聚合原理
概述
聚合物理执行的分类
这里会区分 是否有 distinct 关键字
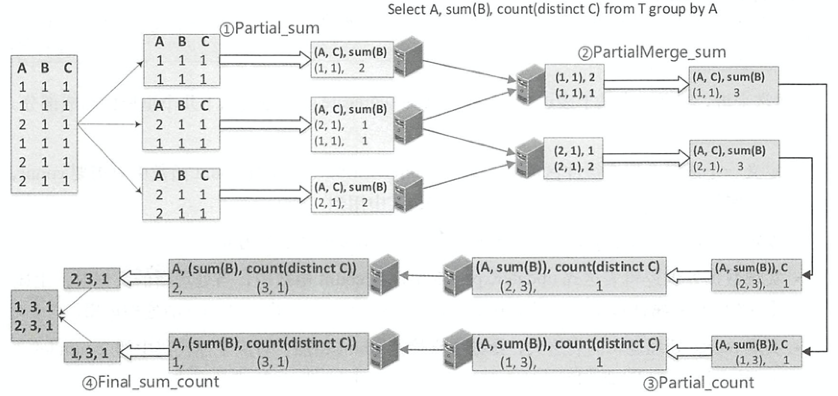
- 不包含的会转为两层 hash,一个是部分聚合,一个是最终聚合
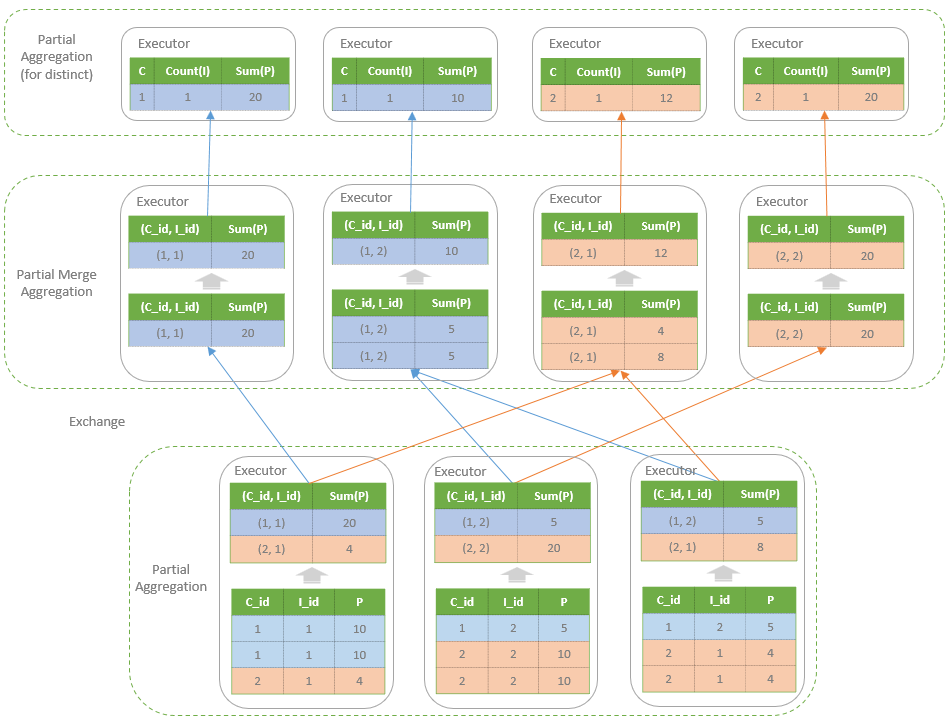
- 包含的会转为四步:1)部分聚合、2)部分合并、3)部分聚合(跟普通的类似)、4)最终聚合(跟普通的类似)
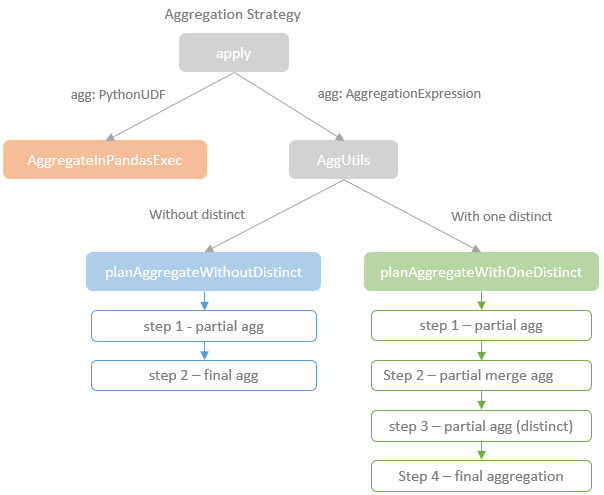
图片来自于这里
聚合过程有4种模式
- Partial模式
- ParitialMerge模式
- Final模式
- Complete模式,应用在不支持Partial模式的聚合函数中
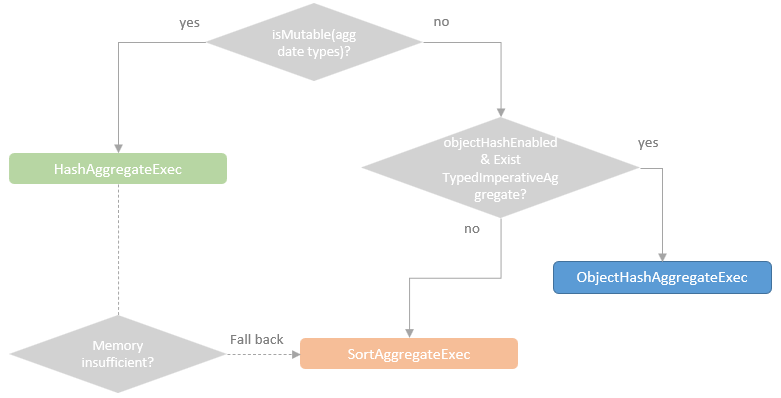
各种聚合类型的选择过程:
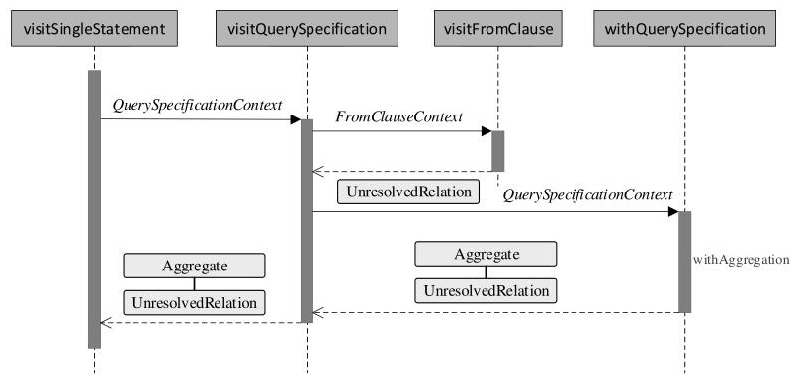
AST 的遍历过程:
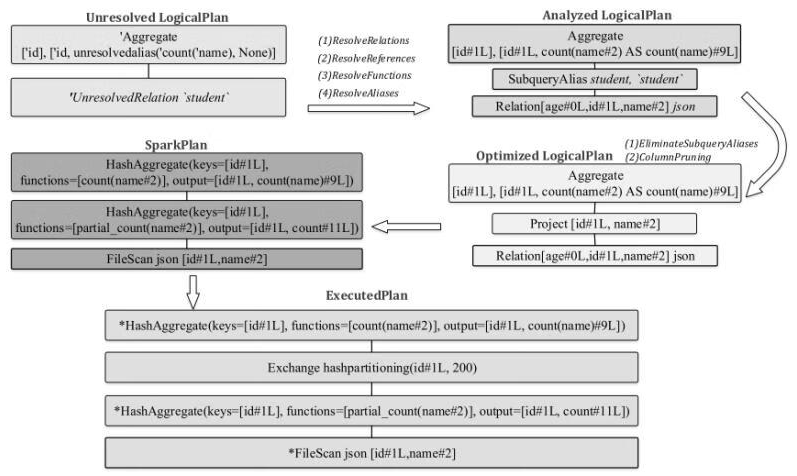
unresolved -> spark plan过程:
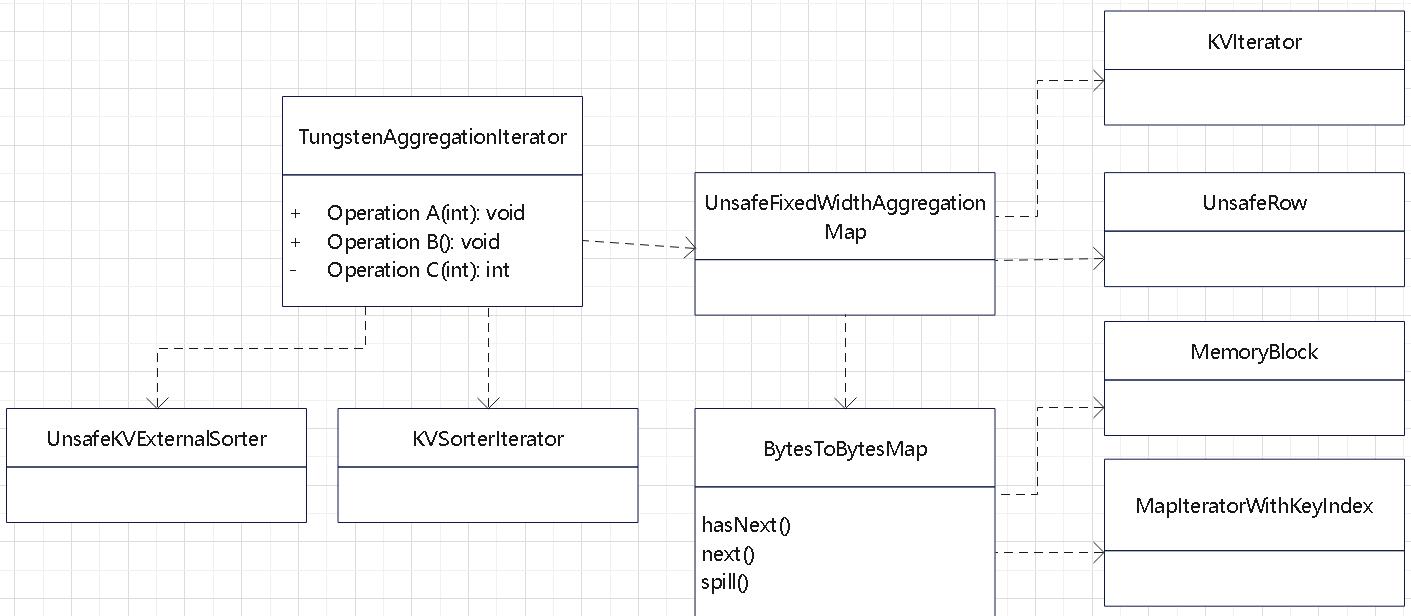
相关的类图
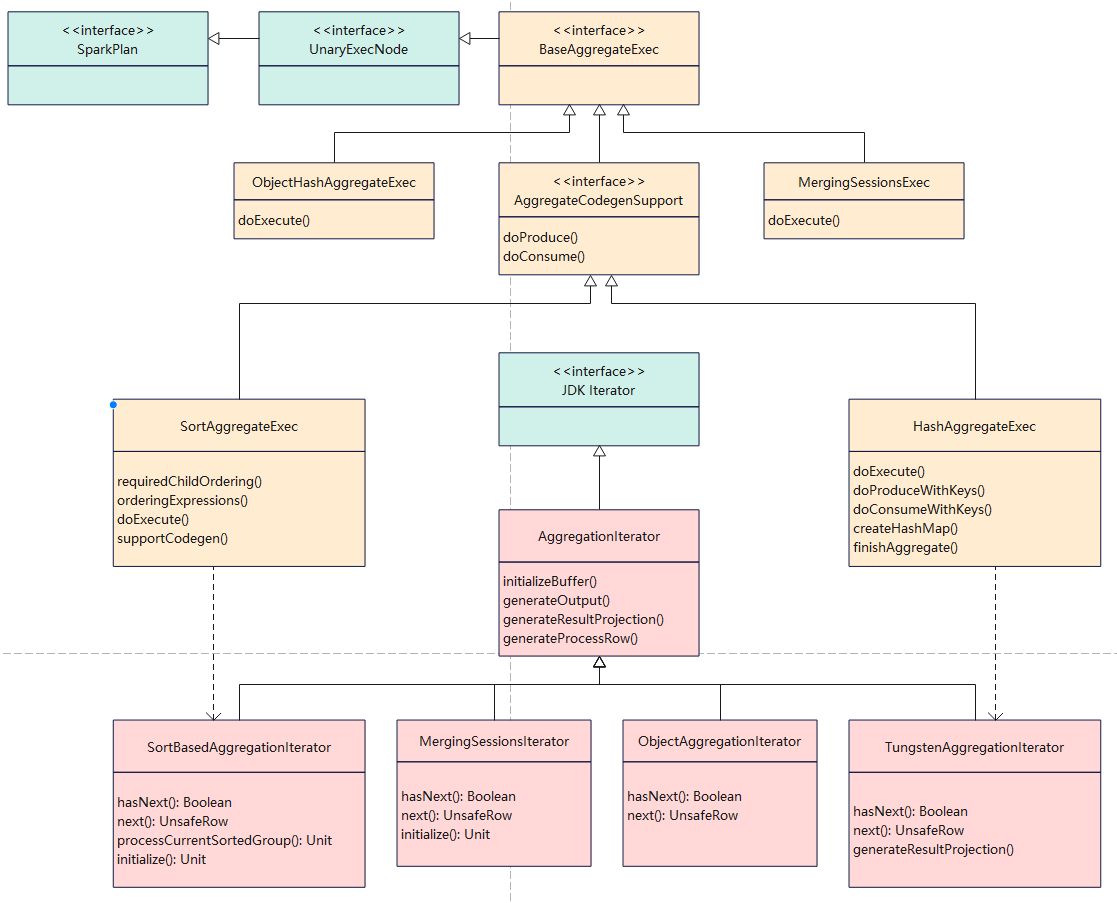
如上图
- 绿色的是 spark、JDK 逻辑
- 黄色的是聚合相关的类
- 红色的是聚合的迭代类
黄色部分
- 基础类 BaseAggregateExec
- 两个主要的聚合实现类:SortAggregateExec、HashAggregateExec
- 基于 Java对象的 ObjectHashAggregateExec
红色部分
- 基础的聚合迭代类 AggregationIterator
- 两个实现类 SortBasedAggregationIterator、TungstenAggregationIterator
- TungstenAggregationIterator 是基于代码生成的
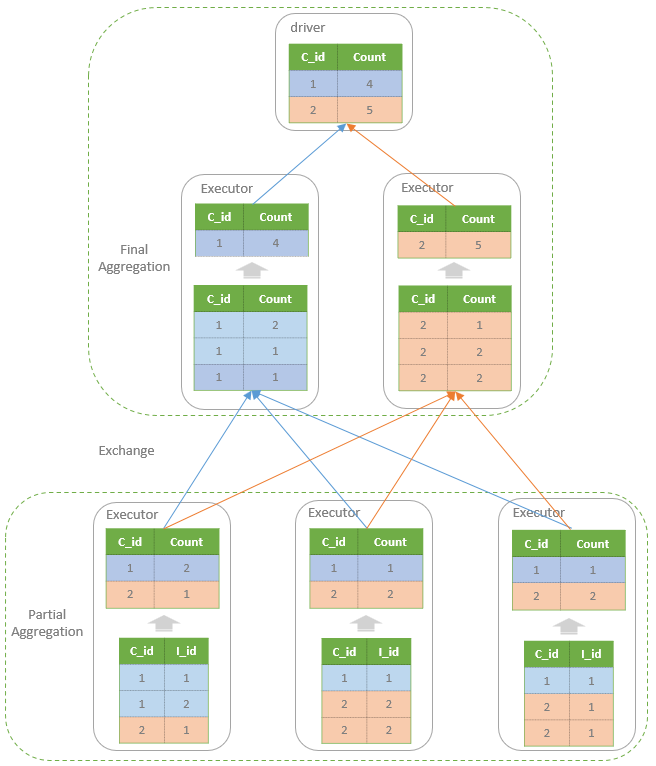
非distinct
比如
1
2
3
|
SELECT customer_id, COUNT(item_id) AS count
FROM order
GROUP BY customer_id
|
转换成的物理计划如下:

从物理执行角度看如下:
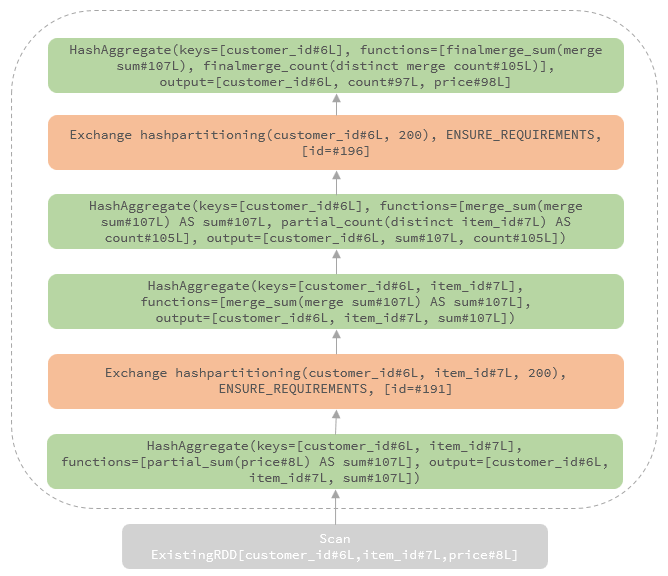
包含distinct
比如
1
2
3
|
SELECT customer_id, COUNT(DISTINCT item_id) AS count, SUM(price) AS price
FROM order
GROUP BY customer_id
|
转换成的物理计划如下:
从执行角度看
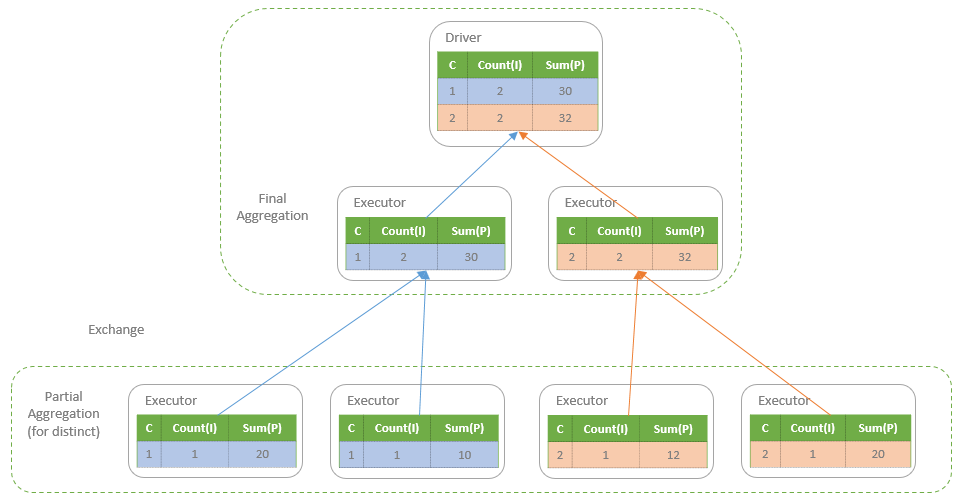
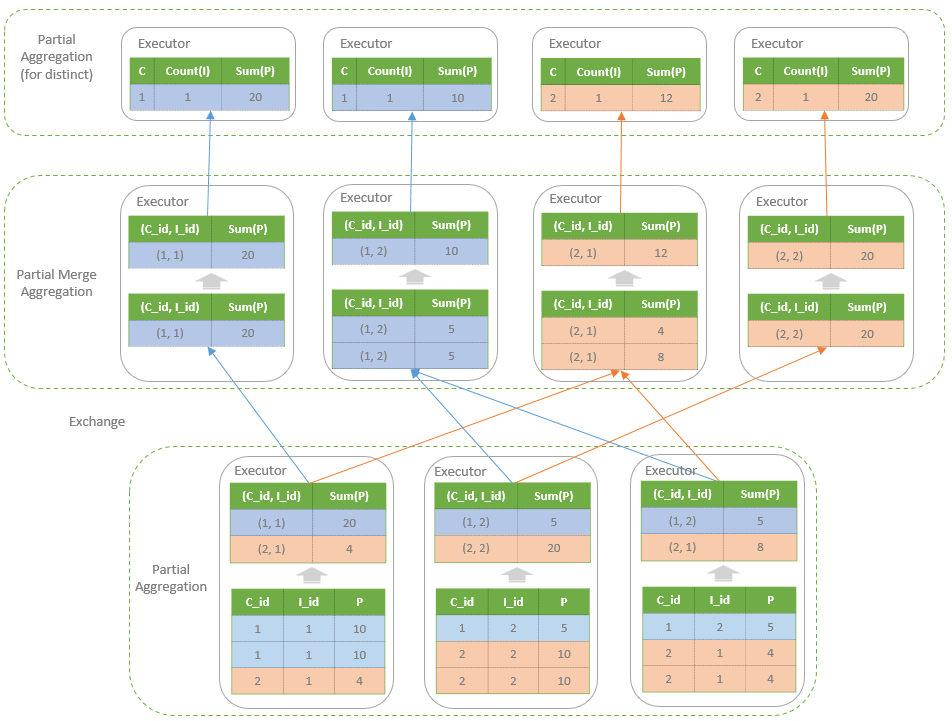
另一个视角:
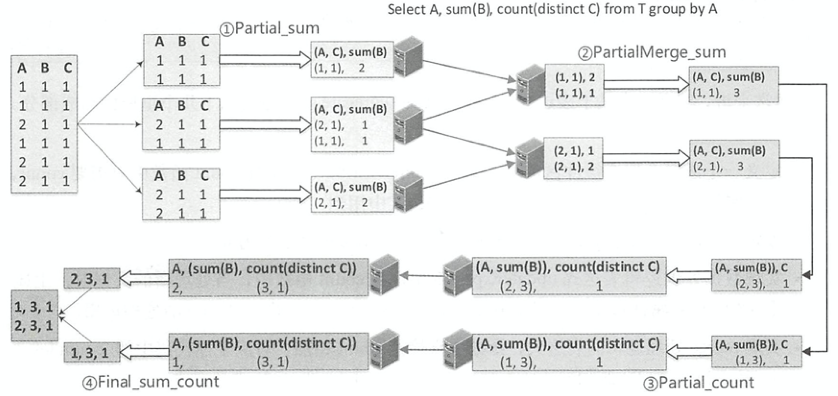
图片来自这里
聚合方式
DeclarativeAggregate
- 直接由表达式Expressions构建的聚合函数,主要逻辑通过调用 4 个表达式完成
- 分别是聚合缓冲区初始化表达式initialValues
- 聚合缓冲区更新表达式updateExpressions
- 聚合缓冲区合并表达式mergeExpressions
- 最终结果生成表达式evaluateExpression
ImperativeAggregate
- 需要显式地实现initialize(), update(), merge()方法来操作聚合缓冲区中的数据
- ImperativeAggregate聚合函数所处理的聚合缓冲区本质上是基于行InternalRow
- 聚合缓冲区是共享的,可能对应多个聚合函数,因此特定的ImperativeAggregate聚合函数会通过偏移量mutableAggBufferOffset在可变缓冲区MutableAggBuffer中进行定位
- 在合并聚合缓冲区时,通过将输入缓冲区InputAggBuffer的值更新到可变缓冲区MutableAggBuffer中,需要通过偏移量inputAggBuferOffset来访问特定的聚合值。
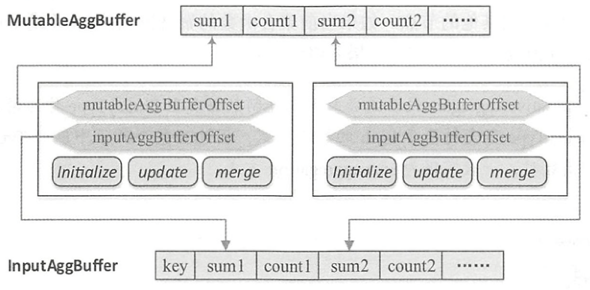
explain with chatGPT4
- DeclarativeAggregate:
- They are defined using expressions and are composed of other expressions.
- They work by using Spark SQL’s Catalyst optimizer to build up an execution plan.
- Since they are made up of expressions, they are more amenable to optimization by Catalyst.
- Common examples include built-in functions like sum, avg, min, max, etc.
- ImperativeAggregate:
- They are defined in terms of programming constructs and typically involve mutable state.
- They require developers to provide the logic for processing input rows, generating the aggregate value, and merging intermediate results.
- They are harder to optimize since they are black boxes to Catalyst.
- User-defined aggregates (UDAFs) are often implemented as ImperativeAggregate.
TypedAggregateExpression
- 聚合函数允许使用用户自定义的 Java 对象作为内部的聚合缓冲区
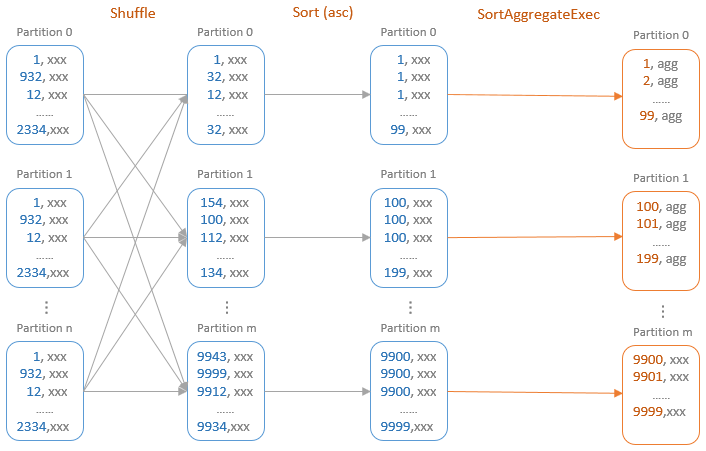
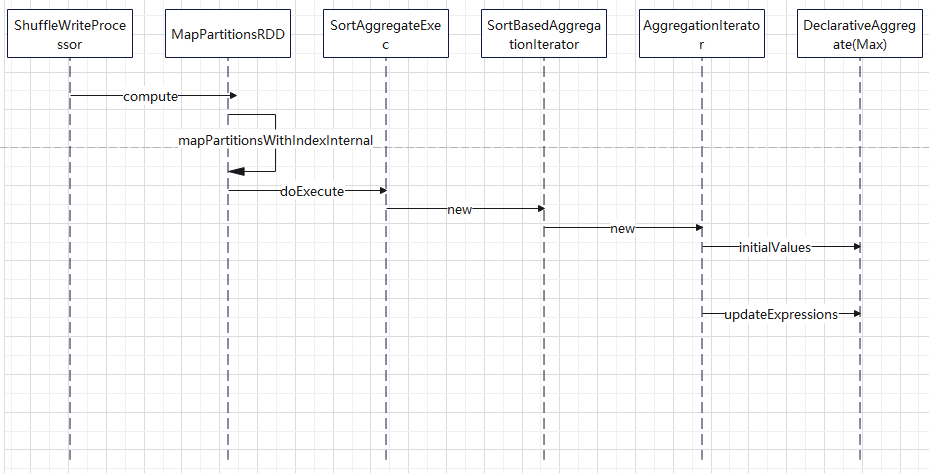
基于排序的聚合
基于排序的聚合物理计划
- 在进行聚合之前,会根据分组键进行shuffle,所以会添加Exchange物理计划
- requiredChildOrdering要求分组表达式列表中的每个表达式都必须满足升序排列
- 因此在SortAggregateExec节点之前通常都会添加一个SortExec节点
- 对于SortAggregateExec来说,只需要顺序遍历整个分区内的数据,即可得到聚合结果
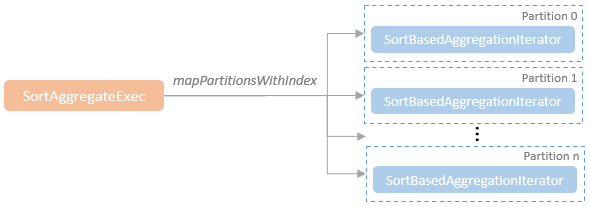
- 在其doExecute()方法中每个分区内都构建了SortBasedAggregationIterator迭代器
- 将聚合的具体逻辑交由迭代器处理
测试代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
test("agg with sort") {
val peopleData = Seq(
"""{"name":"Michael"}""",
"""{"name":"Andy", "age":30}""",
"""{"name":"Justin", "age":19}"""
)
val df: DataFrame = spark.read.json(spark.sparkContext.parallelize(peopleData))
df.createTempView("people")
val df3 = spark.sql(
"""
|SELECT max(name) FROM people GROUP BY name ORDER BY name
|""".stripMargin)
df3.show()
df3.explain("extended")
}
|
结果:
1
2
3
4
5
6
7
|
+---------+
|max(name)|
+---------+
| Andy|
| Justin|
| Michael|
+---------+
|
打印的物理结果(省略掉其他一些逻辑计划)
1
2
3
4
5
6
7
8
9
10
11
12
|
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- Project [max(name)#11]
+- Sort [name#7 ASC NULLS FIRST], true, 0
+- Exchange rangepartitioning(name#7 ASC NULLS FIRST, 1), ENSURE_REQUIREMENTS, [plan_id=107]
+- SortAggregate(key=[name#7], functions=[max(name#7)], output=[max(name)#11, name#7])
+- Sort [name#7 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(name#7, 1), ENSURE_REQUIREMENTS, [plan_id=103]
+- SortAggregate(key=[name#7], functions=[partial_max(name#7)], output=[name#7, max#17])
+- Sort [name#7 ASC NULLS FIRST], false, 0
+- Project [name#7]
+- Scan ExistingRDD[age#6L,name#7]
|
实现方式
基于排序的聚合,需要
- sort 节点
- exchange 节点

之后基于分区创建对应的迭代器
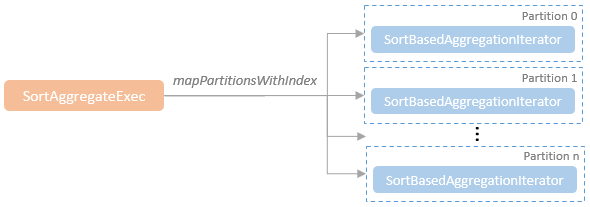
跟 hash agg 不同,不需要一个 map 了,通过一个 row 来 hold 当前的聚合数据即可
SortBasedAggregationIterator#next
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
override final def next(): UnsafeRow = {
if (hasNext) {
// Process the current group.
processCurrentSortedGroup()
// Generate output row for the current group.
val outputRow = generateOutput(currentGroupingKey, sortBasedAggregationBuffer)
// Initialize buffer values for the next group.
initializeBuffer(sortBasedAggregationBuffer)
numOutputRows += 1
outputRow
} else {
// no more result
throw new NoSuchElementException
}
}
|
上面的next是最核心的入口,包括
- 调用 processCurrentSortedGroup,处理当前分组,如果遇到下一个分组,则保存,清空当前 buffer
- 调用 generateResultProjection,将结果加入到中间结果集中(Partial,PartialMerge)或者生成最后结果(Final,Complete)
- 调用 initializeBuffer,待下次使用
- 记录 +1,输出(结果为UnsafeRow 类型)
调用 processCurrentSortedGroup 来处理当前行,直到碰到下一个分组,则继续
如上图,一个分组内,1开头的,会不断处理,更新 agg buffer
当遇到下一个分组时,将结果放到 output 中,再清空分组
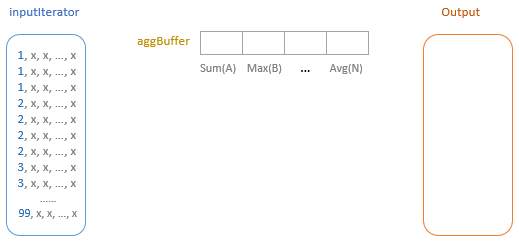
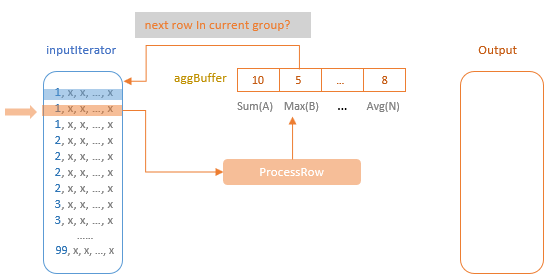
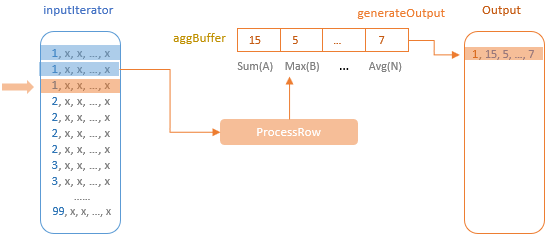
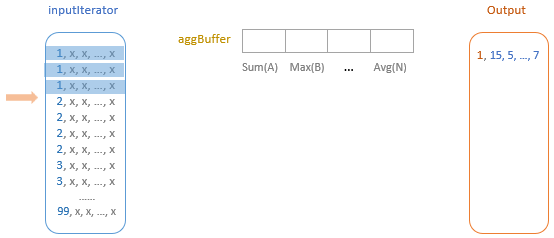
initializeAggregateFunctions():
- 聚合函数初始化。为ImperativeAggregate类型的聚合函数设置输入缓冲区偏移量
- inputBufferOffset和可变缓冲区偏移量mutableAggBufferOffset
generateProcessRow():
- 返回数据处理函数processRow: (InternalRow, InternalRow) => Unit,处理当前的聚合缓冲区和输入数据行。
- 数据处理函数的核心操作是对于Partial和Complete模式,处理的是原始输入数据,因此采用的是update函数;
- 而对于Final和PartialMerge模式,处理的是聚合缓冲区,因此采用的是 merge函数
generateResultProjection():
- 返回最终计算结果函数generateOutput: (UnsafeRow, InternalRow) => UnsafeRow。
- 对于Partial或PartialMerge模式的聚合函数,因为只是中间结果,所以需要保存分组语句与聚合缓冲属性;
- 对于Final和Complete模式,直接对应resultExpressions表达式
自定义函数
比如这个 sql
1
|
SELECT my_add_123(id, 100) AS id FROM mysqldb.hello.t1 AS t
|
这里的 my_add_123 是自定义的函数,功能很简单,将两个整数相加返回
V1 实现
自定义一个 my_add_123 函数,假设:
1
2
3
4
5
6
7
8
9
10
|
trait MyFunc extends Serializable {
def myfunc(a: Int, b: Int): Int
}
class MyXXX extends MyFunc {
override def myfunc(a: Int, b: Int): Int = {
a + b
}
}
|
这里的 接口类非常简单,实际应该是暴露出 函数名,函数签名,返回值等等,这里只是简化了处理
在元数据库中定义一个表,记录 UDF 的一些信息,比如:
| 函数名 |
库名 |
描述信息 |
jar 路径 |
| my_add_123 |
hello |
my add function |
hdfs://myhdfs:8020/test/my_fun.jar |
增加一个自定义的 类加载器,MyClassLoader,这个类加载其根据 hdfs 路径,将这个 jar 包下载
然后将 byte[] -> Class,再将其转换为 MyFunc 类型
V2 实现
继承并自定义loadFunction
根据 Identifier 查找自定义的 function,比如从元数据库中查找,再根据路径从 hdfs 上将对应的 jar 拿到
同样也需要一个元数据信息
| 函数名 |
库名 |
描述信息 |
jar 路径 |
| my_add_123 |
hello |
my add function |
hdfs://myhdfs:8020/test/my_fun.jar |
这里需要增加一个自定义的classloader
然后使用个上下文 classloader
增加自定义的实现类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
class MyUnboundFunction extends UnboundFunction {
override def bind(inputType: StructType): BoundFunction = {
val loader = this.getClass.getClassLoader
println(s"MyUnboundFunction class loader -> $loader")
val threadLoader = Thread.currentThread().getContextClassLoader
println(s"thread context loader -> $threadLoader")
new AddFunction()
}
override def description(): String = {
"my_add_func"
}
override def name(): String = {
"add_func"
}
}
class AddFunction extends ScalarFunction[Int] {
override def inputTypes(): Array[DataType] = {
Array(DataTypes.IntegerType, DataTypes.IntegerType)
}
override def resultType(): DataType = {
DataTypes.IntegerType
}
override def name(): String = {
"add"
}
// 会优先调用这个函数
def invoke(a: Int, b: Int): Int = {
a + b
}
override def produceResult(input: InternalRow): Int = {
val arr: Array[MutableValue] = input.asInstanceOf[SpecificInternalRow].values
arr(0).asInstanceOf[MutableInt].value + arr(1).asInstanceOf[MutableInt].value
}
}
|
add jar 命令引入的 classloader
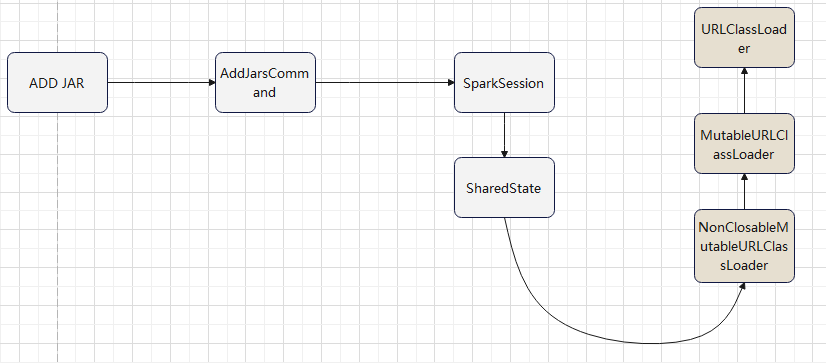
使用自定义的 classloader
- 加载 MyUnboundFunction 时,使用自定义的 classloader
- MyUnboundFunction 加载 AddFunction 时,正常 new 出来就可以了
下面这段,放到 loadFunction 中,执行自定义的加载逻辑
1
2
3
4
5
6
7
8
|
val parent = Thread.currentThread().getContextClassLoader
// 这里 spark 的classloader,这里直接使用
val loader = new NonClosableMutableURLClassLoader(parent)
loader.addURL( new URL("hdfs://myhdfs:8020/test/xx.jar") )
Thread.currentThread().setContextClassLoader(loader)
val funcClassName = "com.test.func.MyUnboundFunction"
val clazz = Class.forName(funcClassName, true, loader)
clazz.newInstance().asInstanceOf[UnboundFunction]
|
加载 MyUnboundFunction 后,打印如下信息,这里已经使用了自定义的 classloader 了
MyUnboundFunction class loader -> org.apache.spark.sql.internal.NonClosableMutableURLClassLoader@514377fc
thread context loader -> org.apache.spark.sql.internal.NonClosableMutableURLClassLoader@514377fc
提供创建 函数的 sql:
1
2
3
4
5
6
7
|
CREATE OR REPLACE FUNCTION IF NOT EXISTS func1
BY 'org.apache.spark.example.A' USING '/tmp/a.jar'
DROP FUNCTION IF EXISTS func1
DESC FUNCTION func1
SHOW FUNCTIONS
|
增加自定义的 parser,逻辑计划等,将这些信息写到数据库中
上述的函数是全局范围的,也可以指定 catalog,将这个函数绑定到某个 catalog 下
这样同名的,但不同功能的函数,就可以区分了
V2方式聚合函数
这里是将 my_add_123作为聚合函数使用
创建两个类,未绑定的函数,以及绑定后的聚合函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
class MyUnboundAgg extends UnboundFunction {
override def bind(inputType: StructType): BoundFunction = {
new MyAggregate()
}
override def description(): String = {
"my_agg_udf"
}
override def name(): String = {
"my_agg"
}
}
class MyAggregate extends AggregateFunction[AtomicInteger, Int] {
override def newAggregationState(): AtomicInteger = {
new AtomicInteger(0)
}
override def update(state: AtomicInteger, input: InternalRow): AtomicInteger = {
val tmp = input.getInt(0) + input.getInt(1)
println(s"update -> $tmp")
val tmp2 = state.get() + tmp
state.set(tmp2)
println(s"update total -> ${state.get()}")
state
}
override def merge(leftState: AtomicInteger, rightState: AtomicInteger): AtomicInteger = {
val res: Int = leftState.get() + rightState.get()
println(s"merge -> $res")
leftState.set(res)
println(s"merge -> ${leftState.get()}")
leftState
}
override def produceResult(state: AtomicInteger): Int = {
println(s"state -> $state")
state.get()
}
override def inputTypes(): Array[DataType] = {
Array(IntegerType, IntegerType)
}
override def resultType(): DataType = {
IntegerType
}
override def name(): String = {
"my_add_123"
}
}
|
在 自定义的 catalog 中增加一段:
1
2
3
|
override def loadFunction(ident: Identifier): UnboundFunction = {
new MyUnboundAgg()
}
|
执行结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
update -> 101
update total -> 101
update -> 102
update total -> 203
update -> 103
update total -> 306
update -> 104
update total -> 410
merge -> 410
merge -> 410
state -> 410
+---+
| id|
+---+
|410|
+---+
|
执行展示 查询的 sql
1
|
SELECT my_add_123(id, 100) AS id FROM mysqldb.hello.t1 AS t
|
物理计划:
1
2
3
4
5
6
|
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- ObjectHashAggregate(keys=[], functions=[v2aggregator(com.test.extension.catalog.MyAggregate@23e0c200, id#0, 100, 0, 0)], output=[v2aggregator(id, 100)#3])
+- Exchange SinglePartition, ENSURE_REQUIREMENTS, [plan_id=11]
+- ObjectHashAggregate(keys=[], functions=[partial_v2aggregator(com.test.extension.catalog.MyAggregate@23e0c200, id#0, 100, 0, 0)], output=[buf#7])
+- Scan org.apache.spark.sql.execution.datasources.v2.jdbc.JDBCScan$$anon$1@3e7ddb7e [id#0] PushedFilters: [], ReadSchema: struct<id:int>
|
结果
1
2
3
4
5
6
7
8
|
+---+
| id|
+---+
|101|
|102|
|103|
|104|
+---+
|
时序图
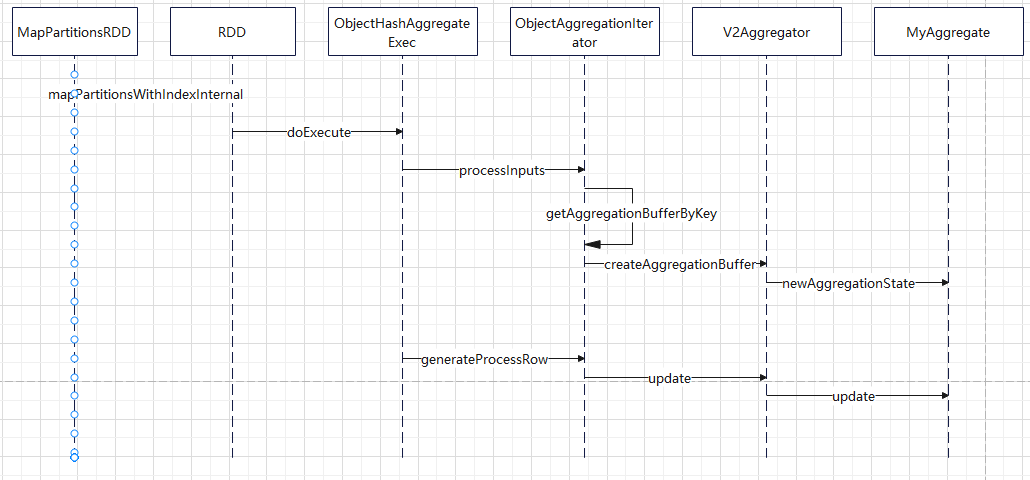
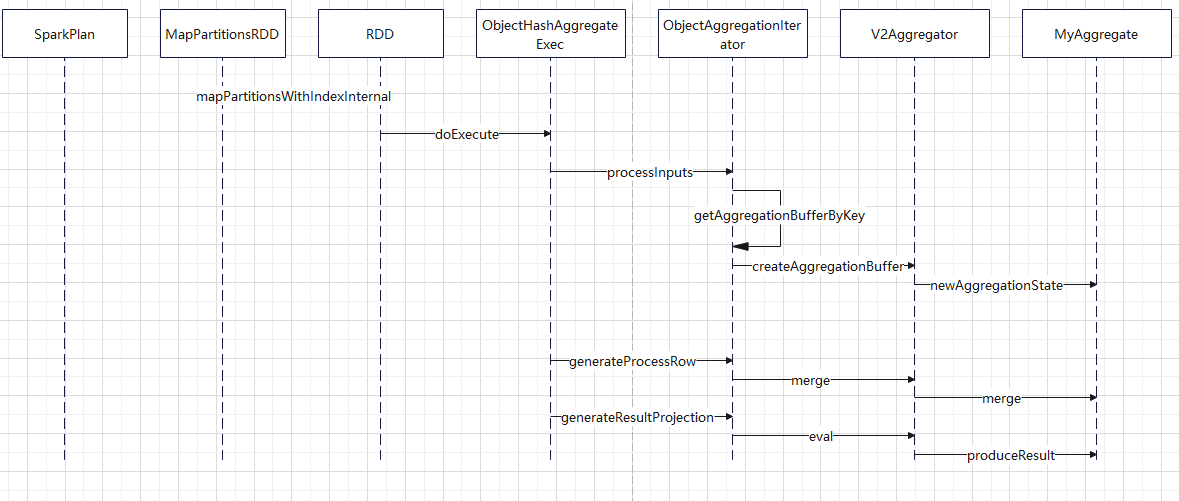
自定义函数下推
查找函数,绑定函数
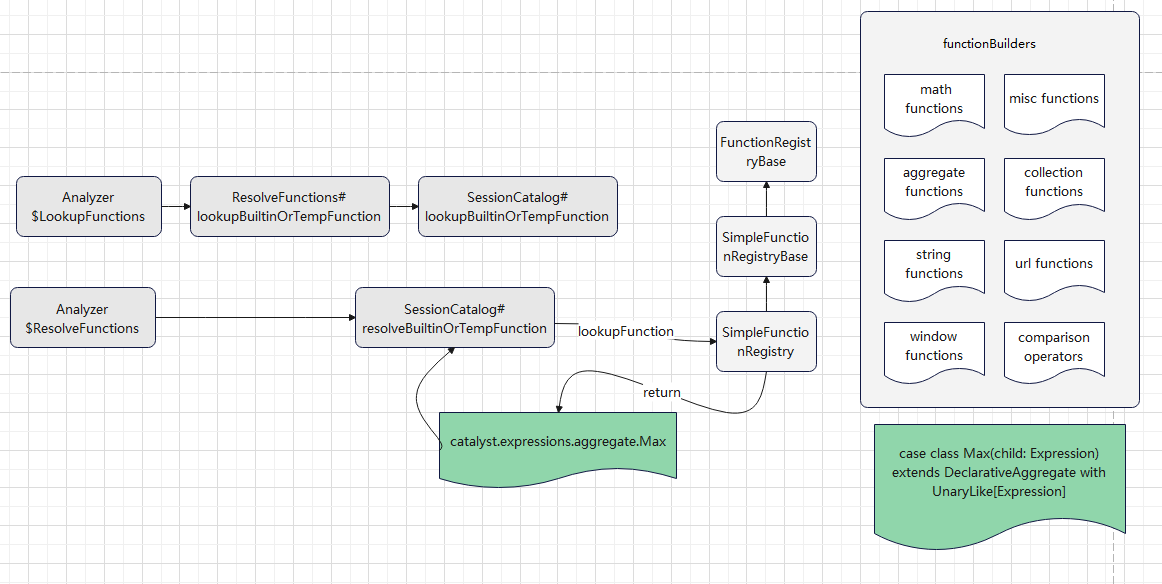
目前走的是 v1 的逻辑
内置很多函数,像max这样的函数就是内置的,所以可以查找到
绑定的时候,返回对应的 表达式
org.apache.spark.sql.catalyst.expressions.aggregate.Max
之后优化逻辑,会将这个 表达式交给具体的方言处理,看是否可以下推
方言类会将这个表达式,如 max(id + 100),转换成一个字符串,最后将这个字符串,作为 project list 的一部分,下推到具体的数据源
这里简单处理一下,实现 聚合函数方言下推
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
class CustomMySQLSQLBuilder extends JDBCSQLBuilder {
override def compileExpression(expr: Expression): Option[String] = {
val mysqlSQLBuilder = new CustomMySQLSQLBuilder()
try {
Some(mysqlSQLBuilder.build(expr))
} catch {
case NonFatal(e) =>
logWarning("Error occurs while compiling V2 expression", e)
None
}
}
override def build(expr: Expression): String = {
val s = expr.toString
if (s.contains("my_add_123")) {
"my_add_123(id, 100)"
} else {
super.build(expr)
}
}
}
|
显示已经可以下推了
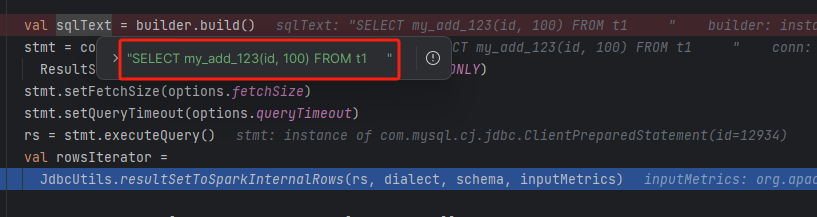
查询结果
1
2
3
4
5
6
7
8
|
+---+
| id|
+---+
|101|
|102|
|103|
|104|
+---+
|
这个函数,在 mysql 端,只是一个普通的函数,只是 spark 端,将他 当做了一个聚合函数下推过去了
但最终是按照普通函数执行的
spark 端只是拼接一个 sql
1
|
SELECT my_add_123(id, 100) FROM t1
|
这里的 my_add_123 是 聚合函数,还是标量函数,spark 不关心
所以按照这种方式,就可以实现
- 标量函数下推,把它当做聚合函数来对待
- 聚合函数下推
Hash聚合
HashAggregateExec、ObjectHashAggregateExec 的选择关系
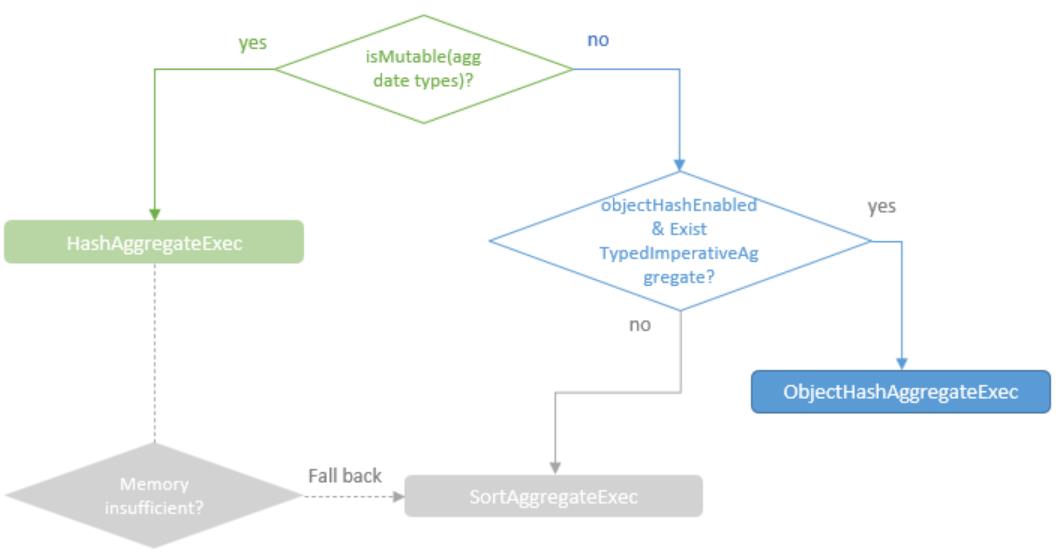
hash 聚合使用 off-heap 来存储 hash,使用的是: UnsafeFixedWidthAggregationMap
如果内存不够则溢出 到磁盘,然后创建 新的 hash map
等所有的输入都处理完后,使用基于基于排序的聚合再来处理
聚合 hash 会引用多个分区,每个分区对应一个TungstenAggregationIterator
TungstenAggregationIterator 则封装了一些核心逻辑,如hash 操作,buffer溢出,fallback到 sort-based aggregation
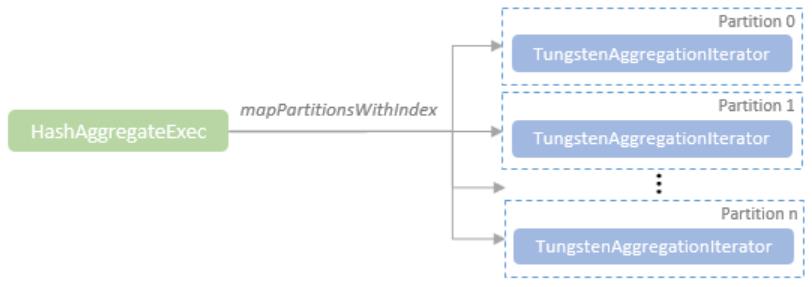
代码注释中给出的溢出到磁盘的处理逻辑:
- Step 0: Do hash-based aggregation.
- Step 1: Sort all entries of the hash map based on values of grouping expressions and spill them to disk.
- Step 2: Create an external sorter based on the spilled sorted map entries and reset the map.
- Step 3: Get a sorted KVIterator from the external sorter.
- Step 4: Repeat step 0 until no more input.
- Step 5: Initialize sort-based aggregation on the sorted iterator. Then, this iterator works in the way of - sort-based aggregation.
TungstenAggregationIterator 类的组织如下:
- Part 1: Initializing aggregate functions.
- Part 2: Methods and fields used by setting aggregation buffer values, processing input rows from inputIter, and generating output rows.
- Part 3: Methods and fields used by hash-based aggregation.
- Part 4: Methods and fields used when we switch to sort-based aggregation.
- Part 5: Methods and fields used by sort-based aggregation.
- Part 6: Loads input and process input rows.
- Part 7: Public methods of this iterator.
- Part 8: A utility function used to generate a result when there is no input and there is no grouping expression.
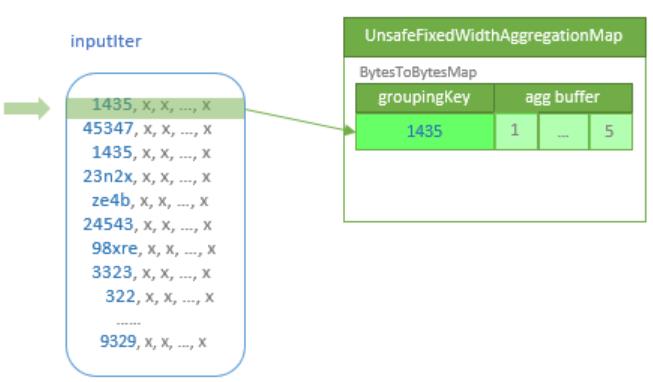
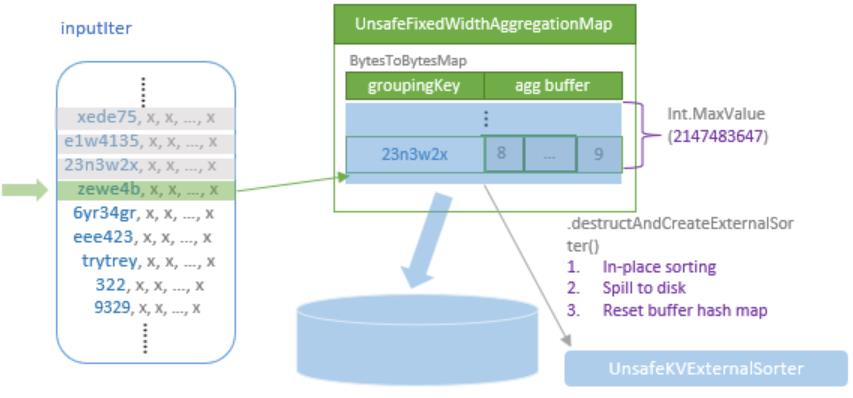
TungstenAggregationIterator 维护了一个 UnsafeFixedWidthAggregationMap,作为中间聚合结果
而内部是又是创建了 BytesToBytesMap 的一个实例,类似下图
处理输入数据
- 之后初始化 map,然后调用
processInputs 开始处理输入数据
- 如果超过阈值,则退回到 sort-based agg
- 一行一行的读取输入数据,然后将key编码成 UnsafeRow,跟 hash map中的比较
- 如果当前是空的,则将这个 key插入
- 如果存在,则更新 hash map
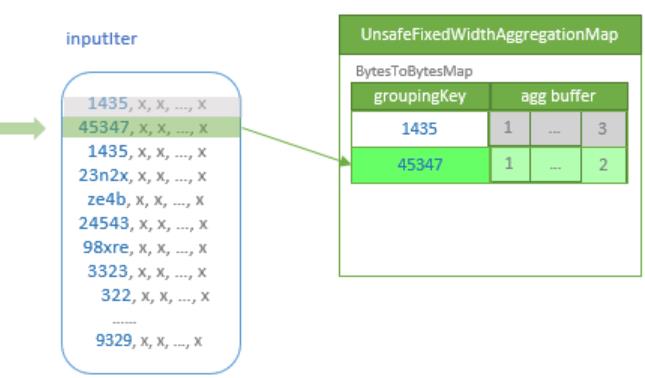

TungstenAggregationIterator 相关类图
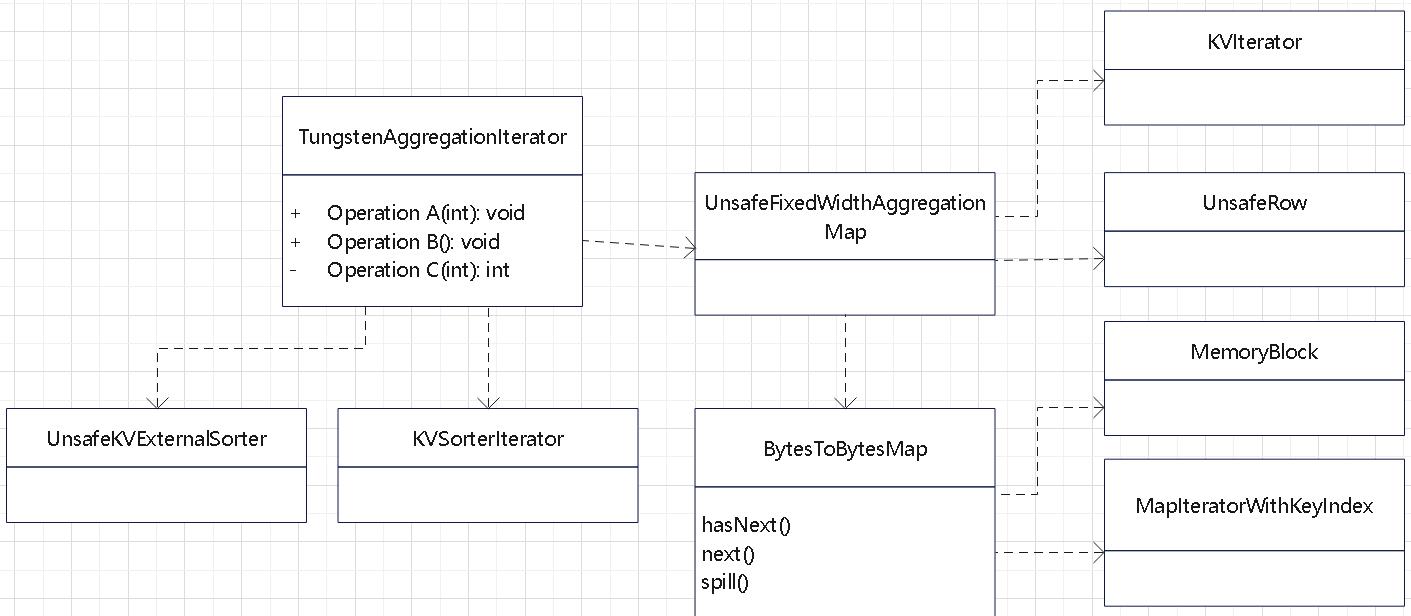
溢出逻辑
- 如果内存不足了,则将当前的 hash map 溢出到磁盘
- 先原地排序,再溢出到磁盘
- 外部存储用的是:UnsafeKVExternalSorter
- 之后创建新的 hash 表,继续处理剩余数据
- 如果所有数据处理完后,发现有 溢出的数据,则最后再做外部合并
- 这里使用的是:UnsafeKVExternalSorter 做排序的
- 之后使用 sort-based aggregation 来做聚合,而排序好的数据,则作为 sort-based agg 的输入
ObjectHashAggregateExec
- 普通的 hash聚合只适合原生数据类型
- 对于用于定义的类型,集合类等,早起会退化为 sort-based agg
- 之后出现了 ObjectHashAggregateExec,用来处理这些特殊类型
- 这种聚合不使用 off-heap,而是保存在 SpecificInternalRow
- 其内部使用 ObjectAggregationMap 作为 hash 表来保存数据
- 支持任意的 java 对象作
- 处理方式跟 hash 的类似,一行一行的读然后跟 hash表中的匹配
- 当内存不足会溢出到磁盘并创建新hash
- 排序完后如果有溢出数据再做一次总merge,然后退化为sort-based agg,排序数据作为输入

生成的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
|
/* 001 */ public Object generate(Object[] references) {
/* 002 */ return new GeneratedIteratorForCodegenStage1(references);
/* 003 */ }
/* 004 */
/* 005 */ // codegenStageId=1
/* 006 */ final class GeneratedIteratorForCodegenStage1 extends org.apache.spark.sql.execution.BufferedRowIterator {
/* 007 */ private Object[] references;
/* 008 */ private scala.collection.Iterator[] inputs;
/* 009 */ private boolean hashAgg_initAgg_0;
/* 010 */ private boolean hashAgg_bufIsNull_0;
/* 011 */ private long hashAgg_bufValue_0;
/* 012 */ private scala.collection.Iterator inputadapter_input_0;
/* 013 */ private boolean hashAgg_hashAgg_isNull_1_0;
/* 014 */ private org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter[]
hashAgg_mutableStateArray_0 = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter[1];
/* 015 */
/* 016 */ public GeneratedIteratorForCodegenStage1(Object[] references) {
/* 017 */ this.references = references;
/* 018 */ }
/* 019 */
/* 020 */ public void init(int index, scala.collection.Iterator[] inputs) {
/* 021 */ partitionIndex = index;
/* 022 */ this.inputs = inputs;
/* 023 */
/* 024 */ inputadapter_input_0 = inputs[0];
/* 025 */ hashAgg_mutableStateArray_0[0] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(1, 0);
/* 026 */
/* 027 */ }
/* 028 */
/* 029 */ private void hashAgg_doAggregateWithoutKey_0() throws java.io.IOException {
/* 030 */ // initialize aggregation buffer
/* 031 */ hashAgg_bufIsNull_0 = true;
/* 032 */ hashAgg_bufValue_0 = -1L;
/* 033 */
/* 034 */ while ( inputadapter_input_0.hasNext()) {
/* 035 */ InternalRow inputadapter_row_0 = (InternalRow) inputadapter_input_0.next();
/* 036 */
/* 037 */ boolean inputadapter_isNull_0 = inputadapter_row_0.isNullAt(0);
/* 038 */ long inputadapter_value_0 = inputadapter_isNull_0 ?
/* 039 */ -1L : (inputadapter_row_0.getLong(0));
/* 040 */
/* 041 */ hashAgg_doConsume_0(inputadapter_row_0, inputadapter_value_0, inputadapter_isNull_0);
/* 042 */ // shouldStop check is eliminated
/* 043 */ }
/* 044 */
/* 045 */ }
/* 046 */
/* 047 */ private void hashAgg_doConsume_0(InternalRow inputadapter_row_0, long hashAgg_expr_0_0,
boolean hashAgg_exprIsNull_0_0) throws java.io.IOException {
/* 048 */ // do aggregate
/* 049 */ // common sub-expressions
/* 050 */
/* 051 */ // evaluate aggregate functions and update aggregation buffers
/* 052 */
/* 053 */ hashAgg_hashAgg_isNull_1_0 = true;
/* 054 */ long hashAgg_value_1 = -1L;
/* 055 */
/* 056 */ if (!hashAgg_bufIsNull_0 && (hashAgg_hashAgg_isNull_1_0 ||
/* 057 */ hashAgg_bufValue_0 > hashAgg_value_1)) {
/* 058 */ hashAgg_hashAgg_isNull_1_0 = false;
/* 059 */ hashAgg_value_1 = hashAgg_bufValue_0;
/* 060 */ }
/* 061 */
/* 062 */ if (!hashAgg_exprIsNull_0_0 && (hashAgg_hashAgg_isNull_1_0 ||
/* 063 */ hashAgg_expr_0_0 > hashAgg_value_1)) {
/* 064 */ hashAgg_hashAgg_isNull_1_0 = false;
/* 065 */ hashAgg_value_1 = hashAgg_expr_0_0;
/* 066 */ }
/* 067 */
/* 068 */ hashAgg_bufIsNull_0 = hashAgg_hashAgg_isNull_1_0;
/* 069 */ hashAgg_bufValue_0 = hashAgg_value_1;
/* 070 */
/* 071 */ }
/* 072 */
/* 073 */ protected void processNext() throws java.io.IOException {
/* 074 */ while (!hashAgg_initAgg_0) {
/* 075 */ hashAgg_initAgg_0 = true;
/* 076 */
/* 077 */ long hashAgg_beforeAgg_0 = System.nanoTime();
/* 078 */ hashAgg_doAggregateWithoutKey_0();
/* 079 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[1]
/* aggTime */).add((System.nanoTime() - hashAgg_beforeAgg_0) / 1000000);
/* 080 */
/* 081 */ // output the result
/* 082 */
/* 083 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[0] /* numOutputRows */).add(1);
/* 084 */ hashAgg_mutableStateArray_0[0].reset();
/* 085 */
/* 086 */ hashAgg_mutableStateArray_0[0].zeroOutNullBytes();
/* 087 */
/* 088 */ if (hashAgg_bufIsNull_0) {
/* 089 */ hashAgg_mutableStateArray_0[0].setNullAt(0);
/* 090 */ } else {
/* 091 */ hashAgg_mutableStateArray_0[0].write(0, hashAgg_bufValue_0);
/* 092 */ }
/* 093 */ append((hashAgg_mutableStateArray_0[0].getRow()));
/* 094 */ }
/* 095 */ }
/* 096 */
/* 097 */ }
|
另一个
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
/* 001 */ public java.lang.Object generate(Object[] references) {
/* 002 */ return new SpecificUnsafeProjection(references);
/* 003 */ }
/* 004 */
/* 005 */ class SpecificUnsafeProjection extends org.apache.spark.sql.catalyst.expressions.UnsafeProjection {
/* 006 */
/* 007 */ private Object[] references;
/* 008 */ private org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter[] mutableStateArray_0 =
new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter[1];
/* 009 */
/* 010 */ public SpecificUnsafeProjection(Object[] references) {
/* 011 */ this.references = references;
/* 012 */ mutableStateArray_0[0] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(1, 0);
/* 013 */
/* 014 */ }
/* 015 */
/* 016 */ public void initialize(int partitionIndex) {
/* 017 */
/* 018 */ }
/* 019 */
/* 020 */ // Scala.Function1 need this
/* 021 */ public java.lang.Object apply(java.lang.Object row) {
/* 022 */ return apply((InternalRow) row);
/* 023 */ }
/* 024 */
/* 025 */ public UnsafeRow apply(InternalRow i) {
/* 026 */ mutableStateArray_0[0].reset();
/* 027 */
/* 028 */
/* 029 */ mutableStateArray_0[0].zeroOutNullBytes();
/* 030 */
/* 031 */ boolean isNull_0 = i.isNullAt(0);
/* 032 */ long value_0 = isNull_0 ?
/* 033 */ -1L : (i.getLong(0));
/* 034 */ if (isNull_0) {
/* 035 */ mutableStateArray_0[0].setNullAt(0);
/* 036 */ } else {
/* 037 */ mutableStateArray_0[0].write(0, value_0);
/* 038 */ }
/* 039 */ return (mutableStateArray_0[0].getRow());
/* 040 */ }
/* 041 */
/* 042 */
/* 043 */ }
|
final 聚合 的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
|
/* 001 */ public Object generate(Object[] references) {
/* 002 */ return new GeneratedIteratorForCodegenStage2(references);
/* 003 */ }
/* 004 */
/* 005 */ // codegenStageId=2
/* 006 */ final class GeneratedIteratorForCodegenStage2 extends org.apache.spark.sql.execution.BufferedRowIterator {
/* 007 */ private Object[] references;
/* 008 */ private scala.collection.Iterator[] inputs;
/* 009 */ private boolean hashAgg_initAgg_0;
/* 010 */ private boolean hashAgg_bufIsNull_0;
/* 011 */ private long hashAgg_bufValue_0;
/* 012 */ private scala.collection.Iterator inputadapter_input_0;
/* 013 */ private boolean hashAgg_hashAgg_isNull_4_0;
/* 014 */ private org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter[]
hashAgg_mutableStateArray_0 = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter[1];
/* 015 */
/* 016 */ public GeneratedIteratorForCodegenStage2(Object[] references) {
/* 017 */ this.references = references;
/* 018 */ }
/* 019 */
/* 020 */ public void init(int index, scala.collection.Iterator[] inputs) {
/* 021 */ partitionIndex = index;
/* 022 */ this.inputs = inputs;
/* 023 */
/* 024 */ inputadapter_input_0 = inputs[0];
/* 025 */ hashAgg_mutableStateArray_0[0] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(1, 32);
/* 026 */
/* 027 */ }
/* 028 */
/* 029 */ private void hashAgg_doAggregateWithoutKey_0() throws java.io.IOException {
/* 030 */ // initialize aggregation buffer
/* 031 */ hashAgg_bufIsNull_0 = true;
/* 032 */ hashAgg_bufValue_0 = -1L;
/* 033 */
/* 034 */ while ( inputadapter_input_0.hasNext()) {
/* 035 */ InternalRow inputadapter_row_0 = (InternalRow) inputadapter_input_0.next();
/* 036 */
/* 037 */ boolean inputadapter_isNull_0 = inputadapter_row_0.isNullAt(0);
/* 038 */ long inputadapter_value_0 = inputadapter_isNull_0 ?
/* 039 */ -1L : (inputadapter_row_0.getLong(0));
/* 040 */
/* 041 */ hashAgg_doConsume_0(inputadapter_row_0, inputadapter_value_0, inputadapter_isNull_0);
/* 042 */ // shouldStop check is eliminated
/* 043 */ }
/* 044 */
/* 045 */ }
/* 046 */
/* 047 */ private void hashAgg_doConsume_0(InternalRow inputadapter_row_0, long hashAgg_expr_0_0, boolean hashAgg_exprIsNull_0_0) throws java.io.IOException {
/* 048 */ // do aggregate
/* 049 */ // common sub-expressions
/* 050 */
/* 051 */ // evaluate aggregate functions and update aggregation buffers
/* 052 */
/* 053 */ hashAgg_hashAgg_isNull_4_0 = true;
/* 054 */ long hashAgg_value_4 = -1L;
/* 055 */
/* 056 */ if (!hashAgg_bufIsNull_0 && (hashAgg_hashAgg_isNull_4_0 ||
/* 057 */ hashAgg_bufValue_0 > hashAgg_value_4)) {
/* 058 */ hashAgg_hashAgg_isNull_4_0 = false;
/* 059 */ hashAgg_value_4 = hashAgg_bufValue_0;
/* 060 */ }
/* 061 */
/* 062 */ if (!hashAgg_exprIsNull_0_0 && (hashAgg_hashAgg_isNull_4_0 ||
/* 063 */ hashAgg_expr_0_0 > hashAgg_value_4)) {
/* 064 */ hashAgg_hashAgg_isNull_4_0 = false;
/* 065 */ hashAgg_value_4 = hashAgg_expr_0_0;
/* 066 */ }
/* 067 */
/* 068 */ hashAgg_bufIsNull_0 = hashAgg_hashAgg_isNull_4_0;
/* 069 */ hashAgg_bufValue_0 = hashAgg_value_4;
/* 070 */
/* 071 */ }
/* 072 */
/* 073 */ protected void processNext() throws java.io.IOException {
/* 074 */ while (!hashAgg_initAgg_0) {
/* 075 */ hashAgg_initAgg_0 = true;
/* 076 */
/* 077 */ long hashAgg_beforeAgg_0 = System.nanoTime();
/* 078 */ hashAgg_doAggregateWithoutKey_0();
/* 079 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[1] /* aggTime */).add((System.nanoTime() - hashAgg_beforeAgg_0) / 1000000);
/* 080 */
/* 081 */ // output the result
/* 082 */ UTF8String hashAgg_value_2;
/* 083 */ if (hashAgg_bufIsNull_0) {
/* 084 */ hashAgg_value_2 = UTF8String.fromString("NULL");
/* 085 */ } else {
/* 086 */ hashAgg_value_2 = UTF8String.fromString(String.valueOf(hashAgg_bufValue_0));
/* 087 */ }
/* 088 */
/* 089 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[0] /* numOutputRows */).add(1);
/* 090 */ hashAgg_mutableStateArray_0[0].reset();
/* 091 */
/* 092 */ hashAgg_mutableStateArray_0[0].write(0, hashAgg_value_2);
/* 093 */ append((hashAgg_mutableStateArray_0[0].getRow()));
/* 094 */ }
/* 095 */ }
/* 096 */
/* 097 */ }
|
final 之后的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
/* 001 */ public java.lang.Object generate(Object[] references) {
/* 002 */ return new SpecificSafeProjection(references);
/* 003 */ }
/* 004 */
/* 005 */ class SpecificSafeProjection extends org.apache.spark.sql.catalyst.expressions.codegen.BaseProjection {
/* 006 */
/* 007 */ private Object[] references;
/* 008 */ private InternalRow mutableRow;
/* 009 */
/* 010 */
/* 011 */ public SpecificSafeProjection(Object[] references) {
/* 012 */ this.references = references;
/* 013 */ mutableRow = (InternalRow) references[references.length - 1];
/* 014 */
/* 015 */ }
/* 016 */
/* 017 */ public void initialize(int partitionIndex) {
/* 018 */
/* 019 */ }
/* 020 */
/* 021 */ public java.lang.Object apply(java.lang.Object _i) {
/* 022 */ InternalRow i = (InternalRow) _i;
/* 023 */ Object[] values_0 = new Object[1];
/* 024 */
/* 025 */ UTF8String value_2 = i.getUTF8String(0);
/* 026 */ boolean isNull_1 = true;
/* 027 */ java.lang.String value_1 = null;
/* 028 */ isNull_1 = false;
/* 029 */ if (!isNull_1) {
/* 030 */
/* 031 */ Object funcResult_0 = null;
/* 032 */ funcResult_0 = value_2.toString();
/* 033 */ value_1 = (java.lang.String) funcResult_0;
/* 034 */
/* 035 */ }
/* 036 */ if (isNull_1) {
/* 037 */ values_0[0] = null;
/* 038 */ } else {
/* 039 */ values_0[0] = value_1;
/* 040 */ }
/* 041 */
/* 042 */ final org.apache.spark.sql.Row value_0 =
new org.apache.spark.sql.catalyst.expressions.GenericRowWithSchema(values_0,
((org.apache.spark.sql.types.StructType) references[0] /* schema */));
/* 043 */ if (false) {
/* 044 */ mutableRow.setNullAt(0);
/* 045 */ } else {
/* 046 */
/* 047 */ mutableRow.update(0, value_0);
/* 048 */ }
/* 049 */
/* 050 */ return mutableRow;
/* 051 */ }
/* 052 */
/* 053 */
/* 054 */ }
|
参考