解析过程
语法解析
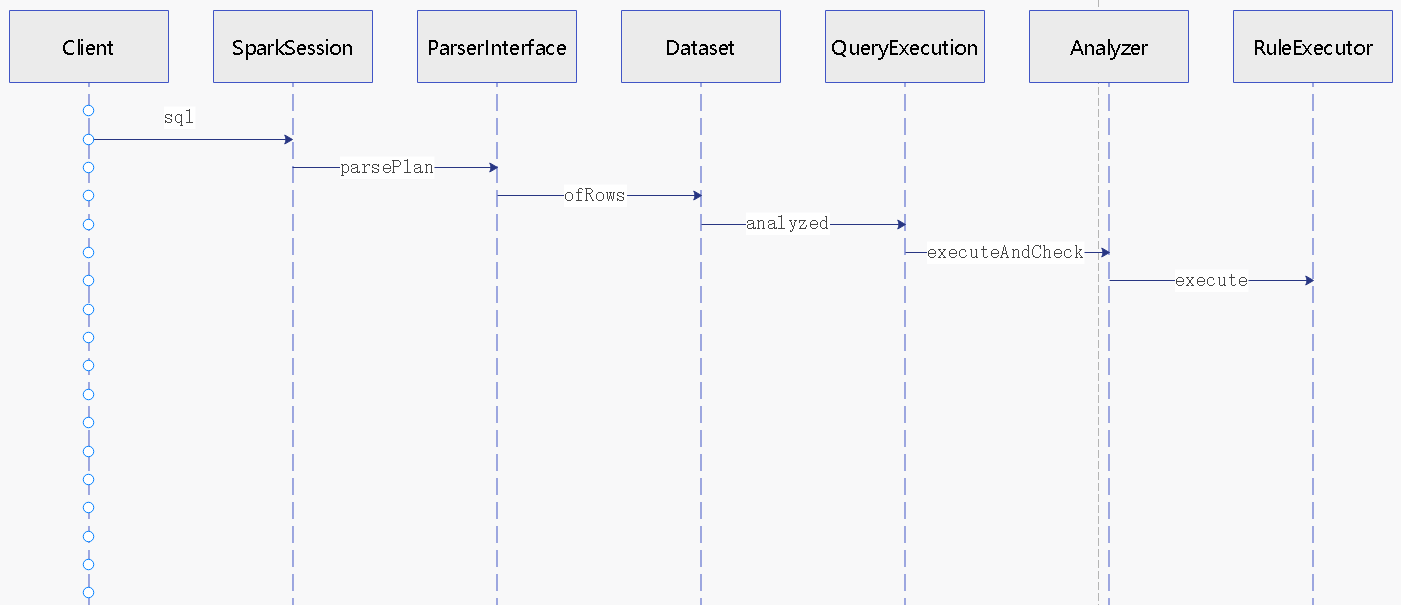
SparkSession 中,先解析SQL,转换成 Spark的逻辑计划,再处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
private[sql] def sql(
sqlText: String,
args: Map[String, Any],
tracker: QueryPlanningTracker): DataFrame =
withActive {
val plan = tracker.measurePhase(QueryPlanningTracker.PARSING) {
val parsedPlan = sessionState.sqlParser.parsePlan(sqlText)
if (args.nonEmpty) {
NameParameterizedQuery(parsedPlan, args.mapValues(lit(_).expr).toMap)
} else {
parsedPlan
}
}
Dataset.ofRows(self, plan, tracker)
}
|
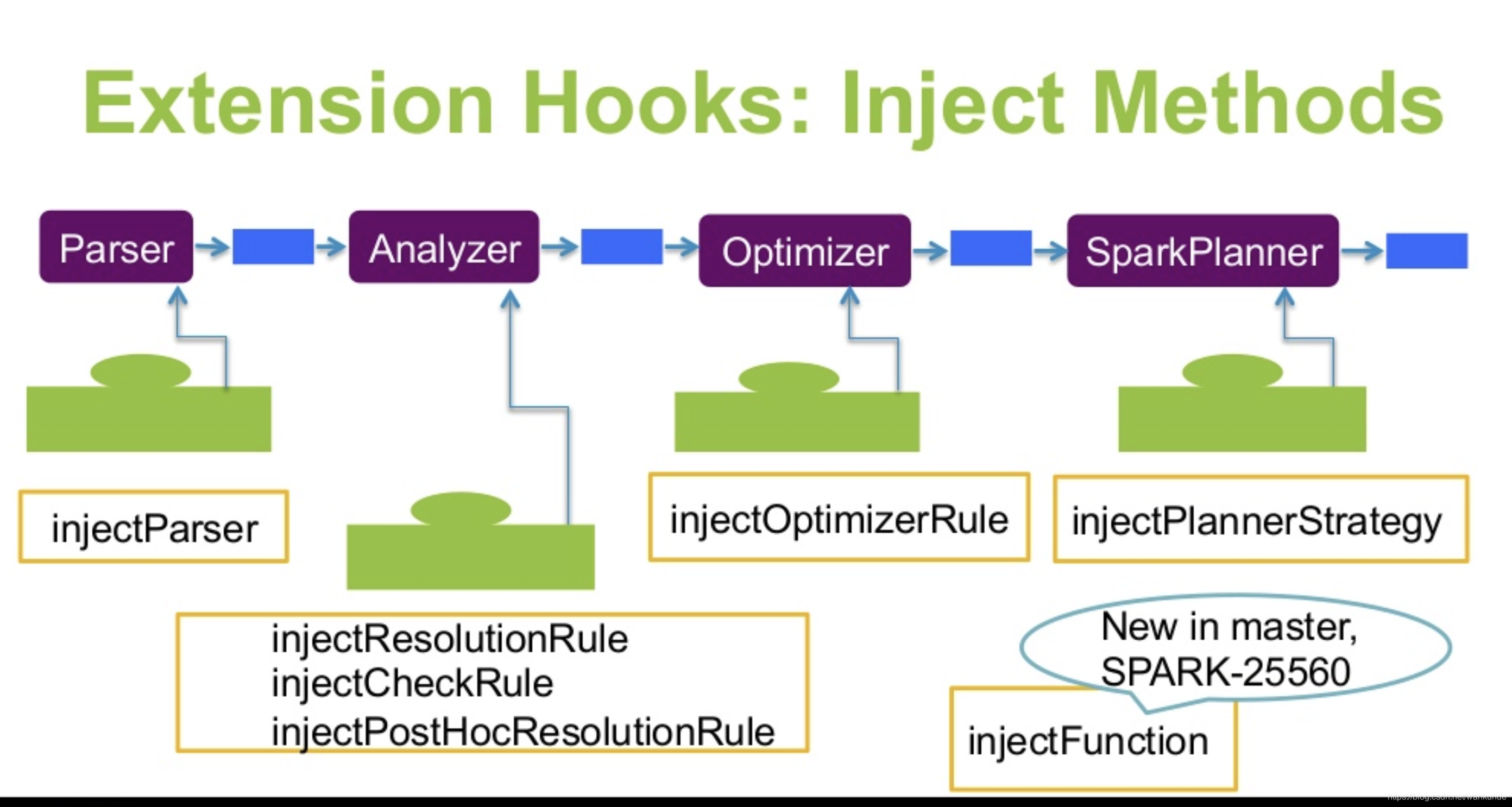
逻辑计划
执行过程(省略了很多细节):
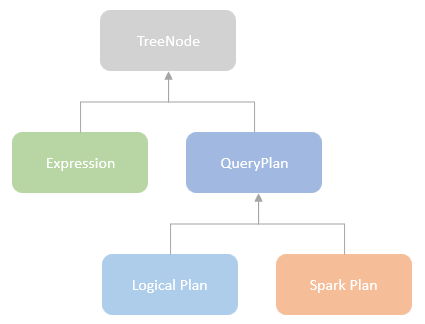
类的层次关系
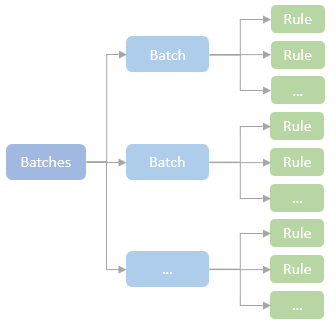
RuleExecutor#execute 的主要逻辑:
1
2
3
4
5
6
7
8
9
10
|
// Run until fix point (or the max number of iterations as specified in the strategy.
while (continue) {
curPlan = batch.rules.foldLeft(curPlan) {
case (plan, rule) =>
val startTime = System.nanoTime()
val result = rule(plan)
val runTime = System.nanoTime() - startTime
val effective = !result.fastEquals(plan)
|
内置的 所有逻辑计划规则:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
0 = {ResolveCatalogs@10511}
1 = {Analyzer$ResolveInsertInto$@10365}
2 = {Analyzer$ResolveRelations$@10364}
3 = {ResolvePartitionSpec$@10512}
4 = {Analyzer$ResolveFieldNameAndPosition$@10387}
5 = {Analyzer$AddMetadataColumns$@10363}
6 = {DeduplicateRelations$@10513}
7 = {Analyzer$ResolveReferences$@10366}
8 = {ResolveLateralColumnAliasReference$@10514}
9 = {ResolveExpressionsWithNamePlaceholders$@10515}
10 = {Analyzer$ResolveDeserializer$@10384}
11 = {Analyzer$ResolveNewInstance$@10385}
12 = {Analyzer$ResolveUpCast$@10386}
13 = {Analyzer$ResolveGroupingAnalytics$@10360}
14 = {Analyzer$ResolvePivot$@10361}
15 = {Analyzer$ResolveUnpivot$@10362}
16 = {Analyzer$ResolveOrdinalInOrderByAndGroupBy$@10367}
17 = {Analyzer$ExtractGenerator$@10374}
18 = {Analyzer$ResolveGenerate$@10375}
19 = {Analyzer$ResolveFunctions$@10369}
20 = {ResolveTableSpec$@10516}
21 = {Analyzer$ResolveAliases$@10359}
22 = {Analyzer$ResolveSubquery$@10370}
23 = {Analyzer$ResolveSubqueryColumnAliases$@10371}
24 = {Analyzer$ResolveWindowOrder$@10381}
25 = {Analyzer$ResolveWindowFrame$@10380}
26 = {Analyzer$ResolveNaturalAndUsingJoin$@10382}
27 = {Analyzer$ResolveOutputRelation$@10383}
28 = {Analyzer$ExtractWindowExpressions$@10376}
29 = {Analyzer$GlobalAggregates$@10372}
30 = {Analyzer$ResolveAggregateFunctions$@10373}
31 = {TimeWindowing$@10517}
32 = {SessionWindowing$@10518}
33 = {ResolveWindowTime$@10519}
34 = {ResolveInlineTables$@10520}
35 = {ResolveLambdaVariables$@10521}
36 = {ResolveTimeZone$@10522}
37 = {Analyzer$ResolveRandomSeed$@10377}
38 = {Analyzer$ResolveBinaryArithmetic$@10357}
39 = {ResolveIdentifierClause$@10523}
40 = {ResolveUnion$@10524}
41 = {ResolveRowLevelCommandAssignments$@10525}
42 = {RewriteDeleteFromTable$@10526}
43 = {RewriteUpdateTable$@10527}
44 = {RewriteMergeIntoTable$@10528}
45 = {TypeCoercionBase$UnpivotCoercion$@10529}
46 = {TypeCoercionBase$WidenSetOperationTypes$@10530}
47 = {TypeCoercionBase$CombinedTypeCoercionRule@10531}
48 = {ResolveWithCTE$@10532}
49 = {ExtractDistributedSequenceID$@10533}
50 = {FindDataSourceTable@10534}
51 = {ResolveSQLOnFile@10535}
52 = {FallBackFileSourceV2@10536}
53 = {ResolveEncodersInScalaAgg$@10537}
54 = {ResolveSessionCatalog@10538}
55 = {ResolveWriteToStream$@10539}
56 = {EvalSubqueriesForTimeTravel@10540}
|
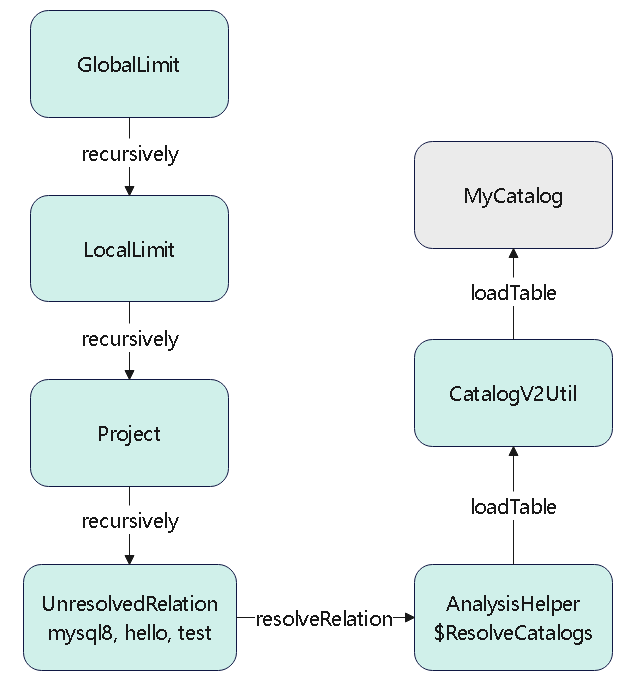
ResolveRelations
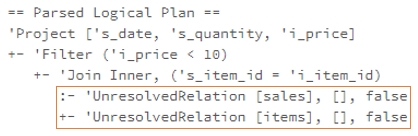
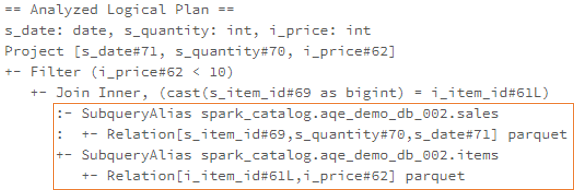
会调用到 loadTable,然后是 CatalogV2Util#loadTable,返回一个 Table 对象
以这个SQL为例子
1
|
SELECT id FROM mysql8.hello.test LIMIT 10
|
得到的逻辑计划:
1
2
3
4
|
'GlobalLimit 10
+- 'LocalLimit 10
+- 'Project ['id]
+- 'UnresolvedRelation [mysql58, hello, test], [], false
|
这里不断的递归往下,直到页节点,然后开始处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
def resolveOperatorsUpWithPruning(cond: TreePatternBits => Boolean,
ruleId: RuleId = UnknownRuleId)(rule: PartialFunction[LogicalPlan, LogicalPlan])
: LogicalPlan = {
if (!analyzed && cond.apply(self) && !isRuleIneffective(ruleId)) {
AnalysisHelper.allowInvokingTransformsInAnalyzer {
val afterRuleOnChildren = mapChildren(_.resolveOperatorsUpWithPruning(cond, ruleId)(rule))
val afterRule = if (self fastEquals afterRuleOnChildren) {
CurrentOrigin.withOrigin(origin) {
rule.applyOrElse(self, identity[LogicalPlan])
}
} else {
CurrentOrigin.withOrigin(origin) {
rule.applyOrElse(afterRuleOnChildren, identity[LogicalPlan])
}
}
。。。。。
}
} else {
self
}
}
|
执行过程如下:
ResolveReferences
自下而上的解析字段
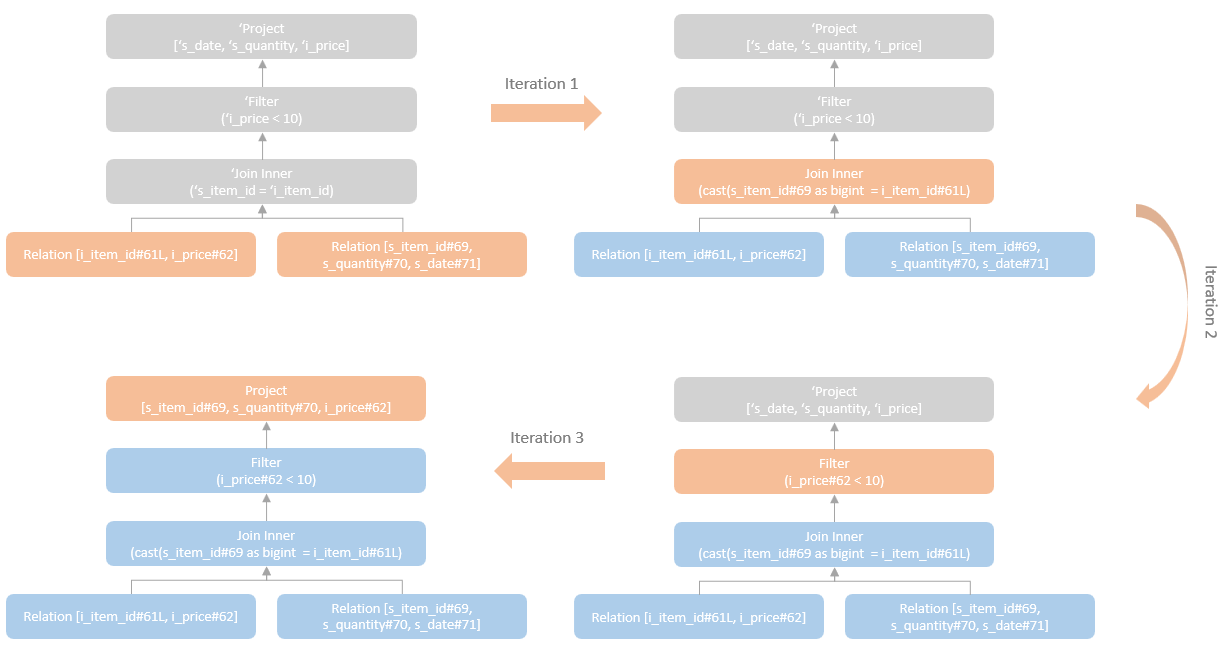
一次只能做一次转换,对于有很多子节点的情况,会执行多次转换
优化规则
Optimizer 类中的所有的优化规则
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
CheckCartesianProducts$
CollapseProject$
CollapseRepartition$
CollapseWindow$
ColumnPruning$
CombineFilters$
CombineUnions$
ConvertToLocalRelation$
DecimalAggregates$
EliminateAggregateFilter$
EliminateDistinct$
EliminateLimits$
EliminateOffsets$
EliminateSorts$
GenerateOptimization$
InferFiltersFromConstraints$
InferFiltersFromGenerate$
LimitPushDown$
Optimizer
OptimizeRepartition$
OptimizeWindowFunctions$
PruneFilters$
PushDownPredicates$
PushPredicateThroughJoin$
PushPredicateThroughNonJoin$
PushProjectionThroughUnion$
RemoveLiteralFromGroupExpressions$
RemoveNoopOperators$
RemoveNoopUnion$
RemoveRedundantAliases$
RemoveRepetitionFromGroupExpressions$
ReplaceDeduplicateWithAggregate$
ReplaceDistinctWithAggregate$
ReplaceExceptWithAntiJoin$
ReplaceIntersectWithSemiJoin$
RewriteExceptAll$
RewriteIntersectAll$
TransposeWindow$
|
查询下推
一个联邦查询中可能包含了好几个数据源,可以将同源的查询做合并,合并成一个大的join,直接下推给数据源处理
比如一个 联邦查询,包含了 mysql、hive、oracle、还有其他数据源
其中 mysql 出现了好 3次,也就是查询了 三个 mysql表,可以将这个查询合并,下推到数据源,让mysql自己处理
1
|
select * from mysql1, mysql2, mysql3, oracle, hive, es ...
|
这里一个 LogicPlan 可能包含多个数据源,然后判断是否可以合并下推
- 比如,一个JOIN条件,包含了两个、或多个同实例的MySQL(数据类型、IP、PORT相等),则可以合并成一个SQL下推过去
- 下图中假设 source-1 和source-2 都是同类型,且ip、port相同,可以合并下推
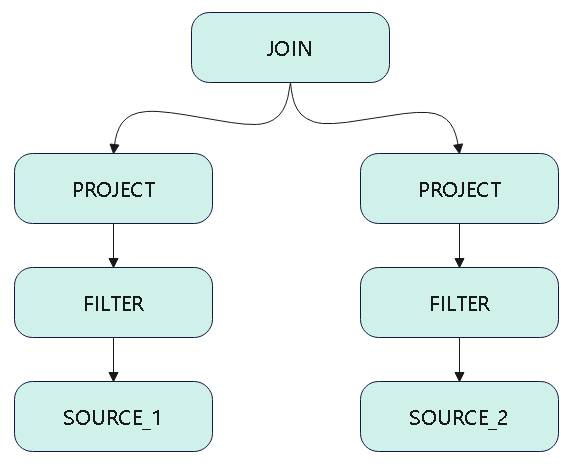
下推过程
- 使用 自顶向下来处理,判断当前的 LogicPlan 是否可以下推,比如JOIN 两边的数据源是同源而且相同的
- 将这个 LogicPlan 转为 Calcite 的逻辑计划,spark和calcite的逻辑计划不完全匹配,中间会有很多转换问题
- 使用 calcite 将逻辑计划,转换为 SQL,这是它自带的功能
- 将这个 logicplain 转为:DataSourceV2Relation,将SQL 作为 JDBCOptions 的query,也就是查询语句,封装进去
- 于是整个大的logicplan 就变成一个数据源了,后面生成代码的时候,直接根据这个数据源做 codegen,然后执行这个SQL
另一种情况,这种不好处理,因为要重写改写整个语法树了,很难处理
所以像这种情况下,mysql还是分别查两次,不做下推处理
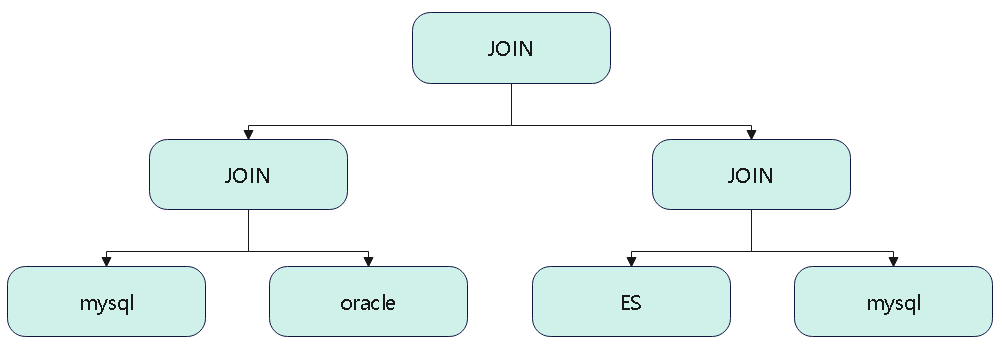
除了关系数据库,理论上非关系的 NoSQL 也可以下推,只要是同源的都可以
用 calcite 将这两个同源的 NoSQL,查询语句做合并,比如两个 ES 的,两个 HBase 的
因为有些 NoSQL,比如ES 实际不支持 index 做聚合,所以下推也没什么意义,大部分场景来说,NoSQL 的 join 可能都不适合下推
catalog
catalog结构
execute执行逻辑
以 CreateDatabaseCommand 为例,其调用逻辑如下
最终是用 hive client imp 调用到 hive meta-data,存到数据库中
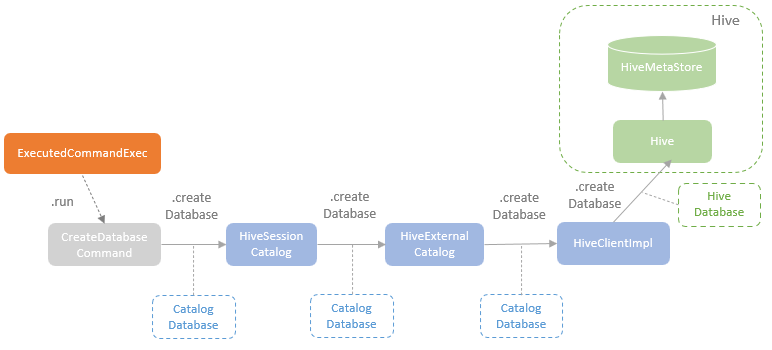
父类 RunnableCOmmand 和相关的缓存,序列化,视图的关系
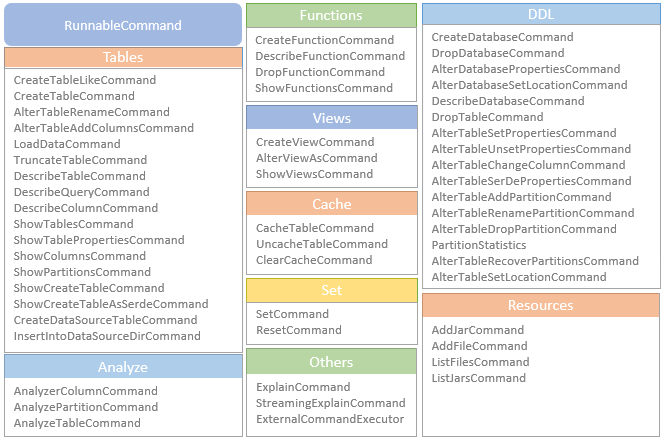
SessionCatalog 的调用链路
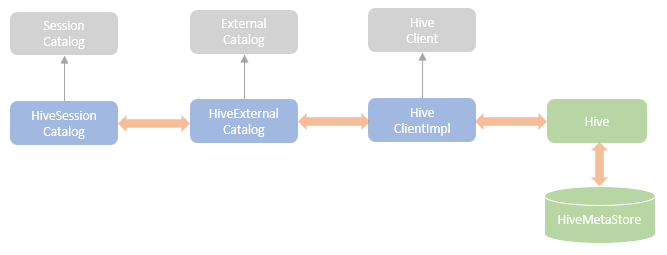
缓存
这个在 spark3.5 中已经 没有了
缓存的执行逻辑
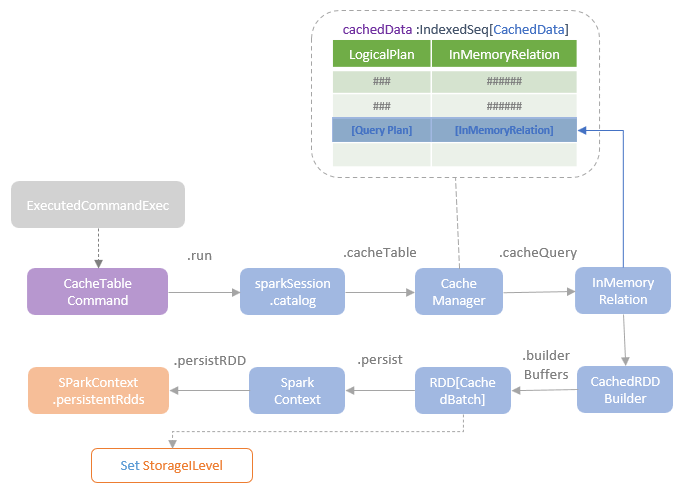
缓存的判断逻辑
UDF整体结构
比如这个 sql
1
|
SELECT my_add_123(id, 100) AS id FROM `mysql57-hello`.t1 AS t
|
这里的 my_add_123 是自定义的函数,功能很简单,将两个整数相加返回
实现方式
V1
自定义一个 my_add_123 函数,假设:
1
2
3
4
5
6
7
8
9
10
|
trait MyFunc extends Serializable {
def myfunc(a: Int, b: Int): Int
}
class MyXXX extends MyFunc {
override def myfunc(a: Int, b: Int): Int = {
a + b
}
}
|
这里的 接口类非常简单,实际应该是暴露出 函数名,函数签名,返回值等等,这里只是简化了处理
在元数据库中定义一个表,记录 UDF 的一些信息,比如:
| 函数名 |
库名 |
描述信息 |
jar 路径 |
| my_add_123 |
hello |
my add function |
hdfs://kdp:8020/test/my_fun.jar |
增加一个自定义的 类加载器,MyClassLoader,这个类加载其根据 hdfs 路径,将这个 jar 包下载
然后将 byte[] -> Class,再将其转换为 MyFunc 类型
V2方式
继承并自定义loadFunction
根据 Identifier 查找自定义的 function,比如从元数据库中查找,再根据路径从 hdfs 上将对应的 jar 拿到
同样也需要一个元数据信息
| 函数名 |
库名 |
描述信息 |
jar 路径 |
| my_add_123 |
hello |
my add function |
hdfs://kdp:8020/test/my_fun.jar |
这里需要增加一个自定义的classloader
但目前有些问题,codegen 的时候找不到这个类,因为是另一套 classloader
解决方法,给 driver 和 executor 增加一个额外的 classpath
将下载的 jar 放到这个指定的 classpath 路径中
增加自定义的实现类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
class MyUnboundFunction extends UnboundFunction {
override def bind(inputType: StructType): BoundFunction = {
val loader = this.getClass.getClassLoader
println(s"MyUnboundFunction class loader -> $loader")
val threadLoader = Thread.currentThread().getContextClassLoader
println(s"thread context loader -> $threadLoader")
new AddFunction()
}
override def description(): String = {
"my_add_func"
}
override def name(): String = {
"add_func"
}
}
class AddFunction extends ScalarFunction[Int] {
override def inputTypes(): Array[DataType] = {
Array(DataTypes.IntegerType, DataTypes.IntegerType)
}
override def resultType(): DataType = {
DataTypes.IntegerType
}
override def name(): String = {
"add"
}
// 会优先调用这个函数
def invoke(a: Int, b: Int): Int = {
a + b
}
override def produceResult(input: InternalRow): Int = {
val arr: Array[MutableValue] = input.asInstanceOf[SpecificInternalRow].values
arr(0).asInstanceOf[MutableInt].value + arr(1).asInstanceOf[MutableInt].value
}
}
|
add jar 命令引入的 classloader
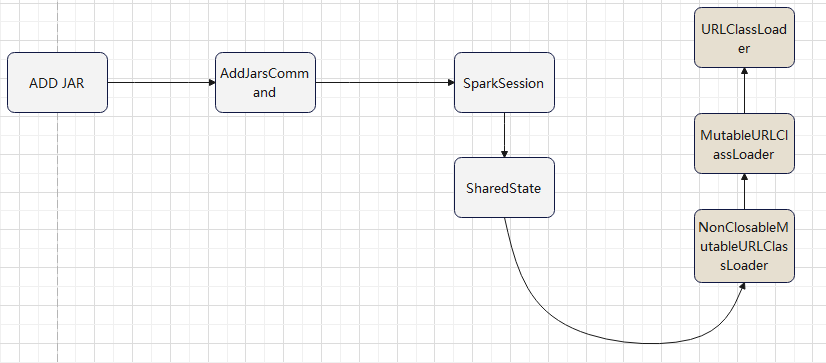
使用自定义的 classloader
- 加载 MyUnboundFunction 时,使用自定义的 classloader
- MyUnboundFunction 加载 AddFunction 时,正常 new 出来就可以了
下面这段,放到 loadFunction 中,执行自定义的加载逻辑
1
2
3
4
5
6
7
8
|
val parent = Thread.currentThread().getContextClassLoader
// 这里 spark 的classloader,这里直接使用
val loader = new NonClosableMutableURLClassLoader(parent)
loader.addURL( new URL("file:/D:\\zzz_my_test\\xx.jar") )
Thread.currentThread().setContextClassLoader(loader)
val funcClassName = "com.test.func.MyUnboundFunction"
val clazz = Class.forName(funcClassName, true, loader)
clazz.newInstance().asInstanceOf[UnboundFunction]
|
加载 MyUnboundFunction 后,打印如下信息,这里已经使用了自定义的 classloader 了
MyUnboundFunction class loader -> org.apache.spark.sql.internal.NonClosableMutableURLClassLoader@514377fc
thread context loader -> org.apache.spark.sql.internal.NonClosableMutableURLClassLoader@514377fc
提供创建 函数的 sql:
1
2
3
4
5
6
7
|
CREATE OR REPLACE FUNCTION IF NOT EXISTS func1
BY 'org.apache.spark.example.A' USING '/tmp/a.jar'
DROP FUNCTION IF EXISTS func1
DESC FUNCTION func1
SHOW FUNCTIONS
|
增加自定义的 parser,逻辑计划等,将这些信息写到数据库中
上述的函数是全局范围的,也可以指定 catalog,将这个函数绑定到某个 catalog 下
这样同名的,但不同功能的函数,就可以区分了
V2方式聚合函数
这里是将 my_add_123作为聚合函数使用
创建两个类,未绑定的函数,以及绑定后的聚合函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
class MyUnboundAgg extends UnboundFunction {
override def bind(inputType: StructType): BoundFunction = {
new MyAggregate()
}
override def description(): String = {
"my_agg_udf"
}
override def name(): String = {
"my_agg"
}
}
class MyAggregate extends AggregateFunction[AtomicInteger, Int] {
override def newAggregationState(): AtomicInteger = {
new AtomicInteger(0)
}
override def update(state: AtomicInteger, input: InternalRow): AtomicInteger = {
val tmp = input.getInt(0) + input.getInt(1)
println(s"update -> $tmp")
val tmp2 = state.get() + tmp
state.set(tmp2)
println(s"update total -> ${state.get()}")
state
}
override def merge(leftState: AtomicInteger, rightState: AtomicInteger): AtomicInteger = {
val res: Int = leftState.get() + rightState.get()
println(s"merge -> $res")
leftState.set(res)
println(s"merge -> ${leftState.get()}")
leftState
}
override def produceResult(state: AtomicInteger): Int = {
println(s"state -> $state")
state.get()
}
override def inputTypes(): Array[DataType] = {
Array(IntegerType, IntegerType)
}
override def resultType(): DataType = {
IntegerType
}
override def name(): String = {
"my_add_123"
}
}
|
执行结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
update -> 101
update total -> 101
update -> 102
update total -> 203
update -> 103
update total -> 306
update -> 104
update total -> 410
merge -> 410
merge -> 410
state -> 410
+---+
| id|
+---+
|410|
+---+
|
执行展示
查询的 sql
1
|
SELECT my_add_123(id, 100) AS id FROM `mysql57-hello`.t1 AS t
|
结果
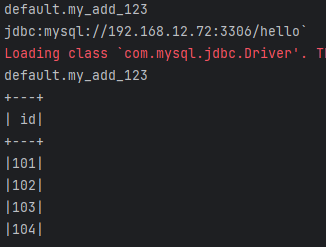
1
2
3
4
5
6
7
8
|
+---+
| id|
+---+
|101|
|102|
|103|
|104|
+---+
|
自定义函数下推
查找函数,绑定函数
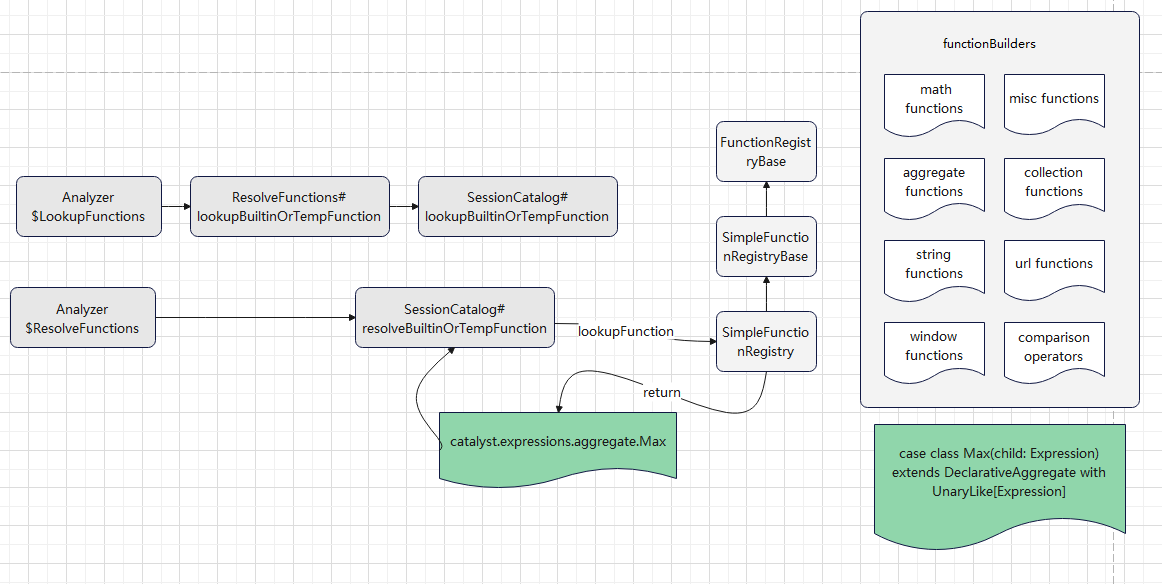
目前走的是 v1 的逻辑
内置很多函数,像max这样的函数就是内置的,所以可以查找到
绑定的时候,返回对应的 表达式
org.apache.spark.sql.catalyst.expressions.aggregate.Max
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
case class Max(child: Expression) extends DeclarativeAggregate with UnaryLike[Expression] {
override def nullable: Boolean = true
// Return data type.
override def dataType: DataType = child.dataType
override def checkInputDataTypes(): TypeCheckResult =
TypeUtils.checkForOrderingExpr(child.dataType, prettyName)
private lazy val max = AttributeReference("max", child.dataType)()
override lazy val aggBufferAttributes: Seq[AttributeReference] = max :: Nil
override lazy val initialValues: Seq[Literal] = Seq(
/* max = */ Literal.create(null, child.dataType)
)
override lazy val updateExpressions: Seq[Expression] = Seq(
/* max = */ greatest(max, child)
)
override lazy val mergeExpressions: Seq[Expression] = {
Seq(
/* max = */ greatest(max.left, max.right)
)
}
override lazy val evaluateExpression: AttributeReference = max
override protected def withNewChildInternal(newChild: Expression): Max = copy(child = newChild)
}
|
之后优化逻辑,会将这个 表达式交给具体的方言处理,看是否可以下推
方言类会将这个表达式,如 max(id + 100),转换成一个字符串,最后将这个字符串,作为 project list 的一部分,下推到具体的数据源
这里简单处理一下,实现 聚合函数方言下推
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
class UniMySQLSQLBuilder extends JDBCSQLBuilder {
override def compileExpression(expr: Expression): Option[String] = {
val mysqlSQLBuilder = new UniMySQLSQLBuilder()
try {
Some(mysqlSQLBuilder.build(expr))
} catch {
case NonFatal(e) =>
logWarning("Error occurs while compiling V2 expression", e)
None
}
}
override def build(expr: Expression): String = {
val s = expr.toString
if (s.contains("my_add_123")) {
"my_add_123(id, 100)"
} else {
super.build(expr)
}
}
}
|
显示已经可以下推了
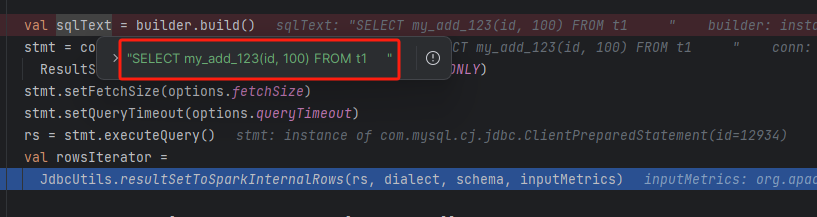
查询结果
1
2
3
4
5
6
7
8
|
+---+
| id|
+---+
|101|
|102|
|103|
|104|
+---+
|
这个函数,在 mysql 端,只是一个普通的函数,只是 spark 端,将他 当做了一个聚合函数下推过去了
但最终是按照普通函数执行的
spark 端只是拼接一个 sql
1
|
SELECT my_add_123(id, 100) FROM t1
|
这里的 my_add_123 是 聚合函数,还是标量函数,spark 不关心
所以按照这种方式,就可以实现
- 标量函数下推,把它当做聚合函数来对待
- 聚合函数下推
UDF 的完整类图

参考