网易对Impala的一些使用
对Impala的一些增强
一些增强
- Impala 管理服务器
- 元数据同步增强
- 基于 zookeeper 的服务高可用
- 支持更多存储后端
- 其他增强和优化
图片来源,这里
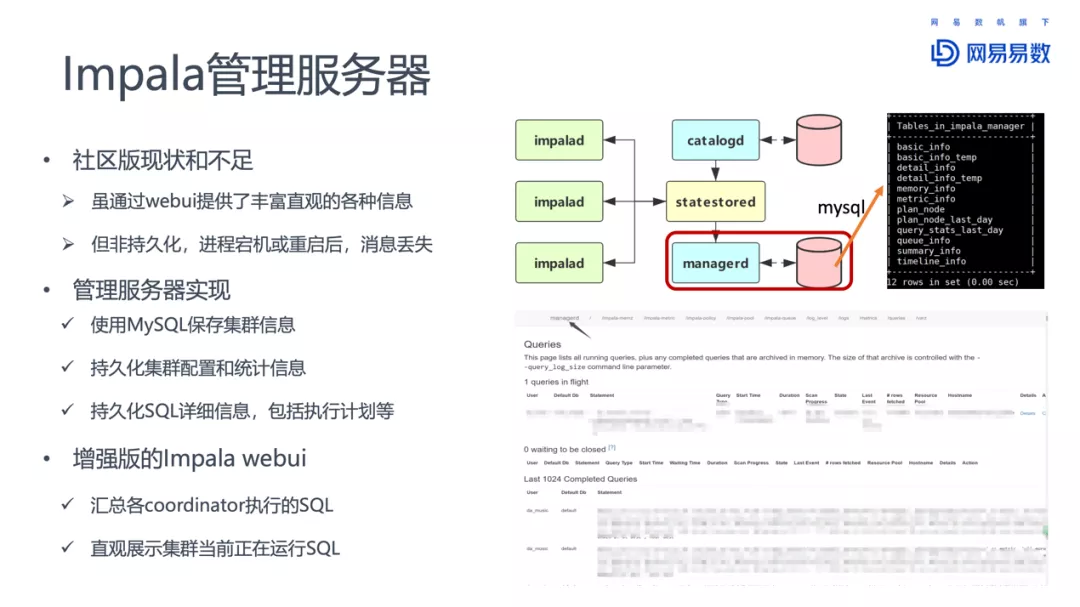
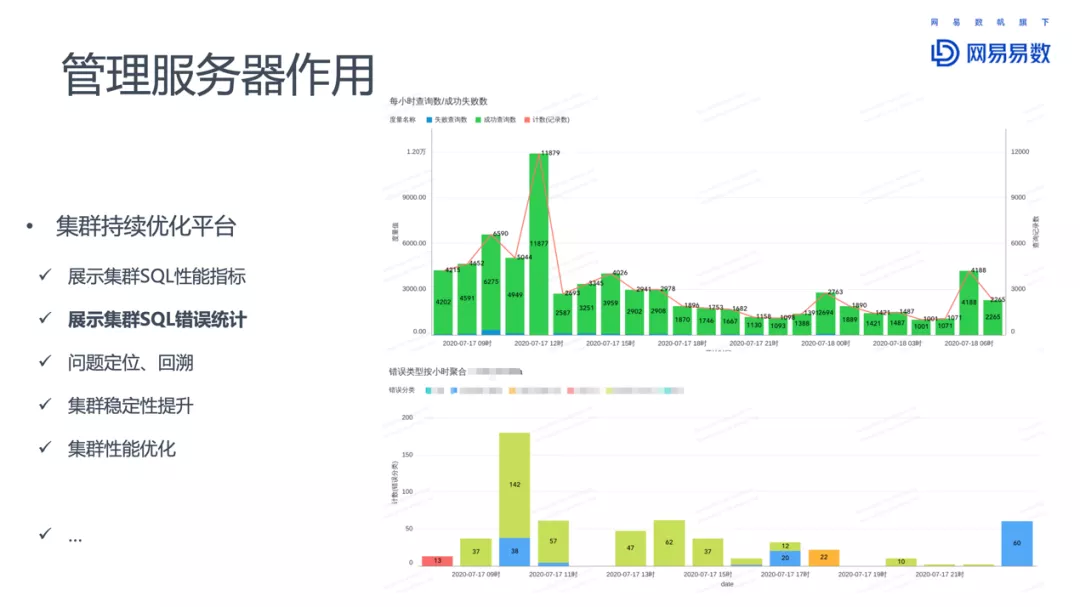
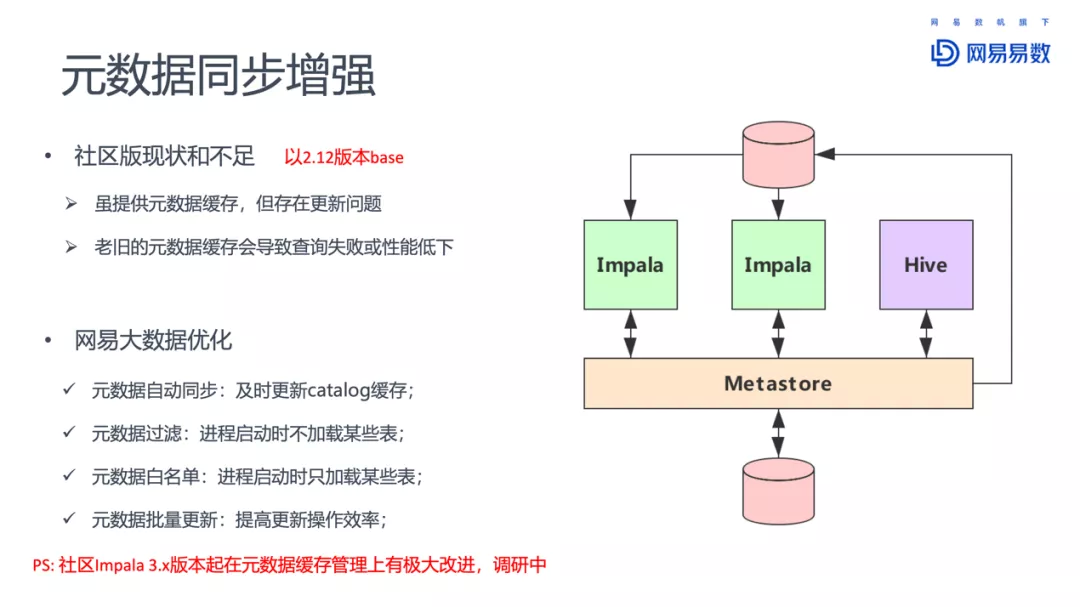
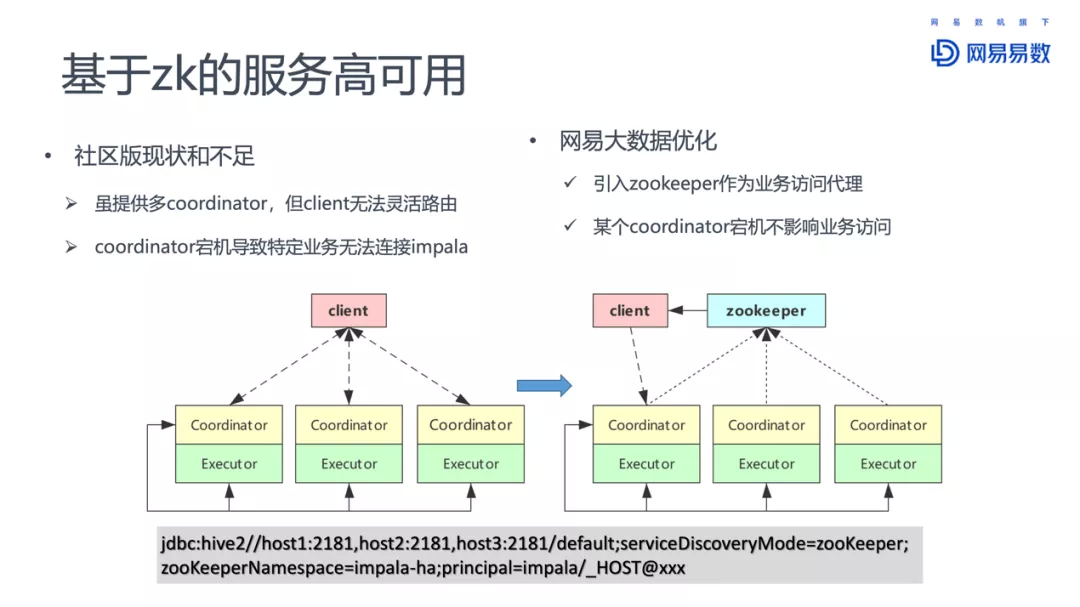
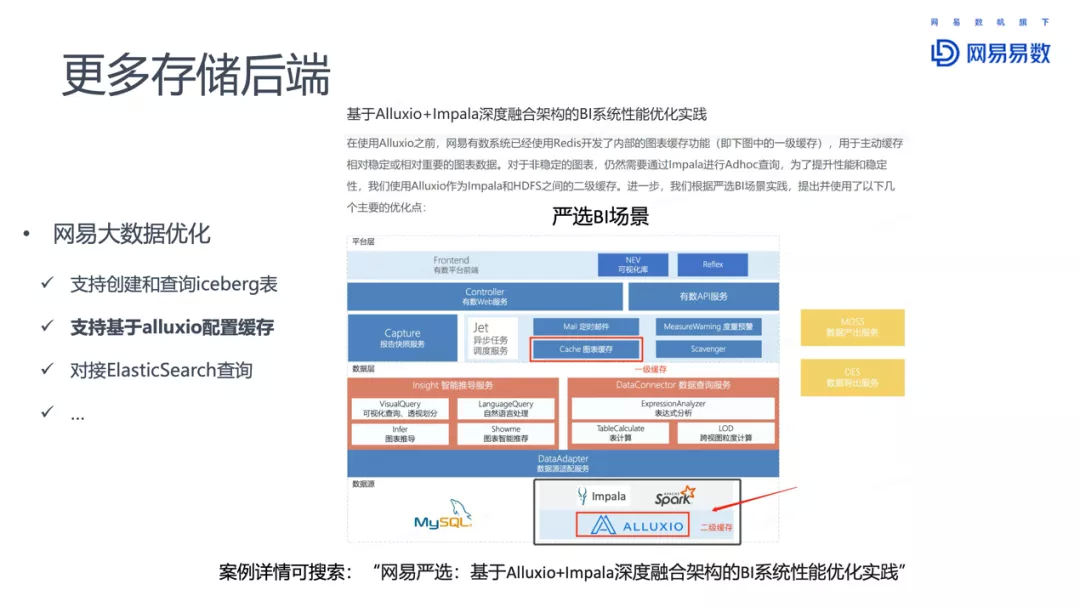


部署情况
- 独立部署
- 混部
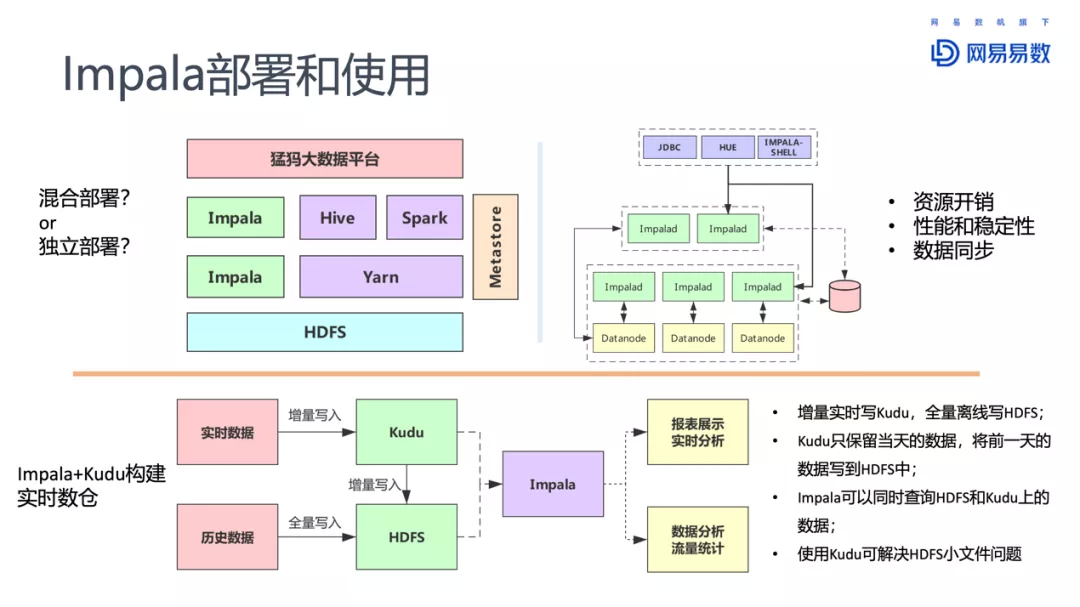
也用了 Impala + Kudu,构建实时数仓
有多个集群,总节点 200+,最大集群 60+
碰到的问题
- 混合型业务负载挑战
- 复杂/聚合查询性能差
- 统计信息缺失导致慢查询
- 元数据缓存和更新问题
- 存储层波动影响查询性能
- 集群状态周期性腐化
解决方式
- 混合型业务负载上,引入了虚拟数仓,对业务进行物理资源隔离,但会降低利用率
- 提供了统计信息自动计算的能力,CDC hive 的 DDL
- 提升性能,Impala 多线程(MT_DOP),多表物化视图
- 防止集群腐化,建立负载指标,引入趋势变化
- 查询历史持久化,还新增了排队耗时、内存预估和实际消耗、扫描的数据量等
- 物化视图监控,评估缓存命中效率
统计信息计算可以进行如下优化:
- 对于分区表,仅对频繁查询的分区计算统计信息,并定期删除旧分区统计信息;
- 对于宽表,仅对频繁查询的列计算统计信息;
- 对于记录数过多的表,启用统计信息高级特性:推断和采样(Extrapolation and Sampling)
物化视图
多表物化视图

使用了 calcite,嵌入到 FE 中,jar集成
SQL -> calcite AST -> rewirte -> back to impala SQL -> impala AST
物化视图生命周期管理,元数据存 MySQL
分类
- 单表物化、多表物化
- 明细、聚合物化
- 全量物化、增量
架构
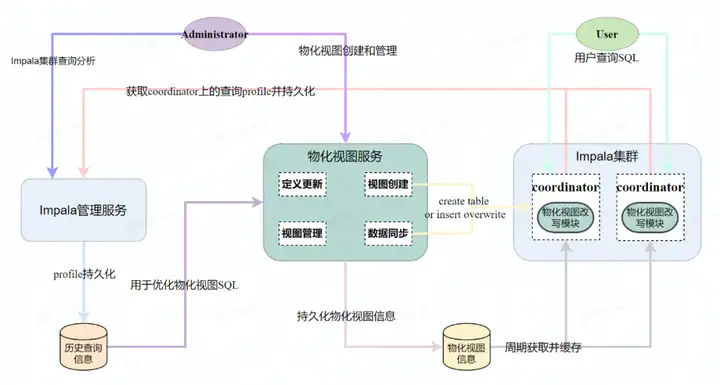
判断是否满足的条件
- 判断是否为实时或准实时表
- 判断是否能够进行模糊匹配
- 判断是否适合用物化视图进行优化,根据历史判断
物化视图改写
- 基于语法,匹配物化和当前SQL语法树,完全匹配或者子查询匹配才可以,适用范围小
- 基于规则的匹配,依赖转换规则查找等价关系,但需要实现复杂的关系转换和枚举,复杂join 不行
- 基于结构的改写,比如规则的简单,但对于 10+表 关联时,不如规则
微软 2001 年发表的论文《Optimizing queries using materialized views: A practical, scalable solution》
将查询表示为 SPJG,Join-Select-Project-GroupBy,提取其中的 join、project、filter、grouping
使用
- 根据物化命中情况,后台自动更新
Impala 物化视图服务对改写方式进行了优化,主要包括元数据缓存、命中预判定、支持更多 SQL 语法和改写校验等

提前预判
- 判断满足物化视图中涉及的表均在查询 SQL 中
- 判断满足查询返回的 selectList 属于物化视图 selectList 的子集
- 若查询 SQL 存在 Sort 算子(定义见下文),判断是否满足 Sort 算子的校验
- 若匹配的物化视图对象数量仍超过阈值,再通过归一化 SQL 进行匹配筛选
还需要对改写的 SQL 增加注释,表明这些改写过的,如果改写执行失败需要记录,再退回重试
需要有良好的机制,监控物化视图命中率
一般应用开发没有很强的 SQL 能力,预建物化视图需要 DBA,如何智能建立物化视图也是一个问题
虚拟数仓

所谓虚拟数仓就是一个集群中,分了多个组,每个组完成不同的业务,从而进行有效的负载隔离
两种方式
- 基于zk的命名空间,Impala 上不同的 Coordinator 注册到不同的 ZK 地址
- Set Request Group 的方式来将你的查询路由到某个虚拟分组中去,这种方式类似 Snowflake
statestored的扩展
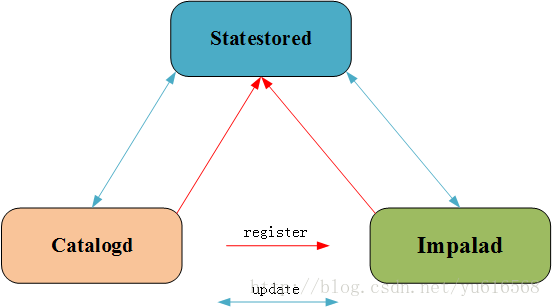
statestored 用于解耦,impalad、catalog 将一些信息注册到 statestored 上
这个组件主要用 thrift 通讯,将信息发布到内置的 topic 上
比如完成 集中查询持久化的功能:
- 每个 impalad 都注册一个新的 topic,如 impala-queries
- impalad 处理请求时,将机器信息,请求 ID 发到 impala-queries 这个 topic
- 新增一个特殊节点 manager,获取新增查询的信息,从 statestored
- 将这些信息持久存储,集中展示,同时异步计算 HBO,基于历史的查询
进一步
包括
- 物化视图自动化
- HBO 优化
- 多场景自动重试
- 向量化
- K8S 部署,资源动态调整和负载均衡,集群监控