Column Imprints: A Secondary Index Structure
原文 https://15721.courses.cs.cmu.edu/spring2023/papers/04-olapindexes/p893-sidirourgos.pdf
column imprints 原理
论文提出了一个新的基于主内存的二级索引 column imprints
主索引 vs 二级索引
- 主索引跟数据布局有关,还带有导航功能
- 二级索引只有导航跟布局无关,占空间很小
zone map vs bit map vs column imprint
- zone map将列分区,然后存一个最大最小值
- bitmap 按照值的基于划分成若干个bit 组,根据对应的位置是否有值设置 1
- column imprint 是基于缓存行的
- bit map是 包含了8组bit位,CI 则将其按照cache line大小,压缩成 3,这里假设一个cache line可以存 3个数字
- 实际的cache line一般是 64个字节
- zone map只包含了min、max,如果很多随机值正好在min、max内,则zone map就没效果了
- 而 CI 因为bit vector中包含了随机值的 bit,可以处理各种场景
- 同时 CI 相比 bitmap,其每个 bit vector对应的是cache line,而 bitmap对应的是一个值,所以空间更小
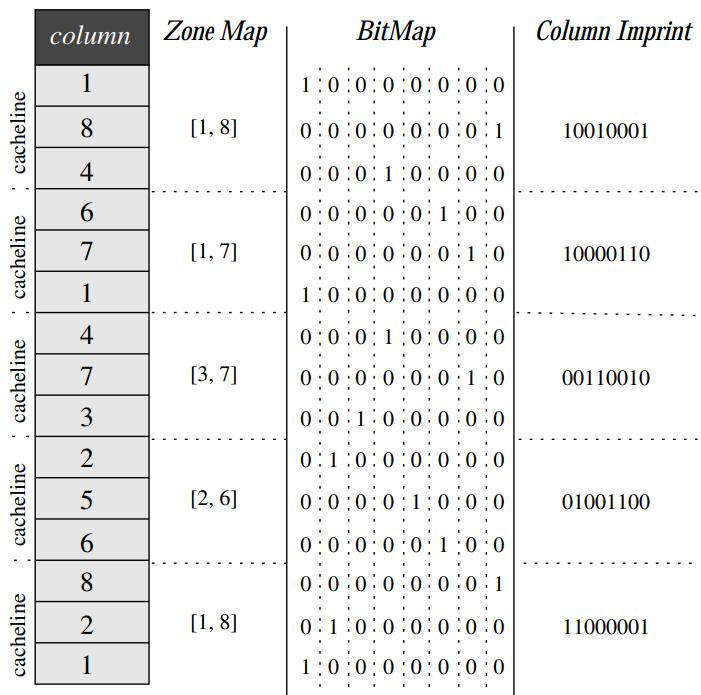
Figure 1: A simple column and an example of zonemaps,bitmaps, and imprints indexes.
上述场景列基数很小,是 1:1 的映射
如果基数很大,采用近似直方图将 域划分范围,将每个 bit 映射为一个范围
cache line的压缩
- 将相同内容的 imprint vector 作为一个来存储
- 比如下图第一个,counter为7,repeat没有设置,表示这 7 个都是随机内容,需要完全存储
- 后面一个标记为 counter 13,repeat设置了,表示这 13个都是重复内容,使用一个 vector就可以表示了
- 这里有个关键点,多少个数据size 表示为一个 imprint vector
- 理论上应该跟底层硬件有关,因为这个技术是针对主内存数据库的,所以imprint vector大小就跟cache line一样,也就是 64 字节
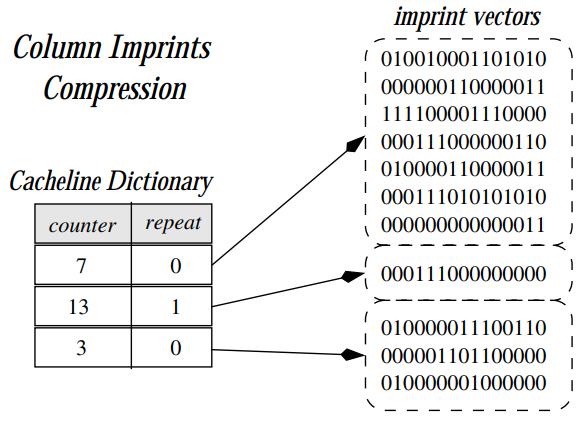
Figure 2: Column imprint index with compression (23 cachelines).
算法-1,函数返回一个 imprint 索引结构imp,其中包含imprint数组和cacheline字典
上述 Algorithm-1,就是 imprint vector的大致工作原理
将数据列划分为多个区间(bin)并为每个区间生成一个imprint值
根据上一value 跟当前value是否相同,来设置 repeat,counter

Algorithm 1 Main function to create the column imprints index: imprints()
Input: column col of size col_sz
Output: imprints index structure imp for column col
算法2的目标是
- 根据给定的列数据和imprints索引结构确定索引的分箱数量和范围
- 如果样本中的唯一值数量少于64个,则将这些唯一值分配给索引的范围,并确定索引的分箱数量
- 如果唯一值数量超过64个,则根据样本中的分位数设置索引的范围
- 该算法的最终目的是为了确定imprints索引的分箱策略和范围,以支持高效的数据查询和定位

Algorithm 2 Define the number of bins and the ranges of the bins of the histogram: binning() Input: imprints index structure imp, column col
Output: number of bins imp.bins and the ranges imp.b
构建列印记索引的算法被设计为高效且优化了CPU性能
- imprints() 函数的复杂度与列的大小成线性关系,记为 n
- 每个缓存行包含 c 个值,其中最耗时的部分是调用 get_bin() 函数
- 每个值需要进行 3 次比较。由于在每次比较中搜索空间被划分为两半
- 因此每个值需要进行 3 × log64 = 18 次比较
- 因此,为了创建完整的印记索引,我们需要进行 18 × n 次比较
一些操作
算法3的目标
- 在基于列imprints索引的情况下,评估范围查询
- 给定imprints索引结构和查询范围Q(由低值和高值组成)
- 该算法通过匹配imprints向量和掩码来筛选出满足查询范围条件的数据
- 对于匹配的数据,如果重复标志未设置,则直接将对应的数据ID添加到结果集中
- 如果重复标志已设置,则需要进一步检查每个数据的确切值是否满足查询条件
- 最终,算法返回满足查询条件的数据ID组成的结果数组res
- 该算法利用imprints索引的特性,在快速定位和筛选数据方面具有高效性能
- 可能存在用户的查询包含多个谓词,涉及同一个关系的多个属性。在这种情况下,会多次调用算法3的query()

Algorithm 3 Evaluate range queries over the column imprints index: query()
Input: imprints index structure imp, column col, query Q = [low, high]
Output: array res of ids
更新采用append,有两点需要注意
- 必要时调整分箱的边界。应尽量避免这种调整,因为它需要完全重建索引
- 更新位向量。对于位图索引,这是一个昂贵的操作,因为需要更新所有位向量,即使它们不映射新值
- 在列式数据库中,不会执行原地更新,因为其代价过高
- 相反,使用增量结构来跟踪更新,并在查询时将它们合并
- 增量结构可以简单地由两个表组成,其中包含需要与基本表进行并集和差集操作的插入和删除
- 或者它可以是更复杂的结构,例如位置更新树
印记可能会产生误报
- 因此相应的印记向量可能会忽略删除操作
- 然而,插入操作将需要设置额外的位到受影响缓存行的印记
- 这种方法最终会使印记索引饱和。在这些情况下,通常会忽略整个二级索引,并在下一次查询扫描期间重建它
- 在常规扫描期间重建印记索引的开销很小,以至于用户几乎察觉不到
相关工作
- imprint column 可以看做是 bitmap 家族的新成员
- bloom filter 不适合范围返厂,这是 imprint column 的目标
- 更新的 Word-Aligned Hybrid 存储模型
- 当索引高基数属性时,压缩间隔编码位图的长度太大,解决方案是:多级索引方案,以帮助设计一个最优的分组策略
实验
实验的数据
- Routing,2.4亿的地理数据,包含经度、维度,旅行ID、时间戳等
- SDSS,6.2G 的天文数据,各种双精度、单精度数据
- cNET,描述技术产品属性的分类数据集,稀疏大宽表
- Airtraffic,包含航班信息、延误等统计信息的数据
- TPC-H,因子为 100 的TPC-H 数据集
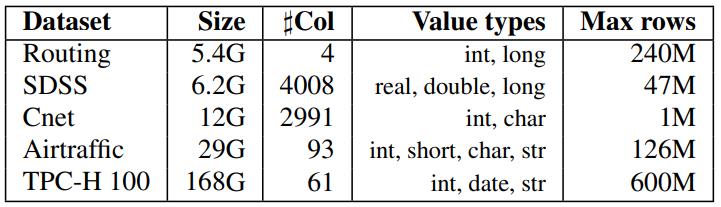
Table 1: Dataset statistics
Word-Aligned Hybrid (WAH)
- 是一种压缩数据结构和位向量编码技术,用于高效地表示大规模位数据
- 设计目标是在高压缩率和快速位操作之间实现平衡
- WAH 结合了两种不同的位向量编码方法:字对齐压缩 (Word-Aligned Compression) 和混合位对齐压缩 (Hybrid Word-Aligned Compression)
- 字对齐压缩将连续的位序列压缩成以字(通常为32位)为单位的块,以减少存储空间
- 每个块包含一个控制字和若干字节的位数据,其中控制字指示每个字节中的位是否为填充位(全0)或实际数据位
- 混合位对齐压缩结合了字对齐压缩和运行长度编码 (Run-Length Encoding, RLE)
- 它通过将连续的填充位或实际数据位组织成运行长度来进一步压缩数据
- 在混合位对齐压缩中,长运行(即连续的填充位或实际数据位)被压缩为一个运行长度标记,而短运行则直接以字对齐压缩的方式存储
- WAH 的优点是在高度压缩位数据的同时能够支持快速的位操作,如位与、位或和位运算等
- 它被广泛应用于各种领域,如数据库管理系统、数据压缩和位图索引等,以提高存储效率和查询性能
我们将两个位向量之间的编辑距离定义为第一个位向量中需要设置和取消设置才能成为第二个位向量的位数
列熵E的值在0.0到1.0之间
熵E 越高,数据就越随机,聚类也就越少
- 下图中bit 被设置了就记为 x、否则是 .
- 第一个图中,是 天文数据,熵非常高,也就是前后元素都不同,这样的记录很难被压缩
- 后面 3 个明显 熵就很低了
- 最后一个是 TPC-H 的数据,也是非常有规律的

Figure 3: Prints of column imprint indexes (’x’ = bit set, ’.’ = bit unset) and the respective column entropy E.
图4展示了不同列的熵的累积分布情况
其中高熵的列表示值分布更加不规律或多样化。这并不意味着列的数量越多,熵就越高
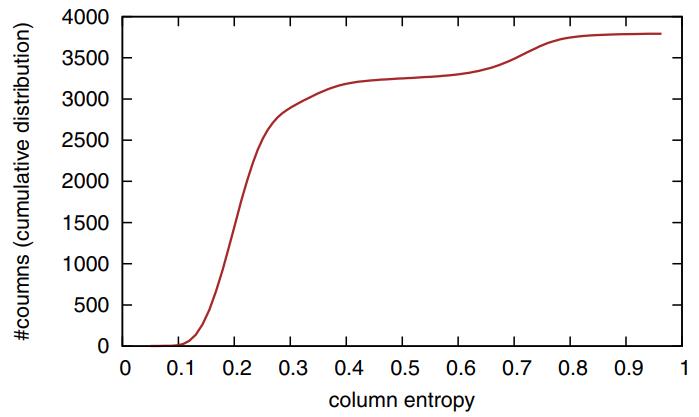
Figure 4: Cumulative distribution of the columns’ entropy E.
图5 是不同索引,zonemap、WAH、imprint column 的存储开销
- WAH索引的存储开销最大,其次是区域映射,而列印索引对存储空间的要求最小
- 列印索引的存储效率通常比区域映射和WAH索引高出一个到两个数量级
- 也存在例外情况,特别是对于WAH索引,其存储需求波动最大
- 对于包含 8字节有序带有主键的数据,WAH 比 imprint column更好
- 对比三个索引的创建时间开销,基本都是线性的
- zone map最快,然后是 imprint column,WAH 最慢
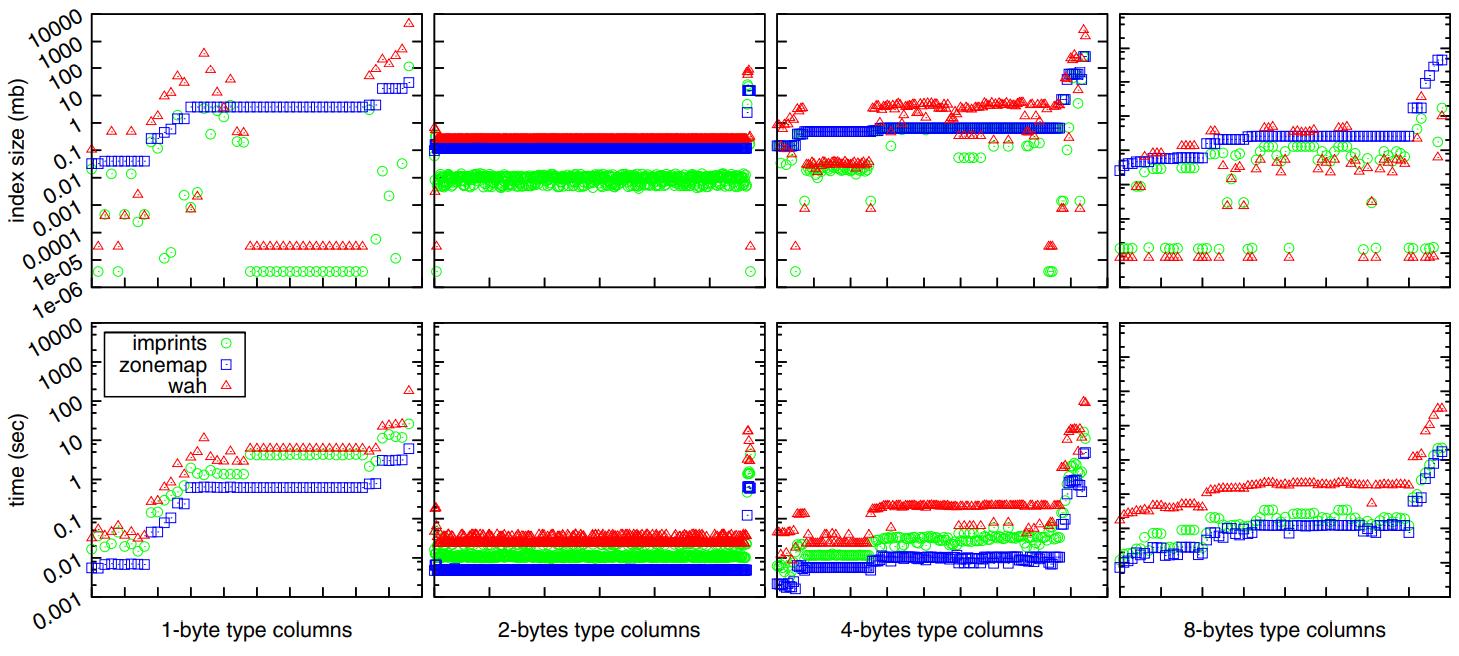
Figure 5: Index size and creation time for different types of columns (x-axis enumerates the columns, ordered by size).
对比索引压缩后的占比情况
- WAH、imprint column、zonemap 在大多数情况下都表现的很好
- 但是航天数据这种带有双精度的值,使的数据分布非常随机,WAH的压缩就非常不好
- 可以看到 WAH 的压缩波动很大
- 而 imprint column 的总体表现跟 zone map 差不多
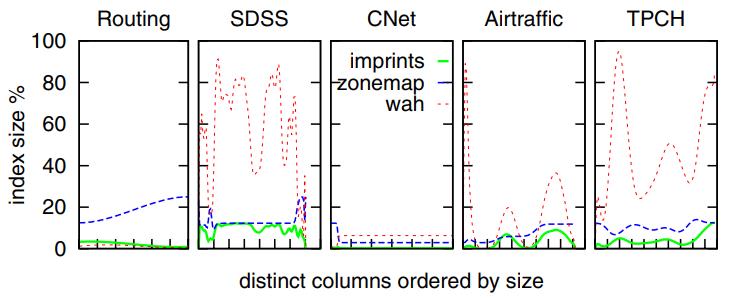 Figure 6: Index size overhead % over the size of the columns.
Figure 6: Index size overhead % over the size of the columns.
对比 熵增加时,imprint column 和 WAH 的对比
- 在熵小于 0.4 的时候,imprint 和 WAH表现的差不多,总体都是 10% 左右
- 随着熵的增加,imprint一致比较稳定,在 12%左右,因为多需要每个cacheline单位的64位,使其对高熵值免疫
- 而WAH索引则有可能变得非常低效,因为没有很多压缩机会
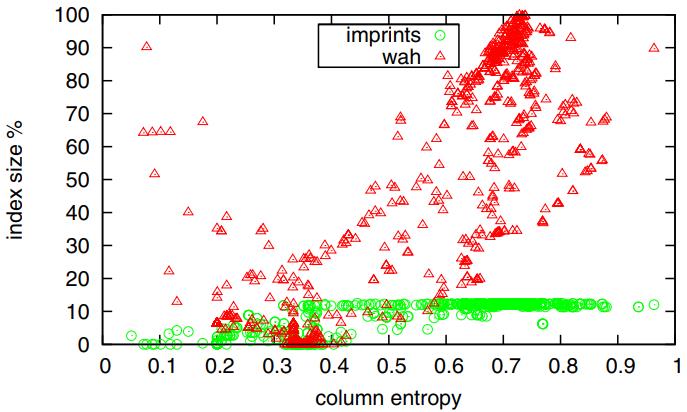 Figure 7: Index size overhead % over column entropy E
Figure 7: Index size overhead % over column entropy E
针对不同查询的选择率情况
- 创建十个不同选择性的范围查询。选择性从小于0.1开始,每次增加0.1,直到超过0.9
- 对于查询时间,所有三个索引和顺序扫描产生了相同的图案,但这些图案在y轴上有所偏移
- 总体而言,imprints是最快的索引,因为图中的点在y轴上最靠下
- 如果查询的选择性较低,返回的数据量较多,观察到的索引之间的差异就越小
- 顺序扫描在这种情况下也变得具有竞争力。这是因为解压数据并实例化几乎所有ID的开销超过了顺序扫描整个列并检查每个值所需的时间
- 对于选择性较低的查询,zonemaps的查询时间与顺序扫描类似,因为与imprints和WAH位图相比,zonemaps需要的管理开销最小
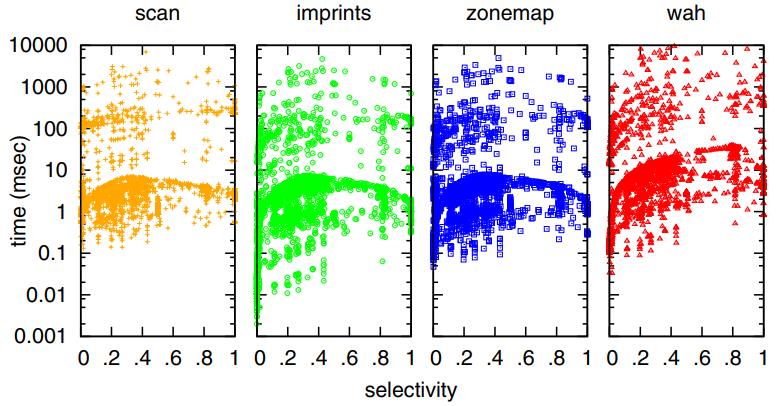 Figure 8: Query time for decreasing selectivity.
Figure 8: Query time for decreasing selectivity.
图9中绘制了查询的累积时间分布
- 计算在每个时间段结束执行的查询数量,并累积它们。在图9中,曲线越陡峭,表示在较短时间内完成的查询数量越多,因此整体上索引效率越高
- 使用imprints索引的近15,000个查询在每个查询中所需的时间少于0.1毫秒
- 其次是zonemaps,在相同时间范围内能够评估超过7,500个查询
- 然而,随着评估时间的增加,不同方法之间的时间差距减小
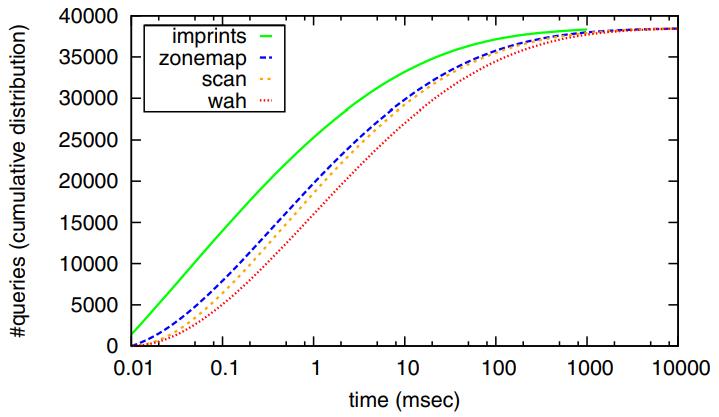
Figure 9: Cumulative distribution of query times.
图10显示了每个查询所实现的改进因素
- 大于1的点表示相对于基准的改进因素,而小于1的点表示一种方法比基准慢的倍数
- 绿色圆圈表示imprints相对于顺序扫描的改进,而红色三角形表示位图与WAH相对于顺序扫描的改进
- 对于选择性较低的查询,imprints变得不那么有竞争力,而WAH可能比扫描慢得多
- 这一观察结果与大多数现代数据库系统的策略一致,即如果查询优化器的成本模型检测到选择性较低的选择,则优先选择顺序扫描而不是任何索引探测
- WAH压缩的处理开销超过了从主存储器到CPU缓存的数据吞吐量
- 图10的下图是相同的比较,但将zonemap索引作为基准,而不是顺序扫描。这里也可以看到相同的趋势
- 尽管zonemaps更具竞争力,因此imprints的改进因素接近100倍
- 然而,在一些低选择性的情况下,由于计算需求较少,zonemaps可能比imprints更快
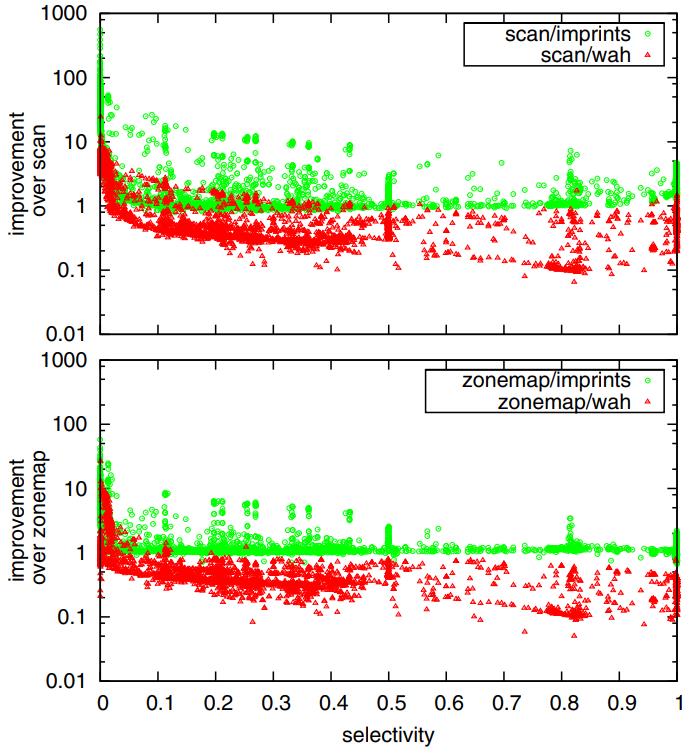 Figure 10: Factor of improvement over scan and zonemap.
Figure 10: Factor of improvement over scan and zonemap.
图11的上图显示了索引探测次数,而下图显示了比较次数
- 对于所有选择性在0.4到0.5之间的查询,WAH的索引探测次数是所有索引中最高的,几乎总是大于总记录数
- 这是因为对于每个记录,需要探测多个位向量,WAH实现了最好的过滤,因为数据比较的次数通常非常低
- zonemaps的索引探测次数保持稳定,即与列的缓存行数相同,zonemaps的比较次数取决于数据的倾斜程度,可能会有所变化
- imprint 在索引探测和数据比较之间实现了平衡。熵较高的列需要更多的索引探测但较少的数据比较
- 另一方面,熵较低的列需要较少的索引探测但较多的数据比较
- 对于选择性较高的查询,imprint column 相对于顺序扫描可以实现1000倍的改进,相对于zonemap可以实现100倍的改进
- 进一步的实验表明,查询评估时间与列的大小或索引的大小之间存在关联,而这又与列的熵相关
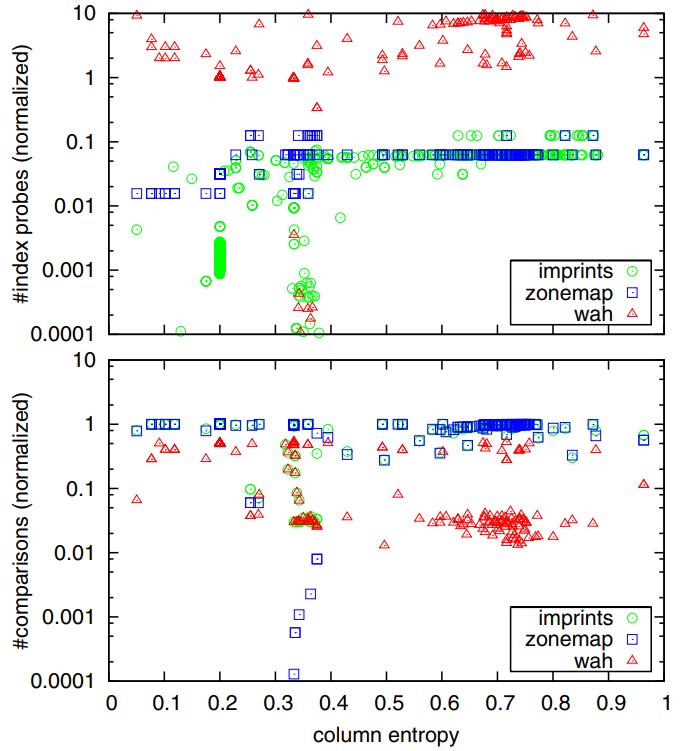 Figure 11: Number of index probes and value comparisons for queries with selectivity between 0.4 and 0.5.
Figure 11: Number of index probes and value comparisons for queries with selectivity between 0.4 and 0.5.