列存 vs 行存,到底有什么不同?
原文 https://15721.courses.cs.cmu.edu/spring2023/papers/03-storage/p967-abadi.pdf
背景
列存对于 OLAP 来说更好,其性能比 行存有数量级提升,因为列存能更有效的利用I/O,对于只读查询非常好
所以给人们一种假设,如果是行存系统
- 将schema垂直分区,如将所有的列分区为 (表key,属性),于是行存也有了列存的特性
- 或者对于所有列加上索引,这样每个列访问就是独立的了
- 对于特定的查询,增加物化视图
但这种假设是不对的 本文演示了各种列查询对性能有提升的技术
- 向量化查询技术
- 压缩
- 新的join 算法
想要让 行存实现列存的一些性能,需要在存储层、查询执行器都做修改才行 讨论的行存系统
- MonetDB
- C-Store
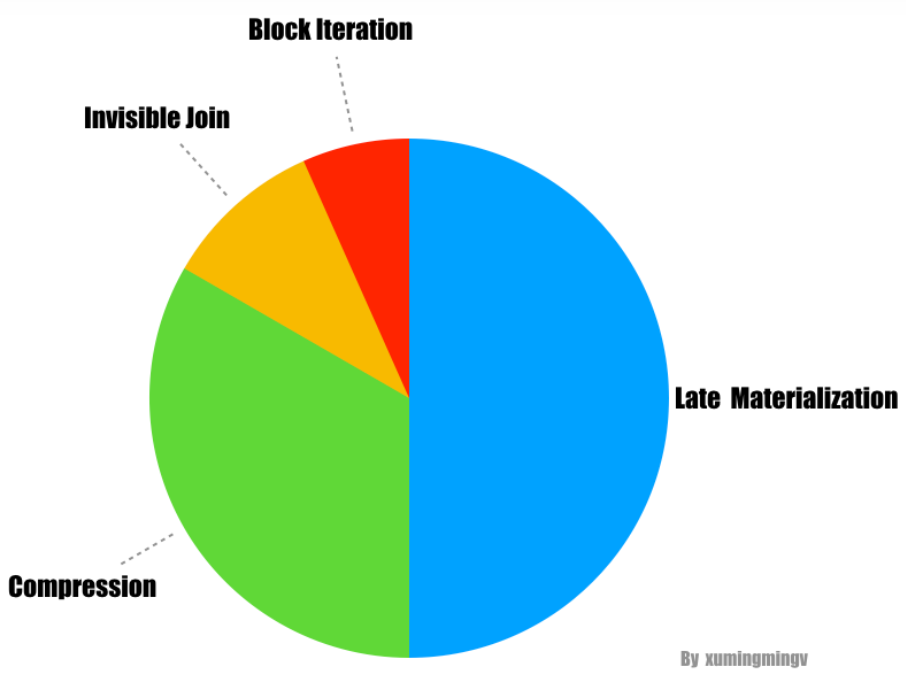
列存中使用以下技术可以大幅度提升性能
- Late materialization,三倍提升
- Block iteration,约 1.5倍
- Column-specific compression techniques,数量级提升
- 新的优化算法:invisible joins,约 1.5倍
论文的贡献
- 在行存中模拟列存行为,并使用各种优化技术:索引、位图等来改善
- 一个新的join 优化算法 invisible joins
- 将延迟物化、压缩、invisible joins、向量化做拆解,看看他们对列存树仓的影响
使用的基准测试数据
使用的是 TPC-H 测试集,比例因子为 10,LINEORDER 表有 6KW 个记录

Figure 1: Schema of the SSBM Benchmark
分为四类查询,或者 四个航班
- 包含 1维的查询,3个
- 包含 2维的查询,3个
- 包含 3维的查询,4个
- 3个 3个列维度的查询
行列对比
行存
首先将一个表 按照每个列做分区,逻辑上一个表有 3 列, 例如,我们有如下的表:
| A | B | C |
|---|---|---|
| 1 | 2 | 3 |
| 4 | 5 | 6 |
| 7 | 8 | 9 |
我们可以按照以下方式进行垂直划分:
A 表:
| A | position |
|---|---|
| 1 | 1 |
| 4 | 2 |
| 7 | 3 |
B 表:
| B | position |
|---|---|
| 2 | 1 |
| 5 | 2 |
| 8 | 3 |
C 表:
| C | position |
|---|---|
| 3 | 1 |
| 6 | 2 |
| 9 | 3 |
行存中的每个列就完全独立了
在查询时,系统将使用这个 position 列来将来自不同列 但相同行号的值连接在一起
默认的 hash-join代价很高,作者尝试在每个表的 position列上添加聚集索引,强制使用索引连接,由于索引访问产生的额外 I/O,这导致比hash-join更慢
比如这样查询:
|
|
可以把 A 和 C 关联的同一行的列取出来
还有索引方式,比如将每个列都加一个索引
对于这种查询
|
|
如果只是在 age、salary 上加索引则不行
首先 age 这个是非聚集索引,然后找到主键,根据主键去 salary索引上提取值
所以这里要加一个联合索引 (age, salary),相当于是利用了覆盖索引
另外是根据每个场景的查询,预先创建一个物化视图,这样看会比前两种效果更好
列存
包括
- 压缩算法
- 延迟物化
- 块迭代
- Invisible Join
对于压缩算法,由于列存都是相同的列放在一起,比如name、电话等,本身就有很多相似性
列存更容易压缩,压缩比更高,而行存因为 name周围的值存在,影响了压缩效果
run-length 这样的压缩算法,可以直接基于压缩数据查询,可以进一步减少 I/O
比如这样的原始值
WWWWWWWWWWWWBWWWWWWWWWWWWBBBWWWWWWWWWWWWWWWWWWWWWWWWBWWWWWWWWWWWWWW
可以被压缩为
12W1B12W3B24W1B14W
延迟物化有这么一些好处
- 因为选择、聚合可以过滤掉一些数据,越往后可能提取的数据就更少,减少了 I/O读取
- 不同的列可能使用不同压缩算法,将他们合并在一起需要先解压,这样就需要更多的CPU
- 对于缓存行更友好,因为不会受到不相关元素的干扰
- 对于块迭代更好
早期物化
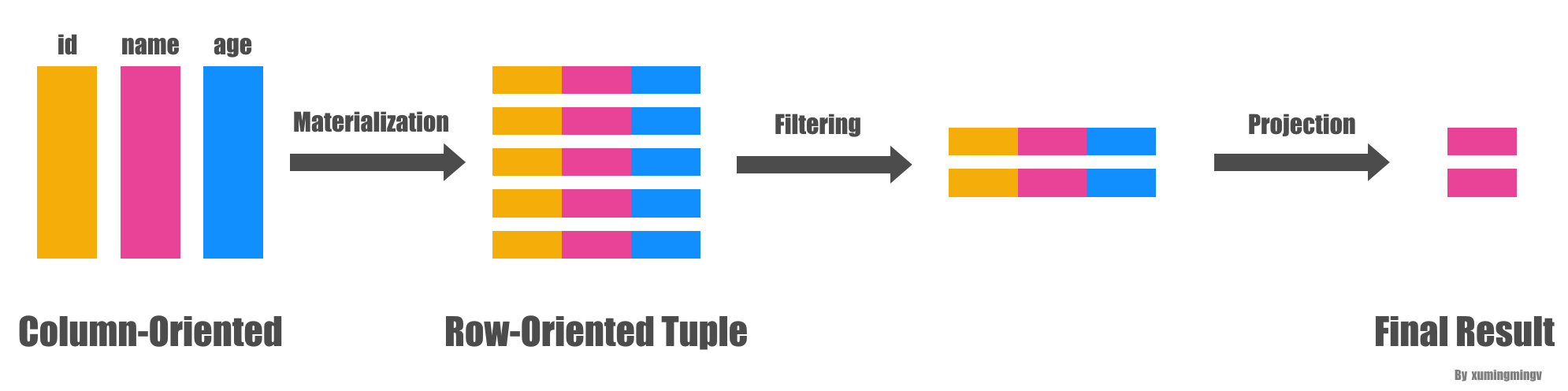
延迟物化
比如对学生姓名、年龄、性别,其中后两个值长度是固定的,用块迭代更容易处理
如果是行存则长度不固定,则整个tuple 长度也不固定,耗费更多
对于块迭代操作
- 行存需要读取一行然后再提取其中的某几列
- 列存直接基于同一列的值读取,然后发送给调用方
- 对于不需要的列则不提取
- 另外可以最大化并行处理
看不见的 join
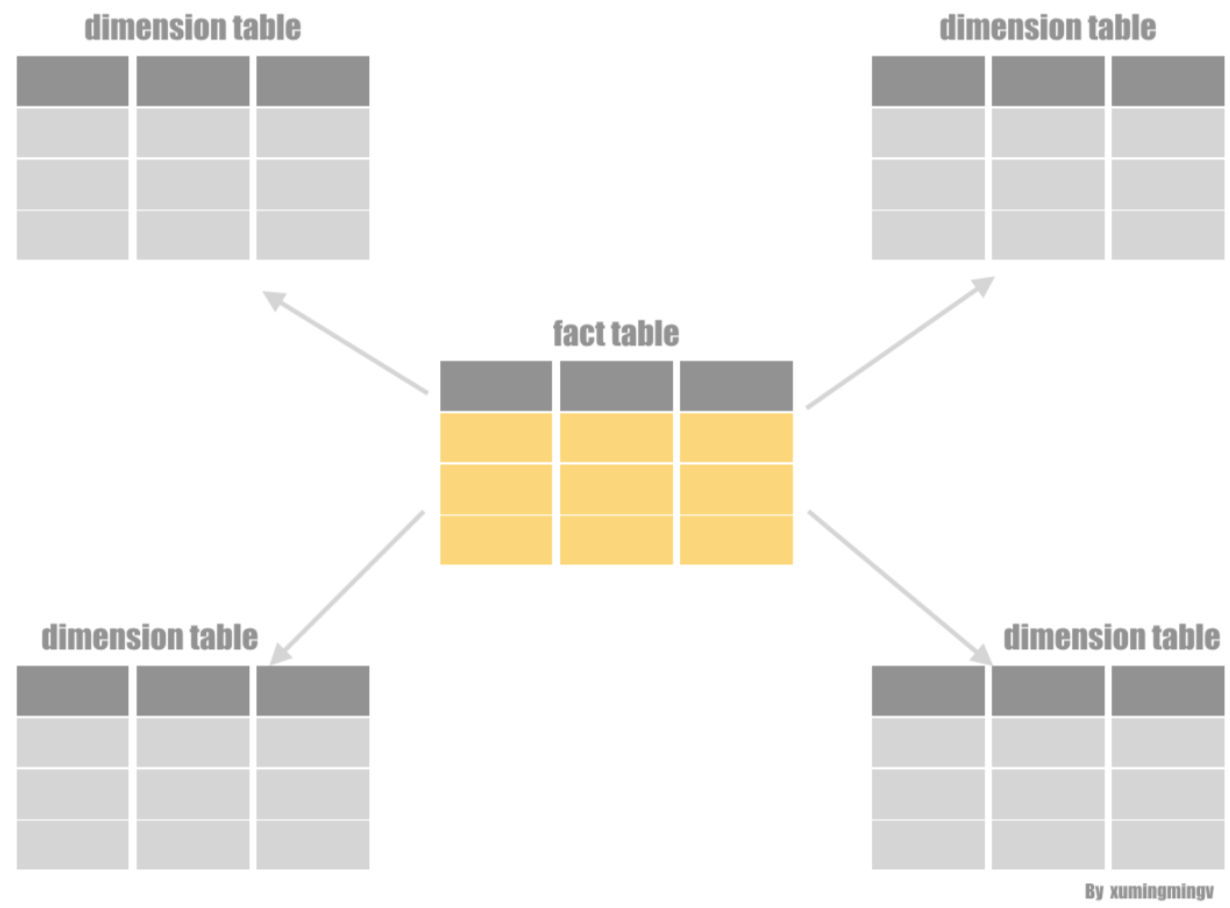
一个事实表 关联多个维度表,通过查询维度表上的谓词,来限制事实表的元素,之后再次查询维度表,再次过滤事实表数据
或者做一些聚合、计算、求平均值等
星型模型如下
|
|
两种 传统方式的缺点
- 按Selectivity依次JOIN:按照选择性从高到低的顺序进行join操作,需要在join前将表的行映射到内存中的元组,导致无法进行后期的延迟物化处理。
- 延迟物化:通过将join操作转化为在事实表的外键列上的谓词来实现后期物化,但需要从维度表中以乱序的方式提取分组列的值,因此效率不高
通过重写 事实表上的谓词,并通过管道的方式并行处理这些谓词,可以提升性能
这些使用了前面介绍的技术
invisible join的执行过程 第一步
- 每一个谓词都被应用在对应维度表,提取维度表中满足谓词条件的主键 key 的一个列表
- 根据这些 key 构建一个 hash table 能够用于测试一个给定的 key 是否满足谓词条件
- (该 hash table 足够小,以便于能加载进内存中,因为只包含了 key,并且一般维表比较小)
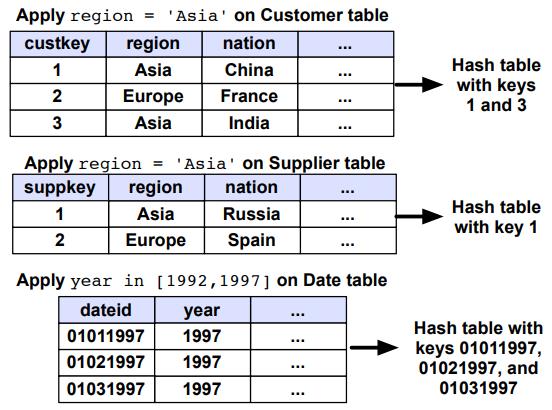
Figure 2: The rst phase of the joins needed to execute Query 3.1 from the Star Schema benchmark on some sample data
第二步
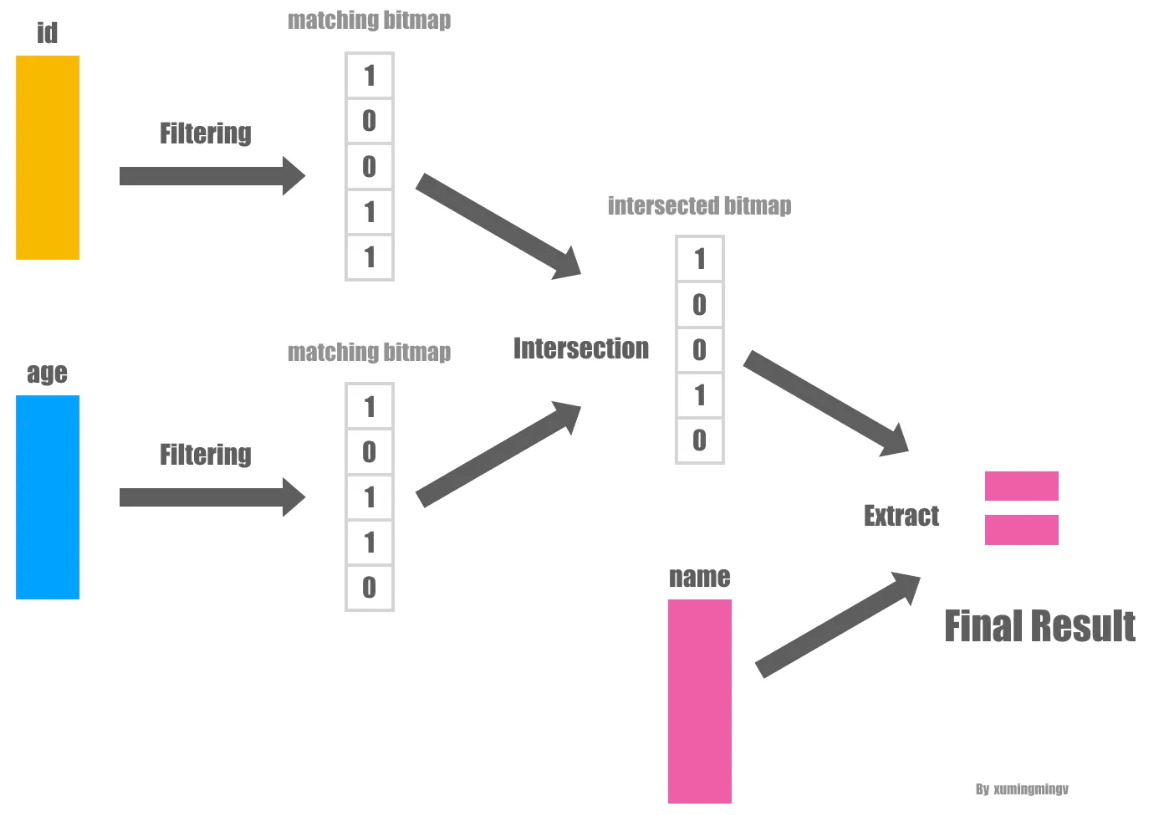
- 一个 hash table 都被用于提取事实表中满足相应谓词的 record 的位置
- 通过用事实表每个外键的值去探测 hash table,得到一个事实表中外键列满足谓词的列的 position 信息
- 然后将所有谓词的 position 列表联合起来求交集
- 得到了事实表的满足所有谓词的 position list
- 这个 list 可以标明具体的位置信息,也可以使用 bitmap 来进行展示
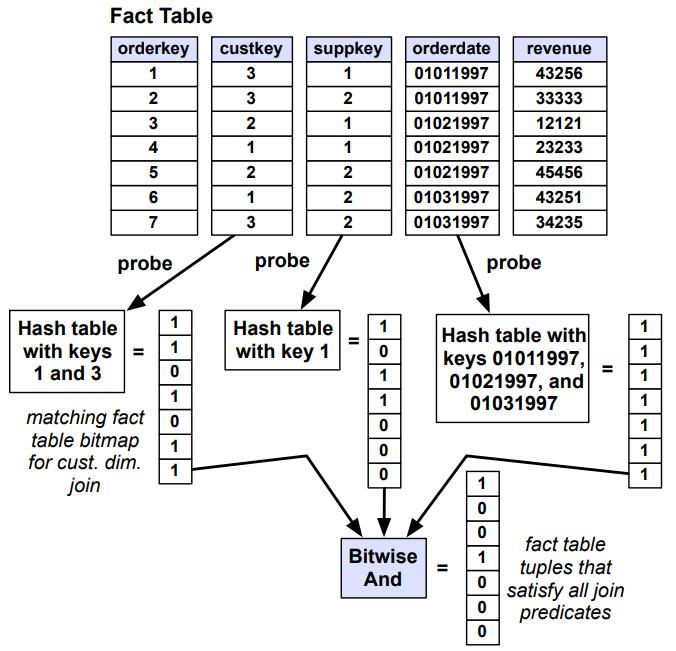
Figure 3: The second phase of the joins needed to execute Query 3.1 from the Star Schema benchmark on some sample data
第三步
- 在事实表上应用阶段二生成的 Position list
- 如果事实表中的某个列C包含对维度表的外键引用,并且需要使用该列来回答查询,如select、分组、聚合等
- 会使用位置列表P来提取外键值,并将这些值用作维度表主键进行查找
- 如果维度表主键是一个排序连续的标识符列表会从 1 开始(这是常见情况),则外键实际上表示所需元组在维度表中的位置
- 查询引擎可以通过提取 position list 来快速提取所需的列,并且不需要对整个表进行扫描
- 还有一种是直接内存数组访问,由于维度表足够的小,可以将整个维度表的列都放置到 CPU 的 L2 缓存中
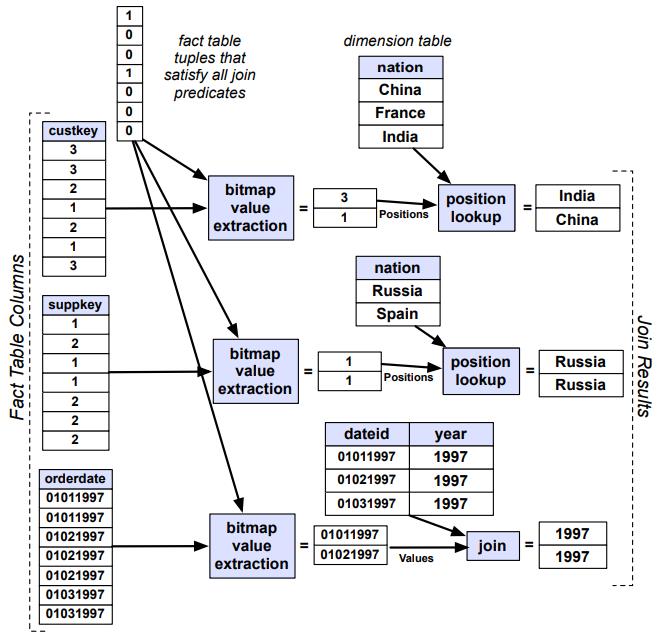
Figure 4: The third phase of the joins needed to execute Query 3.1 from the Star Schema benchmark on some sample data
如果只是这样的话Invisible JOIN可能比上面的第二种方案好不了多少
论文认为在很多时间维度表里面符合过滤条件的数据往往是连续的
连续的好处在于,它能把lookup join变成一个值的范围检查,范围检查比lookup join要快,原因很简单,范围检查只需要所算数运算就好了,不需要做lookup,因此可能大幅度的提高性能
Between-Predicate Rewriting
- 比如检查外键是否在 1000 - 2000 之间,可以将 hash 替换为 between 谓词
- 将谓词从事实表上的哈希查找谓词重写为“between”谓词,其中外键落在键范围的两端之间
- 对于不连续的情况,可以做字典编码,进一步优化
- 优化仅适用于维度表排序列上的谓词这一说法并不完全正确
- 在星型模型中,日期表具有年份列、年月列和完整日期列。如果按年份排序,其次按年月排序,再按完成日期排序
- 则在任何这三个列上的等值谓词都将导致连续的结果集
实验
主要回答这几个问题
- 在行存中模拟列存,然后跟 C-Store 的基准测试对比
- 不修改行存的设计,是否能达到列存的效果
- 压缩、延迟物化、块迭代,那种优化效果更好
- 星型模型中使用 invisible join 对比 非规范化预执行的事实表,结果如何
行存模拟
对比下面的 System X 和 C-Store
- System X 经过了更多的优化,如多线程并行执行、分区
- 这两个点来说,System X 比仅仅是原型的 C-Store更好
- System X 经过 物化的帮助,性能得到了提升
- C-Store 中我们用其模拟了行存,将一行用 string表示,然后拆分模拟
- 这样就实现了 C-Store 的行存物化
- 对比发现,CS 是 CS(Row MV) 的6倍性能,这两者读取的都是同样的数据
- 然列式存储的性能优势不仅仅是减少了从磁盘读取数据的 IO
Figure 5: Baseline performance of C-Store “CS” and System X “RS”, compared with materialized view cases on the same systems.
四种查询,的几种不同优化方式
在行的基础上增加 bitmap 索引、物化视图、垂直分区、所有列加索引
对比发现,物化视图是最好的、然后是传统方式
bitmap就开始下降了
而 垂直分区就比较差了,最差的是 全索引
这可能是两个原因
- tuple 开销
- 因为一个表10个列,拆成10个物理分区,每个分区需要两个字段
- 一个主键、一个列,如果数据量很大,那么每个分区列都需要冗余的存储主键
- 低效率的tuple 重建
- 另外将这些列合并的时候,需要join,甚至可能需要在上面建索引,这就导致更多开销
- System X 倾向于使用 hash-join,如果加上索引强制走索引,效率也不高
- 因为走索引本身也有开销,另外合并之前需要有排序也无法跳过,导致开销无法降低
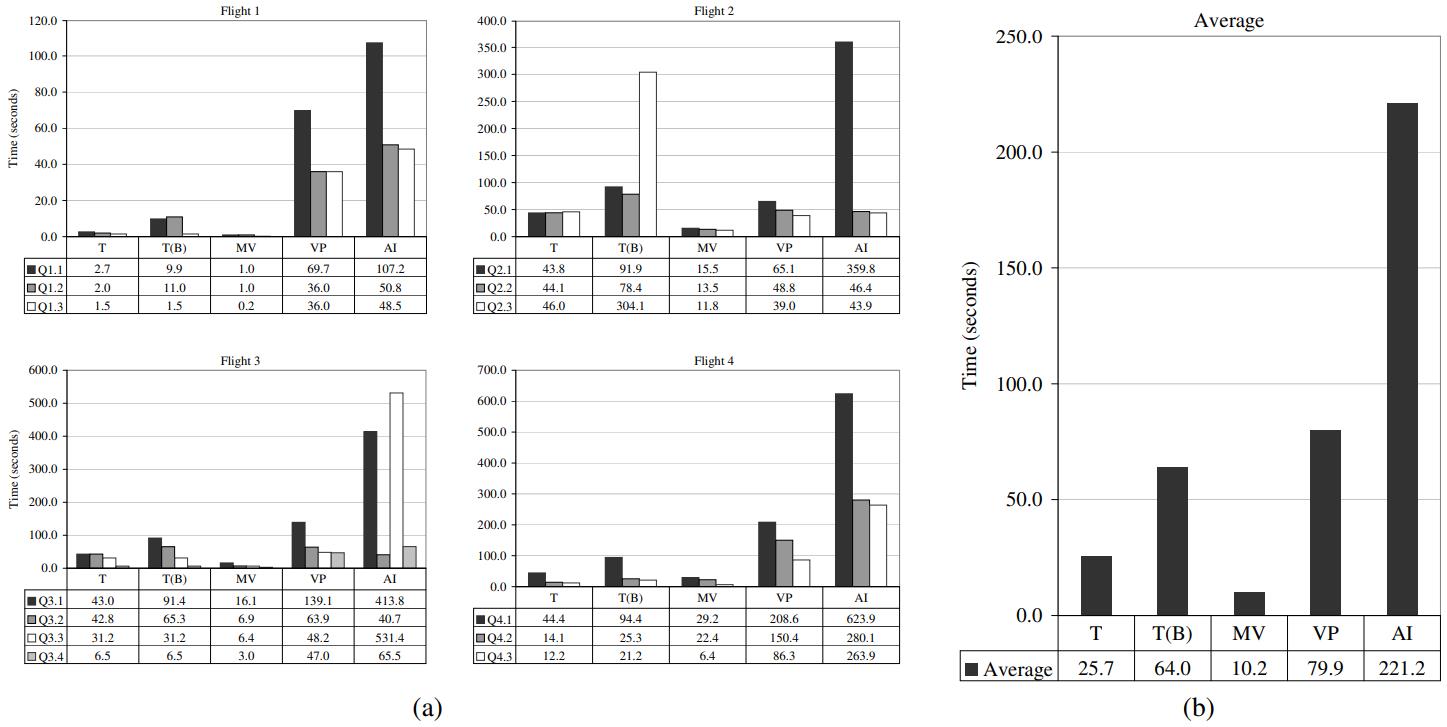
Figure 6:
- (a) Performance numbers for different variants of the row-store by query ight. Here, T is traditional, T(B) is traditional (bitmap), MV is materialized views, VP is vertical partitioning, and AI is all indexes.
- (b) Average performance across all queries.
对于行存的解剖
- 传统方式
- scan占了大部分时间
- 然后是基于排序的聚合
- 垂直分区
- 首先是将partkey列与部件表(part table)中的对应过滤表进行哈希连接
- 接着是将suppkey列与供应商表(supplier table)中的对应过滤表进行哈希连接
- 再把这两个结果集通过一次哈希连接得到符合查询条件的记录ID元组以及部件属性 p.brand1
- 最后再把这些记录ID元组与事实表(lineorder table)进行哈希连接来获取最终结果
- 需要读取四列,跟传统方式读取的数据差不多,但是hash-join使性能下降 25%
- 因为需要将大量的数据加载到内存,耗费很多CPU和内存,即使用了索引,也有很大开销
- 索引
- 需要在事实表中的 4个列 都建立索引
- 先是索引找到对应的值,然后再做hash-join
- 这种方式对于列少、列多的情况下都有可能比传统方式块
- 比如列多但是基于索引,查询的数据少,所以更快
- 而列少但返回的数据多,hash-join的压力就很大,可能会更慢
- 这种方式的变化很大,取决于数据量、查询模式、数据分布
- 查询模式是指:如聚合(大量scan返回少量数据)可能更好,而多表多字段join可能会更差
列存模拟
列存比行存快的原因
- 列存的一列真的只是存一列数据而已,但是行存需要存储主键 + 列数据,有冗余
- 列存的堆文件,i - 1 一定是在 i 前面,但是 行存的顺序没有保证,行存的顺序是通过索引保证的
- 所以在行存中,重建列的时候就必须通过索引,导致额外开销
行存问题讨论
- 垂直分区一开始还不错,但是选择的列超过 总列数的 1/4 后,性能就不行了
- 索引方式,在使用维度列过滤事实表之前,系统被迫使用昂贵的散列连接将事实表的列连接在一起
- 也就是说虽然只是单个列数据找到了,但是两个、多个列连接的开销又很大
- 物化视图,这是最好的,只需要读取部分数据即可
- bitmap,在选择率低的时候比较好,选择率高时候,需要扫描更多page,而位图扫描开销比纯顺序扫描大
如下我们将 C-Store做了分解
- 快迭代:T表示一次一个tuple,t 使用快迭代
- I 开启 invisilbe join,i 为关闭
- C 开启压缩,c 关闭压缩
- L 开启延迟物化,l 关闭物化
对比结果
- 块迭代可以提升 5% - 50%,如果关闭压缩,则 I/O 成为瓶颈,提升效果不明显
- invisible join,大约可以提升 50% - 75%
- 压缩能提高 2倍性能,尤其是 RLE 编码,效率很明显,如果是排序的数据,能提高一个数量级
- 延迟物化效果也很好,如果去掉延迟物化需要有大量的 tuple 重组,因此延迟物化可以提升 3倍性能
- 谓词的选择性越高,前期就有更多的tuple需要构建,这样就更浪费
- 如果将这四个优化全部去掉,列存的性能就跟 行存差不多了
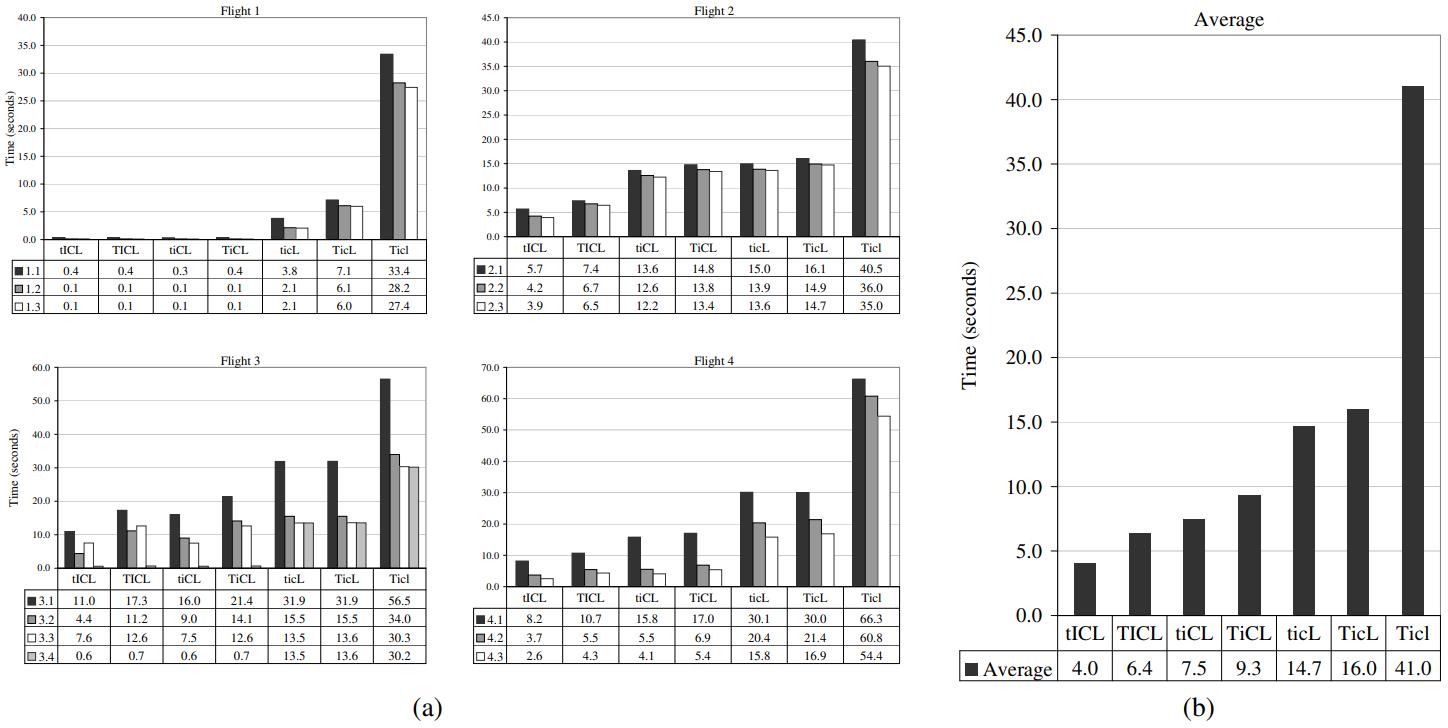
Figure 7: - (a) Performance numbers for C-Store by query ight with various optimizations removed. The four letter code indicates the C-Store conguration: T=tuple-at-a-time processing, t=block processing; I=invisible join enabled, i=disabled; C=compression enabled, c=disabled; L=late materialization enabled, l=disabled.
- (b) Average performance numbers for C-Store across all queries.
四种优化策略效果对比
invisible 和 反规范化对比(反规划化表应用到 列存系统上)
- 反规划化,将所有维度表的信息都放到实事表中,这样就变成大宽表,数据量增加了,但减少了join
- 结果发现这样性能并不好
- 实事表变宽,数据量变多了,而且增加的属性是 string,而在维度表中是整数,所以查询的效果不好
- 应用的外键对应的可能有好几个维度表,可以并行分别做hash,但对于大宽 实事表,需要真实的多次遍历(维度表远小于实事表),导致I/O读取更多
- 实事表 join 维度表之后,还需要在另一个属性上做聚合
- C-Store 可以用块迭代加速,这样两次遍历都是在内存中
- 而 大宽表的列都是隔离的,需要两次真实遍历,I/O 开销高
- 只有当事实表中包含的维度表属性被排序(或二级排序)或具有高度可压缩性时,反规范化才显得有用
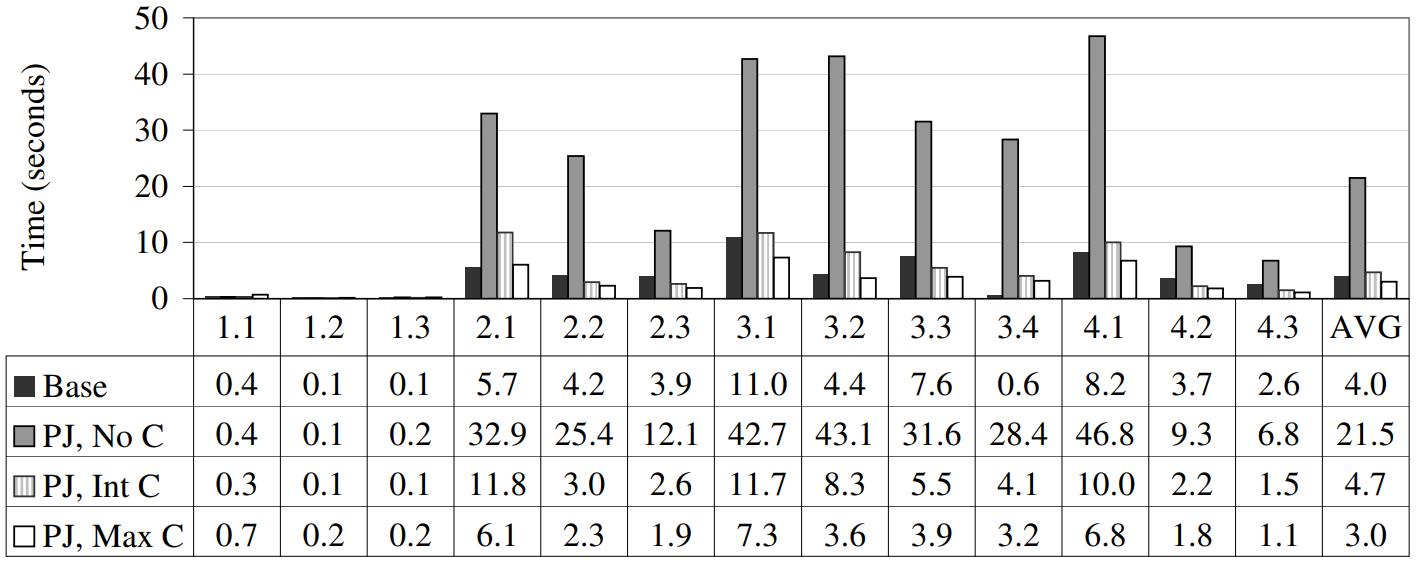
Figure 8: Comparison of performance of baseline C-Store on the original SSBM schema with a denormalized version of the schema. Denormalized columns are either not compressed (“PJ, No C”), dictionary compressed into integers (“PJ, Int C”), or compressed as much as possible (“PJ, Max C”).
参考
- Storage Models & Data Layout
- 《Column-Stores vs. Row-Stores》读后感
- Columnar Storage
- alter table add column多个字段_读后感之《Column-Stores vs. Row-Stores》
- 列存储
- Row-Store / Column-Store / Hybrid-Store
- C-Store: A Column-oriented DBMS
- 稀土掘金 论文解读 Column-Stores vs. Row-Stores
- git book: ColumnStores vs. RowStores: How Different Are They Really?