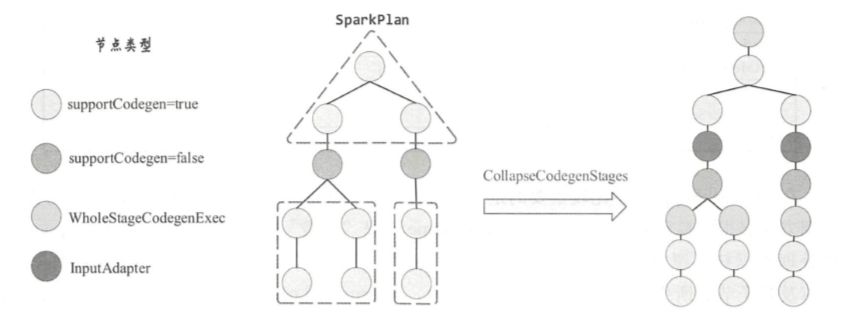
基本原理
全阶段代码生成,即WSCG。它指的是基于同一 Stage 内操作符之间的调用关系,把多个 RDD 的 compute 函数捏合成一个,生成一份“手写代码”
然后把这一个函数一次性地作用在输入数据上,真正把所有计算融合为一个统一的函数
全阶段代码生成具有以下的优势:
- 消除虚函数调度。
- 将中间数据从内存移动到 CPU 寄存器。
- 利用现代 CPU 功能循环展开和使用 SIMD。通过向量化技术,引擎将加快对复杂操作代码生成运行的速度。
Catalyst全阶段代码生成的入口是CollapseCodegenStages规则,它的注入是在代码执行前的preparations阶段。
1
2
3
4
5
6
7
8
9
|
def apply(plan: SparkPlan): SparkPlan = {
if (conf.wholeStageEnabled && CodegenObjectFactoryMode.withName(conf.codegenFactoryMode)
!= CodegenObjectFactoryMode.NO_CODEGEN) {
insertWholeStageCodegen(plan)
} else {
plan
}
}
}
|
如果开启了下面这个参数,才会生成代码
1
|
spark.sql.codegen.wholeStage
|
预处理部分
插入WholeStageCodegenExec算子需要满足以下条件:
- 算子的输出个数为1且数据类型为ObjectType,表明其不是unsafe row,跳过,迭代判断其孩子节点。
- plan为LocalTableScanExec的不进行处理。
- plan为CommandResultExec的不进行处理。
- plan为CodegenSupport的还需判断其所有表达式是否都支持Codegen, 当前plan和其孩子plan的schema的字段个数是否超过了conf.wholeStageMaxNumFields(默认100)。
- 另外需要注意的是whole-stage-codegen是基于row的,如果plan支持columnar, 则不能同时支持全阶段代码生成。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
private def insertWholeStageCodegen(plan: SparkPlan): SparkPlan = {
plan match {
// For operators that will output domain object, do not insert WholeStageCodegen for it as
// domain object can not be written into unsafe row.
case plan if plan.output.length == 1 && plan.output.head.dataType.isInstanceOf[ObjectType] =>
plan.withNewChildren(plan.children.map(insertWholeStageCodegen))
case plan: LocalTableScanExec =>
// Do not make LogicalTableScanExec the root of WholeStageCodegen
// to support the fast driver-local collect/take paths.
plan
case plan: CommandResultExec =>
// Do not make CommandResultExec the root of WholeStageCodegen
// to support the fast driver-local collect/take paths.
plan
case plan: CodegenSupport if supportCodegen(plan) =>
// The whole-stage-codegen framework is row-based. If a plan supports columnar execution,
// it can't support whole-stage-codegen at the same time.
assert(!plan.supportsColumnar)
WholeStageCodegenExec(insertInputAdapter(plan))(codegenStageCounter.incrementAndGet())
case other =>
other.withNewChildren(other.children.map(insertWholeStageCodegen))
}
}
|
对于不支持的,或者 SortMergeJoinExec、ShuffledHashJoinExec 会插入 InputAdapter
InputAdapter 作用
- 他们都可以看作一个codegen的分割点,可将整个物理计划拆分成多个代码段
- 而 InputAdapter节点可以看作是对应 WholeStageCodegenExec所包含子树的叶 子节点,起到 InternalRow的数据输入作用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
private def insertInputAdapter(plan: SparkPlan): SparkPlan = {
plan match {
case p if !supportCodegen(p) =>
// collapse them recursively
InputAdapter(insertWholeStageCodegen(p))
case j: SortMergeJoinExec =>
// The children of SortMergeJoin should do codegen separately.
j.withNewChildren(j.children.map(
child => InputAdapter(insertWholeStageCodegen(child))))
case j: ShuffledHashJoinExec =>
// The children of ShuffledHashJoin should do codegen separately.
j.withNewChildren(j.children.map(
child => InputAdapter(insertWholeStageCodegen(child))))
case p => p.withNewChildren(p.children.map(insertInputAdapter))
}
}
|
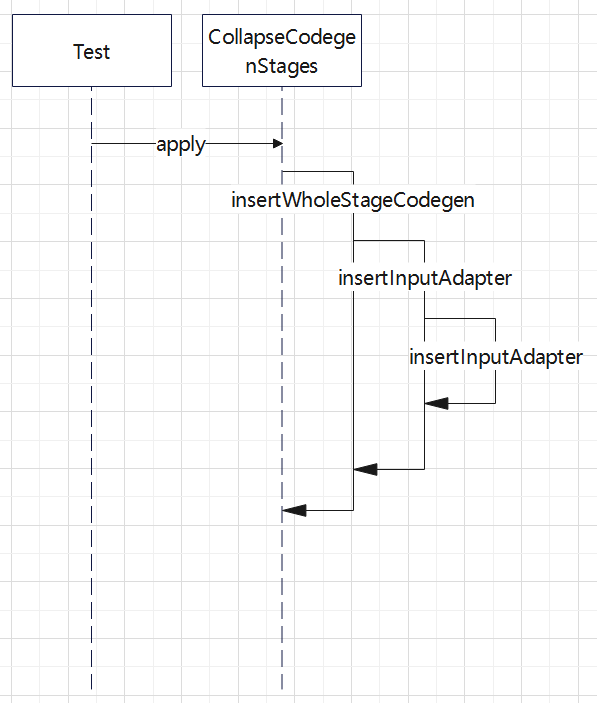
模拟程序
用来 模拟 code-gen 的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
test("mock code-gen") {
import org.apache.spark.sql.catalyst.expressions.{
And, AttributeReference, GreaterThan, LessThan, Literal}
import org.apache.spark.sql.execution.{CollapseCodegenStages, FilterExec, RangeExec}
import org.apache.spark.sql.types.LongType
val ref = AttributeReference("id", LongType)()
val and = And(
GreaterThan(ref, new Literal(0L, LongType)),
LessThan(ref, new Literal(10L, LongType))
)
val range = RangeExec(
new org.apache.spark.sql.catalyst.plans.logical.Range(0, 10, 1, None)
)
val filter = FilterExec(and, range)
val c = CollapseCodegenStages()
val p = c.apply(filter)
println(p)
}
|
打印结果:
1
2
|
*(1) !Filter ((id#0L > 0) AND (id#0L < 10))
+- *(1) Range (0, 10, step=1, splits=16)
|
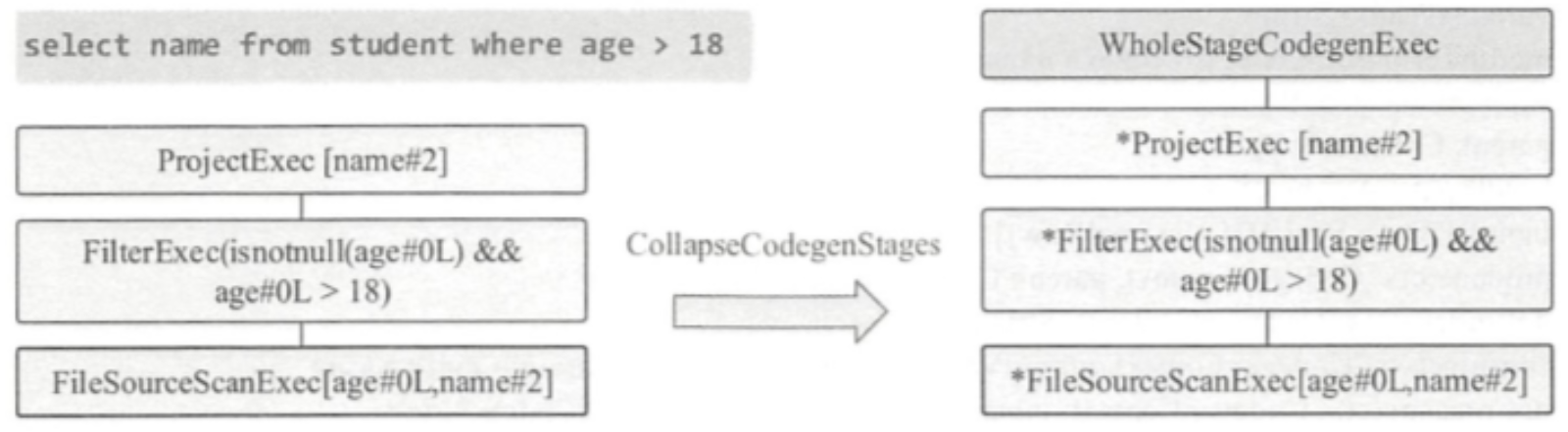
递归的从根节点一直遍历到子节点,如果有不合适的则插入 InputAdapter
代码生成骨架部分
各个算子的 doProduce(),只是简单的继续调用其子类的 produce()
1
2
3
|
protected override def doProduce(ctx: CodegenContext): String = {
child.asInstanceOf[CodegenSupport].produce(ctx, this)
}
|
CodegenSupport 的主要函数

produce()是在父接口 CodegenSupport 中定义的,它会继续调用子节点的 doProduce
于是一层层的递归调用下去,直到子节点,或者 shuffle 边界
1
2
3
4
5
6
7
8
|
final def produce(ctx: CodegenContext, parent: CodegenSupport): String = executeQuery {
this.parent = parent
ctx.freshNamePrefix = variablePrefix
s"""
|${ctx.registerComment(s"PRODUCE: ${this.simpleString(conf.maxToStringFields)}")}
|${doProduce(ctx)}
""".stripMargin
}
|
CodegenSupport#consume的逻辑:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
final def consume(ctx: CodegenContext, outputVars: Seq[ExprCode], row: String = null): String = {
val inputVarsCandidate =
if (outputVars != null) {
assert(outputVars.length == output.length)
// outputVars will be used to generate the code for UnsafeRow, so we should copy them
outputVars.map(_.copy())
} else {
assert(row != null, "outputVars and row cannot both be null.")
ctx.currentVars = null
ctx.INPUT_ROW = row
output.zipWithIndex.map { case (attr, i) =>
BoundReference(i, attr.dataType, attr.nullable).genCode(ctx)
}
}
val inputVars = inputVarsCandidate match {
case stream: Stream[ExprCode] => stream.force
case other => other
}
val rowVar = prepareRowVar(ctx, row, outputVars)
// Set up the `currentVars` in the codegen context, as we generate the code of `inputVars`
// before calling `parent.doConsume`. We can't set up `INPUT_ROW`, because parent needs to
// generate code of `rowVar` manually.
ctx.currentVars = inputVars
ctx.INPUT_ROW = null
ctx.freshNamePrefix = parent.variablePrefix
val evaluated = evaluateRequiredVariables(output, inputVars, parent.usedInputs)
// Under certain conditions, we can put the logic to consume the rows of this operator into
// another function. So we can prevent a generated function too long to be optimized by JIT.
// The conditions:
// 1. The config "spark.sql.codegen.splitConsumeFuncByOperator" is enabled.
// 2. `inputVars` are all materialized. That is guaranteed to be true if the parent plan uses
// all variables in output (see `requireAllOutput`).
// 3. The number of output variables must less than maximum number of parameters in Java method
// declaration.
val confEnabled = conf.wholeStageSplitConsumeFuncByOperator
val requireAllOutput = output.forall(parent.usedInputs.contains(_))
val paramLength = CodeGenerator.calculateParamLength(output) + (if (row != null) 1 else 0)
val consumeFunc = if (confEnabled && requireAllOutput
&& CodeGenerator.isValidParamLength(paramLength)) {
constructDoConsumeFunction(ctx, inputVars, row)
} else {
parent.doConsume(ctx, inputVars, rowVar)
}
s"""
|${ctx.registerComment(s"CONSUME: ${parent.simpleString(conf.maxToStringFields)}")}
|$evaluated
|$consumeFunc
""".stripMargin
}
|
这里会继续调用父类的doConsume,完成进一步代码填充
需要注意的是,这里判断了代码是否太大,如果太大,则将调用逻辑封装为一个函数,然后直接调用这个函数
WholeStageCodegenExec 的 doExecute 流程
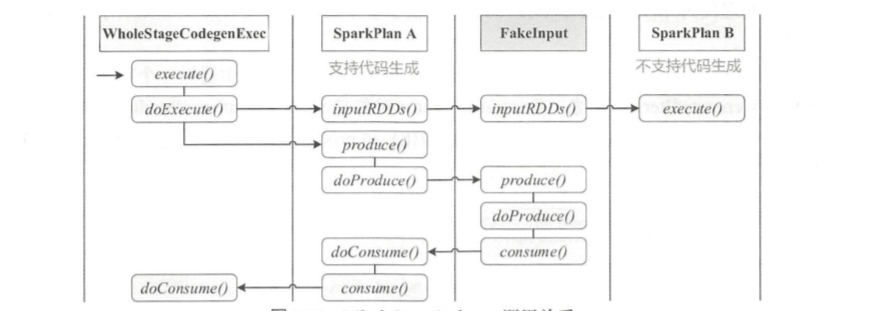
代码生成可以看作是两个方向相反的递归过程:
- 代码的整体框架由 produce/doProduce 方法负责,父节点调用子节点
- 代码具体处理逻辑由 consume/doConsume 方法负责,由子节点调用父节点
- 整个物理算子树的执行过程被InputAdapter分隔开
详细分析
简单查询执行过程
下面这个SQL
1
|
SELECT id FROM people WHERE id > 0 AND id < 100
|
InputRDDCodegen#doProduce主要逻辑:
1
2
3
4
5
6
7
8
|
s"""
| while ($limitNotReachedCond $input.hasNext()) {
| InternalRow $row = (InternalRow) $input.next();
| ${updateNumOutputRowsMetrics}
| ${consume(ctx, outputVars, if (createUnsafeProjection) null else row).trim}
| ${shouldStopCheckCode}
| }
""".stripMargi
|
FilterExec#doCosume()的主要生成逻辑:
1
2
3
4
5
6
7
|
s"""
|do {
| $predicateCode
| $numOutput.add(1);
| ${consume(ctx, resultVars)}
|} while(false);
""".stripMargin
|
生成的核心代码片段:
可读性不好,但是也大概能看出来,是计算 id > 0 AND id < 100
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
boolean rdd_isNull_1 = rdd_row_0.isNullAt(1);
long rdd_value_1 = rdd_isNull_1 ?
-1L : (rdd_row_0.getLong(1));
boolean filter_value_2 = !rdd_isNull_1;
if (!filter_value_2) continue;
boolean filter_value_3 = false;
filter_value_3 = rdd_value_1 > 0L;
if (!filter_value_3) continue;
boolean filter_value_8 = !rdd_isNull_1;
if (!filter_value_8) continue;
boolean filter_value_9 = false;
filter_value_9 = rdd_value_1 < 100L;
if (!filter_value_9) continue;
|
ProjectExec#doConsume()主要逻辑:
1
2
3
4
5
6
7
|
s"""
|// common sub-expressions
|${evaluateVariables(localValInputs)}
|$subExprsCode
|${evaluateRequiredVariables(output, resultVars, AttributeSet(nonDeterministicAttrs))}
|${consume(ctx, resultVars)}
""".stripMargin
|
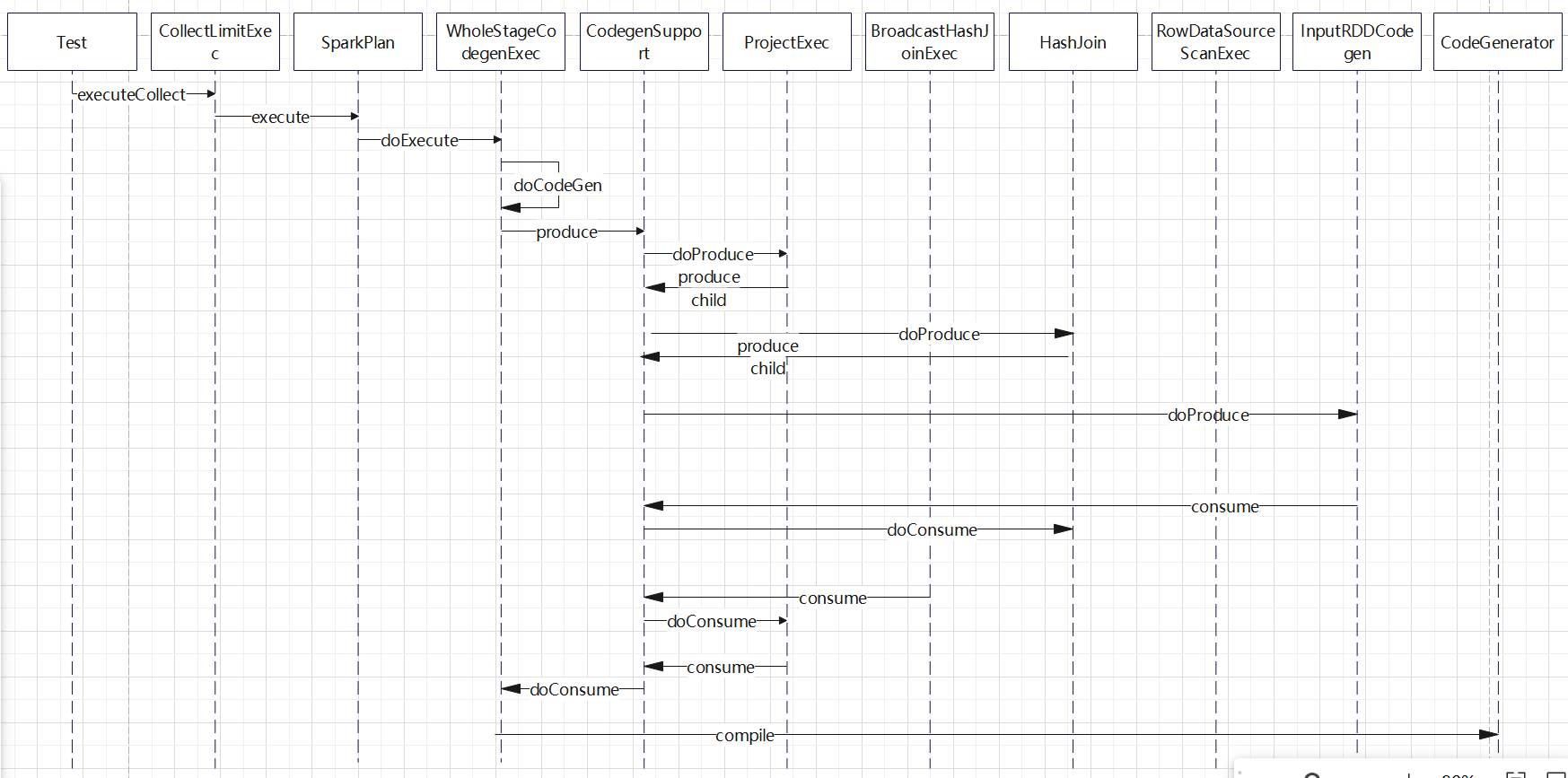
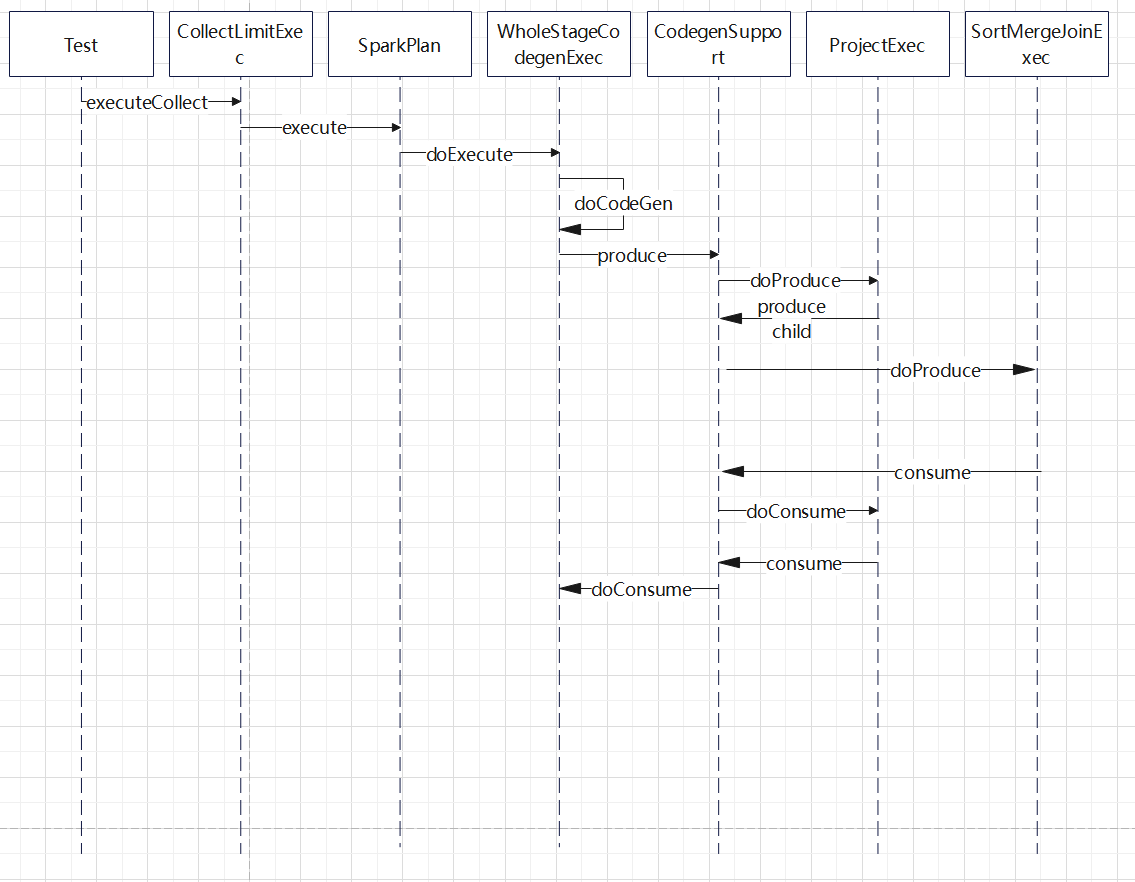
生成的 时序图:
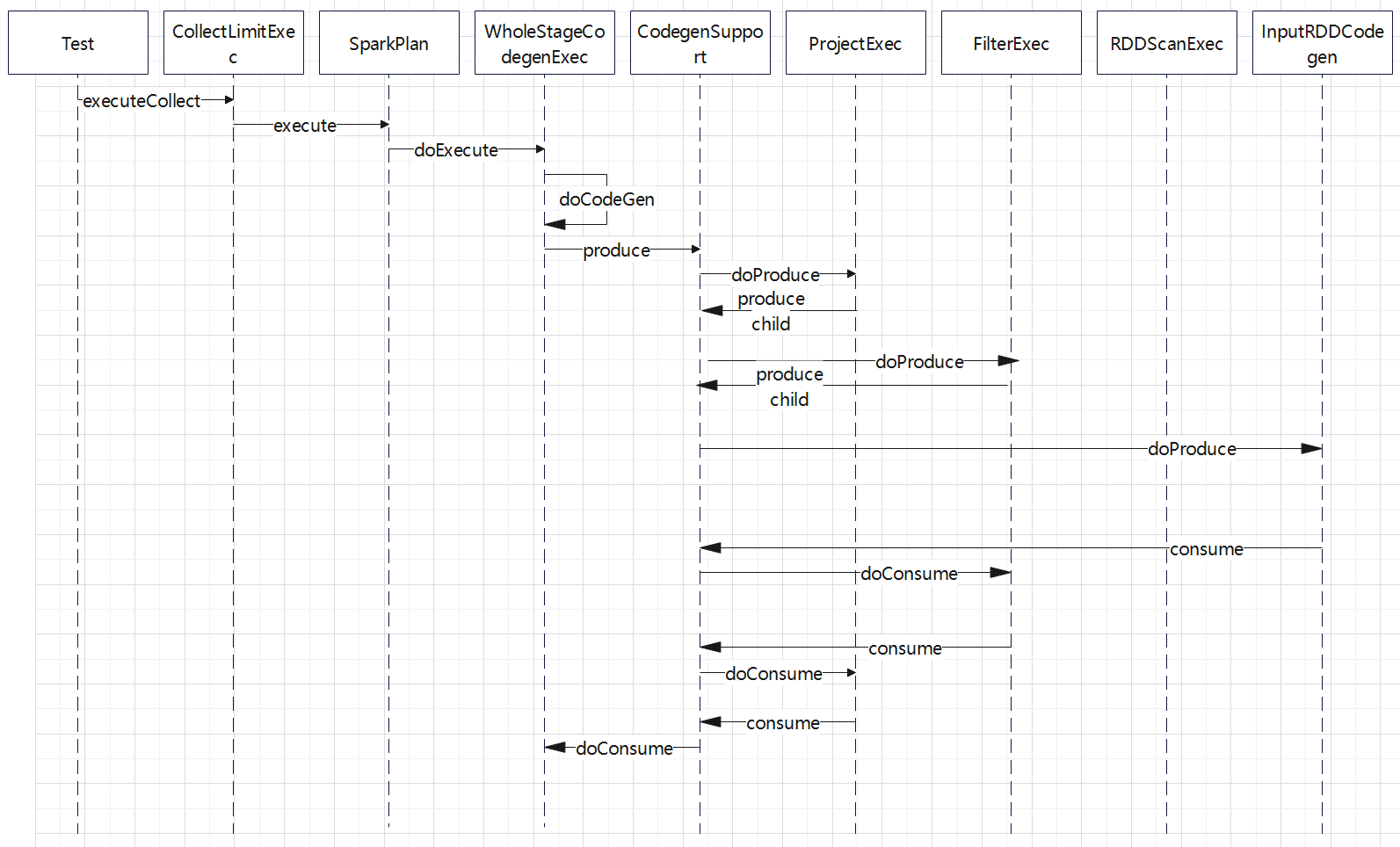
生成过程:
- 从 WholeStageCodegenExec#doExecute出发,在这里调用 doCodeGen 开始生成代码
- 调用 CodegenSupport#produce(),这里只是产生一些metrics的逻辑,然后调用doProduce
- 每个具体算子中 doProduce 只是简单的调用子节点的 produce(),于是由回到CodegenSupport,继续递归往下调用
- 到叶子节点 RDDScanExec时候,其父类 InputRDDCodegen 开始生成骨架代码,然后调用CodegenSupport#consume
- consume中调用每个具体算子的 doConsume,也是继续递归调用到 FilterExec的 doConsume,ProjectExec#doConsume
- 叶子节点RDD 算子只是一个 while循环,读取读取数据,然后调用子节点 Filter,Project等来处理这些数据
- 最后调用到最上层节点 WholeStageCodegenExec#doConsume 获取结果
- 整个过程是从 WholeStageCodegenExec 开始递归往下调用的,一直到叶子节点(读取数据的节点)
- 在读取数据的节点生成骨架代码,然后又递归调用父节点,填充骨架代码
另一个视角
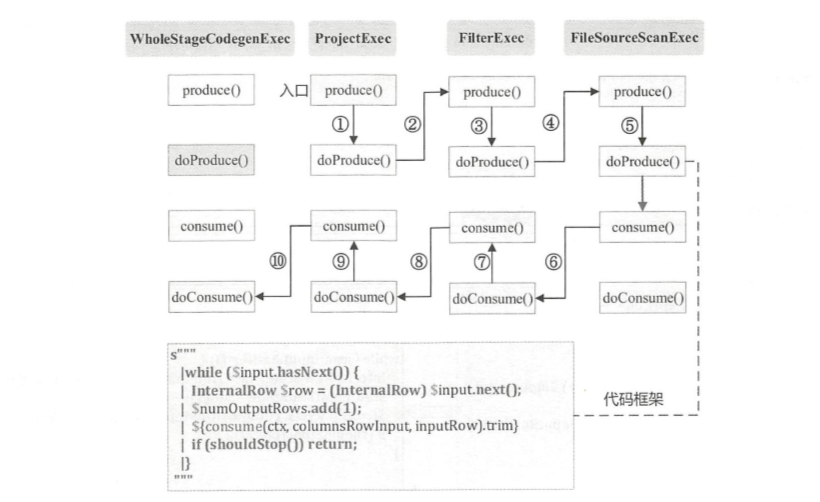
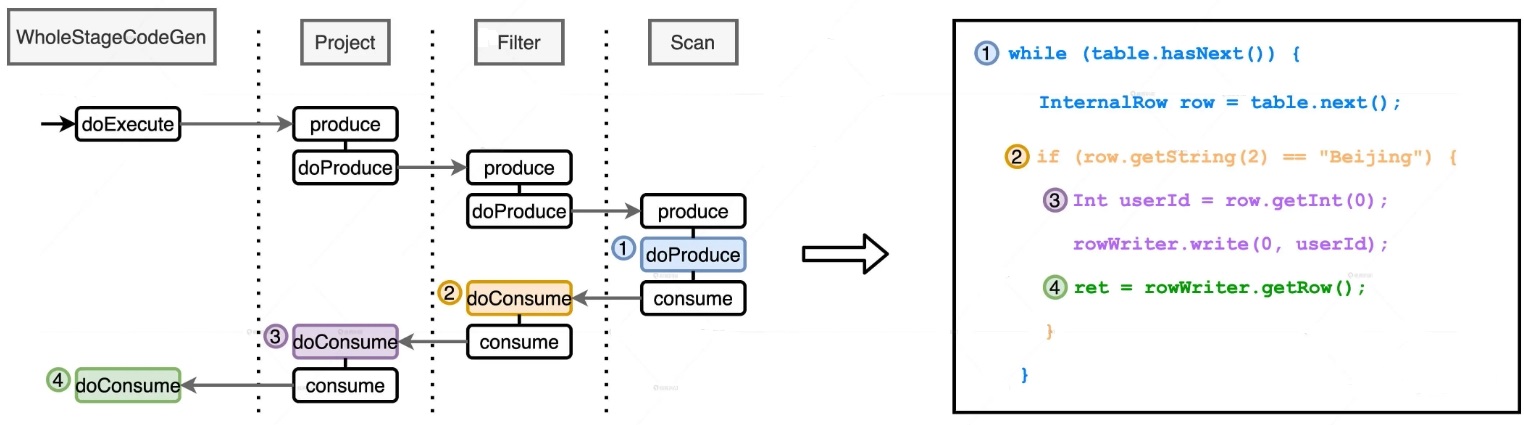
ProjectExec + FilterExec + ScanRDDExec 生成的代码片段:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
while ( rdd_input_0.hasNext()) {
InternalRow rdd_row_0 = (InternalRow) rdd_input_0.next();
((org.apache.spark.sql.execution.metric.SQLMetric) references[0] /* numOutputRows */).add(1);
do {
boolean rdd_isNull_1 = rdd_row_0.isNullAt(1);
long rdd_value_1 = rdd_isNull_1 ?
-1L : (rdd_row_0.getLong(1));
boolean filter_value_2 = !rdd_isNull_1;
if (!filter_value_2) continue;
boolean filter_value_3 = false;
filter_value_3 = rdd_value_1 > 0L;
if (!filter_value_3) continue;
boolean filter_value_8 = !rdd_isNull_1;
if (!filter_value_8) continue;
boolean filter_value_9 = false;
filter_value_9 = rdd_value_1 < 100L;
if (!filter_value_9) continue;
((org.apache.spark.sql.execution.metric.SQLMetric) references[1] /* numOutputRows */).add(1);
// common sub-expressions
UTF8String project_value_0;
if (false) {
project_value_0 = UTF8String.fromString("NULL");
} else {
project_value_0 = UTF8String.fromString(String.valueOf(rdd_value_1));
}
rdd_mutableStateArray_0[2].reset();
rdd_mutableStateArray_0[2].write(0, project_value_0);
append((rdd_mutableStateArray_0[2].getRow()));
} while(false);
if (shouldStop()) return;
}
|
JOIN
Broadcast Hash Join
boradcast-hash-join 的待生成 code-gen 时的物理计划
- 到了 BroadcastHashJoinExec 时候分为左右两个节点
- 其中右边节点是 RowDataSourceScanExec,在下面是 JDBCRDD
- 左边节点是 InputAdapter,相当于对生成代码做了分割
- 这部分跟非code-gen 的 bhj 类似,使用了 BroadcastQueryStageExec 再委托BroadcastExchangeExec 获取广播数据
- 广播exchange 下面又是 WholeStageCodegenExec,下面是又是代码生成部分了
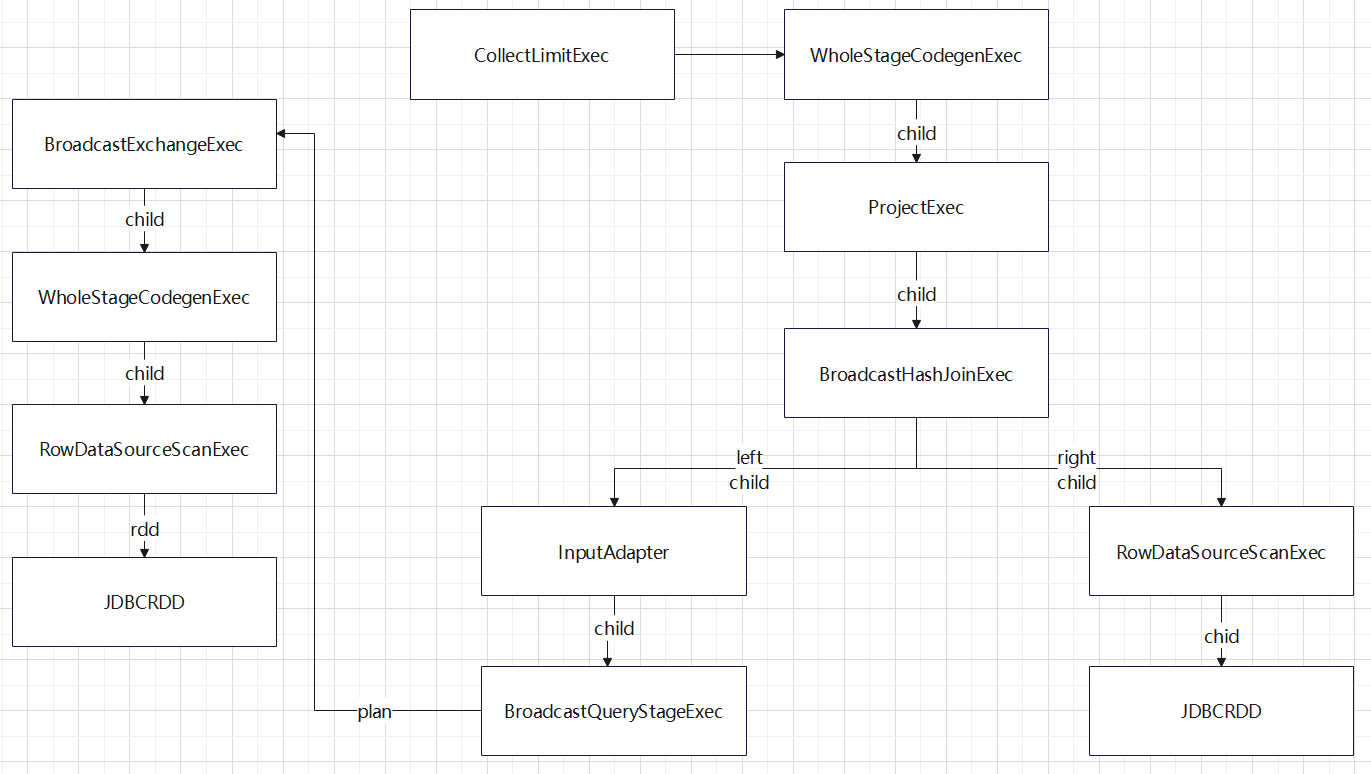
1
2
3
4
5
6
7
8
|
在 HashJoin 中先建立好 build 表,然后将这个 build 放到 拼接代码中
for(遍历 流表的 RDD) {
执行 bhj,探测 build 表
if (找到了匹配值) {
做投影,再输出结果
}
}
|
获取 build 表的时序图,这里跟上面的依赖父子依赖关系展示的类似
读取数据也是通过 代码生成的
然后通过广播的方式发送出去,这里还使用了线程池,等待超时等机制
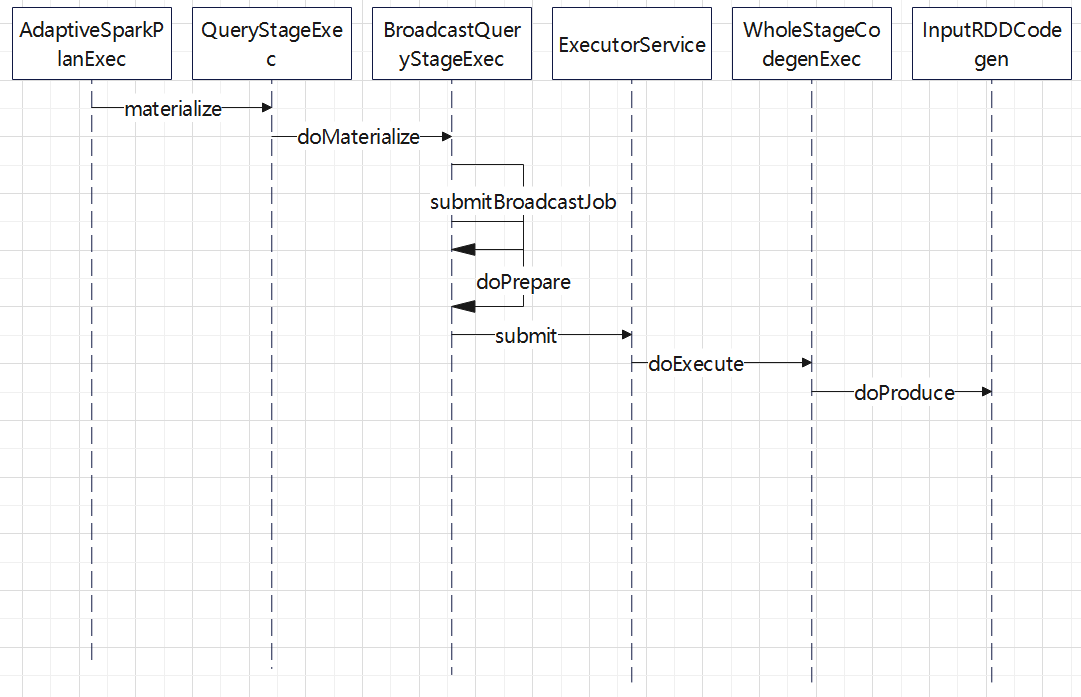
bhj 的总体流程
- 跟普通的查询的时序图差不多
-produce()和consume()也是委托给 CodegenSupport 来调用的
- 先读取数据,也就是InputRDDCode部分,生成读取 JDBCRDD的代码
- 然后调用 bhj,执行join逻辑,在 join 中拿到事先构建好的 build 表去判断
- 如果有匹配的则输出
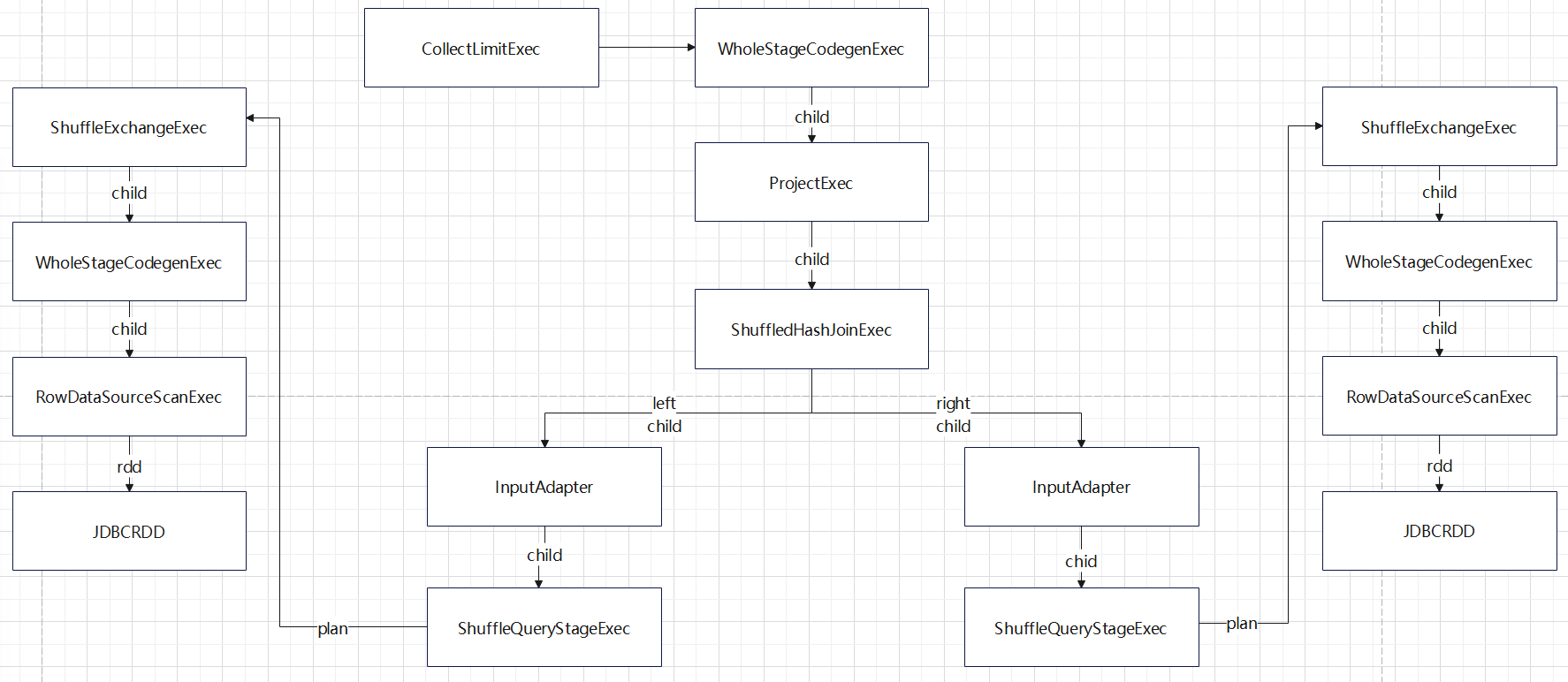
Shuffle Hash Join
shuffle-hash-join 的待生成 code-gen 时的物理计划
总体来说,跟 bhj 类似,只是左右两个子节点都增加了 InputAdapter,作为code-gen 的分割
这两个子节点都是通过广播获取的
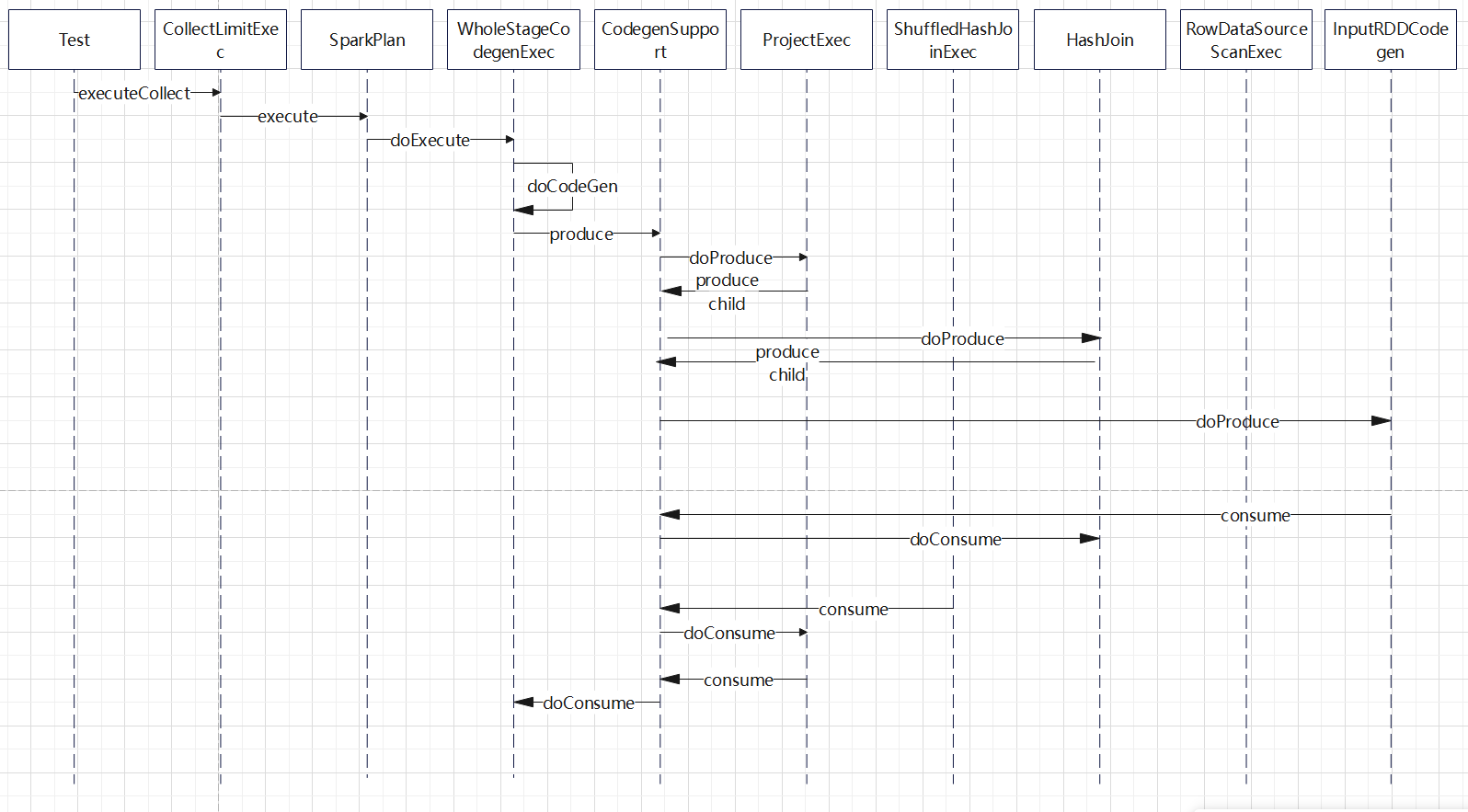
时序图
- 总体来说,跟 bhj 非常类似
- 除了把 执行的 join exec 换成了 ShuffledHashJoinExec,其他调用过程都是一样
- 执行 join 的code-gen是父类 HashJoin 完成的
Shuffle Sort Merge Join
待生成 code-gen 时的物理计划
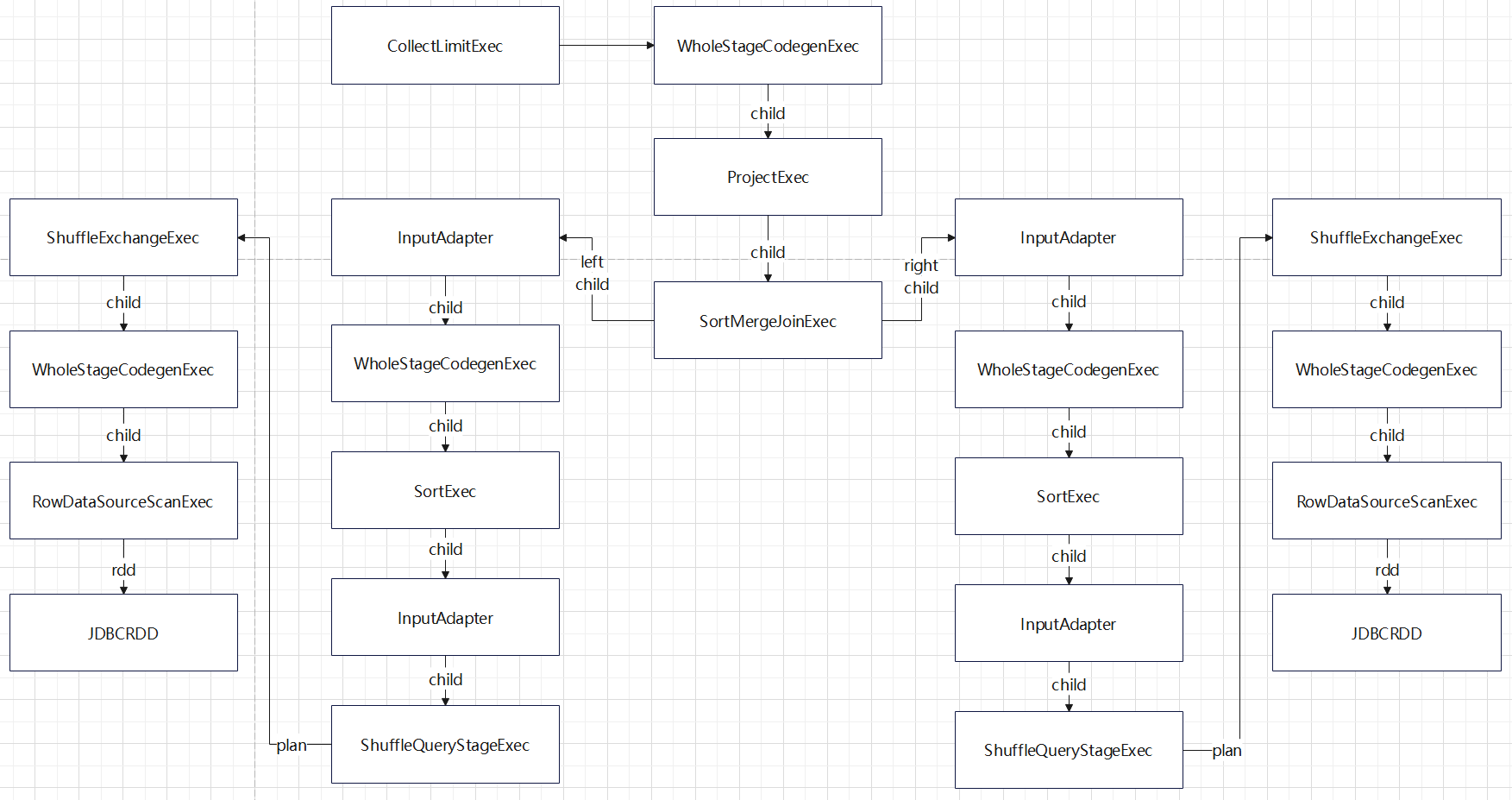 上图中
上图中
- 总体比 bhj,shj 要复杂很多
- sort-merge-join 左右两边都是 InputAdapter,对code-gen做了分割
- 这之后又调用了 SortExec,所以再次增加了 InputAdapter 做了分割
- 之后就是 shuffle逻辑,跟 shj 差不多了
- 这里一共会生成 5个代码片段
- sort-merge-join 一个,左边的 sort,右边的 sort,以及左右的读取数据
执行的时序图如下:
- 相比 bhj,shj 要简单不少
- SortMergeJoinExec 左右节点都是 InputAdapter 类型的,所以到它这里就结束了
SortMergeJoinExec 的 codegenInner 的生成代码逻辑:
1
2
3
4
5
6
7
8
9
10
11
12
|
s"""
|while ($findNextJoinRows) {
| $beforeLoop
| while ($matchIterator.hasNext()) {
| InternalRow $bufferedRow = (InternalRow) $matchIterator.next();
| $conditionCheck
| $outputRow
| }
| if (shouldStop()) return;
|}
|$eagerCleanup
""".stripMargin
|
SortMergeJoinExec + ProjectExec 生成 的代码片段:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
while (smj_findNextJoinRows_0(smj_streamedInput_0, smj_bufferedInput_0)) {
boolean smj_isNull_2 = false;
int smj_value_4 = -1;
boolean smj_isNull_3 = false;
UTF8String smj_value_5 = null;
smj_isNull_2 = smj_streamedRow_0.isNullAt(0);
smj_value_4 = smj_isNull_2 ? -1 : (smj_streamedRow_0.getInt(0));
smj_isNull_3 = smj_streamedRow_0.isNullAt(1);
smj_value_5 = smj_isNull_3 ? null : (smj_streamedRow_0.getUTF8String(1));
scala.collection.Iterator<UnsafeRow> smj_iterator_0 = smj_matches_0.generateIterator();
while (smj_iterator_0.hasNext()) {
InternalRow smj_bufferedRow_1 = (InternalRow) smj_iterator_0.next();
((org.apache.spark.sql.execution.metric.SQLMetric) references[0] /* numOutputRows */).add(1);
// common sub-expressions
UTF8String project_value_0;
if (smj_isNull_2) {
project_value_0 = UTF8String.fromString("NULL");
} else {
project_value_0 = UTF8String.fromString(String.valueOf(smj_value_4));
}
UTF8String project_value_2;
if (smj_isNull_3) {
project_value_2 = UTF8String.fromString("NULL");
} else {
project_value_2 = smj_value_5;
}
boolean smj_isNull_4 = smj_bufferedRow_1.isNullAt(0);
int smj_value_6 = smj_isNull_4 ? -1 : (smj_bufferedRow_1.getInt(0));
UTF8String project_value_4;
if (smj_isNull_4) {
project_value_4 = UTF8String.fromString("NULL");
} else {
project_value_4 = UTF8String.fromString(String.valueOf(smj_value_6));
}
boolean smj_isNull_5 = smj_bufferedRow_1.isNullAt(1);
UTF8String smj_value_7 = smj_isNull_5 ? null : (smj_bufferedRow_1.getUTF8String(1));
UTF8String project_value_6;
if (smj_isNull_5) {
project_value_6 = UTF8String.fromString("NULL");
} else {
project_value_6 = smj_value_7;
}
smj_mutableStateArray_0[1].reset();
smj_mutableStateArray_0[1].write(0, project_value_0);
smj_mutableStateArray_0[1].write(1, project_value_2);
smj_mutableStateArray_0[1].write(2, project_value_4);
smj_mutableStateArray_0[1].write(3, project_value_6);
append((smj_mutableStateArray_0[1].getRow()).copy());
} // end inner while`
if (shouldStop()) return;
} // end outer while
|
BroadcastNestedLoopJoin
跟普的 doExecute 很类似,广播然后用 nested loop 实现的
1
2
3
4
5
6
7
8
9
10
11
12
|
override def doConsume(ctx: CodegenContext, input: Seq[ExprCode], row: ExprCode): String = {
(joinType, buildSide) match {
case (_: InnerLike, _) => codegenInner(ctx, input)
case (LeftOuter, BuildRight) | (RightOuter, BuildLeft) => codegenOuter(ctx, input)
case (LeftSemi, BuildRight) => codegenLeftExistence(ctx, input, exists = true)
case (LeftAnti, BuildRight) => codegenLeftExistence(ctx, input, exists = false)
case _ =>
throw new IllegalArgumentException(
s"BroadcastNestedLoopJoin code-gen should not take neither $joinType as the JoinType " +
s"nor $buildSide as the BuildSide")
}
}
|
inner join 的code-gen 函数如下:就是 一个 for 里面再不断 probe hash-table
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
private def codegenInner(ctx: CodegenContext, input: Seq[ExprCode]): String = {
val (_, buildRowArrayTerm) = prepareBroadcast(ctx)
val (buildRow, checkCondition, buildVars) = getJoinCondition(ctx, input, streamed, broadcast)
val resultVars = buildSide match {
case BuildLeft => buildVars ++ input
case BuildRight => input ++ buildVars
}
val arrayIndex = ctx.freshName("arrayIndex")
val numOutput = metricTerm(ctx, "numOutputRows")
s"""
|for (int $arrayIndex = 0; $arrayIndex < $buildRowArrayTerm.length; $arrayIndex++) {
| UnsafeRow $buildRow = (UnsafeRow) $buildRowArrayTerm[$arrayIndex];
| $checkCondition {
| $numOutput.add(1);
| ${consume(ctx, resultVars)}
| }
|}
""".stripMargin
}
|
CartesianProduct 没有 code-gen
参考