Column Sketches: A Scan Accelerator for Rapid and Robust Predicate Evaluation
原文 https://15721.courses.cs.cmu.edu/spring2023/papers/04-olapindexes/hentschel-sigmod18.pdf
背景
各种索引、存储模式 对于 谓词求值来说,只能用于特定的模式
- 选择率
- 数据分布
- 数据聚集
对于非特定场景来说,这种技术表现的就不好了,论文提出了一个新的索引模式
Column Sketch
通过有损压缩的方式,可以让索引快速获取数据、计算任何查询性能、同时内存开销也不大
现有的技术问题
- 传统索引,如B 树,在选择率低的时候才有用,选择率高的时候就比 scan 差很多了;而列scan 的性能很好,即使很低的选择率也不亚于B 树
- 轻量级索引,如 Zone Map、以及 Column Imprints、Feature Based Data Skipping都是基于元数据统计信息过滤block;但数据没有聚集性则没什么效果
- 早期裁剪,如ByteSlicing、Bit-Slicing、Approximate and Refine,比较每个bit 为,比如谓词100,同时比较高bit 0和低bit 100
- 对于早期裁剪,如果大量的高bit 都是0,相当于都要比较第二个bit,则裁剪效果不好,跟 scan可能差不多
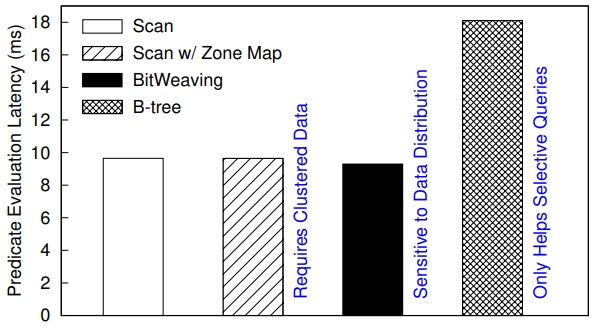 Figure 1: For certain workloads, no state of the art methods provide any significant performance benefit over a scan.
Figure 1: For certain workloads, no state of the art methods provide any significant performance benefit over a scan.
CS的好处
- 有损压缩允许有效的算法找到编码方案,使代码值始终具有信息量
- 编码后的数据量更小
- 相比于无损压缩,对于索引的摄取速度更快
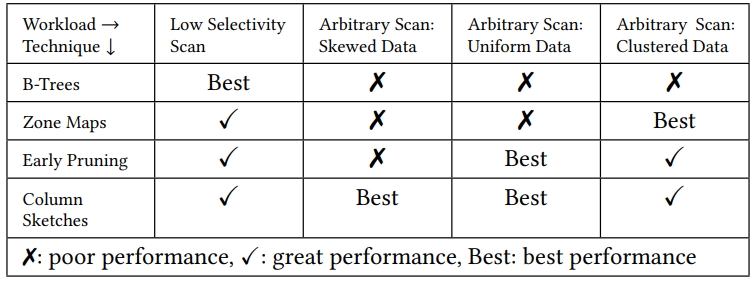 Table 1: Each technique has scenarios where it is the best for select performance. However, Column Sketches are the only technique which improves performance in every scenario.
Table 1: Each technique has scenarios where it is the best for select performance. However, Column Sketches are the only technique which improves performance in every scenario.
论文的贡献
- 提出了 Column Sketch 用于scan,使用有损压缩加速,不关心选择率、数据分布、数据聚集
- 如何使用有损压缩来创建信息位表示,同时保持低内存开销
- 给出了对列进行有效扫描的算法,以及如何将这种方式整合到现代系统架构中
架构
Column Sketch 由两个部分组成
- 一个是映射函数
- 通过映射函数,将原始值映射到 编码后的压缩列上
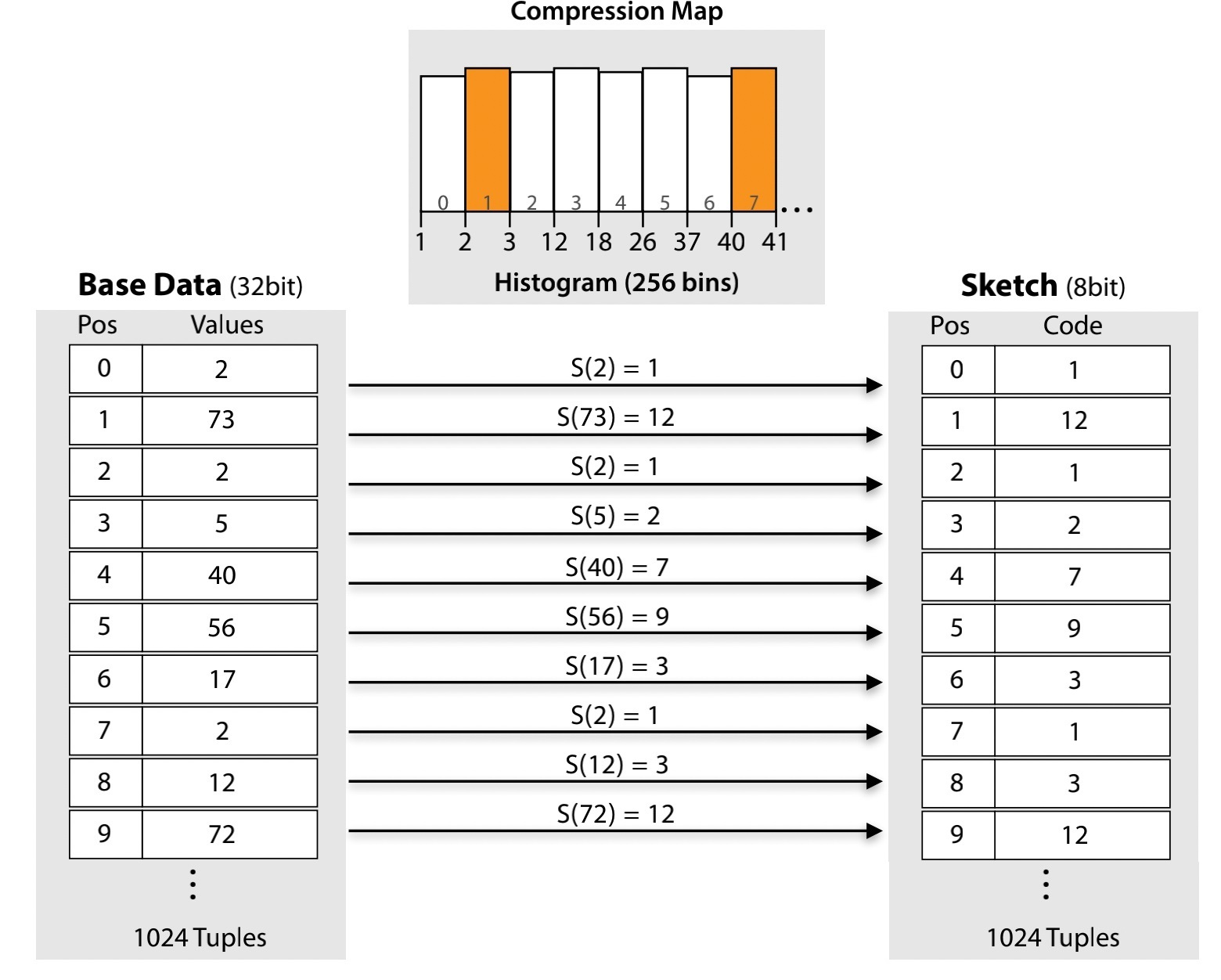
比如下图,数组是有序的,这里建立了一个函数,包含 60、132、170、256
小于60的都被映射为00, 小于 132的映射为 01,小于 170的是 10,小于 256的是 11
然后每个原始值 8bit,就被压缩成 2bit 了
后面查找 x < 90的时候,根据映射函数,可以得知,需要查找的范围是 00,01
然后找到对应的value,这里可能需要反复查询原始列,后面会讲进一步优化
可以看到 00 列的值肯定是小于的,不需要回原表检查,而 01 需要回原表检查
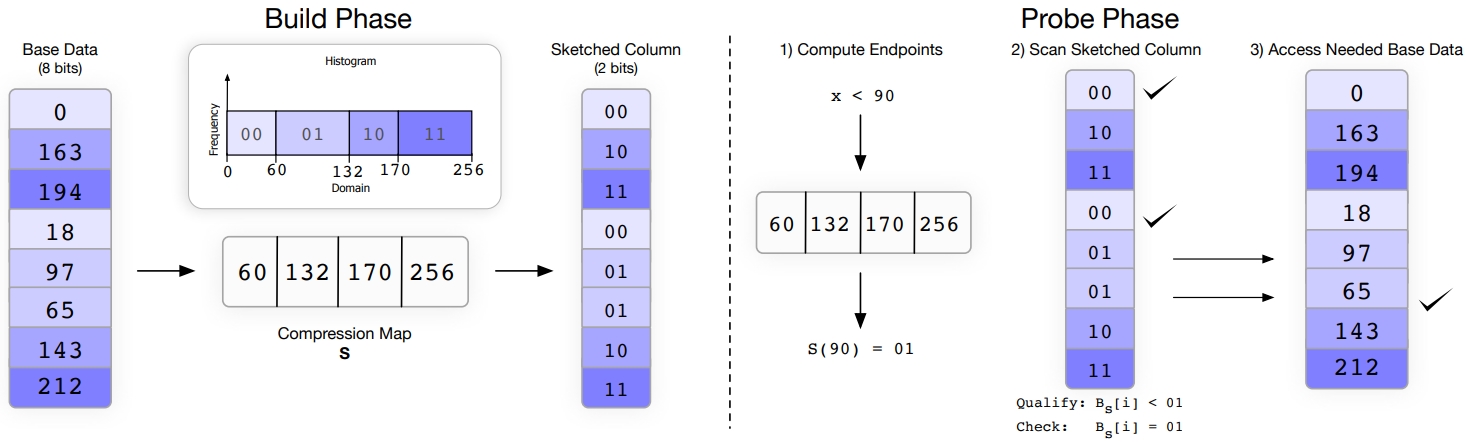
Figure 2: Column Sketches use their compression map to transform (possibly compressed) values in the base data to smaller code values in the sketched column. These codes are then used to filter most values in the base data during predicate evaluation.
所以这里函数映射完后,是满足这两个条件的
- for x,y ∈ I8, S (x) , S (y) ⇒ x , y
- for x,y ∈ I8, S (x) < S (y) ⇒ x < y
Algorithm 1 Select where B < x
|
|
byte 需要对其,否则会有 30%的性能损失
源入股有序可以直接这么映射,无序的话需要做hash
压缩构建
目标是,映射的函数,尽可能少的访问原表,有效的支持修改
- 对于访问频繁的值,分配一个唯一code,比如表中有很多 90,如果是非唯一编码则要频繁回表,分配唯一code就可以解决此问题
- 对于非唯一code,要尽可能保持值分配的均匀
- 尽可能保持有序
- 对于未来的新值无需重新编码,对于有序CS,不允许有连续的唯一code值,对于无需CS 只要有一个非唯一code 即可(新来的value给它)
- 对于频繁访问的值,将其识别(识别过程中不影响性能和鲁棒性),可以提升性能
构建数值压缩映射(Numerical Compression Maps)
- 在原数据列上采样,得到样板后做排序
- 然后根据样板的值(处理频繁值、非频繁值)生成对应的直方图
- 确定直方图中每个柱(桶)的范围端点,然后根据每个柱(桶)的端点来分配对应的 code值
- 此时 Compression map CM就建立好了,利用该 CM 对原数据列进行一一映射 ,形成 code值组成的 sketches column列
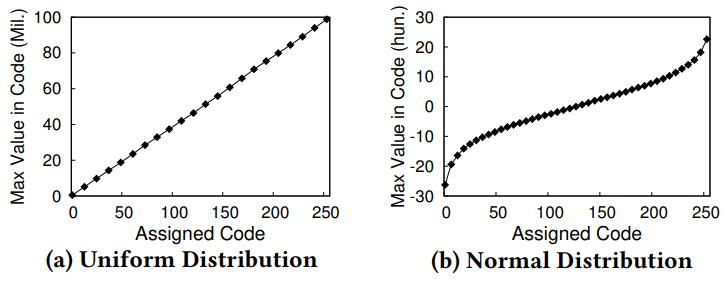
Figure 3: Bucket sizes track the distribution of the data.
数值类型map构建过程
- 先对样本排序
- 查找频繁值, 分为 c 个组,如果是频繁值 一定会跨组出现
- 频繁值 > n/c
- 重复这个过程,直到处理完所有频繁值,再将非唯一值尽可能均匀的分不到每个柱子里
- 利用构造好的compression map构造sketch column
- 如下,2、40都是唯一值
分类压缩类型map
- 字典编码的工作原理是为每个唯一的值 赋予自己的数字代码
- 比如有 1200唯一值的数据集,字典编码的每个值需要11bit
- 分类压缩是找到高频的前缀,比如只需要前 2个、或者3个bit 就表示高频前缀
- 通过高频前缀 + 低频后缀,可能总空间比普通编码要长一些,但是对于scan 更优
- 唯一值的选择类型 数值压缩,通过直方图找到频率高的,建立唯一值
- 分配多少个 code作为唯一值,也是根据频率 z 的分布来的,或者设置一个常数
- 通过 hash 函数,将value相对均匀的分散到 每个 非唯一code上
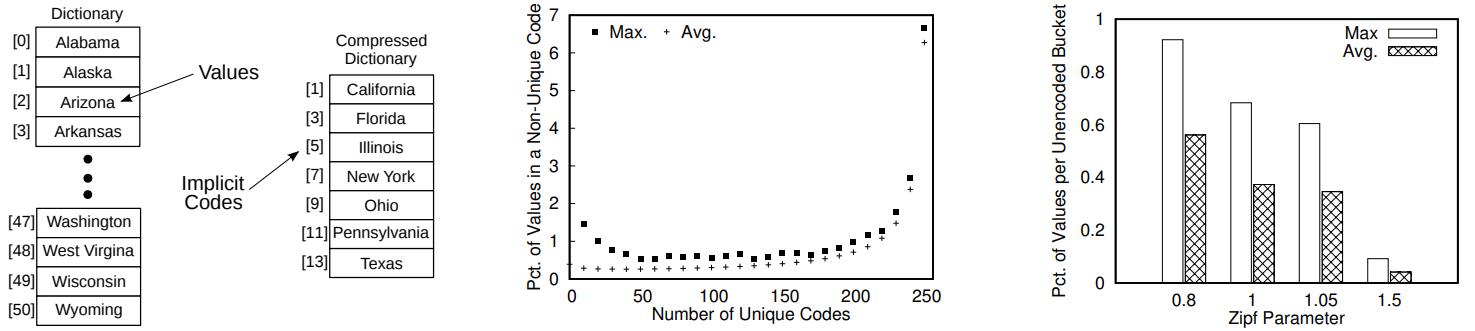
Figure 4: Lossy dictionaries trade uniqueness for better compression.
Figure 5: The number of unique codes should be neither too high nor too low.
Figure 6: Regardless of the level of skew, the number of values in non-unique codes is low.
Algorithm 2 Column Sketches Scan
Select where B < x, Column Sketch of one byte values
|
|
代码解释:
- 将要处理的列拆分成多个段(segment)。
- 对于每个段,使用SIMD指令进行并行计算。
- 在每个段中的SIMD迭代中,加载代码向量(codes1和codes2)和重复向量(repeat_sx)。
- 执行逻辑比较操作,比较代码向量和重复向量,得到确定性匹配结果(definite1和definite2)和可能性匹配结果(possible1和possible2)。
- 将确定性匹配结果和可能性匹配结果转换为位向量(bitvector_def1, bitvector_def2, bitvector_possible1, bitvector_possible2)。
- 将确定性匹配结果存储到结果向量(result)中。
- 检查边界值是否有匹配的元组,并将符合条件的位置存储到临时结果向量(temp_result)中。
- 更新当前段的位置。
- 对于临时结果向量中的每个位置,如果满足条件,则在结果向量中设置相应的位。
- 重复步骤2至步骤9,直到处理完所有段。
性能分析
对比几种索引
- B 树
- Column Imprints
- Optimized Scan
- BitWeaving
- Column Sketch
统一分布的数值数据
图7、可以发现,在选择率很低的时候,B 树的效率是最好的,一旦选择率上升了,B树就不行了
优化scan 在接近 1的时候也会很好
其他如Column Imprints、BitWeaving 都比较稳定,Column Sketch 平均看是最好的
图8、谓词求值期间,因为SC 读取的内存是压缩过的,是最少的,所以 L1 miss也是最少的
Column Imprints、zone map对于聚集元素表现最好,非聚集就不行了
BitWeaving 是早期做裁剪,但可能要读很多bit,不如 CS
图10、对于谓词比较,执行一个tuple需要多少周期,scan是最多的,CS是最少

Figure 7: Column Sketches outperform other access methods in all but the most selective queries.
Figure 8: Column Sketches incur fewer cache misses than competing techniques.
Figure 9: Column Sketches need to access the base data very infrequently.
Figure 10: Column Sketches need fewer cycles to evaluate single and double sided predicates.
倾斜分布的数值数据
下面两个对比是当输入数据未编码的效果,测试鲁棒性,可以看到CS 的鲁棒性不错
对于数据size,从4字节增加到 16字节,scan的效率成比例下降,而SC 因为是缓存到cache中的,性能跟 4字节时差不多
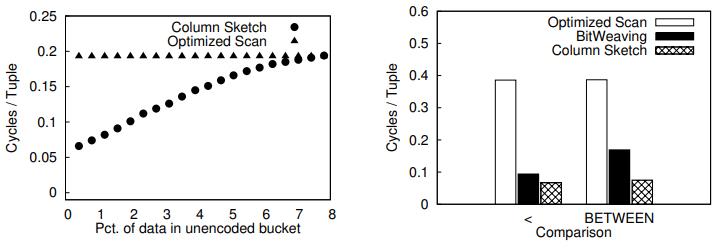
Figure 11: Column Sketches perform well even in the case of a bad compression map.
Figure 12: Column Sketches retain nearly identical performance with larger base data.
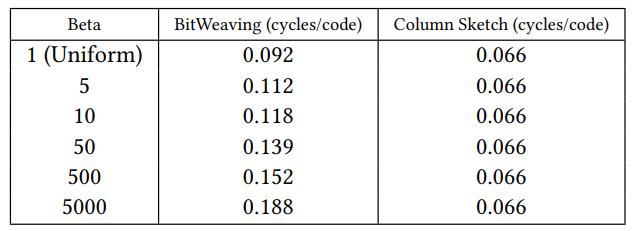
Table 2: Scan Performance under Skewed Datasets
–
分类数据
这里做了三组对比,等值、唯一code,等值、非唯一code,小于、非唯一code
从三种情况看,CS 表现都是最好的
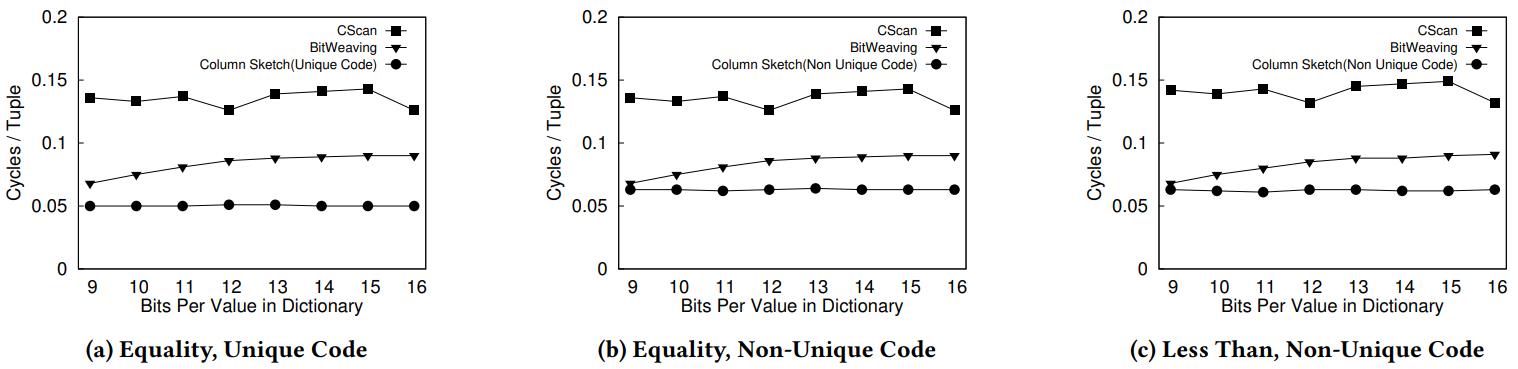
Figure 13: Column Sketches is the fastest scan across unique and non-unique codes, and across equality and range comparisons
负载性能
测试各种类型数据,摄入的情况
读取 1亿条数据,连续跑 5次
可以看到 CS 是 BitWeaving 的 5 - 16倍性能

Table 3: Time to load all batches (sec.)
进一步工作
- Compression and Optimized Scans.
- Early Pruning Extensions
- Lightweight Indexing
- Other Operators over Early Pruning Techniques
- SIMD Scan Optimizations
参考
- 2018 Sigmod : Column Sketches: A Scan Accelerator for Rapid and Robust Predicate Evaluation笔记
- A. Lamb, M. Fuller, and R. Varadarajan. The Vertica Analytic Database: C-Store 7 Years Later. Proceedings of the VLDB Endowment, 5(12):1790–1801, 2012.
- Y. Li and J. M. Patel. BitWeaving: Fast Scans for Main Memory Data Processing. In Proceedings of the ACM SIGMOD International Conference on Management of Data, pages 289–300, 2013.