Impala Tuning Summary
Architecture
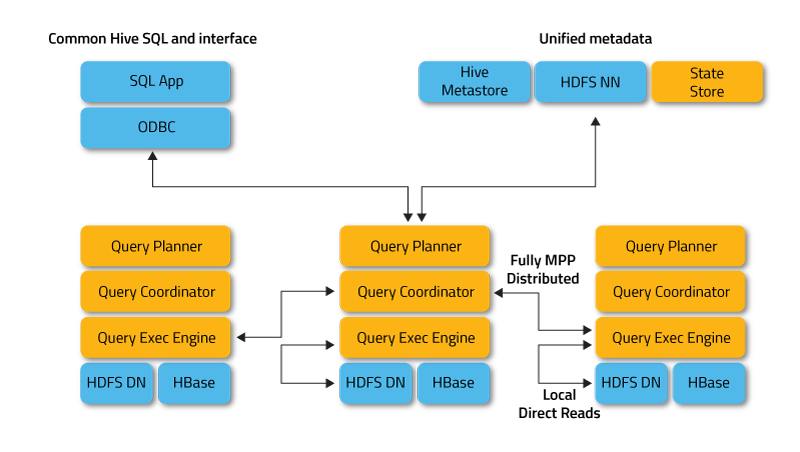
| componet | description |
|---|---|
| Impala Daemon | core Impala component,Plans and executes queries against HDFS, HBase, and Amazon S3 data |
| Statestore | checks on the health of all Impala daemons in a cluster, and continuously relays its findings to each of those daemons |
| Catalog Service | relays the metadata changes from Impala SQL statements to all the Impala daemons in a cluster |
Performance Tuning
Best Practices
- Choose the appropriate file format for the data
- Avoid data ingestion processes that produce many small files
- Choose partitioning granularity based on actual data volume
- Use smallest appropriate integer types for partition key columns
- Choose an appropriate Parquet block size, 256 MB block size for parquet
- Gather statistics for all tables used in performance-critical or high-volume join queries
- Minimize the overhead of transmitting results back to the client
- Verify that your queries are planned in an efficient logical manner
- Verify performance characteristics of queries
- Use appropriate operating system settings
Join Tuning
Join order example
- assume 4 tables: BIG, MEDIUM, SMALL, and TINY
- join order: BIG, TINY, SMALL, MEDIUM
distributed join type
| type | description |
|---|---|
| BROADCAST | The smaller table is broadcast to all nodes containing the larger table. It’s effective when one table is significantly smaller and can fit in memory across all nodes |
| PARTITIONED | Both tables are partitioned on the join key, ensuring that rows with the same key values end up on the same node. It’s used when joining two large tables |
| SHUFFLE | A shuffle join is performed when there’s no clear advantage to broadcasting or partitioning, or when it’s challenging to determine which table should be broadcasted. It involves redistributing the rows across nodes based on the join key |
STRAIGHT_JOIN
|
|
Statistics
Table and Column Statistics
|
|
limit for COMPUTE STATS
- Limit the number of columns
- more threads: MT_DOP
- if 30% of the rows have changed then it is recommended to recompute statistics
- COMPUTE STATS test_table TABLESAMPLE SYSTEM(10), 10% sample
- COMPUTE INCREMENTAL STATS
- COMPUTE INCREMENTAL STATS takes more time than COMPUTE STATS for the same volume of data
- DROP INCREMENTAL STATS
Runtime Filtering
- Build Phase: identifies candidate values from a large table (build side) for the join key,then constructs a bloom filter or hash table containing these values.
- Probe Phase: sends the smaller table (probe side) to the nodes where the build side data resides, then filtered using the previously constructed bloom filter or hash table,ensures that only relevant rows are processed for the join operation
- Dynamic Nature: runtime filters are dynamic and get applied during query execution.
- best for parquet
- wait intervals for runtime filter: RUNTIME_FILTER_WAIT_TIME_MS
other options
- RUNTIME_FILTER_MODE
- MAX_NUM_RUNTIME_FILTERS
- DISABLE_ROW_RUNTIME_FILTERING
- RUNTIME_FILTER_MAX_SIZE
- RUNTIME_FILTER_MIN_SIZE
- RUNTIME_BLOOM_FILTER_SIZE
Cache
HDFS cache
|
|
impala SQL
|
|
Detecting and Correcting HDFS Block Skew Conditions
- use SUMMARY, PROFILE, Impala debug web U
- find any Avg Time and a Max Time value in summary output
- adjust the PARQUET_FILE_SIZE reducing the block size
- use COMPRESSION_CODEC=NONE
Data Cache for Remote Reads
When Impala compute nodes and its storage are not co-located
|
|
Troubleshooting
Fault Tolerance
- RETRY_FAILED_QUERIES
- Node Blacklisting
test I/O
|
|
| Symptom | Explanation | Recommendation |
|---|---|---|
| Impala takes a long time to start | Impala instances with large numbers of tables, partitions, or data files take longer to start because the metadata for these objects is broadcast to all impalad nodes and cached | Adjust timeout and synchronicity settings |
| Joins fail to complete | There may be insufficient memory. During a join, data from the second, third, and so on sets to be joined is loaded into memory. If Impala chooses an inefficient join order or join mechanism, the query could exceed the total memory available | Start by gathering statistics with the COMPUTE STATS statement for each table involved in the join. Consider specifying the [SHUFFLE] hint so that data from the joined tables is split up between nodes rather than broadcast to each node. If tuning at the SQL level is not sufficient, add more memory to your system or join smaller data sets |
| Queries return incorrect results | Impala metadata may be outdated after changes are performed in Hive | Where possible, use the appropriate Impala statement (INSERT, LOAD DATA, CREATE TABLE, ALTER TABLE, COMPUTE STATS, and so on) rather than switching back and forth between Impala and Hive. Impala automatically broadcasts the results of DDL and DML operations to all Impala nodes in the cluster, but does not automatically recognize when such changes are made through Hive. After inserting data, adding a partition, or other operation in Hive |
| Queries are slow to return results | Some impalad instances may not have started. Using a browser, connect to the host running the Impala state store | Ensure Impala is installed on all DataNodes. Start any impalad instances that are not running |
Dedicated Coordinators
1 coordinator for every 50 executors.
including CPU, the number of threads, the number of connections, and RPCs, under 80%.
Consider the following factors to determine the right number of coordinators in your cluster:
- What is the number of concurrent queries?
- What percentage of the workload is DDL?
- What is the average query resource usage at the various stages (merge, runtime filter, result set size, etc.)?
- How many Impala Daemons (impalad) is in the cluster?
- Is there a high availability requirement?
- Compute/storage capacity reduction factor
WEB UI
impalad, http://IP:25000
- main page: version, hardware info, OS, process, cgroup
- admission
- backend
- catalog,all database all tables
- hadoop-varz
- jmx
- log_level
- logs
- memz
- metrics
- profile_docs
- queries
- rpcz
- sessions
- thredz
- varz
statstored, http://IP:25010/
- main page: version, hardware info, OS, process, cgroup
- log_level
- logs
- memz
- metrics
- profile_docs
- rpcz
- subscribers
- thredz
- topics
- varz
catalogd, http://IP:25020/
- main page: version, hardware info, OS, process, cgroup
- catalog, all database, all tables
- jmx
- log_level
- logs
- memz
- metrics
- operations
- profile_docs
- rpcz
- thredz
- varz
Administration
configuration
Setting Timeout
- Increasing the Statestore Timeout
- Setting the Idle Query and Idle Session Timeouts for impalad
- Setting Timeout and Retries for Thrift Connections to the Backend Client
- Cancelling a Query
- Setting a Time Limit on Query Execution
- Interactively Cancelling a Query
Proxy
- Choosing the Load-Balancing Algorithm
- Using Kerberos
- TLS/SSL Enabled
shell
|
|
Deployment Limits
- 150 nodes in Impala 2.12 and higher
- Number of Impalad Coordinators: 1 coordinator for at most every 50 executors
- Number of roles: 10,000 for Ranger
- Maximum number of columns in a query, included in a SELECT list, INSERT, and in an expression: no limit
- Number of tables referenced: no limit
- Number of plan nodes: no limit
- Number of plan fragments: no limit
- Depth of expression tree: 1000 hard limit
- Width of expression tree: 10,000 hard limit
- Codegen,Very deeply nested expressions within queries can exceed internal Impala limits
Spilling Data
- to Disk
- to HDFS
- to Ozone
example
|
|
Metadata Management
- Metadata on-demand mode
- Mixed mode
- Automatic Invalidation of Metadata Cache
- Automatic Invalidation/Refresh of Metadata
- Configure HMS for Event Based Automatic Metadata Sync
Security
Data and Log Files
Hive Metastore Database
Impala Web User Interface
TLS/SSL for Impala
Apache Ranger
Authorization,Privilege Model
|
|
Authentication
- Kerberos Authentication
- LDAP Authentication
- Multiple Authentication Methods
- Impala Delegation for Clients
Format of the Audit Log Files
- Client session state:
- Session ID
- User name
- Network address of the client connection
- SQL statement details:
- Query ID
- Statement Type - DML, DDL, and so on
- SQL statement text
- Execution start time, in local time
- Execution Status - Details on any errors that were encountered
- Target Catalog Objects:
- Object Type - Table, View, or Database
- Fully qualified object name
- Privilege
Lineage Information
- Column Lineage
- Lineage Data for Impala
- -lineage_event_log_dir for impalad
Admission Control
| parameters | desc | in config files |
|---|---|---|
| max memory | The maximum memory capacity of the resource pool is cluster-wide | fair-scheduler.xml, <queue> -> <maxResources> |
| maximum query memory | Maximum memory of a single node | impala.admission-control.max-query-mem-limit.root.default.regularPool |
| minimum query memory | Minimum memory for a single node | impala.admission-control.min-query-mem-limit.root.default.regularPool |
| max running queries | the maximum number of concurrent queries allowed by the resource pool | llama.am.throttling.maximum.placed.reservations.#QUEUE# |
| max queued queries | The maximum length of the queue, which is placed in the queue when the maximum parallelism is exceeded | llama.am.throttling.maximum.queued.reservations.#QUEUE# |
| queue timeout | The maximum waiting time in the queue | impala.admission-control.pool-queue-timeout-ms |
fair-scheduler.xml
|
|
llama-site.xml
|
|
SQL
Statements and Data Type
- ARRAY Complex Type
- BIGINT Data Type
- BOOLEAN Data Type
- CHAR Data Type
- DATE Data Type
- DECIMAL Data Type
- DOUBLE Data Type
- FLOAT Data Type
- INT Data Type
- MAP Complex Type
- REAL Data Type
- SMALLINT Data Type
- STRING Data Type
- STRUCT Complex Type
- TIMESTAMP Data Type
- TINYINT Data Type
- VARCHAR Data Type
DDL Statements
- ALTER TABLE
- ALTER VIEW
- COMPUTE STATS
- CREATE DATABASE
- CREATE FUNCTION
- CREATE ROLE
- CREATE TABLE
- CREATE VIEW
- DROP DATABASE
- DROP FUNCTION
- DROP ROLE
- DROP TABLE
- DROP VIEW
- GRANT
- REVOKE
- TRUNCATE TABLE
- SHUTDOWN
DML Statements
- DELETE
- INSERT
- LOAD DATA
- UPDATE
- UPSERT
- SHOW
- SELECT
- REFRESH
- REFRESH AUTHORIZATION
- REFRESH FUNCTIONS
complex or nested types
|
|
desc complex type
|
|
query complex type:
|
|
Functions
Built-In Functions
- Mathematical Functions
- Type Conversion Functions
- Date and Time Functions
- Conditional Functions
- String Functions
- Window Functions
- Analytic Functions
- Bit Functions
- Miscellaneous Functions
User-Defined Functions (UDFs)
|
|
c++ code
|
|
c++ code
|
|
other c++ example, build:
|
|
sql:
|
|
UDAF
|
|
Compatibility with Hive
The current release of Impala does not support the following SQL features that you might be familiar with from HiveQL
- Extensibility mechanisms such as TRANSFORM, custom file formats, or custom SerDes.
- The DATE data type.
- XML functions.
- Certain aggregate functions from HiveQL: covar_pop, covar_samp, corr, percentile, percentile_approx, histogram_numeric, collect_set; Impala supports the set of aggregate functions listed in Impala Aggregate Functions and analytic functions listed in Impala Analytic Functions.
- Sampling
- Lateral views
Impala does not currently support these HiveQL statements
- ANALYZE TABLE (the Impala equivalent is COMPUTE STATS)
- DESCRIBE COLUMN
- DESCRIBE DATABASE
- EXPORT TABLE
- IMPORT TABLE
- SHOW TABLE EXTENDED
- SHOW TBLPROPERTIES
- SHOW INDEXES
- SHOW COLUMNS
- INSERT OVERWRITE DIRECTORY;
Expalin
explain
|
|
summary
|
|
show table stats
|
|
show column
|
|
show partitions
|
|
File Formats
| File Type | Format | Compression Codecs | Impala Can CREATE? | Impala Can INSERT? |
|---|---|---|---|---|
| Parquet | Structured | Snappy, gzip, zstd, lz4; currently Snappy by default | Yes. | Yes: CREATE TABLE, INSERT, LOAD DATA, and query |
| ORC | Structured | gzip, Snappy, LZO, LZ4; currently gzip by default | Yes, in Impala 2.12.0 and higher.By default, ORC reads are enabled in Impala 3.4.0 and higher | No. Import data by using LOAD DATA on data files already in the right format, or use INSERT in Hive followed by REFRESH table_name in Impala. |
| Text | Unstructured | bzip2, deflate, gzip, LZO, Snappy, zstd | Yes. For CREATE TABLE with no STORED AS clause | If LZO compression is used, you must create the table and load data in Hive. |
| Avro | Structured | Snappy, gzip, deflate | Yes, in Impala 1.4.0 and higher. In lower versions, create the table using Hive | No. Import data by using LOAD DATA on data files already in the right format, or use INSERT in Hive followed by REFRESH table_name in Impala |
| Hudi | Structured | Snappy, gzip, zstd, lz4; currently Snappy by default | Yes, support for Read Optimized Queries is experimental | No. Create an external table in Impala. Set the table location to the Hudi table directory. Alternatively, create the Hudi table in Hive |
| RCFile | Structured | Snappy, gzip, deflate, bzip2 | Yes | No. Import data by using LOAD DATA on data files already in the right format, or use INSERT in Hive followed by REFRESH table_name in Impala |
| SequenceFile | Structured | Snappy, gzip, deflate, bzip2 | Yes | No. Import data by using LOAD DATA on data files already in the right format, or use INSERT in Hive followed by REFRESH table_name in Impala |
Supported table and storage
- Kudu Tables
- HBase Tables
- Iceberg Tables
- S3 Tables
- Azure Data Lake Store
- Isilon Storage
- Ozone Storage
for ice-berg
|
|
Reference
- Tuning Impala for Performance
- Apache Impala — Data Scientist Fundamentals Part I
- Query Join Performance
- Performance Tuning tips for Bigdata Tables in HQL/IMPALA
- What is Impala Troubleshooting & Performance Tuning
- Keeping Small Queries Fast – Short query optimizations in Apache Impala
- code source analyse
- Cloudera-Impala-JDBC-Example
- Resource Management
- Llama Default Configuration -Llama github