eBPF hello-world
背景
1992 年的 USENIX 会议上,Steven McCanne 和 Van Jacobson 发布的论文
- The BSD Packet Filter: A New Architecture for User-level Packet Capture
- 为 BSD 操作系统带来了革命性的包过滤机制 BSD Packet Filter
BPF的特性
- 内核态引入一个新的虚拟机,所有指令都在内核虚拟机中运行
- 用户态使用 BPF 字节码来定义过滤表达式,然后传递给内核,由内核虚拟机解释执行。
eBPF 的诞生是 BPF 技术的一个转折点,使得 BPF 不再仅限于网络栈,而是成为内核的一个顶级子系统
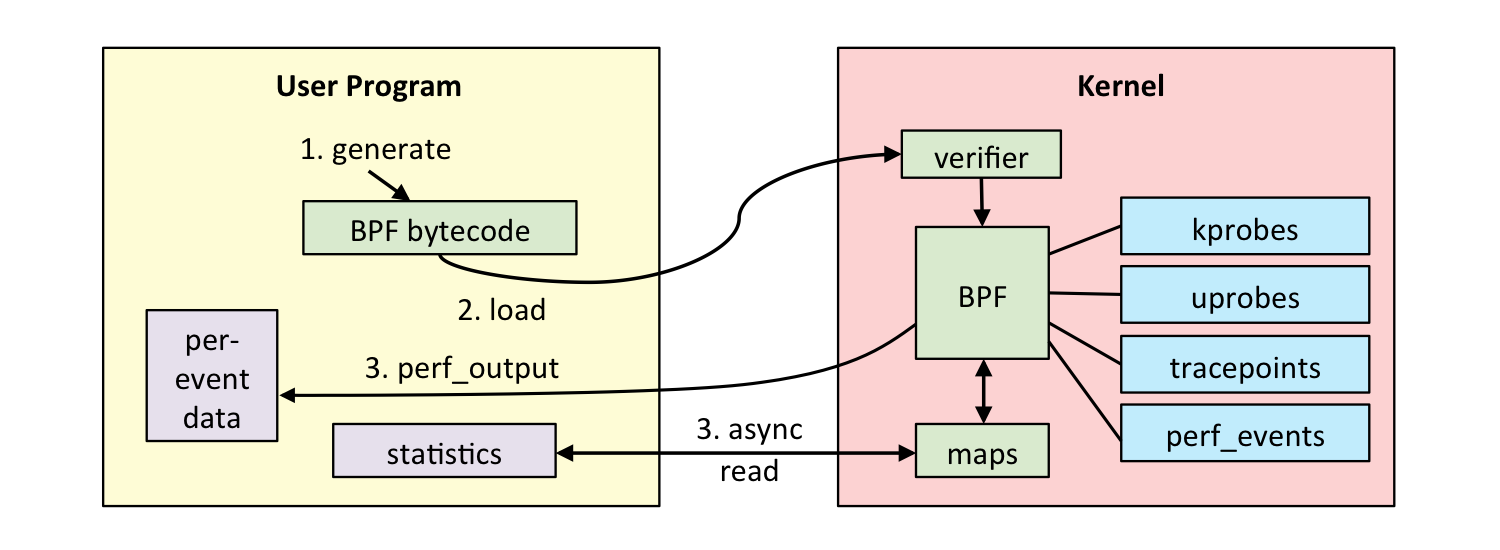
开发过程
- 使用 C 语言开发一个 eBPF 程序;
- 借助 LLVM 把 eBPF 程序编译成 BPF 字节码
- 通过 bpf 系统调用,把 BPF 字节码提交给内核
- 内核验证并运行 BPF 字节码,并把相应的状态保存到 BPF 映射中
- 用户程序通过 BPF 映射查询 BPF 字节码的运行状态。
BCC(BPF Compiler Collection)
- BCC 是一个 BPF 编译器集合,包含了用于构建 BPF 程序的编程框架和库,并提供了大量可以直接使用的工具
- 使用 BCC 的好处是,它把上述的 eBPF 执行过程通过内置框架抽象了起来
- 并提供了 Python、C++ 等编程语言接口
- 可以直接通过 Python 语言去跟 eBPF 的各种事件和数据进行交互
BPF程序可以利用 BPF 映射(map)进行存储,而用户程序通常也需要通过 BPF 映射同运行在内核中的 BPF 程序进行交互
在性能观测中,BPF 程序收集内核运行状态存储在映射中,用户程序再从映射中读出这些状态
例子
hello-world
安装 Ubuntu 24.04.2 LTS
系统内核
|
|
安装相关的工具
|
|
Key packages:
- libelf-dev and libbpf-dev: For eBPF program compilation.
- python3-bpfcc and bpfcc-tools: BCC framework tools for eBPF development.
- linux-headers-$(uname -r): Kernel headers matching your kernel version
c 代码
|
|
python 代码
|
|
以上代码工作过程:
- 处导入了 BCC 库的 BPF 模块,以便接下来调用
- 处调用 BPF() 加载第一步开发的 BPF 源代码
- 处将 BPF 程序挂载到内核探针(简称 kprobe),其中 do_sys_openat2() 是系统调用 openat() 在内核中的实现
- 处则是读取内核调试文件 /sys/kernel/debug/tracing/trace_pipe 的内容,并打印到标准输出中。
当然,也可以将 c 代码嵌入到 python 中
|
|
运行
|
|
结果
|
|
输出的格式可由 /sys/kernel/debug/tracing/trace_options 来修改。前面这个默认的输出中,每个字段的含义如下所示:
- <…>-3726 表示进程的名字和 PID;
- [000] 表示 CPU 编号;
- … 表示一系列的选项;
- 1383.099335 表示时间戳;
- bpf_trace_printk 表示函数名;
- 最后的 “Hello, World!” 就是调用 bpf_trace_printk() 传入的字符串
改进
trace-open.c 代码
|
|
trace-open.py 代码
|
|
执行结果
|
|
c 代码执行
完整的例子
|
|
Makefile
|
|
安装必要的组件
|
|
执行
|
|
输出结果
|
|
Comparison with BCC
| Aspect | This Code | BCC - Based Approach |
|---|---|---|
| Complexity | Manual kernel module setup. | Uses Python/BPF scripts for simplicity. |
| Execution | Context Pure kernel space. | Combines user - space (Python) and kernel - space (BPF). |
| Overhead | Higher (requires module compilation). | Lower (dynamic loading via BPF). |
| Flexibility | Direct control over kprobes. | Limited by BPF’s sandboxed environment |
安全性
- bcc是编译了限制的字节码
- 之后又有校验,所以更安全
- 而直接 kprobe 方式绕过了上述限制,直接注入到内核所以不安全
原理
执行过程
下图,来自 BPF Internals
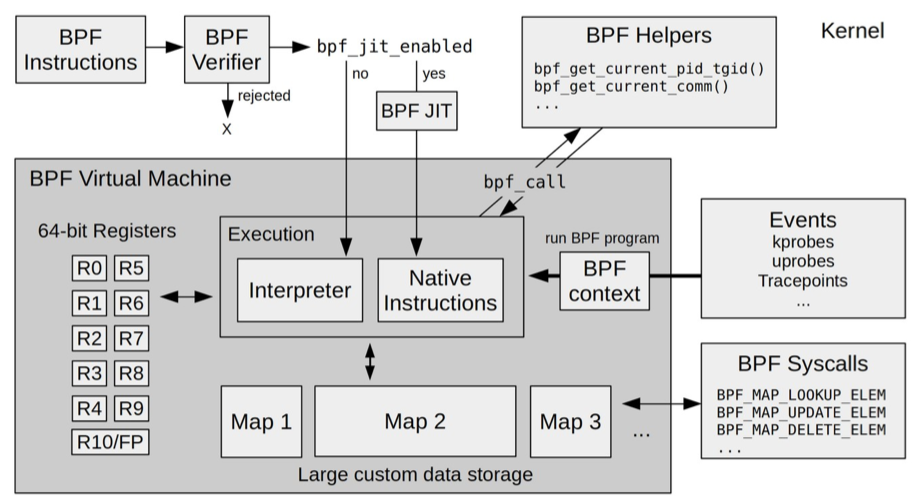 解释
解释
- 第一个模块是 eBPF 辅助函数。它提供了一系列用于 eBPF 程序与内核其他模块进行交互的函数。这些函数并不是任意一个 eBPF 程序都可以调用的,具体可用的函数集由 BPF 程序类型决定
- 第二个模块是 eBPF 验证器。它用于确保 eBPF 程序的安全。验证器会将待执行的指令创建为一个有向无环图(DAG),确保程序中不包含不可达指令;接着再模拟指令的执行过程,确保不会执行无效指令
- 第三个模块是由 11 个 64 位寄存器、一个程序计数器和一个 512 字节的栈组成的存储模块。这个模块用于控制 eBPF 程序的执行。其中,R0 寄存器用于存储函数调用和 eBPF 程序的返回值,这意味着函数调用最多只能有一个返回值;R1-R5 寄存器用于函数调用的参数,因此函数调用的参数最多不能超过 5 个;而 R10 则是一个只读寄存器,用于从栈中读取数据
- 第四个模块是即时编译器,它将 eBPF 字节码编译成本地机器指令,以便更高效地在内核中执行
- 第五个模块是 BPF 映射(map),它用于提供大块的存储。这些存储可被用户空间程序用来进行访问,进而控制 eBPF 程序的运行状态。
指令
BPF 指令
查询 hello world 程序
|
|
这里的 60 就是 id,然后查询
|
|
结果
|
|
解释
- 第一部分,冒号前面的数字 0-12 ,代表 BPF 指令行数
- 第二部分,括号中的 16 进制数值,表示 BPF 指令码。,比如第 0 行的 0xb7 表示为 64 位寄存器赋值
- 第三部分,括号后面的部分,就是 BPF 指令的伪代码。
这些 BPF 指令的含义:
- 第 0-8 行,借助 R10 寄存器从栈中把字符串 “Hello, World!” 读出来,并放入 R1 寄存器中
- 第 9 行,向 R2 寄存器写入字符串的长度 14(即代码注释里面的 sizeof(_fmt) )
- 第 10 行,调用 BPF 辅助函数 bpf_trace_printk 输出字符串
- 第 11 行,向 R0 寄存器写入 0,表示程序的返回值是 0
- 最后一行,程序执行成功退出。
总结
- 这些指令先通过 R1 和 R2 寄存器设置了 bpf_trace_printk 的参数
- 然后调用 bpf_trace_printk 函数输出字符串,最后再通过 R0 寄存器返回成功
BPF 指令
BPF指令加载到内核后,jit 会编译成机器指令,x86的类似于
|
|
strace 跟踪一下
|
|
打印的结果
|
|
编程接口
bpf 系统调用
用户态负责 eBPF 程序的加载、事件绑定以及 eBPF 程序运行结果的汇总输出;内核态运行在 eBPF 虚拟机中,负责定制和控制系统的运行状态
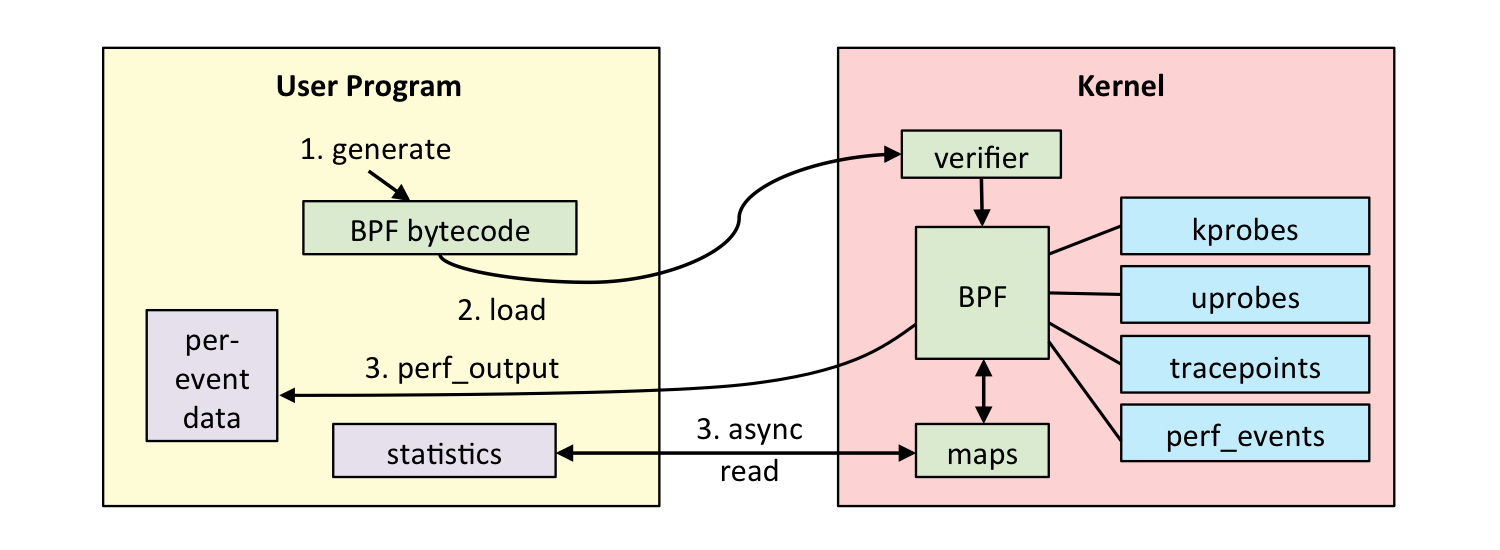
用户态和内核态交互就必须用bpf系统调用
|
|
BPF 系统调用接受三个参数:
- cmd ,代表操作命令,比如上一讲中我们看到的 BPF_PROG_LOAD 就是加载 eBPF 程序
- attr,代表 bpf_attr 类型的 eBPF 属性指针,不同类型的操作命令需要传入不同的属性参数
- size ,代表属性的大小
6.14支持的 command
|
|
常用的命令:
| BPF 命令 | 功能描述 |
|---|---|
| BPF_MAP_CREATE | 创建一个 BPF 映射 |
| BPF_MAP_LOOKUP_ELEM BPF_MAP_UPDATE_ELEMBPF_MAP_DELETE_ELEM BPF_MAP_LOOKUP_AND_DELETE_ELEM BPF_MAP_GET_NEXT_KEY | BPF 映射相关的操作命令,包括查找、更新、删除以及遍历等 |
| BPF_PROG_LOAD | 验证并加载 BPF 程序 |
| BPF_PROG_ATTACHBPF_PROG_DETACH | 把 BPF 程序挂载到内核事件上把 BPF 程序从内核事件上卸载 |
| BPF_OBJ_PIN | 把 BPF 程序或映射挂载到 sysfs 中的 /sys/fs/bpf 目录中(常用于保持 BPF 程序在内核中贮存) |
| BPF_OBJ_GET | 从 /sys/fs/bpf 目录中查找 BPF 程序 |
| BPF_BTF_LOAD | 验证并加载 BTF 信息 |
辅助函数
辅助函数
- eBPF 程序并不能随意调用内核函数
- 内核定义了一系列的辅助函数,用于 eBPF 程序与内核其他模块进行交互
通过bpftool feature probe 可以查询当前系统支持的 辅助函数列表
辅助函数非常多,6.11 内核打印的结果如下:
|
|
通过man bpf-helpers 可以查看每个辅助函数的细节
常用的辅助函数
| 辅助函数 | 功能描述 |
|---|---|
bpf_trace_printk(fmt, fmt_size, ...) |
向调试文件系统写入调试信息 |
bpf_map_lookup_elem(map, key)bpf_map_update_elem(map, key, value, flags)bpf_map_delete_elem(map, key) |
BPF 映射操作函数,分别是查找、更新和删除元素 |
bpf_probe_read(dst, size, ptr)bpf_probe_read_user(dst, size, ptr)bpf_probe_read_kernel(dst, size, ptr) |
从内存指针中读取数据从用户空间内存指针中读取数据从内核空间内存指针中读取数据 |
bpf_probe_read_str(dst, size, ptr)bpf_probe_read_user_str(dst, size, ptr)bpf_probe_read_kernel_str(dst, size, ptr) |
从内存指针中读取字符串从用户空间内存指针中读取字符串从内核空间内存指针中读取字符串 |
bpf_ktime_get_ns() |
获取系统启动以来的时长,单位纳秒 |
bpf_get_current_pid_tgid() |
获取当前线程的 TGID(高32位)和 PID(低32位) |
bpf_get_current_comm(buf, size) |
获取当前线程的任务名称 |
bpf_get_current_task() |
获取当前任务的 task 结构体 |
bpf_perf_event_output(ctx, map, flags, data, size) |
向性能事件缓冲区中写入数据 |
bpf_get_stackid(ctx, map, flags) |
获取内核态和用户态调用栈 |
bpf_probe_read 函数
- eBPF 内部的内存空间只有寄存器和栈。
- 要访问其他的内核空间或用户空间地址,就需要借助 bpf_probe_read 这一系列的辅助函数
- 这些函数会进行安全性检查,并禁止缺页中断的发生
映射
介绍
- BPF 映射用于提供大块的键值存储
- 这些存储可被用户空间程序访问,进而获取 eBPF 程序的运行状态
- eBPF 程序最多可以访问 64 个不同的 BPF 映射
- 并且不同的 eBPF 程序也可以通过相同的 BPF 映射来共享它们的状态
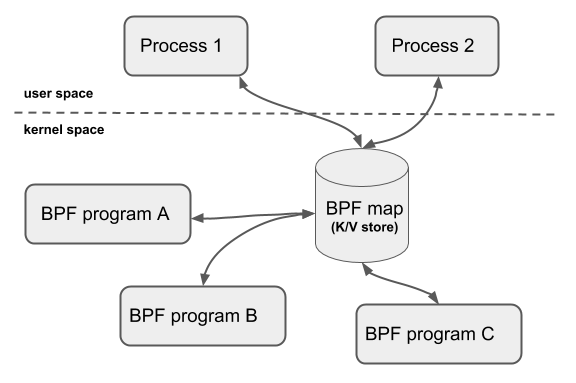
BPF 辅助函数中并没有 BPF 映射的创建函数,BPF 映射只能通过用户态程序的系统调用来创建
|
|
支持的映射类型
|
|
参考内核头文件:include/uapi/linux/bpf.h
常用的映射类型及其功能和使用场景
| 映射类型 | 功能描述 |
|---|---|
| BPF_MAP_TYPE_HASH | 哈希表映射,用于保存 key/value 对 |
| BPF_MAP_TYPE_LRU_HASH | 类似于哈希表映射,但在表满的时候自动按 LRU 算法删除最久未被使用的元素 |
| BPF_MAP_TYPE_ARRAY | 数组映射,用于保存固定大小的数组(注意数组元素无法删除) |
| BPF_MAP_TYPE_PROG_ARRAY | 程序数组映射,用于保存 BPF 程序的引用,特别适合于尾调用(即调用其他 eBPF 程序) |
| BPF_MAP_TYPE_PERF_EVENT_ARRAY | 性能事件数组映射,用于保存性能事件跟踪记录 |
| BPF_MAP_TYPE_PERCPU_HASHBPF_MAP_TYPE_PERCPU_ARRAY | 每个 CPU 单独维护的哈希表和数组映射 |
| BPF_MAP_TYPE_STACK_TRACE | 调用栈跟踪映射,用于存储调用栈信息 |
| BPF_MAP_TYPE_ARRAY_OF_MAPSBPF_MAP_TYPE_HASH_OF_MAPS | 映射数组和映射哈希,用于保存其他映射的引用 |
| BPF_MAP_TYPE_CGROUP_ARRAY | CGROUP 数组映射,用于存储 cgroups 引用 |
| BPF_MAP_TYPE_SOCKMAP | 套接字映射,用于存储套接字引用,特别适用于套接字重定向 |
比如 BCC 的预制的映射函数
|
|
通过以下方式来创建
|
|
BPF 映射会在用户态程序关闭文件描述符的时候自动删除(即close(fd) )
想在程序退出后还保留映射,就需要调用 BPF_OBJ_PIN 命令,将映射挂载到 /sys/fs/bpf 中
通过命令来创建管理映射
|
|
类型格式
内核头文件 linux-headers-$(uname -r) 也是必须要安装的一个依赖项
因为 BCC 在编译 eBPF 程序时,需要从内核头文件中找到相应的内核数据结构定义
主要有这三个方面:
- 在开发 eBPF 程序时,为了获得内核数据结构的定义,就需要引入一大堆的内核头文件
- 内核头文件的路径和数据结构定义在不同内核版本中很可能不同。因此,你在升级内核版本时,就会遇到找不到头文件和数据结构定义错误的问题
- 生产环境以你为安全,不允许安装内核头文件,无法得到内核数据结构的定义。在程序中重定义数据结构虽然可以暂时解决这个问题,但也很容易把使用着错误数据结构的 eBPF 程序带入新版本内核中运行。
= 5.2 版本的内核中就自动内嵌在内核二进制文件 vmlinux 中
导出命令
|
|
在开发 eBPF 程序时只需要引入一个 vmlinux.h 即可,不用再引入一大堆的内核头文件
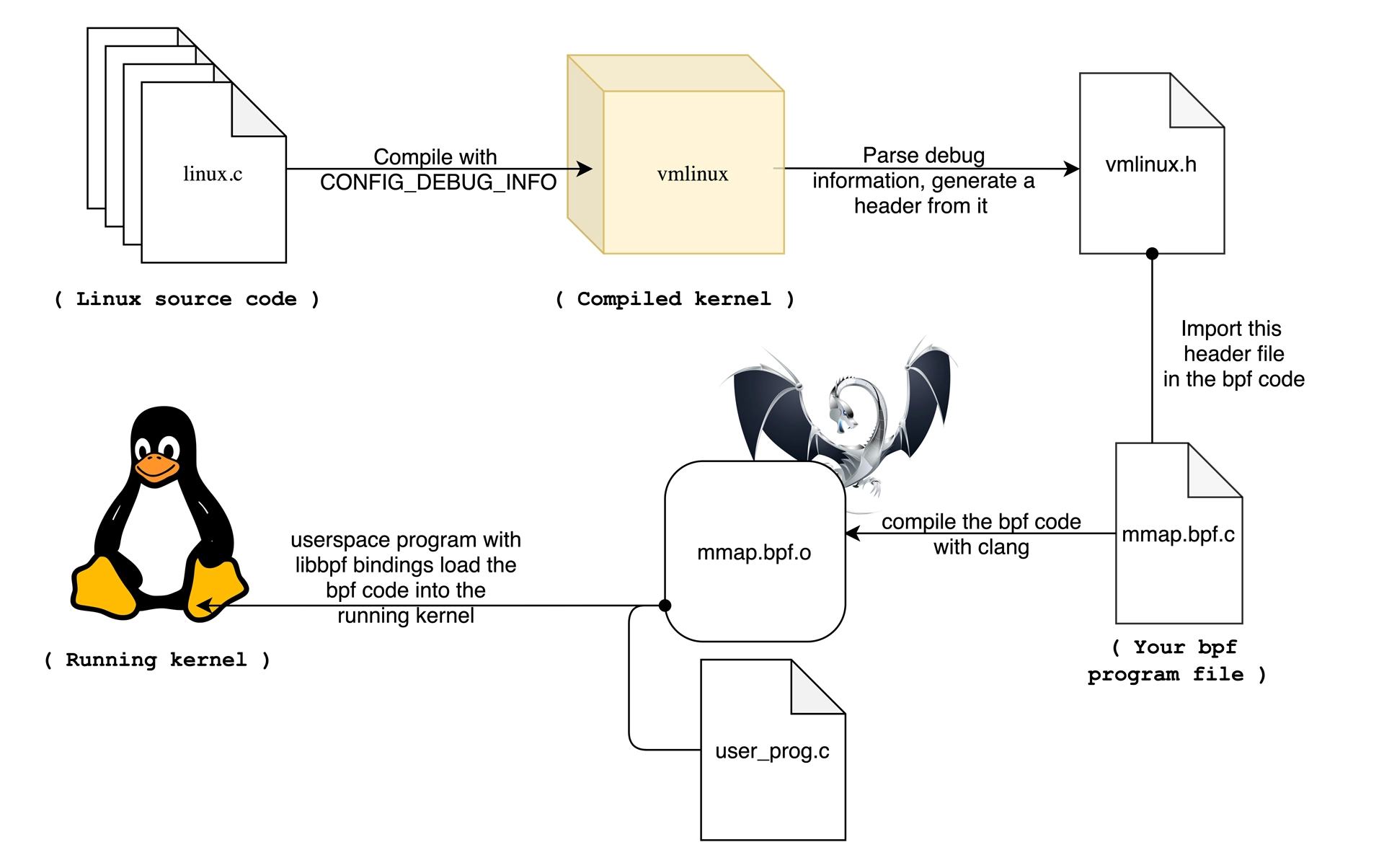 GRANT SELTZER 博客
GRANT SELTZER 博客
一些例子
create_map 例子
|
|
编译执行
|
|
perf_event_open 函数
|
|
打印结果:
|
|
BPF 与性能事件的绑定过程分为以下几步:
- 首先,借助 bpf 系统调用,加载 BPF 程序,并记住返回的文件描述符;
- 然后,查询 kprobe 类型的事件编号。BCC 实际上是通过 /sys/bus/event_source/devices/kprobe/type 来查询的;
- 接着,调用 perf_event_open 创建性能监控事件。比如,事件类型(type 是上一步查询到的 6)、事件的参数( config1 包含了内核函数 do_sys_openat2 )等;
- 最后,再通过 ioctl 的 PERF_EVENT_IOC_SET_BPF 命令,将 BPF 程序绑定到性能监控事件。
各类事件
事件类型
6.13内核支持的事件类型
|
|
查询当前系统支持的类型
|
|
结果
|
|
这些程序类型大致可以划分为三类:
- 跟踪,即从内核和程序的运行状态中提取跟踪信息,来了解当前系统正在发生什么
- 网络,即对网络数据包进行过滤和处理,以便了解和控制网络数据包的收发过程
- 除跟踪和网络之外的其他类型,包括安全控制、BPF 扩展等等
跟踪类 eBPF 程序
跟踪类 eBPF 程序主要用于从系统中提取跟踪信息,进而为监控、排错、性能优化等提供数据支撑
比如
- BPF_PROG_TYPE_KPROBE 类型的跟踪程序,它的目的是跟踪内核函数是否被某个进程调用了
- KPROBE、TRACEPOINT 以及 PERF_EVENT 都是最常用的 eBPF 程序类型
- 大量应用于监控跟踪、性能优化以及调试排错等场景中
| 程序类型 | 功能描述 | 功能限制 |
|---|---|---|
| BPF_PROG_TYPE_KPROBE | 用于对特定函数进行动态插桩,根据函数位置的不同,又可以分为内核态 kprobe 和用户态 uprobe | 内核函数和用户函数的定义属于不稳定 API,在不同内核版本中使用时,可能需要调整 eBPF 代码实现 |
| BPF_PROG_TYPE_TRACEPOINT | 用于内核静态跟踪点(可以使用 perf list 命令,查询所有的跟踪点) | 虽然跟踪点可以保持稳定性,但不如 KPROBE 类型灵活,无法按需增加新的跟踪点 |
| BPF_PROG_TYPE_PERF_EVENT | 用于性能事件(perf_events)跟踪,包括内核调用、定时器、硬件等各类性能数据 | 需配合 BPF_MAP_TYPE_PERF_EVENT_ARRAY 或 BPF_MAP_TYPE_RINGBUF 类型的映射使用 |
| BPF_PROG_TYPE_RAW_TRACEPOINT BPF_PROG_TYPE_RAW_TRACEPOINT_WRITABLE | 用于原始跟踪点 | 不处理参数 |
| BPF_PROG_TYPE_TRACING | 用于开启 BTF 的跟踪点 | 需要开启 BTF |
网络类 eBPF 程序
根据事件触发位置的不同,网络类 eBPF 程序又可以分为
- XDP(eXpress Data Path,高速数据路径)程序
- TC(Traffic Control,流量控制)程序
- 套接字程序
- cgroup 程序
XDP
XDP 程序
- 类型定义为 BPF_PROG_TYPE_XDP
- 它在网络驱动程序刚刚收到数据包时触发执行
- 由于无需通过繁杂的内核网络协议栈,XDP 程序可用来实现高性能的网络处理方案
- 常用于 DDoS 防御、防火墙、4 层负载均衡等场
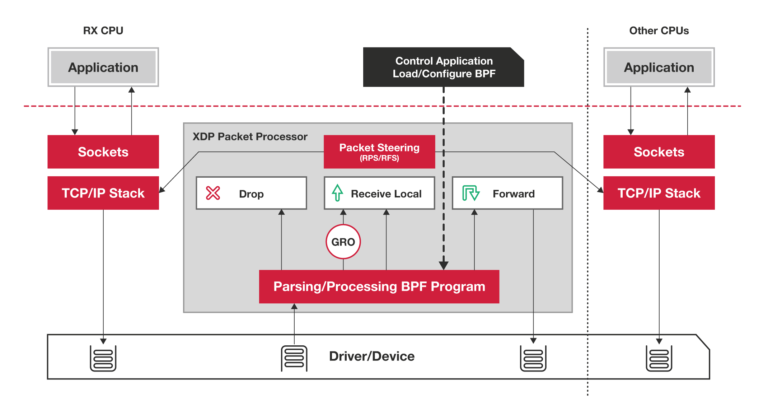
根据网卡和网卡驱动是否原生支持 XDP 程序,XDP 运行模式可以分为下面这三种:
- 通用模式。它不需要网卡和网卡驱动的支持,XDP 程序像常规的网络协议栈一样运行在内核中,性能相对较差,一般用于测试
- 原生模式。它需要网卡驱动程序的支持,XDP 程序在网卡驱动程序的早期路径运行
- 卸载模式。它需要网卡固件支持 XDP 卸载,XDP 程序直接运行在网卡上,而不再需要消耗主机的 CPU 资源,具有最好的性能。
| 结果码 | 含义 | 使用场景 |
|---|---|---|
| XDP_DROP | 丢包 | 数据包尽早丢弃可减少 CPU 处理时间,常用于防火墙、DDoS 防御等丢弃非法包场景 |
| XDP_PASS | 传递到内核协议栈 | 内核协议栈接收网络包,按正常流程继续处理 |
| XDP_TX XDP_REDIRECT | 转发数据包到同一 / 不同网卡 | XDP 程序修改数据包后转发到网卡,按内核协议栈流程处理,常用在负载均衡中 |
| XDP_ABORTED | 错误 | XDP 程序运行错误时,丢弃数据包并记录错误行为以便排错 |
XDP 程序通过 ip link 命令加载到具体的网卡上,加载格式为
|
|
BCC 也提供了方便的库函数,可以在同一个程序中管理 XDP 程序的生命周期
|
|
TC
TC 程序
- 类型定义为 BPF_PROG_TYPE_SCHED_CLS 和 BPF_PROG_TYPE_SCHED_ACT
- 分别作为 Linux 流量控制 的分类器和执行器
- Linux 流量控制通过网卡队列、排队规则、分类器、过滤器以及执行器等
- 实现了对网络流量的整形调度和带宽控制。
下图展示了 HTB(Hierarchical Token Bucket,层级令牌桶)流量控制的工作原理
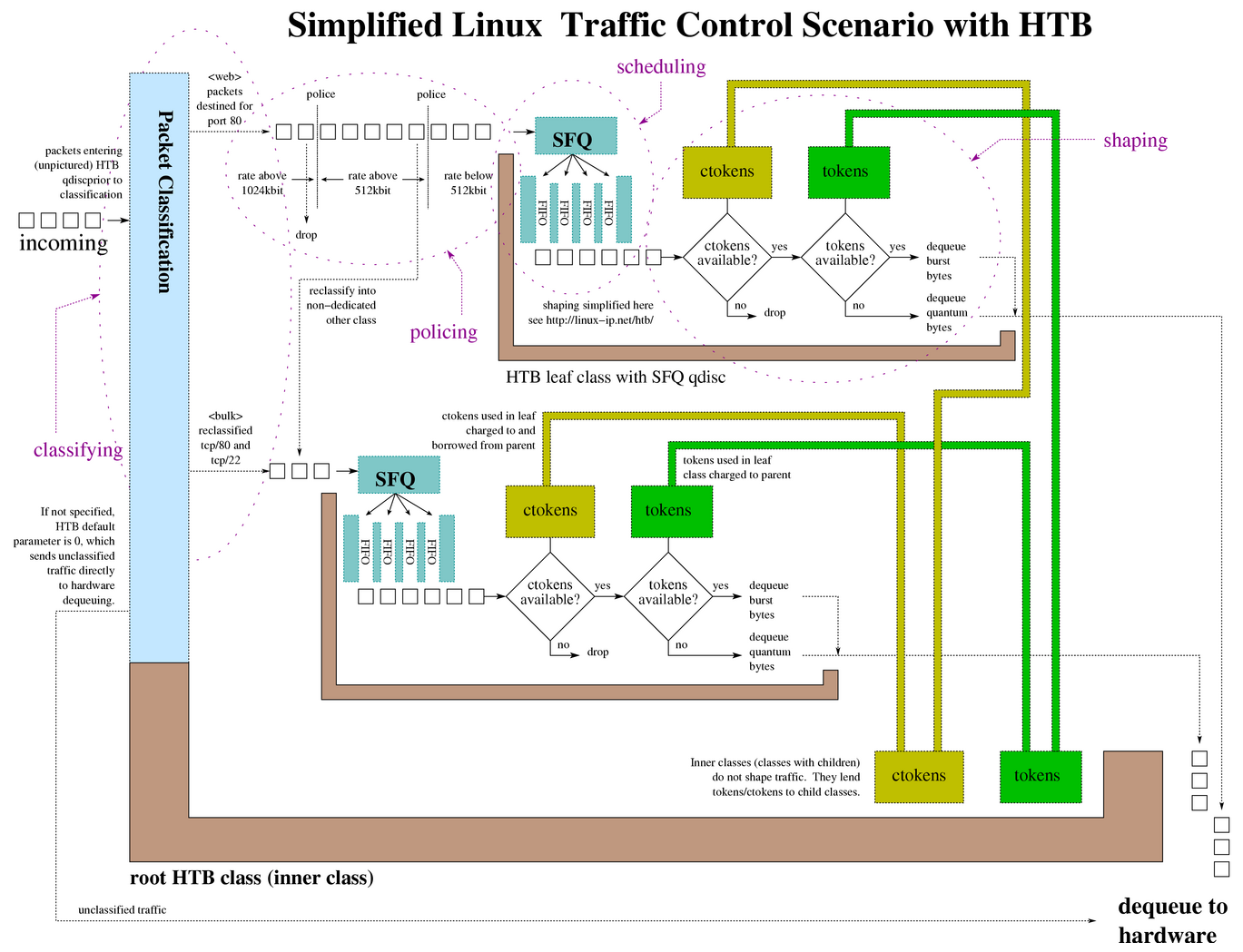 Traffic Control HOWTO
Traffic Control HOWTO
TC 程序可以直接在一个程序内完成分类和执行的动作,而无需再调用其他的 TC 排队规则和分类器
具体如下图所示
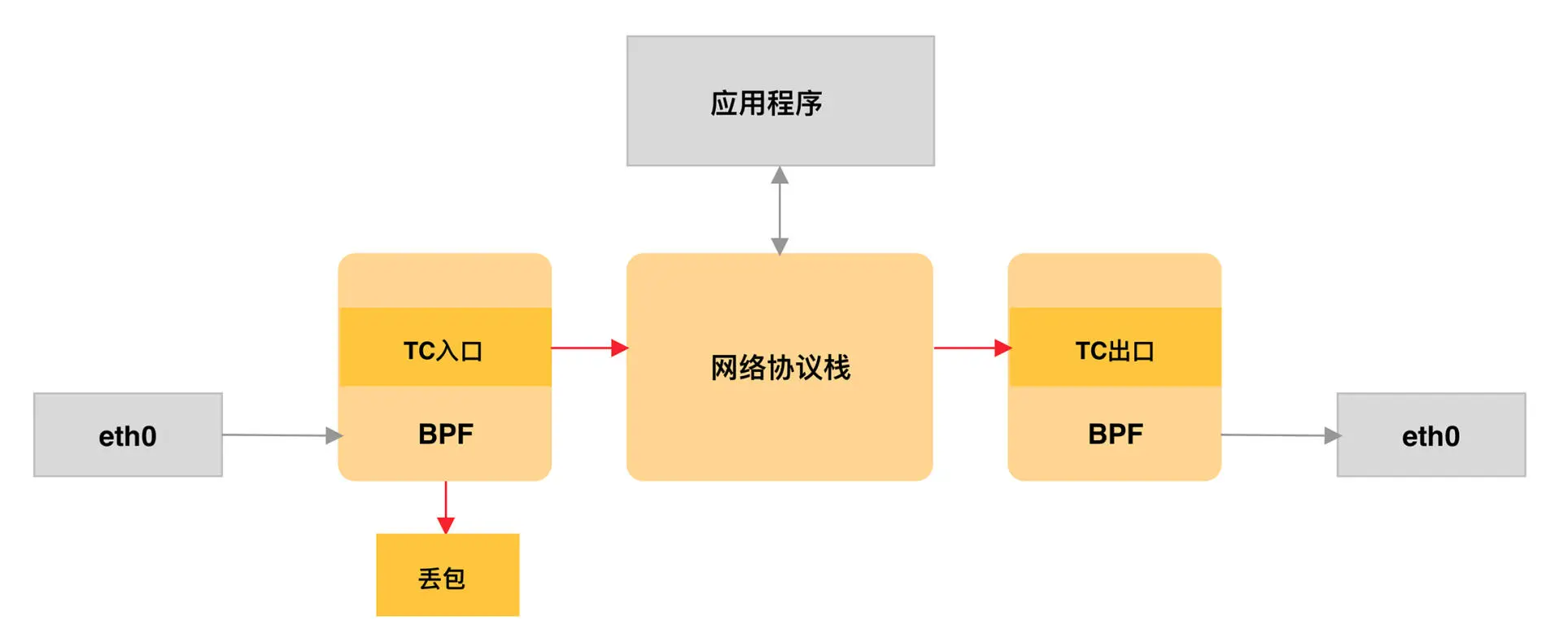
同 XDP 程序相比
- TC 程序可以直接获取内核解析后的网络报文数据结构sk_buff(XDP 则是 xdp_buff)
- 并且可在网卡的接收和发送两个方向上执行(XDP 则只能用于接收)
TC 程序的执行位置
- 对于接收的网络包,TC 程序在网卡接收(GRO)之后、协议栈处理(包括 IP 层处理和 iptables 等)之前执行
- 对于发送的网络包,TC 程序在协议栈处理(包括 IP 层处理和 iptables 等)之后、数据包发送到网卡队列(GSO)之前执行
除此之外,由于 TC 运行在内核协议栈中,不需要网卡驱动程序做任何改动,因而可以挂载到任意类型的网卡设备(包括容器等使用的虚拟网卡)上
同 XDP 程序一样,TC eBPF 程序也可以通过 Linux 命令行工具来加载到网卡上 不过相应的工具要换成 tc
下面命令分别加载接收和发送方向的 eBPF 程序
|
|
Socket
介绍
- 套接字程序用于过滤、观测或重定向套接字网络包
- 根据类型的不同,套接字 eBPF 程序可以挂载到套接字(socket)、控制组(cgroup )以及网络命名空间(netns)等各个位置
| 套接字程序类型 | 应用场景 | 挂载方法 |
|---|---|---|
| BPF_PROG_TYPE_SOCKET_FILTER | 用于套接字过滤和观测 | 用户态程序可通过系统调用 setsockopt(sock, SOL_SOCKET, SO_ATTACH_BPF, ...) ,绑定 BPF 程序到具体的 socket 上 |
| BPF_PROG_TYPE_SOCK_OPS | 用于套接字修改或重定向 | 用户态程序可通过 BPF 系统调用的 BPF_PROG_ATTACH 命令(指定挂载类型为 BPF_CGROUP_SOCK_OPS ),将其挂载到 cgroup 上 |
| BPF_PROG_TYPE_SK_SKB | 用于套接字修改或消息流动态解析 | 用户态程序可通过 BPF 系统调用的 BPF_PROG_ATTACH 命令(指定挂载类型为 BPF_SK_SKB_STREAM_VERDICT 或 BPF_SK_SKB_STREAM_PARSER ),将其挂载到 BPF_MAP_TYPE_SOCKMAP 类型的 BPF 映射上 |
| BPF_PROG_TYPE_SK_MSG | 用于控制内核是否发送消息到套接字 | 用户态程序可通过 BPF 系统调用的 BPF_PROG_ATTACH 命令(指定挂载类型为 BPF_SK_MSG_VERDICT )将其挂载到 BPF_MAP_TYPE_SOCKMAP 类型的 BPF 映射上 |
| BPF_PROG_TYPE_SK_REUSEPORT | 用于控制端口是否重用 | 用户态程序可通过系统调用 setsockopt(sock, SOL_SOCKET, SO_ATTACH_REUSEPORT_EBPF, ...) ,绑定 BPF 程序到具体的 socket 上 |
| BPF_PROG_TYPE_SK_LOOKUP | 用于为新的 TCP 连接选择监听套接字,或为 UDP 数据包选择未连接的套接字,可用来绕过 bind 系统调用的限制 | 用户态程序可通过系统调用 bpf(BPF_LINK_CREATE, ...) ,绑定 BPF 程序到网络命名空间(netns)上 |
cgroup
cgroup 程序用于对 cgroup 内所有进程的网络过滤、套接字选项以及转发等进行动态控制
它最典型的应用场景是对容器中运行的多个进程进行网络控制
| cgroup 程序类型 | 应用场景 |
|---|---|
| BPF_PROG_TYPE_CGROUP_SKB | 在入口和出口过滤数据包,并可以接受或拒绝数据包 |
| BPF_PROG_TYPE_CGROUP_SOCK | 在套接字创建、释放和绑定地址时,接受或拒绝操作,也可用来统计套接字信息 |
| BPF_PROG_TYPE_CGROUP_SOCKOPT | 在 setsockopt 和 getsockopt 操作中修改套接字选项 |
| BPF_PROG_TYPE_CGROUP_SOCK_ADDR | 在 connect、bind、sendto 和 recvmsg 操作中,修改 IP 地址和端口 |
| BPF_PROG_TYPE_CGROUP_DEVICE | 对设备文件的访问进行过滤 |
| BPF_PROG_TYPE_CGROUP_SYSCTL | 对 sysctl 的访问进行过滤 |
这些类型的 BPF 程序都可以通过 BPF 系统调用的 BPF_PROG_ATTACH 命令来进行挂载
并设置挂载类型为匹配的 BPF_CGROUP_xxx 类型
在挂载 BPF_PROG_TYPE_CGROUP_DEVICE 类型的 BPF 程序时,需要设置 bpf_attach_type 为 BPF_CGROUP_DEVICE:
|
|
补充
- 这几类网络 eBPF 程序是在不同的事件触发时执行的
- 因此,在实际应用中可以把多个类型的 eBPF 程序结合起来实现复杂的网络控制功能 比如,最流行的 Kubernetes 网络方案 Cilium 就大量使用了 XDP、TC 和套接字 eBPF 程序
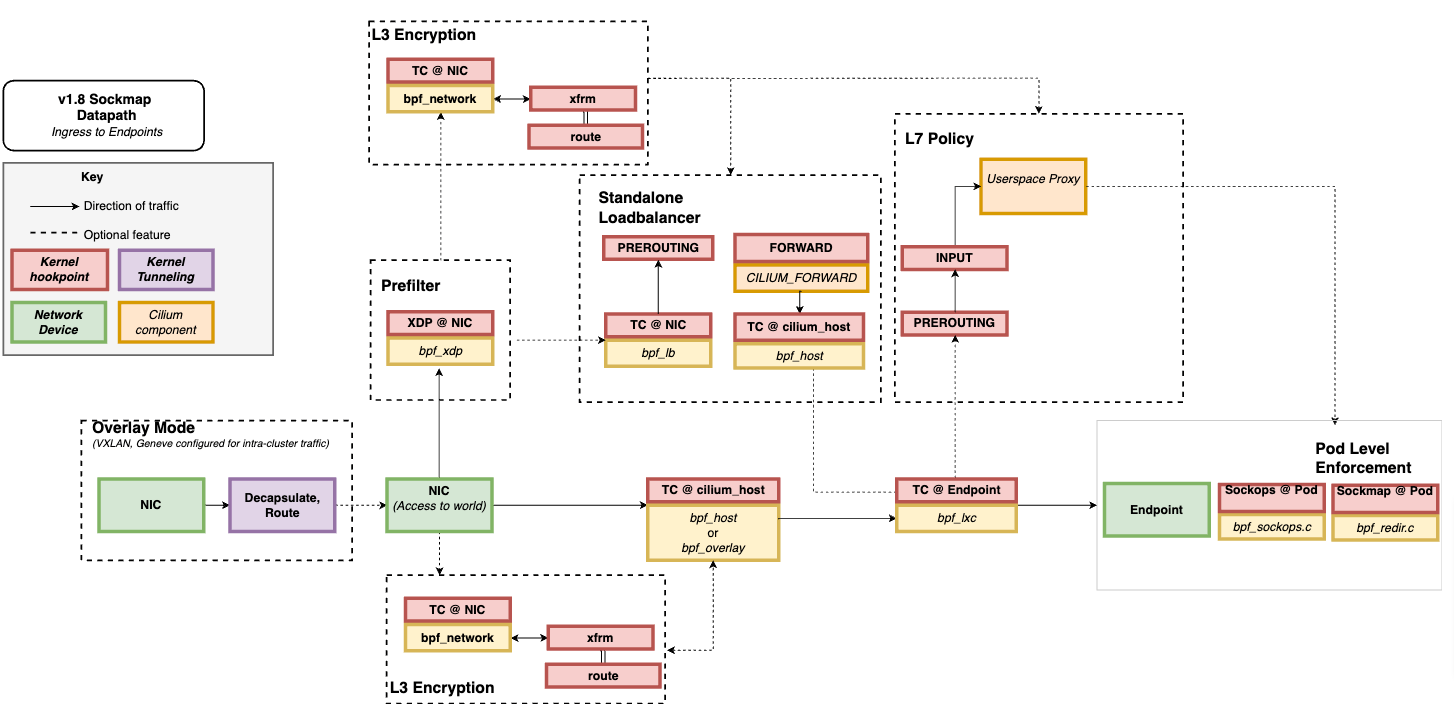 图片来自 Cilium 官方文档,图中黄色部分即为 Cilium eBPF 程序
图片来自 Cilium 官方文档,图中黄色部分即为 Cilium eBPF 程序
其他类 eBPF 程序
除了上面的跟踪和网络 eBPF 程序之外,Linux 内核还支持很多其他的类型
| BPF 程序类型 | 应用场景 |
|---|---|
| BPF_PROG_TYPE_LSM | 用于 Linux 安全模块(Linux Security Module, LSM)访问控制和审计策略 |
| BPF_PROG_TYPE_LWT_IN BPF_PROG_TYPE_LWT_OUT BPF_PROG_TYPE_LWT_XMIT | 用于轻量级隧道(如 vxlan、mpls 等)的封装或解封装 |
| BPF_PROG_TYPE_LIRC_MODE2 | 用于红外设备的远程遥控 |
| BPF_PROG_TYPE_STRUCT_OPS | 用于修改内核结构体,目前仅支持拥塞控制算法 tcp_congestion_ops |
| BPF_PROG_TYPE_FLOW_DISSECTOR | 用于内核流量解析器(Flow Dissector) |
| BPF_PROG_TYPE_EXT | 用于扩展 BPF 程序 |
参考
- bpf 官方文档
- BPF 内核文档
- ebpf
- bcc tools
- Introducing the Calico eBPF data plane
- brendangregg 博客
- bcc Reference Guide
- ebpf-apps github
- Kprobe & Uprobe - Linux Tracing
- eBPF 核心技术与实战
- BPF 学习系列之 - 内核探针 - kprobes 与 kretprobes
- bpf map映射简介
- Unofficial eBPF spec
- How Netflix uses eBPF flow logs at scale for network insight