Spark 注册数据源
例子
在 resouces 目录下新建
- META-INF 目录
- 再创建 services 目录
- 创建 org.apache.spark.sql.sources.DataSourceRegister
- 里面填入需要注册的实现类
比如
|
|
一个自定义的数据源实现类
|
|
启动
|
|
解析
DataSourceRegister的继承体系
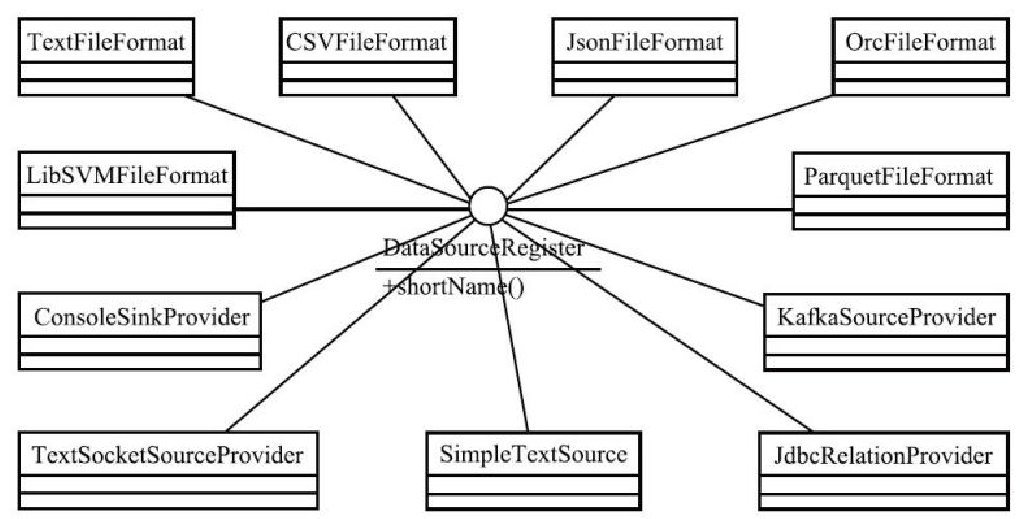
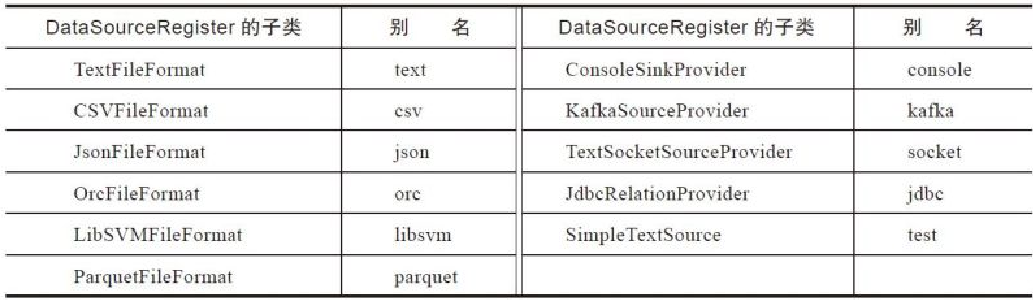
DataSourceRegister的子类及其别名
实现过程
- 在 org.apache.spark.sql.execution.datasources.DataSource 中查找的
- 包含了很多默认的实现
- 先查找默认的,再查找 xx.DefualtProvider,最后查找文件中定义的类
|
|
spark.read实现 在SparkSession中是这样的
|
|
所以是委托给 DataFrameReader
- 做 format
- option
- load,加载实现类
load 的实现,就是用 DataSource 去查找的
|
|
DataFrame 的内部表示
|
|
这个Dataset 包含了
- 各种 sql 的算子,如 join,agg,select,group 等
- toDF,schema,filter,writeTo 等等
df.write 的实现
|
|
save实现
- 判断是 V1 数据源,还是 V2的
- 根据 save 的模式,以及是否 truncate
- 选择是删除表再新建插入,还是直接插入
在save 中
|
|
还会用的 DataSourceV2ScanRelation DataSourceV2Relation
CheckpointRDDPartition抽象类
- LocalCheckpointRDD
- ReliableCheckpointRDD
ReliableCheckpointRDD
- 包含了 读、写 checkpoint
- 写checkpoint 拿到分区信息,然后写每个分区的 checkpoint
- 这个写的动作会交给 SparkSession#runJob()执行
- 之后 DAGScheduler 会提交这个 job,调度到 StandaloneSchedulerBackend,最后发布到 executor中执行
SparkSession的属性如下
- sparkContext:即SparkContext。
- sharedState:在多个SparkSession之间共享的状态(包括SparkContext、缓存的数据、监听器及与外部系统交互的字典信息)。
- sessionState:SparkSession的状态(SessionState)。SessionState中保存着SparkSession指定的状态信息。
- sqlContext:即SQLContext。SQLContext是Spark SQL的上下文信息。
- conf:类型为RuntimeConfig,是Spark运行时的配置接口类
一个完整的例子
一个 world count 例子
|
|