Optimal Column Layout for Hybrid Workloads
原文 https://15721.courses.cs.cmu.edu/spring2023/papers/03-storage/p2393-athanassoulis.pdf
整体分析
对于分析场景,列存是最合适的,但是列存对应更新场景并不好
而对于 HTAP 来说,是各种模式混合的场景,有读也有写
这种情况下,如果预先固定存储模式就无法针对特定场景做调优了,
而底层的数据布局一般都是实现固定好的,这样的话,面向不同的负载情况(读密集、写密集),就无法做到最适应了,效果也不好
而且固定的布局也无法调整
这篇论文讲的是通过学习之前的数据,做出调优决策,然后优化数据布局
有点像 数据库 & ML 的结合场景,主要是针对 HTAP 的
挑战
- 为合适的场景找到合适的布局最坏情况可能是指数级的,因为要在:分区数量、相应大小和范围、缓存空间数量来分配
- 通过将问题场景拆分为多个子问题来求解
- 场景定制化,通过分析采样统计来对读、写场景做布局优化
- 列的场景可能很多,如未排序的、完全有序的,列的分区方式也是多种多样的,更新策略、平衡读写问题,ghost-value
- 创建可变成的分区来适配不同的场景,鲁棒性,避免过度优化拟合
- 如果分区粒度越细,则整体有序性越高、数据组织的结构性越强,对读越有利(快速定位数据、读更少的数据);
- 如果分区粒度越粗,则意味着更新时需要调整的数据快越少(简单标记、追加都可以),因而更简单的变更维护,对于更新越有利
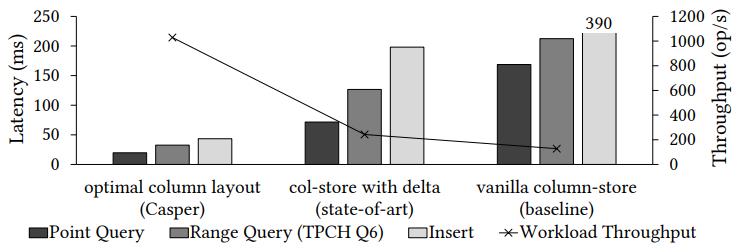
Figure 1: Existing analytical systems have 2× higher performance than vanilla column-stores on hybrid workloads by utilizing a delta-store. Using a workload-tailored optimal column layout, Casper brings an additional 4× performance benefit.
论文的贡献
- 描述了列布局的设计空间,包括:区分、更新策略、buffer空间,可以支持各种场景
- 引入频率模型 覆盖数据分布上的访问模式,分区操作上的详细成本模型,ghost值分配机制
- 将列布局问题当做工作负载驱动的二进制整数优化问题,可以平衡读、更新性能
- 将列布局策略整合到我们从存储引擎 Casper 中,比最先进的布局提升 2倍以上性能
将一个列的值划分为多个分区
- 如果分区数量多了,则读花费增加,但写花费降低
- 如果允许空槽,则写花费降低,读基本不变
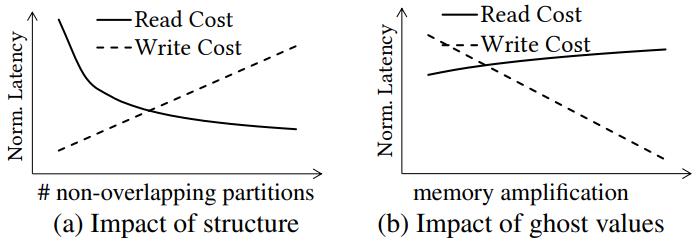
Figure 2: Accessing a column is heavily affected by the structure of the column (e.g., sorted, partitioned). Read cost - (a) logarithmically decreases by adding structure (partitions), while using ghost values to expand the column layout design space
- (b) reduces write cost linearly w.r.t. memory amplification.
根据上述描述,这里使用 range + partition 的基本布局方式
- 这种方式可以覆盖到读、写各种场景
- 列数据划分为多个分区,分区建不想交有序,分区内是无序的
- 分区的数量可以调整,分区内以 block + chunk 组织,利用CPU cache
- 分区内是无序的,所以分区很大(粒度粗)则写有利、但对读不利;相反对读有利但不利于写
对于 5 种基本的场景,来分析一下
- 点查
- 范围查询
- 插入
- 删除
- 更新
下面两个是 点查、范围查找
- 点查的时候,根据索引找到需要查找的分区,然后分区内全部遍历就能找到对应的值
- 范围查找,根据起始-结束 key,找到 第一个和最后一个分区,因为分区之间都是相对有序,落在中间的分区全部读取即可

Figure 3: Maintaining range partitions in a column chunk allows for fast execution of read queries. For point queries - (b), the partition that may contain the value in question is fully scanned. For range queries
- (c) the partitions that (may) contain the first and the last element belonging to the range are scanned, while any intermediate partitions are blindly consumed.
插入、删除、更新 场景
- 插入要用到 ripple-insert 算法,首先定位到分区,然后相邻的分区 第一个元素,挪动后后面一个分区
- 同理后面分区也这样操作,这就是一个递归操作,一直找到最后一个分区,如果空间不够则扩展
- 腾出位置后,就可以将值插入了;之后每个分区的边界都需要扩展一下
- 删除也是定位到某个具体分区,然后最后一个分区的最后一个元素,移动到前一个分区的最后一个;这里分区边界要缩小
- 一直重复这个操作,到当前分区,用最后一个覆盖要删除的值
- 对于更新,等于 删除 + 插入
- 先定位老的值所在的分区和位置,再定位新的值应该在的分区和位置,在这两个分区以及中间分区之间通过 Ripple 的方式正向或者负向的移动数据即可
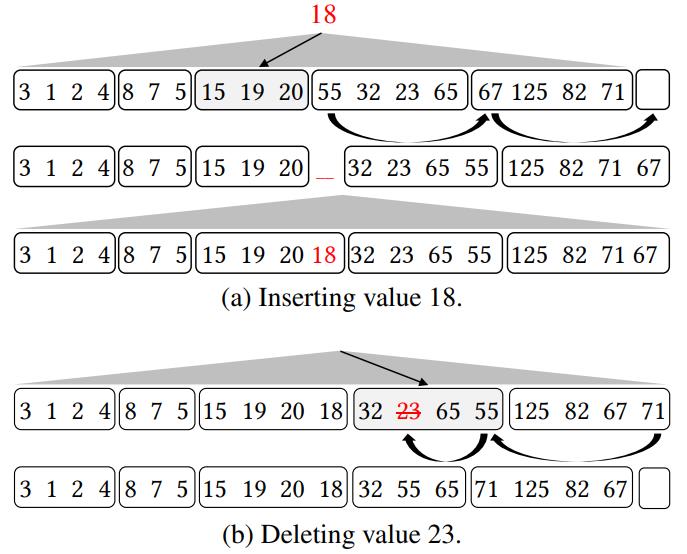
Figure 4: Inserting and deleting data in a partitioned column chunk uses rippling and restricts data movement.
每个分区中增加一个空值,可以减少移动

Figure 5: Adding ghost values allows for less data movement; inserts use empty slots and deletes create new ones.
检测模型
最小代价模型
avg min cost(W, D, P)
这里的 W 是工作负载、D 是数据集、P 是 分区模式
可以设置 block 的大小,它可以是缓存行的数倍,比如这里设置为 2
一个 block 就对应一个 bit 位,如果这个 bit 为0,表示不是分区边界,如果是 1 表示分区边界
下图 b,一个分区跨了三个block,第二分区是 2个block,第三个是 1个,第四个是 2个,每个分区结尾的 bit 都是设置为 1
下图 c,都是按照 2个 block 一个分区来设置
分区大粒度是可以调整的,可大可小

Figure 6: Representing different partitioning schemes (b) and (c) with block size B = 2.
在 五种基本模型(点查、范围、插入、更新、删除),基础上,定义了10种直方图
用来统计访问频率
- pq,计算每个点查的 block访问
- rs,用来统计 range查询的开始块
- re,统计 range 查询的结束块
- sc,统计 range查询时,block的全扫描
- de,统计每个block 的删除
- in,统计每个block 的插入
- udf 和 udb 用来统计 update 删除的 向前/向后 ripple
- utf、utb 跟上面类似
下图中使用了直方图,来统计每个 block 对于不同情况的访问频率
 Figure 7: Frequency model in action. Here we show for each operation which partitions are accessed, and consequently, which histogram buckets are updated.
Figure 7: Frequency model in action. Here we show for each operation which partitions are accessed, and consequently, which histogram buckets are updated.
可以从工作负载模型中抽取样本,然后建立直方图
也可以根据数据部分建立模型
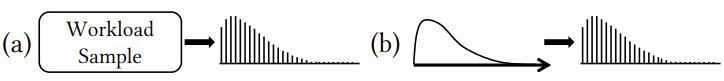 Figure 8: Learning FM from (a) samples or (b) distributions.
Figure 8: Learning FM from (a) samples or (b) distributions.
5种 基本操作对应了底层磁盘 I/O 操作,随机读、随机写、顺序读、顺序写
总工作负载代价 = 不同的基本操作的代价之和 = 不同数量的磁盘block/chunk的读写代价之和 =
不同数量的磁盘block/chunk的不同读写方式 * 总次数代价之和
图9a显示了使用10M个元素的块(每个元素有100个分区)时测量的和基于模型的插入成本
图9b显示了测量的和基于模型的点查询成本
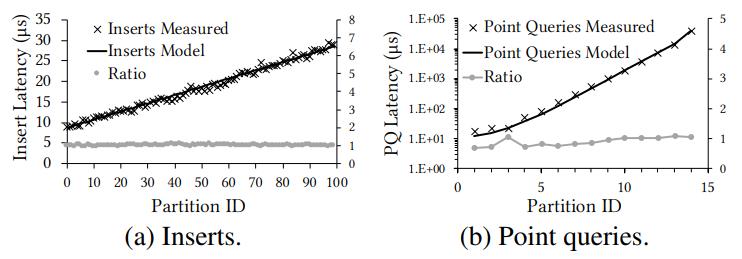 Figure 9: Cost model verification for (a) inserts and (b) point queries (10M chunk, exponentially increasing partition size).
Figure 9: Cost model verification for (a) inserts and (b) point queries (10M chunk, exponentially increasing partition size).
通过定义block 划分,也就是一堆 1 和 0,用来标识分区的边界,连续的或者是边界
这是以 bit 位的方式输出的,有了每个 block 级别的访问频率统计信息。有对应的代价预估模型,以及分区表达输出方式
这样就可以找到最优方案了
这是一个 binary optimization problem,NP hard问题
采集读写数据 –> 训练基本负载模型 –> 二进制优化分区 –> 实际分区挑战平衡读写 –> 被实际读写应用 –> 采集读写数据。。。
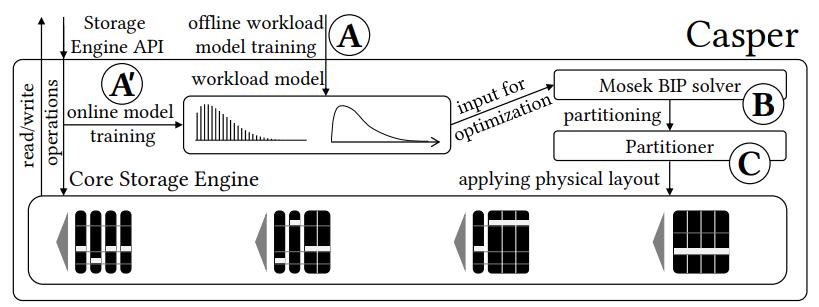 Figure 10: System architecture. (A) Casper uses offline workload information, (B) solves the BIP and (C) applies the partitioning. (A0) During execution monitoring, if the access patterns change, a re-partitioning cycle is triggered.
Figure 10: System architecture. (A) Casper uses offline workload information, (B) solves the BIP and (C) applies the partitioning. (A0) During execution monitoring, if the access patterns change, a re-partitioning cycle is triggered.
由于是 HTAP 场景,还有一些问题需要关注
- 事务,使用MVCC 实现快照隔离,乐观并发策略;对于ghost-value,事务回滚时可以忽略
- 压缩,使用dictionary 编码(很多数据相似)、delta编码(整数情况),而 RLE 需要数据集有序,并且又编码解码开销,所以不如前两者
- 分区定位,5种基本操作,都需要快速定位某个分区,因此构建一个多路搜索树、min-max等zonemap技术、面向cache line对齐等技术,都可以加速计算
性能评估
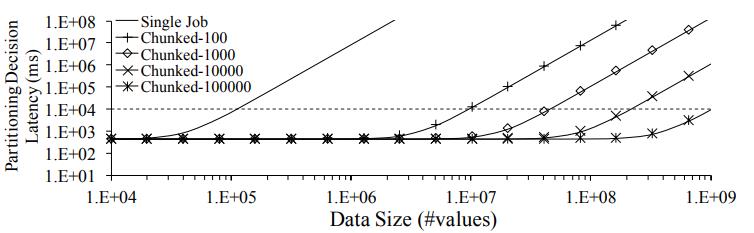 Figure 11: Casper partitioning scales with data size.
Figure 11: Casper partitioning scales with data size.
测量的数据布局包括
- 原生的没有组织的列,也没有排序
- 带排序的列
- 最新技术的更新感知技术,使用 delta 存储新的更新
- 列存储等宽分区数据
- 列存储等宽的分区数据,并带有 ghost-value
- Casper 将所有优化整合
使用了包含混合、读、写、更新的测试用例
可以看到,对于混合场景、更新场景 Casper 要好很多
而只读场景跟其他最好的差不多
但 Casper 目标是混合场景,从测试效果看基本是达到了
 Figure 12: Casper matches or significantly outperforms other column layouts approaches for a variety of workloads (experiments with 16 threads, chunks of 1M values, block size 16KB, and ghost values 0.1%).
Figure 12: Casper matches or significantly outperforms other column layouts approaches for a variety of workloads (experiments with 16 threads, chunks of 1M values, block size 16KB, and ghost values 0.1%).
对于混合、只读、只更新的场景,Casper 比其他都要好,而且吞吐量也不会降低
基本上只有 read only的跟其他场景差不多,其他都要更好
 Figure 13: Casper offers significant performance benefits.
Figure 13: Casper offers significant performance benefits.
- In (a) for a hybrid workload with skewed point queries and inserts, Casper outperforms all approaches by balancing the read and update performance.
- In (b) for a read-heavy workload with range queries, point queries, and a few inserts, Casper matches the state-of-the-art delta-store design. Finally,
- in (c) for an update-only workload, Casper significantly outperforms by 2× or more all other approaches.
通过提升 ghost-value 的比列,也能提升性能
对于插入、更新、混合场景都有不少提升
1% 的数据是 ghost-value情况下,插入延迟可以降低 2倍
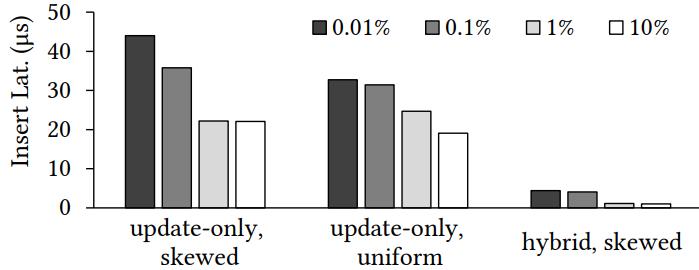 Figure 14: Using ghost values (4 thr., 1M chunks, 16KB blocks).
Figure 14: Using ghost values (4 thr., 1M chunks, 16KB blocks).
在满足 SLA 的同时,性能、吞吐量也没有下降
降低插入延迟的要求后, SLA 也会呈比列提高
Casper平衡了总体吞吐量,并以较小的性能损失(< 3%) 满足插入SLA
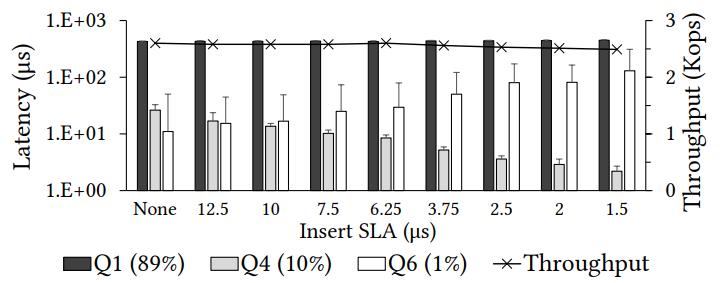 Figure 15: Casper meets performance SLA executing a hybrid workload (Q1,Q4,Q6) (1M chunk size, 16KB block size).
Figure 15: Casper meets performance SLA executing a hybrid workload (Q1,Q4,Q6) (1M chunk size, 16KB block size).
Casper提供了一个健壮的物理布局,它吸收了高达15%的质量位移和高达10%的旋转位移方面的不确定性,而没有任何明显的损失
然而,随着不确定性的增加,我们观察到性能损失高达60%
通过开发新的健壮调优范例,有机会获得更高的收益。我们把使用鲁棒优化技术的新问题表述作为未来的工作
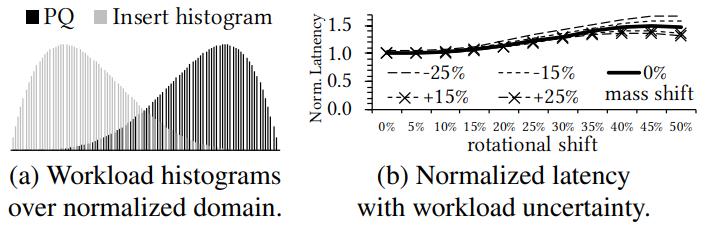 Figure 16: Testing Casper’s robustness.
Figure 16: Testing Casper’s robustness.
总结一下
- delta存储支持主要为更新的场景,等宽分区支持读密集场景,Casper 两者都支持
- 列排序并不总是最优的
- 查询以range 为主时,等宽分区表现比较好
- ghost-value 对列布局影响很大
- ghost-value 对更新有很大提升,对读开销影响很小
后续计划
- Offline Physical Design and Data Partitioning
- Casper是在读取性能、更新性能和内存利用之间进行三方面权衡的第一种方法,它通过分区决策和为更新较多的分区使用额外空间(幽灵值)来实现。
- Physical Design by Querying
- Learning Database Tuning
- Column-Stores and Updates
- Casper支持沿着三个维度进行调优,平衡读取性能、更新性能和内存利用率
- Ghost Values
参考引用
- The SAP HANA Database – An Architecture Overview. IEEE Data Engineering Bulletin, 35(1):28–33,2012.
- A Common Database Approach for OLTP and OLAP Using an In-Memory Column Database. In Proceedings of the ACM SIGMOD International Conference on Management of Data, pages 1–2, 2009
- SAP HANA: ¨The Evolution from a Modern Main-Memory Data Platform to an Enterprise Application Platform. PVLDB, 6(11):1184–1185, 2013
- 《Optimal Column Layout for Hybrid Workloads》论文读后感
- [ Bridging the Archipelago between Row-Stores and Column-Stores for Hybrid Workloads 2016]
- [Multi-Version Concurrency Control for Main-Memory Database System 2015]
- [Efficient Transaction Processing for Hyrise in Mixed Workload Environments 2014
- [Clay: Fine-Grained Adaptive Partitioning for General Database Schemas 2016]