SqlServer的列存索引
原文 https://15721.courses.cs.cmu.edu/spring2023/papers/04-olapindexes/p1177-larson.pdf
背景
微软在 SQL Server 11.0 版本,推出了一款纯的列数据库,代号 Denali
从测试效果看非常不错,对 TPC-DS 的 1T 数据做了测试,包含冷数据,和温数据
从结果看,列存场景比 行存有 10 - 20倍的提升
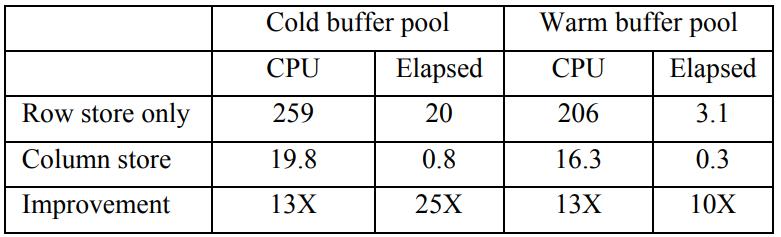
Table 1: Observed CPU and elapsed times (in sec)
SQL Server 早期有两种存储组织
- heap,未排序的
- B树,排序的
这两种都是面向行的,表或者物化视图总是包含一个主存储结构、以及二级搜因
主存储是 heap、B树,二级索引只能是 B树
也支持 filtered 索引,只存储满足选择谓词的行
任何索引都可以当做 列存索引,做的事情也没有限制
列存的物理数据组织方式,首先是将行分组,然后每组再分成若干个列
这里一共 3个行组,每个3 个列,一共 9个列segments
这里没每个行存都是独立的,所以不同组的列数据都是可以独立压缩的
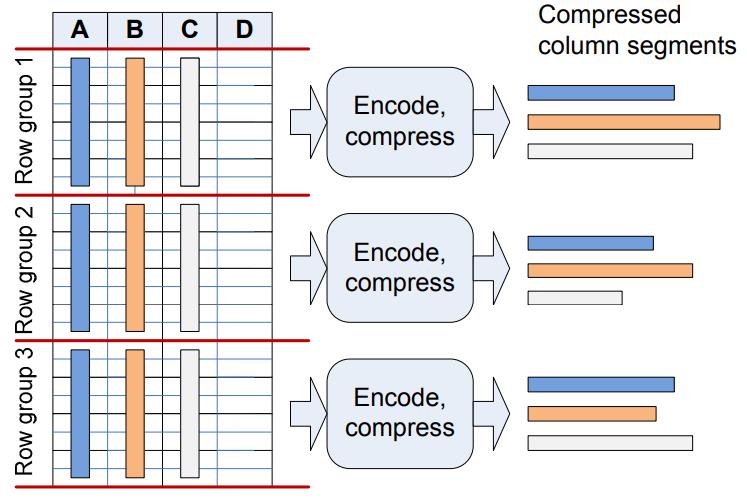 Figure 1: Converting rows to column segments
Figure 1: Converting rows to column segments
索引存储结构
每个 column segment 当做 独立的 blob存储
segment 可能很大,会被自动分成多个 page
这里还有一个 directory 来跟踪每个 segment,directory 可以通过系统 catalog sys.column_store_segments 获取
directory 也包含了一些元信息,行数量、size、多少数据被编码,min、max等
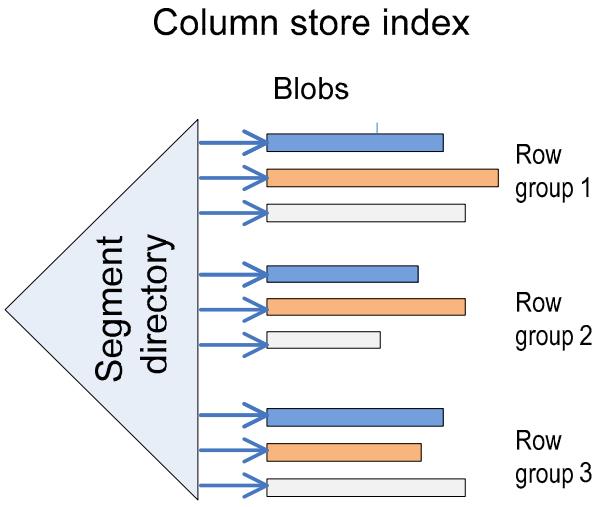
Figure 2: Storing column segments
这种存储方式 列存储索引,好处是
- 使用现有的 blob存储和 catalog 实现,无需新的存储机制
- 很多机制都是自动可用的,如lock、日志、恢复、分区、镜像、复制
- 以及其他一些特定对新的索引类型都是立刻可用的
编码列包含三个阶段
- 对所有列中的值进行编码。
- 确定最优的行排序。
- 压缩每个列
编码方式有两种
- 字典编码
- 基于值的编码
字典编码本质上是一个按数据id索引的数组,每个字典按 blob 存储
并存储到系统表中 sys.column_store_dictionaries
基于值的编码,是将一个大范围的值转换为一个更小的值
比如 0.5、10.77、1.333,应用指数 3(1000)后,就变成了500、10700、1333
也可以应用负指数,如 -2(1/100),对于值500、1700、133300 就变成了: 5,17、13330
首先选择一个一个基数作为最小数,然后每个数都减去这个最小数
比如基数为500、则调整后的值为:0、10270、833
还可以对数据做压缩,如采用 run-length 编码,RLE,这样可以直接基于压缩数据读取,首先对行组做排序,然后压缩
SQL Server 使用的是专利技术:Vertipaq
RLE 被存储为 <value, count> 对
数据从磁盘 -> 内存,不再是面向page的布局,而是连续的 buffer pool 布局
另外 column segment 分成一个一个的page,可以应用预读取技术
查询处理和优化
在这种新的索引基数上需要有新的引擎,但这种引擎不是重新设计的,而是基于现有技术改进的
- 对于客户来说他们使用的还是原有技术,但是新索引类型会加速查询
- 减少了实现成本,并且很多成熟的技术都是可以立刻使用的,如查询计划图、查询执行统计、SQL profiling、SQL debug等
- 查询计划可能会混合多个算子,查询优化会扩展选择最优算子类型
- 查询可以在运行时动态的从 批量操作 转换为 一次一行的操作
- 新操作类型也可以帮助现有技术提升效率
虽然说 一次一批 比一次行提高不少性能,但也达不到数量级的提升,论文中还有几点改进,可以有数量级性能提升
- 利用最新CPU的特性,多核
- bitmap filter
- 算子之间的内存共享
在SQL Server中采用了一种“混合”模式来处理查询:
- 首先将原始行格式转换为批(即按块)格式,并利用批处理操作符等新特性快速完成相关计算
- 然后再根据需要将结果转换回行格式并返回给用户或其他应用程序
以下是一些需要在行和批之间进行转换的具体场景:
- 执行聚合操作,如SUM、AVG等;
- 进行连接操作,如JOIN、UNION等;
- 对大型表进行扫描或筛选时(例如数据仓库中的事实表);
- 在查询结果集较大时(例如返回数百万条记录)。
为了支持列存储索引,SQL Server做了以下查询优化方面的改进:
- 引入新算法用于构建最大尺寸批处理哈希连接管道以提高性能
- 引入位图过滤器和批处理操作符等新特性来减少I/O并提高CPU利用率
- 通过估计成本选择最佳执行计划,并对代价模型进行增强
列存索引的 IndexScan 支持下推 predicate 以及 bitmap(可能由 HashJoin 生成)
此外,还有 delayed materialization(延迟物化)、SIMD 指令集等支持
通过估算 CPU 和 IO 代价,判断使用 列索引,还是 B树索引
为支持行批混合操作,引入了一个新算子:BatchHashTableBuild
接收行、批输入,输出为 批,这个算子还带有 bitmap(Bloom filter),在scan 的早期阶段过滤更多的行
同时还引入了一个物理算子,实现行、批转换,还可以过滤掉不需要的转换
batch 与 row 看作一种 physical property:
- 所有 batch 算子都要求它的子节点是 batch 的
- 所有 row 算子都要求它的子节点是 row 的
- HashJoinBuild 是独立的一个算子,所以 batch 的 HashJoin 只会要求 probe-side 是 batch 的
snowflake 模型下启发式地构建 join order 的算法
- 这个算法会尽可能将 dimension table 作为 HashJoin 的 build side
- 从而构建出 bitmap 下推给 fact table 的 Index Scan(假设含有列式索引)
- 减少 Index Scan 输出的数据量
实验
数据压缩比例如下
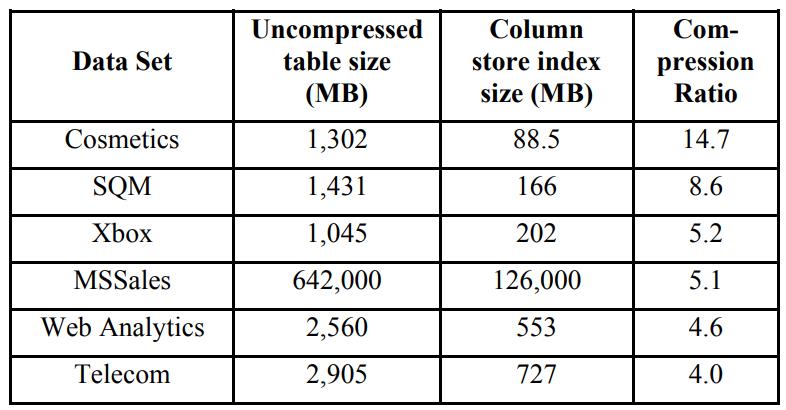
Table 2: Column store compression on real data sets
四个 TPC-DS 查询
- 一个事实表 + 两个维度表的星型查询
- 下钻查询
- 单表的聚合查询
- 带子查询的复杂查询
行存 vs 列存,在温数据的情况下对比,4个 TPC-DS 查询
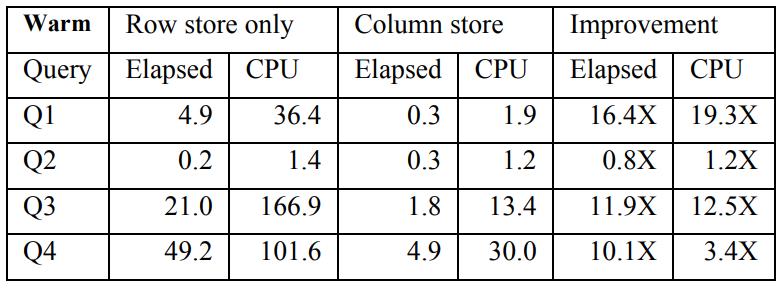 Table 3: Observed query times (sec) with warm buffer pool
Table 3: Observed query times (sec) with warm buffer pool
行存 vs 列存,在冷数据的情况下对比,4个 TPC-DS 查询
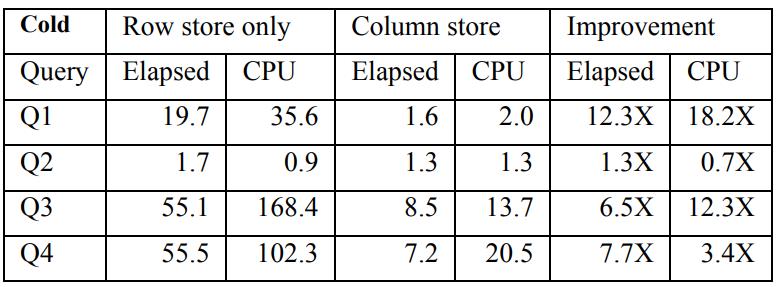 Table 4: Observed query times (sec) with cold buffer pool
Table 4: Observed query times (sec) with cold buffer pool
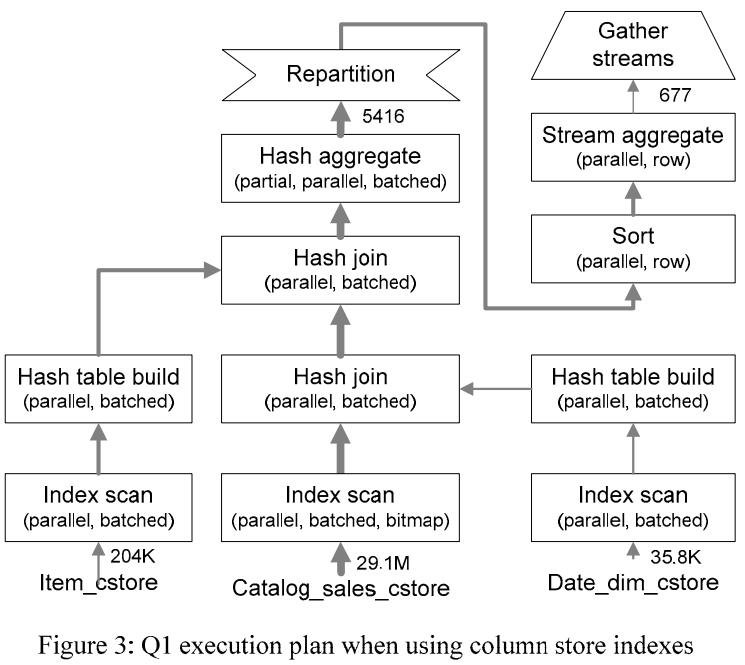
Q1 的查询计划如下
- 扫描两个维度表建立 hash-table
- 然后多个线程扫描多个 catalog_sales 的 segment 列存索引
- 并行的探测hash 表
- 最终聚合在每个流上并行完成,最后将结果元组聚集到单个输出流中
- 这里查询计划说明了 行、批是如何混合完成的,大部分处理是在批下完成的,只有最后的处理时在行下完从,那时只有 5416行
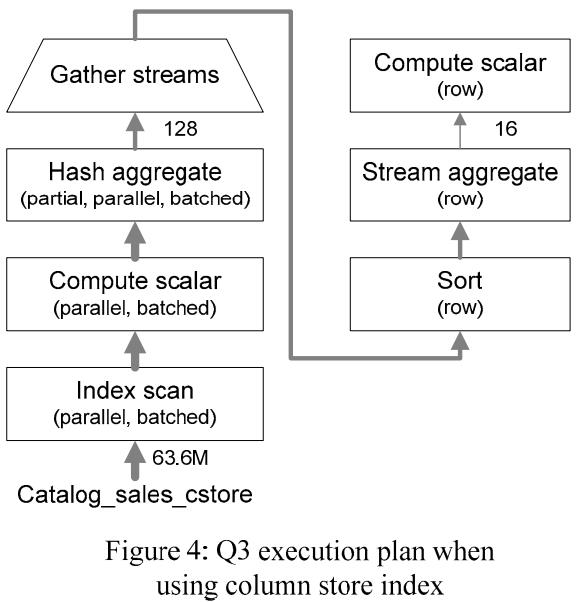
Q3的查询计划
- 批+行混合模式,跟行模式的查询计划差不多,但性能提高很多
- 因为使用了批处理
- 谓词下推过滤,可以减少很多数据扫描
在SQL的Denali版本中不支持直接更新和加载带有列存储索引的表
- 如果表足够小,可以删除它的列存储索引,执行更新,然后重建索引
- 于较大的表,可以使用分区加载staging表,用列存储索引对其进行索引,然后将其切换为最新的分区
关于列存的一些实例
关于列存的一些历史
- 1970年代就有相关研究了,把数据拆分成更小的子集
- 1975年有论文研究如何分解优化数据为更小的子集
- 1979年有研究如何在这小文件上做查询优化
- 1985年研究了如何完全分解存储,其中每个列存储在单独的文件中,也就是列存
- 沉寂了 20年,到2005年,Stonebraker 发表了 C-Store论文,之后又开始了列存研究的热潮
- Sybase IQ、MonetDB是最早的纯列式数据库
- 新玩家包括:Vertica、Exasol、Paraccel、InfoBright、SAND
- SQL Server是第一个将列存储和处理完全集成到系统中的通用数据库系统
- Ingres VectorWise是纯列数据库,但是跟 Ingres不兼容
- Greenplum、Aster Data是面向数仓的,最初是行存,然后增加了列存功能整合进来了