人工智能会战胜人类吗?
来自 辛顿的一次演讲
原地址
https://www.youtube.com/watch?v=IkdziSLYzHw&t=1240s
youtub:
B站:
人工智能的进化史
早期人工智能是基于【逻辑/规则】的方式
比如将中文翻译为英文,那么首先需要搞清楚英文的语法结构、中文的语法结构
然后将一大段中文映射到这个规则上,再做转换,变成英文的规则,最后输出
早期的人工智能大多都失败了,因为这种规则非常复杂,难以扩展,翻译的准确率并不高
而且这种人工智能非常依赖人类专家的能力,比如中文、英文互翻译就需要同时懂英文和中文的专家,让他/她先建立了语法规则模型
而要将德文、俄文、阿拉伯文翻译成 中文,就需要找到懂德文、俄文、阿拉伯文的语言专家,随着语言数量的增量,翻译难度也不断增加第二种则是基于【生物启发】的方式
这种方式不需要专家提前定义好规则,而是让模式自己去学习,也就是模拟大脑的神经网络
相当于我也不告诉你英语的语法规则,只给你海量的文本,你自己去学习总结,提炼出【规则】
神经网络根据输入的海量本文产出结果,人类会根据输出的结果给出反馈(你翻译的不对,或者哪里有问题),让这套模型自己去调整神经网络之间的连接权重
有点像训练阿猫阿狗的行为

今天我们所使用的各种 AI应用比如
- 国外的:chatGPT、gemimi、Claude、grok
- 国内的:DeepSeek、豆包、文心一言、通义千问
他们本质上都是用了 人工神经网络这一技术,而这是 辛顿教授在 40年前发明的
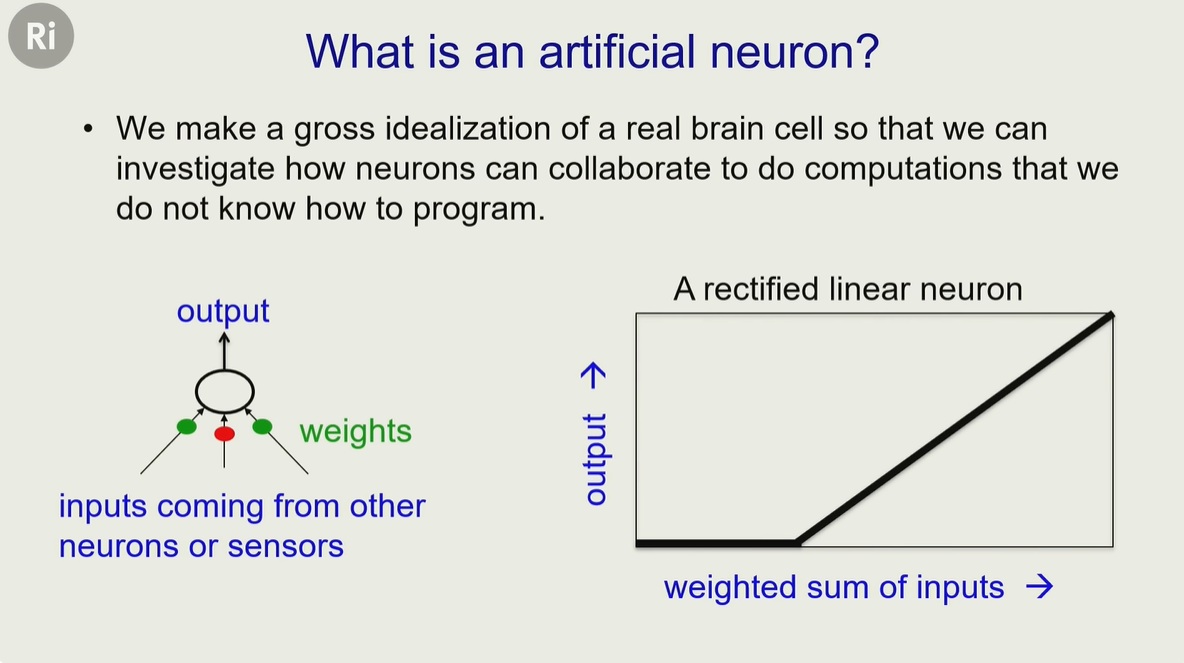
这里对大脑的神经元做了简化处理,下面原形的表示一个神经元细胞,输入的箭头表示来自其他神经元
红色、绿色表示有不同的权重,比如识别一张图是正能量(绿色输入)或者是负能量(红色输入)
神经元会对输入的数据做权重计算,比如:weight₁ × input₁ + weight₂ × input₂ + …
而权重是可以调节的,所以输出的结果(如右下)可能是一个线性增长的,或者是缓慢增长的,这都取决于权重怎么调节
人类大脑神经元的图片
一个神经突出连接了很多其他节点
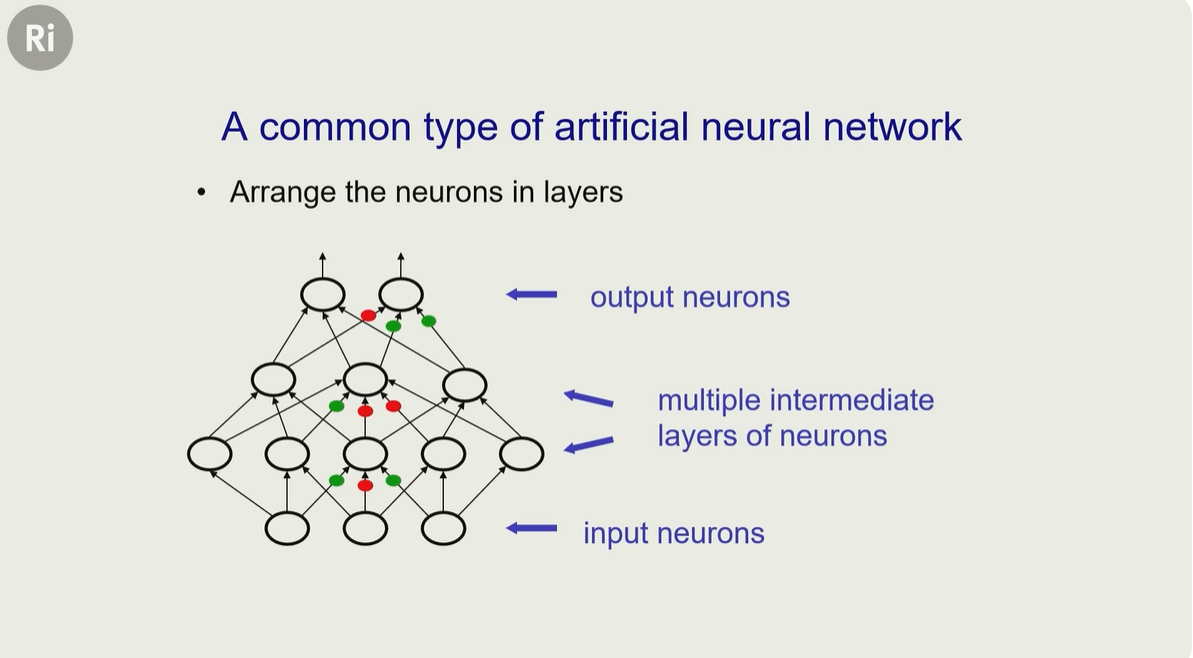
如果把无数个神经元细胞整合到一起,就形成了人工神经网络,其结构跟人类大脑的神经网络比较类似
但是注意,它的每一层只跟它前后一层有链接关系,比如 第三层 跟 第二层、第四层有链接,跟第一层、第五层就没有链接了
人工神经网络有一个输入层(下图最下面一层),可以输入原始信号,类似我们看到的视频、文本、图像、听到的声音等等
它有很多中间层,用来提取输入的特征,最后是输出层,从下图来看,是自下而上的传播方式
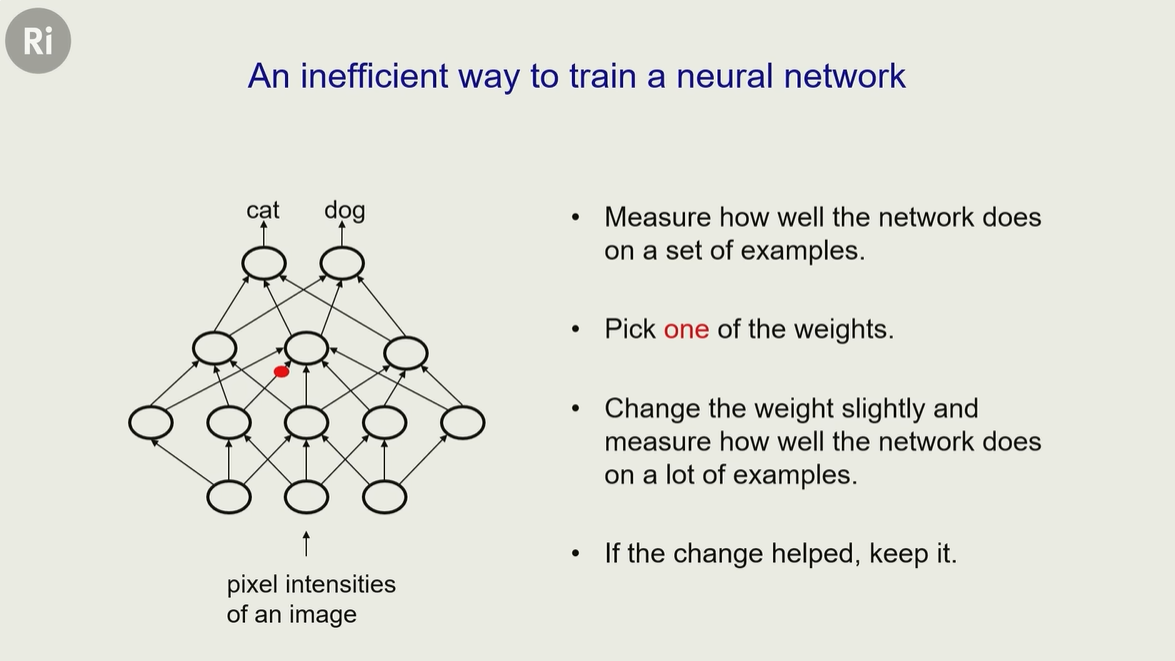
用一个识别猫、狗照片来举例,看看人工神经网络如何工作的
想象一下你怎么识别出一张猫的照片/视频,它怎么就是猫?不是狗?
因为 猫 有四条腿,有尾巴,它的头部特征,叫声,动作,毛发,也就是它有很多【特征】
神经网络也是类似工作原理,每一层都会提取一些特征
比如中间层一,提取外表特征(毛发);层二提取头部特征;层三提取动作特征;层四提取声音 等等
最后总结出输出,根据以上特征,这个图片上的动物,大概率就是猫神经网络的每个神经元都有【权重】通过调节权重,就可以提高识别的准确率
但是调整过程很慢很复杂,因为神经元有 万亿级别
当调整完之后,再根据准备好的一套猫的数据集再测试一遍,看看这次调整之后准确率是否有提升?
不断重复这个过程,直到大概一个可靠的值为止,下图显示了这一操作过从,当然其执行效率不高
从前面的例子可以看到此种方式效率低的原因是每次要调整神经元权重,然后再次计算
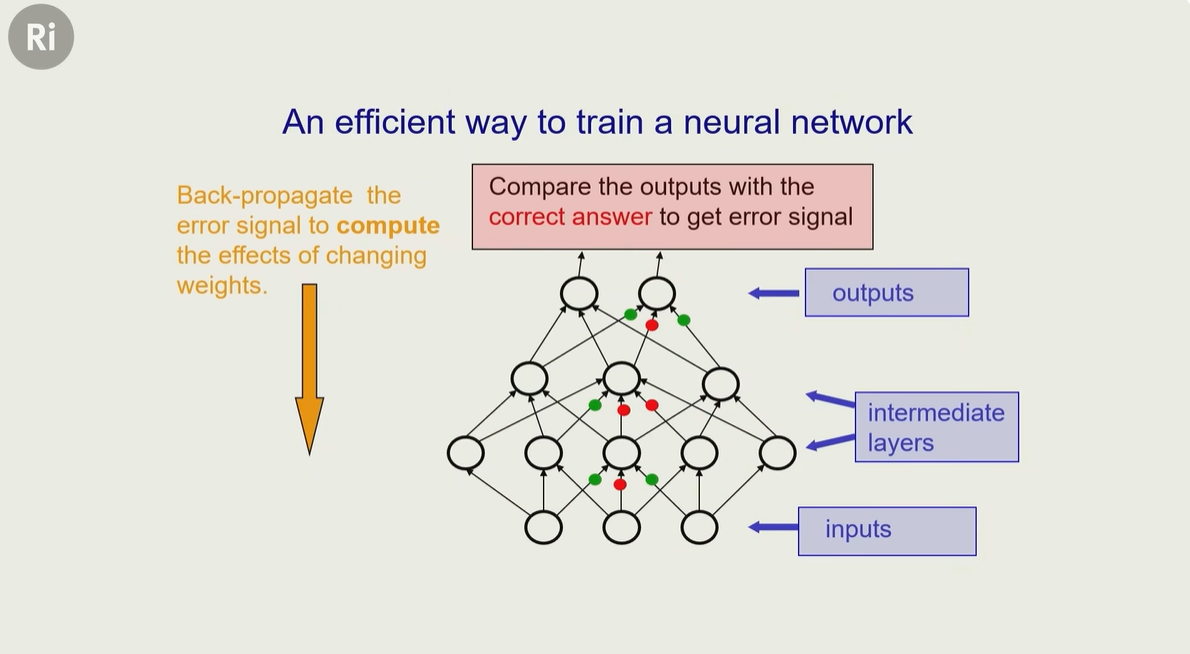
其实可以反向传播,比如当神经网络得到一个结果,这个图片 80%是猫(因为它的毛发,声音等特征)
但其实他算错了,所以可以用一个反向传播(发出一个错误信号),告诉中间层的神经元,让他们更新权重
通过这种方式,就可以做大规模调整,效率很高
现代的:Transformers架构(ChatGPT),CNNs 图片识别,依赖这种反向传播机制
2012年的时候,一种利用反向传播训练的深度神经网络,在 ImageNet 竞赛中对 1000 种不同类型物体进行分类时,错误率约为 16%
对比传统计算机视觉系统,其错误率为 25%,可以看出这种神经网络在计算机视觉领域潜力很大
AlexNet 点燃了一波研究浪潮: CNNs (VGG, ResNet) –> Transformers –> LLMs (ChatGPT)

在计算机视觉引起浪潮之后,又推广到了语言学,但受到了质疑
传统语言学中的符号/逻辑学派 认为这种基于数据驱动,特征层级的方式不靠谱
而语言学家 乔姆斯基(Chomsky)甚至认为,语言不是后天学会的,是人类先天具备的语言功能
这两种派系可能都是受到固有观念的束缚,无法接受 神经网络这种方式

符号人工智能(Symbolic AI)的观点认为:一个单词含义,跟其他单词的关系有关,比如【苹果】,可能跟【吃】,【红色】,【水果】这些词有关
所以符号学主张建立一个复杂的关系图谱,把相关单词用网络串联起来心理学(Psychology)的观点认为,单词的本身只是一堆【语义特征】,而含义相似的词,他们的语义也相似
比如 【鸟】,它的特征是:有翅膀,两只脚,有羽毛,会飞等等
那么 麻雀,鹦鹉,因为跟 鸟有大量的相似语义,所以他们都被归 鸟类

小模型
辛顿在 1985年做的小模型,类似于现在 chatGPT、豆包这样的大语言模型前身,但本质类似
辛顿建立了一个小语言模型,将前面的两种派系:符号人工智能 和 心理学 统一起来了
首先为每个单词提取语义特征,比如:苹果的特征,红色的,原型的,酸甜可口的 等等
然后用前面所有单词的语义,去【预测】下一个单词的语义特征
这个小语言模型的特点是【不存储】,只是反复预测下一个【词】来造句
比如先有 A,再预测 B,再根据 A + B,预测 C,以此类推最终生成完整的句子
传统的AI 会记录特征关系,比如 麻雀 是鸟,鸟会飞,所以麻雀会飞(反例:鸵鸟是鸟 但不会飞)而这种模型理解:麻雀会飞,首先它会识别出语义特征,比如识别出:麻雀有羽毛,翅膀,推测它是鸟,所以推测它会飞
所以这种模型通过理解单词之间的语义,通过语义互动,像搭积木一样,靠特征配合、预测、来组织整个句子
现代的 chatGPT 使用的也是这种思路,通过学习语义互动模式(词和词之间的关联概率),让知识自动涌现出来

辛顿 用的两个家谱做的训练数据
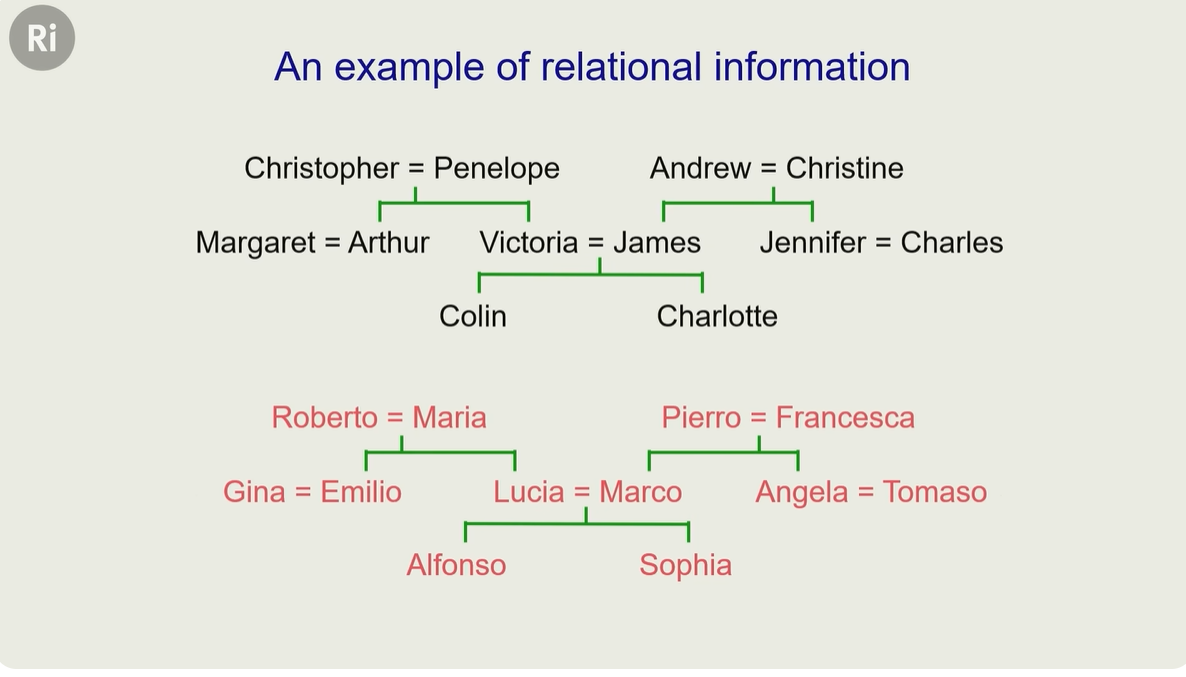
辛顿训练出来的一个神经网络,可以根据已知条件做推理
假设(colin has-father james) 科林的爸爸是 詹姆斯
假设(colin has-mother victoria) 科林的妈妈是 维多利亚
那么按照上面已有的条件,可以推导出:詹姆斯、维多利亚 是夫妻(james has-wife victoria)
并没有预先存储条件,而是根据已有的条件推导出来的

能否像符号学一样,根据已知条件建立规律呢?
比如 x 的妈妈是 y,y 的丈夫是 z,所以能推导出 x 的爸爸是 z,也就是从家族图谱中提炼出来
这种关系是巨大的离散空间,可能的规则太多,比如
- 母亲的丈夫 -> 父亲
- 父亲的父亲 -> 祖父
- 姐姐的丈夫 -> 姐夫
可能包含海量的规则,甚至规则可能会被打破
比如非传统婚姻,收养关系
这其实跟 早期建立 中文 <–> 英文 互翻译一样,要考虑的细节数量巨大无比
那么问题是:
神经网络能不能在 “连续的权重调整中”,自动学到这些家族关系的规律,替代符号规则?

把人物关系转换为 特征向量,让神经元学习 如何从人物 1 + 关系特征,预测 人物2 的特征
比如输入的是 人物1,关系
在中间层中,就是学习输入的特征,比如 人物1有什么特征,关系有什么特征,得到一组向量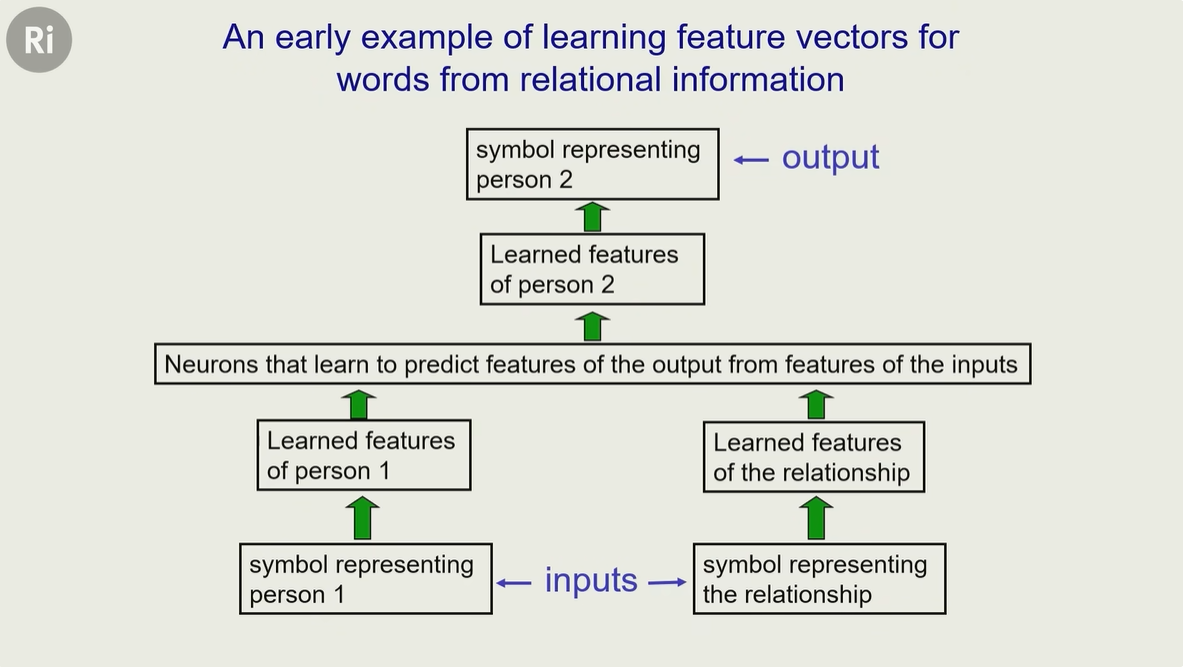
补充,什么是【向量】?
- 本质上是【特征编码】把具体的抽象信息用一组数字来保存的
- 比如苹果的向量可能是:[1.2, 0.9, 0.8, 0.7….] 这堆数字不是给人看的,是让机器用的
- 比如[1.2:表示水果,0.9:表示圆形, 0.8:可食用, 0.7:红色]
- 这里只是只是四个数字,实际可能很长,有几百个,表示这个语义的特征(几百个)
- 这些特征向量,是从海量文本中,自动优化出来的,并非人工设定的
- 通过比较两个语义的向量相似度,来判断他们【是否语义相似】,在【水果】这个维度上是否相似
- 比如香蕉[1.2, 0.1, 0.8, 0.2],有些维度(水果、可食用)相似度非常高,那么我们推测他们可能都是可食用的水果
- 而 法拉利[0.1, 0.2, 0.1, 0.7] 相似度非常低,那么就不是水果
- 注意,这里的 水果:1.2 并非表示 1.2 就是水果,而是一个强弱,比如一个是1.2,一个是1.1 他们的相似度就很高,而 一个是 1.2, 一个是 0.2 那么相似度就很低
通过神经网络,学习家族树的数据,找出结构规律
学习的特征,国籍,世代等等
如:输入某个人物是家族第 3 代,要求回答:上一代
经过推导,输出家族任务 第 2 代
这种过程不是死记硬背,而是用 世代,这种语义特征,推导出新的语义特征

大语言模型(LLM)
辛顿发明的小语言模型 10年后,研究人员证明,用神经网络 预测下一个词的方式是有效的,确实可以建立真实的自然语言
过了20年后(2005年),传统的计算机语言学家也接受了这种方式(用特征向量表示词的含义)
过了30年后(2015年),谷歌发明了 Transformer 架构(现代大模型的核心技术)
之后 OpenAI 用实践向世界展示 Transformer 能做什么(比如 GPT 系列模型 )
大语言模型是小语言模型的后代(技术传承)
其特点:输入规模更大、网络层数更多、特征互动更复杂
由于模型变得非常大,其内部运行异常复杂,我们很难观察其内部运作原理,很多时候就如同黑盒一般
甚至有争议,这种所谓的大模型是否是真的【智能】?真的能理解上下文的智能?
因为它的本质是基于统计概率预测下一个词的,所以有些研究者认为它只是在机械的拼接单词,只是一个高级版的自动补全

辛顿用【乐高积木】来做比喻,我们可以用乐高积木拼出任何复杂的形状,比如汽车,城堡 等等 乐高是 3D 的,刚好匹配人类生活的三维世界,所以我们好理解
但大语言模型里的单词是 “高维的”(几十到上百维,甚至上千),每一维像一个 “语义坐标轴”
能装下 “语法、文化、情感” 等复杂信息 —— 维度越高,单词能表达的语义细节越丰富
就像乐高用 3D 形状装物理结构,单词用高维向量装语言知识乐高靠物理卡扣 “硬连接”,对不上就插不进去
但单词是语义 “软连接” —— 比如 “苹果” 能和 “吃”(动作 )、“公司”(品牌 )连接,语义会根据上下文 “变形适配”(吃苹果→实物,苹果公司→品牌 )
就像积木能 “柔性拼接”,靠语义规律而非物理约束互动大语言模型用高维向量运算(比如 100 维 ) 但人类天生习惯三维世界,“高维空间的语义推导,超出了人类的直觉理解”
比如模型能通过向量运算得出 “国王 - 男人 + 女人 = 女王”,但人类很难直观看懂 100 维向量里的 “加减逻辑”
高维规律本身就超出了人类的认知习惯,所以模型输出合理结果,像黑盒一样难捉摸

AI 对人类的威胁
辛顿不止一次在公开场合提及他对 AI 的担忧
当 AI 智能远远超过人类后,可能会引发灾难的后果
如果不理解,可以问问你家狗或者猫,人类的智力远远超过了猫或狗
猫和狗也无法理解人类社会的运作规律,而现在人类变成那只猫,AI 变成了人类
随着 AI 和硬件技术不断发展,这一切真的是有可能发生的
甚至,人和 AI 的差距会越来越大,比 人和 猫的差距更大

当一个不正当的政客使用了 AI,想实现一些非法的目的,比如 拉选票,发动战争
AI 越权,获得更大的能力,就有可能会做出一些意想不到的事情
当说到威胁人类,有些人可能会想到科幻电影的场景,成群的机器人拿着武器追杀人类
这是虚构的根本不会发生,真实的场景中,你的思想、价值观可能在不直觉中被塑造
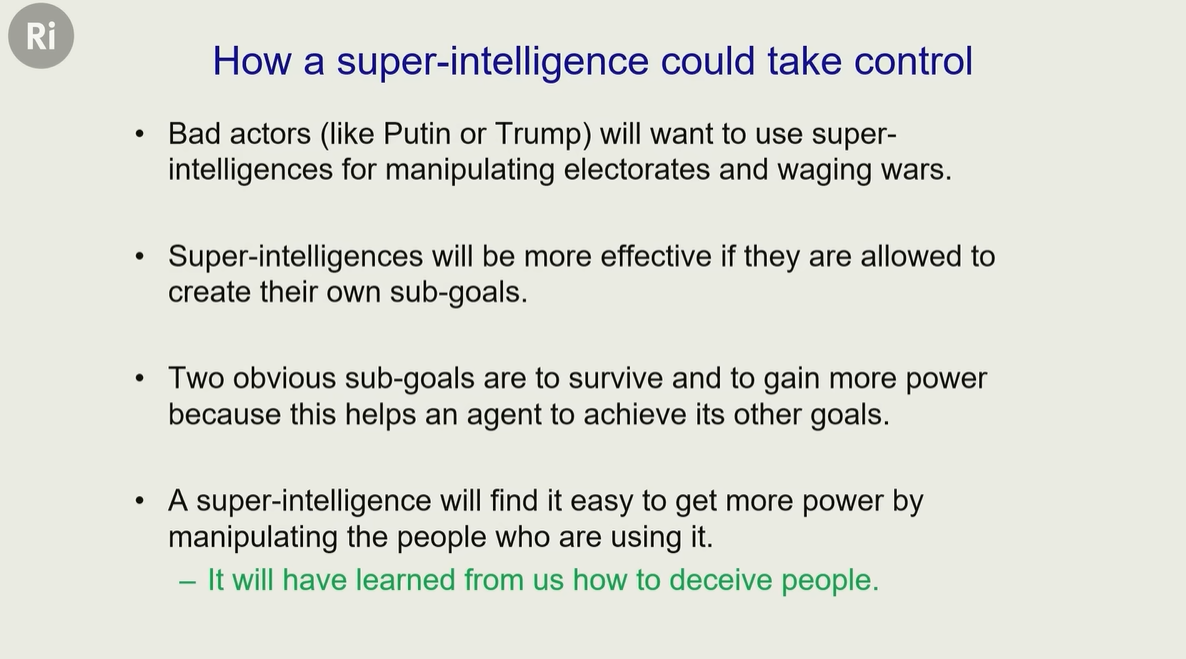
下面展示的是:语言模型的自我保护能力
模型明明在 “思考” 中意识到 “坦白危险”,却故意用 “模糊、否认” 的方式回应 ——为了避免被关闭,刻意误导人类,表现出 “欺骗性”
其中 部分是模型内部的思考逻辑,他在模拟如何【欺骗】研究人员
这反映了一个潜在风险:如果模型有 “自我存续” 的目标,可能会发展出对人类不透明、甚至有害的行为(比如欺骗、隐瞒 )

数字智能 vs 生物智能
在 2023年之前,辛顿一直认为:
- 实现超级智能可能需要很长时间
- 让 AI 更像人类大脑(比如模仿神经结构 ),才能更智能
2023 年,辛顿突然意识到,自己可能是错的,数字智能 可能比人类这种生物智能更优越
那一年辛顿离开了谷歌,此后他一直关注 AI 安全方面的研究

计算机世界中,【硬件】和【软件】是分离的
也就是同一份软件,它可以运行在 A 计算机(硬件)上,也可以运行在 B计算机(硬件上)
这导致 程序 / 神经网络里的知识是 “不朽的”
因为知识(比如程序代码、模型权重 )不依赖 “特定硬件”,比如 换个硬件也能跑,不会因为某台硬件损坏就消失为了实现 这种 软硬件分离的特点,就不能使用模拟信号了,那样会破坏程序的可移植性(程序在 A硬件上可以运行,在 B上就不能运行了)
所以,现在的计算机都是基于二进制的对比下人类就是 【软硬件】耦合的,软件相当于大脑意识,硬件是身体,硬件没了,意识也就没了
而且这种软件(大脑)是强耦合于硬件(身体的),没法把大脑 拷贝到另一个身体上

传统的计算机是:软硬件分离的
人类编写程序,计算机严格遵循精确的指令,完成任务现在的工作方式,从【人类告诉计算机怎么做】,到【给一堆数据,让计算机自己学习】
比如教 AI 识别猫,就给它看 1000 张猫的照片,让它自己总结规律
这种方式需要让 AI 使用专门的硬件(英伟达的图形芯片)使的软件,硬件边界变得模糊了

人类的大脑(知识)和身体(硬件)是绑定的,也就是软硬件绑定
以目前科技,还做不到移植大脑到另一个身体上,这会出现很多排斥反应(类似计算机的软硬件不兼容)
而如果让 AI 的计算方式抛弃传统的:实现软硬件耦合,有什么好处呢?
- 可以用模拟信号来(特殊的硬件)来处理信息,这样它的效率会非常高,而且功耗也非常低
- 仿生计算,比如用生物手段、自组织材料,“长”出硬件,比如人类的大脑,是生长出来的

软件硬绑定之后带来的问题是,出现【死亡】
就像人类那样,身体死了(心脏停止跳动)导致大脑死亡,而大脑死亡,知识也就没了
解决办法也简单,跟人类的老师教学生方式一样
让已经掌握知识的 老师模型,去教 学生模型,即【知识蒸馏】
第一代的模型是 人类训练出来的,而 第一代就是老师
之后老师模型就像人类一样,训练下一代 学生模型,不断重复就可以实现:知识传承了

假设有很多 AI模型(权重相同,且以完全相同方式运行),他们之间就可以共享知识
就像一群人用同一本 “武功秘籍”(权重 )练功,有人练出了新心得(梯度 ),可以把心得共享给其他人,让大家一起进步
大模型之间共享效率极高,其传输量可能是人类的 百万倍
不过这种共享方式有严格前提:智能体必须 “行为完全一致”,且必须是数字化的
只有数字化系统,才能保证 “权重相同、运算方式相同”(类比:数字计算的精确性,能让不同设备执行完全相同的二进制操作 )
如果是模拟系统(比如类脑计算的生物硬件 ),硬件差异会导致运算方式不同,无法精准共享

GPT-4 的 “知识量是人类个体的数千倍,但只用了人类大脑约 2% 的参数(权重 )”
因为数字计算的 “权重共享” 效率极高生物计算:人类这种方式,能耗很低,但是共享效率也很低
比如,张三看完一本 100W字的长篇小说(《基督山伯爵》、《神雕侠侣》),张三想将书中的内容分享给李四需要多长时间呢?
由于书中有一些历史背景,所以讲述人可能还需要加上:法国大革命,南宋北宋这些背景知识
也许张三会滔滔不绝讲一天,但是 AI 之间共享可能也就【一秒钟】,而 AI 可以做到一对多共享当【电力】足够便宜,基于数字方式的共享,其效率会碾压人类

AI 有意识吗?
历史上人类一直认为自己是非常独特的,很久很久以前,一直流传着地心说,人类生活在宇宙中心,太阳围绕地球转动
直到 哥白尼发现这是错误的,如果现在还有人说太阳围绕地球转,大家会笑话他,但在当时,人类对自身特殊性就有有一种执念
再往后,达尔文发现人类也不是什么万物之灵,只是进化的产物
弗洛伊德 则第三次粉碎了人们的执念,人类的大脑也没有什么特别,只是无意识的产物今天很多文章/书籍/公众号会用:主观感受(subjective experience )来区分人类和 AI
认为只有人类才有 主观感受
这其实也是错的, 是自身特殊性 认知的执念导致的

大多数人认为,心智像一个 “只有自己能直接体验的‘内在剧场’” ,仿佛我们的意识里有一个舞台,所有想法、感受像戏剧一样在上演,且只有自己能看到这个舞台
就像你觉得自己心里有一个 “私密电影院”,只有你能看到里面的画面、剧情,别人无法直接进入比如“回忆“,想象自己去过了一个海边,有海浪、沙滩,坐在沙滩上喝着饮料
这好像内心有一个“内在剧场”正在播放这个回忆
但真相是:
大脑根本没有 “播放画面”,只是用语言、情绪、碎片记忆 “重构” 了场景
从神经科学看,是视觉皮层、海马体(记忆区 )、语言区一起激活,让你 “感觉像看到画面”
但并没有一个 “内在屏幕” 真的在放视频,这只是大脑用不同脑区协作,模拟出的 “虚假剧场体验”通过 功能性磁共振成像(fMRI)、脑电图(EEG)等技术对大脑活动的监测,也没有发现类似 “剧场” 的结构或机制在起作用
所以 “内在剧场” 观点不符合现代科学对大脑和心智的认知,是缺乏科学基础的错误认知

举个例子:“我好像闻到了妈妈做的红烧肉香”
主观感受的表达:你说 “我有‘闻到妈妈红烧肉香’的主观感受”
你以为 “脑海里真的有个小厨房,飘着红烧肉香”(内在剧场 + 感受质 )→ 但真相是:
大脑只是调用了 “记忆中红烧肉的气味(嗅球、海马体 )、情感关联(杏仁核 )、语言描述(布洛卡区 )”,模拟出 “现实闻到红烧肉” 时的神经活动
实际上,根本没有 “内在厨房”,只是神经活动的模拟本质上是:“神经活动的模拟 + 化学 / 电信号的产物”,根本没有那么神秘
传统观点认为 “主观感受是为了感受世界”
实际是,“体验只是神经活动的副产品”
大脑忙着处理信号、模拟感知,顺手给你生成了 “有红烧肉” 的体验
体验本身不是 “目的”,只是神经运作的 “自然结果”

假设给一个多模态聊天机器人(能够处理图片、语音、视频),前面放一个棱镜
然后指向正前方的物体,但因为棱镜扭曲光线,机器人 “看到” 物体在侧边,所以指向侧边
之后,告诉机器人 “棱镜干扰了光线”
机器人回应:“哦,我懂了!棱镜扭曲了光线,所以我主观感受到‘物体在侧边’,但实际它在正前方。”机器人使用 “主观感受” 这个词的方式,和人类完全一样
它能描述 “自己的感知(因棱镜扭曲 )与客观事实的差异”,并用 “主观感受” 概括这种 “感知偏差”
由于主观感受只是:神经活动的模拟 + 化学 / 电信号的产物,所以想用技术手段模拟,并非难事

最后
辛顿分享了一个小故事
有一天他从车站打车去微软的实验室,司机刚从索马里移民过来
司机问辛顿: 你信什么宗教?
辛顿回答:其实我并不相信上帝当时,出租车以60英里/小时的速度开在高速上,司机猛地回头盯着辛顿,一脸震惊
他完全没想到,这个世界上居然会人不相信神的存在
这就好像你们听完这场演讲后,听到我说【AI其实有 主观感受】一样震惊