确保移除这个缓存条目后,对当前租户不受影响,目前仍然是一个开放问题
第二个问题
- 因为缓存文件是通过一致性hash落到 一个全局地址空间
- 如果单纯的增加临时存储空间,则会影响其他租户
- 结果就是导致缓存未命中,性能下降
- 为解决这个问题,需要使用私有的地址空间
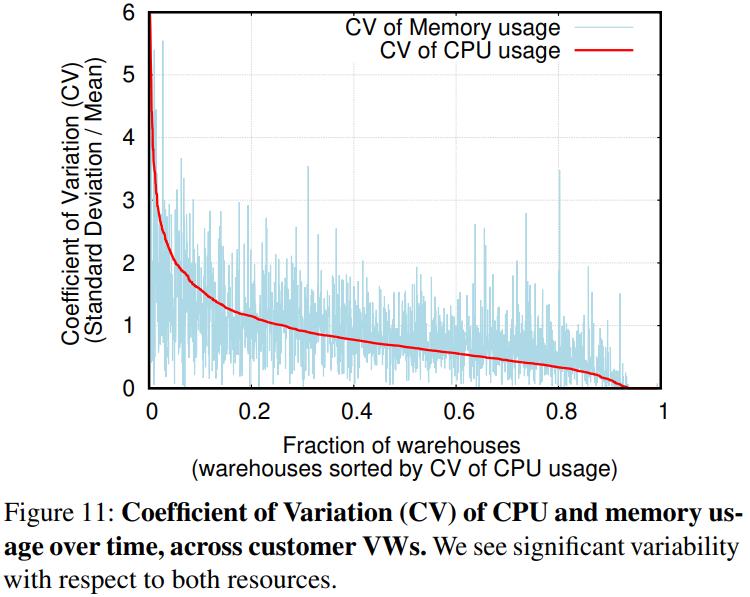
从图11 来看,CPU 和 内存的资源使用情况是不同更多,这是两个维度的指标
所以需要把 CPU 和内存也独立开来,相关的研究资料
- Remote memory in the age of fast networks. In SOCC, 2017.
- Network requirements for resource disaggregation. In OSDI, 2016.
- Efficient memory disaggregation with infiniswap. In NSDI, 2017.
- 相关产品:ESX server、Memshare、FairRide