子查询
理论
SPJ,选择、投影、连接,最重要的三个操作
非 SPJ
从子查询出现在SQL语句的位置看,它可以出现在
- 目标列
- FROM子句
- WHERE子句
- JOIN/ON子句
- GROUPBY子句
- HAVING子句
- ORDERBY子句等位置
子查询出现在不同位置对优化的影响如下
- 目标列位置,子查询如果位于目标列,则只能是标量子查询
- FROM子句位置,不能是相关子查询,可以是 非相关子查询,此时可以 上拉子查询变成 join
- WHERE子句位置,是条件表达式的一部分,如Int类型的>、<、=、<> 此时必须是标量子查询,其他谓词包括:IN、BETWEEN、EXISTS
- JOIN/ON,JOIN类似于FROM 子句,ON 类似于WHERE 子句,总体处理方式跟 FROM、WHERE 类似
- GROUPBY子句位置,目标列必须和 group by 相关联,但一般没什么意义
- ORDERBY子句位置,一般没什么意义
子查询分类
- 相关子查询。子查询的执行依赖于外层父查询的一些属性值。子查询因依赖于父查询的参数,当父查询的参数改变时,子查询需要根据新参数值重新执行
- 非相关子查询。子查询的执行不依赖于外层父查询的任何属性值,这样的子查询具有独立性,可独自求解
从特定谓词看
- [NOT]IN/ALL/ANY/SOME子查询,语义相近,表示“[取反]存在/所有/任何/任何”,左面是操作数,右面是子查询,是最常见的子查询类型之一
- [NOT]EXISTS子查询,半连接语义,表示“[取反]存在”,没有左操作数,右面是子查询,也是最常见的子查询类型之一
查询分类
- SPJ子查询。由选择、连接、投影操作组成的查询。
- GROUPBY子查询。SPJ子查询加上分组、聚集操作组成的查询。
- 其他子查询。GROUPBY子查询中加上其他子句如Top-N、LIMIT/OFFSET、集合、排序等操作
- 后两种子查询有时合称非SPJ子查询
从结果集的角度看,子查询分为以下4类:
- 标量子查询。子查询返回的结果集类型是一个单一值(return a scalar,a single value)。
- 列子查询。子查询返回的结果集类型是一条单一元组(return a single row)。
- 行子查询。子查询返回的结果集类型是一个单一列(return a single column)。
- 表子查询。子查询返回的结果集类型是一个表(多行多列)(return a table,one or more rows of one or more columns)
优化技术
子查询合并(Subquery Coalescing)
1
2
3
4
|
SELECT * FROM t1 WHERE a1<10 AND (
EXISTS (SELECT a2 FROM t2 WHERE t2.a2<5 AND t2.b2=1) OR
EXISTS (SELECT a2 FROM t2 WHERE t2.a2<5 AND t2.b2=2)
);
|
可优化为:
1
2
|
SELECT * FROM t1 WHERE a1<10 AND (
EXISTS (SELECT a2 FROM t2 WHERE t2.a2<5 AND (t2.b2=1 OR t2.b2=2)
|
子查询展开(Subquery Unnesting)
又称子查询反嵌套,又称为子查询上拉。把一些子查询置于外层的父查询中,作为连接关系与外层父查询并列
- 如果子查询包含了:聚集、GROUPBY、DISTINCT子句,则子查询只能单独求解,不可以上拉到上层
- 如果子查询只是一个简单格式(SPJ格式)的查询语句,则可以上拉到上层
1
2
|
SELECT * FROM t1, (SELECT * FROM t2 WHERE t2.a2 >10) v_t2
WHERE t1.a1<10 AND v_t2.a2<20;
|
可优化为:
1
|
SELECT * FROM t1, t2 WHERE t1.a1<10 AND t2.a2<20 AND t2.a2 >10;
|
查询展开的具体步骤如下:
- 将子查询和上层查询的FROM子句连接为同一个FROM子句,并且修改相应的运行参数。
- 将子查询的谓词符号进行相应修改(如:IN修改为=ANY)。
- 将子查询的WHERE条件作为一个整体与上层查询的WHERE条件合并,并用AND条件连接词连接,从而保证新生成的谓词与原谓词的上下文意思相同,且成为一个整体
IN 子查询优化,将外层的条件 下推到内层,然后将 IN 改为 EXIST
EXIST 可以被: 半连接算法实现优化
Spark中的查询分类
Spark 中根据查询结果的 子查询分类
- OneRowSubquery,在 OptimizeOneRowRelationSubquery 中
- LateralSubquery,多行多列
- ScalarSubquery,一行一列
OptimzeSubqueries
OptimzeSubqueries 这个优化规则,目前只包含了一个场景,将子查询上面的 sort 去掉了
这个规则值做这么一个简单的事情,由其他规则负责将 sub-queries 转为 join
1
2
3
4
5
6
7
8
9
|
private def removeTopLevelSort(plan: LogicalPlan): LogicalPlan = {
if (!plan.containsPattern(SORT)) {
return plan
}
plan match {
case Sort(_, _, child) => child
case Project(fields, child) => Project(fields, removeTopLevelSort(child))
case other => other
}
|
SQL语句如下:
1
2
3
4
5
6
7
8
|
SELECT id,
customer_id,
( SELECT MAX(item_price)
FROM item
WHERE item.order_id = order.id
ORDER BY MAX(item_price)
) AS max_item_price
FROM order
|
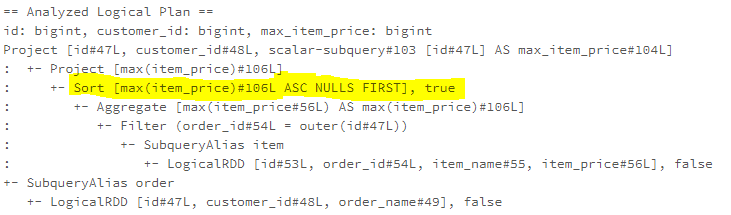
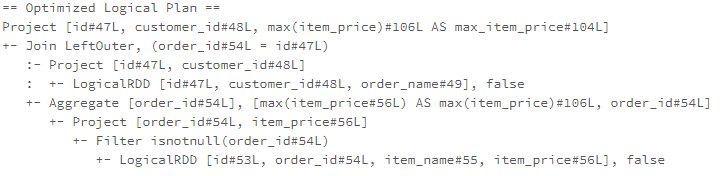
PullupCorrelatedPredicates 优化规则实现如下
SQL如下:
1
2
3
4
5
6
7
|
SELECT id, customer_id, order_name
FROM order
WHERE (
SELECT MAX(item_price) AS max_item_price
FROM item
WHERE item.order_id = order.id
) < 100
|
这里还使用了 RewriteCorrelatedScalarSubquery ,将子查询改写为 join
优化后,Filter(order_id = outer(id)),这个被优化成 join 条件了,也就是把相关 子查询中的 谓词给 上提了
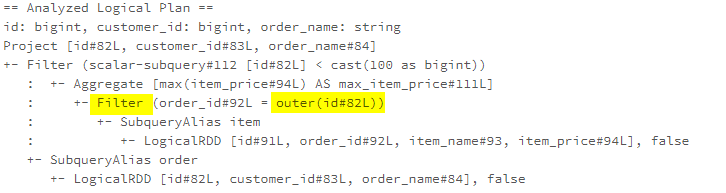
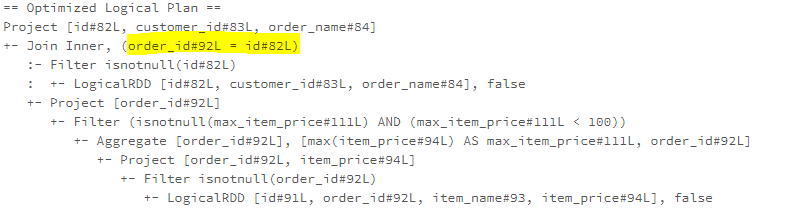
注意,这个规则,以及类似的其他规则,只是做了一部分优化,后面会有其他规则继续做优化,最终看到的结果,是多个优化规则叠加完成的
这个规则执行前,t1 是内表
1
2
3
4
|
SELECT t2.id FROM t2 WHERE t2.id IN
(
SELECT t1.id FROM t1 WHERE t1.id = t2.id
)
|
生成的逻辑规则是这样:
1
2
3
4
5
6
7
8
9
|
id: int
Project [id#1]
+- Filter id#1 IN (list#0 [id#1])
: +- Project [id#3]
: +- Filter (id#3 = outer(id#1))
: +- SubqueryAlias t1
: +- RelationV2[id#3, sname#4] t1
+- SubqueryAlias t2
+- RelationV2[id#1, sname#2] t2
|
下面的这个是优化的中间结果:
1
2
3
4
5
|
Project [id#1]
+- Filter id#1 IN (list#0 [id#1 && (id#3 = id#1)])
: +- Project [id#3]
: +- RelationV2[id#3, sname#4] t1
+- RelationV2[id#1, sname#2] t2
|
也就是只是将 子查询的条件 上提了,转成 JOIN 是后面的规则做的
RewritePredicateSubquery
RewritePredicateSubquery 这个规则将谓词子查询重写为left semi/anti join。支持以下谓词:
- EXISTS/NOT EXISTS将被重写为semi/anti join,Filter中未解析的条件将被提取为join条件
- IN/NOT IN将被重写为semi/anti join,Filter中未解析的条件将作为join条件被拉出,value=selected列也将用作join条件
两个表,结构一样,包含 id(int), sname(varchar)
1
2
3
4
|
SELECT id, sname FROM t1 WHERE id IN
(
SELECT id FROM p1 WHERE id < 10
) AND id > 999
|
逻辑计划:
1
2
3
4
5
6
7
8
9
10
11
12
|
== Analyzed Logical Plan ==
id: bigint, sname: string
Project [id#118L, sname#119]
+- Filter (id#118L IN (list#142 []) AND (id#118L > cast(999 as bigint)))
: +- Project [id#15L]
: +- Filter (id#15L < cast(10 as bigint))
: +- SubqueryAlias p1
: +- View (`p1`, [age#14L,id#15L,sname#16])
: +- Relation [age#14L,id#15L,sname#16] json
+- SubqueryAlias t1
+- View (`t1`, [age#117L,id#118L,sname#119])
+- Relation [age#117L,id#118L,sname#119] json
|
期间会有一个中间步骤的优化,大致相当于
1
2
3
4
5
6
|
Project [id#118L, sname#119]
+- Filter (id#118L IN (list#142 []) AND (id#118L > cast(999 as bigint)))
: +- Project [id#15L]
: +- Filter (id#15L < cast(10 as bigint))
: +- Relation [age#14L,id#15L,sname#16] json
+- Relation [age#117L,id#118L,sname#119] json
|
执行规则,这里用 IN 来 举例
- 跟 IN 拆分 条件,IN 里面的是子查询,跟 IN 同级的是 普通查询的条件
- 将普通查询条件 用 AND 做连接,变成新条件
- 子查询做投影过滤,去掉不需要的列
- 根据外层 plan,新的 plan,获取 join 的ON 条件
- 新条件跟 原外层 plan合并,变成新 outerPlan
- 用 outerPlan,innerPlan(子查询变换的),ON 条件,LeftSemi,组合成 JOIN 逻辑计划
- 如果是 NOT,则 JOIN 类型为 LeftAnti,也就是:左边中没有跟右表匹配的所有行
优化后的:
1
2
3
4
5
6
7
8
|
== Optimized Logical Plan ==
Join LeftSemi, (id#118L = id#15L)
:- Project [id#118L, sname#119]
: +- Filter (isnotnull(id#118L) AND (id#118L > 999))
: +- Relation [age#117L,id#118L,sname#119] json
+- Project [id#15L]
+- Filter (isnotnull(id#15L) AND (id#15L < 10))
+- Relation [age#14L,id#15L,sname#16] json
|
其他一些情况
带常数,无关子查询的 SQL
1
2
3
4
|
SELECT t1.* FROM t1 WHERE 10 IN
(
SELECT t2.id FROM t2
)
|
优化后的,这里使用的是 Spark3.5
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
== Analyzed Logical Plan ==
id: int, sname: string
Project [id#1, sname#2]
+- Filter 10 IN (list#0 [])
: +- Project [id#3]
: +- SubqueryAlias t2
: +- RelationV2[id#3, sname#4] t2
+- SubqueryAlias t1
+- RelationV2[id#1, sname#2] t1
== Optimized Logical Plan ==
Join LeftSemi
:- RelationV2[id#1, sname#2] t1
+- LocalLimit 1
+- Project
+- Filter (10 = id#3)
+- RelationV2[id#3] t2
|
带随机值的SQL:
1
2
3
4
5
|
SELECT t1.id FROM t1 WHERE t1.id + RAND() * 10
IN
(
SELECT t2.id FROM t2
)
|
优化后的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
== Analyzed Logical Plan ==
id: int
Project [id#1]
+- Filter (cast(id#1 as double) + (rand(2079373737972317466) * cast(10 as double))) IN (list#0 [])
: +- Project [cast(id#3 as double) AS id#5]
: +- Project [id#3]
: +- SubqueryAlias t2
: +- RelationV2[id#3, sname#4] t2
+- SubqueryAlias t1
+- RelationV2[id#1, sname#2] t1 t1
== Optimized Logical Plan ==
Join LeftSemi, (knownfloatingpointnormalized(normalizenanandzero((cast(id#1 as double) + (rand(2079373737972317466) * 10.0))))
= knownfloatingpointnormalized(normalizenanandzero(id#5)))
:- RelationV2[id#1] t1
+- Project [cast(id#3 as double) AS id#5]
+- RelationV2[id#3] t2
|
算子合并
CollapseRepartition
合并相邻的RepartitionOperation和RebalancePartitions运算符
1
2
3
4
|
var df = spark.range(1, 100, 1)
df = df.repartition(5)
df = df.coalesce(10)
df.explain("extended")
|
逻辑计划:
1
2
3
4
5
|
== Analyzed Logical Plan ==
id: bigint
Repartition 10, false
+- Repartition 5, true
+- Range (1, 100, step=1, splits=Some(8))
|
优化后
1
2
3
|
== Optimized Logical Plan ==
Repartition 5, true
+- Range (1, 100, step=1, splits=Some(8))
|
如果 repartition 比 coalesce 更大,则不合并
1
2
3
|
var df = spark.range(1, 100, 1)
df = df.repartition(10).coalesce(5)
df.explain("extended")
|
逻辑和优化计划
1
2
3
4
5
6
7
8
9
10
|
== Analyzed Logical Plan ==
id: bigint
Repartition 5, false
+- Repartition 10, true
+- Range (1, 100, step=1, splits=Some(8))
== Optimized Logical Plan ==
Repartition 5, false
+- Repartition 10, true
+- Range (1, 100, step=1, splits=Some(8))
|
CollapseProject
两个Project运算符合并为一个别名替换,在以下情况下,将表达式合并为一个表达式
- 两个Project运算符相邻时。
- 当两个Project运算符之间有LocalLimit/Sample/Repartition运算符,且上层的Project由相同数量的列组成,且列数相等或具有别名时。同时也考虑到GlobalLimit(LocalLimit)模式
1
2
3
4
|
SELECT col_1 FROM
(
SELECT 1 as col_1, 2 as col_2
)
|
逻辑计划
1
2
3
4
5
6
|
== Analyzed Logical Plan ==
col_1: int
Project [col_1#0]
+- SubqueryAlias __auto_generated_subquery_name
+- Project [1 AS col_1#0, 2 AS col_2#1]
+- OneRowRelation
|
优化后的
1
2
3
|
== Optimized Logical Plan ==
Project [1 AS col_1#0]
+- OneRowRelation
|
CombineFilters
将两个相邻的Filter运算符合并为一个,将非冗余条件合并为一个连接谓词
1
2
3
4
5
|
var df = spark.sql(
s"""
|SELECT id, sname FROM $mysqlName.$mysqlDB.t1
|""".stripMargin)
df = df.filter("id > 10").filter("id < 999")
|
逻辑计划
1
2
3
4
5
6
7
|
== Analyzed Logical Plan ==
id: int, sname: string
Filter (id#0 < 999)
+- Filter (id#0 > 10)
+- Project [id#0, sname#1]
+- SubqueryAlias my_catalog.mysql57.hello.t1
+- RelationV2[id#0, sname#1] my_catalog.mysql57.hello.t1 t1
|
中间结果
1
2
|
Filter ((id#0 > 10) AND (id#0 < 999))
+- RelationV2[id#0, sname#1] my_catalog.mysql57.hello.t1 t1
|
CombineUnions
将所有相邻的Union运算符合并为一个
逻辑计划
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
== Analyzed Logical Plan ==
id: int, sname: string
Distinct
+- Union false, false
:- Distinct
: +- Union false, false
: :- Project [id#0, sname#1]
: : +- Filter (id#0 < 10)
: : +- SubqueryAlias t1
: : +- RelationV2[id#0, sname#1] t1
: +- Project [id#2, sname#3]
: +- Filter (id#2 > 100)
: +- SubqueryAlias t1
: +- RelationV2[id#2, sname#3] t1
+- Project [id#4, sname#5]
+- Filter (id#4 < 999)
+- SubqueryAlias t2
+- RelationV2[id#4, sname#5] t2
|
优化的中间结果
1
2
3
4
5
6
7
8
|
Aggregate [id#0, sname#1], [id#0, sname#1]
+- Union false, false
:- Filter (id#0 < 10)
: +- RelationV2[id#0, sname#1] t1
:- Filter (id#2 > 100)
: +- RelationV2[id#2, sname#3] t1
+- Filter (id#4 < 999)
+- RelationV2[id#4, sname#5] t2
|
其他
OptimizeWindowFunctions
- 将first(col)替换成nth_value(col, 1)来获得更好的性能
CollapseWindow
- 折叠相邻的Window表达式
- 如果分区规格和顺序规格相同,并且窗口表达式是独立的,且属于相同的窗口函数类型,则折叠到父节点中
常量折叠和强度消减
在编译器构建中,强度消减(strength reduction)是一种编译器优化
- 其中昂贵的操作被等效但成本较低的操作所取代
- 强度降低的经典例子将循环中的“强”乘法转换为“弱”加法——这是数组寻址中经常出现的情况
- 强度消减的例子包括:用加法替换循环中的乘法、用乘法替换循环中的指数
NullPropagation
Replaces Expressions that can be statically evaluated with equivalent Literal values.
This rule is more specific with Null value propagation from bottom to top of the expression tree.
1
|
SELECT count(id=NULL) FROM t1
|
逻辑计划
1
2
3
4
5
|
== Analyzed Logical Plan ==
count((id = NULL)): bigint
Aggregate [count((id#0 = cast(null as int))) AS count((id = NULL))#3L]
+- SubqueryAlias t1
+- RelationV2[id#0, sname#1] t1
|
中间结果
1
2
3
|
Aggregate [cast(0 as bigint) AS count((id = NULL))#3L]
+- Project [id#0]
+- RelationV2[id#0, sname#1] t1
|
ConstantPropagation
用连接表达式中的相应值替换可以静态计算的属性
- 例如:SELECT * FROM table WHERE i = 5 AND j = i + 3
- 可以替换为: ==> SELECT * FROM table WHERE i = 5 AND j = 8
- 使用的方法:通过查看所有相等的谓词来填充属性 => 常量值的映射;
- 使用这个映射,将属性的出现的地方替换为AND节点中相应的常量值
1
2
|
SELECT *
FROM t3 WHERE id = 10 AND sid = 100 + id
|
逻辑计划:
1
2
3
4
5
6
|
== Analyzed Logical Plan ==
id: int, sid: int, sname: string
Project [id#0, sid#1, sname#2]
+- Filter ((id#0 = 10) AND (sid#1 = (100 + id#0)))
+- SubqueryAlias t3
+- RelationV2[id#0, sid#1, sname#2] t3
|
中间结果
1
2
|
Filter ((id#0 = 10) AND (sid#1 = (100 + 10)))
+- RelationV2[id#0, sid#1, sname#2] t3
|
OptimizeIn
优化IN谓词
- 当列表为空且值不可为null时,将谓词转换为false
- 删除文本值重复
- 将In (value, seq[Literal])替换为更快的优化版本InSet (value, HashSet[Literal])
1
2
|
SELECT * FROM t1
WHERE id IN (1, 2, 1, 1)
|
逻辑计划:
1
2
3
4
5
6
|
== Analyzed Logical Plan ==
id: int, sname: string
Project [id#0, sname#1]
+- Filter id#0 IN (1,2,1,1)
+- SubqueryAlias t1
+- RelationV2[id#0, sname#1] t1
|
优化的中间结果
1
2
|
Filter id#0 IN (1,2)
+- RelationV2[id#0, sname#1] t1
|
如果 IN 中的条件太多,超过阈值,spark.sql.optimizer.inSetConversionThreshold则 改用 insert
1
2
|
SELECT * FROM t1
WHERE id IN (1, 2, 3,4,5,6,7,8,9,10,11,12,13,14,15)
|
逻辑计划:
1
2
3
4
5
6
|
== Analyzed Logical Plan ==
id: int, sname: string
Project [id#0, sname#1]
+- Filter id#0 IN (1,2,3,4,5,6,7,8,9,10,11,12,13,14,15)
+- SubqueryAlias t1
+- RelationV2[id#0, sname#1] t1
|
中间结果:
1
2
|
Filter id#0 INSET 1, 10, 11, 12, 13, 14, 15, 2, 3, 4, 5, 6, 7, 8, 9
+- RelationV2[id#0, sname#1] t1
|
ConstantFolding
替换可以用等效文本值静态计算的表达式
The following conditions are used to determine suitability for constant folding:
- A Coalesce is foldable if all of its children are foldable
- A BinaryExpression is foldable if its both left and right child are foldable
- A Not, IsNull, or IsNotNull is foldable if its child is foldable
- A Literal is foldable
- A Cast or UnaryMinus is foldable if its child is foldable
1
|
SELECT replace('123456', '123', 'abc') AS r
|
逻辑计划:
1
2
3
4
|
== Analyzed Logical Plan ==
r: string
Project [replace(123456, 123, abc) AS r#0]
+- OneRowRelation
|
中间结果:
1
2
|
Project [abc456 AS r#0]
+- OneRowRelation
|
这里面用到了 StringReplace,有很多相关的类
调用了 父类 TernaryExpression#eval(),做求值计算的
另一种情况
1
|
SELECT 1 + (id + 2) + 3 FROM $mysqlName.$mysqlDB.t1
|
逻辑计划:
1
2
3
4
5
|
== Analyzed Logical Plan ==
((1 + (id + 2)) + 3): int
Project [((1 + (id#0 + 2)) + 3) AS ((1 + (id + 2)) + 3)#2]
+- SubqueryAlias t1
+- RelationV2[id#0, sname#1] t1
|
优化后的:
1
2
3
|
== Optimized Logical Plan ==
Project [(id#0 + 6) AS ((1 + (id + 2)) + 3)#2]
+- RelationV2[id#0] t1
|
ReplaceNullWithFalseInPredicate
一个用False Literal替换Literal(null, BooleanType) 的规则,如果可能的话,在WHERE/HAVING/ON(JOIN)子句的搜索条件中
该子句包含一个隐式布尔运算符(search condition) = TRUE。当计算整个搜索条件时,只有当Literal(null, BooleanType)在语义上等同于FalseLiteral时,替换才有效
请注意,在大多数情况下,当搜索条件包含NOT和可空的表达式时,FALSE和NULL是不可交换的
因此,该规则非常保守,适用于非常有限的情况
例如
- Filter(Literal(null, BooleanType))等同于Filter(FalseLiteral)
- 另一个包含分支的示例是Filter(If(cond, FalseLiteral, Literal(null, _)));
- 这可以优化为Filter(If(cond, FalseLiteral, FalseLiteral)),
- 最终Filter(FalseLiteral) -
- 此外,该规则还转换所有If表达式中的谓词,以及所有CaseWhen表达式中的分支条件,即使它们不是搜索条件的一部分
- 例如,Project(If(And(cond, Literal(null)), Literal(1), Literal(2)))可以简化为Project(Literal(2))
1
|
SELECT IF ((( 2 > 1) AND NULL), 'good', 'bad') AS col
|
逻辑计划和优化后的
1
2
3
4
5
6
7
8
|
== Analyzed Logical Plan ==
col: string
Project [if (((2 > 1) AND cast(null as boolean))) good else bad AS col#0]
+- OneRowRelation
== Optimized Logical Plan ==
Project [bad AS col#0]
+- OneRowRelation
|
CombineConcats
合并嵌套的Concat表达式
1
|
SELECT concat("abc", concat("def", "ghi")) AS col
|
逻辑计划和优化后的
1
2
3
4
5
6
7
8
|
== Analyzed Logical Plan ==
col: string
Project [concat(abc, concat(def, ghi)) AS col#0]
+- OneRowRelation
== Optimized Logical Plan ==
Project [abcdefghi AS col#0]
+- OneRowRelation
|
其他
还有很多,如
- TransposeWindow
- 转置相邻的窗口表达式。如果父窗口表达式的分区规范与子窗口表达式的分区规范兼容,就转置它们
- NullDownPropagation
- 如果输入不允许为空,则展开IsNull/IsNotNull的输入
- 例如:IsNull(Not(null)) == IsNull(null)
- FoldablePropagation
- 用原始可折叠表达式的别名替换属性。其他优化将利用传播的可折叠表达
- 如,此规则可以将SELECT 1.0 x, ‘abc’ y, Now() z ORDER BY x, y, 3
- 优化成SELECT 1.0 x, ‘abc’ y, Now() z ORDER BY 1.0, ‘abc’, Now()
- 其他规则可以进一步优化它,并且删除ORDER BY运算符
- PushFoldableIntoBranches
- RemoveDispensableExpressions
算子简化
LikeSimplification
简化了不需要完整正则表达式来计算条件的LIKE表达式
例如,当表达式只是检查字符串是否以给定模式开头时
1
2
|
SELECT *
FROM t1 WHERE sname LIKE '%abc'
|
逻辑计划:
1
2
3
4
5
6
|
== Analyzed Logical Plan ==
id: int, sname: string
Project [id#0, sname#1]
+- Filter sname#1 LIKE %abc
+- SubqueryAlias t1
+- RelationV2[id#0, sname#1] t1
|
优化的中间结果:
1
2
|
Filter EndsWith(sname#1, abc)
+- RelationV2[id#0, sname#1] t1
|
BooleanSimplification
简化了布尔表达式:
- 简化了答案可以在不计算双方的情况下确定的表达式
- 消除/提取共同的因子
- 合并相同的表达式
- 删除Not运算符
1
2
3
|
SELECT *
FROM t1
WHERE (id > 10 AND id < 100) OR id > 10
|


SimplifyBinaryComparison
使用语义相等的表达式简化二进制比较
- 用true文本值替代<==>;
- 如果操作数都是非空的,用true文本值替代 =, <=, 和 >=;
- 如果操作数都是非空的,用false文本值替代>和<;
- 如果有一边操作数是布尔文本值,就展开=、<=>
1
|
SELECT (1 + 2) <=> (4 - 1)
|
逻辑计划和优化后的
1
2
3
4
5
6
7
8
|
== Analyzed Logical Plan ==
((1 + 2) <=> (4 - 1)): boolean
Project [((1 + 2) <=> (4 - 1)) AS ((1 + 2) <=> (4 - 1))#0]
+- OneRowRelation
== Optimized Logical Plan ==
Project [true AS ((1 + 2) <=> (4 - 1))#0]
+- OneRowRelation
|
PruneFilters
删除可以进行简单计算的Filter。这可以通过以下方式实现:
- 在其计算结果始终为true的情况下,省略Filter
- 当筛选器的计算结果总是为false时,替换成一个伪空关系
- 消除子节点输出给定约束始终为true的条件
1
|
SELECT * FROM t1 WHERE 1 > 0
|
逻辑计划和优化后的
1
2
3
4
5
6
7
8
9
|
== Analyzed Logical Plan ==
id: int, sname: string
Project [id#0, sname#1]
+- Filter (1 > 0)
+- SubqueryAlias t1
+- RelationV2[id#0, sname#1] t1
== Optimized Logical Plan ==
RelationV2[id#0, sname#1] t1
|
EliminateSerialization
消除不必要地在对象和数据项的序列化(InternalRow)表示之间切换的情况。例如,背对背映射操作
1
|
spark.range(10).ap(_ * 1).map(_ + 2).explain("extended")
|

简化冗余的 CreateNamedStruct/CreateArray/CreateMap表达式
1
|
SELECT array('a', 'b', 'c')[0] as col_1
|
逻辑计划和优化后的
1
2
3
4
5
6
7
8
|
== Analyzed Logical Plan ==
col_1: string
Project [array(a, b, c)[0] AS col_1#0]
+- OneRowRelation
== Optimized Logical Plan ==
Project [a AS col_1#0]
+- OneRowRelation
|
map 的简化
1
|
SELECT map('a_key', 'a_value', 'b_key', 'b_value').a_key as col_1
|
逻辑计划和优化后的
1
2
3
4
5
6
7
8
|
== Analyzed Logical Plan ==
col_1: string
Project [map(a_key, a_value, b_key, b_value)[a_key] AS col_1#0]
+- OneRowRelation
== Optimized Logical Plan ==
Project [a_value AS col_1#0]
+- OneRowRelation
|
其他
SimplifyCasts
SimplifyCaseConversionExpressions
- 删除不必要的内部大小写转换表达式,因为内部转换被外部转换覆盖
RemoveRedundantAliases
- 从查询计划中删除冗余别名
- 冗余别名是不会更改列的名称或元数据,也不会消除重复数据的别名
Rewrite/Replace/Eliminate规则
EliminateOuterJoin
包含的主要逻辑
图片来源,这里
1
2
3
4
5
6
7
8
|
join.joinType match {
case RightOuter if leftHasNonNullPredicate => Inner
case LeftOuter if rightHasNonNullPredicate => Inner
case FullOuter if leftHasNonNullPredicate && rightHasNonNullPredicate => Inner
case FullOuter if leftHasNonNullPredicate => LeftOuter
case FullOuter if rightHasNonNullPredicate => RightOuter
case o => o
}
|
转换的几个要求
- right outer类型,对join的左表有过滤操作,转换 innert join
- left outer类型,对右表有过滤操作,转换为 inner join
- full outer,对左右表都有过滤,转为 inner join
- full outer,join的左表有过滤,转为 left outer
- full outer,join的右表有过滤,转为 right outer
以 left outer 为例
1
2
3
4
|
SELECT a.sname, b.sname FROM $mysqlName.$mysqlDB.t1 AS a
LEFT JOIN $mysqlName.$mysqlDB.t2 AS b
ON a.id = b.id
WHERE b.id > 99
|
逻辑计划:
1
2
3
4
5
6
7
8
9
10
11
|
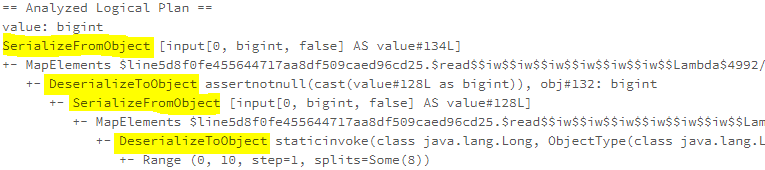
== Analyzed Logical Plan ==
sname: string, sname: string
Project [sname#1, sname#3]
+- Filter (id#2 > 99)
+- Join LeftOuter, (id#0 = id#2)
:- SubqueryAlias a
: +- SubqueryAlias t1
: +- RelationV2[id#0, sname#1] t1
+- SubqueryAlias b
+- SubqueryAlias t2
+- RelationV2[id#2, sname#3] t2
|
优化的中间结果:
1
2
3
4
|
Filter (id#2 > 99)
+- Join Inner, (id#0 = id#2)
:- RelationV2[id#0, sname#1] t1
+- RelationV2[id#2, sname#3] t2
|
FULL JOIN的优化
1
2
3
4
|
SELECT a.sname, b.sname FROM t1 AS a
FULL JOIN t2 AS b
ON a.id = b.id
WHERE b.id > 99
|
逻辑计划:
1
2
3
4
5
6
7
8
9
10
11
|
== Analyzed Logical Plan ==
sname: string, sname: string
Project [sname#1, sname#3]
+- Filter (id#2 > 99)
+- Join FullOuter, (id#0 = id#2)
:- SubqueryAlias a
: +- SubqueryAlias t1
: +- RelationV2[id#0, sname#1] t1
+- SubqueryAlias b
+- SubqueryAlias t2
+- RelationV2[id#2, sname#3] t2
|
优化的中间结果:
1
2
3
4
|
Filter (id#2 > 99)
+- Join RightOuter, (id#0 = id#2)
:- RelationV2[id#0, sname#1] t1
+- RelationV2[id#2, sname#3] t2
|
EliminateDistinct
消除聚合函数中不需要的 distinct
1
|
SELECT max(distinct id) as max_id FROM t1
|
逻辑计划 和 优化结果:
1
2
3
4
5
6
7
8
9
|
== Analyzed Logical Plan ==
max_id: int
Aggregate [max(distinct id#1) AS max_id#0]
+- SubqueryAlias .t1
+- RelationV2[id#1, sname#2] t1
== Optimized Logical Plan ==
Project [MAX(`id`)#6 AS max(id#1)#3 AS max_id#0]
+- RelationV2[MAX(`id`)#6] t1
|
EliminateLimits
该规则由normal和AQE优化器应用,并通过以下方式优化Limit运算符:
- 如果是child max row<=Limit,则消除Limit/GlobalLimit运算符
- 将两个相邻的Limit运算符合并为一个,将多个表达式合并成一个
1
2
3
4
5
|
var df = spark.sql(
s"""
|SELECT id, sname FROM $mysqlName.$mysqlDB.t1
|""".stripMargin)
df = df.limit(5).limit(10)
|
逻辑计划
1
2
3
4
5
6
7
8
9
|
== Analyzed Logical Plan ==
id: int, sname: string
GlobalLimit 10
+- LocalLimit 10
+- GlobalLimit 5
+- LocalLimit 5
+- Project [id#0, sname#1]
+- SubqueryAlias t1
+- RelationV2[id#0, sname#1] t1
|
中间结果
1
2
3
|
GlobalLimit 5
+- LocalLimit 5
+- RelationV2[id#0, sname#1] t1
|
其他
ReplaceIntersectWithSemiJoin
- 使用 left-semi Join 运算符替代逻辑Intersect运算符
ReplaceExceptWithFilter
- 如果逻辑Except运算符中的一或两个数据集都纯粹地使用Filter转换过
- 这个规则会使用反转Except运算符右侧条件之后的Filter运算符替代
ReplaceExceptWithAntiJoin
- 使用 left-anti Join运算符替代逻辑Except运算符
ReplaceDistinctWithAggregate
- 使用Aggregate运算符替代逻辑Distinct运算符
RewriteExceptAll
- 混合使用Union、Aggregate、Generate 运算符来替代逻辑的Except运算符
RewriteIntersectAll
- 混合使用Union、Aggregate、Generate 运算符来替代逻辑的Intersect运算符
EliminateLimits
- 该规则由normal和AQE优化器应用,并通过以下方式优化Limit运算符:
- 1.如果是child max row<=Limit,则消除Limit/GlobalLimit运算符
- 2.将两个相邻的Limit运算符合并为一个,将多个表达式合并成一个
EliminateAggregateFilter
- 删除聚合表达式的无用FILTER子句
- 在RewriteDistinctAggregates之前,应该先应用这个规则
EliminateSerialization
- 消除不必要地在对象和数据项的序列化(InternalRow)表示之间切换的情况
- 例如,背对背映射操作
ReplaceIntersectWithSemiJoin
- 使用 left-semi Join 运算符替代逻辑Intersect运算符
ReplaceExceptWithFilter
- 如果逻辑Except运算符中的一或两个数据集都纯粹地使用Filter转换过
- 这个规则会使用反转Except运算符右侧条件之后的Filter运算符替代。
ReplaceExceptWithAntiJoin
- 用 left-anti Join运算符替代逻辑Except运算符
ReplaceDistinctWithAggregate
- 使用Aggregate运算符替代逻辑Distinct运算符
RewriteExceptAll
- 混合使用Union、Aggregate、Generate 运算符来替代逻辑的Except运算符
RewriteIntersectAll
- 混合使用Union、Aggregate、Generate 运算符来替代逻辑的Intersect运算符
下推规则
PushDownPredicates
这个规则由三个规则组成
1
2
3
4
5
6
7
8
|
object PushDownPredicates extends Rule[LogicalPlan] {
def apply(plan: LogicalPlan): LogicalPlan = plan.transformWithPruning(
_.containsAnyPattern(FILTER, JOIN)) {
CombineFilters.applyLocally
.orElse(PushPredicateThroughNonJoin.applyLocally)
.orElse(PushPredicateThroughJoin.applyLocally)
}
}
|
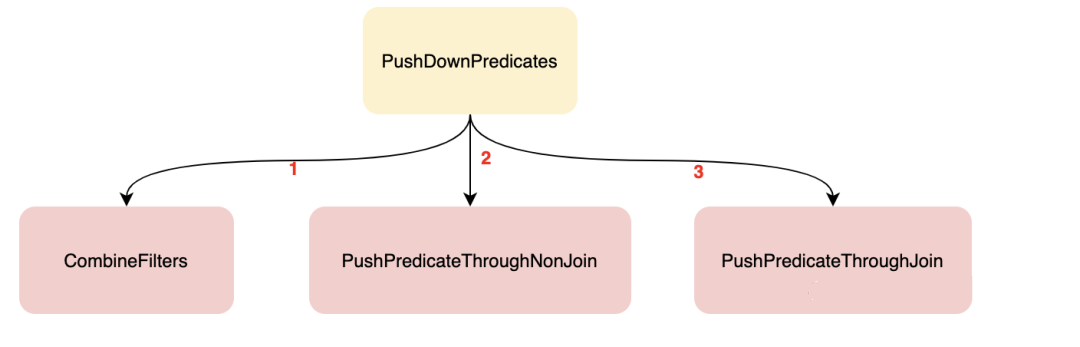
图片来自这里
PushPredicateThroughNonJoin
这个规则又包含了 6 个处理逻辑:
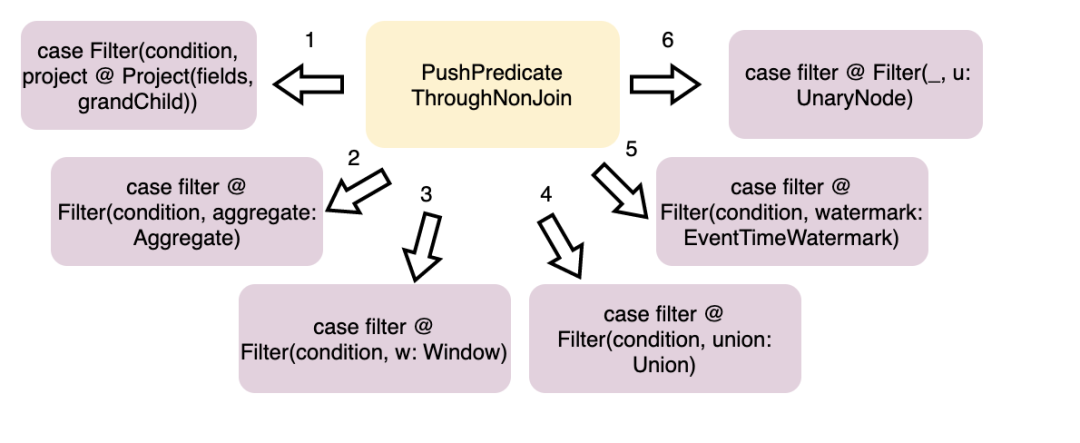
Case 1 – Push predicate through Project
1
2
3
4
|
SELECT id FROM
(
SELECT id FROM t1 WHERE
) WHERE id < 100
|
首先要判断 project 中的字符安是否是确定性的,只有确定性的才能将条件下推
转换后的中间结果
1
2
3
|
Project [id#0]
+- Filter (id#0 < 100)
+- RelationV2[id#0, sname#1] t1
|
这种情况就不能下推,外层
1
2
3
4
5
|
SELECT id, r FROM
(
SELECT id, rand() * 10 AS r FROM t1
WHERE r > 10
) WHERE r < 100
|
下推后相当于: (r > 10 AND r < 100),但因为 字段 r 是随机产生的,是不确定的
这样过滤后结果就不对了,所以不能下推
Case 2 – Push predicate through Aggregate
SQL如下:
1
2
3
4
5
|
SELECT id, sname FROM
(
SELECT id, sname, count(1) AS c FROM t1
WHERE id > 10 GROUP BY id, sname
) WHERE c = 1 AND id < 999
|
执行逻辑:
- 首先也是检查 project 中的字符安是否是确定性的,只有确定性的才能下推
- 字段必须要有 GROUP BY,也就是外层的 Filter 字段在 GROUP BY 中才可以下推
- 获取 Aggregate 中别名和真实字段的对应关系
- 将 Filter字段拆分为 确定的(候选字段)、不确定的
- 根据候选字段,跟聚会的字段作比较,只有在 聚合列表中的,比如 id < 999 中的id可以,c 则不行
- 将能不能下推的字段重新组合
- 能下推的字段,移到 Aggregate 下面作为 Filter,这样就完成了下推
逻辑计划:
1
2
3
4
5
6
7
8
9
|
== Analyzed Logical Plan ==
id: int, sname: string
Project [id#1, sname#2]
+- Filter ((c#0L = cast(1 as bigint)) AND (id#1 < 999))
+- SubqueryAlias __auto_generated_subquery_name
+- Aggregate [id#1, sname#2], [id#1, sname#2, count(1) AS c#0L]
+- Filter (id#1 > 10)
+- SubqueryAlias t1
+- RelationV2[id#1, sname#2] t1
|
优化的中间结果:
1
2
3
4
5
|
Filter (c#0L = cast(1 as bigint))
+- Aggregate [id#1, sname#2], [id#1, sname#2, count(1) AS c#0L]
+- Filter (id#1 < 999)
+- Filter (id#1 > 10)
+- RelationV2[id#1, sname#2] t1
|
Case 3 – Push predicate through Window
SQL:
1
2
3
4
5
6
|
SELECT id, sname FROM
(
SELECT id, sname,
row_number() over(partition by id order by sname desc ) AS rn
FROM $mysqlName.$mysqlDB.t2
) tmp WHERE id < 999 AND sname = 'aa'
|
执行过程
- 跟 Aggregate 类似,判断 project中的字段是否是确定的
- 找出可以下推的,也就是出现的 windows 函数中的字段
- 将不能下推的重新组合,能下推的移动到 windows 算子下面
逻辑计划:
1
2
3
4
5
6
7
8
9
10
11
12
|
== Analyzed Logical Plan ==
id: int, sname: string
Project [id#1, sname#2]
+- Filter ((id#1 < 999) AND (sname#2 = aa))
+- SubqueryAlias tmp
+- Project [id#1, sname#2, rn#0]
+- Project [id#1, sname#2, rn#0, rn#0]
+- Window [row_number() windowspecdefinition(id#1, sname#2 DESC NULLS LAST, specifiedwindowframe(RowFrame,
unboundedpreceding$(), currentrow$())) AS rn#0], [id#1], [sname#2 DESC NULLS LAST]
+- Project [id#1, sname#2]
+- SubqueryAlias t2
+- RelationV2[id#1, sname#2] t2
|
优化后的中间结果
1
2
3
4
5
|
Filter (sname#2 = aa)
+- Window [row_number() windowspecdefinition(id#1, sname#2 DESC NULLS LAST, specifiedwindowframe(RowFrame,
unboundedpreceding$(), currentrow$())) AS rn#0], [id#1], [sname#2 DESC NULLS LAST]
+- Filter (id#1 < 999)
+- RelationV2[id#1, sname#2] t2
|
Case 4 – Push predicate through Union
SQL如下:
1
2
3
4
5
|
SELECT tmpc FROM (
SELECT id AS tmpc FROM t1
UNION ALL
SELECT id AS tmpc FROM t2
) tmp WHERE tmpc >1 AND rand()>0.1
|
逻辑计划:
1
2
3
4
5
6
7
8
9
10
11
12
|
== Analyzed Logical Plan ==
tmpc: int
Project [tmpc#0]
+- Filter ((tmpc#0 > 1) AND (rand(5842271494822007178) > cast(0.1 asf double)))
+- SubqueryAlias tmp
+- Union false, false
:- Project [id#2 AS tmpc#0]
: +- SubqueryAlias t1
: +- RelationV2[id#2, sname#3] t1
+- Project [id#4 AS tmpc#1]
+- SubqueryAlias t2
+- RelationV2[id#4, sname#5] 2 t2
|
优化后的中间结果,之前最外层的 tmpc > 1 被下推到了 UNION的下层了,而不确定的字段 rand 则没被下推
1
2
3
4
5
6
7
8
|
Filter (rand(5842271494822007178) > cast(0.1 as double))
+- Union false, false
:- Filter (tmpc#0 > 1)
: +- Project [id#2 AS tmpc#0]
: +- RelationV2[id#2, sname#3] t1
+- Filter (tmpc#1 > 1)
+- Project [id#4 AS tmpc#1]
+- RelationV2[id#4, sname#5] t2
|
Case 5 – Push predicate through all other supported operators
其他一些可以下推的场景
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
def canPushThrough(p: UnaryNode): Boolean = p match {
// Note that some operators (e.g. project, aggregate, union) are being handled separately
// (earlier in this rule).
case _: AppendColumns => true
case _: Distinct => true
case _: Generate => true
case _: Pivot => true
case _: RepartitionByExpression => true
case _: Repartition => true
case _: RebalancePartitions => true
case _: ScriptTransformation => true
case _: Sort => true
case _: BatchEvalPython => true
case _: ArrowEvalPython => true
case _: Expand => true
case _ => false
}
|
SQL
1
2
3
4
5
6
7
8
9
10
|
SELECT order_id FROM
(
SELECT * FROM item
pivot (
count(id)
FOR item_name IN (
'item1' item_1
)
)
) WHERE order_id > 10
|

PushPredicateThroughJoin
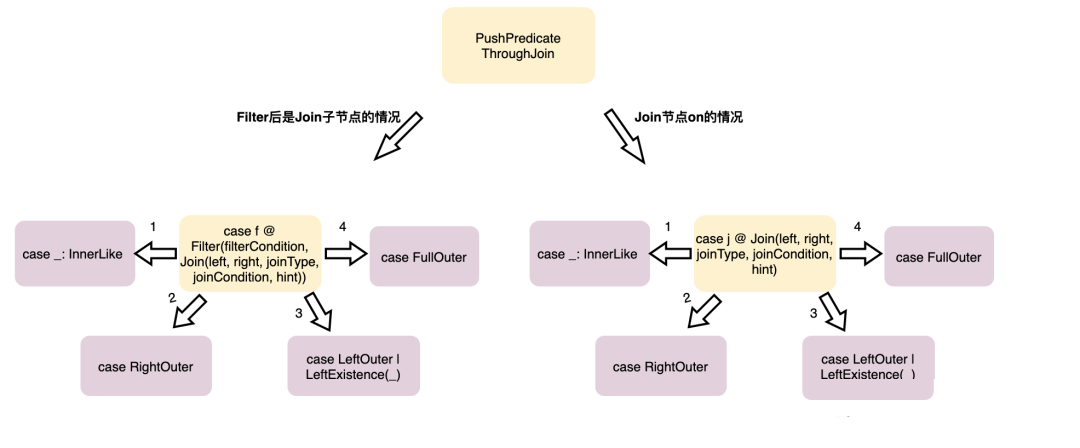
图片来自这里
case-1,Filter+inner join:把过滤条件下推到参加Join的两端
步骤
- 这里会取出 left 条件, right 条件,以及通用条件,然后分别跟 left子节点,right子节点重新拼接
- 也就是将 Filter放到 left、right 节点的上面,实现下推,最后将两个新的 子节点(此时左右都是 Filter)
- 拼接成一个新的 JOIN
1
2
3
|
SELECT a.sname, b.sname FROM t1 AS a JOIN t2 AS b
ON a.id = b.id
WHERE a.id < 1 AND b.id > 99
|
逻辑计划:
1
2
3
4
5
6
7
8
9
10
11
|
== Analyzed Logical Plan ==
sname: string, sname: string
Project [sname#1, sname#3]
+- Filter ((id#0 < 1) AND (id#2 > 99))
+- Join Inner, (id#0 = id#2)
:- SubqueryAlias a
: +- SubqueryAlias t1
: +- RelationV2[id#0, sname#1] t1
+- SubqueryAlias b
+- SubqueryAlias t2
+- RelationV2[id#2, sname#3] t2
|
优化的中间结果:
1
2
3
4
5
|
Join Inner, (id#0 = id#2)
:- Filter (id#0 < 1)
: +- RelationV2[id#0, sname#1] t1
+- Filter (id#2 > 99)
+- RelationV2[id#2, sname#3] t2
|
case-2,Filter+left join,把where子句的左侧数据表的过滤条件下推到左侧数据表
跟 case-1 差不多,只是下推了左节点的条件
1
2
3
|
SELECT a.sname, b.sname FROM t1 AS a LEFT OUTER JOIN t2 AS b
ON a.id = b.id
WHERE a.id < 1
|
逻辑计划:
1
2
3
4
5
6
7
8
9
10
11
|
== Analyzed Logical Plan ==
sname: string, sname: string
Project [sname#1, sname#3]
+- Filter (id#0 < 1)
+- Join LeftOuter, (id#0 = id#2)
:- SubqueryAlias a
: +- SubqueryAlias t1
: +- RelationV2[id#0, sname#1] t1
+- SubqueryAlias b
+- SubqueryAlias t2
+- RelationV2[id#2, sname#3] t2
|
中间结果:
1
2
3
4
|
Join LeftOuter, (id#0 = id#2)
:- Filter (id#0 < 1)
: +- RelationV2[id#0, sname#1] t1
+- RelationV2[id#2, sname#3] t2
|
case-3,Filter+left join,把where子句的右侧数据表的过滤条件下推到右侧数据表
1
2
3
|
SELECT a.sname, b.sname FROM t1 AS a RIGHT OUTER JOIN t2 AS b
ON a.id = b.id
WHERE b.id > 99
|
逻辑计划:
1
2
3
4
5
6
7
8
9
10
11
|
== Analyzed Logical Plan ==
sname: string, sname: string
Project [sname#1, sname#3]
+- Filter (id#2 > 99)
+- Join RightOuter, (id#0 = id#2)
:- SubqueryAlias a
: +- SubqueryAlias t1
: +- RelationV2[id#0, sname#1] 1 t1
+- SubqueryAlias b
+- SubqueryAlias t2
+- RelationV2[id#2, sname#3] t2
|
中间结果:
1
2
3
4
|
Join RightOuter, (id#0 = id#2)
:- RelationV2[id#0, sname#1] t1
+- Filter (id#2 > 99)
+- RelationV2[id#2, sname#3] t2
|
case-4,full join,这个很多时候会被转换为 left、right或者 inner
然后再进一步下推
带 where 的 full join 实际是
- EliminateOuterJoin
- PushPredicateThroughJoin
共同完成的转换,下推的
case-5,join 的 ON 条件下推,这里仅列出 INNER 的情况,其他场景类似
1
2
3
|
SELECT a.sname, b.sname FROM t1 AS a JOIN t2 AS b
ON a.id = b.id
AND a.id > 99 AND b.sname = 'hehe'
|
逻辑计划:
1
2
3
4
5
6
7
8
9
10
|
== Analyzed Logical Plan ==
sname: string, sname: string
Project [sname#1, sname#3]
+- Join Inner, (((id#0 = id#2) AND (id#0 > 99)) AND (sname#3 = hehe))
:- SubqueryAlias a
: +- SubqueryAlias t1
: +- RelationV2[id#0, sname#1] t1
+- SubqueryAlias b
+- SubqueryAlias t2
+- RelationV2[id#2, sname#3] t2
|
优化后的中间结果:
1
2
3
4
5
|
Join Inner, (id#0 = id#2)
:- Filter (id#0 > 99)
: +- RelationV2[id#0, sname#1] t1
+- Filter (sname#3 = hehe)
+- RelationV2[id#2, sname#3] t2
|
LimitPushDown
可以下推的包括
- 子节点为 Union
- 子节点为 JOIN,分好几种情况
- RightOuter 时,join 条件不空,可以下推 limit 到join 右边
- LeftOuter 时,join条件不空,可以下推 limit 到 join 左边
- InnerLike 时,条件不空,下推到左右两边
- LeftSemi,LeftAnti 时,条件不空,下推到 join 的左边
- 子节点为 PROJECT
- 孙子为 JOIN
- 孙子为 BatchEvalPython
- 孙子为 ArrowEvalPython
- limit 1,并且字节为 Aggregate
- limit 1,并且子节点为 project
- 子节点为 OFFSET
- 子节点为 BatchEvalPython
- 子节点为 ArrowEvalPython
SQL:
1
2
3
4
|
SELECT a.sname, b.sname FROM t1 AS a
LEFT OUTER JOIN
t2 AS b
ON a.id = b.id LIMIT 1
|
逻辑计划:
1
2
3
4
5
6
7
8
9
10
11
12
|
== Analyzed Logical Plan ==
sname: string, sname: string
GlobalLimit 1
+- LocalLimit 1
+- Project [sname#1, sname#3]
+- Join LeftOuter, (id#0 = id#2)
:- SubqueryAlias a
: +- SubqueryAlias t1
: +- RelationV2[id#0, sname#1] t1
+- SubqueryAlias b
+- SubqueryAlias t2
+- RelationV2[id#2, sname#3] t2
|
优化后:
1
2
3
4
5
6
7
8
|
== Optimized Logical Plan ==
GlobalLimit 1
+- LocalLimit 1
+- Project [sname#1, sname#3]
+- Join LeftOuter, (id#0 = id#2)
:- LocalLimit 1
: +- RelationV2[id#0, sname#1] t1
+- RelationV2[id#2, sname#3] t2
|
ColumnPruning
试图消除查询计划中不需要的列读取
1
2
3
4
5
|
SELECT id, m_id FROM
(
SELECT id, max(id) as m_id, max(parent_id) as m_pid
FROM $mysqlName.$mysqlDB.zz_3 GROUP BY id
)
|
逻辑计划:
1
2
3
4
5
6
7
|
== Analyzed Logical Plan ==
id: int, m_id: int
Project [id#2, m_id#0]
+- SubqueryAlias __auto_generated_subquery_name
+- Aggregate [id#2], [id#2, max(id#2) AS m_id#0, max(parent_id#3) AS m_pid#1]
+- SubqueryAlias zz_3
+- RelationV2[id#2, parent_id#3, sname#4] zz_3
|
中间结果:
1
2
3
|
Project [id#2, m_id#0]
+- Aggregate [id#2], [id#2, max(id#2) AS m_id#0]
+- RelationV2[id#2, parent_id#3, sname#4] zz_3
|
参考