YARN原理分析
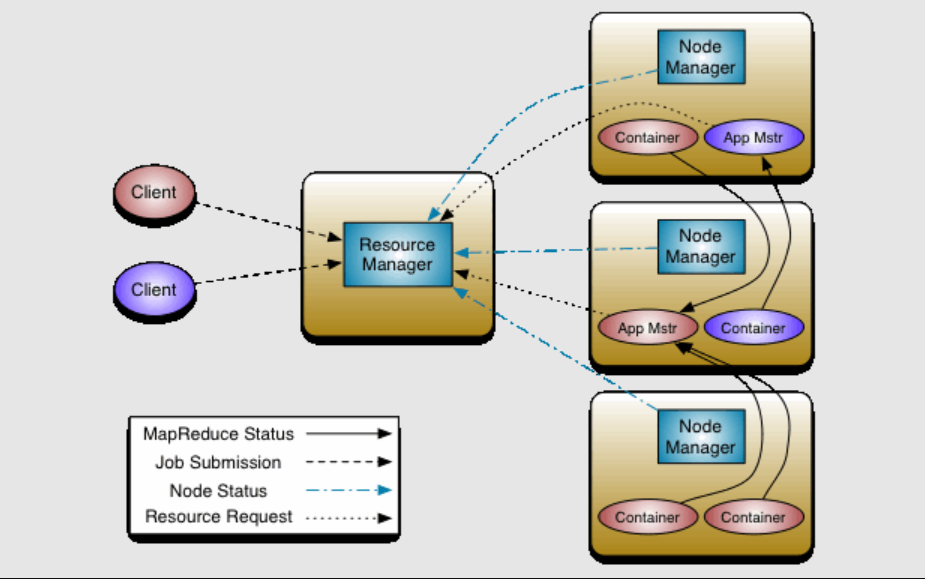
整体架构
整体架构
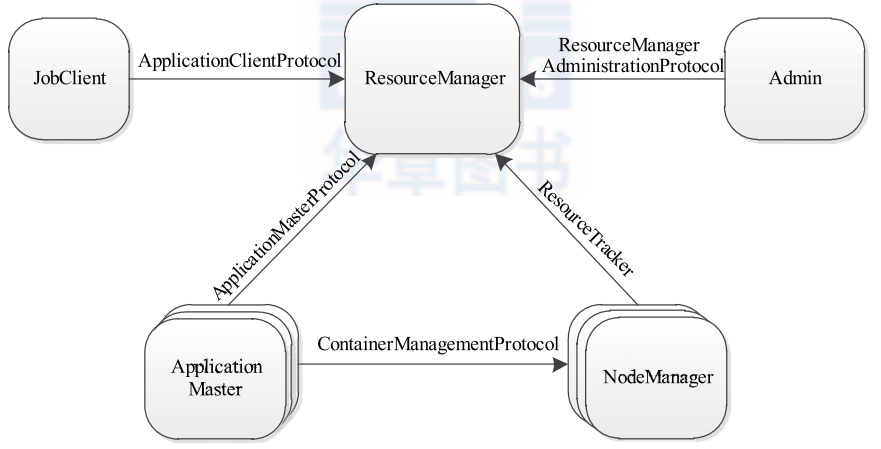
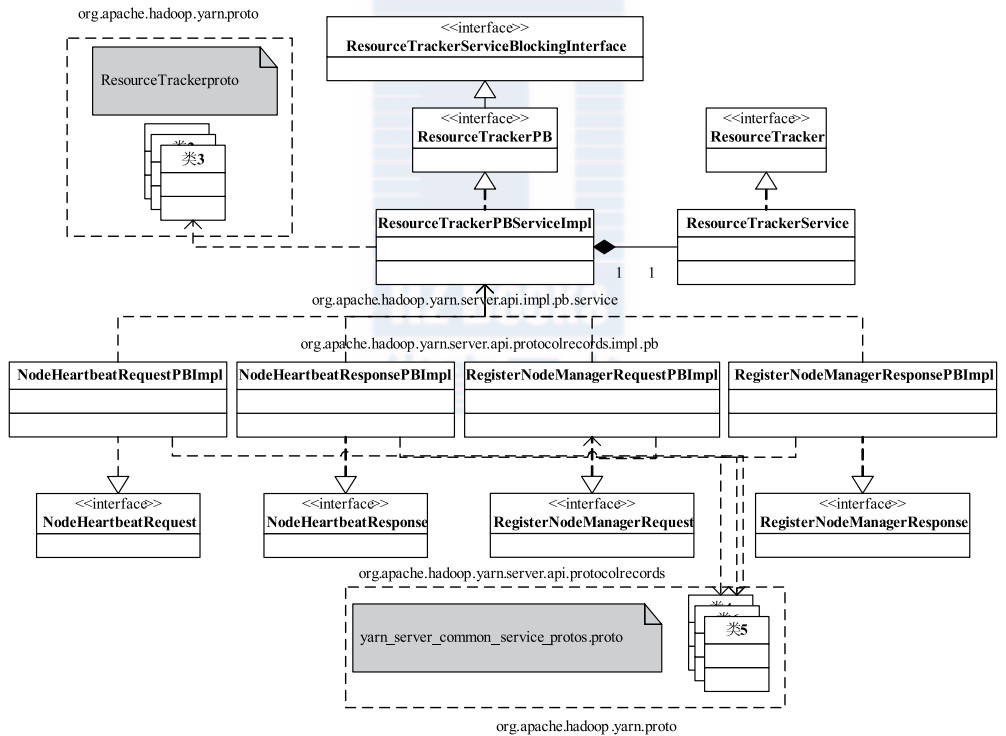
RPC
Apache YARN 的 RPC 协议
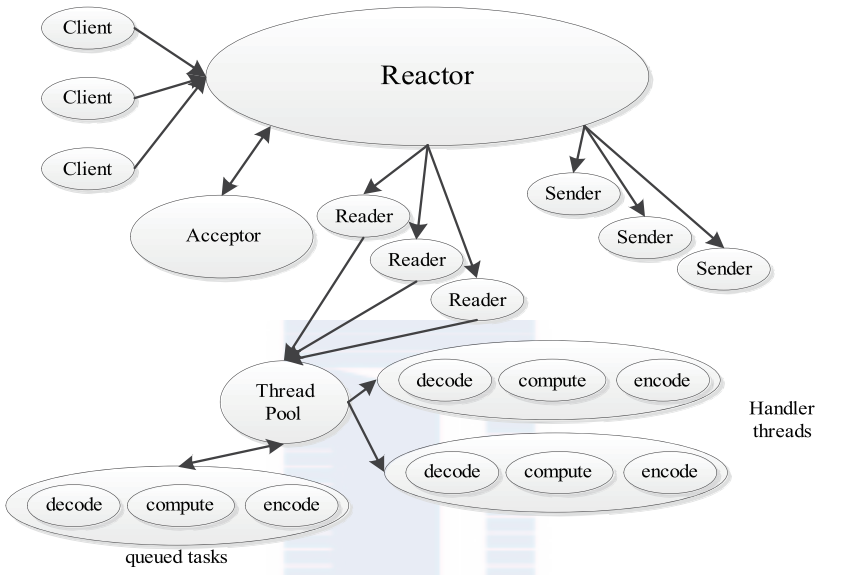
使用了
- protocol buffer
- avro
reactor 模式
- tomcat、jetty 使用的就是这种模式
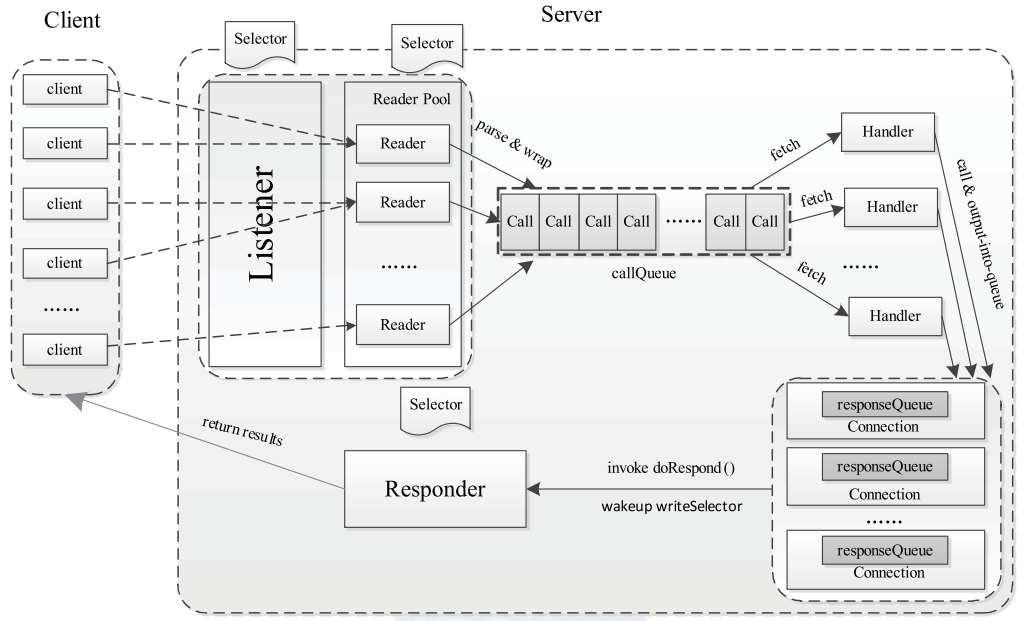
Hadoop RPC Server 处理流程
其他
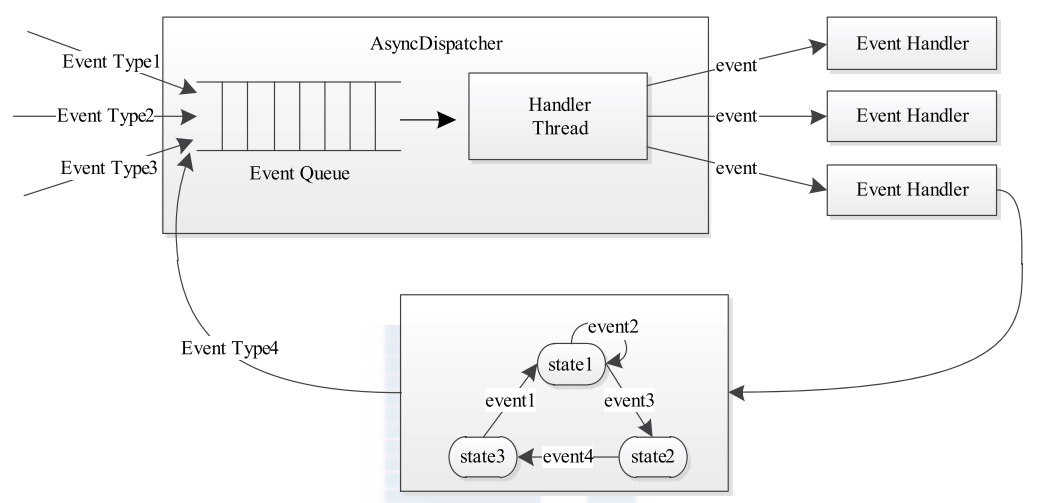
- 使用了状态机
- 使用了 事件驱动
RPC 中的 protocol buffers 封装
事件处理模型
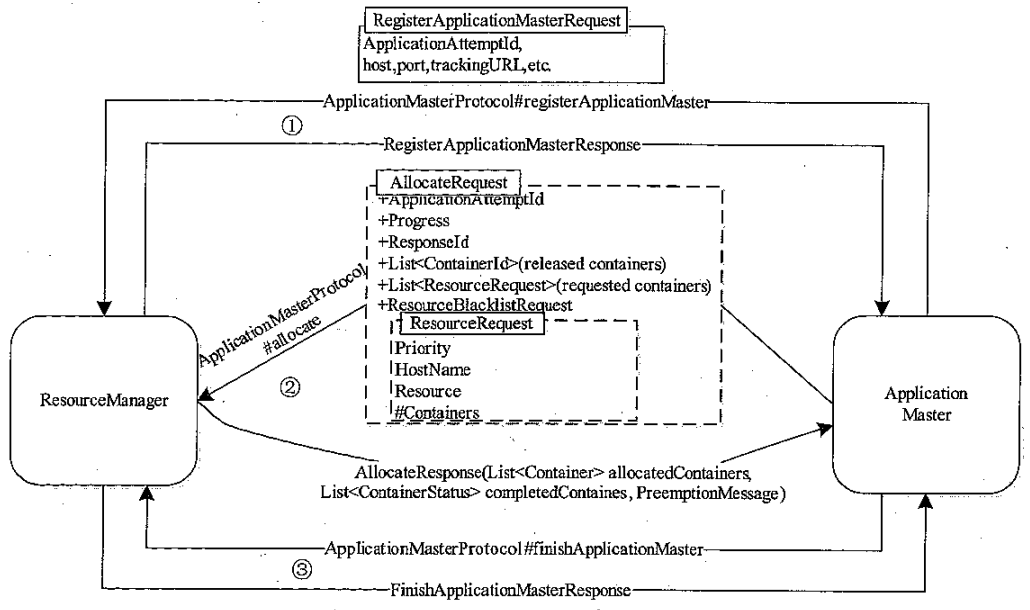
ApplicationMaster
ApplicationMaster 和 ResourcManager 通讯流程
- AM启动识,先向 RM 注册,注册信息封装到 protocol buffers 消息中
- AM 通过 RPC 向 RM 申请资源,以 container为单位
- AM 通过 RPC 告诉 RM 应用程序执行完毕
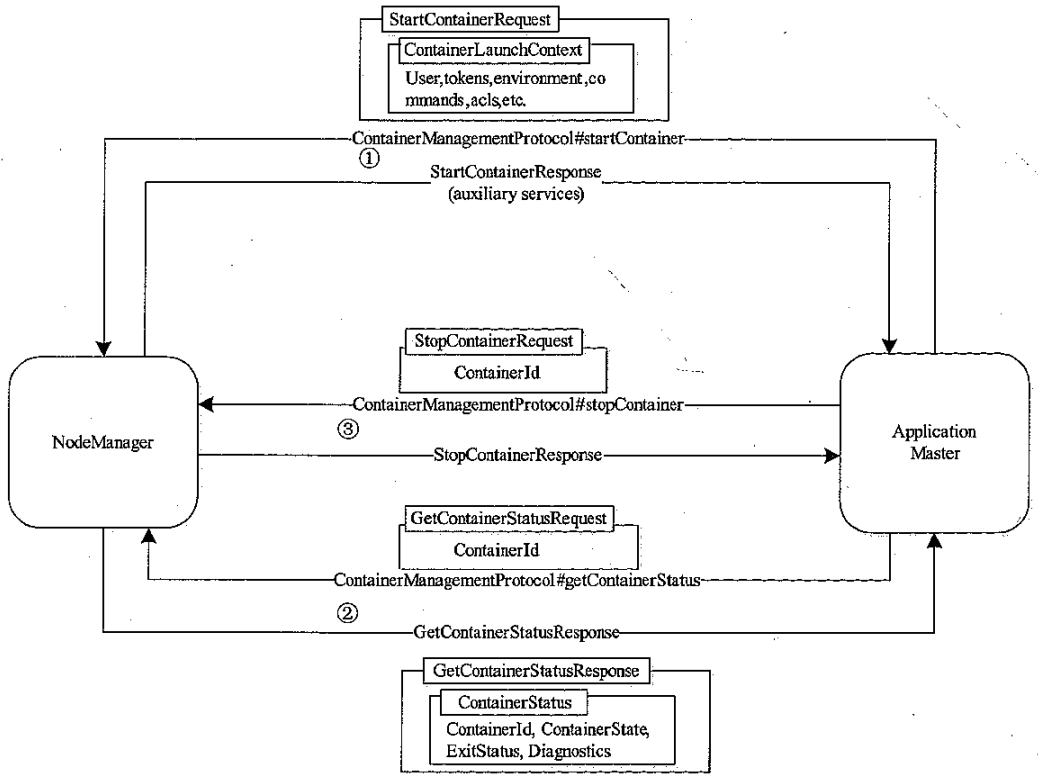
ApplicationMaster 和 NodeManager 通讯流程
- 将申请到的资源二次分配给内部任务,并通过 RPC 和 NM 通讯,启动 Container
- AM 通过 RPC 跟 NM 通讯,获取 container 的运行状态
- 当一个container 结束后,AM 会感知到,并 告诉 NM,可以释放资源了
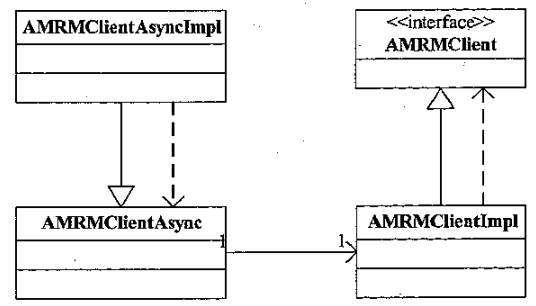
AM - RM 的编程库
- 核心逻辑由 AMRMClientImpl 和 AMRMClientAsync 实现
- AMRMClientAsync 提供了异步回调接口
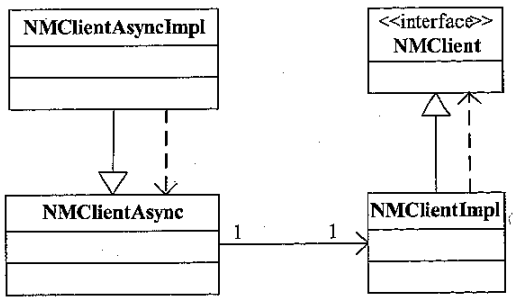
AM - NM 编程接口
- AN 和 NM 的交互核心逻辑由 NMClientIml 和 NMClientAsync 实现
- NMClientAsync 将事件封装到阻塞队列中,等待后面回调 https://v1.ax1x.com/2025/01/12/7WLWGm.png
{kind=link}
YARN 自带的 application 程序实例:
- DistributedShell
- UnManagedAM
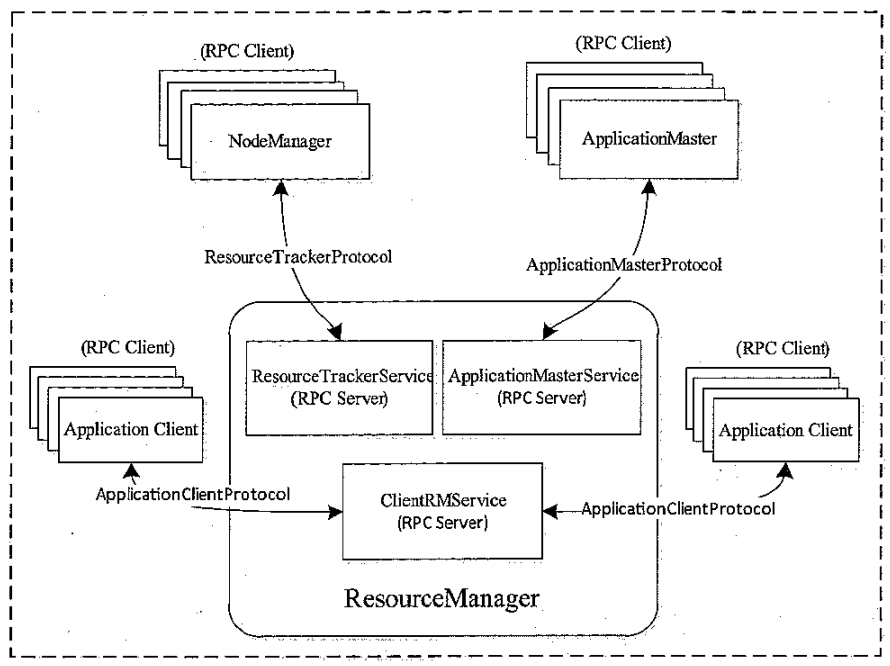
ResourceManager
模块划分
ResourceManager 相关的 RPC 协议
- 与客户端交互,处理来自客户端的请求
- 启动和管理 AM,在 AM 失败的时候重启它
- 管理 NM,接收 NM 的资源汇报信息,并向 NM 下达管理指令,如杀死Container
- 资源管理和调度,接收来自 AM 的资源申请,并为其分配资源
ResourcManager 包含如下一些模块
- 用户交互模块
- 针对普通用户的 ClientRmService,如提交应用程序、终止、获取运行状态
- AdminService,针对管理员的,动态更新节点列表,更新 ACL,更新队列
- WebApp,真实集群资源使用情况
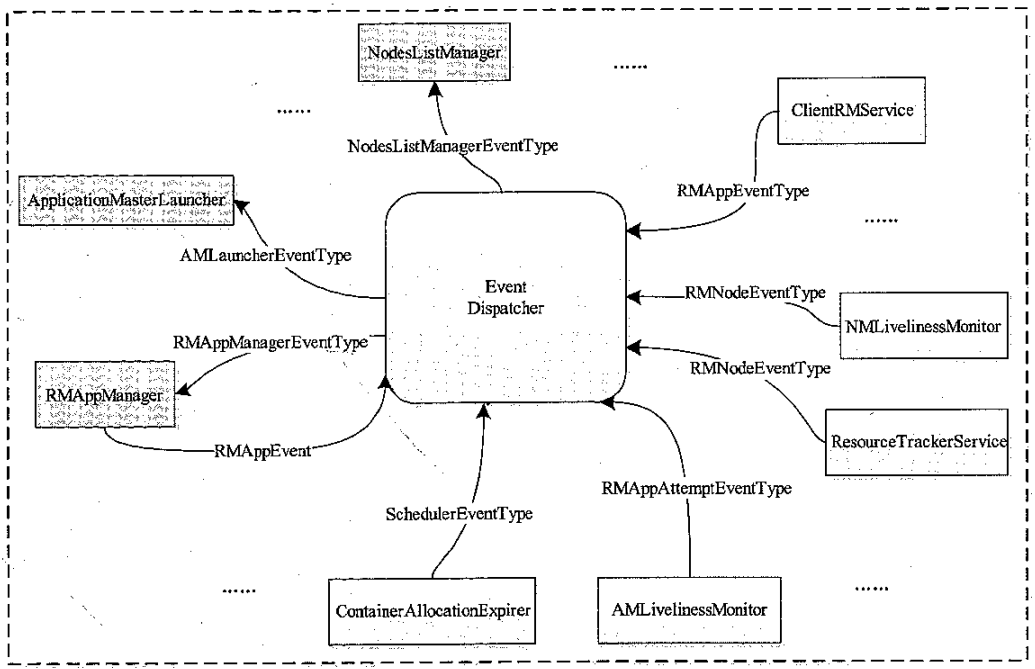
- NM 管理模块
- NMLivelinessMonitor,监控 NM 是否或者,如果一段时间未汇报状态,则认为挂了
- NodesListManager,维护正常节点和异常节点列表,管理白名单、黑名单
- ResourceTrackerService,处理来自 NM 的请求,包括注册(节点ID、可用资源等),心跳(各个Container状态,运行的Application列表,节点健康状态)
- AM 管理模块
- AMLivelinessMonitor,监控 AM 是否或者,一段时间未汇报则认为挂了
- ApplicationMasterLauncher,与某个 NM 通讯,要求它为某个应用程序启动 AM
- ApplicationMasterService(AMS),处理 AM的请求包含注册(启动节点,对外RPC等),心跳(所需的资源描述、待释放的Container列表,黑名单列表)
- Application 管理模块
- ApplicationACLsManager,管理应用程序访问权利,查看权限、修改权限
- RMAppManager,管理应用程序的启动和关闭
- ContainerAllocationExpirer,当 AM 收到 RM新分配的Container后,必须在一段时间内上报
- 状态机管理模块
- RMApp,维护一个应用程序,application的整合运行周期,包括启动到结束
- RMAppAttempt,一个应用程序失败后重启,维护了一次运行厂商的整个生命周期
- RMContainer,将资源封装为 container发送给 AM,而AM会在container描述的运行环境中启动任务,所以container和任务的生命周期是一致的
- RMNode,维护 NM 的生命周期,包括启动到结束
- 安全管理模块
- 自带了非常全面的权限管理机制
- AMSecretManager、ContainerTokenSecretManager、ApplicationTokenSecretManager 等模块
- 资源分片模块
- 主要涉及一个组件:ResourceScheduler,是资源调度器
- 根据一定的约束条件,如队列容量限制等,将集群资源分配给各个应用程序
- 自带了一个批处理调度器 FIFO,和两个多用户调度器 FairScheduler,CapacityScheduler(默认)

ResourceManager 内部事件 和 事件处理器交互图
ApplicationMaster 的启动流程
- 用户向 RM 提交应用程序,RM收到后先向资源调度器申请 AM 资源,再由ApplicationMasterLauncher与对应的NM 通讯,从而启动 AM
- AM 启动完成后,ApplicationMasterLauncher 会通过事件的形式,将刚启动的AM 注册到 AMLivelinessMonitor
- AM启动后,先向 ApplicationMasterService注册,将自己的host、port等回报
- AM 运行过程中,周期性的向 ApplicationMasterService回报心跳
- ApplicationMasterService收到心跳,通知AMLivelinessMonitor 更新最新的信息
- 当应用程序完成后,AM向ApplicationMasterService 发送请求,注销自己
- ApplicationMasterService收到请求后,标准应用程序为完成,通知AMLivelinessMonitor 移除心跳

状态机
应用程序状态机的组织结构
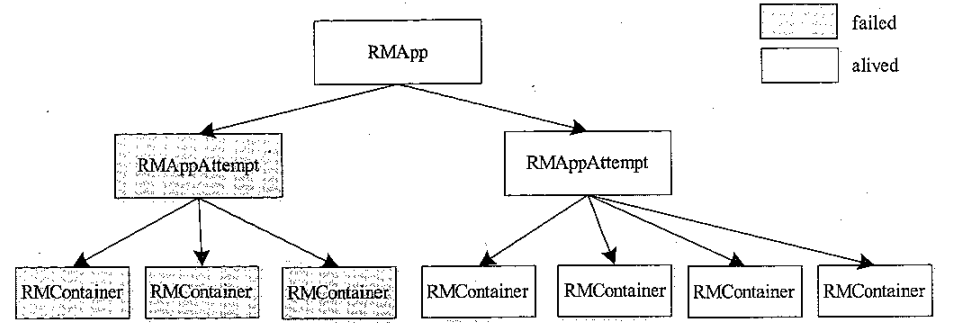
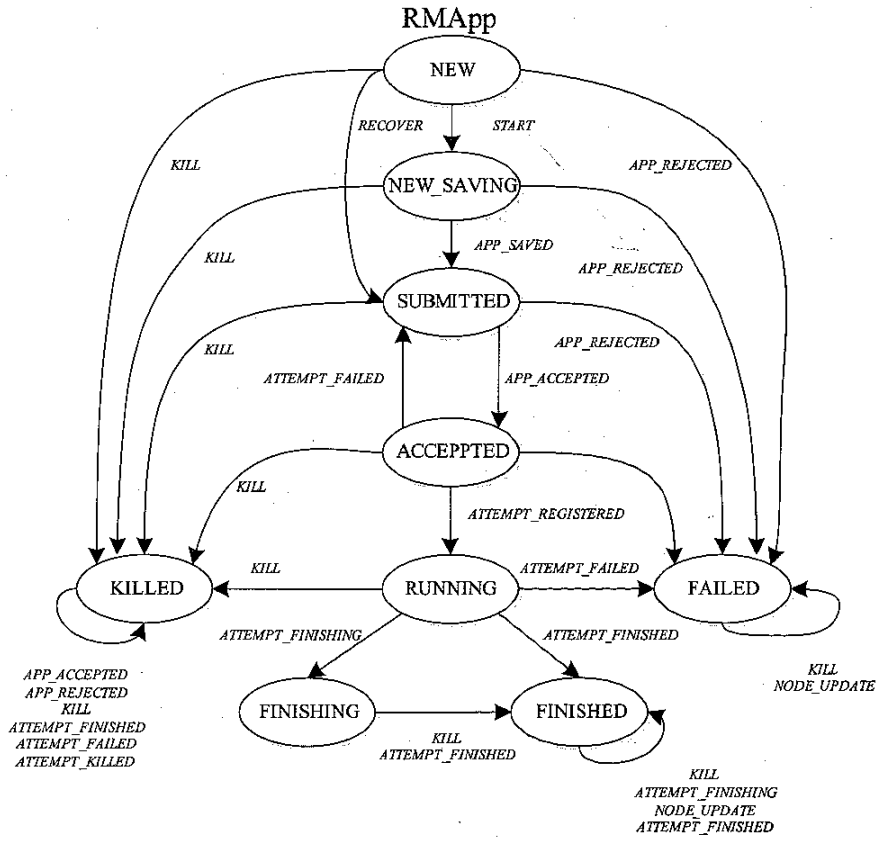
RMApp 状态机
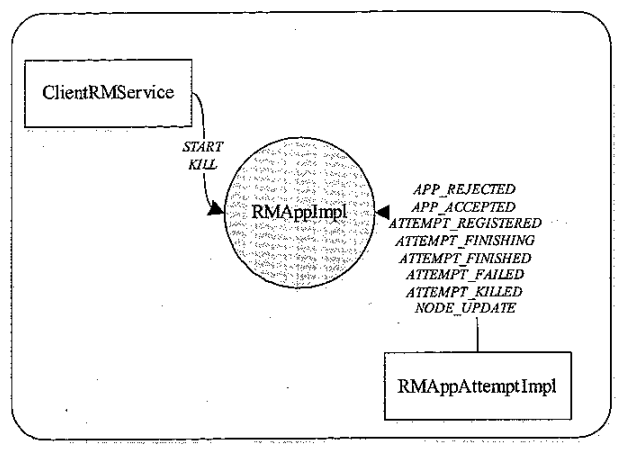
RMApp 状态机事件来源
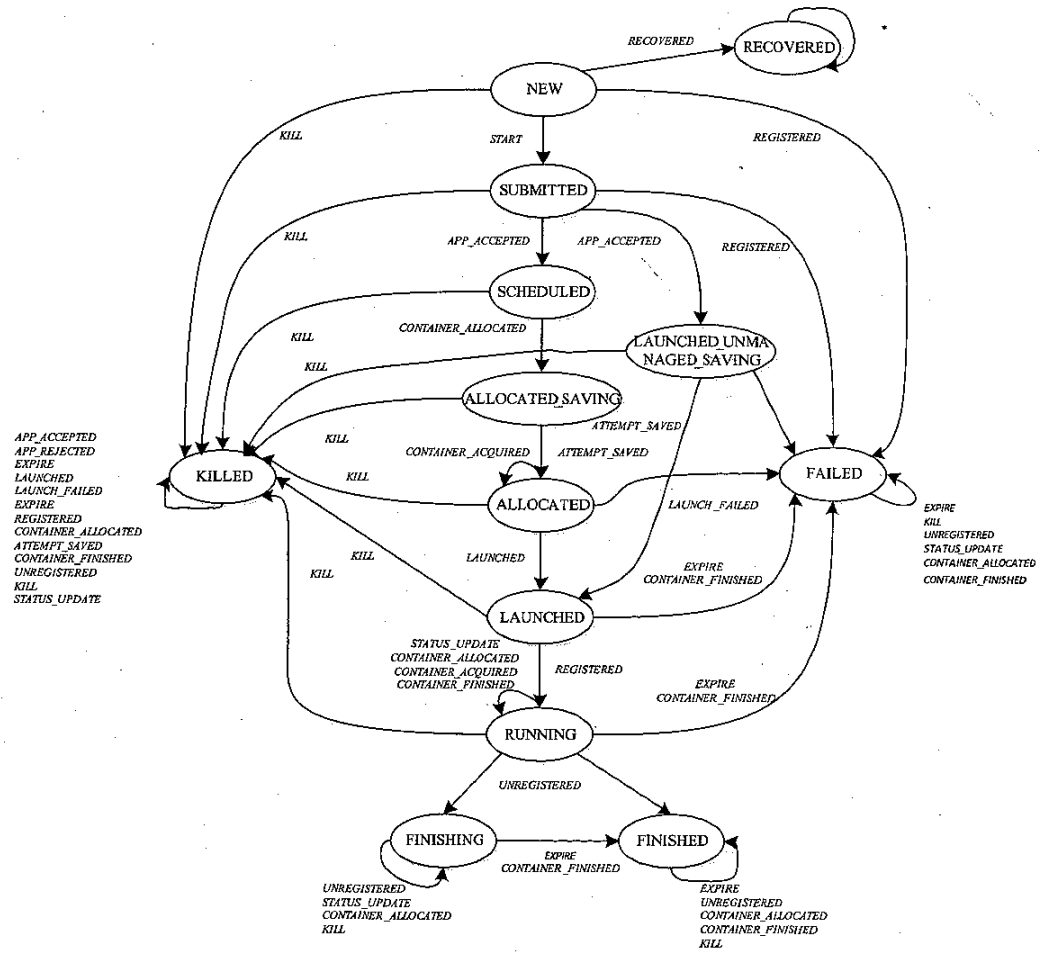
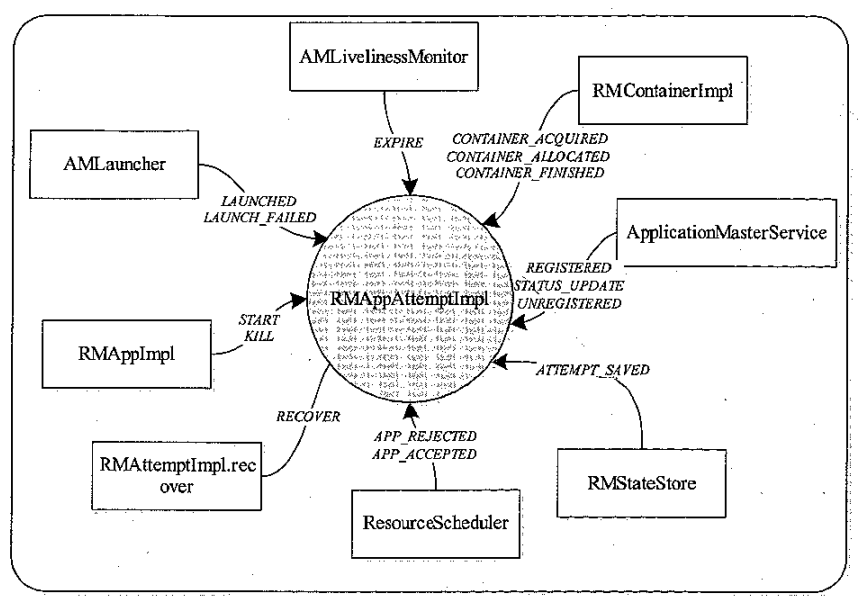
RMAppAttempt 状态机
- 最重要的组件是 AM,它的当前状态代表整个应用程序的当前状态
- 因此 RMAppAttemptlmpl 本质上是维护的 ApplicationMaster 生命周期
RMAppAttempt 状态机事件来源
RMApp: The Application State Machine
- Purpose: RMApp represents the global state of an application submitted to the ResourceManager.
- Scope: It oversees the entire application’s lifecycle, from submission to completion, irrespective of the attempts made to execute it.
RMAppAttempt: The Attempt State Machine
- Purpose: RMAppAttempt represents the state of an individual attempt to run the application.
- Scope: Focuses on the execution of a single attempt to run the application’s master container (ApplicationMaster or AM).
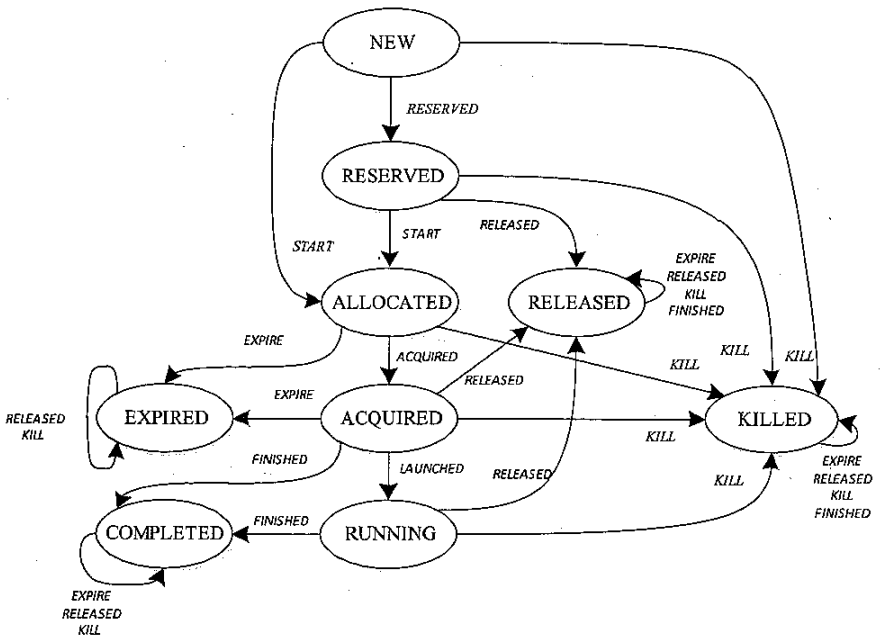
RMContainer: Container State Machine
- Purpose: Represents the state of a single container running on a NodeManager.
- Scope: Manages individual containers allocated for tasks (e.g., mapper or reducer in MapReduce).
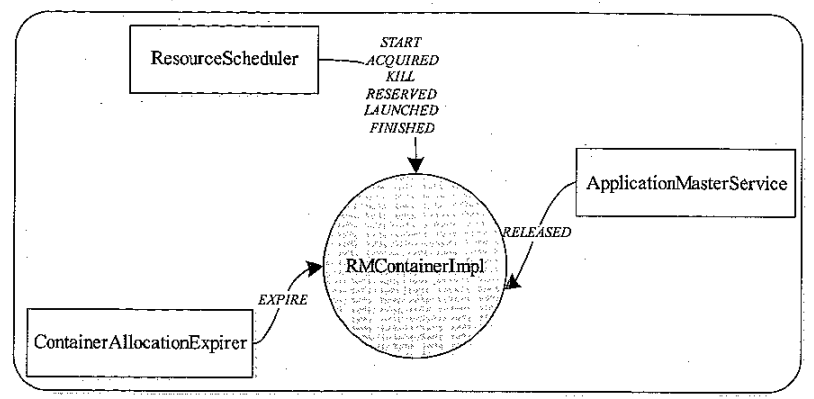
RMContainer 状态机
RMContainer 状态机事件来源
| Feature | RMApp | RMAppAttempt | RMContainer |
|---|---|---|---|
| Purpose | Tracks entire application. | Tracks a single AM attempt. | Tracks an individual container. |
| Scope | Manages multiple attempts. | Focuses on one AM execution. | Focuses on one task container. |
| States | NEW, SUBMITTED, RUNNING, etc. | NEW, ALLOCATED, RUNNING, etc. | NEW, ALLOCATED, RUNNING, etc. |
| Handles Retries | Yes, creates new attempts. | No, retries are managed by RMApp. | No, retries require new containers. |
| Tracks | Overall application lifecycle. | Lifecycle of AM execution. | Lifecycle of a container. |
| Example | MapReduce job success/failure. | AM crash/retry monitoring. | Mapper or Reducer task status. |
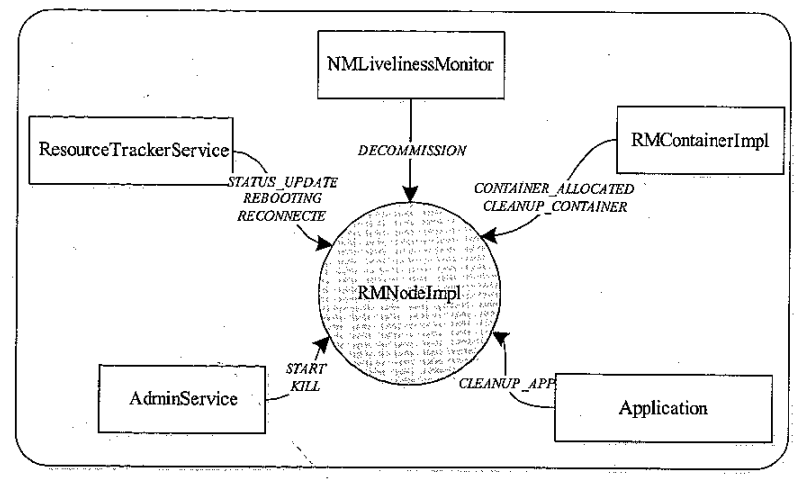
RMNode 状态机
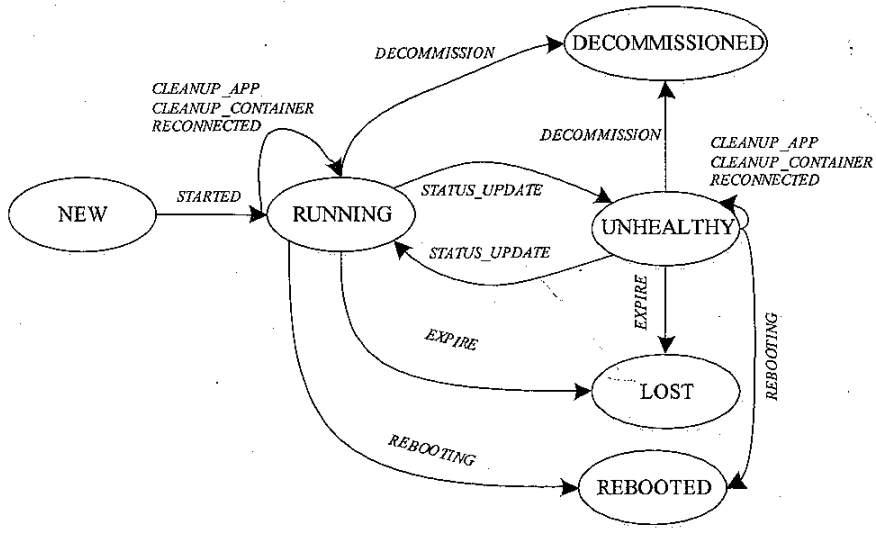
RMNode 状态机事件来源
常见行为分析
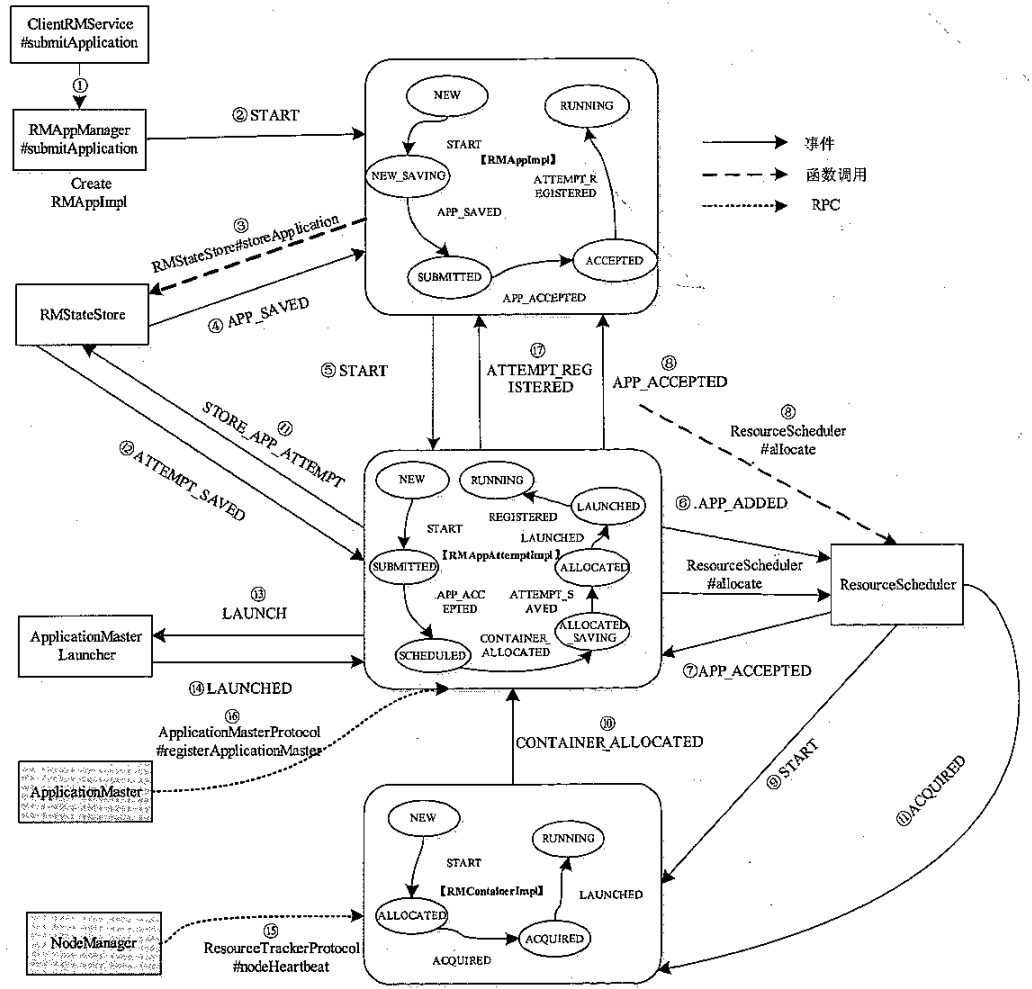
AM 启动流程
-
RM 中的 ClientRMService 实现了 ApplicationClientProtocol 协议,协调RMAppManager 通知其他服务进一步处理
-
RMAppManager维护期运行状态,判断是否故障,发送 start命令
-
RMAppImpl 收到 start事件后,调用 RMStateStore(其他还有MemoryRMState、FileSystemRMStateStore),更改运行状态变更为 NEW_SAVING
-
进一步发送 APP_SAVED 事件
-
创建 RMAppAttemptImpl,发送start事件,RMAppImpl的运行状态由NEW_SAVING转移为SUBMITTED
-
RMAppAttemptImpl收到app_added事件,RMAppAttemptImpl状态由NEW转移为SUBMITTED
-
ResourceScheduler收到app_added事件,检查权限,保持应用程序结构,并向RMAppAttemptImpl发送APP_ACCEPTED事件
-
RMAppAttemptImpl收到APP_ACCEPTED事件后,向RMAppImpl发送 APP_ACCEPTED事件,然后向应用程序申请资源,资源描述为:<AM_CONTAINER_PRIORITY, ResourceRequest.ANY, APPaTTEMPT.GETSUBMISSIONcONTEXT(), GETrESOURCE(), 1>
-
ResourceManager为应用程序的ApplicationMaster分配资源后,创建RMContainerImpl,并发送start事件
-
RMContainerImpl收到事件后,向RMAppAttemptImpl发送CONTAINER_ALLOCATED事件,RMContainerImpl状态从NEW转移为ALLOCATED
-
RMAppAttemptImpl 收到CONTAINER_ALLOCATED事件后分配资源,向RMContainerImpl发送ACQUIRED事件,而而RMAppAttemptImpl收到事件后记录STORE_APP_ATTEMPT 日志;RMAppAttemptImpl状态从SCHEDULED转移为ALLOCATED_SAVING
-
RMStateStore 向 RMAppAttemptImpl发送 ATTEMPT_SAVED 事件
-
RMAppAttemptImpl收到事件后,向ApplicationMasterLauncher 发送LAUNCH事件;RMAppAttemptImpl状态从ALLOCATED_SAVING转移为ALLOCATED
-
ApplicationMasterLauncher收到事件后放入队列,等待AMLauncher处理(和NM通讯),启动AM;再向RMAppAttemptImpl发送LAUNCHED事件,RMAppAttemptImpl会向AMLivelinessMonitor注册监控状态,RMAppAttemptImpl状态从ALLOCATED转移为LAUNCHED
-
NodeManager通过心跳机制汇报ApplicationMaster所在Container已经成功启动,ResourceSchedulerLAUNCHED事件;RMContainerImpl收到该事件后,会从ContainerAllocationExpirer监控列表中移除
-
启动的AM 向RM注册,ApplicationMasterService收到后,向RMAppAttemptImpl发送REGISTERED事件;RMAppAttemptImpl收到后保存其信息,再向RMAppImpl发送ATTEMPT_REGISTERED,RMAppAttemptImpl状态从LAUNCHED转移为RUNNING
-
RMAppImpl收到ATTEMPT_REGISTERED事件后,所做的事情仅是将状态从ACCEPTED转变为RUNNING
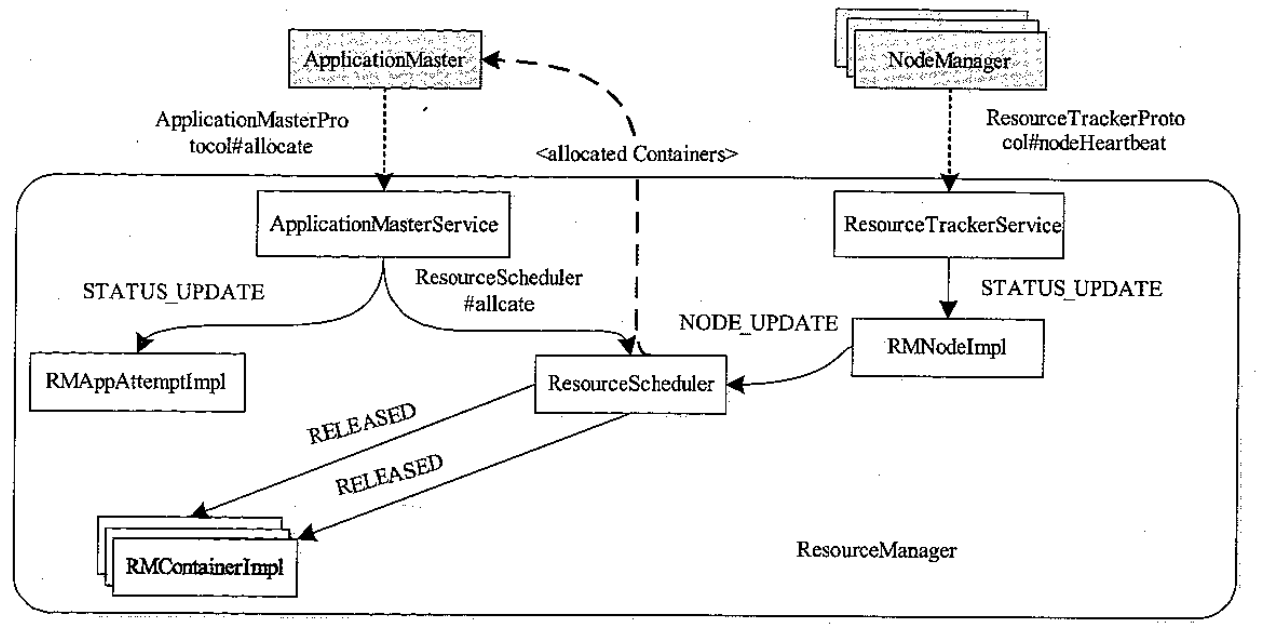
Container 分配与申请流程
- 阶段 1
- AM 向 RM 汇报资源需求,资源描述,等待释放的container,黑名单等
- RM的 ApplicationMasterService 收到请求后,向RMAppAttemptImpl 发送STATUS_UPDATE事件;RMAppAttemptImpl 收到后更新进度并更新AMLivenessMonitor 记录中的时间
- ApplicationMasterService 调用 ResourceScheduler,将AM资源需求汇报给ResourceScheduler
- ResourceScheduler 读取待释放的container列表,向RMContainerImpl 发送RELEASED事件,并返回为该程序分配的资源
- 阶段 2
- NM 向 RM 汇报各个 container 的运行状态
- RM 中的ResourceTrackerService 处理NM 的请求,并会向RMNodeImpl 发送STATUS_UPDATE事件;RMNodeImpl收集到后更新各个Container运行状态,向ResourceScheduler发送 NODE_UPDATE事件
- ResourceScheduler收到后,如果有空闲资源则将这些资源记录,等待AM 下次心态再来领取
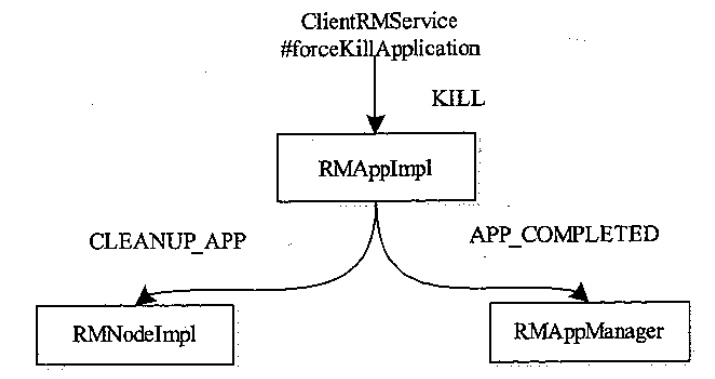
不存在正在运行的 RMAppAttemptImpl 的情况
- 杀掉application 一般是由用户触发的,ResouceScheduler负责处理这个请求
- 并向 RMAppImpl 发送KILL 事件
- 如果不存在对应的 RMAppAttemptImpl
- 则通知 RMNodeImpl,回收资源
- 通知 RMAppManager 任务完成
存在正在运行的 RMAppAttemptImpl 情况
- 同样,也则通知 RMNodeImpl,回收资源;通知 RMAppManager 任务完成
- 真正回收资源操作是由调度器 ResourceScheduler异步完成的
- 回收 AM占用资源,向ApplicationMasterLauncher发送CLEANUP事件
- 回收 Container资源,向已经启动的RMContainerImpl发送KILL 事件

Container 超时
- 又分为 AMContainer 超时
- 普通 Container 超时
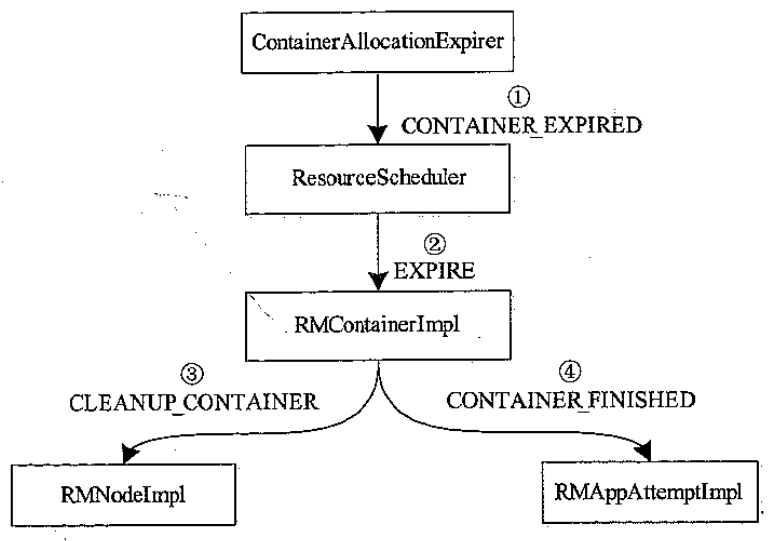
AM Container 超时后紫苑回收流程
- NM 没能在一定时间内启动 AM,导致ContainerAllocationExpirer 触发CONTAINER_EXPIRED;而ResourceScheduler 收到后向 RMContainerImpl 发送EXPIRE事件
- RMContainerImpl 收到事件后,从ContainerAllocationExpirer 移除,向AM Container发送CLEANUP_CONTAINER
- RMNodeImpl 收到 CLEANUP_CONTAINER事件后,放入清理列表
- RMAppAttemptImpl 收到CONTAINER_FINISHED 事件后再向RMAppImpl 发送ATTEMPT_FAILED 事件,向ResourceScheduler 发送APP_REMOVED 事件
- ResourceScheduler 做一些清理操作

普通 container 超时
- 普通 Container 超时触发的资源回收流程跟 AM Container 的回收流程的前三个步骤是一样的
- RMAppAttemptImpl 收到CONTAINER_FINISHED 事件后会保存
- 等下次 AM 心跳过来会告诉它,后面又 AM 决定是重启 还是丢弃
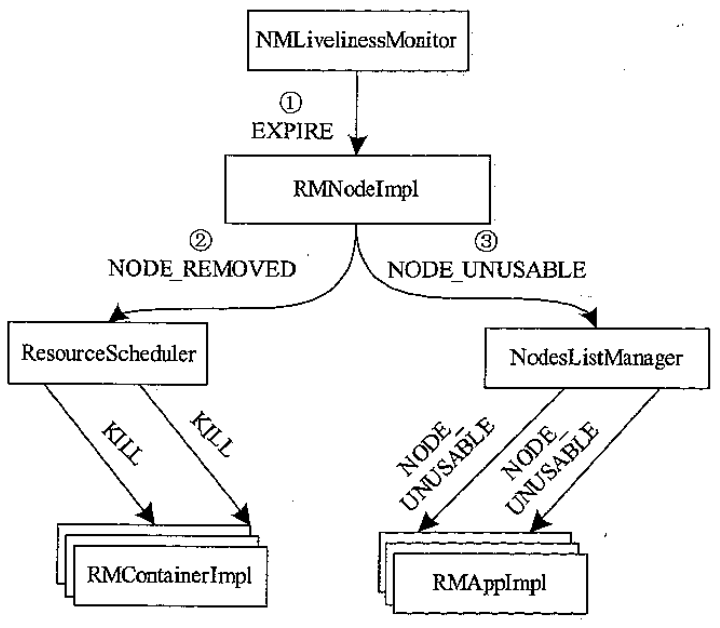
NM 超时后紫苑回收流程
- NMLivenessMonitor 发现 NM 一段时间内未汇报,触发一个 EXPIRE事件
- RMNodeImpl 收到后,分别向ResourceScheduler、NodesListManager 发送NODE_REMOVED 、NODE_UNUSABLE 事件
- ResourceScheduler 收到后向运行在死亡节点的RMContainerImpl 发送KILL事件;
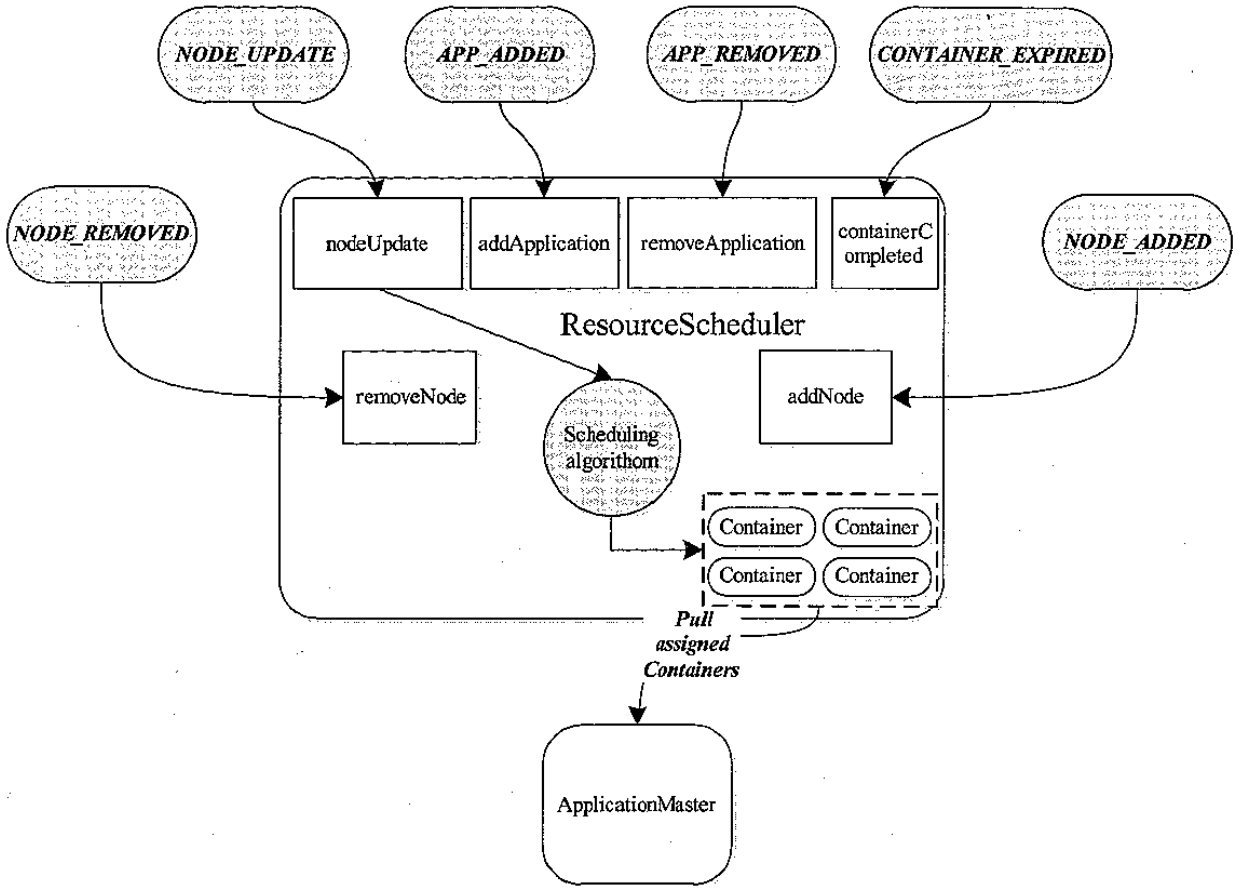
资源调度
基本概念
需要继承ResourceScheduler接口
YARN包括了
- FIFO
- Capacity Scheduler
- Fari Scheduler
YarnScheduler 接口定义如下:
|
|
其他一些重要的接口
- Recoverable
资源调度基本架构
当前 yarn 支持的调度
- 当前 YARN 支持的调度语义包括:
- 请求某个特定节点上的特定资源量。比如,请求节点 nodeX 上 5 个这样的 Container:虚拟 CPU 个数为 2,内存量为 2GB。
- 请求某个特定机架上的特定资源量。比如,请求机架 rackX 上 3 个这样的 Container:虚拟 CPU 个数为 4,内存量为 3GB。
- 将某些节点加入(或移除)黑名单,不再为自己分配这些节点上的资源。比如,ApplicationMaster 发现节点 nodeX 和 nodeY - 失败的任务数目过多,可请求将这两个节点加入黑名单,从而不再收到这两个节点上的资源,过一段时间后,可请求将 nodeX 移除黑名单,从而可再次使用该节点上的资源。
- 请求归还某些资源。比如,ApplicationMaster 已获取的来自节点 nodeX 上的 2 个 Container 暂时不用了,可将之归还给集群,这样这些资源可再次分配给其他应用程序。
YARN 采用了两层调度
- 第一层,RM 中的资源调度器将资源分配给各个 AM
- 第二层,AM 再进一步将资源分配给它内部的各个任务
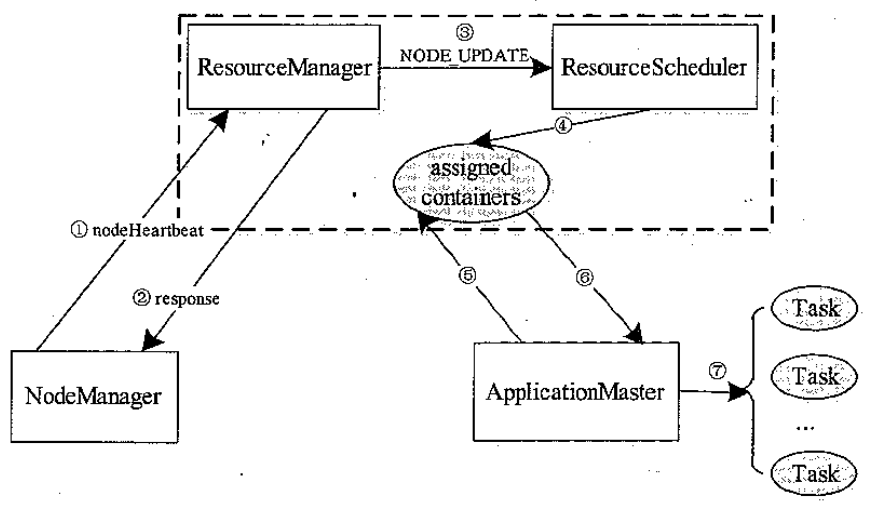
YARN 的资源分配过程
- NodeManager 通过周期性心跳汇报节点信息。
- ResourceManager 为 NodeManager 返回一个心跳应答,包括需释放的 Container 列表等信息。
- ResourceManager 收到来自 NodeManager 的信息后,会触发一个 NODE_UPDATE 事件。
- ResourceScheduler 收到 NODE_UPDATE 事件后,会按照一定的策略将该节点上的资源(步骤 2 中有释放的资源)分配各应用程序,并将分配结果放到一个内存数据结构中。
- 应用程序的 ApplicationMaster 向 ResourceManager 发送周期性的心跳,以领取最新分配的 Container。
- ResourceManager 收到来自 ApplicationMaster 心跳信息后,为它分配的 container 将以心跳应答的形式返回给 ApplicationMaster。
- ApplicationMaster 收到新分配的 container 列表后,会将这些 Container 进一步分配给它内部的各个任务。
资源抢占发生时机
资源抢占流程
- SchedulingEditPolicy 告诉 RM要抢占 资源
- RM更新资源
- 等下一次 AM 心跳来时,将这些待释放的资源和待抢占的 container列表发给他
- 让 AM kill这些 container
- 对于一段时间内未自行 kill 调的 container,则会他通知到 RM
- RM 通知 NM 杀掉这些 container

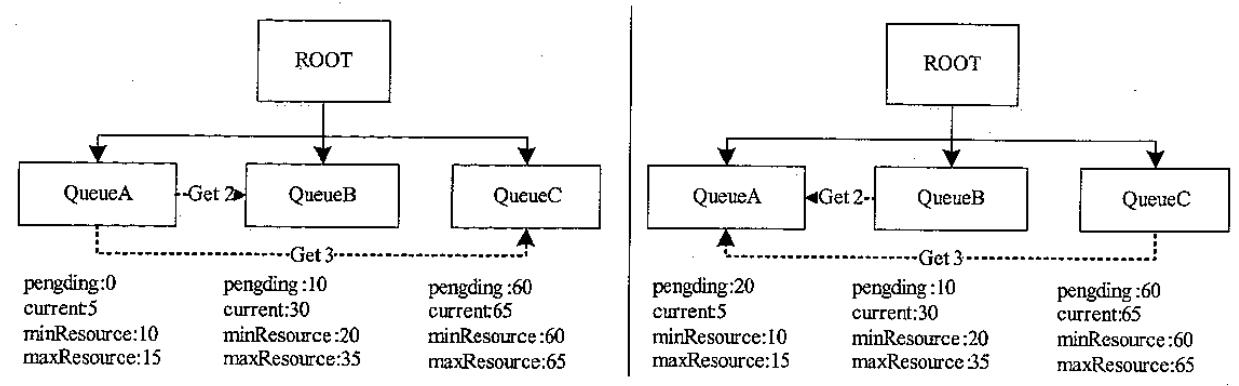
资源抢占资源量计算方法
- 这里假设有三个队列 a,b,c
- 最小资源量 24、16、40

t1 时刻 第一轮计算结果,wQassigned = 90,unassigned = 10
| Queue | normalizedGuarantee | wQavail | accepted | wQidle | idealAssigned | wQdone |
|---|---|---|---|---|---|---|
| QueueA | 24/(24+16+40)=0.3 | 100*0.3=30 | 20 | 10 | 20 | 20 |
| QueueB | 16/(24+16+40)=0.2 | 100*0.2=20 | 20 | 0 | 20 | 20 |
| QueueC | 40/(24+16+40)=0.5 | 100*0.5=50 | 50 | 0 | 50 | 50 |
第二轮计算结果,wQassigned = 95,unassigned = 5
由于 queueA、queueB 的 wQdone 为 0,不再进入下一轮
| Queue | normalizedGuarantee | wQavail | accepted | wQidle | idealAssigned | wQdone |
|---|---|---|---|---|---|---|
| QueueA | 24/(24+16+40)=0.3 | 10*0.3=3 | 0 | 3 | 20 | 0 |
| QueueB | 16/(24+16+40)=0.2 | 10*0.2=2 | 0 | 2 | 20 | 0 |
| QueueC | 40/(24+16+40)=0.5 | 10*0.5=5 | 5 | 0 | 55 | 5 |
三轮计算结果,unassinged = 0,所有资源都已经分配完毕,退出计算
| Queue | normalizedGuarantee | wQavail | accepted | wQidle | idealAssigned | wQdone |
|---|---|---|---|---|---|---|
| QueueC | 40/(40)=1.0 | 5*1.0=5 | 5 | 0 | 60 | 5 |
假设 t2 时刻,用户向 queueA 提交了一批应用,使的资源需求量从 0 变为 100
第一轮计算结果如下
| Queue | normalizedGuarantee | wQavail | accepted | wQidle | idealAssigned | wQdone |
|---|---|---|---|---|---|---|
| QueueA | 24/(24+16+40)=0.3 | 100*0.3=30 | 30 | 0 | 30 | 30 |
| QueueB | 16/(24+16+40)=0.2 | 100*0.2=20 | 20 | 0 | 20 | 20 |
| QueueC | 40/(24+16+40)=0.5 | 100*0.5=50 | 50 | 0 | 50 | 50 |
之后会抢占资源
- 杀死正在使用的 container 实现的,但尽可能避免直接杀死 正在运行的 container
- 选择低优先级的 container 作为抢占对象
- RM 将准备杀掉的 container 列表,发给 AM,由 AM 来决定
- 如果 AM 一直未杀掉,则 RM 去强制杀掉
队列
层级管理方式
- 子队列,可以嵌套
- 最少容量,可以使用父队列的容量比
- 调度器有限选择当前资源使用率最低的
- 最大容量
- 用户权限管理
capacity scheduler 列子
|
|
Capacity 资源分配流程
- 从根节点开始遍历子节点,一直到叶子节点,是 DFS 的过程
- 找到叶子节点的应用后,根据时间排序,选择时间最早的应用
- 选择container,对同一个应用程序,根据 container的各种资源组合的优先级做调度
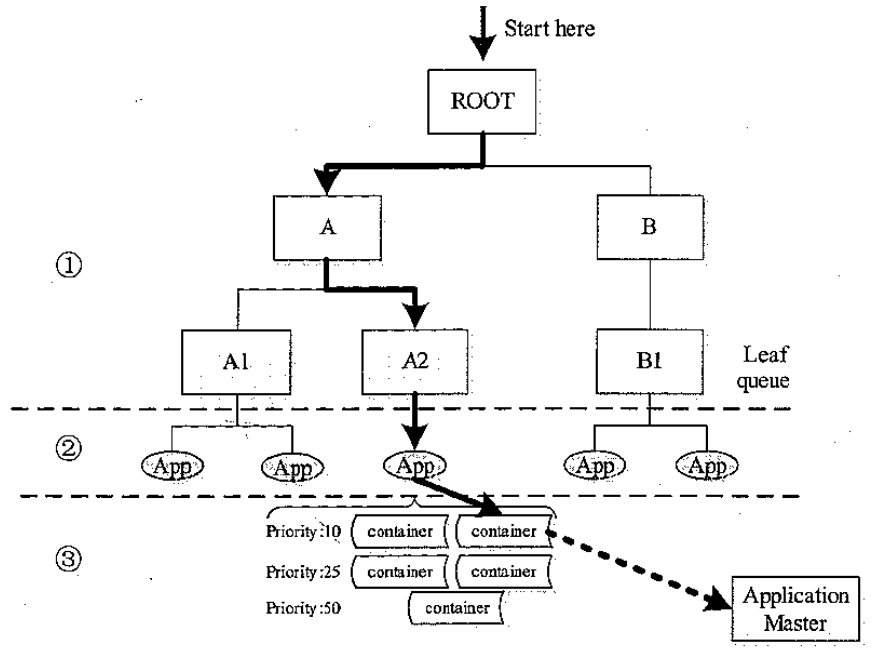
Fair scheduler 调度器
|
|
调度策略
- 跟 capacity 一样也是三步骤
- 先 DFS 方式选择队列
- 选择应用程序,最后选择 container
| Capacity Scheduler | Fair Scheduler | |
|---|---|---|
| 目标 | 提供一种多用户共享 Hadoop 集群的方法,以提高资源利用率和减小集群管理成本 | 基于最大最小公平算法将资源分配给各个资源池或用户 |
| 设计思想 | 资源按比例分配给各个队列,并添加各种严格的限制防止个别用户或队列独占资源 | 基于最大最小公平算法将资源分配给各个资源池或用户 |
| 是否支持动态加载配置文件 | 是 | 是 |
| 是否支持负载均衡 | 否 | 是 |
| 是否支持资源抢占 | 是 | 是 |
| 是否支持批量调度 | 是 | 是 |
| Container 请求资源需求度 | 最小资源量的整倍数,比如 Container 请求量是 1.5GB,最小资源量 1GB,Container 请求量自动被归一化为 2GB | 有专门的内存规范化参数控制,精度更小,Container 请求量是 1.5GB,规范化值为 128MB,则 Container 请求不变 |
| 本地任务调度优化 | 基于跳过次数的延迟调度 | 资源使用率低者优先 |
| 队列内资源分配方式 | FIFO 或者 DRF | Fair, FIFO 或者 DRF |
其他调度器
- 自适应调度器,根据用户期望时间自动分配
- 自学习调度器,根据贝叶斯分类算法的调度器
- 动态优先级调度器
NodeManage
模块划分
NodeManage 相关的 RPC 协议
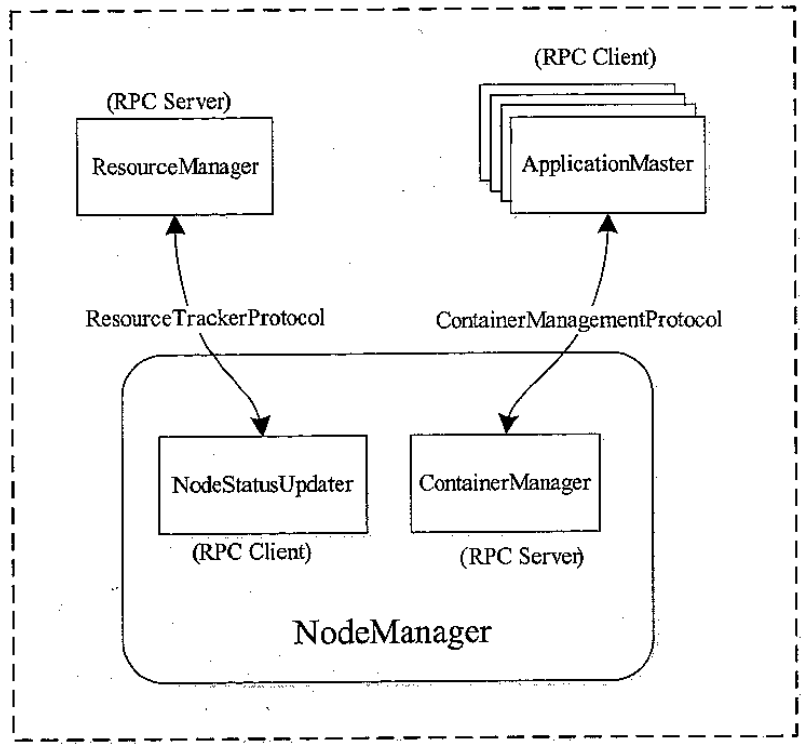
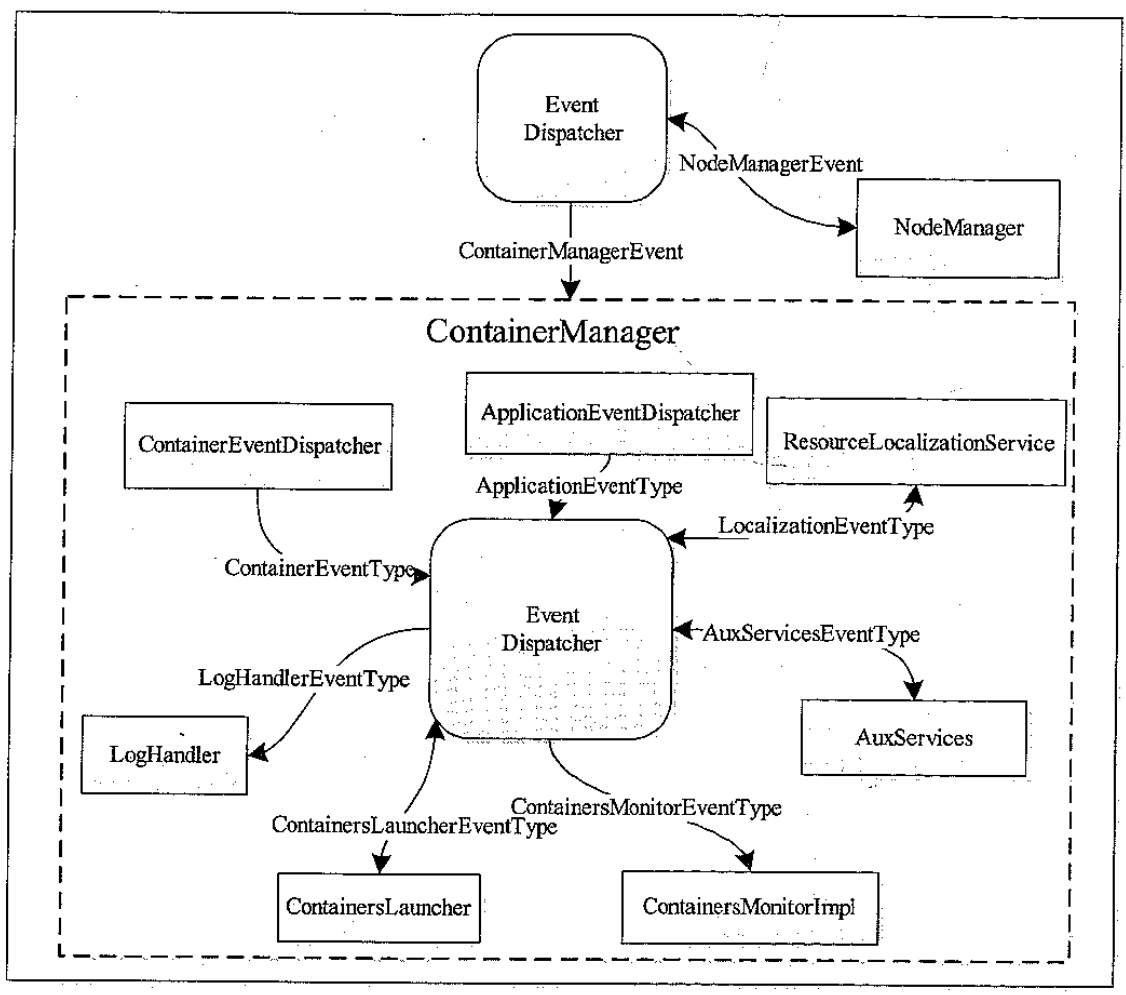
NodeManage 内部架构图
- NodeStatusUpdater,是 NM 和 RM 通讯的通道,负责汇报可用 container状态,包括完成和各种其他状态
- ContainerManager,最核心的组件之一,包括很多子组件
- RPC Server,AM 和 NM 通讯的通道
- ResourceLocalizationService,负责 container所需资源的本地化
- ContainerLauncher,维护线程池完成 container相关操作,启动或者kill
- AuxServices,NM 允许用户通过配置扩展功能,可以增加一些定制化的服务,如MR 的shuffleHTTPServer,就是封装后的附属服务
- ContainersMonitor,负责container的资源使用量,实现隔离和共享,发现超过资源使用则kill
- LoHandler,可插拔的,控制container日志保存方式
- ContainerEventDispatcher,container事件调度器,将对应的事件交给container的状态机
- ApplicationEventDispatcher,Application事件调度器,将对应事件交给Application状态机
- ContainerExecutor,可与底层操作系统交互,安全存放container需要的文件和目录,进而以一种方案的方式启动和清除container对应的进程,其中两个实现的LinuxContainerExecutor以 cgroup方式控制
- NodeHealthCheckerService,周期性的运行自定义脚本,向磁盘写文件,检查节点健康状态,RM检查到不健康的节点后就不再为其分配
- DeletionService,NM 将文件删除功能服务化,提供异步删除失效文件
- Security
- 包括ApplicationACLsManager,确保访问 NM的用户是合法的
- ContainerTokenSecretManager,确保资源被RM授权过
- WebServer,web管理界面
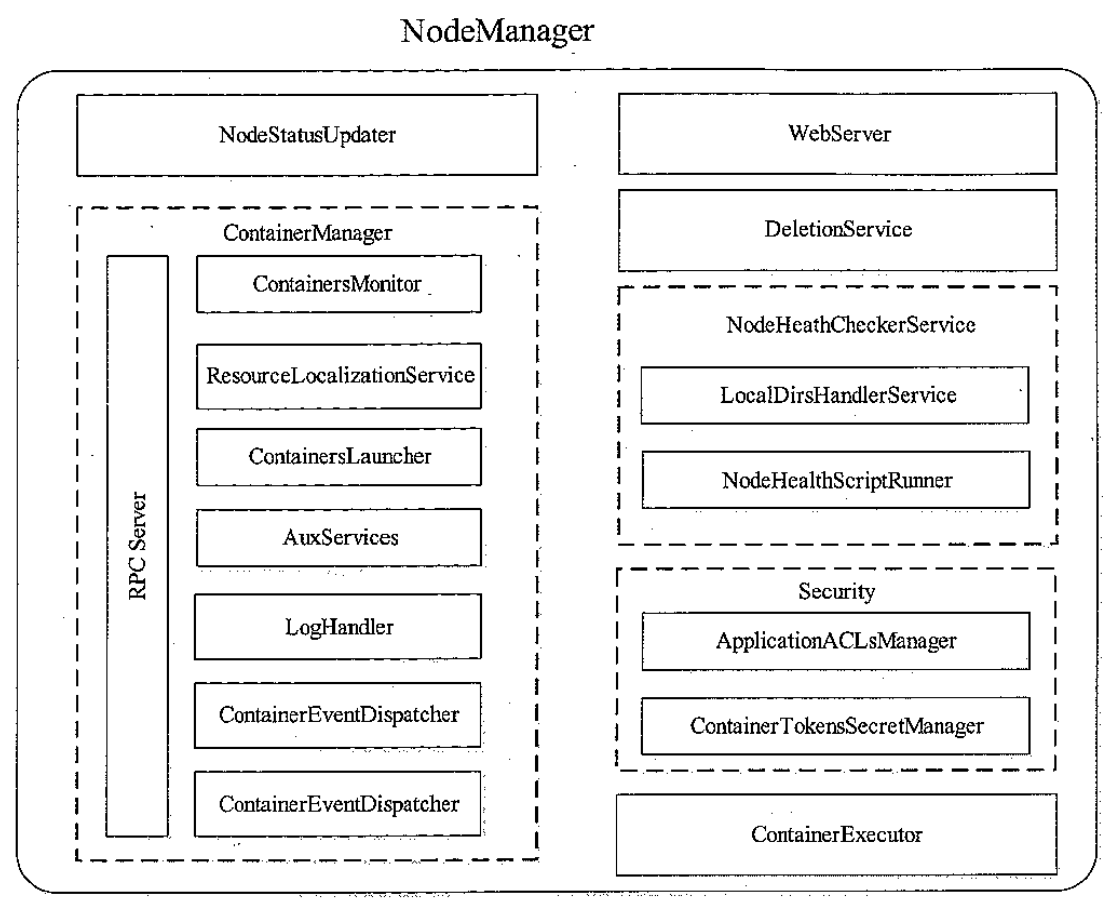
NodeManage 内部事件与事件处理器的交互图
自定义健康检查
- 作为对 YARN 的cpu、内存之外的资源的检测
- 检查 磁盘,网络的情况,负载高的时候返回 ERROR,于是检测服务会返回 unhealthy
- 此时 RM就会放入黑名单,等 NM 恢复后会继续分配
- 也可以作为手工升级,人为修改监控脚本
|
|
分布式缓存
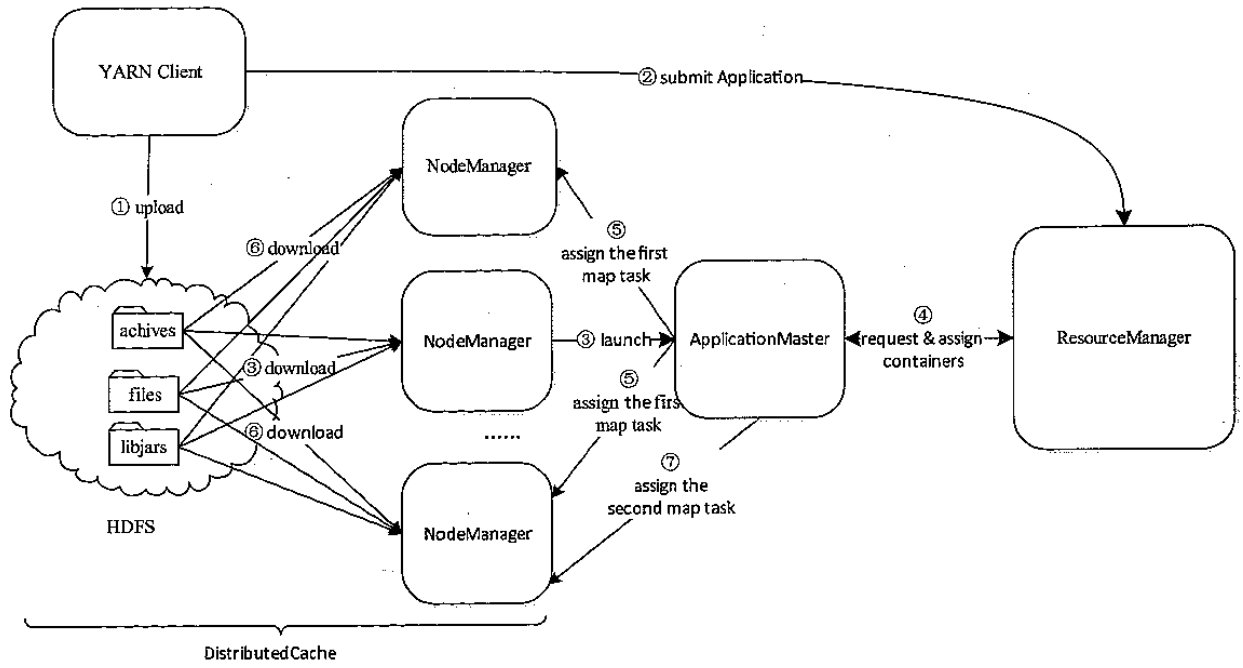
将用户应用程序执行时需要的外部文件资源,自动的下载并缓存到各个节点上
YARN 分布式缓存工作流程具体如下:
- 客户端将应用程序所需的文件资源(外部字典、JAR 包、二进制文件等)提交到 HDFS 上。
- 客户端将应用程序提交到 ResourceManager 上。
- ResourceManager 与某个 NodeManager 通信,启动应用程序 ApplicationMaster,NodeManager 收到命令后,首先从 HDFS 下载文件(缓存),然后启动 ApplicationMaster。
- ApplicationMaster 与 ResourceManager 通信,以请求和获取计算资源。
- ApplicationMaster 收到新分配的计算资源后,与对应的 NodeManager 通信,以启动任务。
- 如果该应用程序第一次在该节点上启动任务,则 NodeManager 首先从 HDFS 上下载文件缓存到本地,然后启动任务。
- NodeManager 后续收到启动任务请求后,如果文件已在本地缓存,则直接运行任务,否则等待文件缓存完成后再启动。
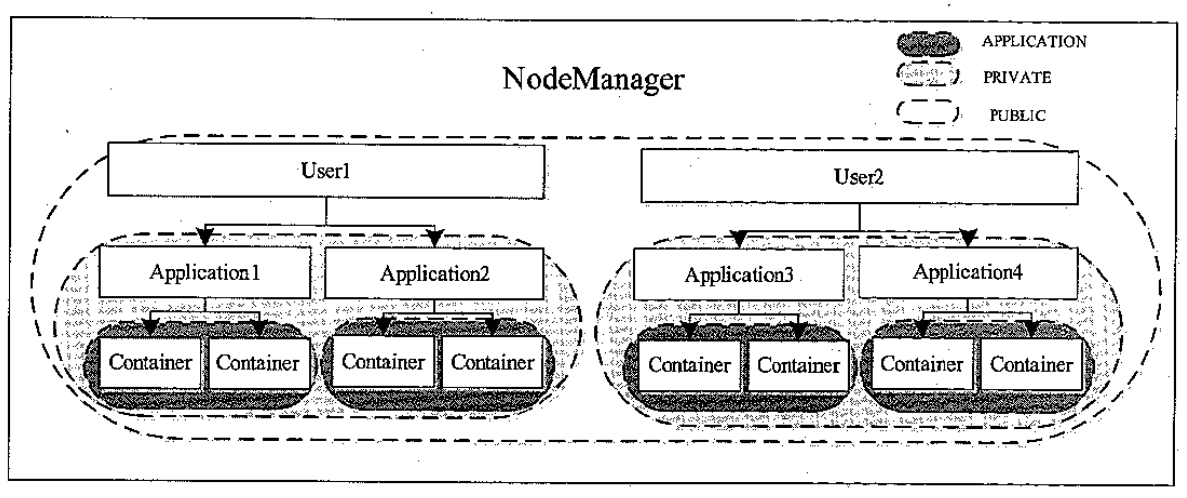
NM 资源可见性分类
- public,所有用户都可见
- private同一节点上所有应用程序共享该资源
- application,节点上同一应用程序的所有 container共享
资源类型
- archive,包括:jar、zip、tar.gz。tgz,tar
- file
- pattern
- 如果是 jar类型,会自动加入到 classpath 中
判断方式
- 比较:resource、timestampe,type、pattern 是否两个资源相同
实现
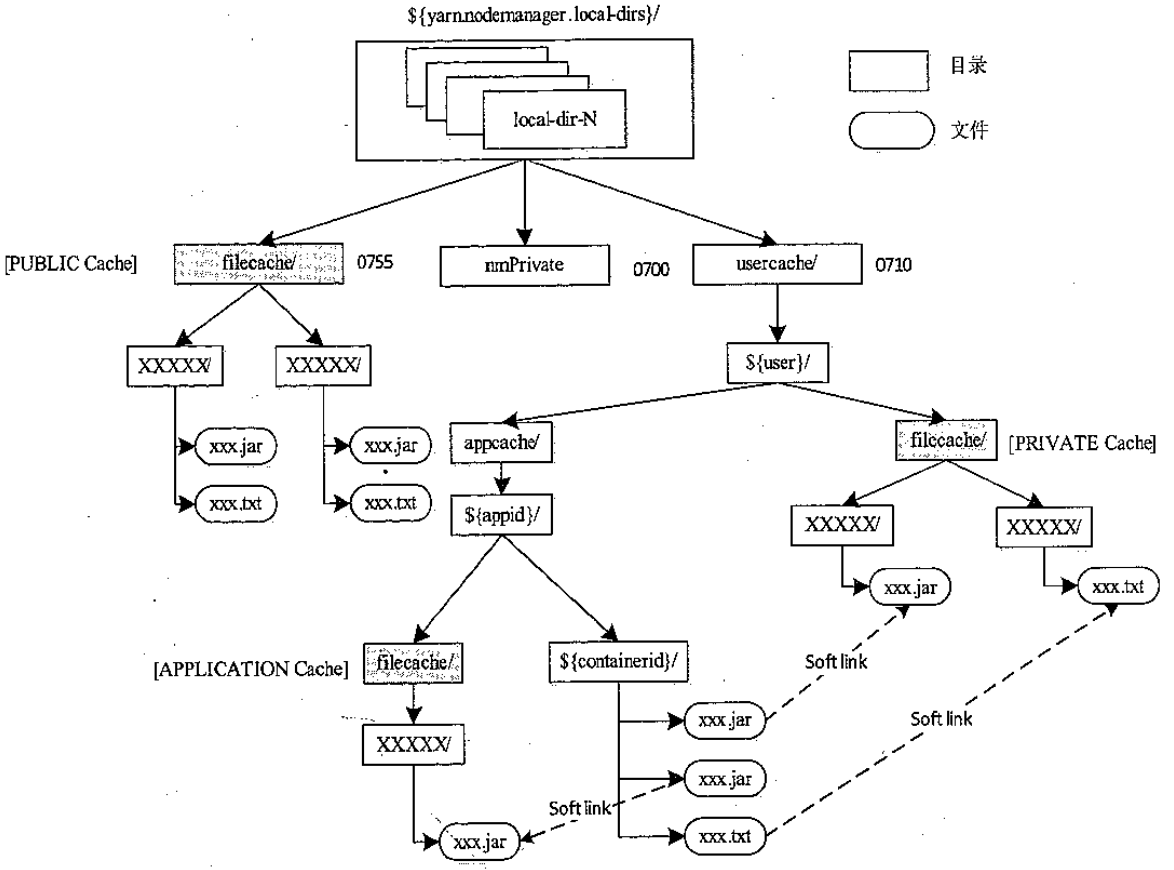
- public资源,放在${yarn.nodemanage.local-dir}/filecache 目录下
- private,${yarn.nodemanage.local-dir}/usercache/${user}/filecache 目录下
- application,${yarn.nodemanage.local-dir}/usercache/${user}/appache/${appid}/filecache 目录下
- container,${yarn.nodemanage.local-dir}/usercache/${user}/appache/${appid}/${containerid} 目录下
- container中的资源会使用软链接
NM 资源下载流程
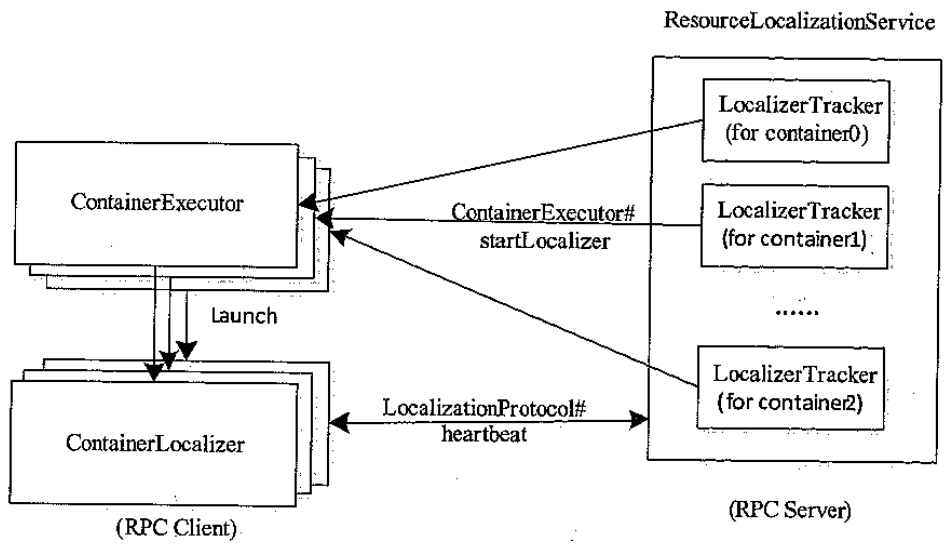
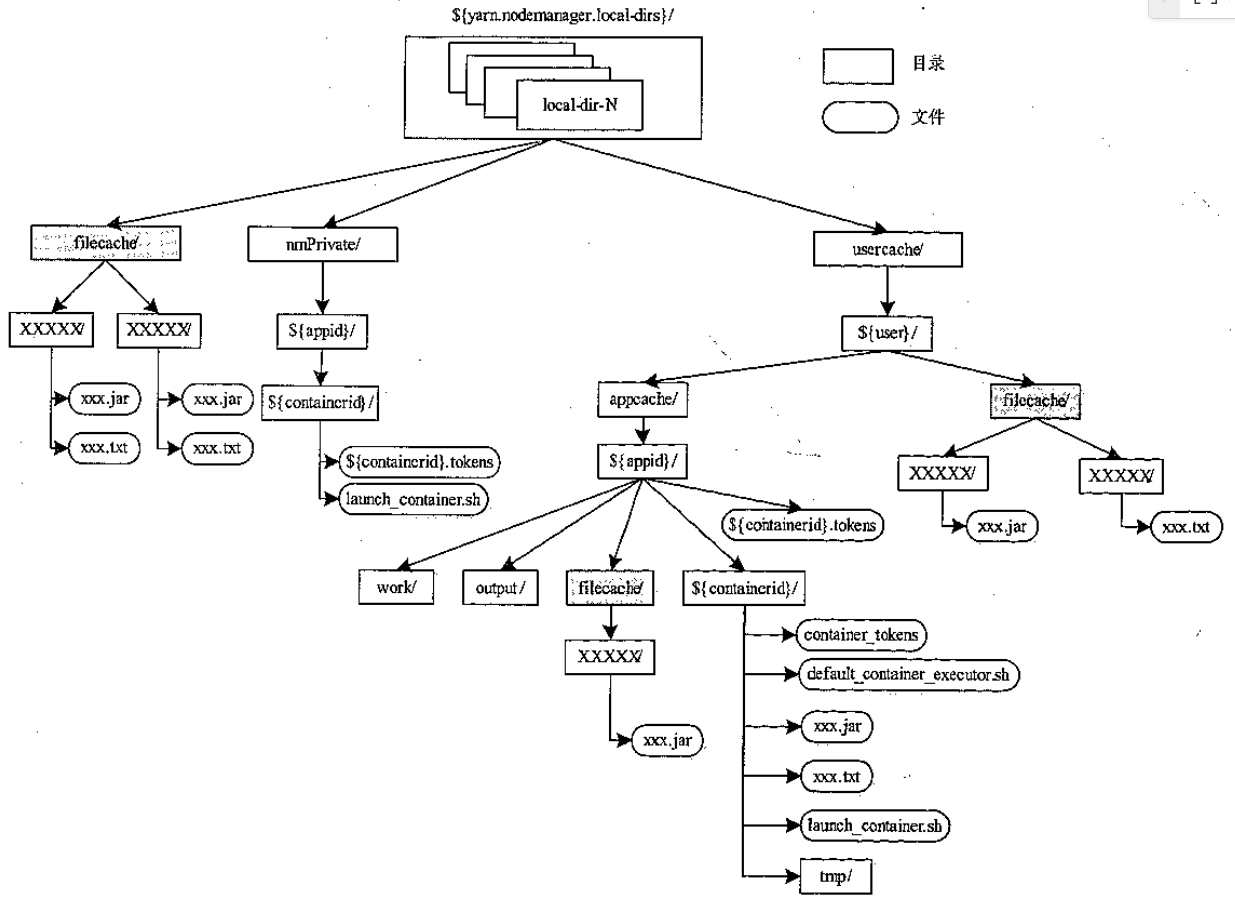
数据目录组织方式
- 可以挂 N 个盘
- 为避免竞争,将 /nmt/disk1 分给 container0,将 /nmt/disk2 分给 container1
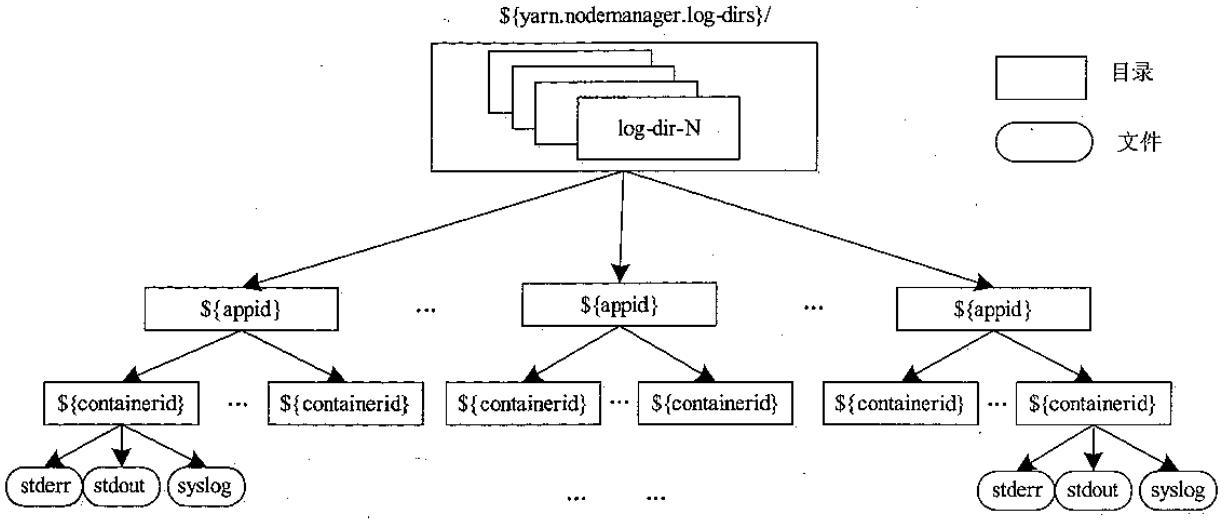
日志目录管理
- 同样也可以管理多个日志目录
- 注意是 container 运行日志,而不是 NM 服务产生的日志
- NM 的日志存放在另外的目录中
- 包括 stdout,stderr,syslog(log4j的)
- 日志也会定期清理(可配置),也提供了日志轮转
日志上传
- 本地的一旦结束,日志就会上传到 HDFS
- 支持三种,上传所有 container日志
- 上传 application master 产生的日志
- 上传am 和 container 的失败日志
- 上传之后就由 JobHistory 这样的组件负责清理了,跟 NM 没关系了
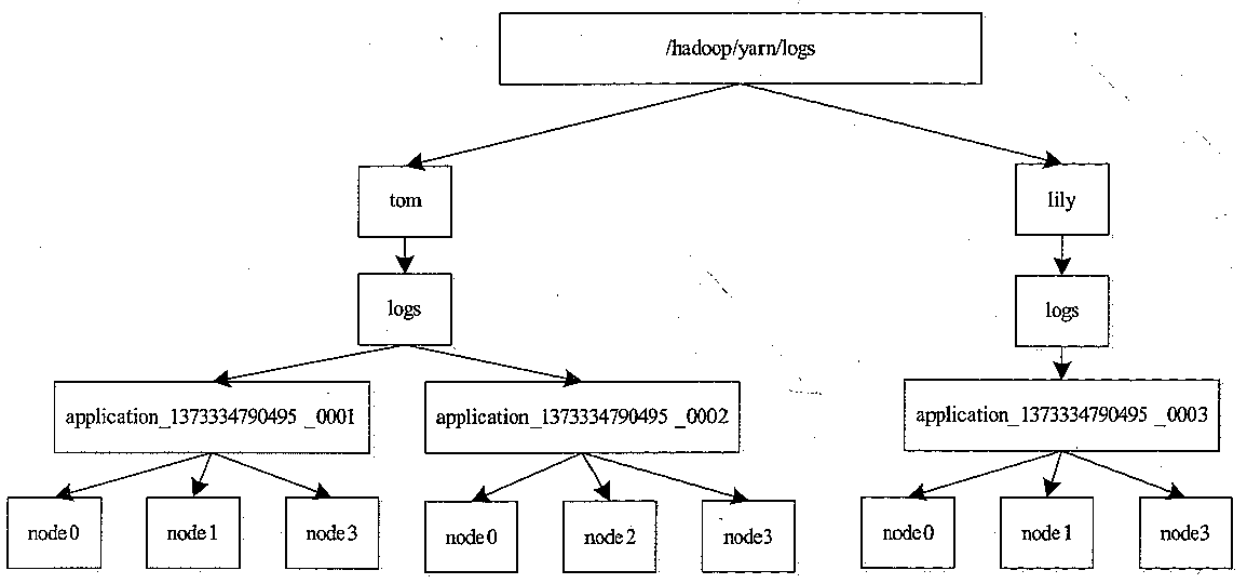
查看一个应用程序产生的所有日志,命令如下:
|
|
查看一个 Container 产生的日志,命令如下:
|
|
状态机
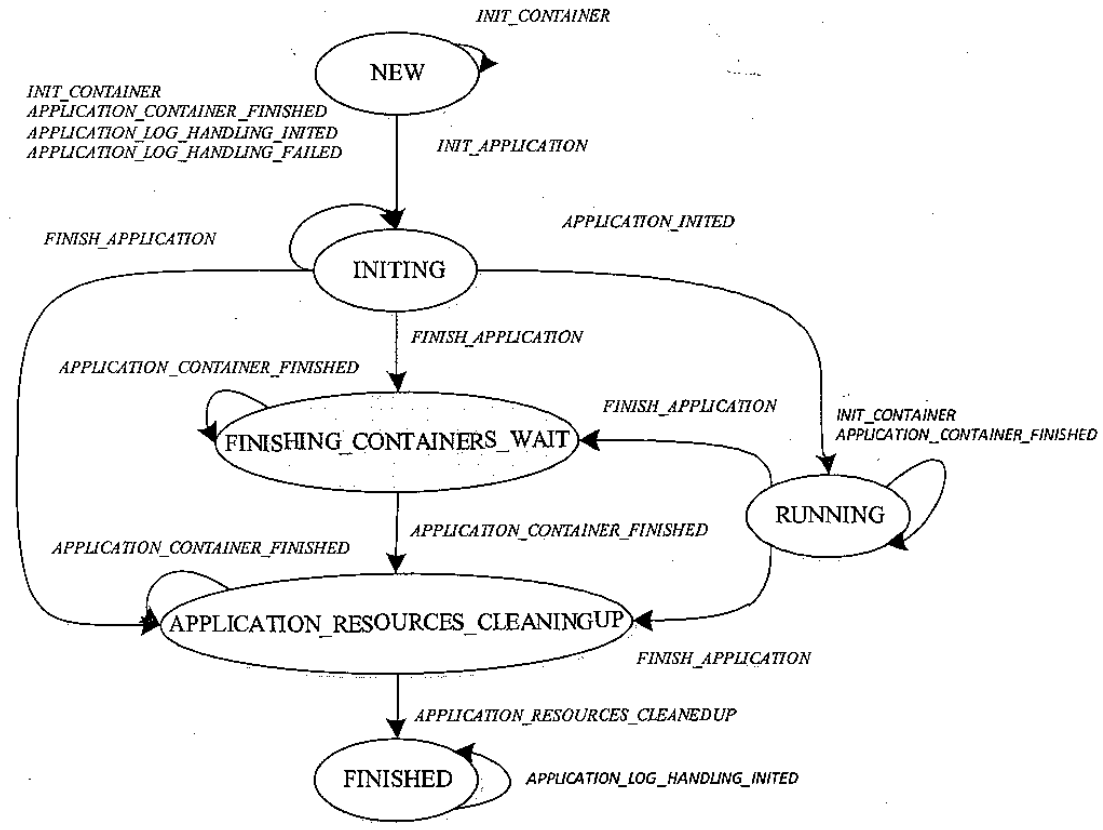
Application 状态机
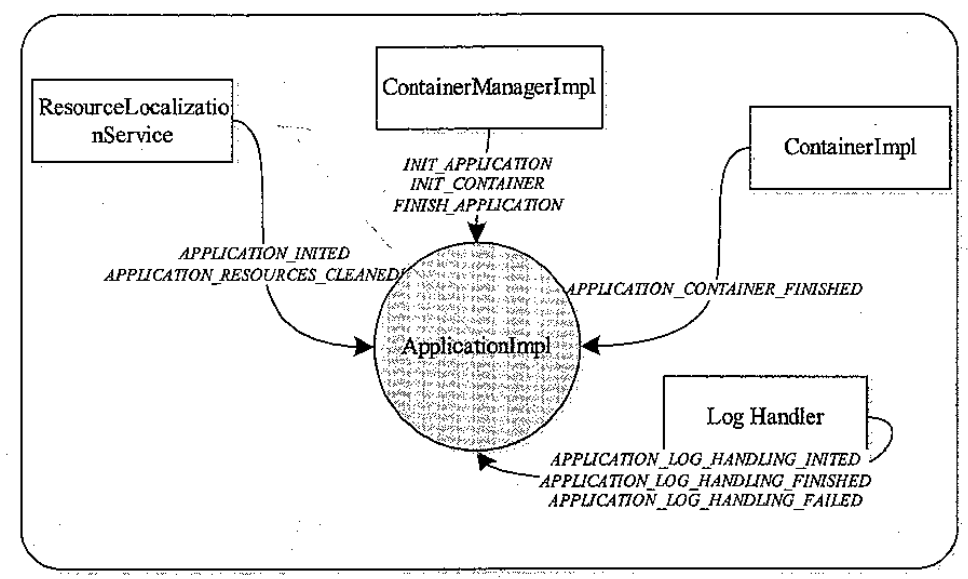
Application 状态机的事件来源
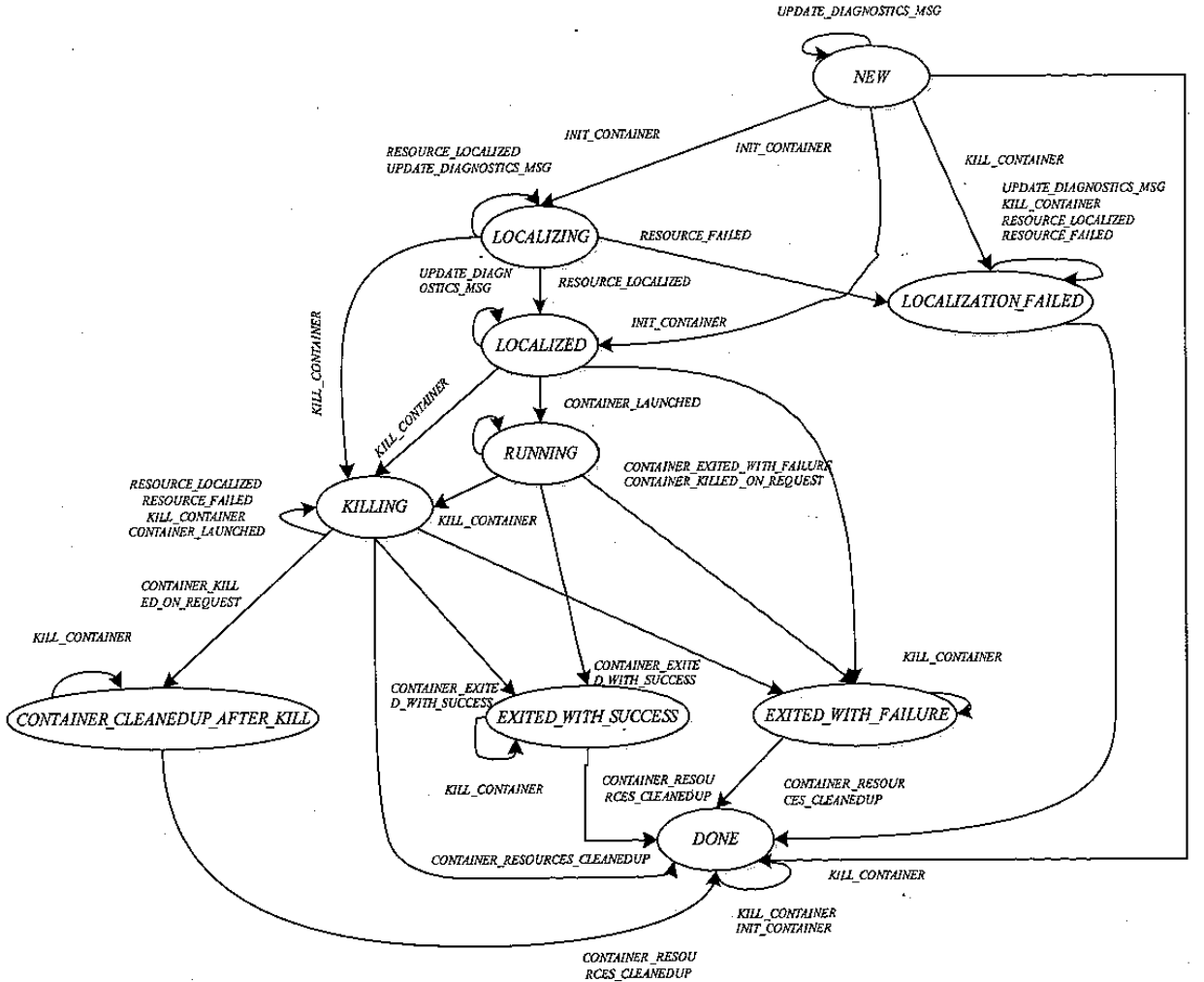
Container 状态机
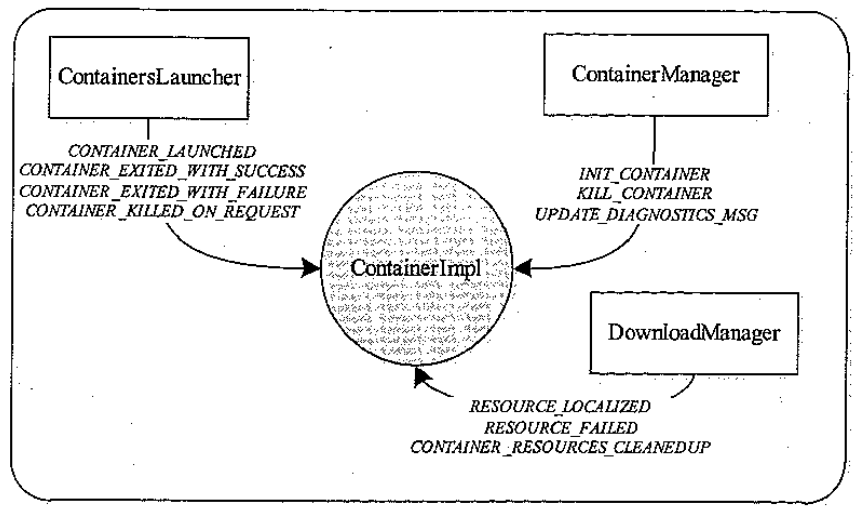
container 状态机的事件来源
LocalizedResource 状态机
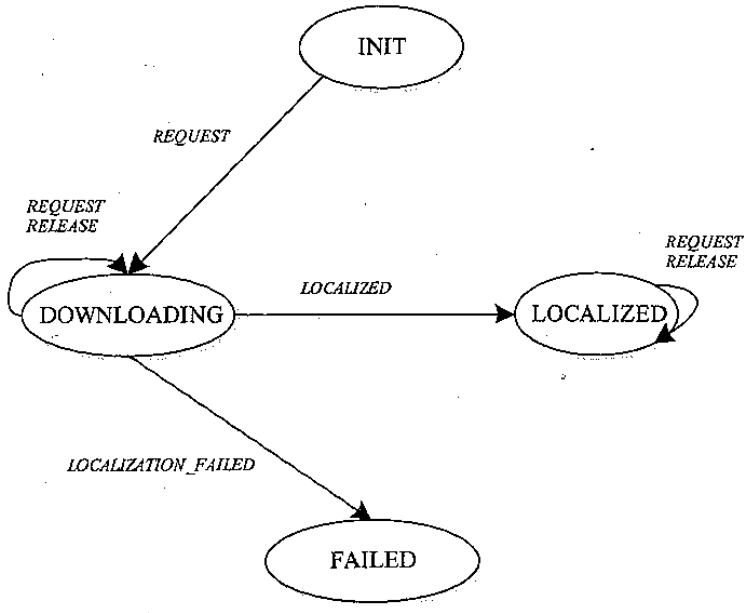
Container 管理
container启动过程主要如下:
- 资源本地化,包括应用程序初始化(日志、track,通常由第一个container完成)、container本地化
- 启动,由 ContainerLauncher 完成,进一步调用可插拔的ContainerExecutor(DefaultContainerExecutor,另一个是LinuxContainerExecutor)
- 资源清理
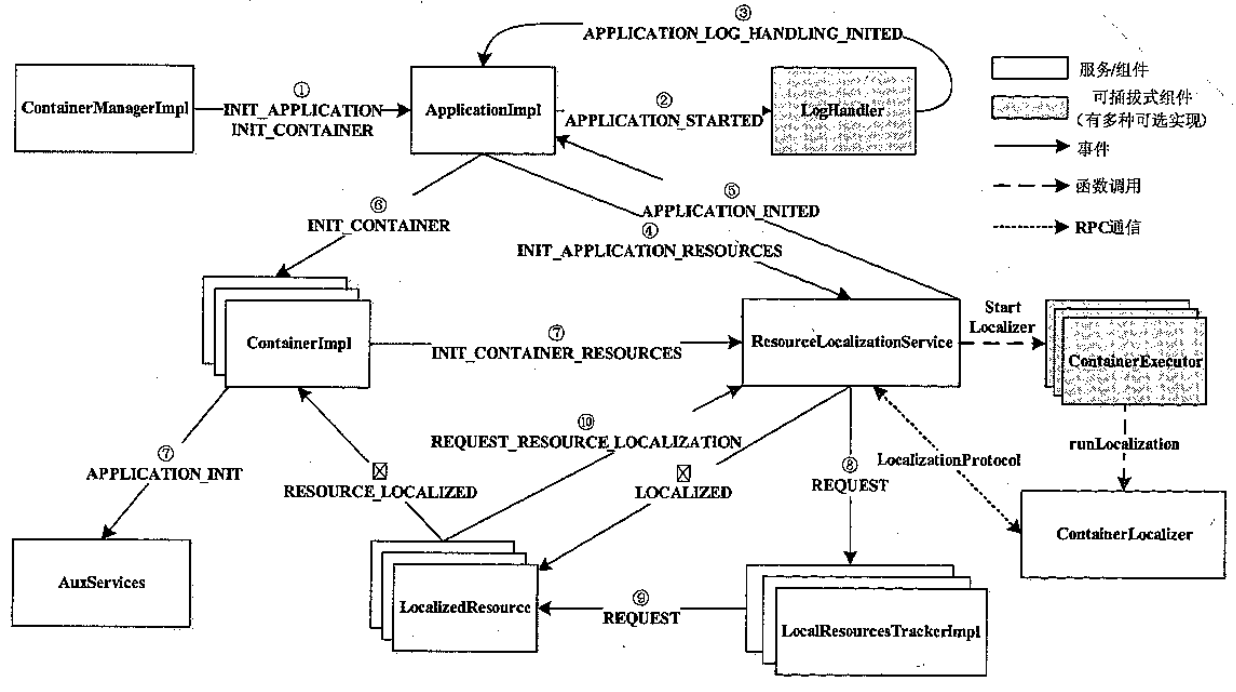
来自 ApplicationMaster 的第一个 Container 本地化过程
- ContainerManagerImpl 收到 AM的请求,创建 ContainerImpl
- ApplicationImpl 收到INIT 事件,设置 LogHandler
- ResourceLocalizationService 收到事件后,为private和appllication 资源创建 track
- ContainerImpl 收到 INIT 后向附属服务 AuxService 发送 事件,通知container启动
- 可以概括为:
- 资源本地化过程是在 NM 上同一个应用程序的所有 ContainerImpl 异步向资源服务 ResourceLoclizationService发送下载资源
- ResourceLocalizationService下载完一类资源后,通知依赖该紫苑的所有Container
- 一旦container依赖下载完,则container进入运行阶段
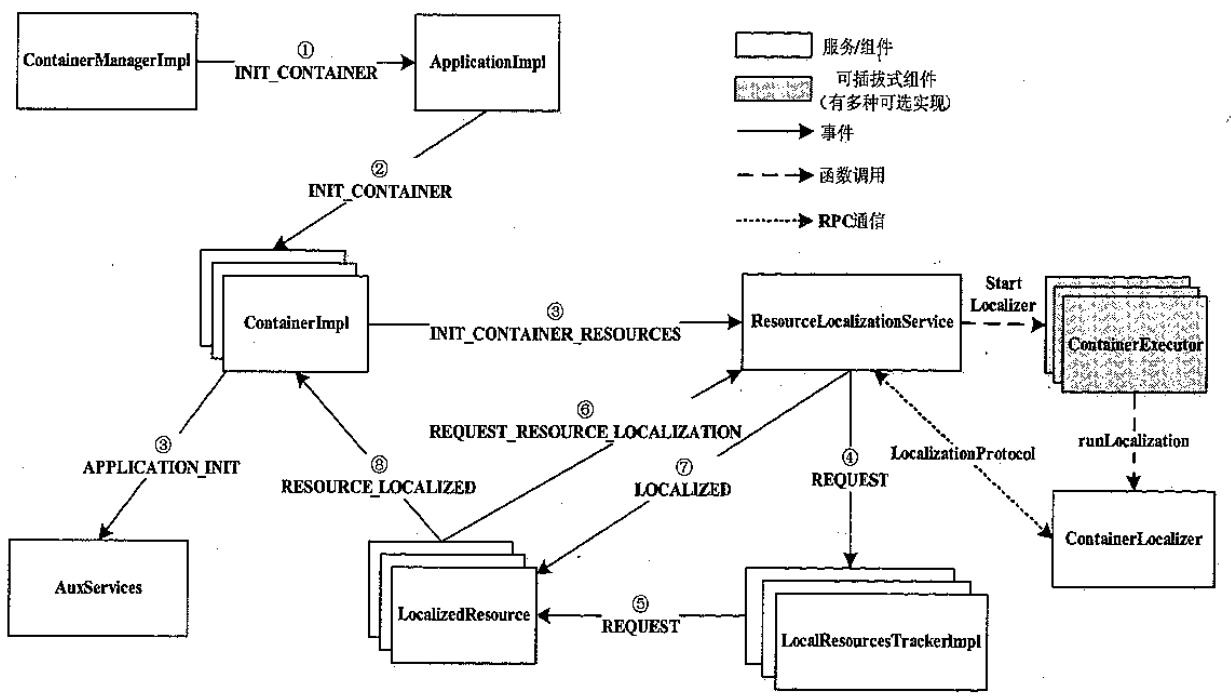
来自 ApplicationMaster 的非第一个 Container 本地化过程
- 复用之前下载过的文件
- 如果之前还有没下载完的则继续下载,之后启动
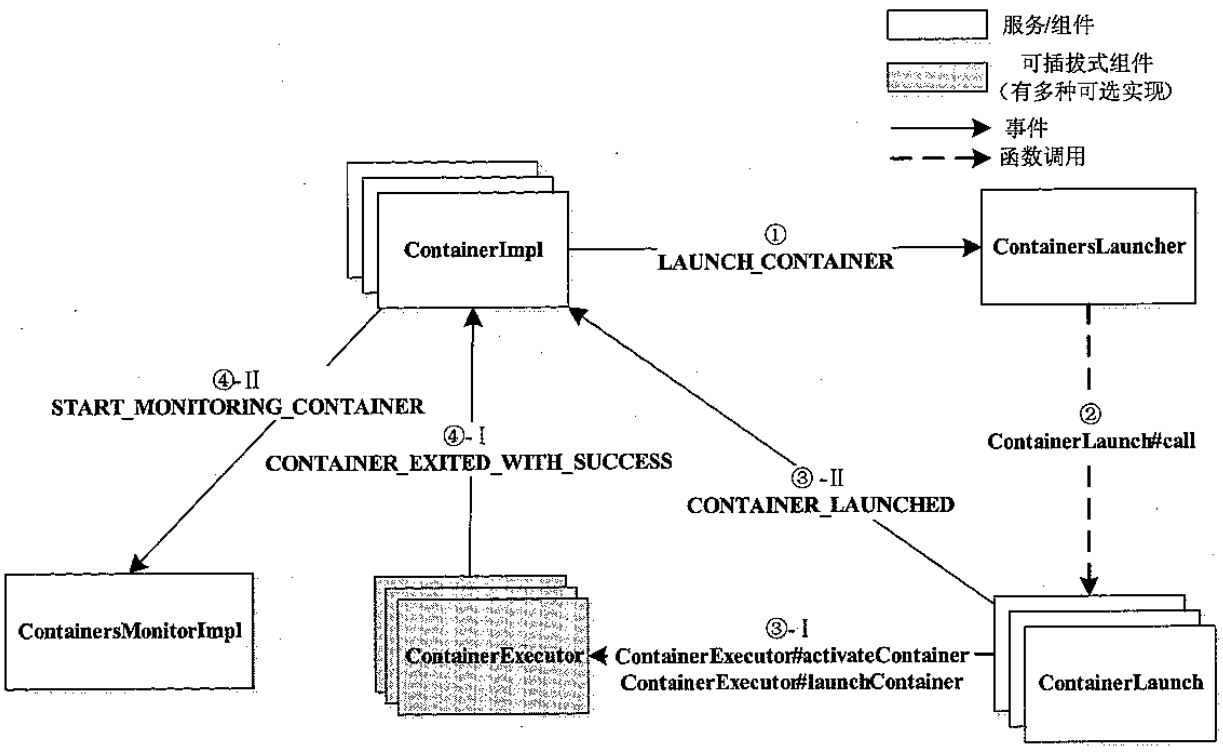
container运行过程
- 由ContainerLauncher服务实现的,将等待运行的container 所需的环境变量和运行命令写入到脚本
- launch_container.sh 中;之后将启动命令写入到 default_container_executor.sh 中,通过命令启动container
- 脚本最后会调用具体实现类,如YarnClient,如 MR的,spark的来启动真实服务
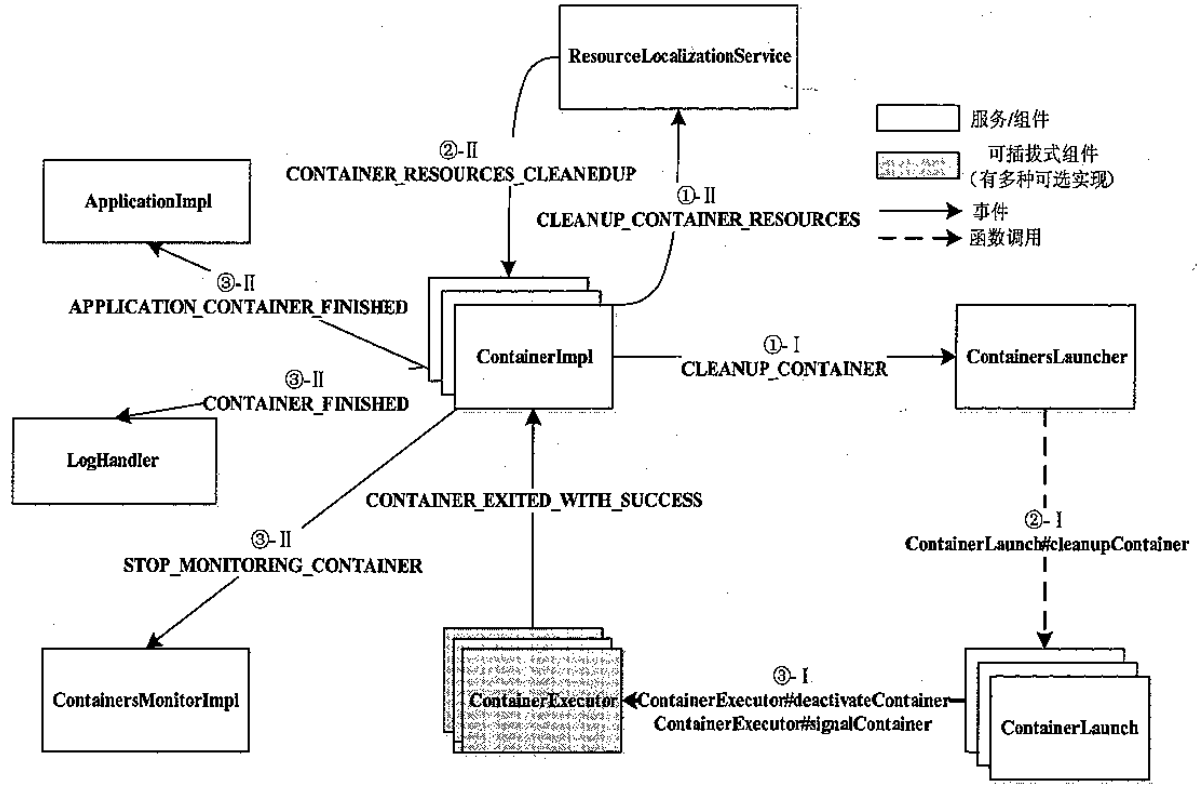
container 资源清理过程
- 会依次删除: ${yarn.nodemanager.local-dirs}/usercache/${user}/appcache/${appid}/${containerid}
- ${yarn.nodemanager.local-dirs}/nmPrivate/${user}/appcache/${appid}/${containerid}
- 这两个目录存放 tokens文件、shell 脚本
container分布
- 由于各个 container 之间可能有依赖关系,比如 shuffle
- 的中间数据,所以不会立即删除,等所有container运行完后再删除
- NM 会通知 RM,最后再由 NM 删除
资源控制
- 默认使用,独立线程监控,java启动时:fork+exec,子进程启动可能会内存翻倍,监控时额外做了判断
- 基于cgourp的方式,限制 cpu 和内存
- cgourp方式启动,java 调用了一个 c语言实现的工具类完成 启动、清理等工作